Машинное обучение как оно есть сейчас
В популярных методах машинного обучения программа не выучивает алгоритм. Классификатор, нейронная сеть или, для большей очевидности, методы регрессии выучивают в лучшем случае функцию (в математическом, а не программистском смысле): имея входные данные, выдать выходные данные. Это может быть в лучшем случае единственным шагом алгоритма и не понятно, как масштабировать такое решение на целый алгоритм вместо одного шага. Без возможности выучивать алгоритмы, эти методы далеки от AGI (общего искусственного интеллекта — Artificial General Intelligence). На пути к AGI неплохо бы найти способ, чтобы программы выучивали алгоритмы с ветвлением, циклами и подпрограммами. Далее следует научить программы понимать другие программы. Далее понимать и улучшать саму себя. Не настаиваю что именно этим путём люди пройдут к AGI, но это моё скромное виденье.
Программа как прикладной искусственный интеллект
В отличие от других методов машинного обучения, в своё свободное время я сделал интерактивную систему, которая задаёт пользователю вопросы и после каждого ответа выдаёт список возможных целей — что может прийтись пользователю по вкусу, будь то новая игра, фильм, книга, товар или услуга. Смысл нового поисковика в том, что пользователь может не иметь представления о том, что именно он(а) ищет, поэтому не может сформировать ключевых слов чтобы вбить в существующие поисковики. А вот ответить на вопросы программы может, и всегда есть вариант «не знаю/затрудняюсь ответить».
Реализация и конкуренты
Пример как это работает можно увидеть у других, кто сделал что-то похожее: Akinator.
Реализован только back-end на C++. Жду когда кто-нибудь напишет front-end web-приложения. Сам по такому не специализируюсь.
Программа изучает алгоритмы
Так получается, что программа ProbQA (Probabilistic Question Asking) в отличие от других методов машинного обучения, по сути способна выучивать алгоритмы. Она показала хорошие результаты в изучении алгоритма двоичного поиска (дихотомии), смотрите картинку ниже. Мы можем говорить, что она выучивает алгоритмы, потому что с её знаниями программа делает следующее: взаимодействие с пользователем в нескольких шагах, ведущее к конечным целям. Программа запрашивает ввод, далее в зависимости от ввода ветвится и спрашивает пользователя о чём-то ещё.

На картинке выше приведена кривая изучения программой алгоритма дихотомии. По оси X количество заданных программой и отвеченных пользователем вопросов, по оси Y процент правильно угаданных целей двоичного поиска для 256 следующих одна за одной попыток. Тестирование всегда проводится на новых данных: мы загадываем случайное число от 0 до 999, и даём программе угадать его путём задавания вопросов и получения ответов от пользователя (в данном случае, пользователь — тестирующая программа, которая знает загаданное число). Далее, если ProbQA угадала правильно, или же провалилась (задала более 100 вопросов), мы её учим, раскрывая выбранное тестирующей программой число.
Как мы видим из картинки, обучение ProbQA до 100% точности занимает количество вопросов и ответов, примерно равное размеру матрицы. В нашем случае матрица состоит из 1000 вопросов умноженное на 5 вариантов ответа умноженное на 1000 целей. Каждый i-й вопрос из этих 1000 имеет вид «Как загаданное число сравнимо с числом i?». Варианты ответа: 0 — «Загаданное число намного меньше чем i», 1 — «Загаданное число чуть меньше i», 2 — «Загаданное число равно i», 3- «Загаданное число чуть больше i», 4 — «Загаданное число намного больше i».
Теперь интересует такой вопрос: какая длина цепочки вопросов, приводящей к правильной цели? На картинке ниже мы можем видеть что сначала (во время тренировки) программа задаёт много вопросов, но когда программа уже выучила алгоритм, средняя длина цепочки падает где-то до 7 вопросов.
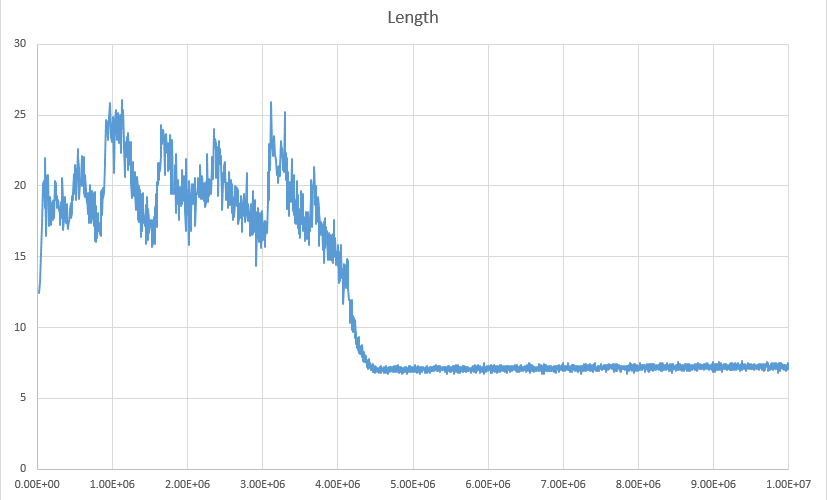
Результат можно считать хорошим, учитывая что написанный человеком алгоритм двоичного поиска задаёт ln(1000)/ln(4) = 5 вопросов. Оставшиеся 2 вопроса нужны программе чтобы продолжать учиться, а не выкладываться по полной, не узнавая ничего нового. Это контролируется упомянутой выше функцией приоритетов и тем, что выбирается не «самый-самый» дифференцирующий вопрос, а взвешенно-случайный.
Кроме того что написанный человеком алгоритм дихотомии не учится, следует заметить что такой алгоритм не толерантен к ошибкам. Если он где-то на вход получит неправильный ответ, то после этого уже не найдёт загаданное число. В то время как ProbQA сортирует цели по их вероятностям.
Долгосрочная перспектива
Пока что в виде ссылок на английском языке, т.к. информация малотехническая и может попадать в категорию «мечты».
Если будут желающие, могу написать отдельную статью на основе тех двух.
