 Так сложилось, что основным языком для работы с микроконтроллерами является C. Многие крупные проекты написаны именно на нем. Но жизнь не стоит на месте. Современные средства разработки уже давно позволяют использовать C++ при разработке ПО для встраиваемых систем. Однако такой подход до сих пор встречается достаточно редко. Не так давно я попробовал использовать С++ при работе над очередным проектом. Об этом опыте я и расскажу в данной статье.
Так сложилось, что основным языком для работы с микроконтроллерами является C. Многие крупные проекты написаны именно на нем. Но жизнь не стоит на месте. Современные средства разработки уже давно позволяют использовать C++ при разработке ПО для встраиваемых систем. Однако такой подход до сих пор встречается достаточно редко. Не так давно я попробовал использовать С++ при работе над очередным проектом. Об этом опыте я и расскажу в данной статье.Вступление
Большая часть моей работы с микроконтроллерами связана именно с C. Сначала это было требованиями заказчика, а потом стало просто привычкой. При этом, когда дело касалось приложений для Windows, то там использовался сначала C++, ну а потом вообще C#.
Вопросов по поводу C или C++ не возникало долгое время. Даже выход очередной версии MDK от Keil с поддержкой C++ для ARM особо меня не смутил. Если посмотреть демо-проекты Keil, то там все написано на C. При этом C++ вынесен в отдельную папку наравне с Blinky-проектом. CMSIS и LPCOpen тоже написан на C. И если “все” используют C, значит есть какие-то причины.
Но многое поменял .Net Micro Framework. Если кто не знает, то это реализация .Net позволяющая писать приложения для микроконтроллеров на C# в Visual Studio. Более подробно с ним можно познакомиться в этих статьях.
Так вот, .Net Micro Framework написан c использованием C++. Впечатлившись этим, я решил попробовать написать очередной проект на С++. Сразу скажу, что однозначных доводов в пользу С++ я в итоге так и не нашел, но некоторые интересные и полезные моменты в таком подходе есть.
В чем разница между проектами на С и С++?
Одно из самых главных отличий между C и C++ — то, что второй является объектно-ориентированным языком. Всем известные инкапсуляция, полиморфизм и наследование являются тут привычным делом. С — это процедурный язык. Тут есть только функции и процедуры, а для логической группировки кода используются модули (пара .h + .c). Но если присмотреться к тому, как C используется в микроконтроллерах, то можно увидеть обычный объектно-ориентированный подход.
Посмотрим на код работы со светодиодами из примера Keil для MCB1000 (Keil_v5\ARM\Boards\Keil\MCB1000\MCB11C14\CAN_Demo):
LED.h:
#ifndef __LED_H
#define __LED_H
/* LED Definitions */
#define LED_NUM 8 /* Number of user LEDs */
extern void LED_init(void);
extern void LED_on (uint8_t led);
extern void LED_off (uint8_t led);
extern void LED_out (uint8_t led);
#endif
LED.c:
#include "LPC11xx.h" /* LPC11xx definitions */
#include "LED.h"
const unsigned long led_mask[] = {1UL << 0, 1UL << 1, 1UL << 2, 1UL << 3,
1UL << 4, 1UL << 5, 1UL << 6, 1UL << 7 };
/*----------------------------------------------------------------------------
initialize LED Pins
*----------------------------------------------------------------------------*/
void LED_init (void) {
LPC_SYSCON->SYSAHBCLKCTRL |= (1UL << 6); /* enable clock for GPIO */
/* configure GPIO as output */
LPC_GPIO2->DIR |= (led_mask[0] | led_mask[1] | led_mask[2] | led_mask[3] |
led_mask[4] | led_mask[5] | led_mask[6] | led_mask[7] );
LPC_GPIO2->DATA &= ~(led_mask[0] | led_mask[1] | led_mask[2] | led_mask[3] |
led_mask[4] | led_mask[5] | led_mask[6] | led_mask[7] );
}
/*----------------------------------------------------------------------------
Function that turns on requested LED
*----------------------------------------------------------------------------*/
void LED_on (uint8_t num) {
LPC_GPIO2->DATA |= led_mask[num];
}
/*----------------------------------------------------------------------------
Function that turns off requested LED
*----------------------------------------------------------------------------*/
void LED_off (uint8_t num) {
LPC_GPIO2->DATA &= ~led_mask[num];
}
/*----------------------------------------------------------------------------
Output value to LEDs
*----------------------------------------------------------------------------*/
void LED_out(uint8_t value) {
int i;
for (i = 0; i < LED_NUM; i++) {
if (value & (1<<i)) {
LED_on (i);
} else {
LED_off(i);
}
}
}
Если присмотреться, то можно привести аналогию с ООП. LED представляет собой объект, имеющий одну публичную константу, конструктор, 3 публичных метода и одно приватное поле:
class LED
{
private:
const unsigned long led_mask[] = {1UL << 0, 1UL << 1, 1UL << 2, 1UL << 3,
1UL << 4, 1UL << 5, 1UL << 6, 1UL << 7 };
public:
unsigned char LED_NUM=8;
public:
LED(); //Аналог LED_init
void on (uint8_t led);
void off (uint8_t led);
void out (uint8_t led);
}
Несмотря не то, что код написан на C, в нем используется парадигма объектного программирования. Файл .C представляет собой объект, позволяющий инкапсулировать внутри механизмы реализации публичных методов, описанных в .h файле. Вот только наследования тут нет, поэтому и полиморфизма тоже.
Большая часть кода в проектах, которые я встречал, написана в таком же стиле. И если используется ООП подход, то почему бы не использовать язык, полноценно его поддерживающий? При этом при переходе на C++ по большому счету будет меняться только синтаксис, но не принципы разработки.
Рассмотрим другой пример. Пусть у нас есть устройство, которое использует датчик температуры, подключенный по I2C. Но вот вышла новая ревизия устройства и этот же датчик теперь подключен к SPI. Что делать? Нужно же поддерживать и первую и вторую ревизию устройства, значит, код должен гибко учитывать эти изменения. В С для этого можно использовать предопределения #define, чтобы не писать два почти одинаковых файла. Например
#ifdef REV1
#include “i2c.h”
#endif
#ifdef REV2
#include “spi.h”
#endif
void TEMPERATURE_init()
{
#ifdef REV1
I2C_int()
#endif
#ifdef REV2
SPI_int()
#endif
}
и так далее.
В С++ можно эту задачу решить немного элегантнее. Сделать интерфейс
class ITemperature
{
public:
virtual unsigned char GetValue() = 0;
}
и сделать 2 реализации
class Temperature_I2C: public ITemperature
{
public:
virtual unsigned char GetValue();
}
class Temperature_SPI: public ITemperature
{
public:
virtual unsigned char GetValue();
}
А затем использовать ту или иную реализацию в зависимости от ревизии:
class TemperatureGetter
{
private:
ITemperature* _temperature;
pubic:
Init(ITemperature* temperature)
{
_temperature = temperature;
}
private:
void GetTemperature()
{
_temperature->GetValue();
}
#ifdef REV1
Temperature_I2C temperature;
#endif
#ifdef REV2
Temperature_SPI temperature;
#endif
TemperatureGetter tGetter;
void main()
{
tGetter.Init(&temperature);
}
Вроде бы разница не очень большая между кодом на C и C++. Объектно-ориентированный вариант выглядит даже более громоздким. Но он позволяет сделать более гибкое решение.
При использовании С можно выделить два основных решения:
- Использовать #define, как показано выше. Данный вариант не очень хорош тем, что “размывает” ответственность модуля. Получается, что он отвечает за несколько ревизий проекта. Когда таких файлов становится много, поддерживать их становится довольно сложно.
- Сделать 2 модуля, так же как при C++. Тут “размытия” не происходит, но усложняется использование этих модулей. Так как у них нет единого интерфейса, то использование каждого метода из этой пары нужно обрамлять в #ifdef. Это ухудшает читаемость, а следовательно, и поддерживаемость кода. И чем выше по абстракции нужно будет поднимать место разделения, тем более громоздким получится код. При этом нужно еще продумывать названия функций для каждого модуля, чтобы они не пересекались, что тоже чревато ухудшением читаемости кода.
Использование полиморфизма дает более красивый результат. С одной стороны, каждый класс решает четкую атомарную задачу, с другой стороны, код не замусорен и легко читается.
“Разветвление” кода на ревизии все равно придется делать и в первом и во втором случае, но использование полиморфизма позволяет легче переносить место разветвления между слоями программы, при этом не загромождать код лишними #ifdef.
Использование полиморфизма позволяет легко сделать еще более интересное решение.
Допустим вышла новая ревизия, в которой стоят оба датчика температуры.
Тот же код при минимальных изменениях позволяет выбирать вам SPI и I2C реализацию в реальном времени, просто используя метод Init(&temperature).
Пример очень упрощенный, но в реальном проекте я использовал тот же подход, чтобы реализовать один и тот же протокол по верх двух разных физических интерфейсов передачи данных. Это позволило легко вынести выбор интерфейса в настройки устройства.
Однако при всем выше сказанном, разница между использованием С и С++ остается не очень большой. Преимущества С++, связанные с ООП не столь очевидны и являются из разряда “на любителя”. Но у использования С++ в микроконтроллерах есть и достаточно серьезные проблемы.
Чем опасно использование C++?
Вторым важным отличием C от C++ является использование памяти. C язык по большей части статический. Все функции и процедуры имеют фиксированные адреса, а работа с кучей ведется только по необходимости. С++ — язык более динамический. Обычно его использование подразумевает активную работу с выделением и освобождением памяти. Этим то C++ и опасен. В микроконтроллерах очень мало ресурсов, поэтому важен контроль над ними. Бесконтрольное использование оперативной памяти чревато порчей хранящихся там данных и такими ”чудесами” в работе программы, что мало не покажется никому. Многие разработчики сталкивались с такими проблемами.
Если внимательнее посмотреть на примеры выше, то можно отметить, что классы не имеют конструкторов и декструкторов. Это сделано потому, что они никогда не создаются динамически.
При использовании динамической памяти (и при использовании new) всегда вызывается функция malloc, которая выделяет необходимое количество байт из кучи (heap). Даже если вы все продумаете (хотя это очень сложно) и будете контролировать использование памяти, вы можете столкнуться с проблемой ее фрагментации.
Кучу можно представить в виде массива. Для примера выделим под нее 20 байт:

При каждом выделении памяти происходит просмотр всей памяти (слева направо или справа налево — это не так важно) на предмет наличия заданного количества незанятых байт. Причем эти байты должны все располагаться рядом:
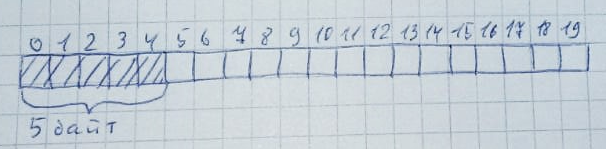
Когда память больше не нужна, она возвращается в исходное состояние:
Очень легко этом может возникнуть ситуация, когда есть достаточное количество свободных байт, но они не располагаются подряд. Пусть будет выделено 10 зон по 2 байта каждая:

Затем будут освобождены 2,4,6,8,10 зоны:
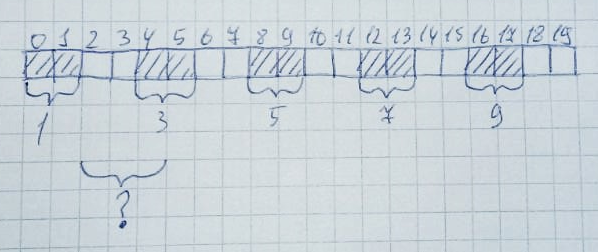
Формально остается свободной половина всей кучи (10 байт). Однако выделить область памяти размером 3 байта все равно не получится, так как в массиве нет 3-х свободных подряд ячеек. Это и называется фрагментацией памяти.
И бороться с этим на системах без виртуализации памяти достаточно сложно. Особенно в больших проектах.
Такую ситуацию можно легко сэмулировать. Я делал это в Keil mVision на микроконтроллере LPC11C24.
Зададим размер кучи в 256 байт:
Пусть у нас есть 2 класса:
#include <stdint.h>
class foo
{
private:
int32_t _pr1;
int32_t _pr2;
int32_t _pr3;
int32_t _pr4;
int32_t _pb1;
int32_t _pb2;
int32_t _pb3;
int32_t _pb4;
int32_t _pc1;
int32_t _pc2;
int32_t _pc3;
int32_t _pc4;
public:
foo()
{
_pr1 = 100;
_pr2 = 200;
_pr3 = 300;
_pr4 = 400;
_pb1 = 100;
_pb2 = 200;
_pb3 = 300;
_pb4 = 400;
_pc1 = 100;
_pc2 = 200;
_pc3 = 300;
_pc4 = 400;
}
~foo(){};
int32_t F1(int32_t a)
{
return _pr1*a;
};
int32_t F2(int32_t a)
{
return _pr1/a;
};
int32_t F3(int32_t a)
{
return _pr1+a;
};
int32_t F4(int32_t a)
{
return _pr1-a;
};
};
class bar
{
private:
int32_t _pr1;
int8_t _pr2;
public:
bar()
{
_pr1 = 100;
_pr2 = 10;
}
~bar() {};
int32_t F1(int32_t a)
{
return _pr2/a;
}
int16_t F2(int32_t a)
{
return _pr2*a;
}
};
Как видно, класс bar будет занимать больше памяти чем foo.
В кучу помещается 14 экземпляров класса bar и экземпляр класса foo уже не влезает:
int main(void)
{
foo *f;
bar *b[14];
b[0] = new bar();
b[1] = new bar();
b[2] = new bar();
b[3] = new bar();
b[4] = new bar();
b[5] = new bar();
b[6] = new bar();
b[7] = new bar();
b[8] = new bar();
b[9] = new bar();
b[10] = new bar();
b[11] = new bar();
b[12] = new bar();
b[13] = new bar();
f = new foo();
}
Если создать всего 7 экземпляров bar, то foo будет тоже нормально создан:
int main(void)
{
foo *f;
bar *b[14];
//b[0] = new bar();
b[1] = new bar();
//b[2] = new bar();
b[3] = new bar();
//b[4] = new bar();
b[5] = new bar();
//b[6] = new bar();
b[7] = new bar();
//b[8] = new bar();
b[9] = new bar();
//b[10] = new bar();
b[11] = new bar();
//b[12] = new bar();
b[13] = new bar();
f = new foo();
}
Однако если сначала создать 14 экземпляров bar, затем удалить 0,2,4,6,8,10 и 12 экземпляры, то для foo выделить память уже не получится из-за фрагментации кучи:
int main(void)
{
foo *f;
bar *b[14];
b[0] = new bar();
b[1] = new bar();
b[2] = new bar();
b[3] = new bar();
b[4] = new bar();
b[5] = new bar();
b[6] = new bar();
b[7] = new bar();
b[8] = new bar();
b[9] = new bar();
b[10] = new bar();
b[11] = new bar();
b[12] = new bar();
b[13] = new bar();
delete b[0];
delete b[2];
delete b[4];
delete b[6];
delete b[8];
delete b[10];
delete b[12];
f = new foo();
}
Получается, что полноценно С++ использовать нельзя, и это существенный минус. С архитектурной точки зрения С++ хотя и превосходит С, но незначительно. В итоге существенной выгоды переход на С++ не несет (хотя и больших отрицательных моментов тоже нет). Таким образом, из-за небольшой разницы, выбор языка будет оставаться просто личным предпочтением разработчика.
Но для себя я нашел один существенный положительный момент в использовании С++. Дело в том, что при правильном подходе C++ код для микроконтроллеров можно достаточно легко покрыть юнит-тестами в Visual Studio.
Большой плюс C++ — возможность использования Visual Studio.
Лично для меня тема тестирования кода для микроконтроллеров всегда была достаточно сложной. Естественно, код проверялся всевозможными способами, но создание полноценной автоматической системы тестирования всегда требовало огромных затрат, так как нужно было собирать аппаратный стенд и писать для него специальную прошивку. Особенно если речь идет о распределенной IoT системе, состоящей из сотен устройств.
Когда я начал писать проект на С++, мне сразу захотелось попробовать засунуть код в Visual Studio а Keil mVision использовать только для отладки. Во-первых, в Visual Studio очень мощный и удобный редактор кода, во-вторых, в Keil mVision совсем не удобная интеграция с системами контроля версий, а в Visual Studio это все отработано до автоматизма. В-третьих, у меня была надежда, что удастся хотя бы часть кода покрыть юнит-тестами, которые тоже хорошо поддерживаются в Visual Studio. Ну и в-четвертых, это появление Resharper C++ — расширения Visual Studio для работы с С++ кодом, благодаря которому можно заранее избежать многих потенциальных ошибок и следить за стилистикой кода.
Создание проекта в Visual Studio и подключение его к системе контроля версий не вызвало никаких проблем. А вот с юнит-тестами пришлось повозиться.
Классы, абстрагированные от аппаратной части (например, парсеры протокола), достаточно легко поддались тестированию. Но хотелось большего! В своих проектах для работы с периферией я использую заголовочные файлы от Keil. Например, для LPC11C24 это LPC11xx.h. В этих файлах описаны все необходимые регистры в соответствии со стандартом CMSIS. Непосредственно определение конкретного регистра сделано через #define:
#define LPC_I2C_BASE (LPC_APB0_BASE + 0x00000)
#define LPC_I2C ((LPC_I2C_TypeDef *) LPC_I2C_BASE )
Оказалось, что если правильно переопределить регистры и сделать пару заглушек, то код, использующий периферию, вполне может быть скомпилирован в VisualStudio. Мало того, если сделать статический класс и указывать его поля как адреса регистров, то получится полноценный эмулятор микроконтроллера, позволяющий полноценно тестировать даже работу с периферией:
#include <LPC11xx.h>
class LPC11C24Emulator
{
public:
static class Registers
{
public:
static LPC_ADC_TypeDef ADC;
public:
static void Init()
{
memset(&ADC, 0x00, sizeof(LPC_ADC_TypeDef));
}
};
}
#undef LPC_ADC
#define LPC_ADC ((LPC_ADC_TypeDef *) &LPC11C24Emulator::Registers::ADC)
И дальше делать так:
#if defined ( _M_IX86 )
#include "..\Emulator\LPC11C24Emulator.h"
#else
#include <LPC11xx.h>
#endif
Таким образом можно скомпилировать и оттестировать весь код проекта для микроконтроллеров в VisualStudio с минимальными изменениями.
В процессе разработки проекта на С++ я написал более 300 тестов, покрывающих как чисто аппаратные аспекты, так и абстрагированный от аппаратуры код. При этом заранее найдены примерно 20 достаточно серьезных ошибок, которые, из-за размеров проекта, было бы не просто обнаружить без автоматического тестирования.
Выводы
Использовать или не использовать С++ при работе с микроконтроллерами — достаточно сложный вопрос. Выше я показал, что, с одной стороны, архитектурные преимущества от полноценного ООП не так уж и велики, а невозможность полноценной работы с кучей является достаточно большой проблемой. Учитывая эти аспекты, большой разницы между С и С++ для работы с микроконтроллерами нет, выбор между ними вполне может быть обоснован личными предпочтениями разработчика.
Однако мне удалось найти большой положительный момент использования С++ в работе с Visaul Studio. Это позволяет существенно повысить надежность разработки за счет полноценной работы с системами контроля версий, использования полноценных юнит-тестов (в том числе и тестов работы с периферией) и других преимуществ Visual Studio.
Надеюсь, мой опыт будет полезен и кому-то поможет повысить эффективность своей работы.
Update:
В комментариях к английской версии данной статьи дали полезные ссылки на эту тему:
- Meeting C++ 2015 Lightning Talks: Odin Holmes — special function register abstraction www.youtube.com/watch?v=AKAYc9ZFBhk
- Meeting C++ 2015: John Hinke — Deeply embedded C++ www.youtube.com/watch?v=TYqbgvHfxjM
- Meeting C++ 2014: Wouter van Ooijen — Objects? No thanks. www.youtube.com/watch?v=k8sRQMx2qUw
