Предисловие
В этой статье речь пойдет о методах решения задач математической оптимизации, основанных на использовании градиента функции. Основная цель — собрать в статье все наиболее важные идеи, которые так или иначе связаны с этим методом и его всевозможными модификациями.
UPD. В комментариях пишут, что на некоторых браузерах и в мобильном приложении формулы не отображаются. К сожалению, не знаю, как с этим бороться. Могу лишь сказать, что использовал макросы «inline» и «display» хабравского редактора. Если вдруг знаете, как это исправить — напишите в комментариях, пожалуйста.
Примечание от автора
На момент написания я защитил диссертацию, задача которой требовала от меня глубокое понимание теоретических основно методов математической оптимизации. Тем не менее, у меня до сих пор (как и у всех) расплываются глаза от страшных длинных формул, поэтому я потратил немалое время, чтобы вычленить ключевые идеи, которые бы характеризовали разные вариации градиентных методов. Моя личная цель — написать статью, содержащую минимальное количество информации, необходимое для более менее подробного понимания тематики. Но будьте готовы, без формул так или иначе не обойтись.
Постановка задачи
Прежде чем описывать метод, следует сначала описать задачу, а именно: «Даны множество
 и функция
и функция  , требуется найти точку
, требуется найти точку  , такую что
, такую что  для всех
для всех  », что обычно записывается например вот так
», что обычно записывается например вот так
В теории обычно предполагается, что
 — дифференцируемая и выпуклая функция, а — выпуклое множество (а еще лучше, если вообще
— дифференцируемая и выпуклая функция, а — выпуклое множество (а еще лучше, если вообще  ), это позволяет дать какие-то гарантии успешности применения градиентного спуска. На практике градиентный спуск успешно применяется даже когда у задачи нет ни одного из вышеперечисленных свойств (пример дальше в статье).
), это позволяет дать какие-то гарантии успешности применения градиентного спуска. На практике градиентный спуск успешно применяется даже когда у задачи нет ни одного из вышеперечисленных свойств (пример дальше в статье).Немного математики
Допустим пока что нам нужно просто найти минимум одномерной функции

Еще в 17 веке Пьером Ферма был придуман критерий, который позволял решать простые задачи оптимизации, а именно, еcли
 — точка минимума
— точка минимума  , то
, то 
где
 — производная . Этот критерий основан на линейном приближении
— производная . Этот критерий основан на линейном приближении
Чем ближе
 к , чем точнее это приближение. В правой части — выражение, которое при
к , чем точнее это приближение. В правой части — выражение, которое при  может быть как больше
может быть как больше  так и меньше — это основная суть критерия. В многомерном случае аналогично из линейного приближения
так и меньше — это основная суть критерия. В многомерном случае аналогично из линейного приближения  (здесь и далее
(здесь и далее  — стандартное скалярное произведение, форма записи обусловлена тем, что скалярное произведение — это то же самое, что матричное произведение вектор-строки на вектор-столбец) получается критерий
— стандартное скалярное произведение, форма записи обусловлена тем, что скалярное произведение — это то же самое, что матричное произведение вектор-строки на вектор-столбец) получается критерий
Величина
 — градиент функции в точке . Также равенство градиента нулю означает равенство всех частных производных нулю, поэтому в многомерном случае можно получить этот критерий просто последовательно применив одномерный критерий по каждой переменной в отдельности.
— градиент функции в точке . Также равенство градиента нулю означает равенство всех частных производных нулю, поэтому в многомерном случае можно получить этот критерий просто последовательно применив одномерный критерий по каждой переменной в отдельности.Стоит отметить, что указанные условия являются необходимыми, но не достаточными, самый простой пример — 0 для
 и
и 
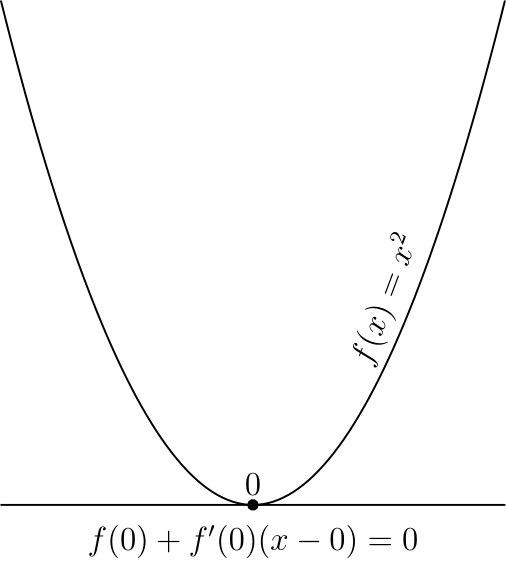
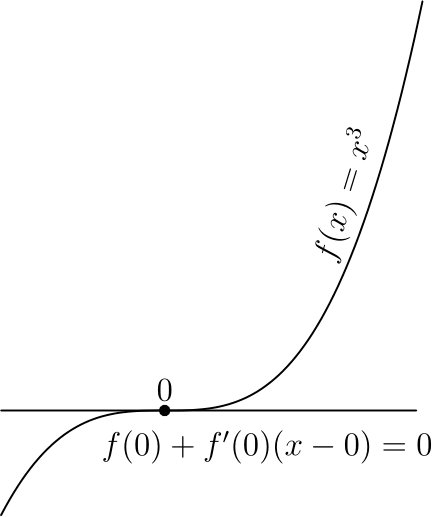
Этот критерий является достаточным в случае выпуклой функции, во многом из-за этого для выпуклых функций удалось получить так много результатов.
Квадратичные функции
Квадратичные функции в
 — это функция вида
— это функция вида
Для экономии места (да и чтобы меньше возиться с индексами) такую функцию обычно записывают в матричной форме:

где
 ,
,  ,
,  — матрица, у которой на пересечении
— матрица, у которой на пересечении  строки и
строки и  столбца стоит величина
столбца стоит величина ( при этом получается симметричной — это важно). Далее. при упомянании квадратичной функции я буду иметь указанную выше функцию.
( при этом получается симметричной — это важно). Далее. при упомянании квадратичной функции я буду иметь указанную выше функцию.Зачем я об этом рассказываю? Дело в том, что квадратичные функции важны в оптимизации по двум причинам:
- Они тоже встречаются на практике, например при построении линейной регрессии методом наименьших квадратов
- Градиент квадратичной функции — линейная функция, в частности для функции выше

Или в матричной форме

Таким образом система — линейная система. Системы, проще чем линейная, просто не существует. Мысль, к которой я старался подобраться — оптимизация квадратичной функции — самый простой класс задач оптимизации. С другой стороны, тот факт, что
— линейная система. Системы, проще чем линейная, просто не существует. Мысль, к которой я старался подобраться — оптимизация квадратичной функции — самый простой класс задач оптимизации. С другой стороны, тот факт, что  — необходимые условия минимума дает возможность решать линейные системы через задачи оптимизации. Чуть позже я постараюсь вас убедить в том, что это имеет смысл.
— необходимые условия минимума дает возможность решать линейные системы через задачи оптимизации. Чуть позже я постараюсь вас убедить в том, что это имеет смысл.
Полезные свойства градиента
Хорошо, мы вроде бы выяснили, что если функция дифференцируема (у нее существуют производные по всем переменным), то в точке минимума градиент должен быть равен нулю. А вот несет ли градиент какую-нибудь полезную информацию в случае, когда он отличен от нуля?
Попробуем пока решить более простую задачу: дана точка
, найти точку  такую, что
такую, что  . Давайте возьмем точку рядом с , опять же используя линейное приближение
. Давайте возьмем точку рядом с , опять же используя линейное приближение  . Если взять
. Если взять  ,
,  то мы получим
то мы получим
Аналогично, если
 , то
, то  будет больше
будет больше  (здесь и далее
(здесь и далее  ). Опять же, так как мы использовали приближение, то эти соображения будут верны только для малых
). Опять же, так как мы использовали приближение, то эти соображения будут верны только для малых  . Подытоживая вышесказанное, если
. Подытоживая вышесказанное, если  , то градиент указывает направление наибольшего локального увеличения функции.
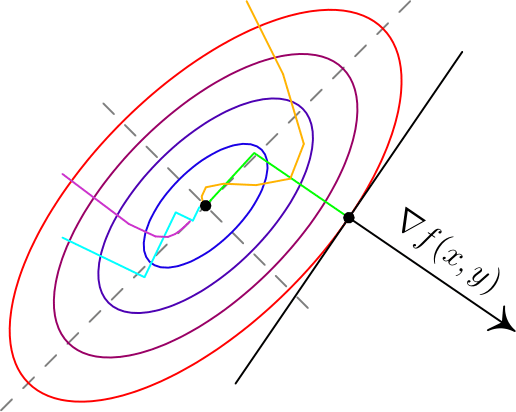
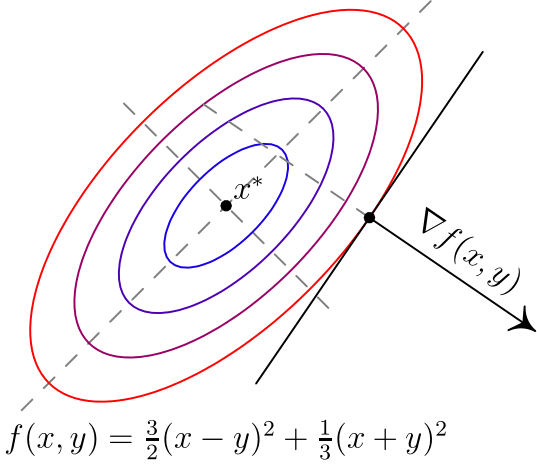
, то градиент указывает направление наибольшего локального увеличения функции. Вот два примера для двумерных функций. Такого рода картинки можно часто увидеть в демонстрациях градиентного спуска. Цветные линии — так называемые линии уровня, это множество точек, для которых функция принимает фиксированное значений, в моем случае это круги и эллипсы. Я обозначил синими линии уровня с более низким значением, красными — с более высоким.
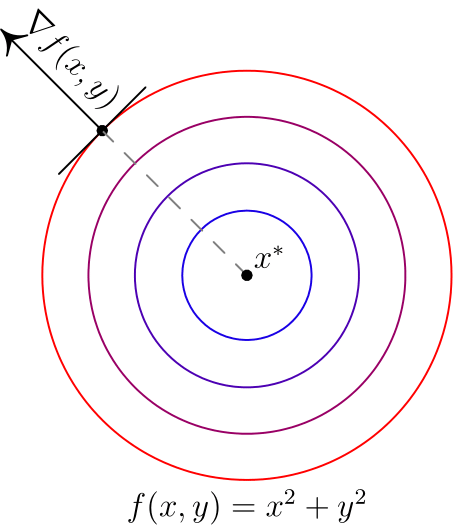
Обратите внимание, что для поверхности, заданной уравнением вида
 ,
,  задает нормаль (в простонародии — перпендикуляр) к этой поверхности. Также обратите внимание, что хоть градиент и показывает в направлении наибольшего увеличения функции, нет никакой гарантии, что по направлению, обратному к градиенту, можно найти минимум (пример — левая картинка).
задает нормаль (в простонародии — перпендикуляр) к этой поверхности. Также обратите внимание, что хоть градиент и показывает в направлении наибольшего увеличения функции, нет никакой гарантии, что по направлению, обратному к градиенту, можно найти минимум (пример — левая картинка).Градиентный спуск
До базового метода градиентного спуска остался лишь малый шажок: мы научились по точке
получать точку с меньшим значением функции . Что мешает нам повторить это несколько раз? По сути, это и есть градиентный спуск: строим последовательность
Величина
 называется размером шага (в машинном обучении — скорость обучения). Пару слов по поводу выбора : если — очень маленькие, то последовательность медленно меняется, что делает алгоритм не очень эффективным; если же очень большие, то линейное приближение становится плохим, а может даже и неверным. На практике размер шага часта подбирают эмпирически, в теории обычно предполагается липшицевость градиента, а именно, если
называется размером шага (в машинном обучении — скорость обучения). Пару слов по поводу выбора : если — очень маленькие, то последовательность медленно меняется, что делает алгоритм не очень эффективным; если же очень большие, то линейное приближение становится плохим, а может даже и неверным. На практике размер шага часта подбирают эмпирически, в теории обычно предполагается липшицевость градиента, а именно, если
для всех
 , то
, то  гарантирует убывание
гарантирует убывание  .
.Анализ для квадратичных функций
Если
— симметричная обратимая матрица,  , то для квадратичной функции
, то для квадратичной функции  точка является точкой минимума (UPD. при условии, что этот минимум вообще существует — не принимает сколько угодно близкие к
точка является точкой минимума (UPD. при условии, что этот минимум вообще существует — не принимает сколько угодно близкие к  значения только если положительно определена), а для метода градиентного спуска можно получить следующее
значения только если положительно определена), а для метода градиентного спуска можно получить следующее

где
 — единичная матрица, т.е.
— единичная матрица, т.е.  для всех . Если же
для всех . Если же  , то получится
, то получится
Выражение слева — расстояние от приближения, полученного на шаге
 градиентного спуска до точки минимума, справа — выражение вида
градиентного спуска до точки минимума, справа — выражение вида  , которое сходится к нулю, если
, которое сходится к нулю, если  (условие, которое я писал на в предыдущем пункте как раз это гарантирует). Эта базовая оценка гарантирует, что градиентный спуск сходится.
(условие, которое я писал на в предыдущем пункте как раз это гарантирует). Эта базовая оценка гарантирует, что градиентный спуск сходится.Модификации градиентного спуска
Теперь хотелось бы рассказать немного про часто используемые модификации градиентного спуска, в первую очередь так называемые
Инерционные или ускоренные градиентные методы
Все методы такого класса выражаются в следующем виде

Последнее слагаемое характеризует эту самую «инерционность», алгоритм на каждом шаге старается двигаться против градиента, но при этом по инерции частично двигается в том же направлении, что и на предыдущей итерации. Такие методы обладают двумя важными свойствами:
- Они практически не усложняют обычный градиентный спуск в вычислительном плане.
- При аккуратном подборе
 такие методы на порядок быстрее, чем обычный градиентный спуск даже с оптимально подобранным шагом.
такие методы на порядок быстрее, чем обычный градиентный спуск даже с оптимально подобранным шагом.
Один из первых таких методов появился в середине 20 века и назывался метод тяжелого шарика, что передавало природу инерционности метода: в этом методе
не зависят от и аккуратно подбираются в зависимости от целевой функции. Стоит отметить, что может быть какой угодно, а  — обычно лишь чуть-чуть меньше единицы.
— обычно лишь чуть-чуть меньше единицы.Метод тяжелого шарика — самый простой инерционный метод, но не самый первый. При этом, на мой взгляд, самый первый метод довольно важен для понимания сути этих методов.
Метод Чебышева
Да да, первый метод такого типа был придуман еще Чебышевым для решения систем линейных уравнений. В какой-то момент при анализе градиентного спуска было получено следующее равенство


где
 — некоторый многочлен степени . Почему бы не попробовать подобрать таким образом, чтобы
— некоторый многочлен степени . Почему бы не попробовать подобрать таким образом, чтобы  было поменьше? Один уз универсальных многочленов, которые меньше всего отклоняются от нуля — многочлен Чебышева. Метод Чебышева по сути заключается в том, чтобы подобрать параметры спуска так, чтобы был многочленом Чебышева. Есть правда одна небольшая проблема: для обычного градиентного спуска это просто невозможно. Однако для инерционных методов это оказывается возможным. В основном это происходит из-за того, что многочлены Чебышева удовлетворяют рекуррентному соотношению второго порядка
было поменьше? Один уз универсальных многочленов, которые меньше всего отклоняются от нуля — многочлен Чебышева. Метод Чебышева по сути заключается в том, чтобы подобрать параметры спуска так, чтобы был многочленом Чебышева. Есть правда одна небольшая проблема: для обычного градиентного спуска это просто невозможно. Однако для инерционных методов это оказывается возможным. В основном это происходит из-за того, что многочлены Чебышева удовлетворяют рекуррентному соотношению второго порядка
поэтому их невозможно построить для градиентного спуска, который вычисляет новое значение лишь по одному предыдущему, а для инерционных становится возможным за счет того, что используется два предыдущих значения. При этом оказывается, что сложность вычисления
не зависит ни от , ни от размера пространства  .
.Метод сопряженных градиентов
Еще один очень интересный и важный факт (следствие теоремы Гамильтона-Кэли): для любой квадратной матрицы
размера  существует многочлен
существует многочлен  степени не больше , для которого
степени не больше , для которого  . Чем это интересно? Все дело в том же равенстве
. Чем это интересно? Все дело в том же равенстве
Если бы мы могли подбирать размер шага в градиентном спуске так, чтобы получать именно этот обнуляющий многочлен, то градиентный спуск сходился бы за фиксированное число итерации не большее размерности
. Как уже выяснили — для градиентного спуска мы так делать не можем. К счастью, для инерционных методов — можем. Описание и обоснование метода довольно техническое, я ограничусь сутью:на каждой итерации выбираются параметры, дающие наилучший многочлен, который можно построить учитывая все сделанные до текущего шага измерения градиента. При этом- Одна итерация градиентного спуска (без учета вычислений параметров) содежит одно умножение матрицы на вектор и 2-3 сложения векторов
- Вычисление параметров также требует 1-2 умножение матрицы на вектор, 2-3 скалярных умножения вектор на вектор и несколько сложений векторов.
Самое сложное в вычислительном плане — умножение Матрицы на вектор, обычно это делается за время
 , однако для со специальной реализацией это можно сделать за
, однако для со специальной реализацией это можно сделать за  , где
, где  — количество ненулевых элементов в . Учитывая сходимость метода сопряженных градиентов не более, чем за итерации получаем общую сложность алгоритма
— количество ненулевых элементов в . Учитывая сходимость метода сопряженных градиентов не более, чем за итерации получаем общую сложность алгоритма  , что во всех случаях не хуже
, что во всех случаях не хуже  для метода Гаусса или Холесского, но намного лучше в случае, если
для метода Гаусса или Холесского, но намного лучше в случае, если  , что не так редко встречается.
, что не так редко встречается.Метод сопряженных градиентов хорошо работает и в случае, если
не является квадратичной функцией, но при этом уже не сходится за конечное число шагов и часто требует небольших дополнительных модификацийМетод Нестерова
Для сообществ математической оптимизации и машинного обучения фамилия «Нестеров» уже давно стало нарицательной. В 80х годах прошлого века Ю.Е. Нестеров придумал интересный вариант инерционного метода, который имеет вид

при этом не предполагается какого-то сложного подсчета
как в методе сопряженных градиентов, в целом поведение метода похоже на метод тяжелого шарика, но при этом его сходимость обычно гораздо надежнее как в теории, так и на практике.Стохастический градиентный спуск
Единственное формальное отличие от обычного градиентного спуска — использование вместо градиента функции
 такой, что
такой, что  (
( — математическое ожидание по случайной величине
— математическое ожидание по случайной величине  ), таким образом стохастический градиентный спуск имеет вид
), таким образом стохастический градиентный спуск имеет вид
 — это некоторый случайный параметр, на который мы не влияем, но при этом в среднем мы идем против градиента. В качестве примера рассмотрим функции
— это некоторый случайный параметр, на который мы не влияем, но при этом в среднем мы идем против градиента. В качестве примера рассмотрим функции 
и

Если
принимает значения  равновероятно, то как раз в среднем
равновероятно, то как раз в среднем  — это градиент . Этот пример показателен еще и следующим: сложность вычисления градиента в раз больше, чем сложность вычисления . Это позволяет стохастическому градиентному спуску делать за одно и то же время в раз больше итераций. Несмотря на то, что стохастический градиентный спуск обычно сходится медленней обычного, за счет такого большого увеличения числа итераций получается улучшить скорость сходимости на единицу времени. Насколько мне известно — на данный момент стохастический градиентный спуск является базовым методом обучения большинства нейронных сетей, реализован во всех основных библиотеках по ML: tensorflow, torch, caffe, CNTK, и т.д.
— это градиент . Этот пример показателен еще и следующим: сложность вычисления градиента в раз больше, чем сложность вычисления . Это позволяет стохастическому градиентному спуску делать за одно и то же время в раз больше итераций. Несмотря на то, что стохастический градиентный спуск обычно сходится медленней обычного, за счет такого большого увеличения числа итераций получается улучшить скорость сходимости на единицу времени. Насколько мне известно — на данный момент стохастический градиентный спуск является базовым методом обучения большинства нейронных сетей, реализован во всех основных библиотеках по ML: tensorflow, torch, caffe, CNTK, и т.д.Стоит отметить, что идеи иннерционных методов применяются для стохастического градиентного спуска и на практике часто дают прирост, в теории же обычно считается, что асимптотическая скорость сходимости не меняется из-за того, что основная погрешность в стохастическом градиентном спуске обусловлена дисперсией
.Субградиентный спуск
Эта вариация позволяет работать с недифференцируемыми функциями, её я опишу более подробно. Придется опять вспомнить линейное приближение — дело в том, что есть простая характеристика выпуклости через градиент, дифференцируемая функция
выпукла тогда и только тогда, когда выполняется  для всех . Оказывается, что выпуклая функция не обязаны быть дифференцируемой, но для любой точки обязательно найдется такой вектор , что
для всех . Оказывается, что выпуклая функция не обязаны быть дифференцируемой, но для любой точки обязательно найдется такой вектор , что  для всех
для всех  . Такой вектор принято называть субградиентом в точке , множество всех субградиентов в точки называют субдифференциалом и обозначают
. Такой вектор принято называть субградиентом в точке , множество всех субградиентов в точки называют субдифференциалом и обозначают  (несмотря на обозначение — не имеет ничего общего с частными производными). В одномерном случае — это число, а вышеуказанное свойство просто означает, что график лежит выше прямой, проходящей через
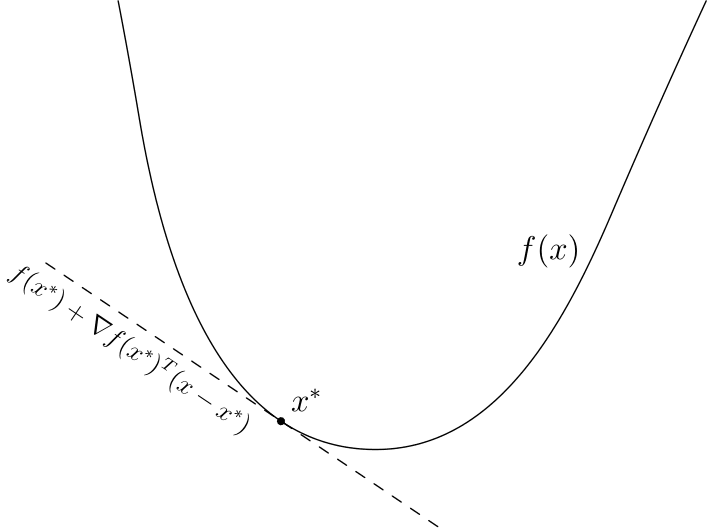
(несмотря на обозначение — не имеет ничего общего с частными производными). В одномерном случае — это число, а вышеуказанное свойство просто означает, что график лежит выше прямой, проходящей через  и имеющей тангенс угла наклона (смотрите рисунки ниже). Отмечу, что субградиентов для одной точки может быть несколько, даже бесконечное число.
и имеющей тангенс угла наклона (смотрите рисунки ниже). Отмечу, что субградиентов для одной точки может быть несколько, даже бесконечное число.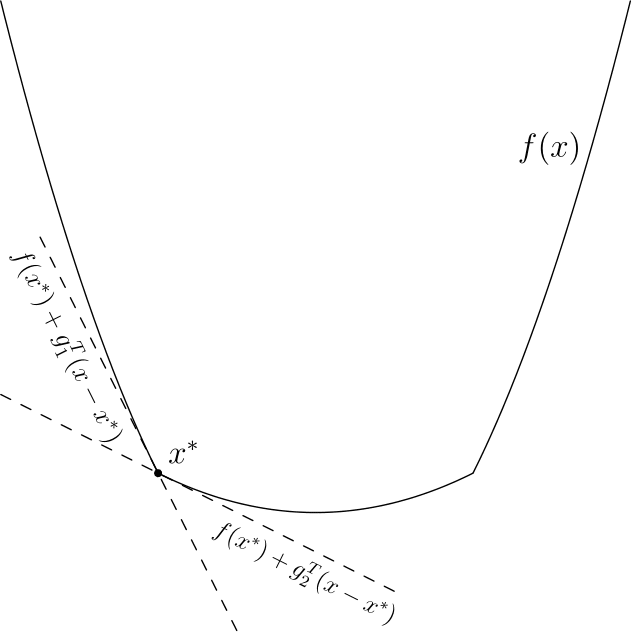
Вычислить хотя бы один субградиент для точки обычно не очень сложно, субградиентный спуск по сути использует субградиент вместо градиента. Оказывается — этого достаточно, в теории скорость сходимости при этом падает, однако например в нейронных сетях недифференцируемую функцию
 любят использовать как раз из-за того, что с ней обучение проходит быстрее (это кстати пример невыпуклой недифференцируемой функции, в которой успешно применяется (суб)градиентный спуск. Сама по себе функция
любят использовать как раз из-за того, что с ней обучение проходит быстрее (это кстати пример невыпуклой недифференцируемой функции, в которой успешно применяется (суб)градиентный спуск. Сама по себе функция  выпукла, но многослойная нейронная сеть, содержащая , невыпукла и недифференцируема). В качестве примера, для функции
выпукла, но многослойная нейронная сеть, содержащая , невыпукла и недифференцируема). В качестве примера, для функции  субдифференциал вычисляется очень просто
субдифференциал вычисляется очень просто![$ \partial f(x)=\begin{cases} 1, & x>0, \\ -1, & x < 0, \\ [-1, 1], & x=0. \end{cases} $](https://habrastorage.org/getpro/habr/formulas/4cc/1c9/e37/4cc1c9e37ffc84dfa619fb2fe951fa59.svg)
Пожалуй, последняя важная вещь, которую стоит знать, — это то, что субградиентный спуск не сходится при постоянном размере шага. Это проще всего увидеть для указанной выше функции
. Даже отсутствие производной в одной точке ломает сходимость:- Допустим мы начали из точки
 .
. - Шаг субградиентного спуска:

- Если
 , то первые несколько шагов мы будет вычитать единицу, если
, то первые несколько шагов мы будет вычитать единицу, если  , то прибавлять. Так или иначе мы в какой-то момент окажемся на интервале
, то прибавлять. Так или иначе мы в какой-то момент окажемся на интервале  , из которого попадем в
, из которого попадем в  , а дальше будем прыгать между двумя точками этих интервалов.
, а дальше будем прыгать между двумя точками этих интервалов.
В теории для субградиентного спуска рекомендуется брать последовательность шагов

Где
 обычно
обычно  или
или  . На практике я часто видел успешное применение шагов
. На практике я часто видел успешное применение шагов  , хоть и для таких шагов вообще говоря не будет сходимости.
, хоть и для таких шагов вообще говоря не будет сходимости.Proximal методы
К сожалению я не знаю хорошего перевода для «proximal» в контексте оптимизации, поэтому просто так и буду называть этот метод. Proximal-методы появились как обобщение проективных градиентных методов. Идея очень простая: если есть функция
, представимая в виде суммы  , где
, где  — дифференцируемая выпуклая функция, а
— дифференцируемая выпуклая функция, а  — выпуклая, для которой существует специальный proximal-оператор
— выпуклая, для которой существует специальный proximal-оператор  (в этой статье ограничусь лишь примерами, описывать в общем виде не буду), то свойства сходимости градиентного спуска для остаются и для градиентного спуска для , если после каждой итерации применять этот proximal-оператор для текущей точки
(в этой статье ограничусь лишь примерами, описывать в общем виде не буду), то свойства сходимости градиентного спуска для остаются и для градиентного спуска для , если после каждой итерации применять этот proximal-оператор для текущей точки  , другими словами общий вид proximal-метода выглядит так:
, другими словами общий вид proximal-метода выглядит так:
Думаю, пока что совершенно непонятно, зачем это может понадобиться, особенно учитывая то, что я не объяснил, что такое proximal-оператор. Вот два примера:
- — индикатор-функция выпуклого множества , то есть

В этом случае — это проекция на множество , то есть «ближайшая к точка множества ». Таким образом, мы ограничиваем градиентный спуск только на множество , что позволяет решать задачи с ограничениями. К сожалению, вычисление проекции в общем случае может быть еще более сложной задачей, поэтому обычно такой метод применяется, если ограничения имеют простой вид, например так называемые box-ограничения: по каждой координате
— это проекция на множество , то есть «ближайшая к точка множества ». Таким образом, мы ограничиваем градиентный спуск только на множество , что позволяет решать задачи с ограничениями. К сожалению, вычисление проекции в общем случае может быть еще более сложной задачей, поэтому обычно такой метод применяется, если ограничения имеют простой вид, например так называемые box-ограничения: по каждой координате

 —
—  -регуляризация. Такое слагаемое любят добавлять в задачи оптимизации в машинном обучении, чтобы избежать переобучения. Регуляризация такого вида еще и имеет тенденцию обнулять наименее значимые компоненты. Для такой функции proximal-оператор имеет вид (ниже описано выражение для одной координаты):
-регуляризация. Такое слагаемое любят добавлять в задачи оптимизации в машинном обучении, чтобы избежать переобучения. Регуляризация такого вида еще и имеет тенденцию обнулять наименее значимые компоненты. Для такой функции proximal-оператор имеет вид (ниже описано выражение для одной координаты):
![$ [prox_{\alpha h}(x)]_i=\begin{cases} x_i-\alpha, & x_i>\alpha,\\ x_i+\alpha, & x_i <-\alpha,\\ 0, & x_i\in [-\alpha, \alpha], \end{cases} $](https://habrastorage.org/getpro/habr/formulas/579/53b/d5d/57953bd5d25e8eb69cade145fc22900a.svg)
что довольно просто вычислить.
Заключение
На этом заканчиваются основные известные мне вариации градиентного метода. Пожалуй под конец я бы отметил, что все указанные модификации (кроме разве что метода сопряженных градиентов) могут легко взаимодействовать друг с другом. Я специально не стал включать в эту перечень метод Ньютона и квазиньютоновские методы (BFGS и прочие): они хоть и используют градиент, но при этом являются более сложными методами, требуют специфических дополнительных вычислений, которые обычно более вычислительно затратны, нежели вычисление градиента. Тем не менее, если этот текст будет востребован, я с удовольствием сделаю подобный обзор и по ним.
Использованная / рекомендованная литература
Boyd. S, Vandenberghe L. Convex Optimization
Shewchuk J. R. An Introduction to the Conjugate Gradient Method Without the Agonizing Pain
Bertsekas D. P. Convex Optimization Theory
Нестеров Ю. Е. Методы выпуклой оптимизации
Гасников А. В. Универсальный градиентный спуск
