В предыдущей статье мы обсудили кодек Opus, который работает на очень низких битрейтах. Но другой кодек стремится достичь ещё более низких битрейтов — это Codec 2.
Codec 2 предназначен для кодирования только речи. И хотя битрейт впечатляет, звук не такой качественный, как в случае Opus, что можно услышать в аудиопримерах. Тем не менее, в сочетании с нейросетью (WaveNet) кодек демонстрирует впечатляющие результаты.
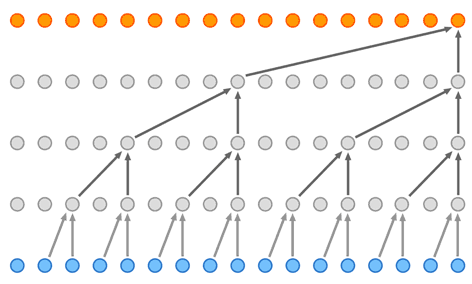
Слои нейронной сети WaveNet
Codec 2 распространяется с открытым исходным кодом и предназначен для кодирования речи. Он ориентируется на битрейт от 700 до 3200 бит/с.
Разработчик — Дэвид Роу, инженер-электроник, в настоящее время живущий в Южной Австралии. Он начал проект в сентябре 2009 года с целью совершенствования недорогой радиосвязи для людей в отдалённых районах мира. С этой целью он собирался разработать кодек, который значительно уменьшит размер файлов и требования к пропускной способности канала при потоковой передаче.
Другой мотивацией, по словам Дэвида, было создание свободного от патентного обременения кодека как альтернативы проприетарным кодекам, которые, по его мнению, «требуют оформления дорогостоящих и неуклюжих лицензий и душат инновации». Он считает, что можно обойтись без запатентованных кодеков, поэтому всю работу распространяет под свободной лицензией.
Автор называет различные применения кодека, среди них VoIP, голосовая связь по узкой полосе цифрового ВЧ/УВЧ радио (особенно для любительского радио, во избежание проблем с использованием проприетарных кодеков), связь в развивающихся странах и удалённых регионах, включая армию, полицию и спасательные службы.
Мы в компании Auphonic заинтересованы в потенциальном применении кодека для лучшего сжатия подкастов, презентаций и аудиокниг, что позволяет уменьшить объём занимаемого места и свести к минимуму эффект плохих сетевых соединений.
Для снижения битрейта необходимо свести речь к минимально возможной информации/данным, то есть минимизировать объём избыточно передаваемой информации.
Для этого Codec 2 использует гармоническое синусоидальное кодирование речи. Он разделяет речь на сегменты по 10−30 мс, которые называются кадрами. Каждый кадр затем анализируется на предмет фундаментального уровня (pitch) и количества гармоник, которые вписываются в полосу пропускания 4 кГц. Далее для каждой гармоники в диапазоне 4 кГц записываются амплитуда и фаза.
Эта информация затем кодируется, а декодер восстанавливает звук на основе этих данных.
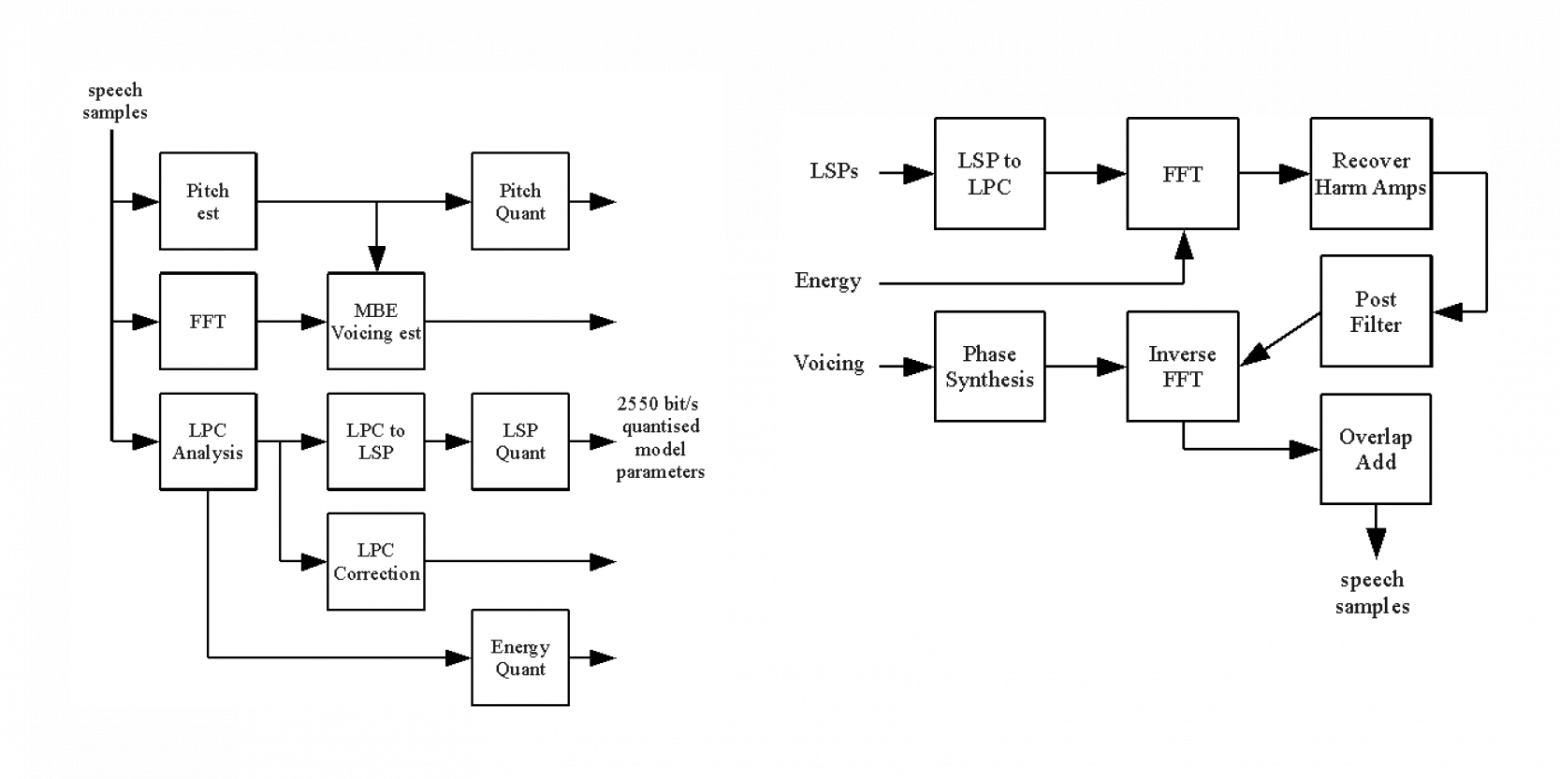
Блок-схемы Codec 2: энкодер (слева) и декодер (справа). Иллюстрация от Rowtel
Хотя всё это звучит здорово в теории, но что в реальности? Давайте послушаем. Вот короткий звуковой файл wav:
intro-orig.wav — 1,3 МБ
Применим Codec 2 (без декодера WaveNet) на разных доступных битрейтах: 3200 бит/с, 2400 бит/с, 1600 бит/с, 1200 бит/с и 700 бит/с.
Эти примеры показывают значительное уменьшение размера файлов.
Посмотрим на файлы с точки зрения их объёма для хранения 1 часа звука:
Сжатие очень сильное, но результат явно звучит неестественно.
Для сравнения, тот же звук в MP3 на 8 Кбит/с.
Размер файла значительно больше, чем у Codec 2, и качество, вероятно, всё ещё неприемлемо. Можно хорошо слышать то, что иногда называют шипением (sizzle) — странные металлические звуки, присущие MP3 низкого качества.
Есть последний кодек, с которым можно провести сравнение. Кажется, он объединяет оба мира, то есть обеспечивает приемлемое качество на низком битрейте: Opus.
Благодаря его убедительной производительности на низких битрейтах компания Auphonic уже предлагает пользователям кодирование Opus вплоть до 6 Кбит/с, самого низкого битрейта, который поддерживает кодек.
На скорости 6 Кбит/с кодек Opus кажется значительно лучше, чем MP3 8 Кбит/с. Голос немного приглушенный, но всё ещё звучит естественно.
Возвращаясь к Codec 2 чисто ради интереса послушаем, как у него получается кодирование музыки! (Имейте в виду, что Codec 2 не предназначен для кодирования музыки, а только для речи).
Исходный файл
MP3 8 Кбит/с
Лично я не могу слушать MP3 на таком битрейте, поэтому давайте посмотрим на результаты Codec 2! Итак, 3200 бит/с, 2400 бит/с, 1600 бит/с, 1200 бит/с, 700 бит/с.
Несложно понять, что для этой цели он вообще не подходит!
Как мы уже слышали, несмотря на впечатляющее сжатие, в результате получается не очень естественное звучание.
Но тут дело становится интереснее, если посмотреть на работу Бастиана Кляйна из Библиотеки Корнельского университета. Он использовал Codec 2 на битрейте 2400 бит/с для кодирования, но заменил декодер Codec 2 на генеративную модель глубокого обучения WaveNet (для дополнительной информации см. статью «Кодирование речи с низким битрейтом на основе Wavenet»).
Вот несколько примеров от авторов:
Мужской голос
Исходный файл
Codec 2
С декодером WaveNet
Женский голос
Исходный файл
Codec 2
С декодером WaveNet
По сравнению с Codec 2 мы слышим значительное улучшение качества, а если сравнить с оригиналом, то существенного снижения качества нет.
Сам Дэвид Роу заявил, что считает результат «кардинальным улучшением в кодировании речи при низкой скорости передачи» и «хорошим широкополосным речевым кодеком 8000 бит/с».
Хотя (оригинальный) кодек Codec 2 представляет собой очень интересную работу, его сфера использования ограничена, а конечный результат не подходит для подкастинга. Также по аудиопримерам понятно, что его можно использовать для сжатия только голоса, но не музыки.
Тем не менее, Codec 2 в сочетании с декодером WaveNet значительно улучшает качество, а низкий битрейт (2400 бит/с) будет чрезвычайно интересен для распространения подкастов и аудиокниг: на один час звука требуется всего 1,03 МБ места!
Auphonic добавит поддержку Codec 2 в файлы выдачи, когда декодер WaveNet появится в удобной для использования форме. Пока мы добавили поддержку Codec 2 только для входных файлов.
Codec 2 предназначен для кодирования только речи. И хотя битрейт впечатляет, звук не такой качественный, как в случае Opus, что можно услышать в аудиопримерах. Тем не менее, в сочетании с нейросетью (WaveNet) кодек демонстрирует впечатляющие результаты.
Слои нейронной сети WaveNet
Введение
Codec 2 распространяется с открытым исходным кодом и предназначен для кодирования речи. Он ориентируется на битрейт от 700 до 3200 бит/с.
Разработчик — Дэвид Роу, инженер-электроник, в настоящее время живущий в Южной Австралии. Он начал проект в сентябре 2009 года с целью совершенствования недорогой радиосвязи для людей в отдалённых районах мира. С этой целью он собирался разработать кодек, который значительно уменьшит размер файлов и требования к пропускной способности канала при потоковой передаче.
Другой мотивацией, по словам Дэвида, было создание свободного от патентного обременения кодека как альтернативы проприетарным кодекам, которые, по его мнению, «требуют оформления дорогостоящих и неуклюжих лицензий и душат инновации». Он считает, что можно обойтись без запатентованных кодеков, поэтому всю работу распространяет под свободной лицензией.
Потенциальное применение
Автор называет различные применения кодека, среди них VoIP, голосовая связь по узкой полосе цифрового ВЧ/УВЧ радио (особенно для любительского радио, во избежание проблем с использованием проприетарных кодеков), связь в развивающихся странах и удалённых регионах, включая армию, полицию и спасательные службы.
Мы в компании Auphonic заинтересованы в потенциальном применении кодека для лучшего сжатия подкастов, презентаций и аудиокниг, что позволяет уменьшить объём занимаемого места и свести к минимуму эффект плохих сетевых соединений.
Как это работает
Для снижения битрейта необходимо свести речь к минимально возможной информации/данным, то есть минимизировать объём избыточно передаваемой информации.
Для этого Codec 2 использует гармоническое синусоидальное кодирование речи. Он разделяет речь на сегменты по 10−30 мс, которые называются кадрами. Каждый кадр затем анализируется на предмет фундаментального уровня (pitch) и количества гармоник, которые вписываются в полосу пропускания 4 кГц. Далее для каждой гармоники в диапазоне 4 кГц записываются амплитуда и фаза.
Эта информация затем кодируется, а декодер восстанавливает звук на основе этих данных.
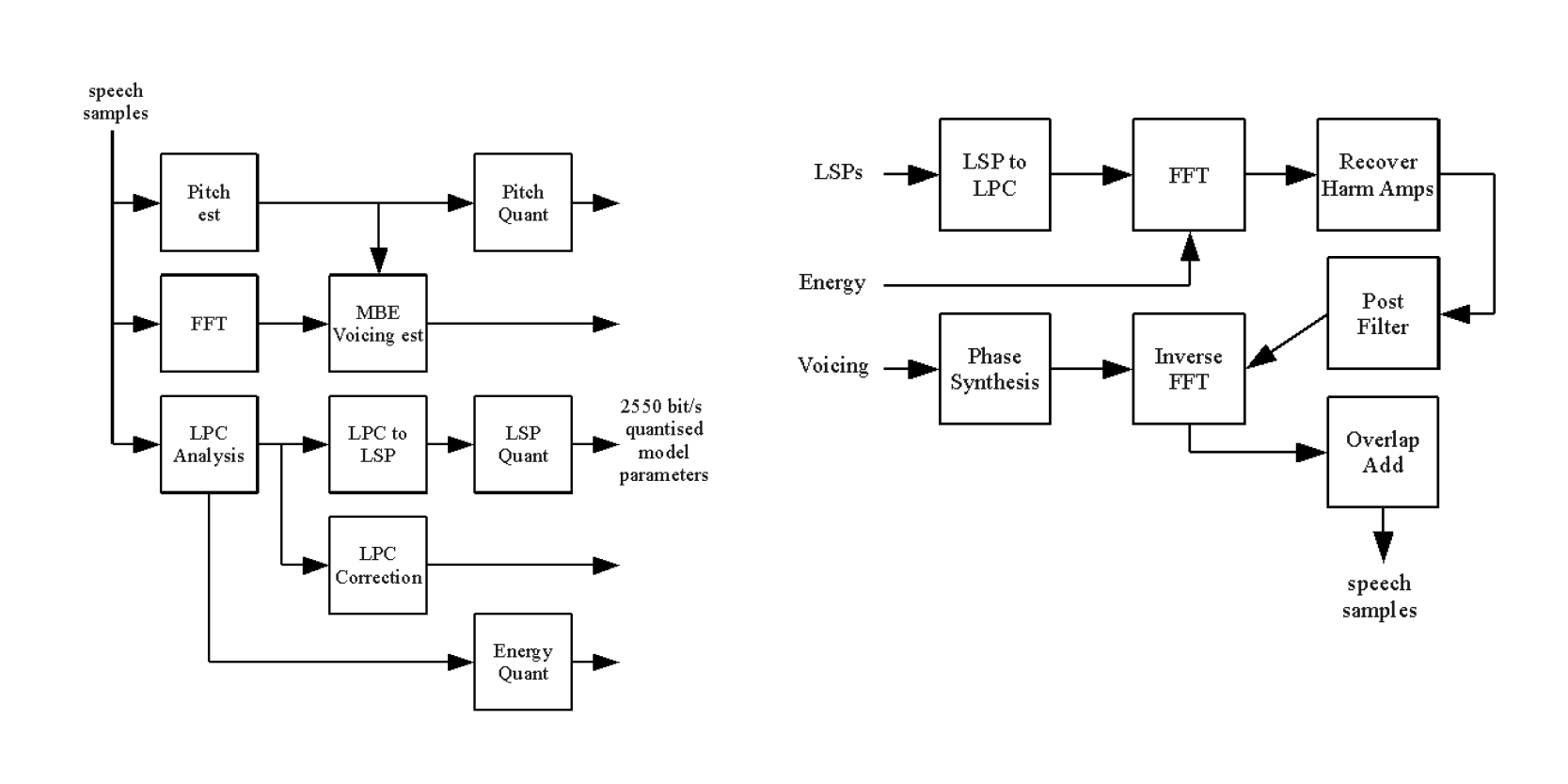
Блок-схемы Codec 2: энкодер (слева) и декодер (справа). Иллюстрация от Rowtel
Аудио примеры и сравнение с другими кодеками
Хотя всё это звучит здорово в теории, но что в реальности? Давайте послушаем. Вот короткий звуковой файл wav:
intro-orig.wav — 1,3 МБ
Применим Codec 2 (без декодера WaveNet) на разных доступных битрейтах: 3200 бит/с, 2400 бит/с, 1600 бит/с, 1200 бит/с и 700 бит/с.
Эти примеры показывают значительное уменьшение размера файлов.
Посмотрим на файлы с точки зрения их объёма для хранения 1 часа звука:
- На 3200 бит/с, один час звука требует всего 1,37 МБ (поместится на одной старой 3½-дюймовой дискете!)
- Битрейт 2400 бит/с соответствует 1,03 МБ/ч
- Битрейт 1600 бит/с равняется 0,68 МБ/ч (или примерно два часа звука на одной дискете!)
- 1200 бит/с — до 0,51 МБ/ч
- 700 бит/с — до 0,3 МБ/ч
Сжатие очень сильное, но результат явно звучит неестественно.
Для сравнения, тот же звук в MP3 на 8 Кбит/с.
Размер файла значительно больше, чем у Codec 2, и качество, вероятно, всё ещё неприемлемо. Можно хорошо слышать то, что иногда называют шипением (sizzle) — странные металлические звуки, присущие MP3 низкого качества.
Есть последний кодек, с которым можно провести сравнение. Кажется, он объединяет оба мира, то есть обеспечивает приемлемое качество на низком битрейте: Opus.
Благодаря его убедительной производительности на низких битрейтах компания Auphonic уже предлагает пользователям кодирование Opus вплоть до 6 Кбит/с, самого низкого битрейта, который поддерживает кодек.
На скорости 6 Кбит/с кодек Opus кажется значительно лучше, чем MP3 8 Кбит/с. Голос немного приглушенный, но всё ещё звучит естественно.
Возвращаясь к Codec 2 чисто ради интереса послушаем, как у него получается кодирование музыки! (Имейте в виду, что Codec 2 не предназначен для кодирования музыки, а только для речи).
Исходный файл
MP3 8 Кбит/с
Лично я не могу слушать MP3 на таком битрейте, поэтому давайте посмотрим на результаты Codec 2! Итак, 3200 бит/с, 2400 бит/с, 1600 бит/с, 1200 бит/с, 700 бит/с.
Несложно понять, что для этой цели он вообще не подходит!
Codec 2 и WaveNet
Как мы уже слышали, несмотря на впечатляющее сжатие, в результате получается не очень естественное звучание.
Но тут дело становится интереснее, если посмотреть на работу Бастиана Кляйна из Библиотеки Корнельского университета. Он использовал Codec 2 на битрейте 2400 бит/с для кодирования, но заменил декодер Codec 2 на генеративную модель глубокого обучения WaveNet (для дополнительной информации см. статью «Кодирование речи с низким битрейтом на основе Wavenet»).
Вот несколько примеров от авторов:
Мужской голос
Исходный файл
Codec 2
С декодером WaveNet
Женский голос
Исходный файл
Codec 2
С декодером WaveNet
По сравнению с Codec 2 мы слышим значительное улучшение качества, а если сравнить с оригиналом, то существенного снижения качества нет.
Сам Дэвид Роу заявил, что считает результат «кардинальным улучшением в кодировании речи при низкой скорости передачи» и «хорошим широкополосным речевым кодеком 8000 бит/с».
Вывод
Хотя (оригинальный) кодек Codec 2 представляет собой очень интересную работу, его сфера использования ограничена, а конечный результат не подходит для подкастинга. Также по аудиопримерам понятно, что его можно использовать для сжатия только голоса, но не музыки.
Тем не менее, Codec 2 в сочетании с декодером WaveNet значительно улучшает качество, а низкий битрейт (2400 бит/с) будет чрезвычайно интересен для распространения подкастов и аудиокниг: на один час звука требуется всего 1,03 МБ места!
Auphonic добавит поддержку Codec 2 в файлы выдачи, когда декодер WaveNet появится в удобной для использования форме. Пока мы добавили поддержку Codec 2 только для входных файлов.
