
К сожалению в интернете довольно мало информации по миграции реальных приложений и продакшн эксплуатации Percona XtraDB Cluster (далее PXC). Своим рассказом я постараюсь исправить эту ситуацию и рассказать о нашем опыте. Тут не будет пошаговой инструкции по установке и статью следует рассматривать не как замену офф документации, а как сборник рекомендаций.
Проблема
Я работаю системным администратором в ultimate-guitar.com. Так как мы предоставляем веб сервис у нас естественно есть бэкенды и БД, которая является ядром сервиса. Аптайм сервиса напрямую зависит от работоспособности БД.
В качестве БД использовался Percona MySQL 5.7. Резервирование было реализовано с помощью мастер-мастер схемы репликации. Слейвы использовались для чтения некоторых данных.
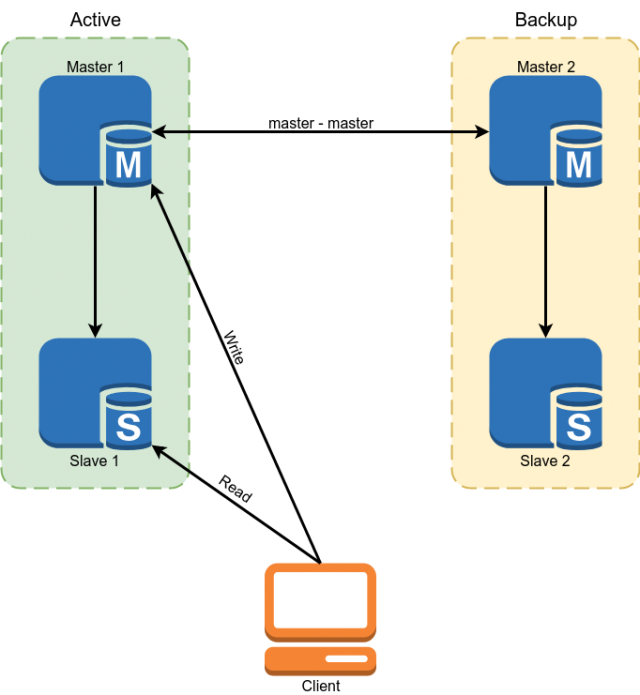
Но данная схема не устраивала нас следующими минусами:
- Из-за того, что в MySQL репликация асинхронная слейвы могли отставать на неопределенное время. Все критичные данные приходилось читать с мастера.
- Из предыдущего пункта вытекает сложность разработки. Разработчик не мог просто сделать запрос к БД, а был обязан продумать готов ли он в каждом конкретном случае к отставанию слейва и если нет, то читать данные с мастера.
- Ручное переключение в случае аварии. Автоматическое переключение реализовать было проблематично из-за того, что в архитектуре MySQL нет встроенной защиты от split brain. Пришлось бы самим писать арбитра со сложной логикой выбора мастера. При записи в оба мастера одновременно могли возникнуть конфликты, ломающие мастер-мастер репликацию и приводящие к классическому split brain.
Немного сухих цифр, чтобы вы понимали с чем мы работали:
Размер БД: 300 Гб
QPS: ~10к
RW ratio: 96/4%
Конфигурация мастер серверов:
CPU: 2x E5-2620 v3
RAM: 128 Gb
SSD: Intel Optane 905p 960 Gb
Сеть: 1 Гбит/с
У нас классическая OLTP нагрузка с большим количеством чтения, которое необходимо выполнять очень быстро и небольшим количеством записи. Нагрузка на БД достаточно маленькая из-за того, что активно применяется кэширование в Redis и Memcached.
Выбор решения
Как вы уже наверное догадались из заголовка мы выбрали PXC, но тут я объясню почему мы выбрали именно его.
У нас было 4 варианта:
- Смена СУБД
- MySQL Group Replication
- Накручивать необходимый функционал самим с помощью скриптов поверх мастер-мастер репликации.
- MySQL Galera cluster (или его форки, например PXC)
Вариант со сменой БД практически не рассматривался, т.к. приложение большое, во многих местах завязано на функционал или синтаксис mysql и миграция например на PostgreSQL займет кучу времени и ресурсов.
Вторым вариантом был MySQL Group Replication. Несомненным его плюсом является то, что он развивается в ванильной ветке MySQL, а значит в перспективе он получит широкое распространение и будет иметь большой пул активных пользователей.
Но у него есть несколько минусов. Во-первых он накладывает больше ограничений на приложение и схему БД, а значит произвести миграцию будет сложнее. Во вторых Group Replication решает проблему отказоустойчивости и split brain, но репликация в кластере по-прежнему асинхронная.
Третий вариант нам тоже не слишком нравился за слишком большое количество велосипедов, которые нам неизбежно придется реализовывать при решении задачи данным способом.
Galera позволяла полностью решить проблему с отказоустойчивостью MySQL и частично решить проблему с актуальностью данных на слейвах. Частично, потому что асинхронность репликации сохраняется. После коммита транзакции на локальной ноде изменения разливаются на остальные ноды асинхронно, но кластер следит что бы ноды не сильно отставали и если они начинают отставать, то он искусственно замедляет работу. Кластер гарантирует, что после коммита транзакции никто не сможет закоммитить конфликтующие изменения даже на ноде, которая еще не реплицировала изменения.
После миграция схема работы нашей БД должна выглядеть так:
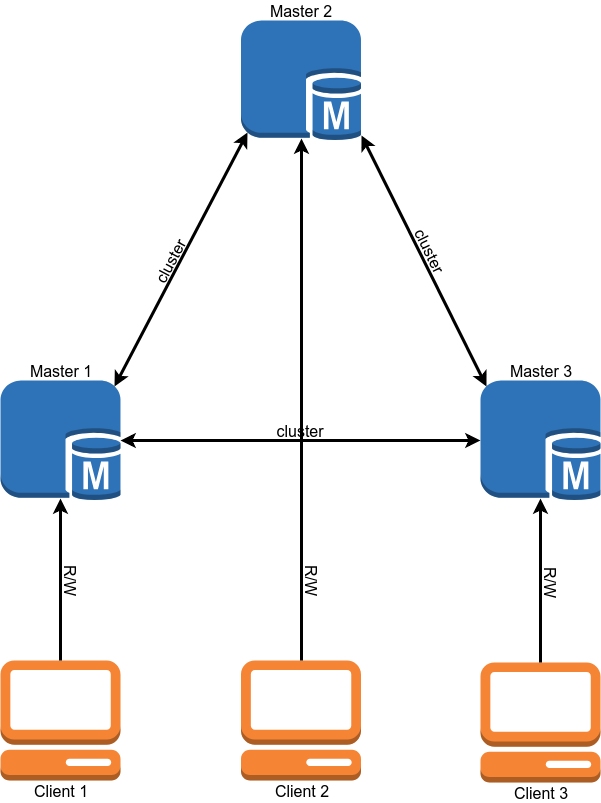
Миграция
Почему миграция стоит вторым пунктом после выбора решения? Все просто — кластер содержит некоторое количество требований, которым должно следовать приложение и БД и выполнить их нам необходимо до миграции.
- Движок InnoDB для всех таблиц. MyISAM, Memory и прочие бэкенды не поддерживаются. Исправляется довольно просто — конвертируем все таблицы в InnoDB.
- Binlog в ROW формате. Кластеру для работы не требуется бинлог и если вам не нужны классические слейвы, то вы можете его выключить, но формат бинлога должен быть ROW.
- Все таблицы должны иметь PRIMARY/FOREIGN KEY.Это требуется для правильной конкурентной записи в одну таблицу с разных нод. Для тех таблиц, которые не содержат уникальный ключ можно использовать составной Primary key или авто инкремент.
- Не использовать 'LOCK TABLES', 'GET_LOCK()/RELEASE_LOCK()', 'FLUSH TABLES {{table}} WITH READ LOCK' или уровень изоляции 'SERIALIZABLE' для транзакций.
- Не использовать 'CREATE TABLE… AS SELECT' запросы, т.к. они объединяют изменение схемы и данных. Легко разбивается на 2 запроса, первый из которых создает таблицу, а второй наполняет данными.
- Не использовать 'DISCARD TABLESPACE' и 'IMPORT TABLESPACE', т.к. они не реплицируются
- Установить опции 'innodb_autoinc_lock_mode' значение '2'. Эта опция может повреждать данные при работе со STATEMENT репликацией, но поскольку в кластере разрешено использовать только ROW репликацию, то проблем не будет.
- В качестве 'log_output' поддерживается только 'FILE'. Если у вас запись логов велась в таблицу, то придется это убрать.
- XA транзакции не поддерживаются. Если они использовались, то придется переписать код без них.
Должен заметить, что почти все эти ограничения можно убрать, если установить переменной 'pxc_strict_mode=PERMISSIVE', но если вам дороги ваши данные, то лучше этого не делать. Если у вас установлен 'pxc_strict_mode=ENFORCING', то MySQL не даст выполнить вышеуказанные операции или не даст запустить ноду.
После того, как мы выполнили все требования к БД и хорошенько протестировали работу нашего приложения в дев среде можно переходить к следующему этапу.
Развертывание и конфигурация кластера
У нас на серверах БД работает несколько баз данных и другие БД не нужно мигрировать в кластер. Но пакет с MySQL кластером заменяет классический mysql. У нас было несколько вариантов решения этой проблемы:
- Использовать виртуализацию и запускать кластер в VM. Этот вариант нам не нравился большими (в сравнении с остальными) накладными расходами и появлением еще одной сущности, которую необходимо обслуживать
- Собрать свою версию пакета, которая будет ставить mysql в нестандартное место. Таким образом появится возможность иметь несколько версий mysql на одном сервере. Неплохой вариант если у вас много серверов, но постоянная поддержка своего пакета, который необходимо регулярно обновлять может отнимать достаточно большое ко-во времени.
- Использовать Docker.
Мы выбрали Docker, но используем его в минимальном варианте. Для хранения данных используются локальные volume. Используется режим работы '--net host' для уменьшения сетевых задержек и нагрузки на CPU.
Нам пришлось так же собрать свою версия Docker образа. Причина в том, что стандартный образ от Percona не поддерживает восстановление позиции при запуске. Это означает, что при каждом перезапуске инстанса выполняется не быстрая IST синхронизация, которая заливает только необходимые изменения, а медленная SST, которая полностью перезаливает базу.
Еще один вопрос это размер кластера. В кластере каждая нода хранит весь набор данных. Поэтому чтение отлично масштабируется с увеличением размера кластера. С записью же ситуация обратная — при коммите каждая транзакция валидируется на отсутствие конфликтов на всех нодах. Естественно чем больше нод, тем больше времени будет занимать коммит.
Тут мы тоже имеем несколько вариантов:
- 2 ноды + арбитр. 2 ноды + арбитр. Хороший вариант для тестов. На время развертывания второй ноды на мастер не должна производиться запись.
- 3 ноды. Классический вариант. Баланс скорости и надежности. Обратите внимание, что в данной конфигурации одна нода должна вытягивать всю нагрузку, т.к. в момент добавления 3ей ноды вторая будет донором.
- 4+ ноды. При четном числе нод необходимо добавлять арбитра, чтобы избежать split-brain. Вариант, который хорошо подходит для очень большого количества чтения. Так же растет надежность кластера.
Мы пока остановились на варианте с 3 нодами.
Конфигурация кластера почти полность копирует конфигурацию standalone MySQL и отличается только некоторыми опциями:
«wsrep_sst_method = xtrabackup-v2» Эта опция задает способ копирования нод. Другие возможные варианты это mysqldump и rsync, но они блокируют ноду на время копирования. Не вижу причин использовать не «xtrabackup-v2» метод копирования.
«Gcache» это аналог кластерного бинлога. Представляет собой кольцевой буфер (в файле) фиксированного размера в который записываются все изменения. Если вы выключите одну из нод кластера, а потом включите обратно она попытается прочитать недостающие изменения из Gcache (IST синхронизация). Если в нем нет нужных ноде изменений, то потребуется полная перезаливка ноды (SST синхронизация). Размер gcache задается следующим образом: wsrep_provider_options='gcache.size=20G;'.
wsrep_slave_threads В отличие от классической репликации в кластере возможно параллельно применять несколько «write сетов» к одной БД. Это опция указывает число воркеров применяющих изменения. Лучше не оставлять дефолтное значение 1, т.к. во время применения воркером большого write сета остальные будут ждать в очереди и репликация ноды начнет отставать. Некоторые советуют выставлять этот параметр равным 2 * CPU THREADS, но я думаю необходимо смотреть на количество выполняющихся у вас параллельных операций записи.
Мы остановились на значении 64. При меньшем значении кластер иногда не успевал применять все write сеты из очереди при всплесках нагрузки (например при запуске тяжелых кронов).
wsrep_max_ws_size Размер одной транзакции в кластере ограничен 2 Гб. Но большие транзакции плохо вписываются в концепцию PXC. Лучше выполнить 100 транзакций по 20 Мб, чем одну на 2 Гб. Поэтому мы сначала ограничили размер транзакции в кластере до 100 Мб, а потом снизили лимит до 50 Мб.
Если у вас включен strict mode, то можно установить переменной "binlog_row_image" значение «minimal». Это снизит размер записей в бинлоге в несколько раз (в 10 раз в тесте от Percona). Это сэкономит место на диске и позволит проводить транзакции, которые не влезали в лимит при «binlog_row_image = full».
Лимиты для SST. Для Xtrabackup, который используется для заливки нод можно задать лимит на использование сети, число потоков и способ компрессии. Это необходимо для того, что бы при заливке ноды сервер-донор не начал тормозить. Для этого в файл my.cnf добавляется секция «sst»:
[sst]
rlimit = 80m
compressor = "pigz -3"
decompressor = "pigz -dc"
backup_threads = 4
Мы ограничиваем скорость копирования до 80 Мб/сек. Для сжатия используем pigz, это многопоточная версия gzip.
GTID Если вы используете классические слейвы, то рекомендую включить GTID на кластере. Это позволит подключать слейв к любой ноде кластера без перезаливки слейва.
Дополнительно хочу поговорить про 2 механизма кластер, их значение и конфигурирование.
Flow control
Flow control это способ управления нагрузкой на запись в кластере. Он не дает нодам слишком сильно отставать в репликации. Таким образом достигается «почти синхронная» репликация. Механизм работы достаточно простой — как только у ноды длинна очереди на прием достигает установленного значение она посылает остальным нодам сообщение «Flow control pause», которое говорит им о том, что нужно повременить с коммитом новых транзакций до момента, пока отстающая нода не закончит разгребать очередь.
Отсюда вытекает несколько вещей:
- Запись в кластере будет происходить со скоростью самой медленной ноды. (Но это можно подкрутить.)
- Если у вас происходит много конфликтов при коммите транзакций, то вы можете настроить Flow Control более агрессивно, что должно уменьшить их число.
- Максимальное отставание ноды в кластере является константой, но не по времени, а по количеству транзакций в очереди. Время отставания зависит от среднего размера транзакции и количества «wsrep_slave_threads».
Посмотреть настройки Flow control можно так:
mysql> SHOW GLOBAL STATUS LIKE 'wsrep_flow_control_interval_%';
wsrep_flow_control_interval_low | 36
wsrep_flow_control_interval_high | 71
В первую очередь нас интересует параметр «wsrep_flow_control_interval_high». Он регулирует длину очереди, по достижении которого включается FC pause. Вычисляется этот параметр по формуле: gcs.fc_limit * √N (где N=число узлов в кластере.).
Второй параметр это «wsrep_flow_control_interval_low». Он отвечает за значение длинны очереди, по достижении которого выключается FC. Рассчитывается по формуле: wsrep_flow_control_interval_high * gcs.fc_factor. По умолчанию gcs.fc_factor=1.
Таким образом меняя длину очереди мы можем управлять отставанием репликации. Уменьшение длины очереди увеличит время, которое кластер проводит в FC pause, но уменьшит отставание нод.
Можно установить сессионную переменную "wsrep_sync_wait=7". Это заставит PXC выполнять запросы на чтение или запись только после применения всех write-set'ов в текущей очереди. Естественно это увеличит latency запросов. Увеличение latency прямо пропорционально длине очереди.
Также желательно уменьшить максимальный размер транзакций до минимально возможного, что бы случайно не проскакивали длинные транзакции.
EVS или Auto Evict
Данный механизм позволяет выкидывать ноды, с которыми неустойчивая связь (например потери пакетов или большие задержки) или которые медленно отвечают. Благодаря ему проблемы связи с одной нодой не положат весь кластер, а позволять отключить ноду и продолжить работу в нормальном режиме. Особенно полезен данный механизм может быть при работе кластера через WAN или неподконтрольные вам участки сети. По умолчанию EVS выключен.
Чтобы включить его необходимо добавить в параметр wsrep_provider_options опции «evs.version=1;» и «evs.auto_evict=5;» (число срабатываний, после которого нода отключается. Значение 0 выключает EVS.) Есть также несколько параметров, которые позволяют тонко настроить EVS:
- evs.delayed_margin Время, которое отводится ноде на ответ. По дефолту 1 сек., но при работе в локальной сети его можно снизить до 0.05-0.1 сек или ниже.
- evs.inactive_check_period Период проверок. По умолчанию 0.5 сек
Фактически время, которое нода может работать при проблемах до срабатывания EVS равно evs.inactive_check_period * evs.auto_evict. Также можно задать «evs.inactive_timeout» и нода не отвечавшая это время будет сразу выкинута, по умолчанию 15 сек.
Важный нюанс в том, что данный механизм сам не вернет ноду обратно при восстановлении связи. Ее необходимо перезапустить руками.
У себя мы настроили EVS, но испытать его в бою еще не довелось.
Балансировка нагрузки
Для того, что бы клиенты равномерно использовали ресурсы каждой ноды, и выполняли запросы только на живых узлах кластера нам нужен балансировщик нагрузки. Percona предлагает 2 решения:
- ProxySQL. Это L7 прокси для MySQL.
- Haproxy. Но Haproxy не умеет проверять статус ноды кластера и определять готова ли она к выполнению запросов. Для решения этой проблемы предлагается использовать дополнительный скрипт percona-clustercheck
Сначала мы хотели использовать ProxySQL, но после тестирования производительности выяснилось, что по latency он проигрывает Haproxy примерно 15-20% даже при использовании режима fast_forward (в этом режиме не работают реврайты запросов, роутинг и многие другие функции ProxySQL, запросы проксируются as-is).
Haproxy работает быстрее, но у скрипта от Percona есть несколько минусов.
Во-первых он написан на bash, что не способствует его кастомизируемости. Более серьезная проблема в том, что он не кэширует результат проверки MySQL. Таким образом если у нас есть 100 клиентов, каждый из которых проверяет состояние ноды раз в 1 секунду, то скрипт будет делать запрос к MySQL каждые 10 мс. Если по каким-то причинам MySQL начнет медленно работать, то скрипт проверки начнет создавать огромное количество процессов, что точно не улучшит ситуацию.
Было решено написать свое решение, в котором проверка состояния MySQL и ответ Haproxy не связаны друг с другом. Скрипт проверяет состояние ноды в бэкграунде через равные промежутки времени и кэширует результат. Веб сервер отдает Haproxy закешированный результат.
Пример используемой конфигурации Haproxy
В данном примере приведена конфигурация с одним мастером. Остальные сервера кластера работают в качестве слейвов.
listen db
bind 127.0.0.1:3302
mode tcp
balance first
default-server inter 200 rise 6 fall 6
option httpchk HEAD /
server node1 192.168.0.1:3302 check port 9200 id 1
server node2 192.168.0.2:3302 check port 9200 backup id 2
server node3 192.168.0.3:3302 check port 9200 backup id 3
listen db_slave
bind 127.0.0.1:4302
mode tcp
balance leastconn
default-server inter 200 rise 6 fall 6
option httpchk HEAD /
server node1 192.168.0.1:3302 check port 9200 backup
server node2 192.168.0.2:3302 check port 9200
server node3 192.168.0.3:3302 check port 9200
В данном примере приведена конфигурация с одним мастером. Остальные сервера кластера работают в качестве слейвов.
Мониторинг
Для мониторинга состояния кластера мы использовали Prometheus + mysqld_exporter и Grafana для визуализации данных. Т.к. mysqld_exporter собирает кучу метрик создавать дашборды самостоятельно довольно утомительно. Можно взять готовые дашборды от Percona и кастомизировать их под себя.
Для сбора основных метрик кластера и алертинга мы также используем Zabbix.
Основные метрики кластера, которые желательно мониторить:
- wsrep_cluster_status На всех нодах должна иметь значение «Primary». Если значение «non-Primary» значит эта нода потеряла связь с кворумом кластера.
- wsrep_cluster_size Число нод в кластере. Сюда также входят «потерянные» ноды, которые должны быть в кластере, но почему-то не доступны. При мягком выключении ноды значение этой переменной уменьшается.
- wsrep_local_state Показывает, является ли нода активным членом кластера и готова ли к работе.
- wsrep_evs_state Важный параметр, если у вас включен механизм Auto Eviction (по умолчанию выключен). Данная переменная показывает, что EVS считает эту ноду здоровой.
- wsrep_evs_evict_list Список нод, которые были выкинуты EVS из кластера. В нормальной ситуации список должен быть пустым.
- wsrep_evs_delayed Список кандидатов на удаление EVS'ом. Также должен быть пустым.
Основные метрики производительности:
- wsrep_evs_repl_latency Показывает (минимальную/среднюю/максимальную/ ст. отклонение/размер пакета) задержу коммуникаций внутри кластера. То есть измеряет задержку сети. Увеличение значений может говорить о перегрузке сети или нод кластера. Данная метрика записывается даже при выключенном EVS.
- wsrep_flow_control_paused_ns Время (в нс) с запуска ноды, которое она провела в Flow control pause. В идеале должно быть 0. Рост этого параметра говорит о проблемах с производительностью кластера или о недостатке «wsrep_slave_threads». Определить какая нода тормозит можно по параметру "wsrep_flow_control_sent".
- wsrep_flow_control_paused Процент времени с последнего выполнения «FLUSH STATUS;», которая нода провела в Flow control pause. Также, как и предыдущая переменная должна стремится к нулю.
- wsrep_flow_control_status Показывает, работает ли в данный момент Flow Control. На инициировавшей FC pause ноде значение данной переменной будет ON.
- wsrep_local_recv_queue_avg Средняя длина очереди на прием. Рост этого параметра говорит о проблемах с производительностью ноды.
- wsrep_local_send_queue_avg Средняя длина очереди на отправку. Рост этого параметра говорит о проблемах с производительностью сети.
Каких то универсальных рекомендаций по значениям этих параметров нет. Понятно, что они должны стремится к нулю, но на реальной нагрузке это скорее всего будет не так и вам придется самим определять, где проходит граница нормального состояния кластера.
Резервное копирование
Резервное копирование кластера практически не отличается от standalone mysql. Для продакшн использования у нас есть несколько вариантов.
- Снимать бэкап с одной из нод «наживую» при помощи xtrabackup. Самый простой вариант, но во время бэкапа будет просаживаться производительность кластера.
- Использовать классические слейвы и снимать бэкап с реплики.
Бекапы со standalone и с кластерной версии созданные с помощью xtrabackup переносимы между собой. То есть снятый с кластера бэкап можно развернуть на standalone mysql и наоборот. Естественно мажорная версия MySQL должна совпадать, желательно и минорная. Бэкапы сделанные с помощью mysqldump естественно тоже переносимы.
Единственный нюанс в том, что после разворачивания бэкапа необходимо запустить скрипт mysql_upgrade который проверит и исправит структуру некоторых системных таблиц.
Миграция данных
Теперь, когда мы разобрались с конфигурированием, мониторингом и прочими вещами можно приступать к миграции на проде.
Миграция данных в нашей схеме выполнялась достаточно просто, но мы немного накосячили;).
Легенда — мастер 1 и мастер 2 связаны мастер-мастер репликацией. Запись идет только на мастер 1. Мастер 3 это чистый сервер.
Наш план миграции (в плане я опущу операции со слейвами для простоты и буду рассказывать только о мастер серверах).
Попытка 1
- Снимаем бэкап БД с мастера 1 с помощью xtrabackup.
- Копируем бэкап на мастер 3 и запускаем кластер в режиме single-node.
- Настраиваем мастер-мастер репликацию между мастерами 3 и 1.
- Переключаем чтение и запись на мастер 3. Проверяем работу приложения.
- На мастере 2 выключаем репликацию и запускаем кластерный MySQL. Ждем пока он скопирует БД с мастера 3. Во время копирования у нас был кластер из одной ноды в статусе «Donor» и одной еще не работающей ноды. Во время копирования мы получили кучу блокировок и в конце концов обе ноды упали с ошибкой (создание новой ноды невозможно завершить из-за dead локов). Этот маленький эксперимент стоил нам четырех минут даунтайма.
- Переключаем чтение и запись обратно на мастер 1.
Миграция не получилась из-за того, что при тестировании схемы в dev среде на БД практически не было трафика на запись, а при повторении этой же схемы под нагрузкой вылезли проблемы.
Мы немного поменяли схему миграции, что бы избежать этих проблем и повторили попытку, на 2ой раз удачно;).
Попытка 2
- Перезапускаем мастер 3, что бы он работал опять в режиме single-node.
- Заново поднимаем на мастере 2 кластерный MySQL. В данный момент на кластер шел трафик только от репликации, поэтому повторения проблем с локами не было и вторая нода успешно добавилась в кластер.
- Опять переключаем чтение и запись на мастер 3. Проверяем работу приложения.
- Отключаем мастер-мастер репликацию с мастером 1. Включаем на мастере 1 кластерный mysql и ждем пока он запустится. Чтобы не наступить на теже грабли важно, чтобы на Donor ноду не писало приложение (подробности в разделе про балансировку нагрузки). После запуска третьей ноды у нас будет полностью работоспособный кластер из трех нод.
- Можно снять с одной из нод кластера бэкап и создать нужное вам количество классических слейвов.
Отличие второй схемы от первой в том, что мы переключили трафик на кластер только после поднятия в кластере второй ноды.
У нас данная процедура заняла примерно 6 часов.
Multi-master
После миграции наш кластер работал в режиме single-master, то есть вся запись шла на один из серверов, а с остальных только читались данные.
После переключения продакшена в режим мульти мастер мы столкнулись с проблемой — конфликты транзакций возникали заметно чаще, чем мы предполагали. Особенно плохо было с запросами, которые изменяют много записей, например обновляют значение всех записей в таблице. Те транзакции, которые успешно выполнялись на одной ноде последовательно на кластере выполняются параллельно и более долгая транзакция получает ошибку deadlock. Не буду тянуть, после нескольких попыток исправить это на уровне приложения мы отказались от идеи с multi-master.
Другие нюансы
- Кластер может быть слейвом. При использовании этой функции рекомендую добавить в конфиг всех нод, кроме той, которая является слейвом опцию «skip_slave_start = 1». Иначе каждая новая нода будет запускать репликацию с мастера, что вызовет либо ошибки репликации, либо порчу данных на реплике.
- Как я уже говорил Donor нода не может нормально обслуживать клиентов. Необходимо помнить, что в кластере из трех нод возможны ситуации, когда одна нода вылетела, вторая является донором и остается только одна нода для обслуживания клиентов.
Выводы
После миграции и некоторого времени эксплуатации мы пришли к следующим выводам.
- Galera кластер работает и достаточно стабилен (по крайней мере пока нештатных падений нод или их нештатного поведения не было). В части отказоустойчивости мы получили именно то, что хотели.
- Заявления Percona про multi-master являются в основном маркетингом. Да, кластер возможно использовать в таком режиме, но это потребует глубокой переделки приложения под данную модель использования.
- Синхронной репликации нет, но теперь мы контролируем максимальное отставание нод (в транзакциях). Вместе с ограничением максимального размера транзакции в 50 Мб мы можем достаточно точно предсказать максимальное время отставания нод. Разработчикам стало легче писать код.
- В мониторинге мы наблюдаем кратковременные пики роста очереди репликации. Причина в нашей 1 Gbit/s сети. Эксплуатировать кластер на такой сети возможно, но при всплесках нагрузки проявляются проблемы. Сейчас планируем апгрейд сети до 10 Gbit/s.
Итого из трех «хотелок» мы получили примерно полторы. Самое главное требование — отказоустойчивость выполнено.
Наш конфигурационный файл PXC для интересующихся:
my.cnf
[mysqld]
#Main
server-id = 1
datadir = /var/lib/mysql
socket = mysql.sock
port = 3302
pid-file = mysql.pid
tmpdir = /tmp
large_pages = 1
skip_slave_start = 1
read_only = 0
secure-file-priv = /tmp/
#Engine
innodb_numa_interleave = 1
innodb_flush_method = O_DIRECT
innodb_flush_log_at_trx_commit = 2
innodb_file_format = Barracuda
join_buffer_size = 1048576
tmp-table-size = 512M
max-heap-table-size = 1G
innodb_file_per_table = 1
sql_mode = "NO_ENGINE_SUBSTITUTION,NO_AUTO_CREATE_USER,ERROR_FOR_DIVISION_BY_ZERO"
default_storage_engine = InnoDB
innodb_autoinc_lock_mode = 2
#Wsrep
wsrep_provider = "/usr/lib64/galera3/libgalera_smm.so"
wsrep_cluster_address = "gcomm://192.168.0.1:4577,192.168.0.2:4577,192.168.0.3:4577"
wsrep_cluster_name = "prod"
wsrep_node_name = node1
wsrep_node_address = "192.168.0.1"
wsrep_sst_method = xtrabackup-v2
wsrep_sst_auth = "USER:PASS"
pxc_strict_mode = ENFORCING
wsrep_slave_threads = 64
wsrep_sst_receive_address = "192.168.0.1:4444"
wsrep_max_ws_size = 50M
wsrep_retry_autocommit = 2
wsrep_provider_options = "gmcast.listen_addr=tcp://192.168.0.1:4577; ist.recv_addr=192.168.0.1:4578; gcache.size=30G; pc.checksum=true; evs.version=1; evs.auto_evict=5; gcs.fc_limit=80; gcs.fc_factor=0.75; gcs.max_packet_size=64500;"
#Binlog
expire-logs-days = 4
relay-log = mysql-relay-bin
log_slave_updates = 1
binlog_format = ROW
binlog_row_image = minimal
log_bin = mysql-bin
log_bin_trust_function_creators = 1
#Replication
slave-skip-errors = OFF
relay_log_info_repository = TABLE
relay_log_recovery = ON
master_info_repository = TABLE
gtid-mode = ON
enforce-gtid-consistency = ON
#Cache
query_cache_size = 0
query_cache_type = 0
thread_cache_size = 512
table-open-cache = 4096
innodb_buffer_pool_size = 72G
innodb_buffer_pool_instances = 36
key_buffer_size = 16M
#Logging
log-error = /var/log/stdout.log
log_error_verbosity = 1
slow_query_log = 0
long_query_time = 10
log_output = FILE
innodb_monitor_enable = "all"
#Timeout
max_allowed_packet = 512M
net_read_timeout = 1200
net_write_timeout = 1200
interactive_timeout = 28800
wait_timeout = 28800
max_connections = 22000
max_connect_errors = 18446744073709551615
slave-net-timeout = 60
#Static Values
ignore_db_dir = "lost+found"
[sst]
rlimit = 80m
compressor = "pigz -3"
decompressor = "pigz -dc"
backup_threads = 8
Источники и полезные ссылки
→ Наш Docker image
→ Percona XtraDB Cluster 5.7 Documentation
→ Monitoring Cluster Status — Galera Cluster Documentation
→ Galera Status Variables — Galera Cluster Documentation
Only registered users can participate in poll. Log in, please.
Заинтресовал ли вас MySQL PXC/Galera Cluster?
56.76% Я использую MySQL и он меня заинтересовал42
5.41% Я использую MySQL и он меня НЕ заинтересовал4
4.05% Я использую другую СУБД и он меня заинтересовал3
8.11% Я использую другую СУБД и он меня НЕ заинтересовал6
25.68% Я уже использую PXC или Galera Cluster19
74 users voted. 16 users abstained.
