Если вы программируете на «большом» компьютере, то у вас такой вопрос, скорее всего, вообще не возникает. Стека много, чтобы его переполнить, нужно постараться. В худшем случае вы нажмёте ОК на окошке вроде этого и пойдете разбираться, в чем дело.
Но вот если вы программируете микроконтроллеры, то проблема выглядит немного иначе. Для начала нужно заметить, что стек переполняется.
В этой статье я расскажу о собственных изысканиях на эту тему. Поскольку я программирую в основном под STM32 и под Миландр 1986 — на них я и фокусировался.
Представим самый простой случай — мы пишем простой однопоточный код без всяких операционных систем, т.е. стек у нас всего один. И если вы, как и я, программируете в uVision Keil, то память распределяется как-то так:

А если вы, как и я, считаете динамическую память на микроконтроллерах злом, то вот так:

Окей, и в чем проблема? Проблема в том, что Keil размещает стек сразу за областью статических данных. А стек в Cortex-M растет в сторону уменьшения адресов. И когда он переполняется, то он просто вылезает за пределы отведенного ему куска памяти. И перезаписывает какие-нибудь статические или глобальные переменные.
Особенно здорово, если стек переполняется только при заходе в прерывание. Или, еще лучше, во вложенное прерывание! И тихо портит какую-нибудь переменную, которая используется совершенно в другом участке кода. И программа падает на ассерте. Если вам повезет. Сферический гейзенбаг, такой можно целую неделю с фонарём искать.
Сразу оговорюсь, что если вы используете кучу, то проблема никуда не уходит, просто вместо глобальных переменных портится куча. Не сильно лучше.
Окей, проблема понятна. Что делать?
Самое простое и очевидное — использовать MPU (сиречь, Memory Protection Unit). Позволяет назначать разным кускам памяти разные атрибуты; в частности можно окружить стек регионами «только для чтения» и ловить MemFault при записи туда.
Например, в stm32f407 MPU есть. К сожалению, во многих других «младших» stm его нет. И в Миландровском 1986ВЕ1 его тоже нет.
Т.е. решение хорошее, но не всегда доступное.
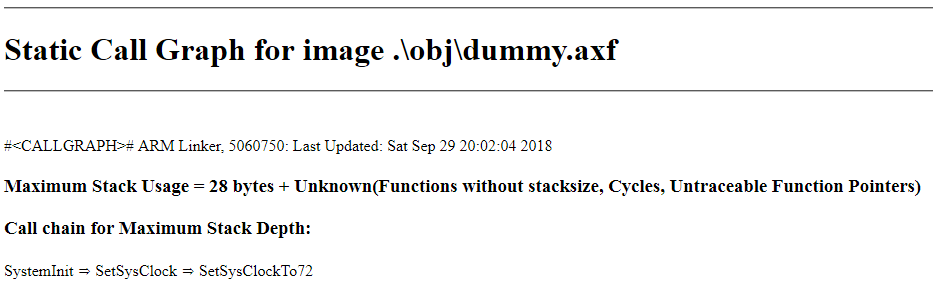
При компиляции Keil может генерировать (и делает это по-умолчанию) html-отчет с графом вызовов (опция линкера "--info=stack"). И в этом отчете приводится и информация об используемом стеке. Gcc тоже так умеет (опция -fstack-usage). Соответственно, можно иногда поглядывать в этот отчет (или написать скрипт, который делает это за вас, и вызывать его перед каждым билдом).
Причем в самом начале отчета написан путь, приводящий к максимальному использованию стека:
Проблема в том, что если в вашем коде есть вызовы функций по указателям или виртуальные методы (а у меня они есть), то этот отчет может сильно недооценивать максимальную глубину стека. Ну и прерывания, разумеется, не учитываются. Не очень надежный способ.
Об этом способе я узнал из вот этой статьи. Статья про rust, но основная идея состоит в следующем:

При использовании gcc это возможно сделать с помощью "двойной линковки".
А в Keil’е расположение областей можно изменить с помощью своего скрипта для линкера (scatter file в терминологии Keil'a). Для этого нужно открыть опции проекта и снять галку «Use memory layout from target dialog». Тогда в поле «Scatter file» появится файл по-умолчанию. Он выглядит примерно так:
Что делать дальше? Возможны варианты. Официальная документация предлагает определить секции с зарезервированными именами — ARM_LIB_HEAP и ARM_LIB_STACK. Но это влечет за собой неприятные последствия, по крайней мере, для меня — размеры стека и кучи придется задавать в scatter-файле.
Во всех проектах, которые я использую, размер стека и кучи задается в ассемблерном startup-файле (который Keil генерирует при создании проекта). Менять его не очень хочется. Хочется, чтобы я просто включил в проект новый scatter-файл, и все стало хорошо. Поэтому я пошел немного другим путем:
Тут я сказал, что все объекты по имени STACK должны размещаться в регионе REGION_STACK, а все объекты HEAP — в регионе REGION_HEAP. А все остальное — в регионе RW_IRAM1. И расположил регионы в таком порядке — начало оперативы, стек, куча, все остальное. Расчет на то, что в ассемблерном startup-файле стек и куча задаются с помощью вот такого кода (т.е. как массивы с названиями STACK и HEAP):
Окей, возможно спросите вы, но что это нам дает? А вот что. Теперь при выходе за пределы стека процессор пытается записать (или прочитать) память, которой нет. И на STM32 при этом возникает прерывание по исключительной ситуации — HardFault.
Это не так удобно, как MemFault из-за MPU, потому что HardFault может возникать из-за множества причин, но, по крайней мере, ошибка получается громкой, а не тихой. Т.е. она возникает сразу, а не через неизвестный промежуток времени, как было раньше.
Что самое классное, мы ничем за это не заплатили, никакого оверхеда времени выполнения! Здорово. Но есть одна проблема.
Это не работает на Миландре.
Да. Конечно, на Миландрах (меня интересуют в основном 1986ВЕ1 и ВЕ91) карта памяти выглядит иначе. В STM32 до начала оперативы нет ничего, а на Миландрах до оперативы лежит область внешней шины.
Но даже если вы не используете внешнюю шину, то никакого HardFault'a вы не получите. А может и получите. А может быть, получите, но не сразу. Я не смог найти никакой информации на этот счет (что для Миландра неудивительно), а эксперименты не дали никаких внятных результатов. HardFault иногда возникал, если размер стека был кратен 256. Иногда HardFault возникал, если стек углублялся уж очень далеко в несуществующую память.
Но это даже неважно. Если HardFault не возникает каждый раз, то простое перемещение стека в начало RAM нас уже не спасает. И если уж совсем честно, STM тоже не обязан генерировать исключение при этом, спецификация ядер Cortex-M ничего конкретного на этот счет вроде бы не говорит.
Так что даже на STM это скорее хак, просто не очень грязный.
Значит, нужно искать какой-то другой способ.
Если мы переместим стек в начало RAM, то предельное значение стека всегда будет одно и то же — 0x20000000. И мы можем просто поставить брейкпоинт на запись в эту ячейку. Это можно сделать командой и даже прописать в автозапуск с помощью .ini-файла:
Но это не очень надежный способ. Этот брейкпоинт будет срабатывать каждый раз при инициализации стека. Его легко случайно прибить, нажав «Kill all breakpoints». А еще он будет вас защищать только в присутствии отладчика. Не годится.
Быстрый поиск на этот счет вывел меня к опциям Keil'a "--protect_stack" и "--protect_stack_all". Опции полезные, к сожалению, защищают они не от переполнения всего стека, а от залезания в стековый кадр другой функции. Например, если ваш код выходит за границы массива или неудачно работает с переменным числом параметров. Gcc, разумеется, тоже так умеет (-fstack-protector).
Суть этой опции в следующем: в каждый стековый кадр добавляется «guard variable», то бишь, сторожевое число. Если после выхода из функции это число изменилось, то вызывается функция-обработчик ошибки. Подробности тут.
Полезная штука, но не совсем то, что мне нужно. Мне нужна гораздо более простая проверка — чтобы при входе в каждую функцию значение регистра SP (Stack Pointer) сверялось с заранее известным минимальным значением. Но не писать же эту проверку руками на входе в каждую функцию?
К счастью, gcc имеет чудесную опцию "-finstrument-functions", которая позволяет вызывать пользовательскую функцию при входе в каждую функцию и при выходе из каждой функции. Обычно это используется для вывода отладочной информации, но какая разница?
К еще большему счастью, Keil вполне сознательно копирует функционал gcc, и там эта же опция доступна под названием "--gnu_instrument" (подробности).
После этого нужно всего лишь написать вот такой код:
И вуаля! Теперь при входе в каждую функцию (в том числе в обработчики прерываний) будет выполняться проверка на переполнение стека. И если стек переполнился — будет ассерт.
Идеально ли полученное решение? Конечно, нет.
Во-первых, эта проверка далеко не бесплатна, код от нее распухает процентов на 10. Ну и работать код будет медленнее (хотя я не измерял). Критично это или нет — решать вам; на мой взгляд, это разумная цена за безопасность.
Во-вторых, это, скорее всего, не будет работать при использовании прекомпилированных библиотек (но т.к. я их не использую вообще, я не проверял).
Зато это решение потенциально пригодно и для многопоточных программ, поскольку проверку мы делаем полностью сами. Но эту мысль я еще не додумал толком, поэтому пока придержу.
Получилось найти работающие решения для stm32 и для Миландра, хотя для последнего пришлось заплатить некоторым оверхедом.
Для меня же самым главным была небольшая смена парадигмы мышления. До вышеупомянутой статьи я вообще не задумывался, что от переполнения стека можно как-то защититься. Я не воспринимал это как проблему, которую нужно решить, а скорее как некое стихийное явление — иногда идет дождь, а иногда переполняется стек, ну, тут ничего не поделаешь, надо стиснуть зубы и потерпеть.
И я вообще достаточно часто замечаю за собой (да и за другими людьми) такое — вместо того, чтобы потратить 5 минут в гугле и найти тривиальное решение — живу со своими проблемами годами.
На этом у меня все. Я понимаю, что ничего кардинально нового я не открыл, но готовых статей с таким решением мне не попадалось (по крайней мере, сам Джозеф Ю в статье на эту тему прямым текстом это не предлагает). Надеюсь, в комментариях мне подскажут, прав я или нет, и каковы подводные камни такого подхода.
UPD: Если при добавлении scatter-файла Keil начинает выдавать непонятный warning аля «AppData\Local\Temp\p17af8-2(33): warning: #1-D: last line of file ends without a newline» — но сам этот файл не открывается, ибо он временный, — то просто добавьте перенос строки последним символом в scatter-файл.
Но вот если вы программируете микроконтроллеры, то проблема выглядит немного иначе. Для начала нужно заметить, что стек переполняется.
В этой статье я расскажу о собственных изысканиях на эту тему. Поскольку я программирую в основном под STM32 и под Миландр 1986 — на них я и фокусировался.
Введение
Представим самый простой случай — мы пишем простой однопоточный код без всяких операционных систем, т.е. стек у нас всего один. И если вы, как и я, программируете в uVision Keil, то память распределяется как-то так:
А если вы, как и я, считаете динамическую память на микроконтроллерах злом, то вот так:
Кстати
Если вы хотите запретить использование кучи, то можно сделать вот так:
Подробности тут
#pragma import(__use_no_heap_region)
Подробности тут
Окей, и в чем проблема? Проблема в том, что Keil размещает стек сразу за областью статических данных. А стек в Cortex-M растет в сторону уменьшения адресов. И когда он переполняется, то он просто вылезает за пределы отведенного ему куска памяти. И перезаписывает какие-нибудь статические или глобальные переменные.
Особенно здорово, если стек переполняется только при заходе в прерывание. Или, еще лучше, во вложенное прерывание! И тихо портит какую-нибудь переменную, которая используется совершенно в другом участке кода. И программа падает на ассерте. Если вам повезет. Сферический гейзенбаг, такой можно целую неделю с фонарём искать.
Сразу оговорюсь, что если вы используете кучу, то проблема никуда не уходит, просто вместо глобальных переменных портится куча. Не сильно лучше.
Окей, проблема понятна. Что делать?
MPU
Самое простое и очевидное — использовать MPU (сиречь, Memory Protection Unit). Позволяет назначать разным кускам памяти разные атрибуты; в частности можно окружить стек регионами «только для чтения» и ловить MemFault при записи туда.
Например, в stm32f407 MPU есть. К сожалению, во многих других «младших» stm его нет. И в Миландровском 1986ВЕ1 его тоже нет.
Т.е. решение хорошее, но не всегда доступное.
Ручной контроль
При компиляции Keil может генерировать (и делает это по-умолчанию) html-отчет с графом вызовов (опция линкера "--info=stack"). И в этом отчете приводится и информация об используемом стеке. Gcc тоже так умеет (опция -fstack-usage). Соответственно, можно иногда поглядывать в этот отчет (или написать скрипт, который делает это за вас, и вызывать его перед каждым билдом).
Причем в самом начале отчета написан путь, приводящий к максимальному использованию стека:
Проблема в том, что если в вашем коде есть вызовы функций по указателям или виртуальные методы (а у меня они есть), то этот отчет может сильно недооценивать максимальную глубину стека. Ну и прерывания, разумеется, не учитываются. Не очень надежный способ.
Хитрое размещение стека
Об этом способе я узнал из вот этой статьи. Статья про rust, но основная идея состоит в следующем:
При использовании gcc это возможно сделать с помощью "двойной линковки".
А в Keil’е расположение областей можно изменить с помощью своего скрипта для линкера (scatter file в терминологии Keil'a). Для этого нужно открыть опции проекта и снять галку «Use memory layout from target dialog». Тогда в поле «Scatter file» появится файл по-умолчанию. Он выглядит примерно так:
; ************************************************************* ; *** Scatter-Loading Description File generated by uVision *** ; ************************************************************* LR_IROM1 0x08000000 0x00020000 { ; load region size_region ER_IROM1 0x08000000 0x00020000 { ; load address = execution address *.o (RESET, +First) *(InRoot$$Sections) .ANY (+RO) } RW_IRAM1 0x20000000 0x00005000 { ; RW data .ANY (+RW +ZI) } }
Что делать дальше? Возможны варианты. Официальная документация предлагает определить секции с зарезервированными именами — ARM_LIB_HEAP и ARM_LIB_STACK. Но это влечет за собой неприятные последствия, по крайней мере, для меня — размеры стека и кучи придется задавать в scatter-файле.
Во всех проектах, которые я использую, размер стека и кучи задается в ассемблерном startup-файле (который Keil генерирует при создании проекта). Менять его не очень хочется. Хочется, чтобы я просто включил в проект новый scatter-файл, и все стало хорошо. Поэтому я пошел немного другим путем:
Спойлер
#! armcc -E ; with that we can use C preprocessor #define RAM_BEGIN 0x20000000 #define RAM_SIZE_BYTES (4*1024) #define FLASH_BEGIN 0x8000000 #define FLASH_SIZE_BYTES (32*1024) ; This scatter file places stack before .bss region, so on stack overflow ; we get HardFault exception immediately LR_IROM1 FLASH_BEGIN FLASH_SIZE_BYTES { ; load region size_region ER_IROM1 FLASH_BEGIN FLASH_SIZE_BYTES { ; load address = execution address *.o (RESET, +First) *(InRoot$$Sections) .ANY (+RO) } ; Stack region growing down REGION_STACK RAM_BEGIN { *(STACK) } ; We have to define heap region, even if we don't actually use heap REGION_HEAP ImageLimit(REGION_STACK) { *(HEAP) } ; this will place .bss region above the stack and heap and allocate RAM that is left for it RW_IRAM1 ImageLimit(REGION_HEAP) (RAM_SIZE_BYTES - ImageLength(REGION_STACK) - ImageLength(REGION_HEAP)) { *(+RW +ZI) } }
Тут я сказал, что все объекты по имени STACK должны размещаться в регионе REGION_STACK, а все объекты HEAP — в регионе REGION_HEAP. А все остальное — в регионе RW_IRAM1. И расположил регионы в таком порядке — начало оперативы, стек, куча, все остальное. Расчет на то, что в ассемблерном startup-файле стек и куча задаются с помощью вот такого кода (т.е. как массивы с названиями STACK и HEAP):
Спойлер
Stack_Size EQU 0x00000400 AREA STACK, NOINIT, READWRITE, ALIGN=3 Stack_Mem SPACE Stack_Size __initial_sp Heap_Size EQU 0x00000200 AREA HEAP, NOINIT, READWRITE, ALIGN=3 __heap_base Heap_Mem SPACE Heap_Size __heap_limit PRESERVE8 THUMB
Окей, возможно спросите вы, но что это нам дает? А вот что. Теперь при выходе за пределы стека процессор пытается записать (или прочитать) память, которой нет. И на STM32 при этом возникает прерывание по исключительной ситуации — HardFault.
Это не так удобно, как MemFault из-за MPU, потому что HardFault может возникать из-за множества причин, но, по крайней мере, ошибка получается громкой, а не тихой. Т.е. она возникает сразу, а не через неизвестный промежуток времени, как было раньше.
Что самое классное, мы ничем за это не заплатили, никакого оверхеда времени выполнения! Здорово. Но есть одна проблема.
Это не работает на Миландре.
Да. Конечно, на Миландрах (меня интересуют в основном 1986ВЕ1 и ВЕ91) карта памяти выглядит иначе. В STM32 до начала оперативы нет ничего, а на Миландрах до оперативы лежит область внешней шины.
Но даже если вы не используете внешнюю шину, то никакого HardFault'a вы не получите. А может и получите. А может быть, получите, но не сразу. Я не смог найти никакой информации на этот счет (что для Миландра неудивительно), а эксперименты не дали никаких внятных результатов. HardFault иногда возникал, если размер стека был кратен 256. Иногда HardFault возникал, если стек углублялся уж очень далеко в несуществующую память.
Но это даже неважно. Если HardFault не возникает каждый раз, то простое перемещение стека в начало RAM нас уже не спасает. И если уж совсем честно, STM тоже не обязан генерировать исключение при этом, спецификация ядер Cortex-M ничего конкретного на этот счет вроде бы не говорит.
Так что даже на STM это скорее хак, просто не очень грязный.
Значит, нужно искать какой-то другой способ.
Access breakpoint на запись
Если мы переместим стек в начало RAM, то предельное значение стека всегда будет одно и то же — 0x20000000. И мы можем просто поставить брейкпоинт на запись в эту ячейку. Это можно сделать командой и даже прописать в автозапуск с помощью .ini-файла:
// breakpoint on stackoverflow BS Write 0x20000000, 1
Но это не очень надежный способ. Этот брейкпоинт будет срабатывать каждый раз при инициализации стека. Его легко случайно прибить, нажав «Kill all breakpoints». А еще он будет вас защищать только в присутствии отладчика. Не годится.
Динамическая защита от переполнений
Быстрый поиск на этот счет вывел меня к опциям Keil'a "--protect_stack" и "--protect_stack_all". Опции полезные, к сожалению, защищают они не от переполнения всего стека, а от залезания в стековый кадр другой функции. Например, если ваш код выходит за границы массива или неудачно работает с переменным числом параметров. Gcc, разумеется, тоже так умеет (-fstack-protector).
Суть этой опции в следующем: в каждый стековый кадр добавляется «guard variable», то бишь, сторожевое число. Если после выхода из функции это число изменилось, то вызывается функция-обработчик ошибки. Подробности тут.
Полезная штука, но не совсем то, что мне нужно. Мне нужна гораздо более простая проверка — чтобы при входе в каждую функцию значение регистра SP (Stack Pointer) сверялось с заранее известным минимальным значением. Но не писать же эту проверку руками на входе в каждую функцию?
Динамический контроль SP
К счастью, gcc имеет чудесную опцию "-finstrument-functions", которая позволяет вызывать пользовательскую функцию при входе в каждую функцию и при выходе из каждой функции. Обычно это используется для вывода отладочной информации, но какая разница?
К еще большему счастью, Keil вполне сознательно копирует функционал gcc, и там эта же опция доступна под названием "--gnu_instrument" (подробности).
После этого нужно всего лишь написать вот такой код:
Спойлер
// это специальный символ, который генерирует линкер // это начало стека, регион для которого я сам так назвал в scatter-файле extern unsigned int Image$$REGION_STACK$$RW$$Base; // чтобы получить его значение, нужно разыменование static const uint32_t stack_lower_address = (uint32_t) &( Image$$REGION_STACK$$RW$$Base ); // эта функция вызывается при входе в любую функцию extern "C" __attribute__((no_instrument_function)) void __cyg_profile_func_enter( void * current_func, void * callsite ) { (void)current_func; (void)callsite; ASSERT( __current_sp() >= stack_lower_address ); } // а эта - при выходе extern "C" __attribute__((no_instrument_function)) void __cyg_profile_func_exit( void * current_func, void * callsite ) { (void)current_func; (void)callsite; }
И вуаля! Теперь при входе в каждую функцию (в том числе в обработчики прерываний) будет выполняться проверка на переполнение стека. И если стек переполнился — будет ассерт.
Небольшие пояснения:
- Да, разумеется, нужно проверять на переполнение с некоторым запасом, иначе есть риск «перепрыгнуть» через начало стека.
- Image$$REGION_STACK$$RW$$Base — это особая магия получения инфы про области памяти с помощью констант, генерируемых линкером. Подробности (хотя не очень внятные местами) тут.
Идеально ли полученное решение? Конечно, нет.
Во-первых, эта проверка далеко не бесплатна, код от нее распухает процентов на 10. Ну и работать код будет медленнее (хотя я не измерял). Критично это или нет — решать вам; на мой взгляд, это разумная цена за безопасность.
Во-вторых, это, скорее всего, не будет работать при использовании прекомпилированных библиотек (но т.к. я их не использую вообще, я не проверял).
Зато это решение потенциально пригодно и для многопоточных программ, поскольку проверку мы делаем полностью сами. Но эту мысль я еще не додумал толком, поэтому пока придержу.
Подведем итоги
Получилось найти работающие решения для stm32 и для Миландра, хотя для последнего пришлось заплатить некоторым оверхедом.
Для меня же самым главным была небольшая смена парадигмы мышления. До вышеупомянутой статьи я вообще не задумывался, что от переполнения стека можно как-то защититься. Я не воспринимал это как проблему, которую нужно решить, а скорее как некое стихийное явление — иногда идет дождь, а иногда переполняется стек, ну, тут ничего не поделаешь, надо стиснуть зубы и потерпеть.
И я вообще достаточно часто замечаю за собой (да и за другими людьми) такое — вместо того, чтобы потратить 5 минут в гугле и найти тривиальное решение — живу со своими проблемами годами.
На этом у меня все. Я понимаю, что ничего кардинально нового я не открыл, но готовых статей с таким решением мне не попадалось (по крайней мере, сам Джозеф Ю в статье на эту тему прямым текстом это не предлагает). Надеюсь, в комментариях мне подскажут, прав я или нет, и каковы подводные камни такого подхода.
UPD: Если при добавлении scatter-файла Keil начинает выдавать непонятный warning аля «AppData\Local\Temp\p17af8-2(33): warning: #1-D: last line of file ends without a newline» — но сам этот файл не открывается, ибо он временный, — то просто добавьте перенос строки последним символом в scatter-файл.
