Анализ публикаций Lenta.ru за 18 лет (с сентября 1999 по декабрь 2017 гг.) средствами python, sklearn, scipy, XGBoost, pymorphy2, nltk, gensim, MongoDB, Keras и TensorFlow.

В исследовании использованы данные из поста «Анализируй это — Lenta.ru» пользователя ildarchegg. Автор любезно предоставил 3 гигабайта статей в удобном формате, и я решил, что это прекрасная возможность протестировать некоторые методы текстовой обработки. Заодно, если повезёт, узнать что-то новое о российской журналистике, обществе и вообще.
Содержание:
- MongoDB для импорта json в python
- Очистка и нормализация текста
- Облако тегов
- Тематическое моделирование на основе LDA
- Предсказание популярности: XGBClassifier, LogisticRegression, Embedding & LSTM
- Изучение объектов с помощью Word2Vec
MongoDB для импорта json в python
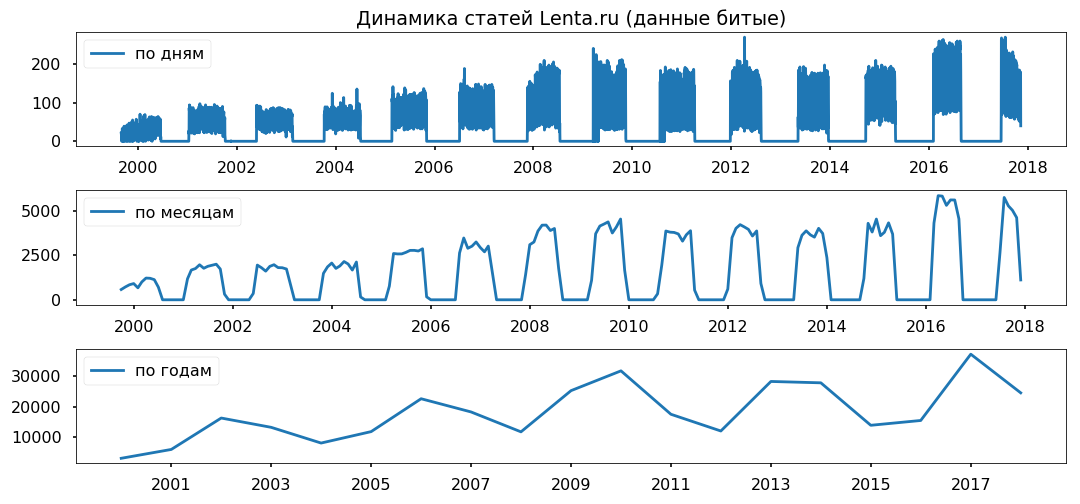
К сожалению, json с текстами оказался немного битый, для меня некритично, но python отказался работать с файлом. Поэтому сначала импортнул в MongoDB, а уж потом через MongoClient из библиотеки pymongo загрузил массив и пересохранил в csv по кускам.
Из замечаний: 1. запускать базу пришлось командой sudo service mongod start – есть и другие варианты, но они не сработали; 2. mongoimport – отдельное приложение, из монго-консоли не запускается, только из терминала.
Пропуски в данных равномерно распределены по годам. Период меньше года использовать не планирую, надеюсь, на корректности выводов скажется не сильно.
Очистка и нормализация текста
Перед непосредственным анализом массив нужно привести к стандартному виду: удалить специальные символы, перевести текст в нижний регистр (строковые методы pandas прекрасно справились), удалить стоп-слова (stopwords.words('russian') из nltk.corpus), вернуть словам нормальную форму с помощью лемматизации (pymorphy2.MorphAnalyzer).
Без огрехов не обошлось, например Дмитрий Песков превратился в «дмитрий» и «песок», но в целом результатом я остался доволен.
Облако тегов
В качестве затравки посмотрим, что из себя представляют публикации в самом общем виде. Выведем 50 наиболее частотных слов, которые употребляли журналисты Ленты с 1999 по 2017 год, в виде облака тегов.

«Риа новость» (самый популярный источник), «миллиард доллар» и «миллион доллар» (финансовая тематика), «настоящее время» (речевой оборот, свойственный всем новостным сайтам), «правоохранительный орган» и «уголовный дело» (криминальные новости), «премьер министр» и «владимир путин» (политика) – вполне ожидаемая стилистика и тематика для новостного портала.
Тематическое моделирование на основе LDA
Вычислим самые популярные темы для каждого года с помощью LDA из gensim. LDA (тематическое моделирование методом латентного размещения Дирихле) автоматически выявляет скрытые темы (набор слов, которые встречаются совместно и наиболее часто) по наблюдаемым частотам слов в статьях.
Краеугольным камнем отечественной журналистики оказались Россия, Путин, США.
В отдельные годы эта тематика разбавлялась Чеченской войной (с 1999 по 2000 гг.), 11-м сентября – в 2001 г., Ираком (с 2002 по 2004 гг.). С 2008 по 2009 года на первое место вышла экономика: процент, компания, доллар, рубль, миллиард, миллион. В 2011 г. часто писали о Каддафи.
С 2014 по 2017 гг. в России начались и продолжаются годы Украины. Пик пришёлся на 2015 г., потом тренд пошёл на спад, но всё ещё продолжает держаться на высоком уровне.

Интересно, конечно, но ничего такого, о чем бы я не знал или не догадывался.
Сменим немного подход – выделим топовые темы за всё время и посмотрим, как менялось их соотношение из года в год, то есть изучим эволюцию тем.
Самым интерпретируемым вариантом оказался Топ-5:
- Криминал (мужчина, полиция, произойти, задержать, полицейский);
- Политика (Россия, Украина, президент, США, глава);
- Культура (спиннер, гнойный, instagram, рамбнуть – да, вот такая у нас культура, хотя конкретно эта тема получилась довольно смешенной);
- Спорт (матч, команда, игра, клуб, спортсмен, чемпионат);
- Наука (учёный, космический, спутник, планета, клетка).
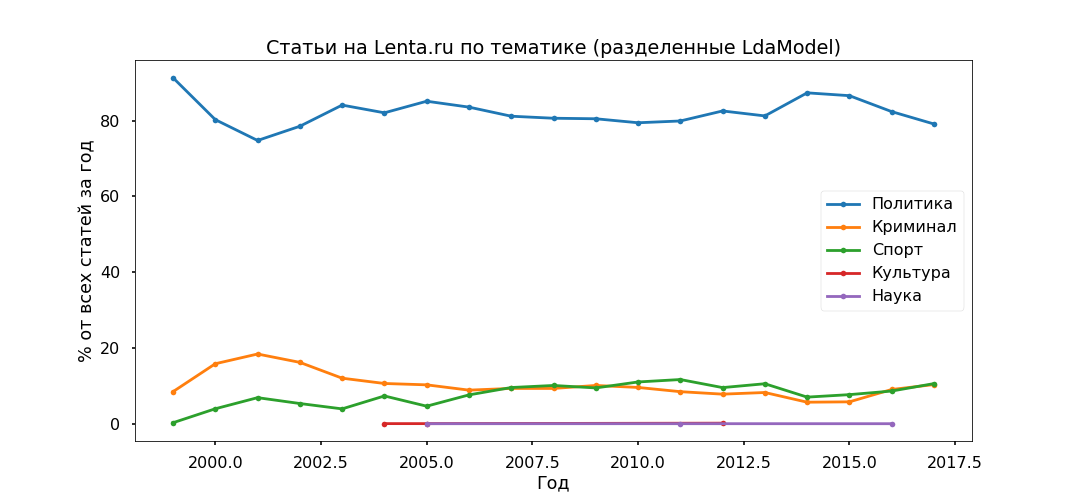
Далее возьмём каждую статью и посмотрим, с какой вероятностью она относится к той или иной теме, в результате все материалы будут поделены на пять групп.
Политика получилась самой популярной – под 80% всех публикаций. Однако пик популярности политических материалов пройден в 2014 г., сейчас их доля снижается, растёт вклад в информационную повестку Криминала и Спорта.
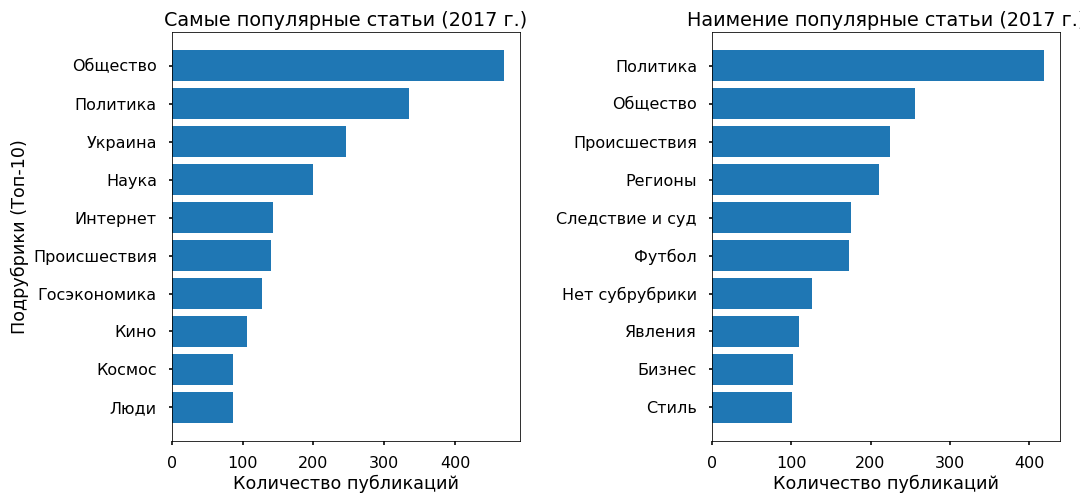
Проверим адекватность тематических моделей, используя подрубрики, которые указали редакторы. Топовые подрубрики удалось более-менее корректно выделить с 2013 года.
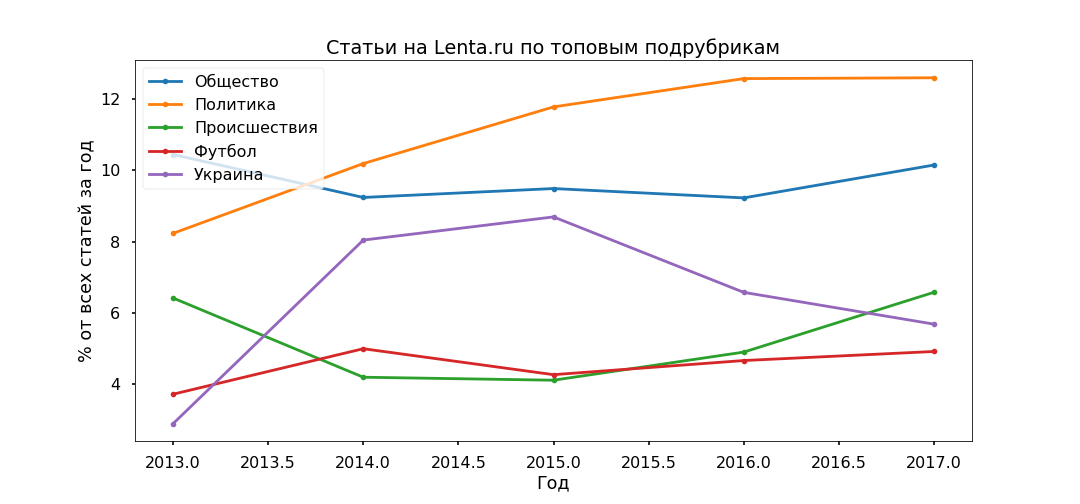
Особых противоречий не замечено: Политика стагнирует в 2017 г., Футбол и Происшествия растут, Украина по-прежнему в тренде, с пиком в 2015 г.
Предсказание популярности: XGBClassifier, LogisticRegression, Embedding & LSTM
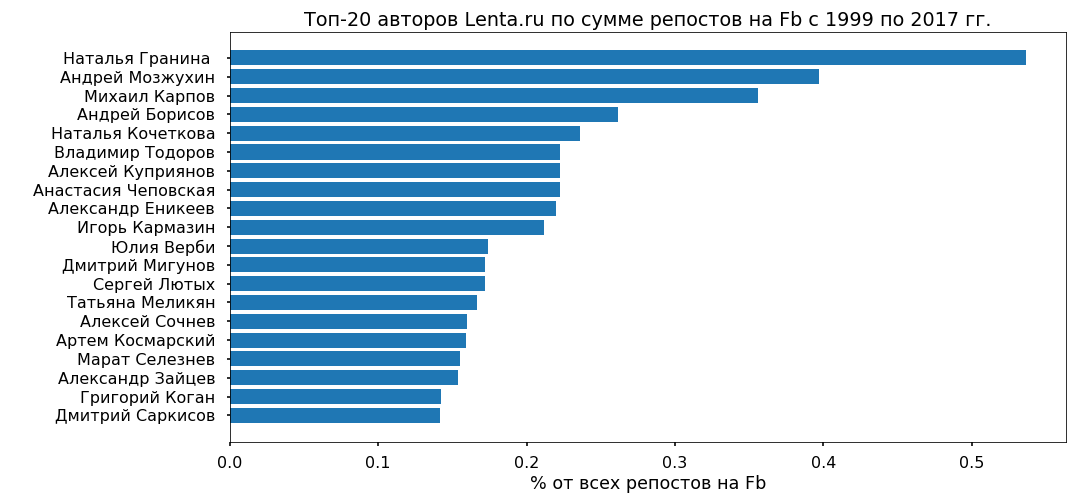
Попытаемся понять, можно ли по тексту предсказать популярность статьи на Ленте, и от чего эта популярность вообще зависит. В качестве целевой переменной я взял количество репостов на Фейсбук за 2017 год.
3 тыс. статей за 2017 г. репостов на Fb не имели – им присвоен класс «непопулярные», 3 тыс. материалов с самым большим количеством репостов получили метку «самые популярные».
Текст (6 тыс. публикаций за 2017 г.) был разбит на унограммы и биграммы (слова-токены, как одиночные, так и словосочетания из двух слов) и построена матрица, где колонками являются токены, рядами – статьи, а на пересечении – относительная частота вхождения слов в статьи. Использованы функции из sklearn – CountVectorizer и TfidfTransformer.
Подготовленные данные были поданы на вход XGBClassifier (классификатор на основе градиентного бустинга из библиотеки xgboost), который через 13 минут перебора гиперпараметров (GridSearchCV при cv=3) выдал точность на тесте 76%.

Потом я использовал обычную логистическую регрессию (sklearn.linear_model.LogisticRegression) и через 17 секунд получил точность в 81%.
В который раз убеждаюсь, для классификации текстов лучше всего подходят линейные методы, при условии тщательной подготовки данных.
Как дань моде немного потестил нейронные сети. Перевёл слова в числа с помощью one_hot из keras, привёл все статьи к одинаковой длине (функция pad_sequences из keras) и подал на вход LSTM (свёрточная нейронная сеть, using TensorFlow backend) через слой Embedding (чтобы сократить размерность и ускорить время обработки).
Сеть отработала за 2 минуту и показала точность на тесте 70%. Совсем не предел, но сильно заморачиваться в данном случае нет смысла.
Вообще, все методы выдали сравнительно небольшую точность. Как показывает опыт, алгоритмы классификации хорошо работают при разнообразии стилистики, – на авторских материалах, другими словами. На Lenta.ru такие материалы есть, но их очень мало – менее 2%.
Основной массив написан с использованием нейтральной новостной лексики. И популярность новостей определяет не сам текст и даже не тема как таковая, а их принадлежность к восходящему информационному тренду.
Например, довольно много популярных статей освещают события на Украине, наименее популярные данной темы почти не касаются.
Изучение объектов с помощью Word2Vec
В качестве завершения хотел провести сентимент-анализ – понять, как журналисты относятся к наиболее популярным объектам, которые они упоминают в своих статьях, меняется ли отношение со временем.
Но размеченных данных у меня нет, а поиск по семантическим тезаурусам вряд ли отработает корректно, так как новостная лексика довольно нейтральна, скупа на эмоции. Поэтому решил сосредоточиться на самом контексте, в котором объекты упоминаются.
В качестве теста взял Украину (2015 vs 2017) и Путина (2000 vs 2017). Выбрал статьи, в которых они упомянуты, перевёл текст в многомерное векторное пространство (Word2Vec из gensim.models) и спроецировал на двумерное с помощью метода Главных компонент.
После визуализации картинки получились эпические, размером не меньше гобелена из Байё. Вырезал нужные кластеры для упрощения восприятия, как смог, извините за «шакалы».


Что заметил.
Путин образца 2000 г. всегда появлялся в контексте с Россией и выступал с обращениями лично. В 2017 г. президент РФ превратился в лидера (чтобы это ни значило) и дистанцировался от страны, теперь он, если судить по контексту, – представитель Кремля, который общается с миром через своего пресс-секретаря.
Украина-2015 в российских СМИ – война, бои, взрывы; упоминается обезличено (Киев заявил, Киев начал). Украина-2017 фигурирует преимущественно в контексте переговоров между официальными лицами, и у этих лиц появились конкретные имена.
...
Заниматься интерпретацией полученной информации можно довольно долго, но, как мне думается, на данном ресурсе это оффтоп. Желающие могут посмотреть самостоятельно. Код и данные прилагаю.
