Эта статья о том, как применить принципы Domain-Driven Design (DDD) к классам, отображаемым Entity Framework Core (EF Core) на базу данных, и почему это может быть полезно.
В DDD-подходе есть множество преимуществ, но главное – DDD переносит код операций создания / изменения внутрь класса сущности. Это значительно понижает шансы неверного понимания / интерпретации разработчиком правил создания, инициализации и использования экземпляров классов.
Эрик в своих выступлениях упоминает репозитории. Я не рекомендую реализовывать репозиторий вместе с EF Core, потому что EF уже реализует паттерны «репозиторий» и «единица работы» сам по себе. Подробнее об этом я рассказываю в отдельно статье «стоит ли использовать репозиторий вместе с EF Core».
Я начну с того, что покажу код сущностей в DDD-стиле и затем сравню их с тем как обычно создают сущности с EF Core (прим. переводчика. автор называет словом «обычно» анемичную модель»). Для примера я буду использовать базу данных интернет-магазина по продаже книг (очень упрощенную версия Амазона». Структура БД показана на изображении ниже.
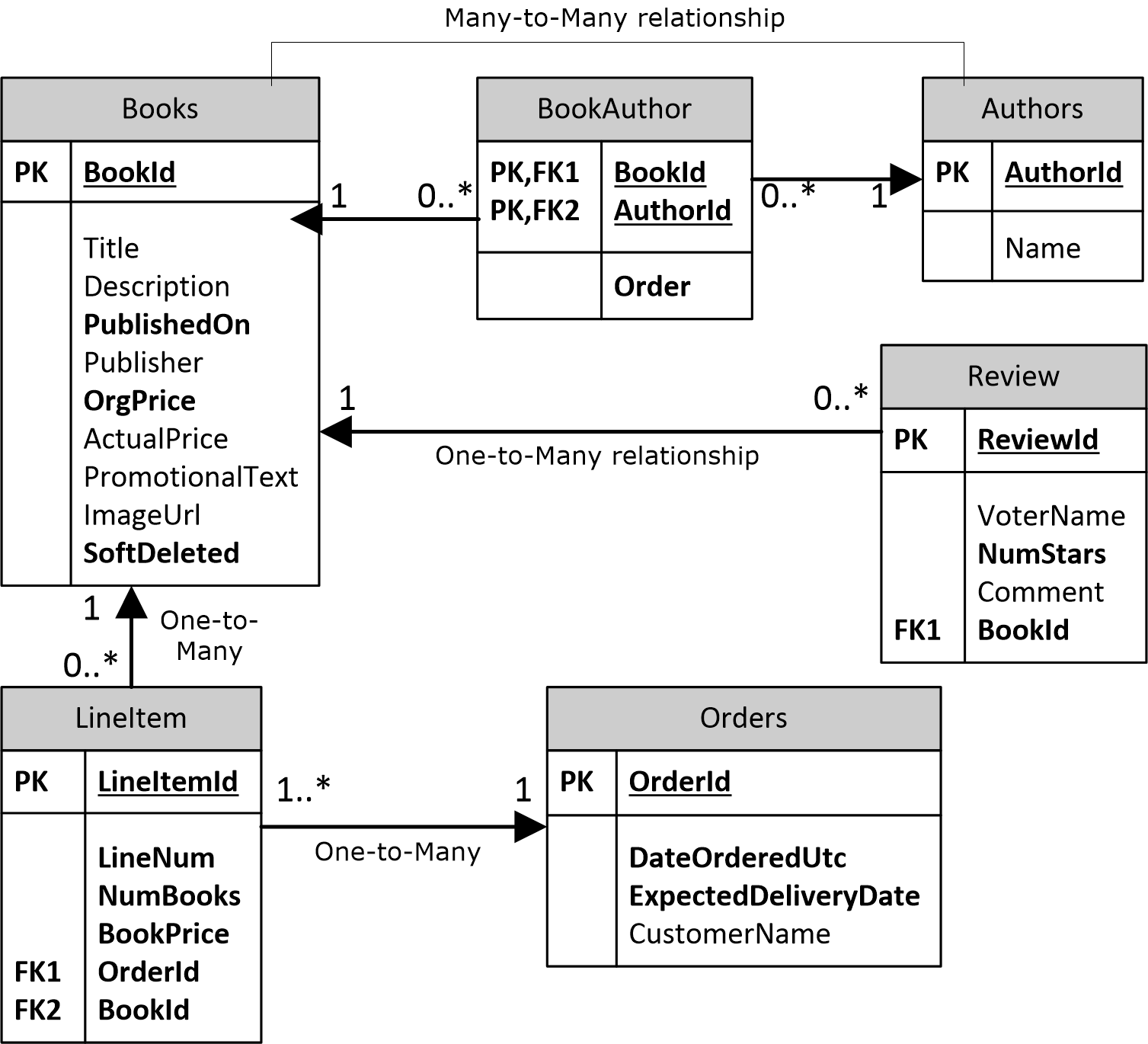
Первые четыре таблицы представляют все что касается книг: сами книги, их авторы, обзоры. Две таблицы внизу используются в коде бизнес-логике. Эта тема подробно раскрыта в отдельной статье.
На что обратить внимание:
Методы на строках 23-39 я буду далее называть «методы, предоставляющие доступ». Эти методы – единственный способ изменить свойства и связи внутри сущности. В сухом остатке класс Book «закрыт». Он создается через специальный конструктор и может быть изменен только частично через специальные методы с подходящими названиями. Такой подход создает резкий контраст со стандартным подходом к созданию / изменению сущностей в EF Core, в котором все сущности содержат пустой конструктор по-умолчанию и все свойства объявлены публичными. Следующий вопрос, почему первый подход лучше?
Сравним код получения данных о нескольких книгах из json и создания на их основе экземпляров классов Book.
Код конструктора класса Book
На что обратить внимание:
Как вы могли заметить, объем кода для создания сущности в обоих случаях примерно одинаков. Так почему же DDD-стиль лучше? Стиль DDD лучше тем, что:
Одним из главных преимуществ сущностей в стиле DDD Эрик Эванс называет следующее: «Они явно описывают правила доступа к объекту» (They communicate design decisions about object access).
Допустим, мы хотим сначала поработать с черновиком книги и лишь затем опубликовать. В момент создания черновика устанавливается ориентировочная дата публикации, которая весьма вероятно, будет изменена в процессе редактирования. Для хранения даты публикации будем использовать свойство PublishedOn.
В DDD-стиле setter свойства объявлен приватным, поэтому мы будем использовать специализированный метод доступа.
Эти два случая почти не отличаются. DDD-вариант даже немного длиннее. Но разница все-же есть. В DDD-стиле вы точно знаете, что дата публикации может быть изменена, потому что существует метод с очевидным названием. Вы также знаете, что вы не можете изменить издателя, потому что для свойства Publisher нет соответствующего метода для изменения. Эта информация будет полезна любому программисту, работающего с классом книги.
Другое требование — мы должны иметь возможность управлять скидками. Скидка состоит из новой цены и комментария, например «50% до конца этой недели!»
Реализация этого правила простая, но не слишком очевидная.
Правила довольно очевидны для того, кто их реализовывал. Однако для другого разработчика, скажем, разрабатывающего UI для добавления скидки. Добавление методов AddPromotion и RemovePromotion в класс сущности скрывает детали реализации. Теперь у другого разработчика есть публичные методы с соответствующими названиями. Семантика использования методов — очевидна.
Взглянем на реализацию методов AddPromotion и RemovePromotion.
На что обратить внимание:
Метод RemovePromotion гораздо проще: он не предполагает обработки ошибок. Поэтому возвращаемое значение просто void.
Эти два примера сильно отличаются друг от друга. В первом примере изменение свойства PublishOn на столько простое, что стандартная реализация вполне подходит. Во втором примере детали реализации не очевидны для того, кто не работал с классом Book. Во втором случае DDD-стиль со специализированными методами доступа скрывает детали реализации и делает жизнь других разработчиков проще. Также, во втором примере код содержит бизнес-логику. Пока объём логики небольшой мы можем хранить ее прямо в методах доступа и возвращать список ошибок, если метод используется не правильно.
DDD предлагает работать с агрегатом только через корень. В нашем случае свойство Reviews создает проблемы. Даже если setter будет объявлен приватным, разработчик все-равно может добавить или удалить объекты с помощью методов add и remove или даже вызвать метод clear, чтобы очистить коллекцию целиком. Здесь нам поможет новая функция EF Core — backing fields.
Backing field позволяет разработчику инкапсулировать настоящую коллекцию и предоставить публичный доступ к интерфейсной ссылке IEnumerable<T>. Интерфейс IEnumerable<T> не предоставляет методов add, remove или clear. В коде ниже пример использования backing fields.
Чтобы это сработало нужно рассказать EF Core что при чтении из бд нужно записывать в приватное поле, а не публичное свойство. Код конфигурации показан ниже.
Для работы с обзорами я добавил два метода: AddReview и RemoveReview классу книги. Метод AddReview более интересен. Вот его код:
На что обратить внимание:
Я спроектировал все мои методы доступа для обратил случая, когда загружена только корневая сущность. Как обновить агрегат остается на усмотрение методов. Возможно потребуется загрузка дополнительных сущностей.
Чтобы создавать сущности в DDD-стиле с EF Core необходимо придерживаться следующих правил:
Мне нравится критический подход к любому паттерну или архитектуре. Вот, что я думаю по поводу использования DDD-сущностей.
Действительно ли это стоит того в простых случаях, вроде обновления даты публикации книги?
Как вы могли заметить мне нравится DDD-подход. Однако, мне потребовалось какое-то время, чтобы правильно его структурировать, но на данный момент подход уже устаканился и я применяю его в проектах, над которыми работаю. Я уже успел попробовать этот стиль а небольших проектах и доволен, но все плюсы и минусы еще предстоит узнать, когда я применю его в больших проектах.
Мое решение разрешить использовать код, специфичный для EFCore в аргументах методов сущностей предметной модели было не простым. Я пытался не допустить этого, но в итоге пришел к тому, что вызывающему коду приходилось загружать множество навигационных свойств. И если этого не сделать, то изменение просто не будет применено без каких-либо ошибок (особенно в отношениях один-к-одному). Это было для меня не приемлемо, поэтому я разрешил использование EF Core внутри некоторых методов (но не конструкторов).
Другая плохая сторона в том, что DDD заставляет писать значительно больше кода для CRUD-операций. Я до сих пор не уверен, следует ли продолжать есть кактус и писать отдельные методы для всех свойств или же в некоторых случаях стоит отойти от столь радикального пуританства. Я знаю, что есть просто вагон и маленькая тележка скучного CRUD’а, который проще написать напрямую. Только работа над реальными проектам покажет, что лучше.
Статья итак получилось чересчур длинной, поэтому я собираюсь закончить здесь. Но, это значит, что есть еще много нераскрытого материла. О чем-то я уже писал, о чем-то я буду писать в ближайшем будущем. Вот, что осталось за бортом:
Весь код этой статьи доступен в репозитории GenericBizRunner на GitHub. Этот репозиторий содержит пример приложения ASP.NET Core со специализированными методами доступа для изменения класса Book. Вы можете клонировать репозиторий и запустить приложение локально. Оно использует in-memory Sqlite в качестве базы данных, так что должно запуститься на любой инфраструктуре.
Счастливой разработки!
TLDR
В DDD-подходе есть множество преимуществ, но главное – DDD переносит код операций создания / изменения внутрь класса сущности. Это значительно понижает шансы неверного понимания / интерпретации разработчиком правил создания, инициализации и использования экземпляров классов.
- В книге Эрика Эванса и его выступлениях не так много информации на этот счет:
- Предоставьте клиенту простую модель для получения постоянных объектов (классов) и управления их жизненным циклом.
- Ваши классы сущностей должны явно сообщать о том могут ли они быть изменены, как именно и по каким правилам.
- В DDD существует понятие агрегат. Агрегат – это дерево связанных сущностей. По правилам DDD работа с агрегатами должна осуществляться через «корень агрегации» (корневую сущность дерева).
Эрик в своих выступлениях упоминает репозитории. Я не рекомендую реализовывать репозиторий вместе с EF Core, потому что EF уже реализует паттерны «репозиторий» и «единица работы» сам по себе. Подробнее об этом я рассказываю в отдельно статье «стоит ли использовать репозиторий вместе с EF Core».
Сущности в DDD-стиле
Я начну с того, что покажу код сущностей в DDD-стиле и затем сравню их с тем как обычно создают сущности с EF Core (прим. переводчика. автор называет словом «обычно» анемичную модель»). Для примера я буду использовать базу данных интернет-магазина по продаже книг (очень упрощенную версия Амазона». Структура БД показана на изображении ниже.
Первые четыре таблицы представляют все что касается книг: сами книги, их авторы, обзоры. Две таблицы внизу используются в коде бизнес-логике. Эта тема подробно раскрыта в отдельной статье.
Весь код этой статьи выложен в репозиторий GenericBizRunner на GitHub. Кроме кода библиотеки GenericBizRunner там есть еще пример ASP.NET Core приложения, использующего GenericBizRunner для работы с бизнес-логикой. Больше об этом написано в статье «библиотека для работы с бизнес-логикой и Entity Framework Core».А вот и код сущностей, соответствующий структуре БД.
public class Book
{
public const int PromotionalTextLength = 200;
public int BookId { get; private set; }
//… all other properties have a private set
//These are the DDD aggregate propties: Reviews and AuthorLinks
public IEnumerable<Review> Reviews => _reviews?.ToList();
public IEnumerable<BookAuthor> AuthorsLink => _authorsLink?.ToList();
//private, parameterless constructor used by EF Core
private Book() { }
//public constructor available to developer to create a new book
public Book(string title, string description, DateTime publishedOn,
string publisher, decimal price, string imageUrl, ICollection<Author> authors)
{
//code left out
}
//now the methods to update the book’s properties
public void UpdatePublishedOn(DateTime newDate)…
public IGenericErrorHandler AddPromotion(decimal newPrice, string promotionalText)…
public void RemovePromotion()…
//now the methods to update the book’s aggregates
public void AddReview(int numStars, string comment, string voterName, DbContext context)…
public void RemoveReview(Review review)…
}
На что обратить внимание:
- Строка 5: set-доступ ко всем свойствам сущностей объявлен приватным. Это значит, что данные могут быть изменены либо с помощью конструктора, либо с помощью публичных методов, описанных ниже в этой статье.
- Строки 9 и 10. Связанные коллекции (те самые агрегаты из DDD) предоставляют публичный доступ к IEnumerable<T>, а не ICollection<T>. Это значит, что вы не сможете добавить или удалить элементы из коллекции напрямую. Вам придется использовать специализированные методы из класса Book.
- Строка 13. EF Core требует беспараметрический конструктор, но он может иметь приватный доступ. Это значит, что другой прикладной код, не сможет обойти инициализацию и создать экземпляры классов с помощью беспараметрического конструктора (прим. переводчика. Если вы конечно не создаете сущности исключительно с помощью reflection)
- Строки 16-20: единственный способ, с помощью которого вы сможете создать экземпляр класса Book – использовать публичный конструктор. Этот конструктор содержит всю необходимую информацию для инициализации объекта. Таким образом, объект гарантированно будет находиться в разрешенном (valid) состоянии.
- Строки 23-25: На этих строчках располагаются методы, позволяющие изменить состояние книги.
- Строки 28-29: Эти методы позволяют изменить связанные сущности (агрегаты)
Методы на строках 23-39 я буду далее называть «методы, предоставляющие доступ». Эти методы – единственный способ изменить свойства и связи внутри сущности. В сухом остатке класс Book «закрыт». Он создается через специальный конструктор и может быть изменен только частично через специальные методы с подходящими названиями. Такой подход создает резкий контраст со стандартным подходом к созданию / изменению сущностей в EF Core, в котором все сущности содержат пустой конструктор по-умолчанию и все свойства объявлены публичными. Следующий вопрос, почему первый подход лучше?
Сравнение создание сущности
Сравним код получения данных о нескольких книгах из json и создания на их основе экземпляров классов Book.
a. Стандартный подход
var price = (decimal) (bookInfoJson.saleInfoListPriceAmount ?? DefaultBookPrice)
var book = new Book
{
Title = bookInfoJson.title,
Description = bookInfoJson.description,
PublishedOn = DecodePubishDate(bookInfoJson.publishedDate),
Publisher = bookInfoJson.publisher,
OrgPrice = price,
ActualPrice = price,
ImageUrl = bookInfoJson.imageLinksThumbnail
};
byte i = 0;
book.AuthorsLink = new List<BookAuthor>();
foreach (var author in bookInfoJson.authors)
{
book.AuthorsLink.Add(new BookAuthor
{
Book = book, Author = authorDict[author], Order = i++
});
}
b. В DDD-стиле
var authors = bookInfoJson.authors.Select(x => authorDict[x]).ToList();
var book = new Book(bookInfoJson.title,
bookInfoJson.description,
DecodePubishDate(bookInfoJson.publishedDate),
bookInfoJson.publisher,
((decimal?)bookInfoJson.saleInfoListPriceAmount) ?? DefaultBookPrice,
bookInfoJson.imageLinksThumbnail,
authors);
Код конструктора класса Book
public Book(string title, string description, DateTime publishedOn,
string publisher, decimal price, string imageUrl,
ICollection<Author> authors)
{
if (string.IsNullOrWhiteSpace(title))
throw new ArgumentNullException(nameof(title));
Title = title;
Description = description;
PublishedOn = publishedOn;
Publisher = publisher;
ActualPrice = price;
OrgPrice = price;
ImageUrl = imageUrl;
_reviews = new HashSet<Review>();
if (authors == null || !authors.Any())
throw new ArgumentException(
"You must have at least one Author for a book", nameof(authors));
byte order = 0;
_authorsLink = new HashSet<BookAuthor>(
authors.Select(a => new BookAuthor(this, a, order++)));
}
На что обратить внимание:
- Строки 1-2: конструктор заставляет вас передать все необходимые для правильной инициализации данные.
- Строки 5, 6 и 17-9: код содержит несколько проверок бизнес-правил. В данном конкретном случае нарушение правил рассматривается как ошибка в коде, поэтому в случае нарушения будет выброшено исключение. Если бы пользователь мог исправить эти ошибки, возможно, я бы использовал статическую фабрику, возвращающую Status<T> (прим. переводчика. Я бы использовал Option<T> или Result<T>, как более широко-употребимое название). Status – это тип, возвращающий список ошибок.
- Строки 21-23: Связь BookAuthor создается в конструкторе. Конструктор BookAuthor может быть объявлен с уровнем доступа internal. Таким образом мы сможем предотвратить создание связей вне DAL.
Как вы могли заметить, объем кода для создания сущности в обоих случаях примерно одинаков. Так почему же DDD-стиль лучше? Стиль DDD лучше тем, что:
- Контролирует доступ. Случайное изменение свойства исключено. Любое изменение происходит через конструктор или публичный метод с соответствующим названием. Совершенно очевидно, что происходит.
- Соответствует DRY (don’t repeat yourself). Вам может потребоваться создавать экземпляры Book в нескольких местах. Код присвоения находится в конструкторе и вам не придется повторять его в нескольких местах.
- Скрывает сложность. В классе Book есть два свойства: ActualPrice и OrgPrice. Оба этих значения должны быть равны при создании новой книги. В стандартном подходе каждый разработчик должен знать об этом. В DDD-подходе достаточно, чтобы об этом знал разработчик класса Book. Остальные узнают об этом правиле, потому что оно явным образом записано в конструкторе.
- Скрывает создание агрегата. В стандартном подходе разработчик должен вручную создать экземпляр BookAuthor. В DDD-стиле эта сложность инкапсулирована для вызывающего кода.
- Позволяет свойствам иметь приватный доступ на запись
- Одна из причин использования DDD – «запереть» (lock down) сущности, т.е. не давать возможности изменять свойства напрямую. Давайте сравним операцию изменения с использованием DDD и без.
Сравнение изменения свойств
Одним из главных преимуществ сущностей в стиле DDD Эрик Эванс называет следующее: «Они явно описывают правила доступа к объекту» (They communicate design decisions about object access).
Прим. переводчика. Оригинальная фраза труднопереводима на русский язык. В данном случае design decisions – это принятые решения о том, как ПО должно работать. Имеется в виду, что решения обсуждались и подтверждены. Код с конструкторами, корректно инициализирующими сущности и методами с корректными названиями, отражающими смысл операций явным образом сообщает разработчику о том, что присвоения определенных значений сделаны с умыслом, а не по ошибке и не являются прихотью другого разработчика или деталями реализации.Я понимаю эту фразу следующим образом.
- Сделайте очевидным, как изменять данные внутри сущности и какие данные должны изменяться вместе.
- Сделайте очевидным когда вы не должны изменять определенные данные в сущности.
1. Изменение даты публикации
Допустим, мы хотим сначала поработать с черновиком книги и лишь затем опубликовать. В момент создания черновика устанавливается ориентировочная дата публикации, которая весьма вероятно, будет изменена в процессе редактирования. Для хранения даты публикации будем использовать свойство PublishedOn.
a. Сущность с публичными свойствами
var book = context.Find<Book>(dto.BookId);
book.PublishedOn = dto.PublishedOn;
context.SaveChanges();
b. Сущность в DDD-стиле
В DDD-стиле setter свойства объявлен приватным, поэтому мы будем использовать специализированный метод доступа.
var book = context.Find<Book>(dto.BookId);
book.UpdatePublishedOn( dto.PublishedOn);
context.SaveChanges();
Эти два случая почти не отличаются. DDD-вариант даже немного длиннее. Но разница все-же есть. В DDD-стиле вы точно знаете, что дата публикации может быть изменена, потому что существует метод с очевидным названием. Вы также знаете, что вы не можете изменить издателя, потому что для свойства Publisher нет соответствующего метода для изменения. Эта информация будет полезна любому программисту, работающего с классом книги.
2. Управление скидкой для книги
Другое требование — мы должны иметь возможность управлять скидками. Скидка состоит из новой цены и комментария, например «50% до конца этой недели!»
Реализация этого правила простая, но не слишком очевидная.
- Свойство OrgPrice — это цена без учета скидки.
- ActualPrice — текущая цена, по которой продается книга. Если скидка действует, то текущая цена будет отличаться от OrgPrice на размер скидки. Если нет, то значение свойств будет равно.
- Свойство PromotionText должно содержать текст скидки, если скидка применена или null, если в данный момент скидка не применяется.
Правила довольно очевидны для того, кто их реализовывал. Однако для другого разработчика, скажем, разрабатывающего UI для добавления скидки. Добавление методов AddPromotion и RemovePromotion в класс сущности скрывает детали реализации. Теперь у другого разработчика есть публичные методы с соответствующими названиями. Семантика использования методов — очевидна.
Взглянем на реализацию методов AddPromotion и RemovePromotion.
public IGenericErrorHandler AddPromotion(decimal newPrice, string promotionalText)
{
var status = new GenericErrorHandler();
if (string.IsNullOrWhiteSpace(promotionalText))
{
status.AddError(
"You must provide some text to go with the promotion.",
nameof(PromotionalText));
return status;
}
ActualPrice = newPrice;
PromotionalText = promotionalText;
return status;
}
На что обратить внимание:
- Строки 4 -10: добавление комментария PromotionalText обязательно. Метод проверяет, что текст не пустой. Т.к. Эту ошибку пользователь может исправить метод возвращает список ошибок для исправления.
- Строки 12, 13: метод устанавливает значения свойств в соответствие с реализацией, которую выбрал разработчик. Пользователю метода AddPromotion не обязательно знать их. Чтобы добавить скидку достаточно написать просто:
var book = context.Find<Book>(dto.BookId);
var status = book.AddPromotion(newPrice, promotionText);
if (!status.HasErrors)
context.SaveChanges();
return status;
Метод RemovePromotion гораздо проще: он не предполагает обработки ошибок. Поэтому возвращаемое значение просто void.
public void RemovePromotion()
{
ActualPrice = OrgPrice;
PromotionalText = null;
}
Эти два примера сильно отличаются друг от друга. В первом примере изменение свойства PublishOn на столько простое, что стандартная реализация вполне подходит. Во втором примере детали реализации не очевидны для того, кто не работал с классом Book. Во втором случае DDD-стиль со специализированными методами доступа скрывает детали реализации и делает жизнь других разработчиков проще. Также, во втором примере код содержит бизнес-логику. Пока объём логики небольшой мы можем хранить ее прямо в методах доступа и возвращать список ошибок, если метод используется не правильно.
3. Работа с агрегатом – свойство-коллекция Reviews
DDD предлагает работать с агрегатом только через корень. В нашем случае свойство Reviews создает проблемы. Даже если setter будет объявлен приватным, разработчик все-равно может добавить или удалить объекты с помощью методов add и remove или даже вызвать метод clear, чтобы очистить коллекцию целиком. Здесь нам поможет новая функция EF Core — backing fields.
Backing field позволяет разработчику инкапсулировать настоящую коллекцию и предоставить публичный доступ к интерфейсной ссылке IEnumerable<T>. Интерфейс IEnumerable<T> не предоставляет методов add, remove или clear. В коде ниже пример использования backing fields.
public class Book
{
private HashSet<Review> _reviews;
public IEnumerable<Review> Reviews => _reviews?.ToList();
//… rest of code not shown
}
Чтобы это сработало нужно рассказать EF Core что при чтении из бд нужно записывать в приватное поле, а не публичное свойство. Код конфигурации показан ниже.
protected override void OnModelCreating
(ModelBuilder modelBuilder)
{
modelBuilder.Entity<Book>()
.FindNavigation(nameof(Book.Reviews))
.SetPropertyAccessMode(PropertyAccessMode.Field);
//… other non-review configurations left out
}
Для работы с обзорами я добавил два метода: AddReview и RemoveReview классу книги. Метод AddReview более интересен. Вот его код:
public void AddReview(int numStars, string comment, string voterName,
DbContext context = null)
{
if (_reviews != null)
{
_reviews.Add(new Review(numStars, comment, voterName));
}
else if (context == null)
{
throw new ArgumentNullException(nameof(context),
"You must provide a context if the Reviews collection isn't valid.");
}
else if (context.Entry(this).IsKeySet)
{
context.Add(new Review(numStars, comment, voterName, BookId));
}
else
{
throw new InvalidOperationException("Could not add a new review.");
}
}
На что обратить внимание:
- Строки 4-7: я намеренно не инициализирую поле _reviews в приватном беспараметрическом конструкторе, который EF Core использует, когда загружает сущности из БД. Это позволяет моему коду определить была ли загружена коллекция с помощью метода .Include(p => p.Reviews). В публичном конструкторе я инициализирую поле, так что NRE при работе с созданной сущностью не произойдет.
- Строки 8-12: Если коллекция Reviews не была загружена код должен использовать DbContext для инициализации.
- Строки 13-16: Если книга была успешно создана и содержит ID, то я использую другую технику добавления обзора: просто устанавливаю foreign key в экземпляре класса Review и записываю в БД. Более подробно об этом написано в секции 3.4.5 моей книги.
- Строка 19: Если мы оказались здесь, то есть какая-то проблема с логикой кода. Поэтому я выбрасываю исключение.
Я спроектировал все мои методы доступа для обратил случая, когда загружена только корневая сущность. Как обновить агрегат остается на усмотрение методов. Возможно потребуется загрузка дополнительных сущностей.
Заключение
Чтобы создавать сущности в DDD-стиле с EF Core необходимо придерживаться следующих правил:
- Создавайте публичные конструкторы для создания корректно инициализированных экземпляров классов. Если в процессе создания могут произойти ошибки, которые пользователь может исправить, создавайте объект не с помощью публичного конструктора, а с помощью фабричного метода, возвращающего Status<T>, где T – тип создаваемой сущности
- Все свойства setter’ы свойств приватные. Т.е. все свойства – read-only за пределами класса.
- Для навигационных свойств коллекций объявляйте backing fields, а тип публичного свойства объявляйте IEnumerable<T>. Это не позволит другим разработчикам неконтролируемо изменять коллекции
- Вместо публичных setter’ов создавайте публичные методы для всех разрешенных операций изменения объекта. Эти методы должны возвращать void, если операция не может завершиться ошибкой, которую пользователь может исправить или Status<T> — если может.
- Рамки ответственности сущности имеет значение. Я думаю, что лучше всего ограничить сущности изменением самого класса и других классов внутри агрегата, но не за пределами. Правила валидации должны быть ограничены проверками правильности создания и изменения состояния сущностей. Т.е. я не проверяю такие бизнес-правила, как остатки на складе. Для этого существует специальный код бизнес-логики.
- Методы, изменяющие состояния должны предполагать, что загружен только корень агрегации. Если методу требуется загрузка других данных, он должен позаботиться об этом самостоятельно.
- Методы, изменяющие состояния должны предполагать, что загружен только корень агрегации. Если методу требуется загрузка других данных, он должен позаботиться об этом самостоятельно. Такой подход упрощает использование сущностей другими разработчиками.
Плюсы и минусы DDD-сущностей при работе с EF Core
Мне нравится критический подход к любому паттерну или архитектуре. Вот, что я думаю по поводу использования DDD-сущностей.
Плюсы
- Использование специализированных методов для изменения состояния – более чистый подход. Это точно хорошее решение, просто потому, что правильно-названные методы гораздо лучше раскрывают намерения кода и делают очевидным, что можно менять, а что нет. Кроме того методы могут вернуть список ошибок, если пользователь может их исправить.
- Изменение агрегатов только через корень тоже хорошо работает
- Детали реализации связи один-ко-многим между классами Book и Review теперь скрыты для пользователя. Инкапсуляция – это базовый принцип ООП.
- Использование специализированных конструкторов позволяет убедиться в том, что сущности созданы и гарантировано корректно инициализированы
- Перемещение кода инициализации в конструктор значительно снижает вероятность того, что разработчик не верно интерпретирует то, как класс должен быть инициализирован.
Минусы
- Мой подход содержит зависимости от реализации EF Core.
- Некоторые люди даже называют это анти-паттерном. Проблема в том, что теперь сущности предметной модели зависят от кода доступа к базе данных. В терминах DDD – это плохо. Я осознал, что если бы я не сделал этого, то мне бы пришлось полагаться на то, что вызывающий код знает о том, что должно быть загружено. Такой подход ломает принцип разделения ответственности (separation of concerns).
- DDD заставляет писать больше кода.
Действительно ли это стоит того в простых случаях, вроде обновления даты публикации книги?
Как вы могли заметить мне нравится DDD-подход. Однако, мне потребовалось какое-то время, чтобы правильно его структурировать, но на данный момент подход уже устаканился и я применяю его в проектах, над которыми работаю. Я уже успел попробовать этот стиль а небольших проектах и доволен, но все плюсы и минусы еще предстоит узнать, когда я применю его в больших проектах.
Мое решение разрешить использовать код, специфичный для EFCore в аргументах методов сущностей предметной модели было не простым. Я пытался не допустить этого, но в итоге пришел к тому, что вызывающему коду приходилось загружать множество навигационных свойств. И если этого не сделать, то изменение просто не будет применено без каких-либо ошибок (особенно в отношениях один-к-одному). Это было для меня не приемлемо, поэтому я разрешил использование EF Core внутри некоторых методов (но не конструкторов).
Другая плохая сторона в том, что DDD заставляет писать значительно больше кода для CRUD-операций. Я до сих пор не уверен, следует ли продолжать есть кактус и писать отдельные методы для всех свойств или же в некоторых случаях стоит отойти от столь радикального пуританства. Я знаю, что есть просто вагон и маленькая тележка скучного CRUD’а, который проще написать напрямую. Только работа над реальными проектам покажет, что лучше.
Другие аспекты DDD, не раскрытые в этой статье
Статья итак получилось чересчур длинной, поэтому я собираюсь закончить здесь. Но, это значит, что есть еще много нераскрытого материла. О чем-то я уже писал, о чем-то я буду писать в ближайшем будущем. Вот, что осталось за бортом:
- Бизнес-логика и DDD. Я использую концепции DDD в коде бизнес-логики уже несколько лет и с использованием новых возможностей EF Core ожидаю, что смогу перенести часть логики в код сущностей. Прочитайте статью «Снова об архитектуре слоя бизнес-логики с Entity Framework (Core и v6)»
- DDD и паттерн «репозиторий». Эрик Эванс рекомендует использовать репозиторий для того, чтобы абстрагировать доступ к данным. Я пришел к выводу, что использование паттерна «репозиторий» вместе с EF Core – плохая затея. Почему? Читайте в той-же самой статье.
- Несколько DBContext’ов / ограниченных контекстов (bounded contexts). Я долго думал о разделении базы данных на несколько DbContext’ов. Например, создать отдельный BookContext для работы только с классом Book и его агрегатом и еще один отдельный OrderContext, для обработки заказов. Думаю, идея «ограниченных контекстов» очень важна, особенно масштабирования приложений по мере роста. Пока я еще не выделили паттерна для этой задачи, но ожидаю написать статью на эту тему в будущем.
Весь код этой статьи доступен в репозитории GenericBizRunner на GitHub. Этот репозиторий содержит пример приложения ASP.NET Core со специализированными методами доступа для изменения класса Book. Вы можете клонировать репозиторий и запустить приложение локально. Оно использует in-memory Sqlite в качестве базы данных, так что должно запуститься на любой инфраструктуре.
Счастливой разработки!
