
IT technologies evolution allowed to control huge data flows. Business has a lot of IT solutions: CRM, ERP, BPM, accounting systems or at least just Excel and Word. Companies are different too. Some of companies are composed of plenty branches. Let’s name such as “Pyramid”. Pyramids have data synchronization issue for pile of IT systems. Software vendors and versions differ for branches significantly. In addition management company continuously modify reporting requirements that causes frustration assaults in the branches. This is a story about the project I happened to encounter chaos that needed to be systematized and automated. Low budget and tight deadlines limited the use of most existing industrial solutions but opened up scope for creativity.
General-purpose format
The customer company set a task to collect reports data from all branches. Let me explain the scale of the challenge — there are dozens of systems, including both: self-made and monsters such as SAP.
One report could contain data from: accountants, repairmen, PR managers, EMERCOM, meteorologists.
Before the project started, major part of the data was sent via email to the head company as Word / Excel attachments. Onward it looked like sunset made manually: the data was manually processed by specially studied staff and put into a couple of systems. In a end there were dozens of reports which formed the basis of management decisions.
Approach choice was prompted by used files formats — xlsx/docx. Even the legacy software supports data uploading to these formats. At least copy-paste can be a last stand for branches.
So our opinionated plan was:
- Describe the structure and schedule of each report.
- Provide branches with reports regulations. Branches should use existing software to send reports via emails. If there are no software — send reports manually as before.
- Develop the system, that:
- takes the right documents from email inbox;
- extracts data from documents;
- writes extracted data to DB, and penalize violators of regulations.
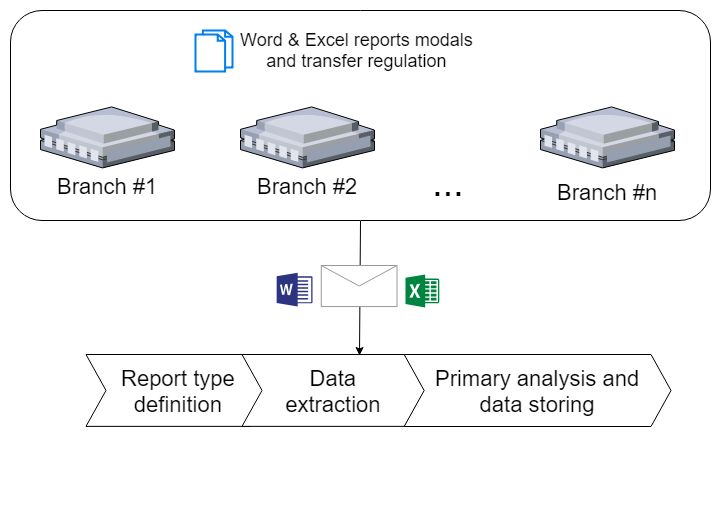
Implementation
Non-development issues
During requirements collection stage it turned out that there are no description of reports structure. Nothing at all. Report structure was stored in the heads of some employees and transferred verbally as folk tales. That issue was solved with some efforts, but the real challenge started later on setting up data exchange stage.
First issue
In couple of days after beta version release we revealed gap between the documents structure and document model. Bad data quality: reports had divergences in amounts, columns were mixed up or had an incorrect naming. These issues mainly happened in the branches where data was collected and sent manually.
Solution — implementation of three-step verification:
- Providing branches with xlsx samples that have structure fixed by Excel tools. Only cells available in these samples were data input. Some cells take additional verification: type, a convergence of sums, etc.
- Data verification while extracting. For example comparing the current date and date in the Word paragraph, data arithmetic verification for Excel documents (if it’s not possible to be set by xlsx tools).
- Deep data analysis after extraction. For example significant deviations detection by key indicators in comparison with previous periods.
Second issue
A systematic violation of the data transfer schedule or unscrupulous sabotage attempts: «We never send any data to anyone, and here you are with your this …», «I sent everything! On time! Probably you didn’t get it because of bad latency».
Feedback became a solution. The software automatically notifies responsible persons in the branch in case of schedule violation.
Some time later the feedback module was wired up to data quality checking module and final reports generating module. This way branch immediately receive a summary of own data and a comparison to the “neighbor branches”. So it would be clear for a branch, why it got reprimanded.
Developed modules
Report templates configuration tool, that describes:
- attributes to identify a report;
- transmission regulations;
- data extraction algorithm;
- other attributes such as the path to the code that validate and stores the data.
An email application that moves attachments to an isolated storage (sandbox) and stores letter associated information;
An attachment parser that identifies report and extracts data.
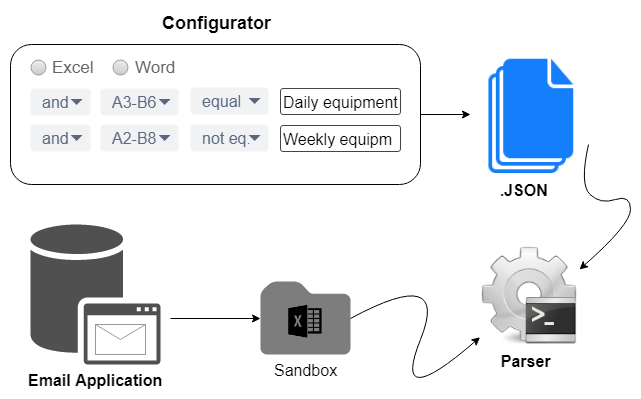
Configuration tool
Historically, letters with reports send to the common email address as well as many other important or unimportant letters. That’s why we needed attributes to identify types of report attachments. Use of certain document name or text in email body are unreliable and uncomfortable for the sender. That’s why we decided that report identification will be determined only by a content.
Brainstorming resulted in a bunch of attributes to identify the report type by content: cell text color, font, etc. But the most proper way is a substring presence in a certain cell — “slot”, or in an array of cells for Excel. For Word we used paragraph or title.
We added simple comparison logic for the “slot”: “equal”, “unequal”, “more”, “less”, and so on. Example for Excel report: in the range of A2-E4, the cell text should be equal to “Daily equipment loading report”.
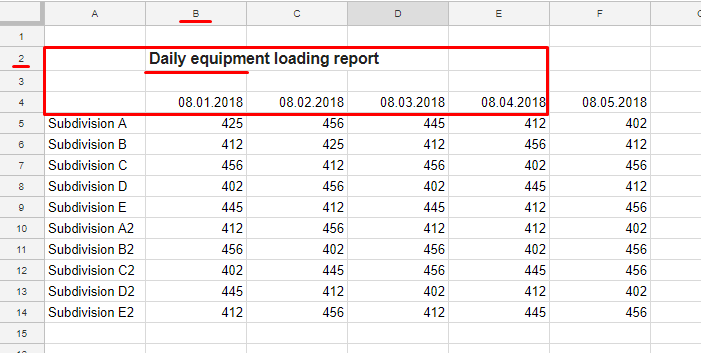
A similar way we configured search area for the beginning and the end of the data.
Below is an example of search condition for the data ending: “2 blank lines in a row”.

Some other settings: a list of allowed senders, a document type (Excel / Word), a path for data exporting.
The output is JSON structure (template) that describes the report.
Email application
This application is email inbox reader that puts all attachments to sandbox, saves email attributes, set attachments to parsing queue.
We faced where 2 security issues:
- what if branch name in report accidentally (or not) substituted with another branch name?
- what if report is sent by intruders?
The first issue is solved by checking the email address of the branch-sender and the branch name specified in the report body.
The second issue is solved using SPF.
Attachment parser
Almost all Word and Excel parsing libraries support only certain versions/extensions. That’s why we decided to use “Libre Office” conversion to bring files to a single format. For example inputs: odt, doc, docx (2007, 2010, 2013) … convert to docx (2016).
After conversion:
- we filter out an array of report templates based on the basic attributes like is it Word or Excel, sender belongs to allowed list;
- threat the report with the remaining templates;
- if a report matched template — extract data and transfer it to the repository.
Resume
We made it!
After two months of painstaking work, the head office started to receive data for reports from all branches on regular basis.
Data quality and completeness become unprecedented better from what it was before. Implemented software has released human resources that paid back the project costs by the end of the year.
For ourselves, we learned that integration process is not always painful and have identified the main aspects of success:
- we didn’t get inside systems in the branches;
- we formalized and approved a unified reporting structure and transfer schedule;
- we made output samples for each report type with built-in verification;
- we used the most common way to deliver data — an email.
As a last word, this approach has two main drawbacks:
- low data delivery speed;
- data package size shouldn’t be larger, than average email attachment.
