Чтобы понять рекурсию, сначала надо понять рекурсию. Возможно, поэтому рекурсивные запросы применяют так редко. Наверняка вы представляете что такое SQL-запрос, я расскажу, чем рекурсивные запросы отличаются от обычных. Тема получилась объемная, приготовьтесь к долгому чтению. В основном речь пойдет об Oracle, но упоминаются и другие СУБД.
Суть проблемы
Большинство современных СУБД (Система Управления Базами Данных) — реляционные, т.е. представляют данные в виде двумерной таблицы, в которой есть строки (записи) и столбцы (поля записей). Но на практике мы часто сталкиваемся с иной организацией данных, а именно иерархической.
Взгляните на список файлов на вашем компьютере: все они организованы в виде дерева. Аналогично можно представить книги в библиотеке: Библиотека->Зал->Шкаф->Полка->Книга. То же самое и статьи на сайте: Сайт->Раздел->Подраздел->Статья. Примеры можно приводить долго. Впрочем, тут еще можно разделить все на отдельные таблицы: таблица для хранения списка библиотек, другая таблица для списка залов, третья для шкафов и т.д. Но если заранее не известна глубина вложенности или эта вложенность может меняться, тут уж от иерархии никак не отмашешься.
Проблема в том, что данные, имеющие иерархическую структуру, очень плохо представляются в реляционной модели. В стандарте SQL-92 нет средств для их обработки.
Зато такие средства появились в стандарте SQL-1999. Правда к тому времени в Oracle уже был собственный оператор CONNECT BY. Несмотря на это, в SQL-1999 синтаксис рекурсивных запросов совершенно не похож на синтаксис CONNECT BY в Oracle и использует ключевое слово WITH. Реализация же рекурсивных запросов в других СУБД несколько запоздала, так в MS SQL Server она появилась лишь в версии 2005.
Так же как и в синтаксисе, есть отличия и в терминологии. В Oracle обычно обсуждаемые запросы называются “иерархические”, у всех остальных “рекурсивные”. Суть от этого не меняется, я буду использовать и то и другое.
От слов к делу!
Для демонстрации будем использовать структуру каталогов, нам потребуется тестовая таблица, состоящая из 3-х полей:
id – идентификатор,
pid – идентификатор родителя (ссылается на id другой записи в той же таблице),
title – название каталога (вместо него может быть что угодно, даже несколько полей или ссылок к другим таблицам).
create table test_table (
id int,
pid int,
title varchar(256)
);Здесь я использовал синтаксис mySQL, в других СУБД он несколько отличается. Так, в Oracle используются другие типы данных: вместо int — number, а вместо varchar — varchar2.
Заполнить табличку тестовыми данными не составит труда. Предлагаю записать список серверов, расположенных на территории различных предприятий в разных городах. Таким образом, в единой таблице оказываются и страны, и города, и фирмы, и сервера.
insert into test_table values (1, null, 'Россия');Думаю, остальные строки заполнить не составит сложностей. Получается почти как на картинке, только не в том порядке. Я специально заполнял не по-порядку, чтобы простым SELECT * FROM test_table получалось не иерархическая структура:
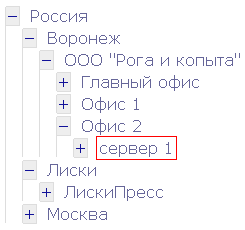
ID PID TITLE ---- ---------- -------------------- 1 Россия 2 1 Воронеж 3 2 ООО "Рога и копыта" 4 1 Москва 5 1 Лиски 6 3 Главный офис 7 3 Офис 1 8 3 Офис 2 9 8 Сервер 1 10 5 ЛискиПресс
Тестовые данные готовы. Приступим к выборкам.
mySQL
Вынужден огорчить пользователей mySQL – в этой СУБД придется рекурсию организовывать внешними по отношению к СУБД средствами, например на php (код приводить не буду, его публиковали не раз, например здесь, достаточно поискать по запросу “mySQL tree” и т.п.).
Впрочем, есть иной подход, заключающийся в создании левой и правой границы для каждого узла, предложенный Джо Селко. Тогда можно будет обойтись обычными, не рекурсивными запросами.
Как-то я выводил дерево объектов в действующем проекте на php. База данных была на mySQL. Поплевавшись на отсутствие удобных операторов, я решил тогда не отображать все дерево целиком, а показать пользователю только первый уровень (схлопнутое дерево). При клике по плюсику в узле дерева отображались дочерние узлы для выбранного объекта, при этом они подгружались через AJAX. Выборка дочерних узлов по известному pid происходит быстро, поэтому интерфейс получился вполне шустрым. Возможно, это не лучшее решение, но оно имеет право на жизнь.
SQL-1999
В отличие от предыдущего стандарта SQL-92, в названии следующего решили отобразить номер тысячелетия, чтобы он не страдал от проблемы двухтысячного года. Помимо этого :-), появились новые типы данных (LOB), новые предикаты SIMILAR и DISTINCT, точки сохранения транзакций, объекты и их методы, и многое другое. Среди нововведений появились также рекурсивные запросы, о которых мы сейчас и поговорим.
Для получения иерархических данных используется временное представление, которое описывается оператором WITH. После этого из нее выбираются данные простым селектом. В общем виде синтаксис примерно такой:
WITH [recursive] имя_алиаса_запроса [ (список столбцов) ] AS (запрос) основной запрос
В MS SQL нет ключевого слова RECURSIVE, его следует опустить. Но в остальном все то же самое. Такой синтаксис поддерживается в DB2, Sybase iAnywhere, MS SQL, начиная с версии 2005, и во всех базах данных, которые поддерживают стандарт SQL 1999.
Тогда для получения нашего дерева запрос получится такой:
WITH RECURSIVE
Rec (id, pid, title)
AS (
SELECT id, pid, title FROM test_table
UNION ALL
SELECT Rec.id, Rec.pid, Rec.title
FROM Rec, test_table
WHERE Rec.id = test_table.pid
)
SELECT * FROM Rec
WHERE pid is null;Здесь используется рекурсивная таблица Rec, которую мы сами придумали, построив ее по исходной таблице test_table. В описании Rec указано правило, каким образом соединять: WHERE Rec.id = test_table.pid. А в главном запросе отметили, что начинать надо с записи, у которой pid является пустым, т.е. с корневой записи.
Честно говоря, я никогда не работал в MS SQL Server 2005 или другой СУБД, использующей такой синтаксис. Поэтому написал этот запрос чисто из теоретических соображений. Для общности картины, чтобы было с чем сравнить.
В MS SQL 2008 можно применить более новое средство hierarchyid. Спасибо XaocCPS за его описание.
Oracle
Наконец-то мы добрались до Oracle! Об этой СУБД я хотел бы рассказать поподробнее. В Oracle иерархические запросы появились в 8-ой версии, задолго до появления стандарта. Поэтому до сих пор используется совсем другой синтаксис. Лично мне он кажется более понятным и напоминающим обычные функциональные языки. Хотя, скорее всего, это дело привычки.
Описание синтаксиса в документации напоминает бусы: на единую нить запроса нанизываются нужные операторы. Никому не приходило в голову сделать украшение для гички?

Тут видно, что единственно важное условие для построения иерархического запроса – это оператор CONNECT BY, остальное “нанизывается” по мере надобности.
Необязательный оператор START WITH говорит Ораклу с чего начинать цикл, т.е. какая строка (или строки) будет корневой. Условие может быть практически любым, можно даже использовать функции или внутренние запросы: pid is null, или id = 1, или даже substr(title, 1, 1) = ‘Р’.
Условие после CONNECT BY нужно указать обязательно. Тут надо сказать Ораклу, как долго продолжать цикл. Что-то в духе while в обычных языках программирования. Например, мы можем попросить достать нам 10 строк: rownum<=10 – он и нафигачит нам в цикле ровно 10 одинаковых строк. Почему одинаковых? Да потому что мы указали какую строку выбрать первой, а как найти следующую нет – вот он и выдает 1-ую строку нужное количество раз. Кстати сказать, rownum это псевдостолбец, в котором нумеруются строки, начиная от 1 в порядке их выдачи. Его можно использовать не только в иерархических запросах. Но это уже другая история.
Как же получить нормальную иерархию? Нужно использовать специальный оператор, который называется PRIOR. Это обычный унарный оператор, точно такой же как + или -. “Позвоните родителям” – говорит он, заставляя Оракл обратиться к предыдущей записи. С его помощью можно написать правило pid = PRIOR id (или PRIOR id = pid, как говорится, от перестановки мест…).
Что получается? Оракл находит первую запись, удовлетворяющую условию в START WITH, и принимается искать следующую. При этом к той первой записи можно обратиться через PRIOR. Если мы все сделали правильно, то Оракл будет искать записи, в которых в поле для хранения информации о родителе (pid) будет содержаться значение, равное идентификатору id нашей первой записи. Таким образом будут найдены все потомки корневой записи. А так как процесс рекурсивный, аналогичный поиск будет продолжаться с каждой найденной строкой, пока не отыщутся все потомки.
Теперь у нас есть все необходимое, чтобы написать иерархический запрос в Oracle. Но прежде чем мы его напишем, расскажу еще об одной штуке. Порядок строк это хорошо, но нам было бы трудно понять, две строки рядом это родитель и его потомок или два брата-потомка одного родителя. Пришлось бы сверять id и pid. К счастью, Oracle предлагает в помощь дополнительный псевдостолбец LEVEL. Как легко догадаться, в нем записывается уровень записи по отношению к корневой. Так, 1-ая запись будет иметь уровень 1, ее потомки уровень 2, потомки потомков — 3 и т.д.
SELECT level, id, pid, title
FROM test_table
START WITH pid is null
CONNECT BY PRIOR id = pid;
LEVEL ID PID TITLE
------ ---------- ---------- -------------------
1 1 Россия
2 2 1 Воронеж
3 3 2 ООО "Рога и копыта"
4 6 3 Главный офис
4 7 3 Офис 1
4 8 3 Офис 2
5 9 8 Сервер 1
2 4 1 Москва
2 5 1 Лиски
3 10 5 ЛискиПресс
Неплохо. Все дочерние строки оказываются под своими родителями. Сортировку бы еще добавить, чтобы записи одного уровня выводились не абы-как, а по алфавиту. Ну чтож, сортировка это просто: добавим в конец запроса конструкцию ORDER BY title.
SELECT level, id, pid, title
FROM test_table
START WITH pid is null
CONNECT BY PRIOR id = pid
ORDER BY title;
LEVEL ID PID TITLE
------ ---------- ---------- -------------------
2 2 1 Воронеж
4 6 3 Главный офис
2 5 1 Лиски
3 10 5 ЛискиПресс
2 4 1 Москва
3 3 2 ООО "Рога и копыта"
4 7 3 Офис 1
4 8 3 Офис 2
1 1 Россия
5 9 8 Сервер 1
О, нет! Вся иерархия поломалась. Что же получилось? Оракл честно выбрал нужные строки в порядке иерархии (об этом говорит правильная расстановка level), а затем пересортировал их согласно правилу ORDER BY. Чтобы указать Ораклу, что сортировать надо только в пределах одного уровня иерархии, нам поможет маленькая добавка в виде оператора SIBLINGS. Достаточно изменить условие сортировки на ORDER SIBLINGS BY title – и все встанет на свои места.
Кстати, возможно все еще не понятно, почему этот порядок строк является деревом. Можно убрать все “лишние” поля и добавить отступы, станет более наглядно:
SELECT lpad(' ', 3*level)||title as Tree
FROM test_table
START WITH pid is null
CONNECT BY PRIOR id = pid
ORDER SIBLINGS BY title;
TREE
-----------------------------
Россия
Воронеж
ООО "Рога и копыта"
Главный офис
Офис 1
Офис 2
Сервер 1
Лиски
ЛискиПресс
Москва
Ну вот, теперь все в точности, как на картинке в самом начале статьи.
Помните, файловые менеджеры обычно пишут путь к каталогу, в котором вы находитесь: /home/maovrn/documents/ и т.п.? Неплохо было бы и нам сделать так же. А сделать это можно абсолютно не напрягаясь: специалисты из Oracle все уже сделали за нас. Просто берем и используем функцию SYS_CONNECT_BY_PATH(). Она принимает два параметра через запятую: название колонки и строку с символом-разделителем. Будем не оригинальны, напишем так: SYS_CONNECT_BY_PATH(title, ‘/’).
Заодно ограничим вывод, выбрав только одну строку. Для этого, как всегда, нужно добавить условие WHERE. Даже в иерархическом запросе ограничивающее условие применяется ко всем строкам. Вставить его надо до иерархической конструкции, сразу после FROM. Для примера определим путь до “Сервер 1”, который у нас записан с id=9:
SELECT SYS_CONNECT_BY_PATH(title, '/') as Path
FROM test_table
WHERE id=9
START WITH pid is null
CONNECT BY PRIOR id = pid;PATH ---------------------------------------------------- /Россия/Воронеж/ООО "Рога и копыта"/Офис 2/Сервер 1
Еще может быть полезен псевдостолбец CONNECT_BY_ISLEAF. Его можно использовать так же, как LEVEL. В этом псевдостолбце напротив каждой строки проставляется 0 или 1. Если есть потомки – проставится 0. Если потомков нет, такой узел в дереве называется “листом”, тогда и значение в поле CONNECT_BY_ISLEAF будет равно 1.
Устали? Осталось немного, самое страшное уже позади. Раньше мы использовали оператор PRIOR, который ссылался к родительской записи. Помимо него есть другой унарный оператор CONNECT_BY_ROOT, который ссылается (ни за что не догадаетесь!) на корневую запись, т.е. на самую первую в выборке.
SELECT id, pid, title, level,
CONNECT_BY_ISLEAF as IsLeaf,
PRIOR title as Parent,
CONNECT_BY_ROOT title as Root
FROM test_table
START WITH pid is null
CONNECT BY PRIOR id = pid
ORDER SIBLINGS BY title;ID PID TITLE LEVEL LEAF PARENT ROOT -- --- -------------------- ----- ---- -------------------- ------ 1 Россия 1 0 Россия 2 1 Воронеж 2 0 Россия Россия 3 2 ООО "Рога и копыта" 3 0 Воронеж Россия 6 3 Главный офис 4 1 ООО "Рога и копыта" Россия 7 3 Офис 1 4 1 ООО "Рога и копыта" Россия 8 3 Офис 2 4 0 ООО "Рога и копыта" Россия 9 8 Сервер 1 5 1 Офис 2 Россия 5 1 Лиски 2 0 Россия Россия 10 5 ЛискиПресс 3 1 Лиски Россия 4 1 Москва 2 1 Россия Россия
Стоит отметить, что если в результате выполнения запроса обнаружится петля, Oracle выдаст ошибку. К счастью, ее можно обойти, хотя если в данных содержатся петли – это явно ошибка, в деревьях не бывает петель. На картинке с “бусами” запроса был нарисован оператор NOCYCLE после CONNECT BY – его мы и будем применять. Теперь запрос не будет вылетать. А чтобы определить “больной” участок, воспользуемся псевдостолбцом CONNECT_BY_ISCYCLE – в нем во всех хороших строках будет записано 0, а в тех, которые приводят к петлям, волшебным образом окажется 1.
Чтобы проиллюстрировать это, придется немного подпортить данные. ЛискиПресс ссылается у нас на город Лиски; изменим запись Лиски, чтобы она ссылалась на ЛискиПресс (не забудьте про commit – я вечно забываю):
update test_table set pid=10 where id=5;Если мы запустим какой-нибудь из предыдущих запросов, увидим, что и Лиски, и ЛискиПресс выпали из выборки, будто их нет совсем. Бегая в цикле, Оракл просто перестал на них натыкаться, т.к. нет пути от записи Россия к городу Лиски. Изменим условия START WITH, чтобы начинать с города Лиски – появится ошибка. Умный Оракл видит что запись уже выбиралась ранее и отказывается бегать в бесконечном цикле. Исправляем ошибку:
SELECT CONNECT_BY_ISCYCLE as cycl, id, pid, title
FROM test_table
START WITH id=5
CONNECT BY NOCYCLE PRIOR id = pid;CYCL ID PID TITLE ---- ---------- ---------- ---------- 0 5 10 Лиски 1 10 5 ЛискиПресс
Практические примеры
Иерархические запросы можно применять не только там, где есть явная иерархия.
Например, рассмотрим задачу получения списка пропущенных номеров из последовательности. Это бывает нужно, когда в некоей таблице id генерируется автоматически путем увеличения на 1, но часть записей были удалены. Нужно получить список удаленных номеров. По хорошей традиции, это следует сделать одним селектом.
Подготовим тестовые данные. Удалим из нашей таблицы пару записей:
DELETE FROM test_table WHERE id IN (3, 5);С чего начнем? Во-первых, неплохо было бы получить список номеров подряд от 1 до максимального значения в нашей таблице, чтобы было с чем сравнивать. Выяснить максимальное значение id из таблицы, думаю, не составит никаких трудностей:
SELECT max(id) FROM test_tableА вот чтобы сгенерировать последовательность от 1 до max как раз и понадобится рекурсивный запрос. Ведь как здорово просто взять и получить нужное количество строк! Достаточно будет их пронумеровать – и вот список готов.
SELECT rownum as rn FROM dual
CONNECT BY level <= (SELECT max(id) FROM test_table);Конструкция “SELECT … FROM dual” используется, когда надо вычислить значение функции, не производя при этом выборки данных. Dual – это системная таблица, состоящая из одного столбца и одной строки. Запрос из нее всегда возвращает одну строку со значением ‘X’. Благодаря такой умопомрачительной стабильности, эту таблицу удобно использовать в качестве источника строк.
Обычно таблицу, которую нагло используют для получения нужного количества строк, не выбирая сами данные, называют pivot. В качестве такой таблицы может выступать любая большая таблица, в том числе системная. Но использование dual в Oracle является более разумным решением.
Теперь, когда список номеров подряд уже есть, достаточно пройтись по нему и сравнить, есть ли такой номер в проверяемой таблице:
SELECT sq.rn
FROM (SELECT rownum as rn FROM dual
CONNECT BY level <= (SELECT max(id) FROM test_table)) sq
WHERE sq.rn not in (SELECT id FROM test_table)
ORDER BY rn;RN ---- 3 5
Всё. Ведро начищено до блеска, лошадь вооружена биноклем для остроты зрения. Да не коснется вас ROLLBACK. COMMIT!
