
Have you heard about memoization? It's a super simple thing, by the way,– just memoize which result you have got from a first function call, and use it instead of calling it the second time - don't call real stuff without reason, don't waste your time.
Skipping some intensive operations is a very common optimization technique. Every time you might not do something — don’t do it. Try to use cache — memcache, file cache, local cache — any cache! A must-have for backend systems and a crucial part of any backend system of past and present.

Memoization vs Caching
Memoization is like caching. Just a bit different. Not cache, let's call it kashe.
Long story short, but memoization is not a cache, not a persistent cache. It might be it on a server side, but can not, and should not be a cache on a client side. It's more about available resources, usage patterns, and the reasons to use.
Problem - Cache need a" cache key"
Cache is storing and fetching data using a string cache key. It's already a problem to construct a unique, and usable key, but then you have to serialise and de-serialise data to store in yet again string based medium… in short - cache might be not as fast, as you might think. Especially distributed cache.
Memoization does not need any cache key
In the same time - no key is needed for memoization. Usually* it uses arguments as-is, not trying to create a single key from them, and does not use some globally available shared object to store results, as cache usually does.
The difference between memoization and cache is in API INTERFACE!
Usually* does not mean always. Lodash.memoize, by default, uses JSON.stringify to convert passed arguments into a string cache(is there any other way? No!). Just because they are going to use this key to access an internal object, holding a cached value. fast-memoize, "the fastest possible memoization library", does the same. Both named libraries are not memoization libraries, but cache libraries.
It worth to mention – JSON.stringify might be 10 times slower than a function, you gonna memoize.
Obviously - the simples solution to the problem is NOT to use a cache key, and NOT access some internal cache using that key. So - remember the last arguments you were called with. Like memoizerific or reselect do.
Memoizerific is probably the only general caching library you would like to use.
The cache size
The second big difference between all libraries is about the cache size and the cache structure.
Have you ever thought – why reselect or memoize-one holds only one, last result? Not to "not to use cache key to be able to store more than one result", but because there are no reasons to store more than just a last result.
…It's more about:
- available resources - a single cache line is very resource friendly
- usage patterns - remembering something "in place" is a good pattern. "In place" you usually need only one, last, result.
- the reason to use -modularity, isolation and memory safety are good reasons. Not sharing cache with the rest of your application is just more safe in terms of cache collisions.
A Single Result?!
Yes - the only one result. With one result memoized some classical things, like memoized fibonacci number generation(you may find as an example in every article about memoization) would be not possible. But, usually, you are doing something else - who needs a fibonacci on Frontend? On Backend? A real world examples are quite far from abstract IT quizzes.
But still, there are two BIG problems about a single-value memoization kind.
Problem 1 - it's "fragile"
By defaults - all arguments should match, exactly be the "===" same. If one argument does not match - the game is over. Even if this comes from the idea of memoization - that might not be something you want nowadays. I mean – you want to memoize as much, as possible, and as often, as possible.
Even cache miss is a cache wiping headshot.
There is a little difference between "nowadays" from "yesterdays" - immutable data structures, used for example in Redux.
const getSomeDataFromState = memoize(state => compute(state.tasks));
Looking good? Looking right? However thestate might change when tasks did not, and you need only tasks to match.
Structural Selectors are here to save the day with their strongest warrior - Reselect – at your beck and call. Reselect is not only memoization library, but it's power comes from memoization cascades, or lenses(which they are not, but think about selectors as optical lenses).
// every time `state` changes, cached value would be rejected const getTasksFromState = createSelector(state => state.tasks); const getSomeDataFromState = createSelector( // `tasks` "without" `state` getTasksFromState, // <---------- // and this operation would be memoized "more often" tasks => compute(state.tasks) );
As a result, in case of immutable data - you always have to first "focus" into the data piece you really need, and then - perform calculations, or else cache would be rejected, and all the idea behind memoization would vanish.
This is actually a big problem, especially for newcomers, but it, as The Idea behind immutable data structures, has a significant benefit - if something is not changed - it is not changed. If something is changed - probably it is changed. That's giving us a super fast comparison, but with some false negatives, like in the first example.
The Idea is about "focusing" into the data you depend on
There are two moments I should have - mentioned:
lodash.memoizeandfast-memoizeare converting your data to a string to be used as a key. That means that they are 1) not fast 2) not safe 3) could produce false positives - some different data could have the same string representation. This might improve "cache hot rate", but actually is a VERY BAD thing.- there is an ES6 Proxy approach, about tracking all the used pieces of variables given, and checking only keys which matter. While I personally would like to create myriads of data selectors - you might not like or understand the process, but might want to have proper memoization out of the box - then use memoize-state.
Problem 2- it's "one cache line"
Infinite cache size is a killer. Any uncontrolled cache is a killer, as long as memory is quite finite. So - all the best libraries are "one-cache-line-long". That's a feature and strong design decision. I just written how right it is, and, believe me - it's a really right thing, but it's still a problem. A Big Problem.
const tasks = getTasks(state); // let's get some data from state1 (function was defined above) getDataFromTask(tasks[0]); // Yep! equal(getDataFromTask(tasks[0]), getDataFromTask(tasks[0])) // Ok! getDataFromTask(tasks[1]); // a different task? What the heck? // oh! That's another argument? How dare you!? // TLDR -> task[0] in the cache got replaced by task[1] you cannot use getDataFromTask to get data from different tasks
Once the same selector has to work with different source data, with more that one - everything is broken. And it is easy to run into the problem:
- As long as we were using selectors to get tasks from a state - we could use the same selectors to get something from a task. Intense comes from API itself. But it does not work then you can memoize only last call, but have to work with multiple data sources.
- The same problem is with multiple React Components - they all are the same, and all a bit different, fetching different tasks, wiping results of each other.
There are 3 possible solutions:
- in case of redux - use mapStateToProps factory. It would create per-instance memoization.
const mapStateToProps = () => { const selector = createSelector(...); // ^ you have to define per-instance selectors here // usually that's not possible :) return state => ({ data: selector(data), // a usual mapStateToProps }); } - the second variant is almost the same (and also for redux) - it's about using re-reselect. It's a complex library, which could save the day by distinguishing components. It just could understand, that the new call was made for "another" component, and it might keep the cache for the "previous" one.
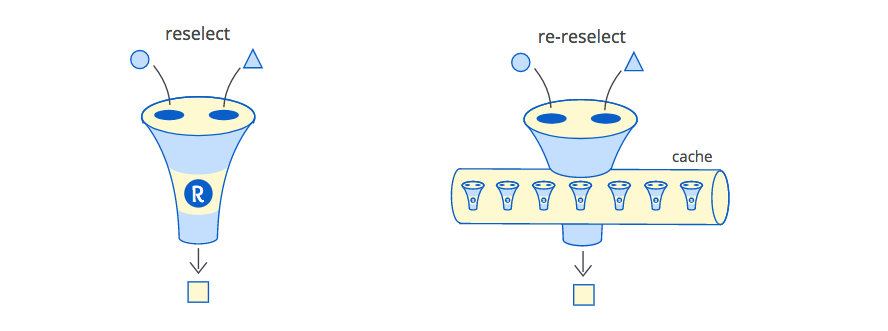
This library would help you "keep" the memoization cache, but not delete it. Especially because it is implementing 5(FIVE!) different cache strategies to fit any case. That's a bad smell. What if you choose the wrong one?
All the data you have memoized - you have to forget it, sooner or later. The point is not to remember last function invocation - the point is to FORGET IT at the right time. Not too soon, and ruin memoization, and not too late.
Got the idea? Now forget it! And where is 3rd variant??
Let take a pause
Stop. Relax. Make a deep breath. And answer one simple question - What's the goal? What we have to do to reach the goal? What would save the day?
TIP: Where is that f*** "cache" LOCATED!

Where is that "cache" LOCATED? Yes - that's the right question. Thanks for asking it. And the answer is simple - it is located in a closure. In a hidden spot inside* a memoized function. For example - here is memoize-one code:
function(fn) { let lastArgs; // the last arguments let lastResult;// the last result <--- THIS IS THE CACHE // the memoized function const memoizedCall = function(...newArgs) { if (isEqual(newArgs, lastArgs)) { return lastResult; } lastResult = resultFn.apply(this, newArgs); lastArgs = newArgs; return lastResult; }; return memoizedCall; }
You will be given a memoizedCall, and it will hold the last result nearby, inside its local closure, not accessible by anyone, except memoizedCall. A safe place. "this" is a safe place.
Reselect does the same, and the only way to create a "fork", with another cache - create a new memoization closure.
But the (another) main question - when it(cache) would be "gone"?
TLDR: It would be "gone" with a function, when the function instance would be eaten by Garbage Collector.
Instance? Instance! So - what's about per instance memoization? There is a whole article about it at React documentation
In short — if you are using Class-based React Components you might do:
import memoize from "memoize-one"; class Example extends Component { filter = memoize( // <-- bound to the instance (list, filterText) => list.filter(...); // ^ that is "per instance" memoization // we are creating "own" memoization function // with the "own" lastResult render() { // Calculate the latest filtered list. // If these arguments haven't changed since the last render, // `memoize-one` will reuse the last return value. const filteredList = this.filter(something, somehow); return <ul>{filteredList.map(item => ...}</ul> } }
So - where "lastResult" is stored? Inside a local scope of memoized filter, inside this class instance. And, when it would be "gone"?
This time it would "be gone" with a class instance. Once component got unmounted - it gone without a trace. It's a real "per instance", and you might use this.lastResult to hold a temporal result, with exactly the same "memoization" effect.
What's about React.Hooks
We are getting closer. Redux hooks have a few suspicious commands, which, probably, are about memoization. Like - useMemo, useCallback, useRef
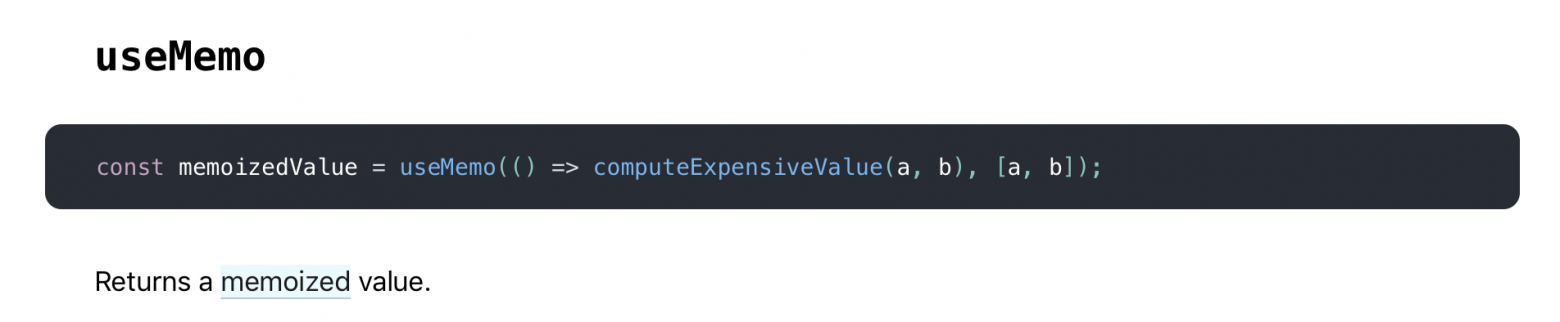
But the question - WHERE it is storing a memoized value this time?
In short - it stores it in "hooks", inside a special part of a VDOM element known as fiber associated with a current element. Within a parallel data structure.
Not so short - hooks are changing the way your program work, moving your function inside another one, with some variables in a hidden spot inside a parent closure. Such functions are known as suspendable or resumable functions — coroutines. In JavaScript they are usually known as generators or async functions.
But that a bit extreme. In a really short - useMemo is storing memoized value in this. It is just a bit different "this".
If we want to create a better memoization library we should find a better "this".
Zing!
WeakMaps!
Yes! WeakMaps! To store key-value, where the key would be this, as long as WeakMap does not accept anything except this, ie "objects".
Let's create a simple example:
const createHiddenSpot = (fn) => { const map = new WeakMap(); // a hidden "closure" const set = (key, value) => (map.set(key, value), value); return (key) => { return map.get(key) || set(key, fn(key)) } } const weakSelect = createHiddenSpot(selector); weakSelect(todos); // create a new entry weakSelect(todos); // return an existing entry weakSelect(todos[0]); // create a new entry weakSelect(todos[1]); // create a new entry weakSelect(todos[0]); // return an existing entry! weakSelect(todos[1]); // return an existing entry!! weakSelect(todos); // return an existing entry!!!
It's stupidly simple, and quite "right". So "when it would be gone"?
- forget weakSelect and a whole "map" would be gone
- forget todos[0] and their weak entry would be gone
- forget todos - and memoized data would be gone!
It's clear when something would "gone" – only when it should!
Magically - all the reselect issues are gone. Issues with aggressive memoization - also a goner.
This approach REMEMBER the data until it's time to FORGET. Its unbelievable, but to better remember something you have to be able to better forget it.
The only thing lasts - create a more robust API for this case
Kashe - is a cache
kashe is WeakMap based memoization library, which could save your day.
This library exposes 4 functions
kashe-for memoization.box- for prefixed memoization, to increase chance of memoization.inbox- nested prefixed memoization, to decrease change of memoizationfork- to fork(obviously) memoization.
kashe(fn) => memoizedFn(…args)
It's actually a createHiddenSpot from a previous example. It will use a first argument as a key for an internal WeakMap.
const selector = (state, prop) => ({result: state[prop]}); const memoized = kashe(selector); const old = memoized(state, 'x') memoized(state, 'x') === old memoized(state, 'y') === memoized(state, 'y') // ^^ another argument // but old !== memoized(state, 'x') // 'y' wiped 'x' cache in `state`
first argument is a key, if you called function again the same key, but different arguments - cache would be replaced, it is still one cache line long memoization. To make it work - you have to provide different keys for different cases, as I did with a weakSelect example, to provide different this to hold results. Reselect cascades A's still the thing.
Not all functions are kashe-memoizable. First argument have to be an object, array or a function. It should be usable as a key for WeakMap .
box(fn) => memoizedFn2(box, …args)
this is the same function, just applied twice. Once for fn, once for memoizedFn, adding a leading key to the arguments. It might make any function kashe-memoizable.
It is quite declarative – hey function! I will store results in this box.
// could not be "kashe" memoized const addTwo = (a,b) => ({ result: a+b }); const bAddTwo = boxed(addTwo); const cacheKey = {}; // any object bAddTwo(cacheKey, 1, 2) === bAddTwo(cacheKey, 1, 2) === { result: 3}
If you will box already memoized function - you will increase memoization chance, like per instance memoization - you may create memoization cascade.
const selectSomethingFromTodo = (state, prop) => ... const selector = kashe(selectSomethingFromTodo); const boxedSelector = kashe(selector); class Component { render () { const result = boxedSelector(this, todos, this.props.todoId); // 1. try to find result in `this` // 2. try to find result in `todos` // 3. store in `todos` // 4. store in `this` // if multiple `this`(components) are reading from `todos` - // selector is not working (they are wiping each other) // but data stored in `this` - exists. ... } }
inbox(fn) => memoizedFn2(box, …args)
this one is opposite to the box, but doing almost the same, commanding nested cache to store data into the provided box. From one point of view - it reduces memoization probability(there is no memoization cascade), but from another - it removes the cache collisions and help isolate processes if they should not interfere with each other by any reason.
It's quite declarative - hey! Everybody inside! Here is a box to use
const getAndSet = (task, number) => task.value + number; const memoized = kashe(getAndSet); const inboxed = inbox(getAndSet); const doubleBoxed = inbox(memoized); memoized(task, 1) // ok memoized(task, 2) // previous result wiped inboxed(key1, task, 1) // ok inboxed(key2, task, 2) // ok // inbox also override the cache for any underlaying kashe calls doubleBoxed(key1, task, 1) // ok doubleBoxed(key2, task, 2) // ok
fork(kashe-memoized) => kashe-memoized
Fork is a real fork - it gets any kashe-memoized function, and return the same, but with another internal cache entry. Remember redux mapStateToProps factory method?
const mapStateToProps = () => { // const selector = createSelector(...); // const selector = fork(realSelector); // just fork existing selector. Or box it, or don't do anything // kashe is more "stable" than reselect. return state => ({ data: selector(data), }); }
Reselect
And there one more thing you should know - kashe could replace reselect. Literally.
import { createSelector } from 'kashe/reselect';
It's actually the same reselect , just created with kashe as a memoization function.
Codesandbox
Here is a little example to play with. Also you may double check tests — they are compact and sound.
If you want to know more about caching and memoization — check how I wrote the fastest memoization library a year ago.
PS: It worth to mention, than the simpler version of this approach - weak-memoize - is used in emotion-js for a while. No complaints. nano-memoize also uses WeakMaps for a single argument case.
Got the point? A more "weak" approach would help you to better remember something, and better forget it.
https://github.com/theKashey/kashe
Yeah, about forgetting something,– could you please look here?

