I have originally posted this article in CodingSight blog
The second part of the article is available here
The need to do things in an asynchronous way – that is, dividing big tasks between multiple working units – was present long before the appearance of computers. However, when they did appear, this need became even more obvious. It is now 2019, and I’m writing this article on a laptop powered by an 8-core Intel Core CPU which, in addition to this, is simultaneously working on hundreds of processes, with the number of threads being even larger. Next to me, there lies a slightly outdated smartphone which I bought a couple of years ago – and it also houses an 8-core processor. Specialized web resources contain a wide variety of articles praising this year’s flagship smartphones equipped with 16-core CPUs. For less then $20 per hour, MS Azure can give you access to a 128-core virtual machine with 2 TB RAM. But, unfortunately, you cannot get the most out of this power unless you know how to control interaction between threads.
Process – an OS object which represents an isolated address space containing threads.
Thread – an OS object which represents the smallest execution unit. Threads are constituent parts of processes, they divide memory and other resources between each other in the scope of a process.
Multitasking – an OS feature which represents the capability of executing multiple processes simultaneously.
Multi-core – a CPU feature which represents the ability to use multiple cores for data processing
Multiprocessing – the feature of a computer which represents the capability to physically work with multiple CPUs.
Multi-threading – the feature of a process which represents the capability of dividing and spreading the data processing between multiple threads.
Parallelism – simultaneous physical execution of multiple actions in a unit of time
Asynchrony – executing an operation without waiting for it to be fully processed, leaving the calculation of the result for later time.
Not all definitions are effective and some of them require elaboration, so let me provide a cooking metaphor for the terminology I just introduced.
Making breakfast represents a process in this metaphor.
When making breakfast in the morning, I(CPU) go to the kitchen(Computer). I have two hands(Cores). On the kitchen, there is an assortment of devices(IO): stove, kettle, toaster, fridge. I turn on the stove, put a frying pan on it and pour some vegetable oil in it. Without waiting for the oil to heat (asynchronously, Non-Blocking-IO-Wait), I get some eggs from the fridge, crack them over a bowl and then whip them with one hand(Thread#1). Meanwhile, the second hand(Thread#2) is holding the bowl in place (Shared Resource). I would like to turn on the kettle, but I don’t have enough free hands at the moment (Thread Starvation). While I was whipping the eggs, the frying pan got hot enough (Result processing), so I pour the whipped eggs into it. I reach over to the kettle, turn it on and look at the water being boiled (Blocking-IO-Wait) – but I could have used this time to wash the bowl.
I only used 2 hands while making the omelet (because I don’t have more), but there were 3 simultaneous operations being executed: whipping the eggs, holding the bowl, heating the frying pan. CPU is the fastest part of the computer and IO is the part which requires waiting the most often, so it is quite effective to load the CPU with some work while it’s waiting for the data from IO.
To extend the metaphor:
.NET is really good when it comes to working with threads – as well as at many other things. With each new version, it provides more tools for working with threads and new OS thread abstraction layers. When working with abstractions, the developers working with the framework are using an approach that allows them to go one or more layers down while using high-level abstractions. In most cases, there is no real need to do this (and doing this may introduce a possibility of shooting yourself in the foot), but sometimes this may be the only way to resolve an issue that cannot be solved on the current abstraction level.
When I said tools earlier, I meant both program interfaces (API) provided by the framework or third-party packages and full-fledged software solutions that simplify the process of searching for issues related to multi-threaded code.
The Thread class is the most basic .NET class for working with threads. Its constructor accepts one of these two delegates:
The delegate will be executed in a newly-created thread after calling the Start method. If the ParametrizedThreadStart delegate was passed to the constructor, then an object should be passed to the Start method. This process is needed to pass any local information to the thread. I should point out that it takes a lot of resources to create a thread and the thread itself is a heavy object – at least because it requires interaction with the OS API and 1MB of memory is allocated to the stack.
The ThreadPool class represents the concept of a pool. In .NET, the thread pool is a piece of engineering art and the Microsoft developers invested much effort to make it work optimally in all sorts of scenarios.
The general concept:
When started, the app creates a few threads in the background, allowing to access them when needed. If threads are used frequently and in great numbers, the pool is expanded to satisfy the needs of the calling code. If the pool doesn’t have enough free threads at the right time, it will either wait for one of the active threads to become unoccupied or create a new one. Based on this, it follows that the thread pool is perfect for short actions and does not work that well for processes that work as services for the whole duration of the application’s operation.
The QueueUserWorkItem method allows to use threads from the pool. This method takes the WaitCallback-type delegate. Its signature coincides with the signature of ParametrizedThreadStart, and the parameter that is passed to it serves the same role.
The less-commonly-known RegisterWaitForSingleObject thread pool method is used to organize non-blocking IO operations. The delegate which is passed to this method will be called when the WaitHandle is released after being passed to the method.
There is a thread timer in .NET, and it differs from the WinForms/WPF timers in that its handler is called in the thread taken from the pool.
There is also a rather unusual way of sending the delegate to a thread from the pool – the BeginInvoke method.
I would also like to take a look at the function which many of the methods I mentioned earlier come down to – CreateThread from the Kernel32.dll Win32 API. There is a way to call this function with the help of the methods’ extern mechanism. I have only seen this being used once in a particularly bad case of legacy code – and I still don’t understand what its author’s reasons were.
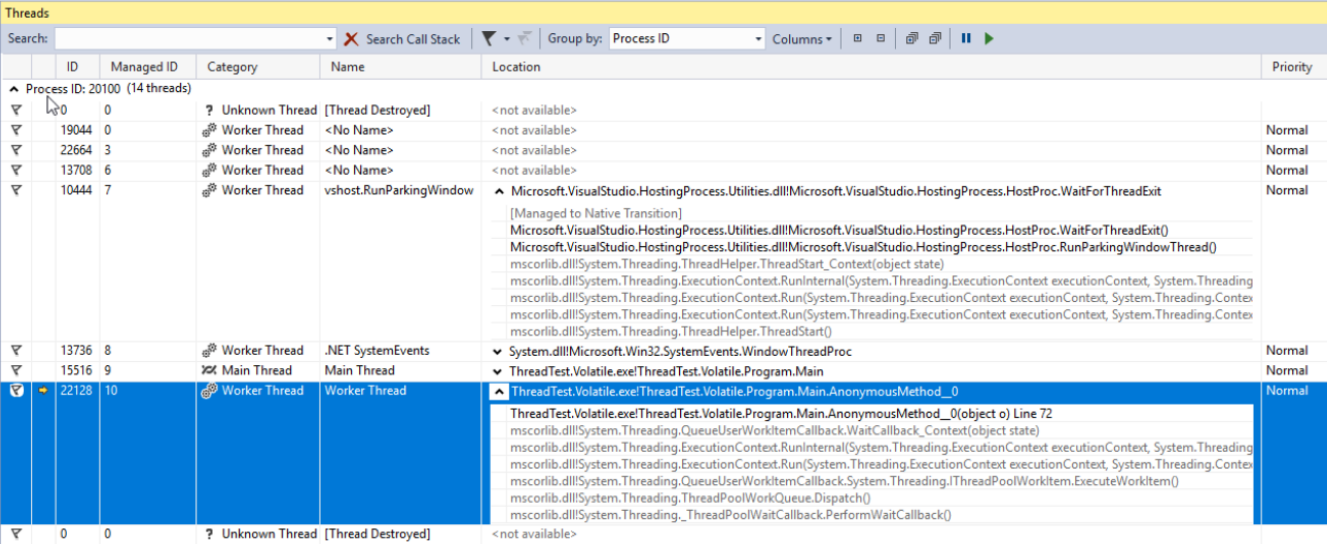
All threads – whether created by you, third-party components or the .NET pool – can be viewed in the Visual Studio’s Threads window. This window will only display the information about threads when the application is being debugged in the Break mode. Here, you can view the names and priorities of each thread and focus the debug mode on specific threads. The Priority property of the Thread class allows you to set the thread’s priority. This priority will be then taken into consideration when the OS and CLR are dividing processor time between threads.
Task Parallel Library (TPL) has first appeared in .NET 4.0. Currently, it’s the main tool for working with asynchrony. Any code utilizing older approaches will be considered legacy code. TPL’s main unit is the Task class from the System.Threading.Tasks namespace. Tasks represent thread abstraction. With the latest version of C#, we acquired a new elegant way of working with Tasks – the async/await operators. These allow for asynchronous code to be written as if it were simple and synchronous, so those who are not well-versed in the theory of threads can now write apps that won’t struggle with long operations. Using async/await is really a topic for a separate article (or even a few articles), but I’ll try to outline the basics in a few sentences:
Once again: the await operator will usually (there are exceptions) let the current thread go and, when the task will be executed and the thread (actually, the context, but we’ll get back to it later) will be free as a result, it will continue executing the method. In .NET, this mechanism is implemented in the same way as yield return – a method is turned into a finite state machine class that can be executed in separate pieces based on its state. If this sound interesting, I would recommend writing any simple piece of code based on async/await, compiling it and looking at its compilation with the help of JetBrains dotPeek with Compiler Generated Code enabled.
Let’s look at the options we have when it comes to starting and using a task. In the example below, we create a new task which doesn’t actually do anything productive(Thread.Sleep(10000)). However, in real cases we should substitute it with some complex work that utilizes CPU resources.
A task is created with the following options:
The second parameter that was passed to the method is CancellationToken. For the operation to be properly cancelled after it was already started, the executable code should contain CancellationToken state checks. If there are no such checks, then the Cancel method called on the CancellationTokenSource object would only be able to stop the task execution before the task is actually started.
For the last parameter, we sent a TaskScheduler-type object called scheduler. This class, along with its children classes, is used to control how tasks are distributed between threads. By default, a task will be executed on a randomly-selected thread from the pool
The await operator is applied to the created task. This means that the code written after it (if there is such code) will be executed in the same context (often, this means ‘on the same thread’) as the code written before await.
This method is labelled as async void, which means that the await operator can be used in it, but the calling code would no be able to wait for execution. If such possibility is needed, the method should return a Task. Methods labelled as async void can be seen quite often: they are usually event handlers or other methods operating under the fire and forget principle. If it’s necessary to wait for the execution to be finished and return the result, then you should use Task.
For tasks that return the StartNew method, we can call ConfigureAwait with the false parameter – then, the execution after await will be continued on a random context instead of a captured one. This should always be done if the code written after await does not require a specific execution context. This is also a recommendation from MS when it comes to writing code provided as a library.
Let’s look at how we can wait for a Task to be finished. Below, you can see an example piece of code with comments denoting when the waiting is implemented in a relatively good or bad manner.
In the first example, we are waiting for the Task to be executed without blocking the calling thread, so we’ll come back to processing the result when it’s ready. Before that happens, the calling thread is left on its own.
In the second attempt, we are blocking the calling thread until the method’s result is calculated. This is a bad approach for two reasons. First of all, we are wasting a thread – a very valuable resource – on simple waiting. Additionally, if the method we’re calling contains an await while a return to the calling thread after await is intended by the synchronization context, we’ll get a deadlock. This happens because the calling thread will be waiting for the result of an asynchronous method, and the asynchronous method itself will be fruitlessly trying to continue its execution in the calling thread.
Another disadvantage of this approach is the increased complexity of error handling. The errors can actually be handled rather easily in asynchronous code if async/await is used – the process in this case is identical to that in synchronous code. However, when a synchronous wait is applied to a Task, the initial exception is wrapped in AggregateException. In other words, to handle the exception, we would need to explore the InnerException type and manually write an if chain in a catch block or, alternatively, use the catch when structure instead of the more usual chain of catch blocks.
The two last examples are also labelled as relatively bad for the same reasons and both contain the same issues.
The WhenAny and WhenAll methods are very useful when it comes to waiting for a group of Tasks – they wrap these tasks into one, and it will be executed either when one Task from the group is started or when all of these tasks are successfully executed.
For various reasons, there may be a need to stop a thread after it has been started. There are a few ways to do this. The Thread class has two methods with appropriate names — Abort and Interrupt. I would strongly discourage using the first one as, after it’s called, there would be a ThreadAbortedException thrown at any random moment while processing any arbitrarily chosen instruction. You’re not expecting such an exception to be encountered when an integer variable is incremented, right? Well, when using the Abort method, this becomes a real possibility. In case you need to deny the CLR’s ability of creating such exceptions in a specific part of the code, you can wrap it in the Thread.BeginCriticalRegion and Thread.EndCriticalRegion calls. Any code written in the finally block is wrapped in these calls. This is why you can find blocks with an empty try and a non-empty finally in the depths of the framework code. Microsoft dislike this method to the extent of not including it in the .NET core.
The Interrrupt method works in a much more predictable way. It can interrupt a thread with a ThreadInterruptedException only when the thread is in the waiting mode. It moves to this state when suspended while waiting for WaitHandle, a lock or after Thread.Sleep is called.
Both of these ways have a disadvantage of unpredictability. To escape this issue, we should use the CancellationToken structure and the CancellationTokenSource class. The general idea is this: an instance of the CancellationTokenSource class is created, and only those who own it can stop the operation by calling the Cancel method. Only CancellationToken is passed to the operation. CancellationToken’s owners cannot cancel the operation themselves – they can only check whether the operation has been cancelled. This can be achieved by using a Boolean property IsCancellationRequested and the ThrowIfCancelRequested method. The last one will generate a TaskCancelledException if the Cancel method has been called on the CancellationTokenSource instance which created the CancellationToken. This is the method I recommend using. It’s advantage over the previously-described methods lies in the fact that it provides full control over the exact exception cases in which an operation can be cancelled.
The most brutal way to stop a thread would be to call a Win32 API function called TerminateThread. After this function is called, the CLR’s behavior can be quite unpredictable. In MSDN, the following is written about this function: “TerminateThread is a dangerous function that should only be used in the most extreme cases. “
If you were fortunate enough to work on a project which was started after the Tasks have been introduced (and when they are no longer inciting existential horror in most of developers), you will not have to deal with old APIs – both the third-party ones and those your team toiled on in the past. Fortunately, the .NET Framework development team made it easier for us – but this could have been self-care, for all we know. In any case, .NET has a few tools which help with seamlessly bringing the code written with old aprroaches to asynchrony in mind to an up-to-date form. One of these is the TaskFactory method called FromAsync. In the example below, I’m wrapping the old asynchronous methods of the WebRequest class into a Task by using FromAsync.
It’s only an example, and you probably won’t be doing something of this sort with built-in types. However, old projects teem with BeginDoSomething methods that return IAsyncResult and EndDoSomething methods that receive them.
Another tool worth exploring is the TaskCompletionSource class. In its functionality, purpose and operation principle, it resembles the RegisterWaitForSingleObject method from the ThreadPool class I mentioned earlier. This class allows us to easily wrap old asynchronous APIs into Tasks.
You may want to say that I already told about the FromAsync method from the TaskFactory class which served these purposes. Here, we would need to remember the full history of asynchronous models Microsoft provided in the last 15 years: before Task-Based Asynchronous Patterns (TAP), there were Asynchronous Programming Patterns (APP). APPs were all about BeginDoSomething returning IAsyncResult and the EndDoSomething method which accepts it – and the FromAsync method is perfect for these years’ legacy. However, as time passed, this was replaced with Event Based Asynchronous Patterns(EAP) which specified that an event is called when an asynchronous operation is successfully executed.
TaskCompletionSource are perfect for wrapping legacy APIs built around the event model into Tasks. This is how it works: objects of this class have a public property called Task, the state of which can be controlled by various methods of the TaskCompletionSource class (SetResult, SetException etc.). In places where the await operator was applied to this Task, it will be executed or crashed with an exception depending on the method applied to TaskCompletionSource. To understand it better, let’s look at this example piece of code. Here, some old API from the EAP era is wrapped in a Task with the help of TaskCompletionSource: when an event is triggered, the Task will be switched to the Completed state while the method that applied the await operator to this Task will continue its execution after receiving a result object.
TaskCompletionSource can do more than just wrapping obsolete APIs. This class opens an interesting possibility of designing various APIs based on Tasks that don’t occupy threads. A thread, as we remember, is a expensive resource limited mostly by RAM. We can easily reach this limit when developing a robust web application with complex business logic. Let’s look at the capabilities I mentioned in action by implementing a neat trick known as Long Polling.
In short, this is how Long Polling works:
You need to get some information from an API about events occurring on its side, but the API, for some reason, can only return a state rather than telling you about the event. An example of such would be any API built over HTTP before WebSocket appeared or in circumstances under which this technology can’t be used. The client can ask the HTTP server. The HTTP server, on the other hand, cannot initiate contact with the client by itself. The simplest solution would be to ask the server periodically using a timer, but this would create additional load for the server and a general delay which approximately equals to TimerInterval / 2. To bypass this, Long Polling was invented. It entails delaying the server response until the Timeout expires or an event happens. If an event occurs, it will be handled; if not – the request will be sent again.
However, this solution’s effectiveness will radically drop should the number of clients waiting for the event grow – each waiting client occupies a full thread. Also, we get an additional delay of 1ms for event triggering. Often, it’s not really that crucial, but why would we make our software worse than it could be? On the other hand, if we remove Thread.Sleep(1), one of the CPU cores will be loaded for the full 100% while doing nothing in a useless cycle. With the help of TaskCompletionSource, we can easily transform our code to resolve all of the issues we mentioned:
Please keep in mind that this piece of code is only an example, and in no way production-ready. To use it in real cases, we would at least need to add a way to handle situations in which a message is received when nothing was waiting for it: in this case, the AcceptMessageAsync method should return an already finished Task. If this case is the most common one, we can consider using ValueTask.
When receiving a message request, we create a TaskCompletionSource, place it in a dictionary, and then wait for one of the following events: either the specified time interval is spent or a message is received.
async/await operators, just like the yield return operator, generate a finite state machine from a method, which means creating a new object – this doesn’t really matter most of the time, but can still create issues in some rare cases. One of these cases can occur with frequently-called methods – we’re talking tens and hundreds of thousands calls per second. If such a method is written in a way which makes it return the result while bypassing all await methods in most of the cases, .NET provides an optimization tool for this – the ValueTask structure. To understand how it works, let’s look at an example. Suppose there is a cache we access on a regular basis. If there are any values in it, we just return them; if there are no values – we try to get them from some slow IO. The latter should ideally be done asynchronously, so the whole method will be asynchronous. So, the most obvious way to implement this method will be as follows:
With a desire to optimize it a little bit and a concern for what Roslyn will generate when compiling this code, we could re-write the method like this:
However, the best solution in this case would be to optimize hot-path – specifically, getting dictionary values with no unnecessary allocations and no load on GC. Meanwhile, in those infrequent cases when we need to get data from IO, things will remain almost the same:
Let’s look at this code fragment more closely: if a value is present in the cache, we’ll create a structure; otherwise, the real task will be wrapped in a ValueTask. The path by which this code is executed is not important for the calling code: from the perspective of C# syntax, a ValueTask will behave just like a usual Task.
The next API I’d like to talk about is the TaskScheduler class and those derived from it. I already mentioned that TPL provides an ability to control how exactly Tasks are being distributed between threads. These strategies are defined in classes inheriting from TaskScheduler. Almost any strategy we may need can be found in the ParallelExtensionsExtras library. This library is developed by Microsoft, but is not a part of .NET – rather, it’s distributed as a Nuget package. Let’s have a look at some of the strategies:
There is a very good article about TaskSchedulers on Microsoft’s blog, so feel free to check it out.
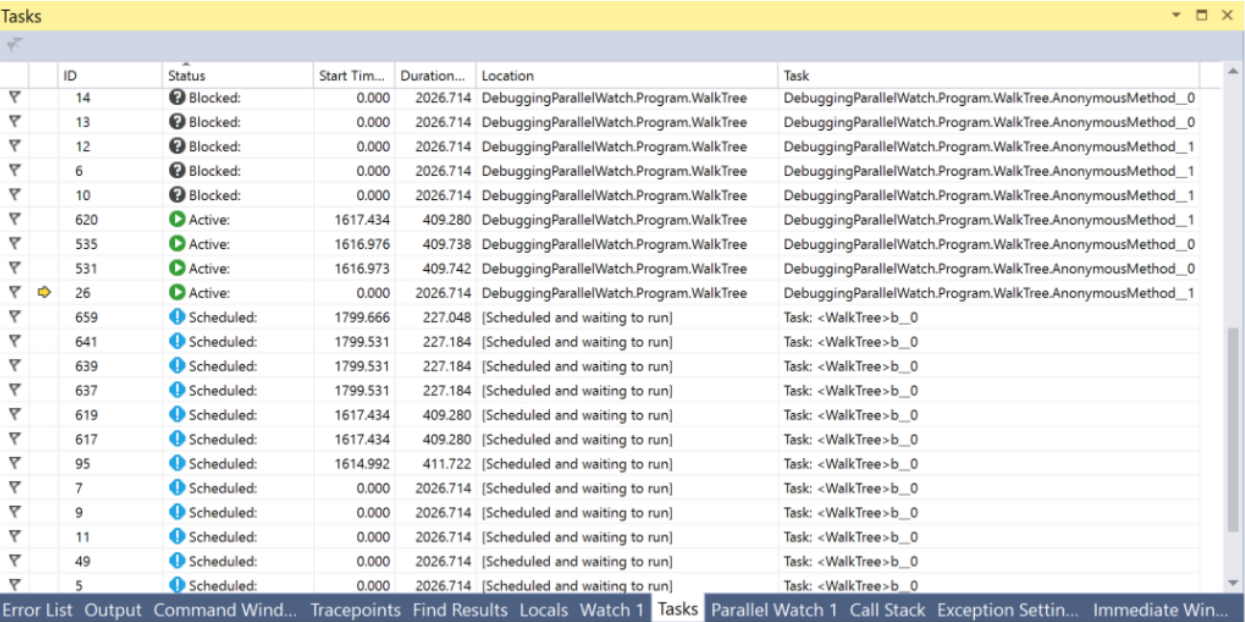
In Visual Studio, there is a Tasks window which can help with debugging everything related to Tasks. In this window, you can see the task’s state and jump to the currently executed line of code.
Aside from Tasks and all things related to them, there are two additional tools in .NET we can find interesting – PLinq(Linq2Parallel) and the Parallel class. The first one promises parallel execution of all Linq operations on all threads. The number of threads can be configured by an extension method WithDegreeOfParallelism. Unfortunately, in most cases, PLinq in the default mode will not have enough information about the data source to provide a significant increase in speed. On the other hand, the cost of trying is very low: you only need to call AsParallel before the chain of Linq methods and carry out performance tests. Moreover, you can pass additional information about the nature of your data source to PLinq by using the Partitions mechanism. You can find more information here and here.
The Parallel static class provides methods for enumerating collections in parallel via Foreach, running the For cycle and executing several delegates in parallel to Invoke. Execution of the current thread will be stopped until the results are calculated. You can configure the number of threads by passing ParallelOptions as the last argument. TaskScheduler and CancellationToken can also be set with the help of options.
When I started writing this article based on my thesis and on the knowledge I gained while working after it, I didn’t think there would be this much information. Now, with the text editor reproachfully telling me that I’ve written almost 15 pages, I’d like to draw an intermediary conclusion. We will look at other techniques, APIs, visual tools and hidden hazards in the next article.
Conclusions:
To be continued…
The second part of the article is available here
The need to do things in an asynchronous way – that is, dividing big tasks between multiple working units – was present long before the appearance of computers. However, when they did appear, this need became even more obvious. It is now 2019, and I’m writing this article on a laptop powered by an 8-core Intel Core CPU which, in addition to this, is simultaneously working on hundreds of processes, with the number of threads being even larger. Next to me, there lies a slightly outdated smartphone which I bought a couple of years ago – and it also houses an 8-core processor. Specialized web resources contain a wide variety of articles praising this year’s flagship smartphones equipped with 16-core CPUs. For less then $20 per hour, MS Azure can give you access to a 128-core virtual machine with 2 TB RAM. But, unfortunately, you cannot get the most out of this power unless you know how to control interaction between threads.
Contents
- Terminology
- A Metaphor
- .NET Tools
- Starting a Thread
- Viewing and Debugging Threads
- Task Parallel Library
- Stopping Threads
- Turning a Legacy API Into a Task-Based One by Using FromAsync
- Turning a Legacy API Into a Task-Based One by Using TaskCompletionSource
- TaskCompletionSource Tips & Tricks
- ValueTask: Why and How
- TaskScheduler: Controlling Task Execution Strategies
- PLinq and the Parallel Class
- Summary
Terminology
Process – an OS object which represents an isolated address space containing threads.
Thread – an OS object which represents the smallest execution unit. Threads are constituent parts of processes, they divide memory and other resources between each other in the scope of a process.
Multitasking – an OS feature which represents the capability of executing multiple processes simultaneously.
Multi-core – a CPU feature which represents the ability to use multiple cores for data processing
Multiprocessing – the feature of a computer which represents the capability to physically work with multiple CPUs.
Multi-threading – the feature of a process which represents the capability of dividing and spreading the data processing between multiple threads.
Parallelism – simultaneous physical execution of multiple actions in a unit of time
Asynchrony – executing an operation without waiting for it to be fully processed, leaving the calculation of the result for later time.
A Metaphor
Not all definitions are effective and some of them require elaboration, so let me provide a cooking metaphor for the terminology I just introduced.
Making breakfast represents a process in this metaphor.
When making breakfast in the morning, I(CPU) go to the kitchen(Computer). I have two hands(Cores). On the kitchen, there is an assortment of devices(IO): stove, kettle, toaster, fridge. I turn on the stove, put a frying pan on it and pour some vegetable oil in it. Without waiting for the oil to heat (asynchronously, Non-Blocking-IO-Wait), I get some eggs from the fridge, crack them over a bowl and then whip them with one hand(Thread#1). Meanwhile, the second hand(Thread#2) is holding the bowl in place (Shared Resource). I would like to turn on the kettle, but I don’t have enough free hands at the moment (Thread Starvation). While I was whipping the eggs, the frying pan got hot enough (Result processing), so I pour the whipped eggs into it. I reach over to the kettle, turn it on and look at the water being boiled (Blocking-IO-Wait) – but I could have used this time to wash the bowl.
I only used 2 hands while making the omelet (because I don’t have more), but there were 3 simultaneous operations being executed: whipping the eggs, holding the bowl, heating the frying pan. CPU is the fastest part of the computer and IO is the part which requires waiting the most often, so it is quite effective to load the CPU with some work while it’s waiting for the data from IO.
To extend the metaphor:
- If I was also trying to change my clothes while making the breakfast, then I would have been multitasking. Computers are way better at this than humans are.
- A kitchen with multiple cooks – for example, in a restaurant – is a multi-core computer.
- A mall food court with many restaurants would represent a data center.
.NET Tools
.NET is really good when it comes to working with threads – as well as at many other things. With each new version, it provides more tools for working with threads and new OS thread abstraction layers. When working with abstractions, the developers working with the framework are using an approach that allows them to go one or more layers down while using high-level abstractions. In most cases, there is no real need to do this (and doing this may introduce a possibility of shooting yourself in the foot), but sometimes this may be the only way to resolve an issue that cannot be solved on the current abstraction level.
When I said tools earlier, I meant both program interfaces (API) provided by the framework or third-party packages and full-fledged software solutions that simplify the process of searching for issues related to multi-threaded code.
Starting a Thread
The Thread class is the most basic .NET class for working with threads. Its constructor accepts one of these two delegates:
- ThreadStart – no parameters
- ParametrizedThreadStart – one object-type parameter.
The delegate will be executed in a newly-created thread after calling the Start method. If the ParametrizedThreadStart delegate was passed to the constructor, then an object should be passed to the Start method. This process is needed to pass any local information to the thread. I should point out that it takes a lot of resources to create a thread and the thread itself is a heavy object – at least because it requires interaction with the OS API and 1MB of memory is allocated to the stack.
new Thread(...).Start(...);
The ThreadPool class represents the concept of a pool. In .NET, the thread pool is a piece of engineering art and the Microsoft developers invested much effort to make it work optimally in all sorts of scenarios.
The general concept:
When started, the app creates a few threads in the background, allowing to access them when needed. If threads are used frequently and in great numbers, the pool is expanded to satisfy the needs of the calling code. If the pool doesn’t have enough free threads at the right time, it will either wait for one of the active threads to become unoccupied or create a new one. Based on this, it follows that the thread pool is perfect for short actions and does not work that well for processes that work as services for the whole duration of the application’s operation.
The QueueUserWorkItem method allows to use threads from the pool. This method takes the WaitCallback-type delegate. Its signature coincides with the signature of ParametrizedThreadStart, and the parameter that is passed to it serves the same role.
ThreadPool.QueueUserWorkItem(...);
The less-commonly-known RegisterWaitForSingleObject thread pool method is used to organize non-blocking IO operations. The delegate which is passed to this method will be called when the WaitHandle is released after being passed to the method.
ThreadPool.RegisterWaitForSingleObject(...)
There is a thread timer in .NET, and it differs from the WinForms/WPF timers in that its handler is called in the thread taken from the pool.
System.Threading.Timer
There is also a rather unusual way of sending the delegate to a thread from the pool – the BeginInvoke method.
DelegateInstance.BeginInvoke
I would also like to take a look at the function which many of the methods I mentioned earlier come down to – CreateThread from the Kernel32.dll Win32 API. There is a way to call this function with the help of the methods’ extern mechanism. I have only seen this being used once in a particularly bad case of legacy code – and I still don’t understand what its author’s reasons were.
Kernel32.dll CreateThread
Viewing and Debugging Threads
All threads – whether created by you, third-party components or the .NET pool – can be viewed in the Visual Studio’s Threads window. This window will only display the information about threads when the application is being debugged in the Break mode. Here, you can view the names and priorities of each thread and focus the debug mode on specific threads. The Priority property of the Thread class allows you to set the thread’s priority. This priority will be then taken into consideration when the OS and CLR are dividing processor time between threads.
Task Parallel Library
Task Parallel Library (TPL) has first appeared in .NET 4.0. Currently, it’s the main tool for working with asynchrony. Any code utilizing older approaches will be considered legacy code. TPL’s main unit is the Task class from the System.Threading.Tasks namespace. Tasks represent thread abstraction. With the latest version of C#, we acquired a new elegant way of working with Tasks – the async/await operators. These allow for asynchronous code to be written as if it were simple and synchronous, so those who are not well-versed in the theory of threads can now write apps that won’t struggle with long operations. Using async/await is really a topic for a separate article (or even a few articles), but I’ll try to outline the basics in a few sentences:
- async is a modificator of a method which returns a Task or void
- await is an operator of a non-blocking wait Task.
Once again: the await operator will usually (there are exceptions) let the current thread go and, when the task will be executed and the thread (actually, the context, but we’ll get back to it later) will be free as a result, it will continue executing the method. In .NET, this mechanism is implemented in the same way as yield return – a method is turned into a finite state machine class that can be executed in separate pieces based on its state. If this sound interesting, I would recommend writing any simple piece of code based on async/await, compiling it and looking at its compilation with the help of JetBrains dotPeek with Compiler Generated Code enabled.
Let’s look at the options we have when it comes to starting and using a task. In the example below, we create a new task which doesn’t actually do anything productive(Thread.Sleep(10000)). However, in real cases we should substitute it with some complex work that utilizes CPU resources.
using TCO = System.Threading.Tasks.TaskCreationOptions; public static async void VoidAsyncMethod() { var cancellationSource = new CancellationTokenSource(); await Task.Factory.StartNew( // Code of action will be executed on other context () => Thread.Sleep(10000), cancellationSource.Token, TCO.LongRunning | TCO.AttachedToParent | TCO.PreferFairness, scheduler ); // Code after await will be executed on captured context }
A task is created with the following options:
- LongRunning – this option hints at the fact that the task can not be performed quickly. Therefore, it is possibly better to create a separate thread for this task rather than taking an existing one from the pool to minimize harm to other tasks.
- AttachedToParent – Tasks can be arranged hierarchically. If this option is used, the task will be waiting for its children tasks to be executed after being executed itself.
- PreferFairness – this option specifies that the task should better be executed before the tasks that were created later. However, it’s more of a suggestion, so the result is not always guaranteed.
The second parameter that was passed to the method is CancellationToken. For the operation to be properly cancelled after it was already started, the executable code should contain CancellationToken state checks. If there are no such checks, then the Cancel method called on the CancellationTokenSource object would only be able to stop the task execution before the task is actually started.
For the last parameter, we sent a TaskScheduler-type object called scheduler. This class, along with its children classes, is used to control how tasks are distributed between threads. By default, a task will be executed on a randomly-selected thread from the pool
The await operator is applied to the created task. This means that the code written after it (if there is such code) will be executed in the same context (often, this means ‘on the same thread’) as the code written before await.
This method is labelled as async void, which means that the await operator can be used in it, but the calling code would no be able to wait for execution. If such possibility is needed, the method should return a Task. Methods labelled as async void can be seen quite often: they are usually event handlers or other methods operating under the fire and forget principle. If it’s necessary to wait for the execution to be finished and return the result, then you should use Task.
For tasks that return the StartNew method, we can call ConfigureAwait with the false parameter – then, the execution after await will be continued on a random context instead of a captured one. This should always be done if the code written after await does not require a specific execution context. This is also a recommendation from MS when it comes to writing code provided as a library.
Let’s look at how we can wait for a Task to be finished. Below, you can see an example piece of code with comments denoting when the waiting is implemented in a relatively good or bad manner.
public static async void AnotherMethod() { int result = await AsyncMethod(); // good result = AsyncMethod().Result; // bad AsyncMethod().Wait(); // bad IEnumerable<Task> tasks = new Task[] { AsyncMethod(), OtherAsyncMethod() }; await Task.WhenAll(tasks); // good await Task.WhenAny(tasks); // good Task.WaitAll(tasks.ToArray()); // bad }
In the first example, we are waiting for the Task to be executed without blocking the calling thread, so we’ll come back to processing the result when it’s ready. Before that happens, the calling thread is left on its own.
In the second attempt, we are blocking the calling thread until the method’s result is calculated. This is a bad approach for two reasons. First of all, we are wasting a thread – a very valuable resource – on simple waiting. Additionally, if the method we’re calling contains an await while a return to the calling thread after await is intended by the synchronization context, we’ll get a deadlock. This happens because the calling thread will be waiting for the result of an asynchronous method, and the asynchronous method itself will be fruitlessly trying to continue its execution in the calling thread.
Another disadvantage of this approach is the increased complexity of error handling. The errors can actually be handled rather easily in asynchronous code if async/await is used – the process in this case is identical to that in synchronous code. However, when a synchronous wait is applied to a Task, the initial exception is wrapped in AggregateException. In other words, to handle the exception, we would need to explore the InnerException type and manually write an if chain in a catch block or, alternatively, use the catch when structure instead of the more usual chain of catch blocks.
The two last examples are also labelled as relatively bad for the same reasons and both contain the same issues.
The WhenAny and WhenAll methods are very useful when it comes to waiting for a group of Tasks – they wrap these tasks into one, and it will be executed either when one Task from the group is started or when all of these tasks are successfully executed.
Stopping Threads
For various reasons, there may be a need to stop a thread after it has been started. There are a few ways to do this. The Thread class has two methods with appropriate names — Abort and Interrupt. I would strongly discourage using the first one as, after it’s called, there would be a ThreadAbortedException thrown at any random moment while processing any arbitrarily chosen instruction. You’re not expecting such an exception to be encountered when an integer variable is incremented, right? Well, when using the Abort method, this becomes a real possibility. In case you need to deny the CLR’s ability of creating such exceptions in a specific part of the code, you can wrap it in the Thread.BeginCriticalRegion and Thread.EndCriticalRegion calls. Any code written in the finally block is wrapped in these calls. This is why you can find blocks with an empty try and a non-empty finally in the depths of the framework code. Microsoft dislike this method to the extent of not including it in the .NET core.
The Interrrupt method works in a much more predictable way. It can interrupt a thread with a ThreadInterruptedException only when the thread is in the waiting mode. It moves to this state when suspended while waiting for WaitHandle, a lock or after Thread.Sleep is called.
Both of these ways have a disadvantage of unpredictability. To escape this issue, we should use the CancellationToken structure and the CancellationTokenSource class. The general idea is this: an instance of the CancellationTokenSource class is created, and only those who own it can stop the operation by calling the Cancel method. Only CancellationToken is passed to the operation. CancellationToken’s owners cannot cancel the operation themselves – they can only check whether the operation has been cancelled. This can be achieved by using a Boolean property IsCancellationRequested and the ThrowIfCancelRequested method. The last one will generate a TaskCancelledException if the Cancel method has been called on the CancellationTokenSource instance which created the CancellationToken. This is the method I recommend using. It’s advantage over the previously-described methods lies in the fact that it provides full control over the exact exception cases in which an operation can be cancelled.
The most brutal way to stop a thread would be to call a Win32 API function called TerminateThread. After this function is called, the CLR’s behavior can be quite unpredictable. In MSDN, the following is written about this function: “TerminateThread is a dangerous function that should only be used in the most extreme cases. “
Turning a Legacy API Into a Task-Based One by Using FromAsync
If you were fortunate enough to work on a project which was started after the Tasks have been introduced (and when they are no longer inciting existential horror in most of developers), you will not have to deal with old APIs – both the third-party ones and those your team toiled on in the past. Fortunately, the .NET Framework development team made it easier for us – but this could have been self-care, for all we know. In any case, .NET has a few tools which help with seamlessly bringing the code written with old aprroaches to asynchrony in mind to an up-to-date form. One of these is the TaskFactory method called FromAsync. In the example below, I’m wrapping the old asynchronous methods of the WebRequest class into a Task by using FromAsync.
object state = null; WebRequest wr = WebRequest.CreateHttp("http://github.com"); await Task.Factory.FromAsync( wr.BeginGetResponse, we.EndGetResponse );
It’s only an example, and you probably won’t be doing something of this sort with built-in types. However, old projects teem with BeginDoSomething methods that return IAsyncResult and EndDoSomething methods that receive them.
Turning a Legacy API Into a Task-Based One by Using TaskCompletionSource
Another tool worth exploring is the TaskCompletionSource class. In its functionality, purpose and operation principle, it resembles the RegisterWaitForSingleObject method from the ThreadPool class I mentioned earlier. This class allows us to easily wrap old asynchronous APIs into Tasks.
You may want to say that I already told about the FromAsync method from the TaskFactory class which served these purposes. Here, we would need to remember the full history of asynchronous models Microsoft provided in the last 15 years: before Task-Based Asynchronous Patterns (TAP), there were Asynchronous Programming Patterns (APP). APPs were all about BeginDoSomething returning IAsyncResult and the EndDoSomething method which accepts it – and the FromAsync method is perfect for these years’ legacy. However, as time passed, this was replaced with Event Based Asynchronous Patterns(EAP) which specified that an event is called when an asynchronous operation is successfully executed.
TaskCompletionSource are perfect for wrapping legacy APIs built around the event model into Tasks. This is how it works: objects of this class have a public property called Task, the state of which can be controlled by various methods of the TaskCompletionSource class (SetResult, SetException etc.). In places where the await operator was applied to this Task, it will be executed or crashed with an exception depending on the method applied to TaskCompletionSource. To understand it better, let’s look at this example piece of code. Here, some old API from the EAP era is wrapped in a Task with the help of TaskCompletionSource: when an event is triggered, the Task will be switched to the Completed state while the method that applied the await operator to this Task will continue its execution after receiving a result object.
public static Task<Result> DoAsync(this SomeApiInstance someApiObj) { var completionSource = new TaskCompletionSource<Result>(); someApiObj.Done += result => completionSource.SetResult(result); someApiObj.Do(); result completionSource.Task; }
TaskCompletionSource Tips & Tricks
TaskCompletionSource can do more than just wrapping obsolete APIs. This class opens an interesting possibility of designing various APIs based on Tasks that don’t occupy threads. A thread, as we remember, is a expensive resource limited mostly by RAM. We can easily reach this limit when developing a robust web application with complex business logic. Let’s look at the capabilities I mentioned in action by implementing a neat trick known as Long Polling.
In short, this is how Long Polling works:
You need to get some information from an API about events occurring on its side, but the API, for some reason, can only return a state rather than telling you about the event. An example of such would be any API built over HTTP before WebSocket appeared or in circumstances under which this technology can’t be used. The client can ask the HTTP server. The HTTP server, on the other hand, cannot initiate contact with the client by itself. The simplest solution would be to ask the server periodically using a timer, but this would create additional load for the server and a general delay which approximately equals to TimerInterval / 2. To bypass this, Long Polling was invented. It entails delaying the server response until the Timeout expires or an event happens. If an event occurs, it will be handled; if not – the request will be sent again.
while(!eventOccures && !timeoutExceeded) { CheckTimout(); CheckEvent(); Thread.Sleep(1); }
However, this solution’s effectiveness will radically drop should the number of clients waiting for the event grow – each waiting client occupies a full thread. Also, we get an additional delay of 1ms for event triggering. Often, it’s not really that crucial, but why would we make our software worse than it could be? On the other hand, if we remove Thread.Sleep(1), one of the CPU cores will be loaded for the full 100% while doing nothing in a useless cycle. With the help of TaskCompletionSource, we can easily transform our code to resolve all of the issues we mentioned:
class LongPollingApi { private Dictionary<int, TaskCompletionSource<Msg>> tasks; public async Task<Msg> AcceptMessageAsync(int userId, int duration) { var cs = new TaskCompletionSource<Msg>(); tasks[userId] = cs; await Task.WhenAny(Task.Delay(duration), cs.Task); return cs.Task.IsCompleted ? cs.Task.Result : null; } public void SendMessage(int userId, Msg m) { if (tasks.TryGetValue(userId, out var completionSource)) completionSource.SetResult(m); } }
Please keep in mind that this piece of code is only an example, and in no way production-ready. To use it in real cases, we would at least need to add a way to handle situations in which a message is received when nothing was waiting for it: in this case, the AcceptMessageAsync method should return an already finished Task. If this case is the most common one, we can consider using ValueTask.
When receiving a message request, we create a TaskCompletionSource, place it in a dictionary, and then wait for one of the following events: either the specified time interval is spent or a message is received.
ValueTask: Why and How
async/await operators, just like the yield return operator, generate a finite state machine from a method, which means creating a new object – this doesn’t really matter most of the time, but can still create issues in some rare cases. One of these cases can occur with frequently-called methods – we’re talking tens and hundreds of thousands calls per second. If such a method is written in a way which makes it return the result while bypassing all await methods in most of the cases, .NET provides an optimization tool for this – the ValueTask structure. To understand how it works, let’s look at an example. Suppose there is a cache we access on a regular basis. If there are any values in it, we just return them; if there are no values – we try to get them from some slow IO. The latter should ideally be done asynchronously, so the whole method will be asynchronous. So, the most obvious way to implement this method will be as follows:
public async Task<string> GetById(int id) { if (cache.TryGetValue(id, out string val)) return val; return await RequestById(id); }
With a desire to optimize it a little bit and a concern for what Roslyn will generate when compiling this code, we could re-write the method like this:
public Task<string> GetById(int id) { if (cache.TryGetValue(id, out string val)) return Task.FromResult(val); return RequestById(id); }
However, the best solution in this case would be to optimize hot-path – specifically, getting dictionary values with no unnecessary allocations and no load on GC. Meanwhile, in those infrequent cases when we need to get data from IO, things will remain almost the same:
public ValueTask<string> GetById(int id) { if (cache.TryGetValue(id, out string val)) return new ValueTask<string>(val); return new ValueTask<string>(RequestById(id)); }
Let’s look at this code fragment more closely: if a value is present in the cache, we’ll create a structure; otherwise, the real task will be wrapped in a ValueTask. The path by which this code is executed is not important for the calling code: from the perspective of C# syntax, a ValueTask will behave just like a usual Task.
TaskScheduler: Controlling Task Execution Strategies
The next API I’d like to talk about is the TaskScheduler class and those derived from it. I already mentioned that TPL provides an ability to control how exactly Tasks are being distributed between threads. These strategies are defined in classes inheriting from TaskScheduler. Almost any strategy we may need can be found in the ParallelExtensionsExtras library. This library is developed by Microsoft, but is not a part of .NET – rather, it’s distributed as a Nuget package. Let’s have a look at some of the strategies:
- CurrentThreadTaskScheduler – executes Tasks on the current thread
- LimitedConcurrencyLevelTaskScheduler – limits the number of concurrently executed Tasks by using the N parameter which it accepts in the constructor
- OrderedTaskScheduler – is defined as LimitedConcurrencyLevelTaskScheduler(1), so Tasks will be executed sequentially.
- WorkStealingTaskScheduler – implements the work-stealing approach to task execution. Essentially, it can be viewed as a separate ThreadPool. This helps with the issue of ThreadPool being a static class in .NET — if it’s overloaded or used improperly in one part of the application, unpleasant side effects may occur in a different place. Real causes of such defects can be difficult to locate, so you may need to use separate WorkStealingTaskSchedulers in those parts of the application where ThreadPool usage can be aggressive and unpredictable.
- QueuedTaskScheduler – allows to execute tasks on a basis of a prioritized queue
- ThreadPerTaskScheduler – creates a separate thread for each Task that’s executed on it. This can be helpful for tasks the execution time of which cannot be estimated.
There is a very good article about TaskSchedulers on Microsoft’s blog, so feel free to check it out.
In Visual Studio, there is a Tasks window which can help with debugging everything related to Tasks. In this window, you can see the task’s state and jump to the currently executed line of code.
PLinq and the Parallel Class
Aside from Tasks and all things related to them, there are two additional tools in .NET we can find interesting – PLinq(Linq2Parallel) and the Parallel class. The first one promises parallel execution of all Linq operations on all threads. The number of threads can be configured by an extension method WithDegreeOfParallelism. Unfortunately, in most cases, PLinq in the default mode will not have enough information about the data source to provide a significant increase in speed. On the other hand, the cost of trying is very low: you only need to call AsParallel before the chain of Linq methods and carry out performance tests. Moreover, you can pass additional information about the nature of your data source to PLinq by using the Partitions mechanism. You can find more information here and here.
The Parallel static class provides methods for enumerating collections in parallel via Foreach, running the For cycle and executing several delegates in parallel to Invoke. Execution of the current thread will be stopped until the results are calculated. You can configure the number of threads by passing ParallelOptions as the last argument. TaskScheduler and CancellationToken can also be set with the help of options.
Summary
When I started writing this article based on my thesis and on the knowledge I gained while working after it, I didn’t think there would be this much information. Now, with the text editor reproachfully telling me that I’ve written almost 15 pages, I’d like to draw an intermediary conclusion. We will look at other techniques, APIs, visual tools and hidden hazards in the next article.
Conclusions:
- To effectively use the resources of modern PCs, you would need to know tools for working with threads, asynchrony and parallelism.
- There are many tools like this in .NET
- Not all of them were created at the same time, so you may often encounter some legacy code – but there are ways of transforming old APIs with little effort.
- In .NET, the Thread and ThreadPool classes are used for working with threads
- The Thread.Abort and Thread.Interrupt method, along with the Win32 API function TerminateThread, are dangerous and not recommended for use. Instead, it’s better to use CancellationTokens
- Threads are a valuable resource and their number is limited. You should avoid cases in which threads are occupied by waiting for events. The TaskCompletionSource class can help achieve this.
- Tasks are the most powerful and robust tool .NET has for working with parallelism and asynchrony.
- The async/await C# operators implement the concept of a non-blocking wait
- You can control how Tasks are distributed between threads with the help of classes derived from TaskScheduler
- The ValueTask structure can be used to optimize hot-paths and memory-traffic
- The Tasks and Threads windows in Visual Studio provide a lot of helpful information for debugging multi-threaded or asynchronous code
- PLinq is an awesome tool, but it may not have all required information about your data source – which can still be fixed with the partitioning mechanism
To be continued…
