
Hello, dear Habr users! This article is about Web 3.0 — the decentralized Internet. Web 3.0 introduces the concept of decentralization as the foundation of the modern Internet. Many computer systems and networks require security and decentralization features to meet their needs. A distributed registry using blockchain technology provides efficient solutions for decentralization.
Blockchain is a distributed registry. You can think of it as a huge database that lives forever, never changing over the course of time. The blockchain provides the basis for decentralized web applications and services.
However, the blockchain is more than just a database. It serves to increase security and trust between network members, enhancing online business transactions.
Byzantine consensus increases network reliability and solves the problem of consistency.
The scalability provided by DLT changes existing business networks.
Blockchain offers new, very important benefits:
- Prevents costly mistakes.
- Ensures transparent transactions.
- Digitalizes real goods.
- Enforces smart contracts.
- Increases the speed and security of payments.
We have developed a special PoE to research cryptographic protocols and improve existing DLT and blockchain solutions.
Most public registry systems lack the property of scalability, making their throughput rather low. For example, Ethereum processes only ~ 20 tx/s.
Many solutions were developed to increase scalability while maintaining decentralization. However, only 2 out of 3 advantages — scalability, security, and decentralization — can be achieved simultaneously.
The use of sidechains provides one of the most effective solutions.
The Plasma Concept
The Plasma concept boils down to the idea that a root chain processes a small number of commits from child chains, thereby acting as the most secure and final layer for storing all intermediate states. Each child chain works as its own blockchain with its own consensus algorithm, but there are a few important caveats.
- Smart contracts are created in a root chain and act as checkpoints for child chains within the root chain.
- A child chain is created and functions as its own blockchain with its own consensus. All states in the child chain are protected by fraud proofs that ensure all transitions between states are valid and apply a withdrawal protocol.
- Smart contracts specific to DApp or child chain application logic can be deployed in the child chain.
- Funds can be transferred from the root chain to the child chain.
Validators are given economic incentives to act honestly and send commitments to the root chain — the final transaction settlement layer.
As a result, DApp users working in the child chain do not have to interact with the root chain at all. In addition, they can place their money in the root chain whenever they want, even if the child chain is hacked. These exits from the child chain allow users to securely store their funds with Merkle proofs, confirming ownership of a certain amount of funds.
Plasma's main advantages are related to its ability to significantly facilitate calculations that overload the main chain. In addition, the Ethereum blockchain can handle more extensive and parallel data sets. Time removed from the root chain is also transferred to Ethereum nodes, which have lower processing and storage requirements.
Plasma Cash assigns unique serial numbers to online tokens. The advantages of this scheme include no need for confirmations, simpler support for all types of tokens (including Non-fungible tokens), and mitigation against mass exits from a child chain.
The concept of “mass exits” from a child chain is a problem faced by Plasma. In this scenario, coordinated simultaneous withdrawals from a child chain could potentially lead to insufficient computing power to withdraw all funds. As a result, users may lose funds.
Options for implementing Plasma

Basic Plasma has a lot of implementation options.
The main differences refer to:
- archiving information about state storage and presentation methods;
- token types (divisible, indivisible);
- transaction security;
- consensus algorithm type.
The main variations of Plasma include:
- UTXO-based Plasma — each transaction consists of inputs and outputs. A transaction can be conducted and spent. The list of unspent transactions is the state of a child chain itself.
- Account-based Plasma — this structure contains each account's reflection and balance. It is used in Ethereum, since each account can be of two types: a user account and a smart contract account. Simplicity is an important advantage of account-based Plasma. At the same time, the lack of scalability is a disadvantage. A special property, «nonce,» is used to prevent the execution of a transaction twice.
In order to understand the data structures used in the Plasma Cash blockchain and how commitments work, it is necessary to clarify the concept of Merkle Tree.
Merkle Trees and their use in Plasma
Merkle Tree is an extremely important data structure in the blockchain world. It allows us to capture a certain data set and hide the data, yet prove that some information was in the set. For example, if we have ten numbers, we could create a proof for these numbers and then prove that some particular number was in this set. This proof would have a small constant size, which makes it inexpensive to publish in Ethereum.
You can use this principle for a set of transactions, and prove that a particular transaction is in this set. This is precisely what an operator does. Each block consists of a transaction set that turns into a Merkle Tree. The root of this tree is a proof that is published in Ethereum along with each Plasma block.
Users should be able to withdraw their funds from the Plasma chain. For this, they send an “exit” transaction to Ethereum.
Plasma Cash uses a special Merkle Tree that eliminates the need to validate a whole block. It is enough to validate only those branches that correspond to the user's token.
To transfer a token, it is necessary to analyze its history and scan only those tokens that a certain user needs. When transferring a token, the user simply sends the entire history to another user, who can then authenticate the entire history and, most importantly, do it very quickly.

Plasma Cash data structures for state and history storage
It is advisable to use only selected Merkle Trees, because it is necessary to obtain inclusion and non-inclusion proofs for a transaction in a block. For example:
- Sparse Merkle Tree
- Patricia Tree
We have developed our own Sparse Merkle Tree and Patricia Tree implementations for our client.
A Sparse Merkle Tree is similar to a standard Merkle Tree, except that its data is indexed, and each data point is placed on a leaf that corresponds to this data point's index.
Suppose we have a four-leaf Merkle Tree. Let's fill this tree with letters A and D, for demonstration. The letter A is the first alphabet letter, so we will place it on the first leaf. Similarly, we will place D on the fourth leaf.
So what happens on the second and third leaves? They should be left empty. More precisely, a special value (for example, zero) is used instead of a letter.
The tree eventually looks like this:
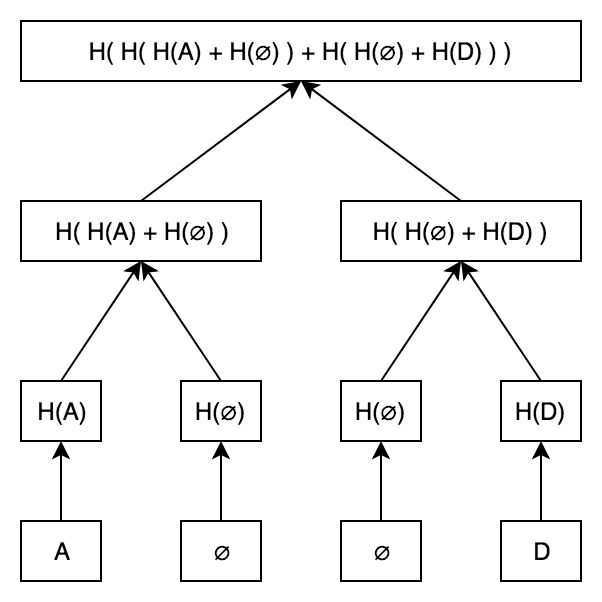
The inclusion proof works in the same way as in a regular Merkle Tree. What happens if we want to prove that C is not a part of this Merkle Tree? Elementary! We know that if C is a part of a tree, it would be on the third leaf. If C is not a part of the tree, then the third leaf should be zero.
All that is needed is a standard Merkle inclusion proof showing that the third leaf is zero.
The best feature of a Sparse Merkle Tree is that it provides repositories for key-values inside the Merkle Tree!
A part of the PoE protocol code constructs a Sparse Merkle Tree:
class SparseTree { //... buildTree() { if (Object.keys(this.leaves).length > 0) { this.levels = [] this.levels.unshift(this.leaves) for (let level = 0; level < this.depth; level++) { let currentLevel = this.levels[0] let nextLevel = {} Object.keys(currentLevel).forEach((leafKey) => { let leafHash = currentLevel[leafKey] let isEvenLeaf = this.isEvenLeaf(leafKey) let parentLeafKey = leafKey.slice(0, -1) let neighborLeafKey = parentLeafKey + (isEvenLeaf ? '1' : '0') let neighborLeafHash = currentLevel[neighborLeafKey] if (!neighborLeafHash) { neighborLeafHash = this.defaultHashes[level] } if (!nextLevel[parentLeafKey]) { let parentLeafHash = isEvenLeaf ? ethUtil.sha3(Buffer.concat([leafHash, neighborLeafHash])) : ethUtil.sha3(Buffer.concat([neighborLeafHash, leafHash])) if (level == this.depth - 1) { nextLevel['merkleRoot'] = parentLeafHash } else { nextLevel[parentLeafKey] = parentLeafHash } } }) this.levels.unshift(nextLevel) } } } }
This code is quite trivial. We have a key-value repository with an inclusion / non-inclusion proof.
In each iteration, a specific level of a final tree is filled, starting with the last one. Depending on whether the key of the current leaf is even or odd, we take two adjacent leaves and count the hash of the current level. If we reach the end, we would write down a single merkleRoot — a common hash.
You have to understand that this tree is filled with initially empty values. If we stored a huge amount of token IDs, we would have a huge tree size, and it would be long!
There are many remedies for this non-optimization, but we have decided to change this tree to a Patricia Tree.
A Patricia Tree is a combination of Radix Tree and Merkle Tree.
A Radix Tree data key stores the path to the data itself, which allows us to create an optimized data structure for memory.
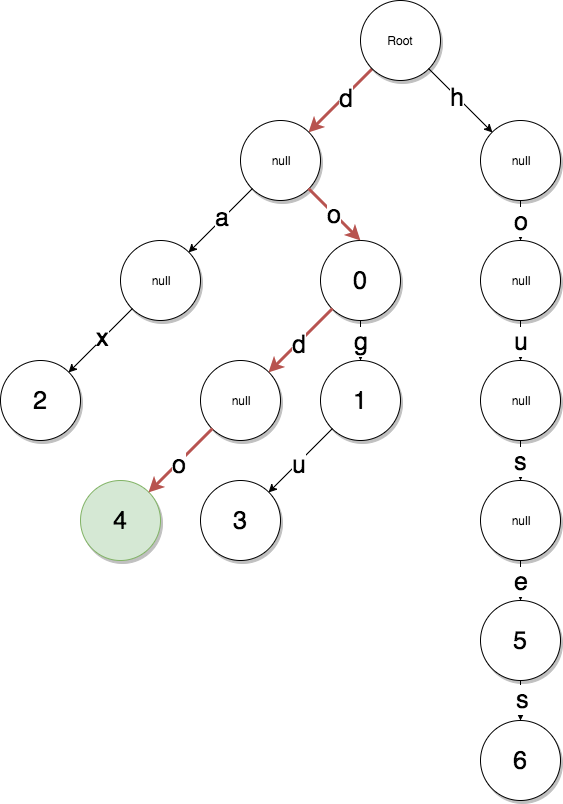
Here is an implementation developed for our client:
buildNode(childNodes, key = '', level = 0) { let node = {key} this.iterations++ if (childNodes.length == 1) { let nodeKey = level == 0 ? childNodes[0].key : childNodes[0].key.slice(level - 1) node.key = nodeKey let nodeHashes = Buffer.concat([Buffer.from(ethUtil.sha3(nodeKey)), childNodes[0].hash]) node.hash = ethUtil.sha3(nodeHashes) return node } let leftChilds = [] let rightChilds = [] childNodes.forEach((node) => { if (node.key[level] == '1') { rightChilds.push(node) } else { leftChilds.push(node) } }) if (leftChilds.length && rightChilds.length) { node.leftChild = this.buildNode(leftChilds, '0', level + 1) node.rightChild = this.buildNode(rightChilds, '1', level + 1) let nodeHashes = Buffer.concat([Buffer.from(ethUtil.sha3(node.key)), node.leftChild.hash, node.rightChild.hash]) node.hash = ethUtil.sha3(nodeHashes) } else if (leftChilds.length && !rightChilds.length) { node = this.buildNode(leftChilds, key + '0', level + 1) } else if (!leftChilds.length && rightChilds.length) { node = this.buildNode(rightChilds, key + '1', level + 1) } else if (!leftChilds.length && !rightChilds.length) { throw new Error('invalid tree') } return node }
We moved recursively and built the separate left and right subtrees. A key was built as a path in this tree.
This solution is even more trivial. It is well-optimized and works faster. In fact, a Patricia Tree may be optimized even more by introducing new node types — extension node, branch node, and so on, as done in the Ethereum protocol. But the current implementation satisfies all our requirements — we have a fast and memory-optimized data structure.
By implementing these data structures in our client’s project, we have made Plasma Cash scaling possible. This allows us to check a token’s history and inclusion / non-inclusion of the token in a tree, greatly accelerating the validation of blocks and the Plasma Child Chain itself.
