Всем доброго здравия!
При обучении студентов разработке встроенного программного обеспечения для микроконтроллеров в университете я использую С++ и иногда даю особо интересующимся студентам всякие задачки для определения особобольных на голову одаренных учеников.
В очередной раз таким студентам была дана задача поморгать 4 светодиодами, используя язык С++ 17 и стандартную библиотеку С++, без подключения дополнительных библиотек, типа CMSIS и их заголовочных файлов с описанием структур регистров и так далее… Побеждает тот, у кого код в ROM будет занимать наименьший размер и меньше всего затрачено ОЗУ. Оптимизация компилятора при этом не должна быть выше Medium. Компилятор IAR 8.40.1.
Победительедет на Канары получает 5 за экзамен.
Сам я до этого тоже эту задачу не решал, поэтому расскажу как её решили студенты и что получилось у меня. Предупреждаю сразу, навряд ли такой код можно будет использовать в реальных приложениях, потому и разместил публикацию в раздел «Ненормальное программирование», хотя кто знает.
Есть 4 светодиода на портах GPIOA.5, GPIOC.5, GPIOC.8, GPIOC.9. Ими нужно поморгать. Чтобы было с чем сравнивать мы взяли код написанный на Си:
Функция
Предполагается, что порты уже настроены на выход и на них подано тактирование.
А также сразу скажу, что bitbanging не использовался, чтобы код был переносимым.
Этот код занимает 8 байт на стеке и 256 байт в ROM на Medium оптимизации
255 байт из-за того, что часть памяти ушла под таблицу векторов прерывания, вызовы функций IAR для инициализации блока с плавающей точкой, всякие отладочные функции и функция __low_level_init, где собственно порты настроились.
Итак, полные требования:
Вообще решений было несколько, я покажу только одно… оно не оптимальное, но мне понравилось.
Так как нельзя использовать заголовочные файлы, студенты первым делом сделали класс
Как видно они сразу определили класс
Затем определили структуру для
Затем они сделали массив светодиодов, которые сидят на конкретных ножках порта и пробежались по нему вызвав метод
Статистика их кода на Medium оптимизации:
Хорошее решение, но памяти занимает много :)
Я конечно решил не искать простых путей и решил действовать по серьезному :).
Светодиоды находятся на разных портах и разных ножках. Первое что необходимо, это сделать класс
В качестве параметра шаблона у него будет адрес порта. В заголовочнике
Чтобы поморгать нужен метод Toggle(const std::uint8_t bit), который будет переключать необходимый бит с помощью операции исключающее ИЛИ. Метод должен быть статическим, добавляем его в класс:
Отлично
Плохо, что мы можем передать любую чепуху типа
Теперь шаблон инстанциируется, только если наш класс имеет базовый класс
По идее уже можно использовать эти классы, давайте посмотрим, что получится без оптимизации:
Откуда взялись эти дополнительные 16 байт в ОЗУ и 16 байт в ROM. Они взялись из того, факта, что мы передаем в функцию Toggle(const std::uint8_t bit) класса Port параметр bit, и компилятор, при входе в функцию main сохраняет на стеке 4 дополнительных регистра, через которые передает этот параметр, потом использует эти регистры в которых сохраняется значения номера ножки для каждого Pin и при выходе из main восстанавливает эти регистры из стека. И хотя по сути это какая-то полностью бесполезная работа, так как функции встроенные, но компилятор действует в полном соответствии со стандартом.
От этого можно избавиться убрав класс порт вообще, передать адрес порта в качестве параметра шаблона для класса
Но это выглядит не совсем хорошо и удобно для пользователя. Поэтому будем надеяться, что компилятор уберет это ненужное сохранение регистров при небольшой оптимизации.
Ставим оптимизацию на Medium и смотрим результат:
Вау вау вау… у нас на 4 байта меньше
Как такое может быть? Давайте взглянем на ассемблер в отладчике для С++ кода(слева) и Си кода(справа):
Видно, что во-первых, компилятор все функции сделал встроенные, теперь нет никаких вызовов вообще, а во вторых, он оптимизировал использование регистров. Видно, в случае с Си кодом, для хранения адресов портов компилятор использует то регистр R1, то R2 и делает дополнительную операции каждый раз после переключения бита (сохранить адрес в регистре то в R1, то в R2). Во втором же случае он использует только регистр R1, а поскольку 3 последних вызова на переключение всегда с порта C, то надобности сохранять тот же самый адрес порта С в регистре уже нет. В итоге экономится 2 команды и 4 байта.
Вот оно чудо современных компиляторов :) Ну да ладно. В принципе можно было на этом остановится, но пойдем дальше. Оптимизировать еще что-то, думаю, уже не выйдет, хотя возможно не прав, если есть идеи, пишите в комментариях. А вот с количеством кода в main() можно поработать.
Теперь хочется, чтобы все светодиоды были бы где нибудь в контейнере, и можно было бы вызывать метод, переключить все… Вот как-то так:
Мы не будем тупо вставлять переключение 4 светодиодов в функцию LedsContainer::ToggleAll, потому что это неинтересно :). Мы хотим светодиоды положить в контейнер и потом пройтись по ним и вызывать у каждого метод Toggle().
Студенты использовали массив для того, чтобы хранить указатели на светодиоды. Но у меня разные типы, например:уделать выиграть студентов мне не удастся.
Поэтому будем использовать кортеж. Он позволяет хранить у себя объекты разных типов. Выглядеть это дело будет выглядеть так:
Отлично есть контейнер, он хранит все светодиоды. Теперь добавим в него метод
Просто так пройтись по элементам кортежа нельзя, так как получение элемента кортежа должно происходить только на этапе компиляции. Для доступа к элементам кортежа есть темплейтный метод get. Ну т.е. если напишем так
Можно былоутереть студентам нос и просто написать так:
Но мы не хотим напрягать программиста, который будет поддерживать этот код и позволять делать ему дополнительную работу, тратя ресурсы его компании, скажем в случае, если появится еще один светодиод. Придется добавлять код в двух местах, в кортеж и в этот метод — а это нехорошо и владелец компании будет не очень доволен. Поэтому обходим кортеж с помощью методов помощников:
Выглядит страшновато, но я предупреждал в начале статьи, что способшизанутый не очень обычный…
Вся эта магия сверху на этапе компиляции делает буквально следующее:
Вперед компилировать и проверять размер кода без оптимизации:
Видим, что по памяти перебор, на 18 байтов больше. Проблемы все те же, плюсом еще 12 байт. Не стал разбираться откуда они… может кто пояснит.
Теперь тоже самое на Medium оптимизации и о чудо… получили код идентичный С++ реализации в лоб и оптимальнее Си кода.
Как видите победил я, ипоехал на Канары и довольный отдыхаю в Челябинске :), но студенты тоже молодцы, экзамен сдали успешно!
Кому интересно, код тут
Где можно такое использовать, ну я придумал, например такое, у нас есть параметры в EEPROM памяти и класс описывающий эти параметры (Читать, писать, инициализировать в начальное значение). Класс шаблонный, типа
P.S. Надо признаться, что на максимальной оптимизации этот код по размеру получается такой же как на Си и на моем решении. И все потуги программиста по улучшению кода сводятся к одному и тому же коду на ассемблере.
P.S1 Спасибо 0xd34df00d за дельный совет. Можно упростить распаковку кортежа с помощью
К сожалению в IAR std::apply в текущей версии еще не реализован, но работать будет также, см на реализацию с std::apply
При обучении студентов разработке встроенного программного обеспечения для микроконтроллеров в университете я использую С++ и иногда даю особо интересующимся студентам всякие задачки для определения особо
В очередной раз таким студентам была дана задача поморгать 4 светодиодами, используя язык С++ 17 и стандартную библиотеку С++, без подключения дополнительных библиотек, типа CMSIS и их заголовочных файлов с описанием структур регистров и так далее… Побеждает тот, у кого код в ROM будет занимать наименьший размер и меньше всего затрачено ОЗУ. Оптимизация компилятора при этом не должна быть выше Medium. Компилятор IAR 8.40.1.
Победитель
Сам я до этого тоже эту задачу не решал, поэтому расскажу как её решили студенты и что получилось у меня. Предупреждаю сразу, навряд ли такой код можно будет использовать в реальных приложениях, потому и разместил публикацию в раздел «Ненормальное программирование», хотя кто знает.
Условия задачи
Есть 4 светодиода на портах GPIOA.5, GPIOC.5, GPIOC.8, GPIOC.9. Ими нужно поморгать. Чтобы было с чем сравнивать мы взяли код написанный на Си:
void delay() {
for (int i = 0; i < 1000000; ++i){
}
}
int main() {
for(;;) {
GPIOA->ODR ^= (1 << 5);
GPIOC->ODR ^= (1 << 5);
GPIOC->ODR ^= (1 << 8);
GPIOC->ODR ^= (1 << 9);
delay();
}
return 0 ;
}Функция
delay() здесь чисто формальная, обычный цикл, её оптимизировать нельзя. Предполагается, что порты уже настроены на выход и на них подано тактирование.
А также сразу скажу, что bitbanging не использовался, чтобы код был переносимым.
Этот код занимает 8 байт на стеке и 256 байт в ROM на Medium оптимизации
255 bytes of readonly code memory
1 byte of readonly data memory
8 bytes of readwrite data memory
255 байт из-за того, что часть памяти ушла под таблицу векторов прерывания, вызовы функций IAR для инициализации блока с плавающей точкой, всякие отладочные функции и функция __low_level_init, где собственно порты настроились.
Итак, полные требования:
- Функция main() должна содержать как можно меньше кода
- Нельзя использовать макросы
- Компилятор IAR 8.40.1 поддерживающий С++17
- Нельзя использовать заголовочные файлы CMSIS, типа "#include «stm32f411xe.h»
- Можно использовать директиву __forceinline для встраиваемых функций
- Оптимизация компилятора Medium
Решение студентов
Вообще решений было несколько, я покажу только одно… оно не оптимальное, но мне понравилось.
Так как нельзя использовать заголовочные файлы, студенты первым делом сделали класс
Gpio, который должен хранить ссылку на регистры порта по их адресам. Для этого они используют оверлей структуры, скорее всего идею взяли отсюда: Structure overlay:class Gpio {
public:
__forceinline inline void Toggle(const std::uint8_t bitNum) volatile {
Odr ^= bitNum ;
}
private:
volatile std::uint32_t Moder;
volatile std::uint32_t Otyper;
volatile std::uint32_t Ospeedr;
volatile std::uint32_t Pupdr;
volatile std::uint32_t Idr;
volatile std::uint32_t Odr;
//Проверка что структура выравнена
static_assert(sizeof(Gpio) == sizeof(std::uint32_t) * 6);
} ;Как видно они сразу определили класс
Gpio с атрибутами, которые должны быть расположены по адресам соответствующих регистров и метод для переключения состояния по номеру ножки:Затем определили структуру для
GpioPin, содержащую указатель на Gpio и номер ножки:struct GpioPin
{
volatile Gpio* port ;
std::uint32_t pinNum ;
} ;Затем они сделали массив светодиодов, которые сидят на конкретных ножках порта и пробежались по нему вызвав метод
Toggle() каждого светодиода:const GpioPin leds[] = {{reinterpret_cast<volatile Gpio*>(GpioaBaseAddr), 5},
{reinterpret_cast<volatile Gpio*>(GpiocBaseAddr), 5},
{reinterpret_cast<volatile Gpio*>(GpiocBaseAddr), 9},
{reinterpret_cast<volatile Gpio*>(GpiocBaseAddr), 9}
} ;
struct LedsDriver {
__forceinline static inline void ToggelAll() {
for (auto& it: leds) {
it.port->Toggle(it.pinNum);
}
}
} ;Ну собственно и весь код:
constexpr std::uint32_t GpioaBaseAddr = 0x4002'0000 ;
constexpr std::uint32_t GpiocBaseAddr = 0x4002'0800 ;
class Gpio {
public:
__forceinline inline void Toggle(const std::uint8_t bitNum) volatile {
Odr ^= bitNum ;
}
private:
volatile std::uint32_t Moder;
volatile std::uint32_t Otyper;
volatile std::uint32_t Ospeedr;
volatile std::uint32_t Pupdr;
volatile std::uint32_t Idr;
volatile std::uint32_t Odr;
} ;
//Проверка что структура выравнена
static_assert(sizeof(Gpio) == sizeof(std::uint32_t) * 6);
struct GpioPin {
volatile Gpio* port ;
std::uint32_t pinNum ;
} ;
const GpioPin leds[] = {{reinterpret_cast<volatile Gpio*>(GpioaBaseAddr), 5},
{reinterpret_cast<volatile Gpio*>(GpiocBaseAddr), 5},
{reinterpret_cast<volatile Gpio*>(GpiocBaseAddr), 9},
{reinterpret_cast<volatile Gpio*>(GpiocBaseAddr), 9}
} ;
struct LedsDriver {
__forceinline static inline void ToggelAll() {
for (auto& it: leds) {
it.port->Toggle(it.pinNum);
}
}
} ;
int main() {
for(;;) {
LedsContainer::ToggleAll() ;
delay();
}
return 0 ;
}Статистика их кода на Medium оптимизации:
275 bytes of readonly code memory
1 byte of readonly data memory
8 bytes of readwrite data memory
Хорошее решение, но памяти занимает много :)
Решение мое
Я конечно решил не искать простых путей и решил действовать по серьезному :).
Светодиоды находятся на разных портах и разных ножках. Первое что необходимо, это сделать класс
Port, но чтобы избавиться от указателей и переменных, которые занимают ОЗУ, нужно использовать статические методы. Класс порт может выглядеть так:template <std::uint32_t addr>
struct Port {
//здесь скоро что-то будет
};В качестве параметра шаблона у него будет адрес порта. В заголовочнике
"#include "stm32f411xe.h", например для порта А, он определен как GPIOA_BASE. Но заголовочники нам использовать запрещено, поэтому просто нужно сделать свою константу. В итоге класс можно будет использовать так:constexpr std::uint32_t GpioaBaseAddr = 0x4002'0000 ;
constexpr std::uint32_t GpiocBaseAddr = 0x4002'0800 ;
using PortA = Port<GpioaBaseAddr> ;
using PortC = Port<GpiocBaseAddr> ;
Чтобы поморгать нужен метод Toggle(const std::uint8_t bit), который будет переключать необходимый бит с помощью операции исключающее ИЛИ. Метод должен быть статическим, добавляем его в класс:
template <std::uint32_t addr>
struct Port {
//сразу применяем директиву __forceinline, чтобы компилятор воспринимал эту функцию как встроенную
__forceinline inline static void Toggle(const std::uint8_t bitNum) {
*reinterpret_cast<std::uint32_t*>(addr+20) ^= (1 << bitNum) ; //addr + 20 адрес ODR регистра
}
};Отлично
Port<> есть, он может переключать состояние ножки. Светодиод сидит на конкретной ножке, поэтому логично сделать класс Pin, у которого в качестве параметров шаблона будет Port<> и номер ножки. Поскольку тип Port<> у нас шаблонный, т.е. разный для разного порта, то передавать мы можем только универсальный тип T.template <typename T, std::uint8_t pinNum>
struct Pin {
__forceinline inline static void Toggle() {
T::Toggle(pinNum) ;
}
} ;Плохо, что мы можем передать любую чепуху типа
T у которой есть метод Toggle() и это будет работать, хотя предполагается что передавать мы должны только тип Port<>. Чтобы от этого защититься, сделаем так, чтобы Port<> наследовался от базового класса PortBase, а в шаблоне будем проверять, что наш переданный тип действительно базируется на PortBase. Получаем следующее:constexpr std::uint32_t OdrAddrShift = 20U;
struct PortBase {
};
template <std::uint32_t addr>
struct Port: PortBase {
__forceinline inline static void Toggle(const std::uint8_t bit) {
*reinterpret_cast<std::uint32_t*>(addr ) ^= (1 << bit) ;
}
};
template <typename T, std::uint8_t pinNum,
class = typename std::enable_if_t<std::is_base_of<PortBase, T>::value>> //Вот и защита
struct Pin {
__forceinline inline static void Toggle() {
T::Toggle(pinNum) ;
}
} ;Теперь шаблон инстанциируется, только если наш класс имеет базовый класс
PortBase.По идее уже можно использовать эти классы, давайте посмотрим, что получится без оптимизации:
using PortA = Port<GpioaBaseAddr> ;
using PortC = Port<GpiocBaseAddr> ;
using Led1 = Pin<PortA, 5> ;
using Led2 = Pin<PortC, 5> ;
using Led3 = Pin<PortC, 8> ;
using Led4 = Pin<PortC, 9> ;
int main() {
for(;;) {
Led1::Toggle();
Led2::Toggle();
Led3::Toggle();
Led4::Toggle();
delay();
}
return 0 ;
}271 bytes of readonly code memory
1 byte of readonly data memory
24 bytes of readwrite data memory
Откуда взялись эти дополнительные 16 байт в ОЗУ и 16 байт в ROM. Они взялись из того, факта, что мы передаем в функцию Toggle(const std::uint8_t bit) класса Port параметр bit, и компилятор, при входе в функцию main сохраняет на стеке 4 дополнительных регистра, через которые передает этот параметр, потом использует эти регистры в которых сохраняется значения номера ножки для каждого Pin и при выходе из main восстанавливает эти регистры из стека. И хотя по сути это какая-то полностью бесполезная работа, так как функции встроенные, но компилятор действует в полном соответствии со стандартом.
От этого можно избавиться убрав класс порт вообще, передать адрес порта в качестве параметра шаблона для класса
Pin, а внутри метода Toggle() высчитывать адрес регистра ODR:constexpr std::uint32_t OdrAddrShift = 20U;
template <std::uint32_t addr, std::uint8_t pinNum,
struct Pin {
__forceinline inline static void Toggle() {
*reinterpret_cast<std::uint32_t*>(addr + OdrAddrShift ) ^= (1 << bit) ;
}
} ;
using Led1 = Pin<GpioaBaseAddr, 5> ; Но это выглядит не совсем хорошо и удобно для пользователя. Поэтому будем надеяться, что компилятор уберет это ненужное сохранение регистров при небольшой оптимизации.
Ставим оптимизацию на Medium и смотрим результат:
251 bytes of readonly code memory
1 byte of readonly data memory
8 bytes of readwrite data memory
Вау вау вау… у нас на 4 байта меньше
сишного кода
255 bytes of readonly code memory
1 byte of readonly data memory
8 bytes of readwrite data memory
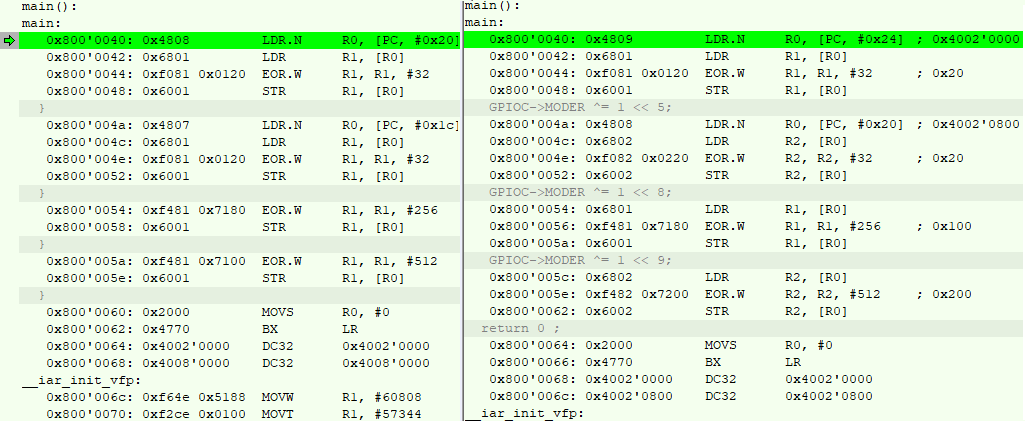
Как такое может быть? Давайте взглянем на ассемблер в отладчике для С++ кода(слева) и Си кода(справа):
Видно, что во-первых, компилятор все функции сделал встроенные, теперь нет никаких вызовов вообще, а во вторых, он оптимизировал использование регистров. Видно, в случае с Си кодом, для хранения адресов портов компилятор использует то регистр R1, то R2 и делает дополнительную операции каждый раз после переключения бита (сохранить адрес в регистре то в R1, то в R2). Во втором же случае он использует только регистр R1, а поскольку 3 последних вызова на переключение всегда с порта C, то надобности сохранять тот же самый адрес порта С в регистре уже нет. В итоге экономится 2 команды и 4 байта.
Вот оно чудо современных компиляторов :) Ну да ладно. В принципе можно было на этом остановится, но пойдем дальше. Оптимизировать еще что-то, думаю, уже не выйдет, хотя возможно не прав, если есть идеи, пишите в комментариях. А вот с количеством кода в main() можно поработать.
Теперь хочется, чтобы все светодиоды были бы где нибудь в контейнере, и можно было бы вызывать метод, переключить все… Вот как-то так:
int main() {
for(;;) {
LedsContainer::ToggleAll() ;
delay();
}
return 0 ;
}Мы не будем тупо вставлять переключение 4 светодиодов в функцию LedsContainer::ToggleAll, потому что это неинтересно :). Мы хотим светодиоды положить в контейнер и потом пройтись по ним и вызывать у каждого метод Toggle().
Студенты использовали массив для того, чтобы хранить указатели на светодиоды. Но у меня разные типы, например:
Pin<PortA, 5>, Pin<PortC, 5>, и указатели на разные типы я хранить в массиве не могу. Можно сделать виртуальный базовый класс, для всех Pin, но тогда появится таблица виртуальных функций и Поэтому будем использовать кортеж. Он позволяет хранить у себя объекты разных типов. Выглядеть это дело будет выглядеть так:
class LedsContainer {
private:
constexpr static auto records = std::make_tuple (
Pin<PortA, 5>{},
Pin<PortC, 5>{},
Pin<PortC, 8>{},
Pin<PortC, 9>{}
) ;
using tRecordsTuple = decltype(records) ;
}Отлично есть контейнер, он хранит все светодиоды. Теперь добавим в него метод
ToggleAll():class LedsContainer {
public:
__forceinline static inline void ToggleAll() {
//сейчас придумаем как тут перебрать все элементы кортежа
}
private:
constexpr static auto records = std::make_tuple (
Pin<PortA, 5>{},
Pin<PortC, 5>{},
Pin<PortC, 8>{},
Pin<PortC, 9>{}
) ;
using tRecordsTuple = decltype(records) ;
}Просто так пройтись по элементам кортежа нельзя, так как получение элемента кортежа должно происходить только на этапе компиляции. Для доступа к элементам кортежа есть темплейтный метод get. Ну т.е. если напишем так
std::get<0>(records).Toggle(), то вызовется метод Toggle() для объекта класса Pin<PortA, 5>, если std::get<1>(records).Toggle(), то вызовется метод Toggle() для объекта класса Pin<PortС, 5> и так далее…Можно было
__forceinline static inline void ToggleAll() {
std::get<0>(records).Toggle();
std::get<1>(records).Toggle();
std::get<2>(records).Toggle();
std::get<3>(records).Toggle();
} Но мы не хотим напрягать программиста, который будет поддерживать этот код и позволять делать ему дополнительную работу, тратя ресурсы его компании, скажем в случае, если появится еще один светодиод. Придется добавлять код в двух местах, в кортеж и в этот метод — а это нехорошо и владелец компании будет не очень доволен. Поэтому обходим кортеж с помощью методов помощников:
class class LedsContainer {
friend int main() ;
public:
__forceinline static inline void ToggleAll() {
// создаем последовательность индексов 3,2,1,0 и вызываем соответствующий метод, куда передается эта последовательность
visit(std::make_index_sequence<std::tuple_size<tRecordsTuple>::value>());
}
private:
__forceinline template<std::size_t... index>
static inline void visit(std::index_sequence<index...>) {
Pass((std::get<index>(records).Toggle(), true)...); // распаковываем в последовательность get<3>(records).Toggle(), get<2>(records).Toggle(), get<1>(records).Toggle(), get<0>(records).Toggle()
}
__forceinline template<typename... Args>
static void inline Pass(Args... ) {//Вспомогательный метод для распаковки вариативного шаблона
}
constexpr static auto records = std::make_tuple (
Pin<PortA, 5>{},
Pin<PortC, 5>{},
Pin<PortC, 8>{},
Pin<PortC, 9>{}
) ;
using tRecordsTuple = decltype(records) ;
}Выглядит страшновато, но я предупреждал в начале статьи, что способ
Вся эта магия сверху на этапе компиляции делает буквально следующее:
//Это вызов
LedsContainer::ToggleAll() ;
//Преобразуется в эти 4 вызова:
Pin<PortС, 9>().Toggle() ;
Pin<PortС, 8>().Toggle() ;
Pin<PortC, 5>().Toggle() ;
Pin<PortA, 5>().Toggle() ;
//А поскольку у нас метод Toggle() inline, то в это:
*reinterpret_cast<std::uint32_t*>(0x40020814 ) ^= (1 << 9) ;
*reinterpret_cast<std::uint32_t*>(0x40020814 ) ^= (1 << 8) ;
*reinterpret_cast<std::uint32_t*>(0x40020814 ) ^= (1 << 5) ;
*reinterpret_cast<std::uint32_t*>(0x40020014 ) ^= (1 << 5) ;Вперед компилировать и проверять размер кода без оптимизации:
Код который компилим
#include <cstddef>
#include <tuple>
#include <utility>
#include <cstdint>
#include <type_traits>
//#include "stm32f411xe.h"
#define __forceinline _Pragma("inline=forced")
constexpr std::uint32_t GpioaBaseAddr = 0x4002'0000 ;
constexpr std::uint32_t GpiocBaseAddr = 0x4002'0800 ;
constexpr std::uint32_t OdrAddrShift = 20U;
struct PortBase
{
};
template <std::uint32_t addr>
struct Port: PortBase
{
__forceinline inline static void Toggle(const std::uint8_t bit)
{
*reinterpret_cast<std::uint32_t*>(addr + OdrAddrShift) ^= (1 << bit) ;
}
};
template <typename T, std::uint8_t pinNum,
class = typename std::enable_if_t<std::is_base_of<PortBase, T>::value>>
struct Pin
{
__forceinline inline static void Toggle()
{
T::Toggle(pinNum) ;
}
} ;
using PortA = Port<GpioaBaseAddr> ;
using PortC = Port<GpiocBaseAddr> ;
//using Led1 = Pin<PortA, 5> ;
//using Led2 = Pin<PortC, 5> ;
//using Led3 = Pin<PortC, 8> ;
//using Led4 = Pin<PortC, 9> ;
class LedsContainer {
friend int main() ;
public:
__forceinline static inline void ToggleAll() {
// создаем последовательность индексов 3,2,1,0 и вызываем соответствующий метод, куда передается эта последовательность
visit(std::make_index_sequence<std::tuple_size<tRecordsTuple>::value>());
}
private:
__forceinline template<std::size_t... index>
static inline void visit(std::index_sequence<index...>) {
Pass((std::get<index>(records).Toggle(), true)...);
}
__forceinline template<typename... Args>
static void inline Pass(Args... ) {
}
constexpr static auto records = std::make_tuple (
Pin<PortA, 5>{},
Pin<PortC, 5>{},
Pin<PortC, 8>{},
Pin<PortC, 9>{}
) ;
using tRecordsTuple = decltype(records) ;
} ;
void delay() {
for (int i = 0; i < 1000000; ++i){
}
}
int main() {
for(;;) {
LedsContainer::ToggleAll() ;
//GPIOA->ODR ^= 1 << 5;
//GPIOC->ODR ^= 1 << 5;
//GPIOC->ODR ^= 1 << 8;
//GPIOC->ODR ^= 1 << 9;
delay();
}
return 0 ;
}Ассемблерный пруф, распаковалось как планировали: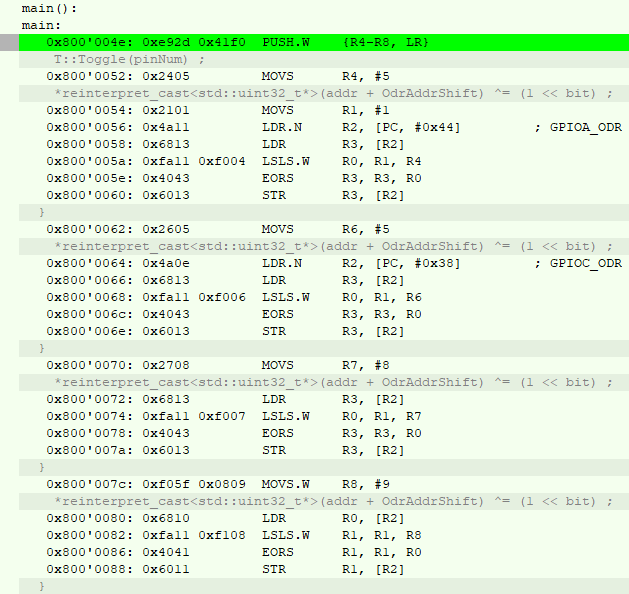
Видим, что по памяти перебор, на 18 байтов больше. Проблемы все те же, плюсом еще 12 байт. Не стал разбираться откуда они… может кто пояснит.
283 bytes of readonly code memory
1 byte of readonly data memory
24 bytes of readwrite data memory
Теперь тоже самое на Medium оптимизации и о чудо… получили код идентичный С++ реализации в лоб и оптимальнее Си кода.
251 bytes of readonly code memory
1 byte of readonly data memory
8 bytes of readwrite data memory
Ассемблер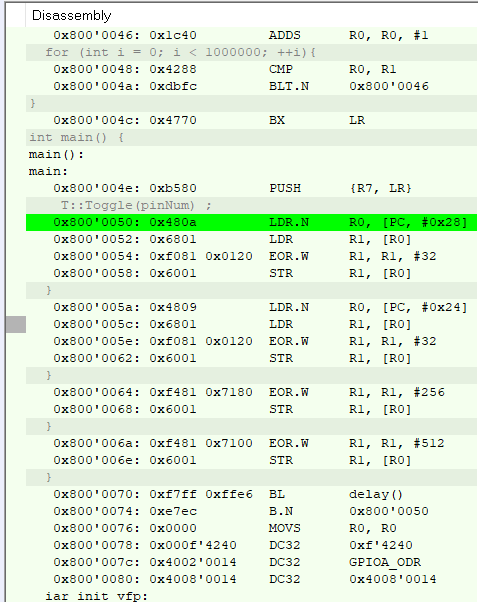
Как видите победил я, и
Кому интересно, код тут
Где можно такое использовать, ну я придумал, например такое, у нас есть параметры в EEPROM памяти и класс описывающий эти параметры (Читать, писать, инициализировать в начальное значение). Класс шаблонный, типа
Param<float<>>, Param<int<>> и нужно, например, все параметры сбросить в default значения. Как раз тут и можно все их положить в кортеж, так как тип разный и вызвать у каждого параметра метод SetToDefault(). Правда, если таких параметров будет 100, то ПЗУ отъестся много, зато ОЗУ не пострадает.P.S. Надо признаться, что на максимальной оптимизации этот код по размеру получается такой же как на Си и на моем решении. И все потуги программиста по улучшению кода сводятся к одному и тому же коду на ассемблере.
P.S1 Спасибо 0xd34df00d за дельный совет. Можно упростить распаковку кортежа с помощью
std::apply(). Код функции ToggleAll() тогда упроститься до такого: __forceinline static inline void ToggleAll()
{
std::apply([](auto... args) { (args.Toggle(), ...); }, records);
} К сожалению в IAR std::apply в текущей версии еще не реализован, но работать будет также, см на реализацию с std::apply
