Привет, Хабр.
В первой части была рассмотрена NVIDIA Jetson Nano — плата в форм-факторе Raspberry Pi, ориентированная на производительные вычисления с помощью GPU. Настала пора протестировать плату в том, для чего она создавалась — для AI-ориентированных расчетов.

Рассмотрим, как идут на плате разные задачи, вроде классификации изображений или распознавания пешеходов или котиков (куда же без них). Для всех тестов приведены исходники, которые можно запустить на десктопе, Jetson Nano или Raspberry Pi. Для тех, кому интересно, продолжение под катом.
Есть два способа использования этой платы. Первый — это запустить стандартные фреймворки, типа Keras и Tensorflow. Оно работать в принципе, будет, но как уже было видно из первой части, Jetson Nano, разумеется, уступает полноценной десктопной или ноутбучной видеокарте. Задачу оптимизации модели пользователю придется взять на себя. Второй способ — взять готовые классы, поставляемые вместе с платой. Оно проще и работает «из коробки», минус в том, что в гораздо большей степени скрыты все детали реализации, к тому же, придется изучить и использовать custom-sdk, который кроме этих плат, нигде больше не пригодится. Впрочем, мы посмотрим оба способа, начнем с первого.
Рассмотрим задачу распознавания изображений. Для этого воспользуемся поставляемой вместе с Keras моделью ResNet50 (эта модель была победителем ImageNet Challenge в 2015). Чтобы ее использовать, достаточно нескольких строчек кода.
Я даже не стал убирать код под спойлер, т.к. он весьма небольшой. Как можно видеть, изображение сначала ресайзится к 224х224 (таков входной формат сети), в завершении, функция predict делает всю работу.
Берем фотографию котика и запускаем программу.

Результаты:
В очередной раз огорчившись своему знанию английского (интересно, многие ли не-нативы знают что такое «tabby»?), сверил вывод со словарем, да, все работает.
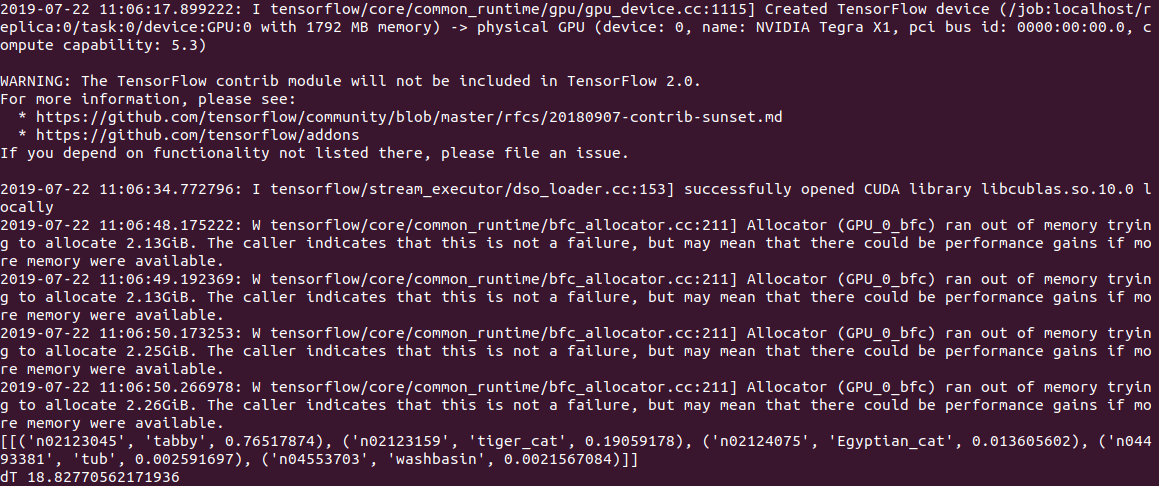
Время выполнения кода на ПК составило 0.5с при расчетах на CPU и 2с (!) при расчете на GPU. Судя по логу, проблема то ли в модели, то ли в Tensorflow, но при запуске код пытается выделить много памяти, получая на выходе несколько warnings вида «Allocator (GPU_0_bfc) ran out of memory trying to allocate 2.13GiB with freed_by_count=0.». Это warning а не error, код при этом работает, но гораздо медленнее чем должен был бы.
На Jetson Nano все еще медленнее: 2.8c на CPU и 18.8с на GPU, вывод при этом выглядит так:
В общем, даже 3с на изображение, это пока не real time. Установка рекомендуемой на stack overflow опции gpu_options.allow_growth не помогает, если кто знает другой способ, напишите в комментариях.
Правка: как подсказали в комментариях, первый запуск tensorflow всегда выполняется долго, и измерять по нему время некорректно. Действительно, при обработке второго и последующего файлов, результаты гораздо лучше — 0.6с без GPU и 0.2с с GPU. На десктопе быстродействие составляет, впрочем, 2.0с и 0.05с соответственно.
Удобной особенностью ResNet50 является то, что при первом старте она выкачивает всю модель на диск (порядка 100Мб), далее код работает полностью автономно, без регистраций и SMS. Что особенно приятно, учитывая что большинство современных AI-сервисов работают только на сервере, и без интернета устройство превращается в «тыкву».
Рассмотрим следующую задачу. Создадим с помощью Keras нейронную сеть, способную различать на фото кошек и собак. Это будет сверточная нейронная сеть (CNN — Convolutional Neural Network), дизайн сети возьмем из этой публикации. Обучающий набор изображений кошек и собак уже включен в пакет tensorflow_datasets, так что фотографировать их самостоятельно не придется.
Загружаем набор изображений и разбиваем его на три блока — обучающий, проверочный и тестовый. Каждую картинку «нормализуем», приводя цвета к диапазону 0..1.
Напишем функцию генерации сверточной нейросети.
Теперь мы можем запустить обучение сети на нашем наборе «кошки-собаки». Обучение длится долго (минут 20 на GPU и 1-2 часа на CPU), так что по окончании сохраняем модель в файл.
Кстати, попытка запустить обучение прямо на Jetson Nano провалилась — плата минут через 5 перегрелась и повисла. Для ресурсоемких расчетов к плате необходим кулер, хотя по большому счету, делать такие задачи прямо на Jetson Nano смысла нет — модель можно обучить на ПК, а готовый сохраненный файл использовать на Nano.
Тут вылез еще один подводный камень — на ПК установлена библиотека tensowflow версии 14, а для Jetson Nano последняя версия пока что 13. И модель, сохраненная в 14й версии, не прочиталась в 13й, пришлось ставить одинаковые версии с помощью pip.
Наконец, мы можем загрузить модель из файла и использовать ее для распознавания картинок.
Фотография котика использовалась та же самая, а для «собачьего» теста использовалось 2 картинки:

Первая угадывалась безошибочно, а на второй сначала были ошибки и нейросеть считала что это кот, пришлось увеличить число итераций обучения. Впрочем, я бы наверно с первого раза тоже ошибся ;)
Время выполнения на Jetson Nano оказалось вполне небольшим — самое первое фото обрабатывалось за 0.3с, но все последующие гораздо быстрее, видимо данные кешируются в памяти.
В общем, можно считать, что на таких несложных нейросетях скорости платы вполне хватает даже без каких-либо оптимизаций, 100fps это величина, достаточная даже для видео в real time.
Как можно видеть, даже стандартные модели из Keras и Tensorflow можно использовать на Nano, хотя и с переменным успехом — что-то работает, что-то нет. Впрочем, результаты можно улучшить, инструкцию по оптимизации модели и уменьшению размера памяти можно почитать здесь.
Но к счастью для нас, производители за нас это уже сделали. Если у читателей еще останется интерес, заключительная часть будет посвящена готовым библиотекам, оптимизированным для работы с Jetson Nano.
В первой части была рассмотрена NVIDIA Jetson Nano — плата в форм-факторе Raspberry Pi, ориентированная на производительные вычисления с помощью GPU. Настала пора протестировать плату в том, для чего она создавалась — для AI-ориентированных расчетов.
Рассмотрим, как идут на плате разные задачи, вроде классификации изображений или распознавания пешеходов или котиков (куда же без них). Для всех тестов приведены исходники, которые можно запустить на десктопе, Jetson Nano или Raspberry Pi. Для тех, кому интересно, продолжение под катом.
Есть два способа использования этой платы. Первый — это запустить стандартные фреймворки, типа Keras и Tensorflow. Оно работать в принципе, будет, но как уже было видно из первой части, Jetson Nano, разумеется, уступает полноценной десктопной или ноутбучной видеокарте. Задачу оптимизации модели пользователю придется взять на себя. Второй способ — взять готовые классы, поставляемые вместе с платой. Оно проще и работает «из коробки», минус в том, что в гораздо большей степени скрыты все детали реализации, к тому же, придется изучить и использовать custom-sdk, который кроме этих плат, нигде больше не пригодится. Впрочем, мы посмотрим оба способа, начнем с первого.
Классификация изображений
Рассмотрим задачу распознавания изображений. Для этого воспользуемся поставляемой вместе с Keras моделью ResNet50 (эта модель была победителем ImageNet Challenge в 2015). Чтобы ее использовать, достаточно нескольких строчек кода.
import tensorflow as tf
import numpy as np
import time
IMAGE_SIZE = 224
IMG_SHAPE = (IMAGE_SIZE, IMAGE_SIZE, 3)
resnet = tf.keras.applications.ResNet50(input_shape=IMG_SHAPE)
img = tf.contrib.keras.preprocessing.image.load_img('cat.png', target_size=(IMAGE_SIZE, IMAGE_SIZE))
t_start = time.time()
img_data = tf.contrib.keras.preprocessing.image.img_to_array(img)
x = tf.contrib.keras.applications.resnet50.preprocess_input(np.expand_dims(img_data, axis=0))
probabilities = resnet.predict(x)
print(tf.contrib.keras.applications.resnet50.decode_predictions(probabilities, top=5))
print("dT", time.time() - t_start)
Я даже не стал убирать код под спойлер, т.к. он весьма небольшой. Как можно видеть, изображение сначала ресайзится к 224х224 (таков входной формат сети), в завершении, функция predict делает всю работу.
Берем фотографию котика и запускаем программу.
Результаты:
[[('n02123045', 'tabby', 0.765179), ('n02123159', 'tiger_cat', 0.19059166), ('n02124075', 'Egyptian_cat', 0.013605555), ('n04493381', 'tub', 0.0025916891), ('n04553703', 'washbasin', 0.0021566998)]]В очередной раз огорчившись своему знанию английского (интересно, многие ли не-нативы знают что такое «tabby»?), сверил вывод со словарем, да, все работает.
Время выполнения кода на ПК составило 0.5с при расчетах на CPU и 2с (!) при расчете на GPU. Судя по логу, проблема то ли в модели, то ли в Tensorflow, но при запуске код пытается выделить много памяти, получая на выходе несколько warnings вида «Allocator (GPU_0_bfc) ran out of memory trying to allocate 2.13GiB with freed_by_count=0.». Это warning а не error, код при этом работает, но гораздо медленнее чем должен был бы.
На Jetson Nano все еще медленнее: 2.8c на CPU и 18.8с на GPU, вывод при этом выглядит так:
В общем, даже 3с на изображение, это пока не real time. Установка рекомендуемой на stack overflow опции gpu_options.allow_growth не помогает, если кто знает другой способ, напишите в комментариях.
Правка: как подсказали в комментариях, первый запуск tensorflow всегда выполняется долго, и измерять по нему время некорректно. Действительно, при обработке второго и последующего файлов, результаты гораздо лучше — 0.6с без GPU и 0.2с с GPU. На десктопе быстродействие составляет, впрочем, 2.0с и 0.05с соответственно.
Удобной особенностью ResNet50 является то, что при первом старте она выкачивает всю модель на диск (порядка 100Мб), далее код работает полностью автономно, без регистраций и SMS. Что особенно приятно, учитывая что большинство современных AI-сервисов работают только на сервере, и без интернета устройство превращается в «тыкву».
Cats vs Dogs
Рассмотрим следующую задачу. Создадим с помощью Keras нейронную сеть, способную различать на фото кошек и собак. Это будет сверточная нейронная сеть (CNN — Convolutional Neural Network), дизайн сети возьмем из этой публикации. Обучающий набор изображений кошек и собак уже включен в пакет tensorflow_datasets, так что фотографировать их самостоятельно не придется.
Загружаем набор изображений и разбиваем его на три блока — обучающий, проверочный и тестовый. Каждую картинку «нормализуем», приводя цвета к диапазону 0..1.
import tensorflow as tf
from tensorflow.keras import layers
import tensorflow_datasets as tfds
from keras.preprocessing import image
import numpy as np
import time
IMAGE_SIZE = 64
IMG_SHAPE = (IMAGE_SIZE, IMAGE_SIZE, 3)
splits = tfds.Split.TRAIN.subsplit(weighted=(80, 10, 10))
(cat_train, cat_valid, cat_test), info = tfds.load('cats_vs_dogs', split=list(splits), with_info=True, as_supervised=True)
label_names = info.features['label'].int2str
def pre_process_image(image, label):
image = tf.cast(image, tf.float32)
image = image / 255.0 # Normalize image: 0..255 -> 0..1
image = tf.image.resize(image, (IMAGE_SIZE, IMAGE_SIZE))
return image, label
BATCH_SIZE = 32
SHUFFLE_BUFFER_SIZE = 1000
train_batch = cat_train.map(pre_process_image).shuffle(SHUFFLE_BUFFER_SIZE).repeat().batch(BATCH_SIZE)
validation_batch = cat_valid.map(pre_process_image).repeat().batch(BATCH_SIZE)
Напишем функцию генерации сверточной нейросети.
def custom_model():
# Source: https://medium.com/@ferhat00/deep-learning-with-keras-classifying-cats-and-dogs-part-1-982067594856
classifier = tf.keras.Sequential()
# Step 1 — Convolution
classifier.add(layers.Conv2D(32, (3, 3), input_shape=IMG_SHAPE, activation='relu'))
# Step 2 — Pooling
classifier.add(layers.MaxPooling2D(pool_size=(2, 2)))
# Adding a second convolutional layer
classifier.add(layers.Conv2D(32, (3, 3), activation='relu'))
classifier.add(layers.MaxPooling2D(pool_size=(2, 2)))
# Step 3 — Flattening
classifier.add(layers.Flatten())
# Step 4 — Full connection
classifier.add(layers.Dense(units=128, activation='relu'))
classifier.add(layers.Dense(units=1, activation='sigmoid'))
# Compiling the CNN we shall use the Adam stochastic optimisation method, binary cross entropy loss function
classifier.compile(optimizer=tf.keras.optimizers.Adam(), loss='binary_crossentropy', metrics=['accuracy'])
return classifier
Теперь мы можем запустить обучение сети на нашем наборе «кошки-собаки». Обучение длится долго (минут 20 на GPU и 1-2 часа на CPU), так что по окончании сохраняем модель в файл.
tl_model = custom_model()
t_start = time.time()
tl_model.fit(train_batch, steps_per_epoch=8000, epochs=2, validation_data=validation_batch, validation_steps=10, callbacks=None)
print("Training done, dT:", time.time() - t_start)
print(tl_model.summary())
validation_steps = 20
loss0, accuracy0 = tl_model.evaluate(validation_batch, steps=validation_steps)
print("Loss: {:.2f}".format(loss0))
print("Accuracy: {:.2f}".format(accuracy0))
tl_model.save("dog_cat_model.h5")
Кстати, попытка запустить обучение прямо на Jetson Nano провалилась — плата минут через 5 перегрелась и повисла. Для ресурсоемких расчетов к плате необходим кулер, хотя по большому счету, делать такие задачи прямо на Jetson Nano смысла нет — модель можно обучить на ПК, а готовый сохраненный файл использовать на Nano.
Тут вылез еще один подводный камень — на ПК установлена библиотека tensowflow версии 14, а для Jetson Nano последняя версия пока что 13. И модель, сохраненная в 14й версии, не прочиталась в 13й, пришлось ставить одинаковые версии с помощью pip.
Наконец, мы можем загрузить модель из файла и использовать ее для распознавания картинок.
def predict_model(model, image_file):
img = image.load_img(image_file, target_size=(IMAGE_SIZE, IMAGE_SIZE))
t_start = time.time()
img_arr = np.expand_dims(img, axis=0)
result = model.predict_classes(img_arr)
print("Result: {}, dT: {}".format(label_names(result[0][0]), time.time() - t_start))
model = tf.keras.models.load_model('dog_cat_model.h5')
predict_model(model, "cat.png")
predict_model(model, "dog1.png")
predict_model(model, "dog2.png")
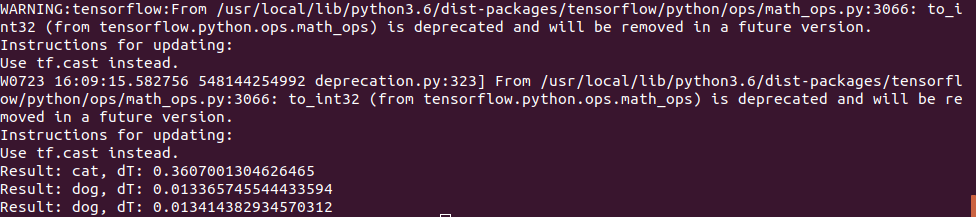
Фотография котика использовалась та же самая, а для «собачьего» теста использовалось 2 картинки:
Первая угадывалась безошибочно, а на второй сначала были ошибки и нейросеть считала что это кот, пришлось увеличить число итераций обучения. Впрочем, я бы наверно с первого раза тоже ошибся ;)
Время выполнения на Jetson Nano оказалось вполне небольшим — самое первое фото обрабатывалось за 0.3с, но все последующие гораздо быстрее, видимо данные кешируются в памяти.
В общем, можно считать, что на таких несложных нейросетях скорости платы вполне хватает даже без каких-либо оптимизаций, 100fps это величина, достаточная даже для видео в real time.
Заключение
Как можно видеть, даже стандартные модели из Keras и Tensorflow можно использовать на Nano, хотя и с переменным успехом — что-то работает, что-то нет. Впрочем, результаты можно улучшить, инструкцию по оптимизации модели и уменьшению размера памяти можно почитать здесь.
Но к счастью для нас, производители за нас это уже сделали. Если у читателей еще останется интерес, заключительная часть будет посвящена готовым библиотекам, оптимизированным для работы с Jetson Nano.
