I have originally posted this article in CodingSight blog.
It's also available in Russian here.
This article comprises the second part of my speech at the multithreading meetup. You can have a look at the first part here and here. In the first part, I focused on the basic set of tools used to start a thread or a Task, the ways to track their state, and some additional neat things such as PLinq. In this part, I will fix on the issues you may encounter in a multi-threaded environment and some of the ways to resolve them.
You can’t write a program which work is based on multiple threads without having shared resources. Even if it works on your current abstraction level, you will find that it actually has shared resources as soon as you go down one or more abstraction levels. Here are some examples:
Example #1:
To avoid possible issues, you make the threads work with different files, one file for each thread. It seems to you that the program has no shared resources whatsoever.
Going a few levels down, you get to know that there’s only one hard drive, and it’s up to the driver or the OS to find a solution for issues with hard drive access.
Example #2:
Having read example #1, you decided to place the files on two different remote machines with physically different hardware and operating systems. You also maintain two different FTP or NFS connections.
Going a few levels down again, you understand that nothing has really changed, and the competitive access issue is now delegated to the network card driver or the OS of the machine on which the program is running.
Example #3:
After pulling out most of your hair over the attempts of proving you can write a multi-threaded program, you decide to ditch the files completely and move the calculations to two different objects, with the links to each of the object available only to their specific threads.
To hammer the final dozen nails into this idea’s coffin: one runtime and Garbage Collector, one thread scheduler, physically one unified RAM, and one processor are still considered shared resources.
So, we learned that it is impossible to write a multi-threaded program with no shared resources on all abstraction levels and on the whole scope of the technology stack. Fortunately, each abstraction level (as a general rule) partially or even fully takes care of the issues of competitive access or just denies it right away (example: any UI framework does not allow working with elements from different threads). So typically, the issues with shared resources appear at your current abstraction level. To take care of them, the concept of synchronization is introduced.
We can classify software errors into the following categories:
In multi-threaded environments, the main issues that result in errors #1 and #2 are deadlock and race condition.
Deadlock is a mutual block. There are many variations of a deadlock. The following one can be considered as the most common:
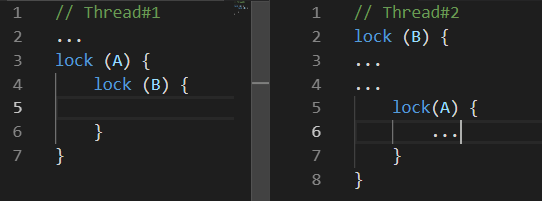
While Thread#1 was doing something, Thread#2 blocked resource B. Sometime later, Thread#1 blocked resource A and was trying to block resource B. unfortunately, this won’t ever happen because Thread#2 will only let go of resource B after blocking resource А.
Race-Condition is a situation when both, the behavior and results of the calculations depend on the thread scheduler of the execution environment
The trouble is that your program can work improperly one time in a hundred, or even in a million.
The things may get worse when issues come in threes. For example, the specific behavior of the thread scheduler may lead to a mutual deadlock.
In addition to these two issues which lead to explicit errors, there are also the issues which, if not leading to incorrect calculation results, may still make the program take much more time or resources to produce the desired result. Two of such issues are Busy Wait and Thread Starvation.
Busy Wait is an issue that takes place when the program spends processor resources on waiting rather than on calculation.
Typically, this issue looks like the following:
This is an example of an extremely poor code as it fully occupies one core of your processor while not really doing anything productive at all. Such code can only be justified when it is critically important to quickly process a change of a value in a different thread. And by ‘quickly’ I mean that you can’t wait even for a few nanoseconds. In all other cases, that is, all cases a reasonable mind can come up with, it is much more convenient to use the variations of ResetEvent and their Slim versions. We’ll talk about them a little bit later.
Probably, some readers would suggest resolving the issue of one core being fully occupied with waiting by adding Thread.Sleep(1) (or something similar) into the cycle. While it will resolve this issue, a new one will be created – the time it takes to react to changes will now be 0.5 ms on average. On one hand, it’s not that much, but on the other, this value is catastrophically higher than what we can achieve by using synchronization primitives of the ResetEvent family.
Thread Starvation is an issue with the program having too many concurrently-operating threads. Here, we’re talking specifically about the threads occupied with calculation rather than with waiting for an answer from some IO. With this issue, we lose any possible performance benefits that come along with threads because the processor spends a lot of time on switching contexts.
You can find such issues by using various profilers. The following is a screenshot of the dotTrace profiler working in the Timeline mode
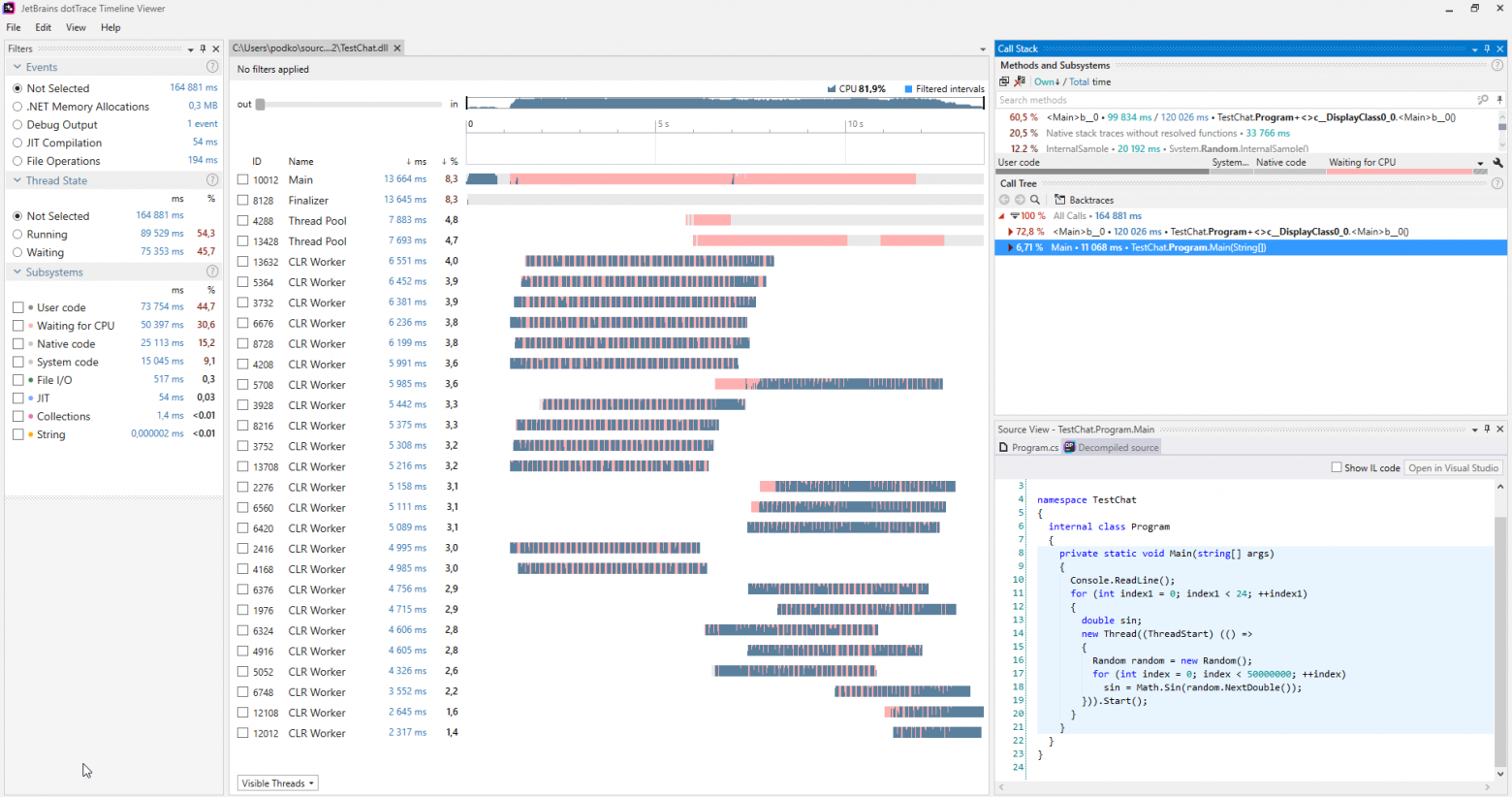
(click to enlarge).
Usually, programs that are not suffering from the thread starvation do not have any pink sections on the charts representing the threads. Moreover, in the Subsystems category, we can see that the program was waiting for CPU for 30.6% of the time.
When such an issue is diagnosed, you can take care of it rather simply: you have started too many threads at once, so just start fewer threads.
This is probably the most lightweight synchronization method. Interlocked is a set of simple atomic operations. When an atomic operation is being executed, nothing can happen. In .NET, Interlocked is represented by the static class of the same name with a selection of methods, each one of them implementing one atomic operation.
To realize the ultimate horror of non-atomic operations, try writing a program that launches 10 threads, each one of them incrementing the same variable a million times over. When they are done with their job, output the value of this variable. Unfortunately, it will greatly differ from 10 million. In addition, it will be different each time you run the program. This happens because even such simple operation as the increment is not an atomic one, and includes the value extraction from memory, calculation of new value and writing it to the memory again. So, two threads can make any of these operations and an increment will be lost in this case.
The Interlocked class provides the Increment/Decrement methods, and it’s not difficult to guess what they’re supposed to do. They are really handy if you process data in several threads and calculate something. Such code will work much faster than the classic lock. If we used Interlocked in the situation described in the previous paragraph, the program would reliably produce a value of 10 million in any scenario.
The function of the CompareExchange method is not that obvious. However, its existence enables the implementation of a lot of interesting algorithms. Most importantly, the ones from the lock-free family.
This method takes three values. The first one is passed through a reference and it is the value that will be changed to the second one if location1 is equal to comparand when the comparison is performed. The original value of location1 will be returned. This sounds complicated, so it’s easier to write a piece of code that performs the same operations as CompareExchange:
The only difference is that the Interlocked class implements this in an atomic way. So, if we wrote this code ourselves, we could face a scenario in which the condition location1 == comparand has already been met. But when the statement location1 = value is being executed, a different thread has already changed the location1 value, so it will be lost.
We can find a good example of how this method can be used in the code that the compiler generates for any С# event.
Let’s write a simple class with one event called MyEvent:
Now, let’s build the project in Release configuration and open the build through dotPeek with the “Show Compiler Generated Code” option enabled:
Here, we can see that the compiler has generated a rather complex algorithm behind the scenes. This algorithm prevents us from losing a subscription to the event in which a few threads are simultaneously subscribed to this event. Let’s elaborate on the add method while keeping in mind what the CompareExchange method does behind the scenes:
This is much more manageable, but probably still requires an explanation. This is how I would describe the algorithm:
If MyEvent is still the same as it was at the moment we started executing Delegate.Combine, then set it to what Delegate.Combine returns. If it’s not the case, try again until it works.
In this way, subscriptions will never be lost. You will have to solve a similar issue if you would like to implement a dynamic, thread-safe, lock-free array. If several threads suddenly start adding elements to that array, it’s important for all of those elements to be successfully added.
These constructions are used for thread synchronization most frequently. They implement the concept of a critical section: that is, the code written between the calls of Monitor.Enter and Monitor.Exit can only be executed on one resource at one point of time by only one thread. The lock operator serves as syntax-sugar around the Enter/Exit calls wrapped in try-finally. A pleasant quality of the critical section in .NET is that it supports reentrancy. This means that the following code can be executed with no real issues:
It’s unlikely that anyone would write in this exact way, but if you spread this code between a few methods through the depth of the call-stack, this feature can save you a few IFs. For this trick to work, the developers of .NET had to add a limitation – you can only use instances of reference types as a synchronization object, and a few bytes are added to each object where the thread identifier will be written.
This peculiarity of the critical section’s work process in C# imposes one interesting limitation on the lock operator: you can’t use the await operator inside the lock operator. At first, this surprised me since a similar try-finally Monitor.Enter/Exit construction can be compiled. What’s the deal? It’s important to re-read the previous paragraph and apply some knowledge of how async/await works: the code after await won’t be necessarily executed on the same thread as the code before await. This depends on the synchronization context and whether the ConfigureAwait method is called or not. From this, it follows that Monitor.Exit may be executed on a different thread than Monitor.Enter, which will lead to SynchronizationLockException being thrown. If you don’t believe me, try running the following code in a console application – it will generate a SynchronizationLockException:
It’s worth noting that, in a WinForms or WPF application, this code will work correctly if you call it from the main thread as there will be a synchronization context that implements returning to UI-Thread after calling await. In any case, it’s better not to play around with critical sections in the context of a code containing the await operator. In such examples, it’s better to use synchronization primitives we will look at a little bit later.
While we’re on the topic of critical sections in .NET, it’s important to mention one more peculiarity of how they’re implemented. A critical section in .NET works in two modes: spin-wait and core-wait. We can represent the spin-wait algorithm like the following pseudocode:
This optimization is directed towards capturing a critical section as quickly as possible in a short amount of time on the basis that, even if the resource is currently occupied, it will be released very soon. If this doesn’t happen in a short amount of time, the thread will switch to waiting in the core mode, which takes time – just as going back from waiting. The developers of .NET have optimized the scenario of short blocks as much as possible. Unfortunately, if many threads start pulling the critical section between themselves, it can lead to a sudden high load on CPU.
Having already mentioned the cyclic wait algorithm (spin-wait), it’s worth talking about the SpinLock and SpinWait structures from BCL. You should use them if there are reasons to suppose it will always be possible to get a block very quickly. On the other hand, you shouldn’t really think about them until the profiling results will show that your program’s bottleneck is caused by using other synchronization primitives.
We should look at these two methods side-by-side. With their help, you can implement various Producer-Consumer scenarios.
Producer-Consumer is a pattern of multi-process/multi-threaded design implying one or more threads/processes which produce data and one or more processes/threads which process this data. Usually, a shared collection is used.
Both of these methods can only be called by a thread which currently has a block. The Wait method will release the block and freeze until another thread will call Pulse.
As a demonstration of this, I wrote a little example:

(I used an image rather than text here to accurately show the instruction execution order)
Explanation: I set a 100-ms latency when starting the second thread to specifically guarantee that it will be executed later.
— T1:Line#2 the thread is started
— T1:Line#3 the thread enters a critical section
— T1:Line#6 the thread goes to sleep
— T2:Line#3 the thread is started
— T2:Line#4 it freezes and waits for the critical section
— T1:Line#7 it lets the critical section go and freezes while waiting for Pulse to come out
— T2:Line#8 it enters the critical section
— T2:Line#11 it signals T1 with the help of Pulse
— T2:Line#14 it comes out of the critical section. T1 cannot continue its execution before this happens.
— T1:Line#15 it comes out from waiting
— T1:Line#16 it comes out from the critical section
There is an important remark in MSDN regarding the use of the Pulse/Wait methods: Monitor doesn’t store the state information, which means that calling the Pulse method before the Wait method can lead to a deadlock. If such a case is possible, it’s better to use one of the classes from the ResetEvent family.
The previous example clearly shows how the Wait/Pulse methods of the Monitor class work, but still leaves some questions about the cases in which we should use them. A good example is this implementation of BlockingQueue<T>. On the other hand, the implementation of BlockingCollection<T> from System.Collections.Concurrent uses SemaphoreSlim for synchronization.
I dearly love this synchronization primitive, and it’s represented by the class of the same name from the System.Threading namespace. I think that a lot of programs would work much better if their developers used this class instead of the standard lock.
Idea: a lot of threads can read, and the only one can write. When a thread wants to write, new reads cannot be started – they will be waiting for the writing to the end. There is also the upgradeable-read-lock concept. You can use it when, during the process of reading, you understand there is a need to write something – such a lock will be transformed into a write-lock in one atomic operation.
In the System.Threading namespace, there is also the ReadWriteLock class, but it’s highly recommended not to use it for new development. The Slim version will help avoid cases which lead to deadlocks and allows to quickly capture a block as it supports synchronization in the spin-wait mode before going to the core mode.
If you didn’t know about this class before reading this article, I think by now, you have remembered a lot of examples from the recently-written code where this approach to blocks allowed the program to work effectively.
The interface of the ReaderWriterLockSlim class is simple and easy to understand, but it’s not that comfortable to use:
I usually like to wrap it in a class – this makes it much handier.
Idea: create Read/WriteLock methods which return an object along with the Dispose method. You can then access them in Using, and it probably won’t differ too much from the standard lock when it comes to the number of lines.
This allows us to just write the following later in the code:
I include the following classes in this family: ManualResetEvent, ManualResetEventSlim, and AutoResetEvent.
The ManualResetEvent class, its Slim version, and the AutoResetEvent class can exist in two states:
— Non-signaled – in this state, all threads that have called WaitOne freeze until the event switches to a signaled state.
— Signaled – in this state, all threads previously frozen on a WaitOne call are released. All new WaitOne calls on a signaled event are performed relatively instantaneously.
AutoResetEvent differs from ManualResetEvent in that it automatically switches to the non-signaled state after releasing exactly one thread. If a few threads are frozen while waiting for AutoResetEvent, then calling Set will only release one random thread, as opposed to ManualResetEvent which releases all threads.
Let’s look at an example of how AutoResetEvent works:

In these examples, we can see that the event switches to the non-signaled state automatically only after releasing the thread that was frozen on a WaitOne call.
Unlike ReaderWriterLock, ManualResetEvent is not considered obsolete even after its Slim version appeared. This Slim version of the class can be effective for short waits as it happens in the Spin-Wait mode; the standard version is good for long waits.
Apart from the ManualResetEvent and AutoResetEvent classes, there is also the CountdownEvent class. This class is very useful for implementing algorithms that merge results together after a parallel section. This approach is known as fork-join. There is a great article dedicated to this class, so I won’t describe it in detail here.
It's also available in Russian here.
This article comprises the second part of my speech at the multithreading meetup. You can have a look at the first part here and here. In the first part, I focused on the basic set of tools used to start a thread or a Task, the ways to track their state, and some additional neat things such as PLinq. In this part, I will fix on the issues you may encounter in a multi-threaded environment and some of the ways to resolve them.
Contents
- Concerning shared resources
- Possible issues in multi-threaded environments
- Synchronization methods
- Conclusions
Concerning shared resources
You can’t write a program which work is based on multiple threads without having shared resources. Even if it works on your current abstraction level, you will find that it actually has shared resources as soon as you go down one or more abstraction levels. Here are some examples:
Example #1:
To avoid possible issues, you make the threads work with different files, one file for each thread. It seems to you that the program has no shared resources whatsoever.
Going a few levels down, you get to know that there’s only one hard drive, and it’s up to the driver or the OS to find a solution for issues with hard drive access.
Example #2:
Having read example #1, you decided to place the files on two different remote machines with physically different hardware and operating systems. You also maintain two different FTP or NFS connections.
Going a few levels down again, you understand that nothing has really changed, and the competitive access issue is now delegated to the network card driver or the OS of the machine on which the program is running.
Example #3:
After pulling out most of your hair over the attempts of proving you can write a multi-threaded program, you decide to ditch the files completely and move the calculations to two different objects, with the links to each of the object available only to their specific threads.
To hammer the final dozen nails into this idea’s coffin: one runtime and Garbage Collector, one thread scheduler, physically one unified RAM, and one processor are still considered shared resources.
So, we learned that it is impossible to write a multi-threaded program with no shared resources on all abstraction levels and on the whole scope of the technology stack. Fortunately, each abstraction level (as a general rule) partially or even fully takes care of the issues of competitive access or just denies it right away (example: any UI framework does not allow working with elements from different threads). So typically, the issues with shared resources appear at your current abstraction level. To take care of them, the concept of synchronization is introduced.
Possible issues in multi-threaded environments
We can classify software errors into the following categories:
- The program doesn’t produce a result – it crashes or freezes.
- The program gives an incorrect result.
- The program produces a correct result but doesn’t satisfy some non-function-related requirement – it spends too much time or resources.
In multi-threaded environments, the main issues that result in errors #1 and #2 are deadlock and race condition.
Deadlock
Deadlock is a mutual block. There are many variations of a deadlock. The following one can be considered as the most common:
While Thread#1 was doing something, Thread#2 blocked resource B. Sometime later, Thread#1 blocked resource A and was trying to block resource B. unfortunately, this won’t ever happen because Thread#2 will only let go of resource B after blocking resource А.
Race-Condition
Race-Condition is a situation when both, the behavior and results of the calculations depend on the thread scheduler of the execution environment
The trouble is that your program can work improperly one time in a hundred, or even in a million.
The things may get worse when issues come in threes. For example, the specific behavior of the thread scheduler may lead to a mutual deadlock.
In addition to these two issues which lead to explicit errors, there are also the issues which, if not leading to incorrect calculation results, may still make the program take much more time or resources to produce the desired result. Two of such issues are Busy Wait and Thread Starvation.
Busy-Wait
Busy Wait is an issue that takes place when the program spends processor resources on waiting rather than on calculation.
Typically, this issue looks like the following:
while(!hasSomethingHappened) ;
This is an example of an extremely poor code as it fully occupies one core of your processor while not really doing anything productive at all. Such code can only be justified when it is critically important to quickly process a change of a value in a different thread. And by ‘quickly’ I mean that you can’t wait even for a few nanoseconds. In all other cases, that is, all cases a reasonable mind can come up with, it is much more convenient to use the variations of ResetEvent and their Slim versions. We’ll talk about them a little bit later.
Probably, some readers would suggest resolving the issue of one core being fully occupied with waiting by adding Thread.Sleep(1) (or something similar) into the cycle. While it will resolve this issue, a new one will be created – the time it takes to react to changes will now be 0.5 ms on average. On one hand, it’s not that much, but on the other, this value is catastrophically higher than what we can achieve by using synchronization primitives of the ResetEvent family.
Thread Starvation
Thread Starvation is an issue with the program having too many concurrently-operating threads. Here, we’re talking specifically about the threads occupied with calculation rather than with waiting for an answer from some IO. With this issue, we lose any possible performance benefits that come along with threads because the processor spends a lot of time on switching contexts.
You can find such issues by using various profilers. The following is a screenshot of the dotTrace profiler working in the Timeline mode
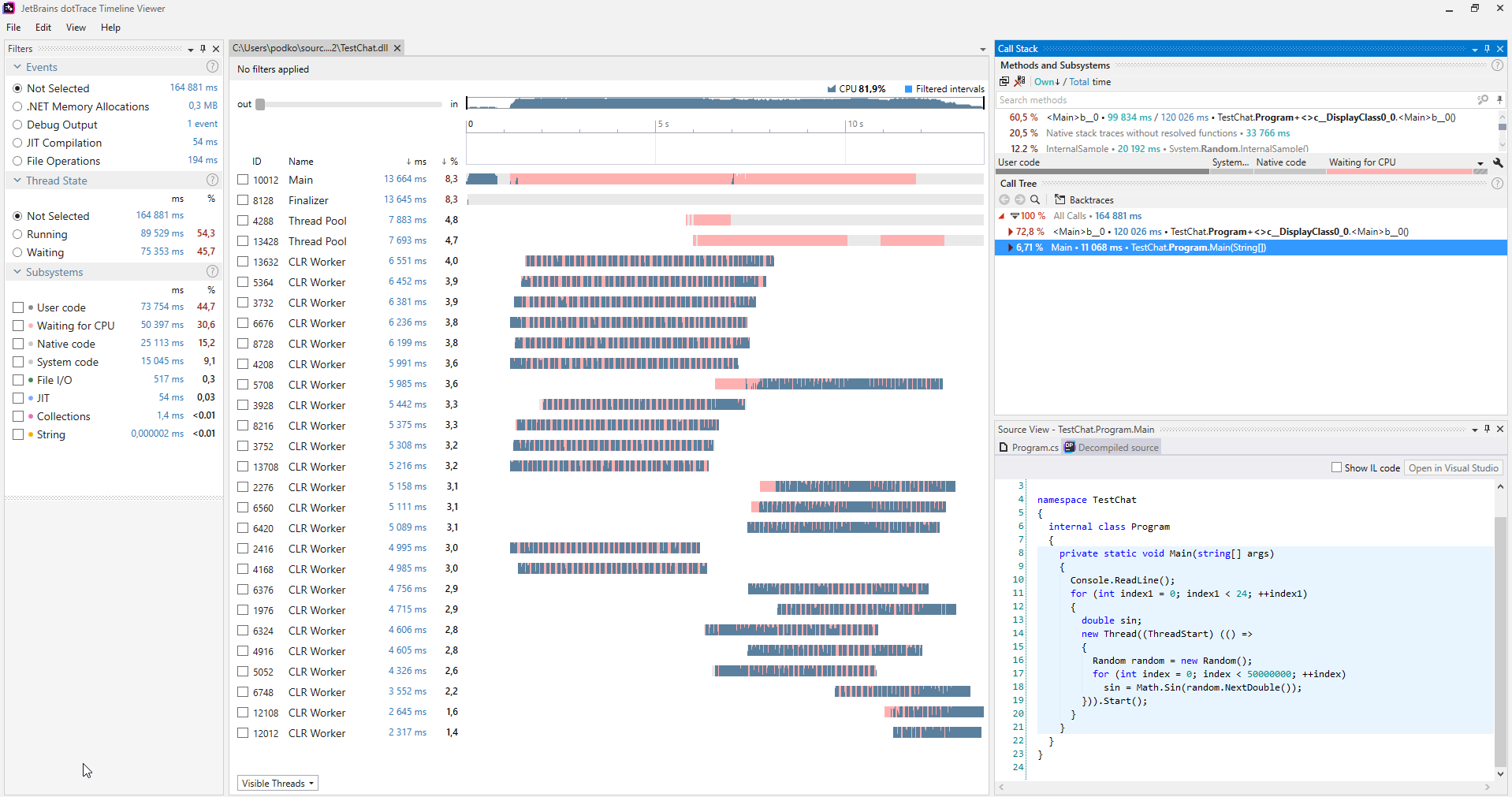
(click to enlarge).
Usually, programs that are not suffering from the thread starvation do not have any pink sections on the charts representing the threads. Moreover, in the Subsystems category, we can see that the program was waiting for CPU for 30.6% of the time.
When such an issue is diagnosed, you can take care of it rather simply: you have started too many threads at once, so just start fewer threads.
Synchronization methods
Interlocked
This is probably the most lightweight synchronization method. Interlocked is a set of simple atomic operations. When an atomic operation is being executed, nothing can happen. In .NET, Interlocked is represented by the static class of the same name with a selection of methods, each one of them implementing one atomic operation.
To realize the ultimate horror of non-atomic operations, try writing a program that launches 10 threads, each one of them incrementing the same variable a million times over. When they are done with their job, output the value of this variable. Unfortunately, it will greatly differ from 10 million. In addition, it will be different each time you run the program. This happens because even such simple operation as the increment is not an atomic one, and includes the value extraction from memory, calculation of new value and writing it to the memory again. So, two threads can make any of these operations and an increment will be lost in this case.
The Interlocked class provides the Increment/Decrement methods, and it’s not difficult to guess what they’re supposed to do. They are really handy if you process data in several threads and calculate something. Such code will work much faster than the classic lock. If we used Interlocked in the situation described in the previous paragraph, the program would reliably produce a value of 10 million in any scenario.
The function of the CompareExchange method is not that obvious. However, its existence enables the implementation of a lot of interesting algorithms. Most importantly, the ones from the lock-free family.
public static int CompareExchange (ref int location1, int value, int comparand);
This method takes three values. The first one is passed through a reference and it is the value that will be changed to the second one if location1 is equal to comparand when the comparison is performed. The original value of location1 will be returned. This sounds complicated, so it’s easier to write a piece of code that performs the same operations as CompareExchange:
var original = location1; if (location1 == comparand) location1 = value; return original;
The only difference is that the Interlocked class implements this in an atomic way. So, if we wrote this code ourselves, we could face a scenario in which the condition location1 == comparand has already been met. But when the statement location1 = value is being executed, a different thread has already changed the location1 value, so it will be lost.
We can find a good example of how this method can be used in the code that the compiler generates for any С# event.
Let’s write a simple class with one event called MyEvent:
class MyClass { public event EventHandler MyEvent; }
Now, let’s build the project in Release configuration and open the build through dotPeek with the “Show Compiler Generated Code” option enabled:
[CompilerGenerated] private EventHandler MyEvent; public event EventHandler MyEvent { [CompilerGenerated] add { EventHandler eventHandler = this.MyEvent; EventHandler comparand; do { comparand = eventHandler; eventHandler = Interlocked.CompareExchange<EventHandler>(ref this.MyEvent, (EventHandler) Delegate.Combine((Delegate) comparand, (Delegate) value), comparand); } while (eventHandler != comparand); } [CompilerGenerated] remove { // The same algorithm but with Delegate.Remove } }
Here, we can see that the compiler has generated a rather complex algorithm behind the scenes. This algorithm prevents us from losing a subscription to the event in which a few threads are simultaneously subscribed to this event. Let’s elaborate on the add method while keeping in mind what the CompareExchange method does behind the scenes:
EventHandler eventHandler = this.MyEvent; EventHandler comparand; do { comparand = eventHandler; // Begin Atomic Operation if (MyEvent == comparand) { eventHandler = MyEvent; MyEvent = Delegate.Combine(MyEvent, value); } // End Atomic Operation } while (eventHandler != comparand);
This is much more manageable, but probably still requires an explanation. This is how I would describe the algorithm:
If MyEvent is still the same as it was at the moment we started executing Delegate.Combine, then set it to what Delegate.Combine returns. If it’s not the case, try again until it works.
In this way, subscriptions will never be lost. You will have to solve a similar issue if you would like to implement a dynamic, thread-safe, lock-free array. If several threads suddenly start adding elements to that array, it’s important for all of those elements to be successfully added.
Monitor.Enter, Monitor.Exit, lock
These constructions are used for thread synchronization most frequently. They implement the concept of a critical section: that is, the code written between the calls of Monitor.Enter and Monitor.Exit can only be executed on one resource at one point of time by only one thread. The lock operator serves as syntax-sugar around the Enter/Exit calls wrapped in try-finally. A pleasant quality of the critical section in .NET is that it supports reentrancy. This means that the following code can be executed with no real issues:
lock(a) { lock (a) { ... } }
It’s unlikely that anyone would write in this exact way, but if you spread this code between a few methods through the depth of the call-stack, this feature can save you a few IFs. For this trick to work, the developers of .NET had to add a limitation – you can only use instances of reference types as a synchronization object, and a few bytes are added to each object where the thread identifier will be written.
This peculiarity of the critical section’s work process in C# imposes one interesting limitation on the lock operator: you can’t use the await operator inside the lock operator. At first, this surprised me since a similar try-finally Monitor.Enter/Exit construction can be compiled. What’s the deal? It’s important to re-read the previous paragraph and apply some knowledge of how async/await works: the code after await won’t be necessarily executed on the same thread as the code before await. This depends on the synchronization context and whether the ConfigureAwait method is called or not. From this, it follows that Monitor.Exit may be executed on a different thread than Monitor.Enter, which will lead to SynchronizationLockException being thrown. If you don’t believe me, try running the following code in a console application – it will generate a SynchronizationLockException:
var syncObject = new Object(); Monitor.Enter(syncObject); Console.WriteLine(Thread.CurrentThread.ManagedThreadId); await Task.Delay(1000); Monitor.Exit(syncObject); Console.WriteLine(Thread.CurrentThread.ManagedThreadId);
It’s worth noting that, in a WinForms or WPF application, this code will work correctly if you call it from the main thread as there will be a synchronization context that implements returning to UI-Thread after calling await. In any case, it’s better not to play around with critical sections in the context of a code containing the await operator. In such examples, it’s better to use synchronization primitives we will look at a little bit later.
While we’re on the topic of critical sections in .NET, it’s important to mention one more peculiarity of how they’re implemented. A critical section in .NET works in two modes: spin-wait and core-wait. We can represent the spin-wait algorithm like the following pseudocode:
while(!TryEnter(syncObject)) ;
This optimization is directed towards capturing a critical section as quickly as possible in a short amount of time on the basis that, even if the resource is currently occupied, it will be released very soon. If this doesn’t happen in a short amount of time, the thread will switch to waiting in the core mode, which takes time – just as going back from waiting. The developers of .NET have optimized the scenario of short blocks as much as possible. Unfortunately, if many threads start pulling the critical section between themselves, it can lead to a sudden high load on CPU.
SpinLock, SpinWait
Having already mentioned the cyclic wait algorithm (spin-wait), it’s worth talking about the SpinLock and SpinWait structures from BCL. You should use them if there are reasons to suppose it will always be possible to get a block very quickly. On the other hand, you shouldn’t really think about them until the profiling results will show that your program’s bottleneck is caused by using other synchronization primitives.
Monitor.Wait, Monitor.Pulse[All]
We should look at these two methods side-by-side. With their help, you can implement various Producer-Consumer scenarios.
Producer-Consumer is a pattern of multi-process/multi-threaded design implying one or more threads/processes which produce data and one or more processes/threads which process this data. Usually, a shared collection is used.
Both of these methods can only be called by a thread which currently has a block. The Wait method will release the block and freeze until another thread will call Pulse.
As a demonstration of this, I wrote a little example:
object syncObject = new object(); Thread t1 = new Thread(T1); t1.Start(); Thread.Sleep(100); Thread t2 = new Thread(T2); t2.Start();
(I used an image rather than text here to accurately show the instruction execution order)
Explanation: I set a 100-ms latency when starting the second thread to specifically guarantee that it will be executed later.
— T1:Line#2 the thread is started
— T1:Line#3 the thread enters a critical section
— T1:Line#6 the thread goes to sleep
— T2:Line#3 the thread is started
— T2:Line#4 it freezes and waits for the critical section
— T1:Line#7 it lets the critical section go and freezes while waiting for Pulse to come out
— T2:Line#8 it enters the critical section
— T2:Line#11 it signals T1 with the help of Pulse
— T2:Line#14 it comes out of the critical section. T1 cannot continue its execution before this happens.
— T1:Line#15 it comes out from waiting
— T1:Line#16 it comes out from the critical section
There is an important remark in MSDN regarding the use of the Pulse/Wait methods: Monitor doesn’t store the state information, which means that calling the Pulse method before the Wait method can lead to a deadlock. If such a case is possible, it’s better to use one of the classes from the ResetEvent family.
The previous example clearly shows how the Wait/Pulse methods of the Monitor class work, but still leaves some questions about the cases in which we should use them. A good example is this implementation of BlockingQueue<T>. On the other hand, the implementation of BlockingCollection<T> from System.Collections.Concurrent uses SemaphoreSlim for synchronization.
ReaderWriterLockSlim
I dearly love this synchronization primitive, and it’s represented by the class of the same name from the System.Threading namespace. I think that a lot of programs would work much better if their developers used this class instead of the standard lock.
Idea: a lot of threads can read, and the only one can write. When a thread wants to write, new reads cannot be started – they will be waiting for the writing to the end. There is also the upgradeable-read-lock concept. You can use it when, during the process of reading, you understand there is a need to write something – such a lock will be transformed into a write-lock in one atomic operation.
In the System.Threading namespace, there is also the ReadWriteLock class, but it’s highly recommended not to use it for new development. The Slim version will help avoid cases which lead to deadlocks and allows to quickly capture a block as it supports synchronization in the spin-wait mode before going to the core mode.
If you didn’t know about this class before reading this article, I think by now, you have remembered a lot of examples from the recently-written code where this approach to blocks allowed the program to work effectively.
The interface of the ReaderWriterLockSlim class is simple and easy to understand, but it’s not that comfortable to use:
var @lock = new ReaderWriterLockSlim(); @lock.EnterReadLock(); try { // ... } finally { @lock.ExitReadLock(); }
I usually like to wrap it in a class – this makes it much handier.
Idea: create Read/WriteLock methods which return an object along with the Dispose method. You can then access them in Using, and it probably won’t differ too much from the standard lock when it comes to the number of lines.
class RWLock : IDisposable { public struct WriteLockToken : IDisposable { private readonly ReaderWriterLockSlim @lock; public WriteLockToken(ReaderWriterLockSlim @lock) { this.@lock = @lock; @lock.EnterWriteLock(); } public void Dispose() => @lock.ExitWriteLock(); } public struct ReadLockToken : IDisposable { private readonly ReaderWriterLockSlim @lock; public ReadLockToken(ReaderWriterLockSlim @lock) { this.@lock = @lock; @lock.EnterReadLock(); } public void Dispose() => @lock.ExitReadLock(); } private readonly ReaderWriterLockSlim @lock = new ReaderWriterLockSlim(); public ReadLockToken ReadLock() => new ReadLockToken(@lock); public WriteLockToken WriteLock() => new WriteLockToken(@lock); public void Dispose() => @lock.Dispose(); }
This allows us to just write the following later in the code:
var rwLock = new RWLock(); // ... using(rwLock.ReadLock()) { // ... }
The ResetEvent family
I include the following classes in this family: ManualResetEvent, ManualResetEventSlim, and AutoResetEvent.
The ManualResetEvent class, its Slim version, and the AutoResetEvent class can exist in two states:
— Non-signaled – in this state, all threads that have called WaitOne freeze until the event switches to a signaled state.
— Signaled – in this state, all threads previously frozen on a WaitOne call are released. All new WaitOne calls on a signaled event are performed relatively instantaneously.
AutoResetEvent differs from ManualResetEvent in that it automatically switches to the non-signaled state after releasing exactly one thread. If a few threads are frozen while waiting for AutoResetEvent, then calling Set will only release one random thread, as opposed to ManualResetEvent which releases all threads.
Let’s look at an example of how AutoResetEvent works:
AutoResetEvent evt = new AutoResetEvent(false); Thread t1 = new Thread(T1); t1.Start(); Thread.Sleep(100); Thread t2 = new Thread(T2); t2.Start();
In these examples, we can see that the event switches to the non-signaled state automatically only after releasing the thread that was frozen on a WaitOne call.
Unlike ReaderWriterLock, ManualResetEvent is not considered obsolete even after its Slim version appeared. This Slim version of the class can be effective for short waits as it happens in the Spin-Wait mode; the standard version is good for long waits.
Apart from the ManualResetEvent and AutoResetEvent classes, there is also the CountdownEvent class. This class is very useful for implementing algorithms that merge results together after a parallel section. This approach is known as fork-join. There is a great article dedicated to this class, so I won’t describe it in detail here.
Conclusions
- When working with threads, there are two issues that may lead to incorrect results or even the absence of results – race condition and deadlock.
- Issues that can make the program spend more time or resources are thread starvation and busy wait.
- .NET provides a lot of ways to synchronize threads.
- There are two modes of block waits – Spin Wait and Core Wait. Som.e thread synchronization primitives in .NET use both of them.
- Interlocked is a set of atomic operations which can be used to implement lock-free algorithms. It’s the fastest synchronization primitive.
- The lock and Monitor.Enter/Exit operators implement the concept of a critical section – a code fragment that can only be executed by one thread at one point of time.
- The Monitor.Pulse/Wait methods are useful for implementing Producer-Consumer scenarios.
- ReaderWriterLockSlim can be more useful than the standard locking cases when parallel reading is expected.
- The ResetEvent class family can be useful for thread synchronization.
