Привет! Эта статья продолжение моей статьи FFmpeg начало работы Visual Studio. Здесь мы приступим к аппаратному декодированию RTSP-потока FULL HD. Заранее скажу, что с данной задачей легко справится даже Intel ATOM Z8350.
Задача: аппаратное декодирование и запись до 4-х кадров в оперативную память для последующей параллельной обработки (четырьмя ядрами процессора) с IP-камеры RTSP h.264. Обработанные кадры отображаю с помощью функций WinAPI. Как итог мы получим быстродействующую систему для компьютерной обработки RTSP-потока в параллельном режиме. Далее можно подключать алгоритмы Компьютерного зрения для обработки кадров Real Time.

Зачем нужно аппаратное декодирование? Вы хотите слабым и дешевым процессором декодировать видео реал-тайм или хотите максимально разгрузить процессор, тогда пора знакомиться с аппаратным декодированием.
DirectX Video Acceleration (DXVA) — это API для использования аппаратного ускорения для ускорения обработки видео силами графических процессоров (GPU). DXVA 2.0 позволяет перенаправлять на GPU большее количество операций, включая захват видео и операции обработки видео.
После написания предыдущей статьи мне было задано не мало вопросов: «почему использован именно FFmpeg?» Начну с проблематики. Основная сложность аппаратного декодирования состоит в записи раскодированного кадра в ОЗУ. Для Full HD это 1920 х 1080 х 3 = 6 220 800 байт. Даже с учетом того что кадр хранится в формате NV12 – это тоже немало 1920 x 1080 x 1.5 = 3 110 400 байт. Перезаписывать 75 Мбайт в секунду серьезная задача для любого процессора. Для решения этой задачи Intel добавила команды SSE 4, которые позволяют переписывать данные без участия процессора. К сожалению, не во всех библиотеках это реализовано. Мной были опробованы следующие библиотеки:
VLC – работает с IP-камерами через аппаратное декодирование (очень низкая загрузка процессора), примитивный проигрыватель потока RTSP можно построить буквально в 10 строк кода, но получение декодированных кадров в оперативную память занимает слишком много процессорного времени.
OpenCV – для работы с потоком RTSP использует FFmpeg, поэтому решено работать без посредников, т.е. использовать библиотеку FFmpeg. К тому же FFmpeg, который установлен по умолчанию, в OpenCV собран без аппаратного декодирования.
FFmpeg – показала хорошие, на мой взгляд результаты, работает стабильно. Единственный недостаток не реализована работа с WEB-камерами для версии X86 (X64 вроде позволяет работать) в Windows.
На самом деле аппаратное декодирование с помощью библиотеки FFmpeg — не сложнее программного. Настройки проекта такие же, как и для программной реализации, блок-схема осталась без изменений.
Вывести на экран список поддерживаемых FFmpeg методов аппаратного декодирования можно
Первое, что нам нужно сделать — это сообщить FFmpeg с помощью какого аппаратного декодера Вы хотите декодировать видео. В моем случае Windows10 + Intel Atom Z8350 оставляют только DXVA2:
Вы же в качестве аппаратного декодера можете выбрать CUDA, D3D11VA, QSV или VAAPI (только Linux). Соответственно у вас должно быть данное аппаратное решение и FFmpeg должен быть собран с его поддержкой.
Открываем видеопоток:
Получаем информацию о видеопотоке:
Выделяем память:
Данная функция переписывает декодированный файл в ОЗУ:
Итак, мы получили кадр в структуру sw_frame. Полученный кадр хранится в формате NV12. Данный формат был придуман Microsoft. Он позволяет хранить информацию о пикселе в 12 бит. Где 8 бит интенсивность, а 4 битами описывается цветность (вернее цветность сразу описывается для 4-х рядом стоящих пикселей 2х2). Причем, sw_frame.data[0] – хранится интенсивность, а в sw_frame.data[1] – хранится цветность. Для перевода из NV-12 в RGB можете воспользоваться следующей функцией:
Хотя работа с NV12 позволяет ускорить выполнение таких процедур, как размывка, Retinex и получение изображения в оттенках серого (просто отбросив цветность). В моих задачах я не перевожу формат NV12 в RGB, так как это занимает дополнительное время.
И так мы научились аппаратно декодировать видеофайлы и выводить их в окно. Познакомились в форматом NV12 и как его преобразовывать в привычный RGB.
Кадры FFmpeg выдает через 40 мс (при 25 кадрах в секунду). Как правило, обработка кадра Full HD занимает значительно больше времени. Для этого требуется организовать многопоточность, для максимальной загрузки всех 4-х ядер процессора. Я на практике один раз запускаю 6 потоков и больше их не снимаю, что значительно упрощает работу и увеличивает надежность работы программы. Схема работы приведена на рис. 1
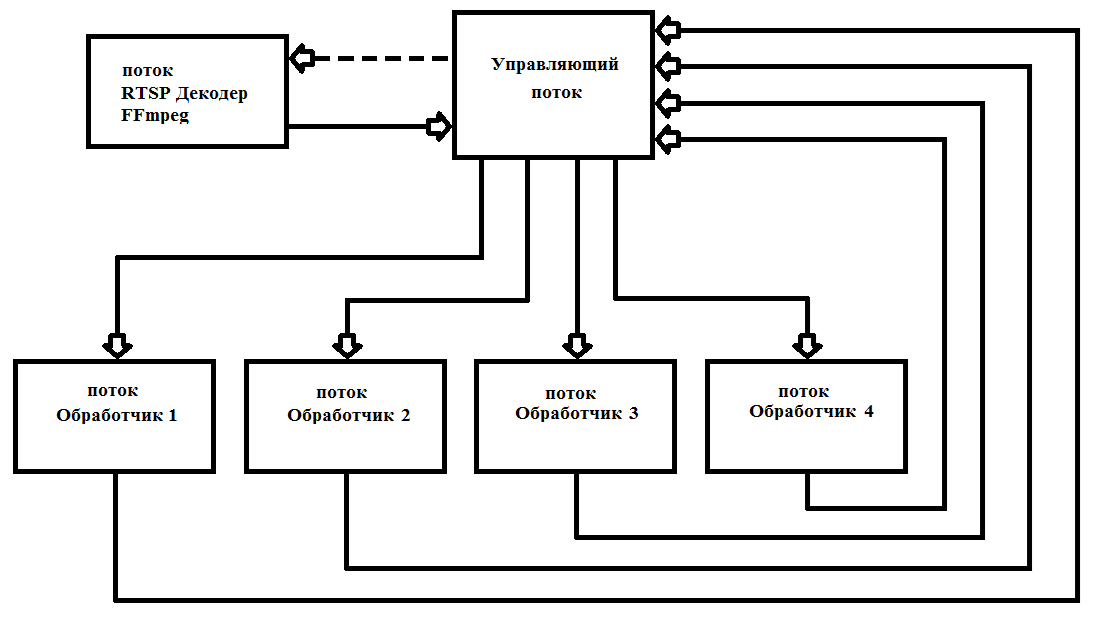
рис.1 Схема построения многопоточной программы с FFmpeg
Я написал свой декодер в виде *.dll (FFmpegD.DLL) для включения в свои проекты. Это позволяет сократить код-проекта, что повышает понимание кода и включать в любые языки программирования, вплоть до Ассемблера (проверено:) ). С помощью нее мы напишем свой проигрыватель RTSP-потока с IP-камеры.
Для начала работы с DLL нужно передать указатель массив int[13], HANDLE события поступления нового кадра, HANDLE начала обработки нового пакета данных с камеры и массив char адрес камеры.
Структура массива дана в таблице 1.

Перед вызовом необходимо обнулить номера кадров 1-4.
DLL выполнит все необходимые действия по инициализации FFmpeg и будет записывать указатели и номера кадров. После установит событие «Поступление нового кадра». Нужно только обрабатывать поступающие кадры и вместо номера кадра записывать 0 (это значит кадр обработан и больше не используется).
Ниже Вы найдете пример проигрывателя с исходным кодом. За основу взят пример ShowDib3 Charles Petzold.
→ Архив с проектом
→ Архив FFmpegD.dll
ИТОГ: аппаратный детектор движения FFmpeg даже на Intel Atom Z8350 декодирует h264 Full HD в реальном времени с загрузкой процессора до 20% с подключенный детектором движения.
Пример работы детектора движения на Intel ATOM Z8350. Первые 30 сек идет подсчет фона. После работает детектор движения по методу вычитания фона.
P.S. Так же можете декодировать и видеофайлы (сжатые h.264)!!!
Ссылки:
Задача: аппаратное декодирование и запись до 4-х кадров в оперативную память для последующей параллельной обработки (четырьмя ядрами процессора) с IP-камеры RTSP h.264. Обработанные кадры отображаю с помощью функций WinAPI. Как итог мы получим быстродействующую систему для компьютерной обработки RTSP-потока в параллельном режиме. Далее можно подключать алгоритмы Компьютерного зрения для обработки кадров Real Time.
Вступление
Зачем нужно аппаратное декодирование? Вы хотите слабым и дешевым процессором декодировать видео реал-тайм или хотите максимально разгрузить процессор, тогда пора знакомиться с аппаратным декодированием.
DirectX Video Acceleration (DXVA) — это API для использования аппаратного ускорения для ускорения обработки видео силами графических процессоров (GPU). DXVA 2.0 позволяет перенаправлять на GPU большее количество операций, включая захват видео и операции обработки видео.
После написания предыдущей статьи мне было задано не мало вопросов: «почему использован именно FFmpeg?» Начну с проблематики. Основная сложность аппаратного декодирования состоит в записи раскодированного кадра в ОЗУ. Для Full HD это 1920 х 1080 х 3 = 6 220 800 байт. Даже с учетом того что кадр хранится в формате NV12 – это тоже немало 1920 x 1080 x 1.5 = 3 110 400 байт. Перезаписывать 75 Мбайт в секунду серьезная задача для любого процессора. Для решения этой задачи Intel добавила команды SSE 4, которые позволяют переписывать данные без участия процессора. К сожалению, не во всех библиотеках это реализовано. Мной были опробованы следующие библиотеки:
- FFmpeg
- VLC
- OpenCV
VLC – работает с IP-камерами через аппаратное декодирование (очень низкая загрузка процессора), примитивный проигрыватель потока RTSP можно построить буквально в 10 строк кода, но получение декодированных кадров в оперативную память занимает слишком много процессорного времени.
OpenCV – для работы с потоком RTSP использует FFmpeg, поэтому решено работать без посредников, т.е. использовать библиотеку FFmpeg. К тому же FFmpeg, который установлен по умолчанию, в OpenCV собран без аппаратного декодирования.
FFmpeg – показала хорошие, на мой взгляд результаты, работает стабильно. Единственный недостаток не реализована работа с WEB-камерами для версии X86 (X64 вроде позволяет работать) в Windows.
Аппаратное декодирование видео — это просто
На самом деле аппаратное декодирование с помощью библиотеки FFmpeg — не сложнее программного. Настройки проекта такие же, как и для программной реализации, блок-схема осталась без изменений.
Вывести на экран список поддерживаемых FFmpeg методов аппаратного декодирования можно
fprintf(stderr, " %s", av_hwdevice_get_type_name(type));Первое, что нам нужно сделать — это сообщить FFmpeg с помощью какого аппаратного декодера Вы хотите декодировать видео. В моем случае Windows10 + Intel Atom Z8350 оставляют только DXVA2:
type = av_hwdevice_find_type_by_name("dxva2");Вы же в качестве аппаратного декодера можете выбрать CUDA, D3D11VA, QSV или VAAPI (только Linux). Соответственно у вас должно быть данное аппаратное решение и FFmpeg должен быть собран с его поддержкой.
Открываем видеопоток:
avformat_open_input(&input_ctx, filename, NULL, NULL;Получаем информацию о видеопотоке:
av_find_best_stream(input_ctx, AVMEDIA_TYPE_VIDEO, -1, -1, &decoder, 0);Выделяем память:
frame = av_frame_alloc(); // здесь хранится декодированный файл вне ОЗУ
sw_frame = av_frame_alloc(); // Сюда мы перепишем декодированный файл в ОЗУДанная функция переписывает декодированный файл в ОЗУ:
av_hwframe_transfer_data(sw_frame, frame, 0);Немного о формате NV12
Итак, мы получили кадр в структуру sw_frame. Полученный кадр хранится в формате NV12. Данный формат был придуман Microsoft. Он позволяет хранить информацию о пикселе в 12 бит. Где 8 бит интенсивность, а 4 битами описывается цветность (вернее цветность сразу описывается для 4-х рядом стоящих пикселей 2х2). Причем, sw_frame.data[0] – хранится интенсивность, а в sw_frame.data[1] – хранится цветность. Для перевода из NV-12 в RGB можете воспользоваться следующей функцией:
C++ перевод из NV12 в RGB
void SaveFrame(uint8_t * f1, uint8_t * f2, int iFrame) {
FILE *pFile;
char szFilename[32];
int x, i, j;
// char buff[1920 * 1080 * 3];
uint8_t *buff = new uint8_t(1920*3*2);
int u=0, v=0, y=0;
// Open file
sprintf(szFilename, "frame%d.ppm", iFrame);
pFile = fopen(szFilename, "wb");
if (pFile == NULL)
return;
// Записуем заголовок файла
fprintf(pFile, "P6\n%d %d\n255\n", 1920, 1080);
for (j = 0; j < 1080 / 2; j++) {
for (i = 0; i < 1920; i +=2) {
// 1 точка rgb
y = *(f1 + j * 1920 * 2 + i);
v = *(f2 + j * 1920 + i) - 128;
u = *(f2 + j * 1920 + i + 1) - 128;
x = round(y + 1.370705 * v);
if (x < 0) x = 0;
if (x > 255) x = 255;
// if (j > 34) printf("%i, ",(j * 1920 * 2 + i) * 3);
buff[i * 3 + 2] = x;
x = round(y - 0.698001 * v - 0.337633 * u);
if (x < 0) x = 0;
if (x > 255) x = 255;
buff[i * 3 + 1] = x;
x = round(y + 1.732446 * u);
if (x < 0) x = 0;
if (x > 255) x = 255;
buff[i * 3] = x;
// 2 точка rgb
y = *(f1 + j * 1920 * 2 + i + 1);
x = y + 1.370705 * v;
if (x < 0) x = 0;
if (x > 255) x = 255;
buff[i * 3 + 5] = x;
x = y - 0.698001 * v - 0.337633 * u;
if (x < 0) x = 0;
if (x > 255) x = 255;
buff[i * 3 + 4] = x;
x = y + 1.732446 * u;
if (x < 0) x = 0;
if (x > 255) x = 255;
buff[i * 3 + 3] = x;
// 3 точка rgb
y = *(f1 + j * 1920 * 2 + 1920 + i);
x = y + 1.370705 * v;
if (x < 0) x = 0;
if (x > 255) x = 255;
buff[(1920 + i) * 3 + 2] = x;
x = y - 0.698001 * v - 0.337633 * u;
if (x < 0) x = 0;
if (x > 255) x = 255;
buff[(1920 + i) * 3 + 1] = x;
x = y + 1.732446 * u;
if (x < 0) x = 0;
if (x > 255) x = 255;
buff[(1920 + i) * 3 + 0] = x;
// 4 точка rgb
y = *(f1 + j * 1920 * 2 + 1920 + i + 1);
x = y + 1.370705 * v;
if (x < 0) x = 0;
if (x > 255) x = 255;
buff[(1920 + i) * 3 + 5] = x;
x = y - 0.698001 * v - 0.337633 * u;
if (x < 0) x = 0;
if (x > 255) x = 255;
buff[(1920 + i) * 3 + 4] = x;
x = y + 1.732446 * u;
if (x < 0) x = 0;
if (x > 255) x = 255;
buff[(1920 + i) * 3 + 3] = x;
// printf("%i, ", i);
} // for i
fwrite(buff, 1, 1920 * 3 * 2, pFile);
printf("\n %i\n", j);
} // for j
// printf("Save4\n");
// Write pixel data
// fwrite(buff, 1, 1920*1080*3, pFile);
// Close file
printf("close\n");
fclose(pFile);
printf("exit\n");
delete buff;
// return;
}
Хотя работа с NV12 позволяет ускорить выполнение таких процедур, как размывка, Retinex и получение изображения в оттенках серого (просто отбросив цветность). В моих задачах я не перевожу формат NV12 в RGB, так как это занимает дополнительное время.
И так мы научились аппаратно декодировать видеофайлы и выводить их в окно. Познакомились в форматом NV12 и как его преобразовывать в привычный RGB.
Dll аппаратного декодирования
Кадры FFmpeg выдает через 40 мс (при 25 кадрах в секунду). Как правило, обработка кадра Full HD занимает значительно больше времени. Для этого требуется организовать многопоточность, для максимальной загрузки всех 4-х ядер процессора. Я на практике один раз запускаю 6 потоков и больше их не снимаю, что значительно упрощает работу и увеличивает надежность работы программы. Схема работы приведена на рис. 1
рис.1 Схема построения многопоточной программы с FFmpeg
Я написал свой декодер в виде *.dll (FFmpegD.DLL) для включения в свои проекты. Это позволяет сократить код-проекта, что повышает понимание кода и включать в любые языки программирования, вплоть до Ассемблера (проверено:) ). С помощью нее мы напишем свой проигрыватель RTSP-потока с IP-камеры.
Для начала работы с DLL нужно передать указатель массив int[13], HANDLE события поступления нового кадра, HANDLE начала обработки нового пакета данных с камеры и массив char адрес камеры.
Структура массива дана в таблице 1.
Перед вызовом необходимо обнулить номера кадров 1-4.
DLL выполнит все необходимые действия по инициализации FFmpeg и будет записывать указатели и номера кадров. После установит событие «Поступление нового кадра». Нужно только обрабатывать поступающие кадры и вместо номера кадра записывать 0 (это значит кадр обработан и больше не используется).
Ниже Вы найдете пример проигрывателя с исходным кодом. За основу взят пример ShowDib3 Charles Petzold.
→ Архив с проектом
→ Архив FFmpegD.dll
ИТОГ: аппаратный детектор движения FFmpeg даже на Intel Atom Z8350 декодирует h264 Full HD в реальном времени с загрузкой процессора до 20% с подключенный детектором движения.
Пример работы детектора движения на Intel ATOM Z8350. Первые 30 сек идет подсчет фона. После работает детектор движения по методу вычитания фона.
P.S. Так же можете декодировать и видеофайлы (сжатые h.264)!!!
Ссылки:
