
Всемирная паутина — это океан данных. Здесь можно посмотреть практически любую интересующую Вас информацию. Однако, "вытащить" эту информацию из интернета уже сложнее. Есть несколько способов получить данные и web-scraping один из них.
Что такое web-scraping? Вкратце, это технология позволяющая извлекать данные с HTML-страниц. При использовании скрэпинга отпадает необходимость копипастить нужную информацию или переносить её с экрана в блокнот. Информация окажется у Вас в компьютере в удобном для Вас виде.
Web-scraping на примере сайта Кинопоиск.ru
Чтобы не заниматься скрэпингом ради скрэпинга неплохо поставить себе цель. Я решил, что это будет сравнение оценок фильмов на сайтах Кинопоиск.ru и IMDB.com, а также средние оценки фильмов по жанрам. Для анализа брались фильмы, вышедшие в прокат с 2010 по 2018 годы, с количеством голосов не менее 500.
Для начала загрузим необходимые нам библиотеки:
# Загружаемые библиотеки
library(rvest)
library(selectr)
library(xml2)
library(jsonlite)
library(tidyverse)Далее я получаю количество фильмов в году, которые удовлетворяют условию отбора (более 500 голосов). Делается это для того, чтобы узнать общее количество страниц с данными и "сгенерировать" ссылки на них, т.к. ссылки однотипны по своей структуре.
# Ссылка на первую страницу поиска фильмов за 2018 год
url <-
"https://www.kinopoisk.ru/top/navigator/m_act[year]/2018/m_act[rating]/1%3A/order/rating/page/1/#results"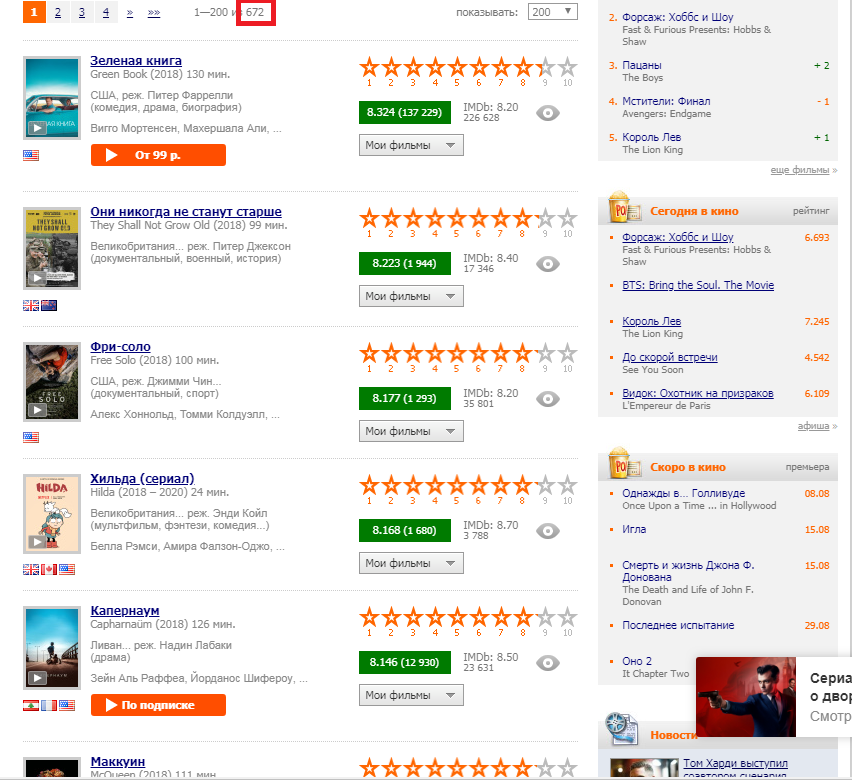
Наша задача "вытащить" число 672, выделенное на картинке красным прямоугольником. Для этого нам и пригодиться web-scraping.
Web-scraping страницы сайта Кинопоиск.ру с помощью пакета rvest
Сначала нам нужно "прочитать" полученный нами url. Для этого используем функцию read_html() пакета xml2.
# Использование функции для прочтения XML и HTML файлов
webpage <- read_html(url)А дальше, с помощью функций пакета rvest мы сначала "извлекаем" необходимую нам часть HTML-документа (функция html_nodes()), а затем из этой части извлекаем нужную нам информацию в удобном для нас виде (функции html_text(), html_table(), html_attr() др.)
Но как мы поймём, какой элемент нам нужно извлечь? Для этого мы должны навести на интересующую нас информацию курсор мыши, нажать ЛКМ и выбрать "просмотреть код". В нашем случае мы получим следующую картинку:
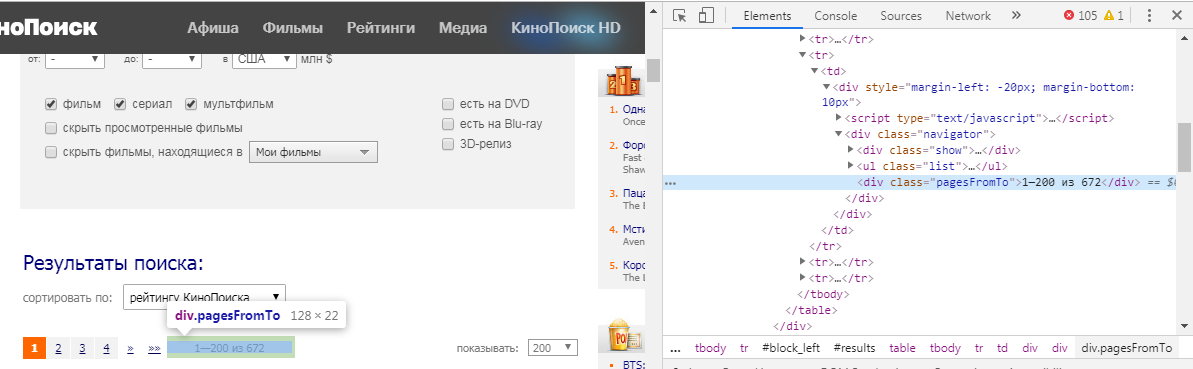
Функция html_nodes() имеет вид html_nodes(x, css). х — это определённая ранее webpage, а вот в css мы пишем id или класс элемента. В нашем случае это:
number_html <- html_nodes(webpage, ".pagesFromTo")Также, для "детекции" нужного элемента можно использовать расширение selectorGadget, которое показывает, что нам нужно вводить в явном виде:
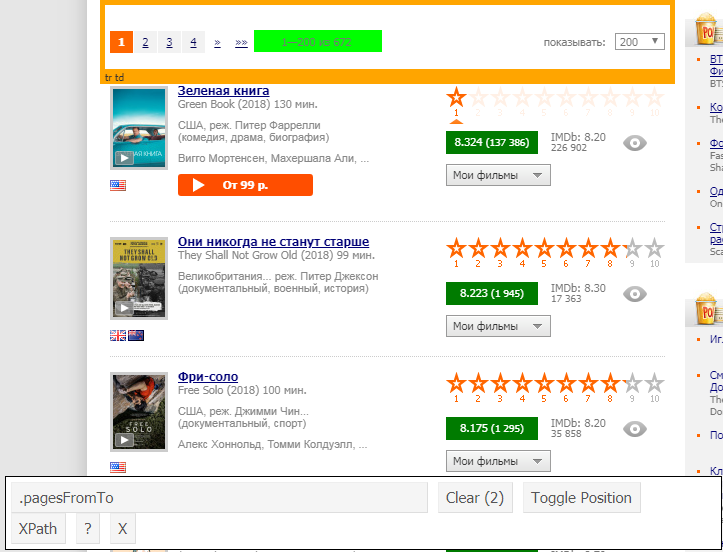
Далее функцией html_text мы извлекаем из выбранного элемента текстовую часть:
number <- html_text(number_html)
[1] "1—50 из 672" "1—50 из 672"Мы получили нужное нам число из HTML-страницы Кинопоиска, но теперь нам нужно его "очистить". Это стандартная процедура для скрэпинга, потому что очень редко нужный нам элемент можно получить в необходимом нам виде.
Мы получили 2 одинаковых элемента из-за того, что общее число фильмов указано вверху и внизу страницы и их css селектор абсолютно одинаковый. Поэтому для начала мы убираем лишний элемент:
number <- number[1]
[1] "1—50 из 672"Далее нам нужно избавиться от той части вектора, которая идёт до цифры 672. Сделать это можно по разному, но в основе всех способов лежит написание регулярного выражения. В данном случае я "заменяю" часть "1-50 из" на пустоту (вместо str_replace можно использовать str_remove), затем удаляю лишние пробелы (функция str_trim) и, наконец, перевожу вектор из символьного типа в числовой. На выходе получаю число 672. Ровно столько фильмов 2018 года имеют на Кинопоиске более 500 голосов пользователей.
number <- str_replace(number, ".{2,}из", "")
number <- as.numeric(str_trim(number))
[1] 672Что мы делаем далее? Если вы полистаете страницы на Кинопоиске то увидите, что адреса страниц поиска имеют одинаковую структуру и различаются только номером. Поэтому, чтобы не вводить адрес страницы каждый раз вручную, мы посчитаем число страниц и "сгенерируем" необходимое количество адресов. Делается это так:
#Подсчёт числа страниц
page_number <- ceiling(number/50)
#Генерирование их адресов
page <- sapply(seq(1:page_number), function(n){
list_page <- paste0("https://www.kinopoisk.ru/top/navigator/m_act[year]/2018/m_act[rating]/1%3A/order/rating/page/", n, "/#results")
})На выходе получаем 14 адресов. Функция ceiling в данном примере округляет число до БОЛЬШЕГО целого числа.
А дальше используем функцию lapply на вход которой подаются адреса страниц, а функция "извлекает" со страниц Кинопоиска информацию о названии, рейтинге, количестве голосов и основных жанрах (максимум 3) фильма. Код функции можно найти в репозитории на Github.
В итоге мы получаем таблицу с 8111 фильмами.
| NAME | RATING | VOTES | GENRE | YEAR |
|---|---|---|---|---|
| шерлок | 8.884 | 235316 | триллер, драма, криминал | 2010 |
| бегущий человек | 8.812 | 1917 | игра, реальное ТВ, комедия | 2010 |
| великая война | 8.792 | 5690 | документальный, военный, история | 2010 |
| discovery как устроена вселенная | 8.740 | 3033 | документальный | 2010 |
| начало | 8.664 | 533715 | фантастика, боевик, триллер | 2010 |
| discovery во вселенную со стивеном хокингом | 8.520 | 4373 | документальный | 2010 |
Стоит заметить про использование функции Sys.sleep. С помощью неё можно задать время задержки между выполнением выражений. Зачем это нужно? Если вы хотите получить информацию по одному году, то незачем. Но если Вас интересует большое количество фильмов/лет, то через определённое количество запросов Кинопоиск посчитает вас роботом и на ваш запрос вы будете получать пустой список. Чтобы избежать этого и нужно вводить время задержки.
Аналогично "скрэпим" сайт IMDB.com.
Анализ полученных данных
У нас появилось две таблицы, в одной информация о фильмах с IMDB, в другой c Кинопоиска. Теперь нам нужно их объединить. Объединять будем по столбцам NAME и YEAR. Для того, чтобы уменьшить количество расхождений в названиях, я ещё на стадии скрэпинга удалил все знаки пунктуации и перевёл буквы в нижний регистр. В итоге, после всех соединений и удалений, получаем 3450 фильмов, которые имеют необходимую нам информацию с обоих сайтов.
Меня интересует разница в оценках фильмов на двух сайтах, поэтому создадим переменную DELTA, которая является разностью между оценкой IMDB и Кинопоиска. Если DELTA положительна, то оценка на IMDB выше, если отрицательна, то ниже.
Сначала построим гистограмму для показателя DELTA:

На графике нет ничего удивительного. Разница оценок имеет нормальное распределение и вершину в районе нуля, что говорит о том, что пользователи двух сайтов, обычно, в оценке фильмов сходятся.
Сходятся, но не совсем. t-test двух независимых выборок позволяет нам сказать, что оценки на Кинопоиске выше и эта разница статистически значима (p-value < 0.05).
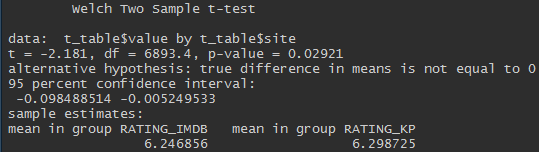
Хотя разница и значима, но очень небольшая.
Далее давайте посмотрим как разница в оценках зависит от количества голосов.

Тут тоже ничего неожиданного. Фильмы с большим количеством голосов, обычно, имеют очень небольшую разницу в оценках.
Теперь перейдём к оценке фильмов по жанрам. Стоит сразу заметить, что один фильм может иметь до трёх жанров, но всего одну оценку, так что один фильм может идти "в зачёт" и комедии, и мелодраме.
Начнём с Кинопоиска. Среди жанров с минимум 150 появлениями в базе данных явным аутсайдером являются ужасы. Также невысоко пользователи оценивают триллеры, боевики детективы и, что для меня стало удивительным, фантастику. С другой стороны, мелодраматические фильмы на Кинопоиске заходят "на ура", имея среднюю оценку выше 6,5 и уступая только мультфильмам и байопикам, которых в базе данных гораздо меньше

Теперь рассмотрим такой же график, но для IMDB. В принципе, он снова подтверждает, что разница в оценках между сайтами незначительна. Это неудивительно, ведь многие пользователи имеют аккаунты на обеих площадках и вряд ли ставят на разных сайтах разные оценки. Снова главный неудачник — это ужасы и можно сказать, что именно они являются самым низкорейтинговым жанром фильмов. Мне сложно оценить почему так происходит, потому что единственный ужастик который я посмотрел в жизни — это Гремлины. Возможно, именно ужасы являются самым низкобюджетным жанром, откуда произрастает слабая игра дешёвых актёров и откровенно плохие сценарии. Триллеры с фантастикой и на IMDB идут в числе отстающих, а вот у боевиков дела получше. Среди лидеров снова биографические фильмы и мультфильмы. Драма удерживает третье место, а вот оценка мелодрам упала ниже 6.5, на уровень приключенческих фильмов. Также на IMDB ниже оценки у комедий.

Заключение и немного о "внешних факторах"
Разница в оценках хотя и есть (на Кинопоиске они чуть выше), но именно, что чуть. По оценкам различных жанров большой разницы также незаметно. Блокбастеры, имеющие десятки, а то и сотни тысяч голосов если и имеют расхождения, то в пределах 0,5 баллов.
Большую разницу в оценках обычно имеют фильмы с небольшим (особенно на Кинопоиске) числом голосов, до 10 тысяч. Однако, наибольшую разницу в оценке в "пользу" IMDB имеет фильм с 30000 голосов на зарубежном сайте и более 90000 на Кинопоиске. Это творение Алексея Пиманова "Крым". Неужели фильм так понравился зарубежным зрителям? Вряд ли. Скорее всего, создатели фильма использовали в отношении IMDB ту же "маркетинговую политику", что и на Кинопоиске. Просто если Кинопоиск "вычистил" такие оценки, то на IMDB они остались. Думаю, что именно поэтому там "Крым" является "годным кинчиком".
Буду благодарен за любые комментарии, пожелания, претензии
Ссылка на репозиторий Github
Профиль на "Мой круг"
