Comments 320
class CustomError extends Error {
constructor(...args) {
super(...args);
}
}
const error = new CustomError('asdasd');
const isCustomError = error instanceof CustomError; // false, если транспайлим в es5...
const isError = error instanceof Error; // true
Это же уже исправлено?
Сейчас прогнал в babel
Он создает свою функцию для проверки instanceof, хотя она везде поддерживается. хм..
github.com/Microsoft/TypeScript-wiki/blob/master/Breaking-Changes.md#extending-built-ins-like-error-array-and-map-may-no-longer-work
constructor() {
super();
Object.setPrototypeOf(this, BaseClass.prototype);
}
this._removeResizeFunc = setAndCallResizeFunc(async () => {
/* ... */
await this.$timeout();
/* ... */
});
На всех браузерах он отрабатывал нормально, кроме safari 10. В нем он выдавал ошибку:
Can't find private variable: @derivedConstructor
В дев режиме ошибка не воспроизводилась.
Проблема оказалась в том, что на safari 10 не работают асинхронные функции в калбеках. В дев режиме весь код транспилировался в es5 и асинхронные функции заменялись на промисы, поэтому ошибки не возникало. А для прода для разных бразуеров собирались разные сборки с теми полифилами и транспиляциями, которые нужны именно этому браузеру. Safari 10 поддерживает асинхронные функции, так что в его сборке оставался асинхронный калбек.
Переписали на промисы и все заработало :)
Переписали на промисы и все заработало :)
А не проще было настройки компиляции для Safari 10 подкрутить?
this._removeResizeFunc = setAndCallResizeFunc(() => {
/* ... */
this.$timeout().then(() => {
/* ... */
});
});
П.С. И практически везде где в тексте статьи стоит «усложнили» я бы поставил «упростили». Или это я просто сарказм/иронию не уловил? :)
Не упростили, а переложили с рантайма на девелоп.
Упростили для тех, кто знал в чём проблема и усложнили порог входа для всех остальных. Хотя я вообще не frontend-guy (на самом деле даже не web-guy), но мне в целом не тяжело понять зачем и почему существуют все эти сложности. Однако, я уже умею программировать и это сильно упрощает мне понимание. Думаю для новичков погружение в современный фронтэнд просто сущий ад)
Думаю для новичков погружение в современный фронтэнд просто сущий ад)
Простите, а погружение в какую практическую область разрабоки для новичка не ад? :)
Не знаю, мне уже поздно рассуждать :) Я пишу на С++ и первую программу написал году где-то в 2012м. И уже тогда объем исторических знаний, который необходим для понимания какие проблемы решались теми или иными инструментами был почти неподъемным. Сейчас разрыв стал еще больше :) Везде, не только в JS и C++.
Так что да, наверное вы правы — для новичка абсолютно все — ад :)
Если знаешь что спросить — ты уже решил проблему. Но чтобы сформировать вопрос, нужно хотя бы нужные термины знать и иметь способность понять ответ :) Мне, как программисту, понять что такое транспайлер не составляет труда. Я отлично понимаю что означает "скомпилировать" JavaScript в JavaScript :) Но человеку с чистым разумом это тяжело понять в целом, как концепцию, мне кажется.
Как пример из мира С++ — впервые встретив такую аббревиатуру, как ABI, я погряз в гуглении на неделю, а чтобы хоть как-то глубоко разобраться в местах, где возникают проблемы с ABI и реально осознать как их решать, ушло наверное больше полугода, да и то, до сих пор всплывают пробелы в познаниях.
И я до сих пор помню, как тяжело было преодолеть первый барьер, когда ты открываешь первый абзац статьи и понимаешь, что тебе надо прочитать еще 10 статей, чтобы его понять. И в каждой из десяти ты встречаешь еще по такому абзацу. К вечеру ты имеешь список из 100 статей, которые нужно прочитать :)
Хорошие книги сокращают этот путь, потому что в хороших книгах дают системные знания добавляя детали по ходу прочтения. Но найти хорошие книги, понятные новичку, это тоже искусство)
А иногда ответов нет. И вот ты уже сам создаёшь решение проблемы, и потом другим объясняешь, как им пользоваться. Или сделал, может даже запостил в свой мелкий, не известный никому гит, и забыл. А другим придётся начинать с той же точки.
А ещё часть новичков на ровном месте начинает делать велосипеды. Отдельная история.
Программирование это весело.
Втягиваться в программирование — это тоже навык. Для него нужен навык программирования.
Ох, это сложный вопрос. Потому что я начинал учить С++, когда С++11 только-только вышел и в своё время начинал с какой-то книги по С++98 от издательства Питер, что как бы было далеко не самым лучшим выбором, как я уже понял намного позднее, познав боли и просидев сотни часов на форумах, задавая вопросы.
Сейчас же уже С++20 на подходе и я не знаю книг для новичков, которые бы постепенно раскрывали язык начиная хотя бы с С++11.
Из хороших книг по С++, которые подойдут для уже хотя бы немного разобравшихся, я бы наверное порекомендовал:
"Эффективный и современный С++", Скотт Мейерс. (Но лучше читать более свежий оригинал на английском)
"Язык программирования С++", Б. Страуструп. (Спорная книга. Написана просто ужасно скучно, но в ней я в своё время находил много всяких интересных деталей о внутреннем устройстве С++)
Если честно, не знаю ни одной хорошей книги по шаблонам, я как-то в своё время с шаблонами и compile-time вычислениями разбирался методом проб и ошибок.
Крайне рекомендую когда что-то непонятно в языке — ходить на
https://en.cppreference.com/w/cpp/language
Простите, а погружение в какую практическую область разрабоки для новичка не ад? :)
При правильно выбранном инструменте можно практически безболезненно войти в любую область разработки. Вопрос лишь в наличии хотя бы одного правильного инструмента, подходящего под задачу.
Пожалуй, по этому критерию на первом месте для меня стабильно окопался .NET. Область применения максимальна, порог входа минимален, C# интуитивно понятен почти всем, имевшим опыт хоть с каким-то языком программирования (даже паскаля или бейсика хватит), а вместо тьмы-тьмущей кривых редакторов новичка встречает студия.
Нода тащилась бы на втором месте, если бы не изначально инопланетный JavaScript со своими историческими особенностями. Как по мне, Питон ещё более инопланетен и неинтуитивен для быстрого старта, хоть от многих людей и слышал обратное мнение. Поэтому лично для меня второе место занял бы PHP.
Ну а в общем и целом, «не ад» — это всё, что развивается достаточно стабильно, без лишних форков и перезапусков, в результате чего про это можно найти большую базу знаний на том же стек-оверфлоу. Полтора миллиарда различных AwesomeFreakingJS в эту категорию, очевидно, не входят.
Главная проблема современной веб-разработки — это количество инструментов. Никто, даже эта статья, не рассказывает про эти инструменты, не сравнивает, не даёт анализ. Все просто говорят, что есть первое, второе, третье. А потом ты ставишь себе пакет, а он тянет первое. Ты ставить другой пакет, а он тянет второе. Таким образом, элементарная задача собрать бандл выливается в 100500+ пакетов, вотчеров и прочего бесполезного мусора. Как решают эту проблему? Никак, её просто откладывают, создавая новый инструмент-обёртка а-ля бандлер бандлов и т. п.
Фронтенд писался прямо в том же PHPStorm. Это был HTML + CSS без библиотек + нативный JS + jQuery. Скажем так, у меня больше сложностей вызывала бекенд разработка (вел обе одновременно, и даже немного администрировал сервер, например, настраивал bind9 чтобы юзеры прямо в ПУ сервиса могли свои домены подключать, почту на них делать и т.д.).
Если вы занимаетесь огромным проектом, который обслуживает кластер из десятка серверов. У вас миллионы пользователей в сутки, а чистый написанный код весит десятки мегабайт — тогда может быть есть смысл задействовать различные инструменты. Но мне кажется, 80% разработчиков в жизни с таким не сталкивались. У нас пиковая посещаемость была 2,7 млн. пользователей в месяц. На это и «блокнота» бы хватило. В PHPStorm просто удобней.
Представьте, что вместо проверенной столетиями циркулярной пилы вам предложат 200 принципиально разных инструментов для распила досок, и у большинства из них инструкция даже не содержит пункта, как его включить. А когда вы всё-таки освоите выбранный инструмент, он отслужит срок эксплуатации и вы придёте за новой моделью, то внезапно окажется, что ваши инструкции по технике безопасности, будучи применёнными к новой модели, приводят к отрезанию не доски, а руки.
Возможна то она возможна, но инструменты позиционируют себя прежде всего как средство повышение эффективности разработки, а не средство создания каких-то фич для юзера, которых нельзя создать по старинке.
Как я понимаю, в целом тут речь больше о инструментах времени разработки, а не исполнения. Типа раз пишем на JS, то используем SCSS-in-JS, ES-next со stage-3 и даже некоторыми stage-2 и одну вообще отмененную используем, babel, webpack, минификаторы для прода и дев-сервер c хотрелоадингом для дева. Плюс линтеры-форматтеры в гитхуках (гит вообще мастхэв), BDD-тесты, докер, CI/CD. А можно на ES-3 в блокноте писать и по ftp заливать на прод
Полностью согласен. И практически на любом уровне есть выбор из нескольких похожих вариантов: grunt/gulp/webpack/rollup/parcel, angular/vue/react, less/sass/postcss, typescript/flow, karma/jasmine/jest/mocha... — а еще есть всякие адаптеры, типа "директива, интегрирующая выпадалку Selectize в Angular" — и их тоже бывает несколько, каждая со своими особенностями (одна удобная, другая работает стабильнее). В итоге количество возможных комбинаций растет геометрически, и есть вполне реальный шанс наткнуться на проблему, с которой никто до вас не сталкивался, потому что она возникает из конкретного вашего набора инструментов.
Это так просто! Зачем всё усложнили?!
потому что веб дев развивался несколько не следуя канонам софтваредизайна, как говорят ист
Мы намеренно хотим разделить эти вещи, потому что:
Код разработки хорош для разработчиков, но плох для пользователей
Код продакшна хорош для пользователей, но плох для разработчиков
если речь о генерации кода по модели, то упомянутое несколько некорректно так как код модели не
плох для пользователейа предназначен для генерации кода, который не
плох для разработчикова не предназначен для чтения и редактирования человеком. А если подходить с умом то можно было бы давно удалить код продакшна из процесса (код модели -> код продакшна -> исполнение браузером) и использовать напрямую код модели-> исполнение браузером.
Так проблема в том, что браузер не умеет код модели. Это как компиляция какого-нить C# или Java в JS — вынужденная мера.
И ещё дикая идея. В очень хорошо структурированой технологии, не было бы разницы где запускать код в браузере или это как GUI.
Предложил бы на базе Питона.
Он же принципиально тормозной.
Он же принципиально тормозной.
не думаю что особо по сравнению с JS. К тому же это чисто фейл интерпретации и разных моментов питона. При нормальном интерпретаторе можно эквивалентом С сделать.
не знаю что такое TAL-0.
то на этом языке сразу что ли все писать будут?
скорее всего не начнут, там колоссальная инерция всякого уже написанного быдлокода. Никто ж не будет отменять node или react и т.п.
Коменты натолкнули на идею что интерпретатор языка может быть самостоятельным от браузера, и вы с удивлением увидите что коллосс веб дева не нужен. Например на машине стоит Питон, на нём же хоть и не обязательно написана тонкая оболочка браузера. Веб страница соответствует некой компонетне унаследованной например от TK если его взять для GUI. Текст веб страницы — это модель для GUI, просто исполняется функцией exec, и не нужны танцы с бубном для DI в код оболочки потому что в питоне всё DI. Можно и песочницу встроить.
Нет, они сделают 10 браузеров и 30 скрепящих огромными шестернями технологий с крутыми именами.
Как по мне, заменить JS на Python ничего особо не изменит. Были одни косяки и странности, будут другие:
- Объявление переменных без ключевых слов var/let/const, приводящее к опечаткам. Раньше в ES3 такое тоже было, но в ES5 добавили strict mode, который это запрещает.
- Модульная система, в которой очень неочевидно делаются относительные импорты. В ES6 модули работают намного понятнее.
- Отсутствие приватности в модулях. Любая переменная или класс, будет доступна снаружи. Опять-таки, в ES6 экспорты явно отмечаются ключевым словом export.
Недавно пришлось поработать с проектом на Flask и после нескольких лет работы с Javascript эти странности вызывали некоторое недоумение.
Объявление переменных без ключевых слов var/let/const
и так понятно. Мне например надоедает писать модификатор, потому что он может легко определяться автоматически.
Да импорты и приватность в питоне немного проседают нужен модификатор вроде private-set и импорт только модуля, да и много чего…
Зато настолько гибкий язык, что фактически в базу (ненадо никаких Flask) занесён функционал например шаблонов, json- подобного синтаксиса обьектов, легкой модифицируемости под свой домен-специфический язык. Суть в том что там это уже есть даже в базе языка и работает в обычных прогах, а чтоб это было в вебе, дуплицируя это придумали XHTML, XPATH, CSS, JS там node, react всякие и т.п. делая тупую работу и абсолютно нереюсабельный код.
Мне например надоедает писать модификатор, потому что он может легко определяться автоматически.
Модификаторы за тем и пишутся, что их нельзя определить автоматически.
Если вам нужно чтобы всё определялось автоматически — просто пишите везде let и всё.
Модификатор const в любой корректной программе всегда можно заменить на let без изменений в поведении (единственное исключение — если вы используете eval в нестрогом режиме, но так делать не надо). Он нужен только для того, чтобы явно запретить самому себе из будущего менять переменную и попросить компилятор или интерпретатор за этим проследить.
Ну а модификатор var просто устарел и точка.
Он нужен только для того, чтобы явно запретить самому себе из будущего менять переменную
не, на этапе компиляции переменная которая «чуть чуть» меняется может замениться несколькими константами. «Чуть чуть» — значит изменения понятны на этапе компиляции.Пример:
a = 5, не в непредсказуемом цикле
делаем что то дальше
a = 10, не в непредсказуемом цикле
все значения a можно заменить на константы. Нельзя заменить только если присвоения определяются только в рантайме например в непредсказуемом цикле или по внешним данным например вводу с консоли или чтению файла.
чтобы явно запретить самому себе из будущего
а надо переменные правильно называть а лучше вынести все константы в отдельный файл.
Что скажешь поповоду гипотетического языка с таким обьявлением:
- Если модификатора нет, компилятор/ интерпретатор сначала пытается сделать переменную константой
- если не получается и переменная зависит от рантайма но в компайлтайме известны все типы, можно её статически типизировать. Это фактически предсказуемое число переменных с постоянным типом
- иначе типизируем её динамически
- также кто хочет мудохаться, можно задавать явные ограничители, вроде const или типов, причём можно применить или для типов например
Str|Int a - что действительно надо это модификатор private set потому что в компайл(интерпрет)тайме видны все присвоения переменной
А неважно на что переменная меняется в процессе оптимизаций, важно лишь что означает написанное вами определение.
Нельзя заменить только если присвоения определяются только в рантайме например в непредсказуемом цикле или по внешним данным например вводу с консоли или чтению файла.
Если у компилятора или интерпретатора есть полный код модуля, не использующий eval в нестрогом режиме, то у него не может быть никаких "непредсказуемых" циклов.
а надо переменные правильно называть а лучше вынести все константы в отдельный файл.
Как вы вынесете в отдельный файл переменную цикла: for (const item of array) {... }?
А неважно на что переменная меняется в процессе оптимизаций,
как меняется? каких оптимизаций?
то у него не может быть никаких «непредсказуемых» циклов.если значения переменных или вообще переменной цикла зависят от ввода или генерации случайного числа в рантайме. Иначе цикл просчитуется при компиляции и схлопывается, как делает gcc
for (const item of array)а, просто чтоб не присваивали item? зачем?
А вообще я смортю тут много сторонников лишней писанины, для установления ограничений… самому себе??
как меняется? каких оптимизаций?
Не важно каких, всё равно от этого ничего не зависит.
Иначе цикл просчитуется при компиляции и схлопывается, как делает gcc
Вот вы привели пример оптимизации. Эта оптимизация не важна, она никак не меняет смысл переменной.
а, просто чтоб не присваивали item? зачем?
Чтобы потом при чтении кода не задаваться вопросом "так, а не поменял ли кто-то эту переменную?.."
с какой стати нельзя определить это константа илои переменная и точный тип при компиляции/ интерпретации что ли?
Ну вот я написал:
a = 10;
a = 20;Возможно, в первой строке должно было быть const и, с-но, вторая строчка — ошибка, компилятор должен эту ошибку выдать. А возможно, в первой строке должен быть let, и тогда вторая строка — корректна, ошибки быть не должно.
Каким образом компилятор может догадаться, какой вариант правильный? Никаким.
Точно так же как никаким способом не догадаетесь и вы. А вот если стоит const — вы точно знаете, что переменная не меняется.
Так становится нельзя делать уже например при
a = input() или a = rand() и другое что неизвестно при компиляции.
То есть более умный компилятор может посчитать константой что-то, чего не считала константой старая версия, и из-за этого перестать компилировать код?
Ужасная идея.
я как раз писал о том что простые присвоения можно рассматривать как константы.
Зачем? Смысл const как раз в том и есть, что если явижу const a, то знаю что оно присвается только раз — при объявлении. И компилятор мне это гарантирует. А если я вижу a = 10, то что?
Вообще-то, любая операция присваивания как раз и означает, что её нужно выполнить всего 1 раз, и дальше подставлять результат! const тут ничего не меняет.
А каким боком тут const? Вот есть два куска кода:
// 1
const foo = JSON.parse(await readFile(...));
return foo.bar.baz;
// 2
let foo = JSON.parse(await readFile(...));
return foo.bar.baz;Какой из кусков кода будет использовать операнд по адресу, а какой — из регистра? :-)
«взять операнд, непосредственно идущий за командой». Последнее, как вы понимаете, быстрее.
Ох не факт. Из регистра должно быть самым быстрым.
immediate обозвали. Это может быть быстрее обращения к регистру.В общем случае нет. Даже если в кэше, не говоря о полноценном чтении из ОЗУ. Иначе регистры не нужны особо, их суть — сверхоперативный доступ к данным.
Но да, это какую-то экономию даёт.
Загрузка из регистра в ALU никогда не была отдельной микроопераций
Я не буду особо спорить, т.к. процессоры не проектирую, но подозреваю, что в современных процессорах, где есть большой пул регистров, для которого блок спекулятивного выполнения решает «а вот для этой операции мы тебя назначим в роли EAX» и есть пул исполнительных блоков, это всё-таки отдельная микрооперация.
μops'ы просто преобразуют CISC в RISC, если говорить условно. И всё. В ARM они не используются даже на современных суперскалярах, например.
Микроопераций управления там нет, что ли?Не очень понятно, что вы подразумеваете под «операциями управления». Да собственно вообще не очень понятно как вы себе представляете микрооперации и что они, по вашему, вообще делают.
Разве микрооперации — это только команды ALU и тому подобных блоков?В микрооперациях нет никаких «команд ALU» и «блоками» они не управляют.
То, что инструкции разбиваются на микроинструкции — это таки правда. А вот какого-то одного устройства, который их исполняет — в процессоре нет. Ну или, альтернативно, весь процессор, кроме декодера — это такое устройство.
А вот какого-то одного устройства, который их исполняет — в процессоре нет.
Ясно. Ну тогда наш спор возник на пустом месте. Если есть инструкция, то естественно, есть и устройство исполнения. Если в процессоре можно выделить блоки FPU, ALU, MMU и прочие штуки, и они выполняют какие-то действия по микроинструкциям, то считать или не считать их устройствами исполнения, это уже вопрос философии или там словесности, а не техники :)
Если есть инструкция, то естественно, есть и устройство исполнения.Совершенно неестественно. Потому что может быть много таких устройств.
Если в процессоре можно выделить блоки FPU, ALU, MMU и прочие штуки, и они выполняют какие-то действия по микроинструкциямВ том-то и дело, что выделить блоки можно, но эти блоки не выполняют никаких «действий по микроинструкциям». В процессоре имеются десятки отдельных блоков и каждая микроинструкция обрабатывается далеко не в одном из них. Более того, в процессорах со спекулятивным исполнением даже нельзя сказать, что они последовательно обрабатывается. Одна и та же микроинструкция может быть обработана одним и тем же блоком много раз (Pentium 4 этим был особенно знаменит).
Более того, она может быть спекулятивно исполнена на одном устройстве, после чего будет обнаружено, что это выполнение получило неверные данные — и после этого та же микроинструкция может быть исполнена на другом устройстве.
то считать или не считать их устройствами исполнения, это уже вопрос философии или там словесности, а не техники :)Это вопрос понимания. Если процессор у нас суперскалярный, то ALU у нас несколько (неожиданно, правда?), а если исполнение спекулятивное — то мы заранее даже не знаем какой из них какую операцию, допустим, умножения будет исполнять.
Ну и как в таком случае «микрооперация загрузки регистра» работает? Что, откуда и куда она может загружать? Вот как вы себе это представляете?
Совершенно неестественно. Потому что может быть много таких устройств.
Не понял смысл вашего возражения. Какая разница, одно устройство или несколько? На что это влияет?
Ну и как в таком случае «микрооперация загрузки регистра» работает? Что, откуда и куда она может загружать? Вот как вы себе это представляете?
Элементарно — устройство декодирования разбивает какой-нибудь MUL EAX, EBX на группу команд «загрузить слово из регистра 1», «загрузить слово из регистра 2», «перемножить», «сохранить результат в регистр 1». Затем этот самый блок спекулятивного выполнения (не важно, так он называется или нет, но устройство, которое выбирает порядок и конкретного исполнителя для микрокоманд там определённо есть, не так ли?) назначает блок-исполнитель и конкретные регистры для арифметической операции, возможно, проставляя им какие-либо атрибуты, превращая их в «загрузить слово из регистра X», «загрузить слово из регистра Y», «перемножить на ALU2», «сохранить результат в регистр Z»
И после этого по атрибутам они выбираются из конвейера в конкретный блок-исполнитель.
Ну и уточню — это ответ на «как я себе это представляю». Представляю вполне логично и адекватно, но как оно в реальности реализовано, я на самом деле не знаю, поэтому могу ошибаться. Если я не прав, напишите как на самом деле, если вы сами это знаете, а не догадываетесь точно так же, как и я.
Только плиз, не придирайтесь к формулировкам. Это за возражение и понимание не считается ;)
Затем этот самый блок спекулятивного выполнения (не важно, так он называется или нет, но устройство, которое выбирает порядок и конкретного исполнителя для микрокоманд там определённо есть, не так ли?)Конечно. Планировщик называется.
Ну и уточню — это ответ на «как я себе это представляю».Спасибо и на этом. Стало хотя бы понятно чего вы не понимаете. Вот этого:
И после этого по атрибутам они выбираются из конвейера в конкретный блок-исполнитель.Так делать нельзя. Часть конвеера между планировщиком и ALU — это как неподрессоренная масса в автомобиле. Любая ошибка в этом месте будет бить по производительности не просто сильно, а катастрофически сильно.
Не забывайте: ALU у нас штуки 3-4 всего. Представьте, что у вас есть команда, обращающаяся в память и вы её куда-то там запланировали. Что будет если данных ни в L1, ни в L2 не окажется? Не забыли ещё? Двести тактов мы будем ждать этих данных. Двести! И всё это время ваше ALU будет тупо греть воздух! Потому что пока не загружены данные мы не может ничего вычислять — а мы уже всё распланировали! И ALU «тупит и ждёт данных»? Так, что ли?
Нет — так дело не пойдёт. Процессоры проектируют так, чтобы назначение операции на ALU происходило после того, как станут известны её операнды, а не до. Беречь надо ALU, у нас их мало. А вот регистров зато много, их беречь не нужно (AMD в последнем поколении увеличила их количество со 168 штук до 180 штук, к примеру).
Потому в микрооперациях прописаны регистры (не архитектурные, конечно, а железные — для этого у нас есть переименование регистров), а вот ALU — там не прописано. Какое будет свободно — то и «подберёт» инструкцию…
Вот отсюда и мои вопросы:
Элементарно — устройство декодирования разбивает какой-нибудь MUL EAX, EBX на группу команд «загрузить слово из регистра 1»,Куда загрузить? Зачем загрузить? Вот взяли вы это число из регистра 1 — куда вы его пошлёте? В воздух? Оно будет сиять над процессором божественным сиянием?
Представляю вполне логично и адекватноНе совсем адекватно, как видим. Вы вот над чем задумайтесь: нафига нам 180 регистров, если у нас всего 4 ALU? Зачем всё это, если у вас всё в команде жёстко планировщиком прописано? Как это с вашей картинкой согласуется?
Какое будет свободно — то и «подберёт» инструкцию…
Ок, без проблем. А если результат предыдущей арифметической операции сразу же является операндом для следующей? Он все равно будет сохраняться в регистр, и ждать, когда его кто-то подберёт? Может, планировщик современного процессора всё-таки чуть умнее? ;)
Куда загрузить? Зачем загрузить?
В ALU. Разве оно в современном x86 производит операции непосредственно над содержимым регистров общего назначения? Очевидно же, что раз есть некая адресация и переименование этих регистров, то между ними и ALU есть схема выборки и непосредственно операции выполняются во внутренних регистрах ALU, а не в РОН.
Вы же не разработчик процессоров, а такой же, как и я, т.е. интересующийся, верно?
Он ведь в курсе и какие команды последуют потом, и какие данные операнды каких регистрах готовы.Про то, какие команды следуют потом он мало задумываются (ибо на частоте в 4GHz мы можем заставить работать только очччень ограниченную по сложности схему), а про то какие данные будут готовы и когда — он может знать только лишь ex post facto: далеко не все команды исполняются за одинаковое, предсказуемое, время. Особенно непредсказуемы команды загрузки данных из памяти: они мало того, что могут заставить вас ждать 200 тактов… они ещё и исключение могут вызвать и вообще весь конвеер вам сбросить.
А если результат предыдущей арифметической операции сразу же является операндом для следующей?То мы всё равно не может быть уверены, что у нас будет свободное ALU для обработки.
Может, планировщик современного процессора всё-таки чуть умнее? ;)Вы про operand forwarding? Да, в некоторых случаях он позволяет экономию в один такт получить. Но данные всё равно направляются и в регистр тоже.
В ALUСказка про белого бычка. В какое ALU? Их у нас несколько, не забывайте. И портов в этих ALU, кстати, тоже несколько.
Очевидно же, что раз есть некая адресация и переименование этих регистров, то между ними и ALU есть схема выборки и непосредственно операции выполняются во внутренних регистрах ALU, а не в РОН.Конечно. Но если вы не знаете в какое ALU вам загружать данные (а это зависит не только от того, готовы данные или нет, но и от того, какие ALU у вас свободны, а также от того, каким по счёту этот операнд у вас является), то куда вы будете их загружать? Разбить одну операцию на две микрооперации, чтобы потом их слить обратно в планировщике — это какой-то несколько странный подход, не находите?
Вы же не разработчик процессоров, а такой же, как и я, т.е. интересующийся, верно?Непохоже, чтобы вы этим реально интересовались, судя по владению предметом. Потому что представление у том, что внутри процессора происходит у вас, мягко скажем, приблизительное. И непохоже, чтобы таблички Agner Fogа или LLVM-MCA могли бы вам какую-нибудь пользу принести…
далеко не все команды исполняются за одинаковое, предсказуемое, время
Вы не путайте планировщик процессора и прикладного программиста. Это для нас они исполняются за непредсказуемое время. Для планировщика все операции абсолютно детерменированы и выполняются известное количество времени, за исключением загрузки данных из оперативной памяти.
то куда вы будете их загружать?
Не понимаю ваше, кхм, непонимание. Чем операция «сложить в ALU два операнда» отличается от операции «загрузить операнд из регистра в ALU»? Почему первую можно передать в свободное ALU, а вторую якобы нельзя?
По моему, это уже спор ради спора. Вы увидели пару неточностей в моих рассуждениях, и кинулись махать секирой «всё неправда, вы ничего не понимаете». Давайте прекращать.
Для планировщика все операции абсолютно детерменированы и выполняются известное количество времени, за исключением загрузки данных из оперативной памяти.Не только. Деление непредсказуемо, корни и тригонометрия. Даже умножение только на самых «больших» процессорах реализовано на сетках с гарантированным временем исполнения. Ну а загрузка (и выгрузка, кстати) — это, собственно, «слон в комнате и есть». На x86, с его нехваткой регистров, временные результаты очень часто в памяти хранятся — потому вам важно «не тормозить» с локальными данными… но и устраивать безумные задержки, когда кто-то обращается к массивам — тоже не годится.
Чем операция «сложить в ALU два операнда» отличается от операции «загрузить операнд из регистра в ALU»?Ничем не отличаются. Обе не имеют смысла.
Почему первую можно передать в свободное ALU, а вторую якобы нельзя?Ни первая, ни вторая не имеют смысла если вы не знаете в какое ALU их загружать. Не имеет смысла загружать что-то в «свободное ALU» если вы не знаете на каком ALU должны выполняться рассчёты. И точно также вы не можете ничего выгружать из ALU, если вы не знаете — какая там сейчас исполнялась команда.
Вы увидели пару неточностей в моих рассуждениях, и кинулись махать секирой «всё неправда, вы ничего не понимаете».Не совсем так. Если вы не читали Фейнмана, то почитайте — отличная вещь. А нам оттуда нужен всего лишь маленький фрагмент:
Занимаясь тригонометрией самостоятельно, я никогда не пользовался символами, которыми принято обозначать синус, косинус и тангенс, потому что мне они не нравились. Для меня выражение sin f выглядело как s, умноженное на i, умноженное на n, умноженное на f! Тогда я придумал другой символ, — ведь придумали же символ для обозначения квадратного корня, — сигму с длинной горизонтальной палкой, под которой я и ставил f. Тангенс я обозначал буквой тау с удлиненной крышечкой, а для косинуса я придумал букву вроде гаммы, но она была немножко похожа на знак квадратного корня.
Арксинус я обозначал с помощью этой же сигмы, но зеркально отраженной, так что она начиналась с горизонтальной линии, под которой стояла буква, и уже потом шла сигма. Вот это был арксинус, а НЕ sin-1 f, что выглядело как полный бред! В учебниках были такие выражения! По мне так sin-1 обозначал 1/ sin, величину, обратную синусу. Так что мои символы были лучше.
Также мне не нравилось обозначение f(x), для меня оно выглядело как f, умноженное на x. Не нравилось мне и dy/dx — всегда возникает желание сократить d, поэтому я придумал другой знак, что-то вроде &. Логарифмы я обозначал большой буквой L с удлиненной горизонтальной чертой, над которой
писал величину, из которой брал логарифм и т.д.
Я считал свои символы не хуже, если не лучше, стандартных — ведь нет никакой разницы в том, какие символы используются, — однако впоследствии я понял, что разница есть. Как-то в школе я что-то объяснял другому парнишке и, не подумав, начал писать свои символы, а он говорит: «Что это за чертовщина?» Тогда я понял, что если я разговариваю с кем-то еще, то мне следует использовать стандартные символы, поэтому, в конце концов, я отказался от своих обозначений.
Слова имеют-таки значение, хотите вы этого или нет.
Давайте прекращать.Да в общем-то давно пора. Называть красное зелёным, а белое — синим… это ваше святое право. А право любого другого посетителя Хабра — вас игнорировать. Это проще, чем пытаться понять каким знаком вы решили обозначить синус, а каким — логарифм.
Есть тут несколько персонажей со своими идеями о том, что и как называется — я c ними стараюсь не общаться. Так как на то, чтобы понять что они, собственно, хотели сказать, слишком сложно — редкие случаи, когда их «чертовщина» несёт-таки полезную информацию не стоят затрат, уходящих на то, чтобы разобраться в «потоке сознания», который на вас выливается при попытке с ними общаться.
const — это не для вас, это как раз для компилятора. Чтобы он понимал, что это выражение можно посчитать один раз и дальше в коде подставлять его результат.
Вообще-то нет. const — это для меня, чтобы я знал — эта переменная не меняется. А компилятору оно не надо.
Это и так всегда из контекста понятно
Если const стоит — конечно, понятно, а если не стоит — совсем непонятно. Вот написано: "a = 10" — по каким критериям я должен определить, что а — это константа и она не меняется?
Вот написано: «a = 10» — по каким критериям я должен определить, что а — это константа и она не меняется?
А очень просто. Это какая-то переменная, либо это говнокод. Вот если было бы написано MESSAGE_TYPE_TEXT = 10, то очевидно, константа.
И не забывайте про другие важные критерии: по каким критериям вам это вообще нужно знать, кроме любопытства? Знание предполагает использование, верно?
Вот если было бы написано MESSAGE_TYPE_TEXT = 10, то очевидно, константа.
Какой интересный критерий. Мне вот например такое ну вообще не очевидно. В отличие от «const» :)
Я понимаю что такое могло где-то исторически сложиться, но как минимум если следовать clean code, то пытаться запихать в имя переменной в каком либо виде её тип или любую другую аттрибутику, это не особо хорошая идея.
Вообще-то нет. const — это для меня, чтобы я знал — эта переменная не меняется.
а не лучше выделить обьявление констант в один блок, по требованием софтваредизайна — в начале текста или в отдельный конфиг-файл с константами, и/или использовать общепринятое имя что это константа, а не загружать язык разными декларациями.
Это не константы типа #define TRUE FALSE; это иммутабельная переменная
#define TRUE FALSE;
Не одно и тоже. "си-образные константы" не создают переменной, они разрешаются в компайл-тайме. const в js/ts создаёт переменную!
const в js/ts создаёт переменную!при должной оптимизации тоже разрешался бы в компайл/интерпрет тайме, что я писал выше. Собственно я неправильно думал что js/ts делает это с const потому что там уж точно написано что переменная не меняется, переоценил интерпретатор. Более того, так замещаться может также изменение переменной вида
a = 10…
a = 20 создаст 2 константы, известные в компайл тайме.
Как вы разрешите в компайл-тайме иммутабельную переменную, значение которой определяется юзерским вводом?
а не лучше выделить обьявление констант в один блок, по требованием софтваредизайна — в начале текста или в отдельный конфиг-файл с константами, и/или использовать общепринятое имя что это константа, а не загружать язык разными декларациями.
Ну вот:
function yoba(x, y) {
const z = x + y;
return f (z);
}как и куда мне вынести z?
Вам-то какой смысл иметь дополнительное указание, что это выражение, дескать, дальше не изменяется?
Это ещё и «запрет» для вас или кого-то другого на смену значения. То есть если вы решите поменять значение const, то обычно самое позднее при компиляции вам выдадут ошибку.
И тогда вы как минимум задумаетесь почему там стоит const и проверите нужен ли он там.
Полноте, в яваскрипте не меньше странностей, причем более серьезных. Например, неявное приведение типов. Или 2 типа undefined и null. Или параметры по умолчанию, которые вычисляются каждый раз при вызове и зависят от контекста. Или странный метод join у массива, который почему-то возвращает строку, хотя массив никакого понятия о строке и ее создании не должен иметь (в том же питоне это метод у строки, принимающий любой итератор, а не только массив). Все эти странности при сравнении переменных разных типов. В общем, то ещё веселье.
У меня кстати как раз обратный опыт. После питона яваскрипт кажется очень многословным, избыточным, такие вещи, как проверка вхождения значения в итерируемый объект в каждом случае требует вызова разных методов в зависимости от объекта. В общем, после питона все это выглядит как-то топорно и сложно.
Вот именно так и получается, меняем шило на мыло, один набор странностей на другие.
Хотелось бы нормальный удобный язык, но это, видимо, из области фантастики
Если вы не понимаете волшебные инструменты, всё ужасно запутанно
Есть иной вариант: вы понимаете эти волшебные инструменты. Но вы до веб-разработки писали под десктоп, и вы знаете, что да, всё действительно ужасно запутанно и неудобно. И нифига они не волшебные :(
волшебные инструменты (babel! бандлеры! вотчеры! и так далее!)
Да уж, прям верх магичности.
5 копеек по поводу сложности и ES vs JavaScript. Вся проблема вот этой сложности в том, что стандарт ES браузерные вендоры имплементируют не целиком, а по частям. Из-за этого вся е**я с проверками наличия функций и API и транспиляцией. В угоду того, чтобы сайт открылся любой ценой.
Представьте, что бы было, если бы на бекенде так было.
И конца этой истории видно, все браузерные движки получают обновления. Я искренне не понимаю, почему этот подход никто не изменяет.
Было бы идеально при разработке указывать версию ES, на которой ты работаешь и браузер бы это понимал и запускал соответствующую версию интерпретатора.
Если бы такой подход имел место, то не было бы никаких бабелов и всех этих магических инструментов.
Но, сожалению, версии стандарта не корректируют с версиями CSS и уж подавно с реализациями WebAPi, у которых вообще нет версий.
Было бы идеально при разработке указывать версию ES, на которой ты работаешь и браузер бы это понимал и запускал соответствующую версию интерпретатора.
В принципе, такое можно сделать и сейчас. Добавляем проверку на поддержку новых фич, если они отсутствуют – показываем пользователю баннер с просьбой обновить браузер
Бизнес такую идею не оценит :)
вот-вот, поэтому и пользуемся бабелем, автопрефиксером и другими подобными тулами.
И как вишенка на торте — теперь уже нельзя просто открыть исходник JS, там сам чёрт ногу сломит. Абстракция на абстракции и абстракцией погоняет. А все эти новые техники по типу ангуляра и вью вообще ломают привычный jQuery — подход.
Нет, я не буду утверждать, что стало хуже. Но вся грусть-печаль в том, что сложно (да и не надо уже) в этом зоопарке знать и понимать, как работает твоё приложение.
Достаточно понимать, как добиться требуемого результата, пользуясь новыми удобными конструкциями языка, а об остальном голова будет болеть у инструментов.
18 лет назад Дуглас Крокфорд опубликовал JSMin – первый минификатор Javascript. С тех пор понятие "сборка Javascript" стало нормой для мало-мальски больших проектов. Разработчикам нужен отформатированный читаемый код, а пользователям – наиболее компактный. Довольно странно, что столько лет спустя есть еще люди, которых это удивляет.
Например, в случае сборщика, требуется подгрузить и обновить все зависимости. Некоторые из которых могут сильно устареть и попросту не собраться. И тогда начинается самое интересное. И это не только в JS.
Подход к разработке через сборщик сейчас настолько популярен, что есть люди, которых удивляет желание контролировать все этапы разработки лично и хранить статические библиотеки необходимых версий вместо поручения этого сборщику с указанием нужных версий и зависимостей.
Ну не знаю, на мой взгляд современные веб фронтенд-фреймворки вполне себе умеют MVVM.
А если сравнивать с тем что мы имели 10-15 лет назад, то просто небо и земля;)
Ну не знаю, на мой взгляд современные веб фронтенд-фреймворки вполне себе умеют MVVM.Они «вполне себе умеют MVVM» — вот только на выходе они порождают нечто несуразное.
Я уже предлагал пролистать какой-нибудь Web-комикс на пару лет назад тут (MVVM, React и куча всего вкусного и можного) и тут (тупо по старинке, технологии 10-летней давности).
Потому что MVVM и прочие акронимы — это прекрасно, а вот конечный результат, зачастую — ужасен.
Если какую-то технологию кто-то не умеет правильно применять, то это на мой взгляд не является виной или проблемой технологии ;)
Если подавляющее большинство этого не могут сделать — то это уже вина технологии.
При этом, если честно, сайтов, сделанных на этих чудесных новых технологиях, но при этом не тормозящих и не жрущих ресурсы «как не в себя» я вообще не видел.
Если вы видели — покажите, у меня есть образ PCemu с [вирутальным] процессором 300MHz, можно будет посмотреть на отзывчивость.
А давайте зайдём с другой стороны и вы мне просто покажете сайты с функциональностью а ля amazon, facebook, web.de или хабр, но написанных на "старых технологиях" и не тормозящих/жрущих ресурсы :)
facebook 10 лет назад, хабр 10 лет назад, вконтактик 10 лет назад и т.д…
У меня все эти сайты прекрасно работали 10 лет назад на машине с 2Гб ОЗУ, браузер отжирал примерно 20% от того, что отжирает сейчас. На Хабре с тех пор появилась боковая панелька со стрелочками перехода к непросмотренным комментариям, ну и он несколько «мобильней» стал. В FB дизайн подрихтовали, ещё там мессенджер какой-то добавился, и картинки стало большего размера пихать. Что, стоят эти 5% функционала в пять раз большего потребления ресурсов? ;)
Ожидаемый ответ. Вот только давайте вспомним что во первых 10 лет назад точно так же было достаточно людей, называющих эти странички "тормозящими и жрущими ресурсы":)
И если уж на то пошло, то и сегодня лично я не испытываю никаких проблем с перформансом нынешних вариантов этих страничек.
Ну а во вторых за последние 10 лет добавилось всё таки больше чем "5% функционала". Одни только мобильные версии многого стоят.
И кстати кроме функционала для пользователей добавилась ещё и куча функционала для владельцев.
П. С. Ну и "раньше" оно всегда всё было лучше :) Это по моему закон человеческой психики :)
Вот только давайте вспомним что во первых 10 лет назад точно так же было достаточно людей, называющих эти странички «тормозящими и жрущими ресурсы»:)И что интересно — они тогда тоже были правы.
Одни только мобильные версии многого стоят.А чего они стоят? У всех перечисленных сайтов есть приложения — зачем при их наличии ещё и web-сайт уродовать?
И кстати кроме функционала для пользователей добавилась ещё и куча функционала для владельцев.Не знаю что там с владельцами, но для пользователей всё только хуже стало. Ибо из-за свистоперделок странички стали чаще сбрасываться на мобильниках — а функционала, позволяющего обнаружить новые комментарии после того, как страницы были перезагружены — нет и поныне. Напомню, что в LWN он был 10 лет назад.
П. С. Ну и «раньше» оно всегда всё было лучше :) Это по моему закон человеческой психики :)В данном случае, спасибо Archive.org, мы можем сравнить напрямую. Хабр 10 лет назад: 300 килобайт человеческого JavaScript'а, без всякой обфускации. Хабр сегодня: 900 килобайт обфусцированного… добра. Потребляемые ресурсы увеличились примерно на порядок… что мы получили за это?
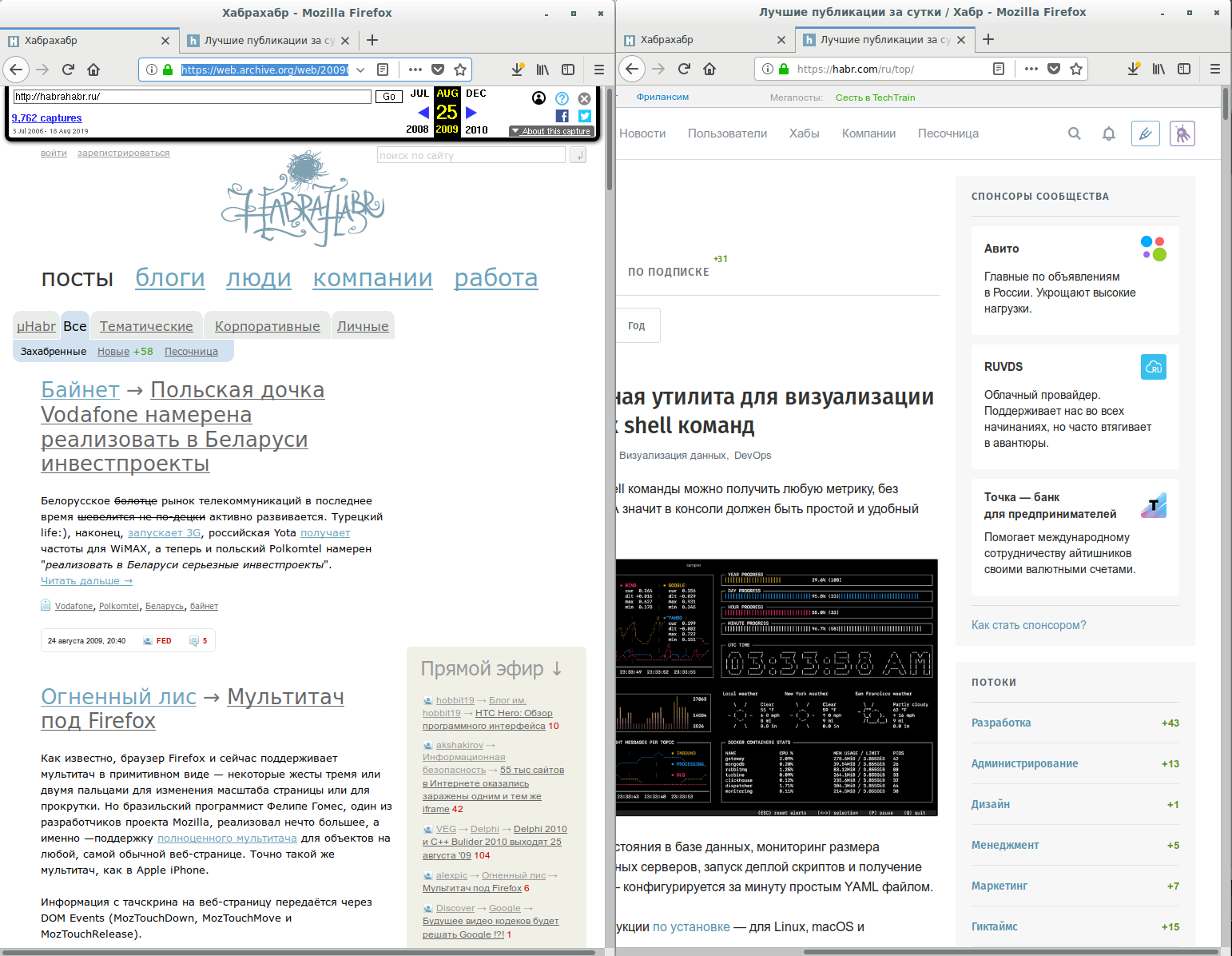
— Облако тегов пропало
— Найти популярные блоги стало сложнее
+ Хотя популярность вычисляется теперь за сутки/неделю/месяц
Ну а во вторых за последние 10 лет добавилось всё таки больше чем «5% функционала».Ну и какой конкретно функционал, которого кому-то остро не хватало, добавился на главную?
И что интересно — они тогда тоже были правы.
Тогда я всё ещё жду примеры «правильных страниц»:)
А чего они стоят? У всех перечисленных сайтов есть приложения — зачем при их наличии ещё и web-сайт уродовать?
Я например предпочитаю мобильные версии и приложения себе почти никогда не ставлю.
Не знаю что там с владельцами, но для пользователей всё только хуже стало.
Субъективное мнение, которого придерживаются далеко не все пользователи.
Тогда я всё ещё жду примеры «правильных страниц»:)От кого и зачем? Как я уже сказал: делать хорошо — невыгодно. Так что на на сайтах, живущих на хайпе вы ничего подобного не дождётесь.
Но если хотите пример… пожалуйтста: LWN 10 лет назад — 400 килобайт. LWN сегодня — 160 килобайт.
Конечно и то и другое, так-то, для 15-20 килобайт текста многовато… но Web-платформа дурная… хорошо сделать сложно. Уже то, что наблюдается прогресс, идущий в правильном направлении — само по себе неплохо.
Я например предпочитаю мобильные версии и приложения себе почти никогда не ставлю.А зачем тогда его делают? Зачем вообще выпускать всё нарастающее количество дерьма и оправдывать ужасное качество тем, что у нас нет времени сделать что-то нормально?
Серьёзно? Времени нет? Притом что сайт больше 10 лет существует? Ну дык его и не будет никогда если вместо одной, нормально сделанной вещи, порождать 100500 кучек дерьма…
Субъективное мнение, которого придерживаются далеко не все пользователи.Это всё достаточно объективно и измеряется. Вот как раз «стильно и молодёжно» — это измерить сложнее. Но реклама творит чудеса, только вот взамен — требует порождать дерьмо во всё больших количествах.
И лично мне на сегодняшний день абсолютно наплевать грузит страничка 300кб или 600кб или даже 900кб. Всё равно при современных скоростях и девайсах лично я не замечу разницы.
Но при этом лично мне важно чтобы мне было удобно пользоваться страничкой и её мобильной версией. И чтобы у неё было куча разных удобных для меня «свистелок и перделок».
П. С. И да, иногда мне даже хочется чтобы эта самая страничка была «стильная и молодёжная». И да, иногда для меня это даже важнее чем «лишние» килобайты, которые мне для этого надо скачать.
Всё равно при современных скоростях и девайсах лично я не замечу разницы.А я — замечу. Потому что бываю и местах, где безлимит и в местах, где только EDGE берёт.
Вы меня конечно извините, но измерять качество веб страницы исключительно через её размер это маразм.Это один, достаточно объективный показатель. Есть ещё потребляемая памяти и скорость реакции — но тут многое зависит от браузера, потому сравнивать сложнее.
И чтобы у неё было куча разных удобных для меня «свистелок и перделок».Ну и какие конкретно «свистелки и перделки» на Хабре оправдывают 5-10 кратное уверличение в требованиях к системе и что конкретно вам не нравилось в Хабре десятилетней давности?
На LWN, кстати, кой-какие фичи за прошедшие 10 тоже появились. И некоторые — мне вполне себе интересны. Но при этом они не требуют увеличения потребления ресурсов в 10 раз. Удивительно, правда?
П. С. И да, иногда мне даже хочется чтобы эта самая страничка была «стильная и молодёжная». И да, иногда для меня это даже важнее чем «лишние» килобайты, которые мне для этого надо скачать.Это нормально. Есть люди, которым важно, чтобы наушники имели хороший звук, а есть люди, для которых важно, чтобы они на Airpods походили.
Но вот только наушники с дерьмовым звуком «хорошими» никто не называет, как бы они ни походили на Airpods (хотя спрос есть, то есть «пипл хавает»), а в случае с вебсайтами — всё совсем не так. Почему, собственно?
А я — замечу.
Судя по всему таких как я гораздо больше чем таких как вы. И если это действительно так, то какой резон ориентироваться на меньшинство?
Есть ещё потребляемая памяти и скорость реакции
И опять же у меня на данный момент с этим нет абсолютно никаких проблем. Подозреваю что и здесь я далеко не одинок.
Ну и какие конкретно «свистелки и перделки» на Хабре оправдывают 5-10 кратное уверличение в требованиях к системе и что конкретно вам не нравилось в Хабре десятилетней давности?
Например мобильная версия, новaя лента, хабы, новый редактор, трекер…
И самое главное лично я никаких ограничений или повышенных требований к системе не заметил. Даже если они были.
Почему, собственно?
Потому что наушники с дерьмовым дизайном и удобством использования хорошими тоже никто не назовёт. Вне зависимости от того какой хороший у них звук.
Об этом и речь: «хороший» в данном контексте это понятие субъективное. И похоже ваше понимание «хорошего» в случае со страничками сильно отличается от понимания большинства и акцентируется на абсолютно других критериях.
У всех перечисленных сайтов есть приложения — зачем при их наличии ещё и web-сайт уродовать?
Потеряют пользователей типа меня. Если на сайт того же фейсбука с мобильника я иногда могу зайти, то приложение не установлю, а установленное не активирую.
Раньше и вебприложений с непростым UI и максимальной приближенностью к native по отзывчивости и usability не писалиА сейчас пишут разве? Почти любое web-приложение засунутое в нативное (популярный в последнее время подход) легко опознать по «дёрганью» (если тормоза при запуске не выдали). Потому что в таких «ультрапродвинутых» средах, как MacOS System 1 (1984й год) и Windows 1.0 (1985й год) была возможность «заморозить» изображение, изменить состояние контролов и атомарно это изменение вывести на экран. А Web-технологии — до этого не доросли. Максимум, что они могут предложить — не показывать изменения элементов, которые возникают, когда вы меняете DOM и CSS. Все рассчёты — всё равно просходят после каждого изменения чего угодно, а если не думать очень внимательно над тем, что и где происходит (а это очень сложно сделать, если у вас программа подтягивает сотни компонент, которые неизвестно что и где делают) — то это всё, в итоге, вываливается на экран.
И да, разработчики Chrome и Firefox очень стараются всё это скрыть и ускорить, сделать в ленивом режиме… но результат, в любом случае — это дикое потребление ресурсов и весьма паршивая отзывчивость.
Про CSS вообще молчу, то как его писали «раньше» — это стыд и позор и за такое вообще деньги нельзя брать.А что улучшилось с тех пор? Визуально только хуже стало, тормозов больше и отзывчивости никакой.
Вообще не могу сказать, что Web совсем не стоит на месте. Но просто все «новейшие» достижения типа Shadow DOM (ура-ура, ещё полгода и мы получим то, что в MacOS/Windows было лет 30 назад) — вызывают скорее улыбку и недоумение.
Напоминает фантастические романы, где люди, уже тысячи лет летающие на звездолётах забыли математику от слова «совсем» и теперь с удивлением «открывают для себя» дистрибутивность и ассоциативность… вот то же самое и здесь. Скоро и до известного прикола таким образом доберёмся.
ура-ура, ещё полгода и мы получим то, что в MacOS/Windows было лет 30 назад
Тут вопрос возникает, насколько корректно сравнивать ОС с приложением просмотра гипертекстовых страниц :) При том, что никто в здравом умер наверное не ожидает, что приложения MacOS System 1 и Windows 1.0 можно запустить на современных версиях без костылей, а вот нормального показа http://info.cern.ch/hypertext/WWW/TheProject.html ожидают...
Тут вопрос возникает, насколько корректно сравнивать ОС с приложением просмотра гипертекстовых страниц :)
С тех пор, как приложение для просмотра гипертекстовых страниц стало использоваться как среда для выполнения приложений, это стало совершенно корректно :)
а вот нормального показа info.cern.ch/hypertext/WWW/TheProject.html ожидают...
Раз на раз не приходится. Технологий, которые объявлены Legacy и убраны из современных браузеров, тоже не счесть.
где браузер возьмёт «соответствующую версию интерпретатора», если к моменту релиза браузера версии интерпретатора с поддержкой нужной фичи
Это проблема, согласен, но как-то все справляются с этим на бекенде. Есть же разныеверсии ОС, десктопные и мобильные. Софт делают не универсальным, а под каждую платформу и/или версию.
Это проблема, согласен, но как-то все справляются с этим на бекенде.Открою страшную тайну: на бекенде с этим справляются… за счёт наличия фронтенда.
В XX веке, когда фронтенда не было поддержка старых версий MacOS, Windows и так далее — была тем ещё цирком…
Был, а возможно и есть, такой дядька, Дэн Седенхольм, благодаря которому я познакомился с термином "пуленепробиваемый веб дизайн", сейчас этот подход похоже не особо котируется. Наверное стоит начать сожалеть об этом.
Никто(возможно почти никто) не вникает в то как работает его C# или Java код после компиляции.
Мм, это позволительно только юниор, имхо. Не вникать, как работает исполняемый код — плохая история.
Тут проблема немного шире
- Помимо исполнения есть ещё момент загрузки js на страницу, этот процесс может происходить разными способами
- Вариантов, как из исходников на мета-языках сделать нечто, что загружать бы и исполнилось на клиенте, тоже великое множество
Т.е. дополняя Вашу мысль: из проблемы вариативности вытекает проблема тулинга — он есть, но он нестандартный в силу вариативности способов доставки и исполнения кода.
И это, чёрт возьми, всем тоже вызывает мозг. Первые 2 дня настраиваем вебпак (сейчас обычно смотрят на мануал конкретного JS-фреймворка) со всем зоопарком, только потом начинаем делать что-то полезное для общества.
Автор не осилил Википедию поправить, как он с такой сложной веб-разработкой справляется?
Все на Flutter, товарищи!
Другими словами, переходите на Dart! Не скажу, что это лучшее решение
Почему? Язык на порядок адекватнее и JS и Python.
Некорректен сам тезис статьи.
Именно разработка фронтенда упростилась в разы. Мы получили абстракции и готовые решения над всеми основными болями фронтенда за последние несколько лет: сеть, синхронизация состония и представления, управление состоянием, инкапсуляция стилей, асинхронность, модульность и так далее. Только посмотрите как далеко ушли инструменты разработки в браузере! С точки зрения Developer Experience фронтенд развился очень сильно: от alert() и console.log до дебагера который умеет отлаживать асинхронные вызовы сохраняя весь стек. От script.js со всеми скриптами в одной куче до асинхронной подгрузки модулей по мере надобности. Современному фронтендеру нужно держать минимум информации в голове при разработке, за него это уже всё делают автоматизированные системы (линтеры, тесты, сборка, CI) и инкапсуляция. С этой точки зрения разработка стала даже проще.
А вот что усложнилось так это инструменты под капотом. Ты можешь поставить Parcel, собрать проект в одну команду и вообще не задумываться о том как оно работает. А если захочешь разобраться как работает каждый этап то увидишь насколько там всё сложно и тяжело для понимания.
Выше правильно отметили об избытке инструментов в современном фронтенде, даже был в своё время такой термин как Javascript Fatigue. Но этот период уже скорее прошёл, среди всех инструментов появились явные лидеры и выбирать приходится не из 10-25 вариантов, а из 3-4. При этом у вас всегда есть возможность попробовать что-то новое, даже если не на проекте, то для личного развития.
Так же сильно повысились требования к фронтенду, а соответственно и к фронтенд-разработчикам. Недостаточно просто знать HTML, CSS и JS, нужно разбираться в смежных областях, в инструментах, уметь писать тесты. Это новые ответственности фронтендера, про которые можно сказать что они усложнили саму сферу фронтенда. Но абсолютно такие же процессы происходят и в других областях, так что это вполне закономерно.
Различие продакшн кода и исходников это самая меньшая боль во фронтенде, особенно учитывая сколько задач она решает такой малой кровью.
А вот из действительно больших нерешённых болей фронтенда я бы отметил кроссбраузерность. И это не про поддержку фичей, а про поведение браузеров. До сих пор в 2019 году вам придётся городить велосипеды для исправления поведения браузеров. Может показаться что со смертью IE и Edge эта проблема решилась, но на самом деле нет потому что появились различные мобильные браузеры которые в некоторых аспектах работают совсем иначе чем десктопные. И далеко не факт что под ваш конкретный баг есть готовое решение.
Проблема не в сложности фронтенда, а в том, что на фронте огромная куча людей с практически нулевой базой. Знаний нет, навыков нет, и по-хорошему, на крепкого стажора-то эти люди часто не тянут, зато называются "мидлами", а то и "сеньорами".
Та же проблема была в беке с ворохом "php-программистов", но со временем бек повзрослел и проблема как-то сама собой исчезла. То же будет и на фронте.
Пишутся низкокачественные библиотеки, которые многие начинают использовать в других библиотеках и пошло поехало.
Про память вообще никто не думает (а зачем, это же JS). От сюда одностраничники жрущие гигабайты памяти!
А по факту, ситуации бывают разные, внутренние сервисы компании, в которых все всегда на последних версиях браузеров, могут писаться на чистом JS с новыми фишками. Где-то проще небольшой и срочный проект на jQuery набросать и быть уверенным что у всех всё ОК.
Но чаще всего, конечно да, если проект не однодневный и будет расти экспоненциально, то тут уж нужно пилить какой-то boilerplate с webpack'ами и с JS фреймворками, чтобы кодовая база росла, а сложность — нет.
1. Сегментация. Браузеров много и они разные. Порой различия встречаются в самых неожиданных местах, влияющих на результат непредсказуемым образом. Даже если мы говорим о «современных» и «вечнозеленых» браузерах. Отсутствие монополии, в этом аспекте — палка о двух концах. Тут написали уже, про то какие фронтендеры недопрограммисты и веб-макаки, но я посмотрел бы на умников, которые это пишут, если им пришлось бы работать со средой исполнения, которую они никак не контролируют, ни в плане доступных ресурсов, ни в плане поддержки технологий, ни в плане параметров области вывода данных ни в плане доступных способов взаимодействия с UI. Каждый из этих пунктов — множитель сложности и потенциальный источник проблем, подумайте на досуге, во что это выливается в совокупности.
2. Сегментиция. В вебе решаются ОЧЕНЬ разные задачи. Кому-то нужно отобразить простой html-документ, а кому-то сделать сложное интерактивное приложение. А кому-то нужно сделать нечто среднее. В каждом случае, нужны свои подходы и архитектурные решения.
3. Сегментация. Продукты делаются под определенный сегмент аудитории. Продукты «для всех» — достаточно редкий случай. Ваши пользователи могут быть как продвинутыми так и полными нубами. Пользователи могут быть мотивированными, а могут оставлять вам только крохи своего внимания, забитого остальным информационным шумом. Пользователи могут охотно платить за ваш сервис, а могут делать все, чтобы вас обхитрить тем или иным образом. Все это, в конечном счете, сильно влияет на реализацию и соотношение ваших производственных затрат.
4. Безопасность. Многие, рассуждая о веб-технологиях, заводят старую шарманку, про то, какой JavaScript плохой и непродуманный язык, и вообще сайты нужно писать на условных «плюсах» со строгой типизацией и жестким ручным контролем памяти. Подумайте о том, что веб — это открытая среда, и в ней водится очень разная «рыба». Вы хотите, чтобы на вашей машине исполнялся чей-то «замечательный» скомпилированный высокопроизводительный код, написанный неизвестно кем и с какой целью? Браузер — это песочница, и определенная доля компромиссов с производительностью — плата за свободу в вебе. JavaScript — мощный и выразительный язык, и его дизайн — прямое следствие его главного назначения. (WASM — совсем не панацея, как некоторым кажется).
Радует, что в последнее время ситуация с веб-разработкой постепенно исправляется. Браузеры реализуют поддержку нужных стандартов (а принятие этих стандартов — это процесс сам по себе очень непростой), которые многое меняют и делают многие вынужденные усложнения ненужными.
Вы хотите, чтобы на вашей машине исполнялся чей-то «замечательный» скомпилированный высокопроизводительный код, написанный неизвестно кем и с какой целью?А что в этом плохого?
Браузер — это песочница, и определенная доля компромиссов с производительностью — плата за свободу в вебе.Очень малая. C++ что в PNaCl, что в WebAssembly — всё равно гораздо эффективнее JS. При полном контроле.
JS — это «первородный грех» Web'а. Задуманный как «дерьмо собачье» (вот прямо из первых рук: “I was under marketing orders to make it look like Java but not make it too big for its britches. It’s just this sort of silly little brother language, right? The sidekick to Java.”) он, даже после десятилетий полировки, всё равно остаётся довольно-таки… эксцентричным языком.
Ну вот как в C++ есть «первородные грехи» (в частности тот факт, что есть как нормальный std::array, так и «полутип» — «обычный» массив), так и в JS они есть.
Браузер — это песочница, и определенная доля компромиссов с производительностью — плата за свободу в вебе.Doker — это тоже песочница… и никаких ограничений на языки она не накладывает. И Linux приложения на ChromeOS — тоже в песочнице живут и ради этого никто не переходит на прототипное наследование. Странно, да?
JavaScript — мощный и выразительный язык, и его дизайн — прямое следствие его главного назначения.Вот же ж блин. Все слова правда — а смысл… ровно на 180%. Действительно его дизайн — рождён из основной идеи: не быть хорошим языком. Как, собственно, его автор совершенно честно и признал. При этом JS сегодня — это действительно мощный и выразительный язык… ну потому что фирма, которая «заказывала» этот язык давно исчезла и сегодня эту «свинью» обмазали буквально тоннами помады. Но это не делает его хорошим. Он по-прежнему плох, просто так получилось, что в определённых областях — он безальтернативен…
всё равно гораздо эффективнее JS
Это в каком месте оно эффективнее? В воронке производительности, узким местом является работа внутренних механизмов браузера, при работе с ними через API. Открою Вам секрет: там все очень сложно, куча комбинаторики, и написано оно вовсе не на JS.
Открою Вам секрет: там все очень сложно, куча комбинаторики, и написано оно вовсе не на JS.Спасибо, я в курсе. Люди, которые этим занимаются сидят через коридор от меня. Вы только к кучке эпитетов забыли добавить ещё один. Важный: там сложно, куча комбинаторики, а главное — всё это не нужно. Вернее — не нужно было бы в идеальном мире, где фронтэнд можно было бы разрабатывать не только на HTML+JS.
Это в каком месте оно эффективнее?Во всех, которые имеет смысл сравнивать: скорость работы, отзывчивость, потребление памяти. Любое приложение на QT или FLTK требует в разы меньше ресурсов, чем типичный высер на HTML+JS. Даже какой-нибудь YouTube.apk требует на порядок меньше ресурсов и работает гораздо плавнее, чем YouTube.com в браузере. И так далее.
И не надо рассказывать про безопасность — с этим всё тоже в порядке. Единственное, в чём вы проигрываете — это в возможности использования «условных дешёвых индусов». Ну и в кроссплатформенности — но тут есть другие подходы.
Вернее — не нужно было бы в идеальном мире, где фронтэнд можно было бы разрабатывать не только на HTML+JS.
Пожалуйста — native apps.
Вернее — не нужно было бы в идеальном мире, где фронтэнд можно было бы разрабатывать не только на HTML+JS.
Так браузеры и пишутся не на js/html. С-но, тот код, который по факту тормозит — это не js. Это та условная сишка, на которой написан дом и рендер. Потому что за редким исключением 90% времени тормозящее приложение апдейтит дом и рендерит его. А уже остальные 10% исполняется клиентский js.
И основная часть оптимизаций для страниц сводится к тому, чтобы пооптимальнее дергать дом-апи и эффективнее использовать рендер.
Любое приложение на QT или FLTK требует в разы меньше ресурсов, чем типичный высер на HTML+JS.
Еще раз — браузеры пишутся не на js+html. И те ресурсы, что жрет страница — жрет не код страницы. Жрет код браузера.
Почему он такой тормозной и требует такого количества ресурсов (несмотря на то, что на условной сишке) — ну это сами можете ответить.
Так тормозит рендер не сам по себе, а потому что на него слишком много фич повесили, к тому же не самых удобных в реализации.
Почему он такой тормозной и требует такого количества ресурсов (несмотря на то, что на условной сишке) — ну это сами можете ответить.Легко: потому что вместо примитивов «провести линию из точки с координатами X₁Y₁ в точку X₂Y₂» какой-то архитектурный астронавт ему навязал DOM-деревья с CSS-свойствами, которые в принципе не реализуемы ни на какой архитектуре эффективно, а также черезвычайно неэффективный язык, который далёк как от того, что думают программисты, так и от железа.
Добавлением 100500 уровней абстракции эту проблему не решить.
Ну не думаете же вы, что ответ в том, что горстка программистов, разрабатывающих FLTK умнее, чем десятки тысячи разработчиков браузеров и фреймворков на JS?
провести линию из точки с координатами X₁Y₁ в точку X₂Y₂
Так это вполне доступно на canvas, и в SVG (там тоже DOM, но более быстрый). А теперь попробуйте нарисовать «примитивами» простенькую табличку и заполнить ее ячейки текстом произвольной длины.
А теперь попробуйте нарисовать «примитивами» простенькую табличку и заполнить ее ячейки текстом произвольной длины.Дык легко: берёте Pango — и вперёд. Что-то? У вас нет возможности использовать Pango? Ну так в этом и беда: в браузере у вас «руки связаны». Причём, что смешно, даже в браузере типа Firefox'а, который сам таки Pango использует…
Создание кода для фронтэнда — это бег мешке, когда на вас ещё и смирительная рубашка, а сверху — ещё один мешок, уже на голову.
То, что фронтэндеры, в этих условиях, ещё что-то работающее, в конце-концов, порождают — иначе как подвигом не назвать, их работа вызывает уважение… а вот то, что других вариантов сделать что-то, чем люди смогли бы пользоваться, у них нет — вызывает грусть.
Впрочем для решения таких проблем есть webassembly и webgl, просто пока удобных инструментов нет.
Легко: потому что вместо примитивов «провести линию из точки с координатами X₁Y₁ в точку X₂Y₂»
Я правильно понимаю, что вы с каждым сайтом предлагаете тащить свою копию полноценного гуитулкита, и при переходе на страницу поднимать соответствующее окружение в виртуалке?
Только не с сайтом, а с приложением.
Именно для сайтов, т.е. некоторым образом оформленных блоков текста с картинками, html + css — довольно адекватная связка.
А вот при разработке приложений с большинством плюсов веба так или иначе в итоге приходится бороться. Только проблема в том, что альтернативы ещё хуже (главным образом, по части доставки приложения до пользователя).
Я правильно понимаю, что вы с каждым сайтом предлагаете тащить свою копию полноценного гуитулкитаМожно использовать CDN (как они и сейчас используются). И вы зря думаете, что «копия полноценного гуитулкита» — это что-то огромадное. Какой-нибудь FLTK занимает мегабайт — и это сегодня, когда о размере никто не думает особо. В те времена, когда об этом думали в 3-5 мегабайт влазила целая электронная таблица с графиками и прочими красивостями (полный комплект занимает аж целых десять мегабайт, что во-первых всё равно не смертельно много по меркам современного веба, а во-вторых там есть и тьюториал и подсказки и много чего ещё, помимо собственно электронной таблицы).
Можно использовать CDN (как они и сейчас используются).
- А версионность как обеспечивать?
- это мне придется сотни гигабайт всех фреймворков хранить на своем смартфоне, чтобы можно было с минимальным комфортом по интернетам серфить? а если вдруг нужная версия не закеширована и связь плохая то все, сайт в отказ? ну спасибо, экономия ресурсов, надежность и вообще качество подхода налицо..
Какой-нибудь FLTK занимает мегабайт — и это сегодня, когда о размере никто не думает особо.
Какая разница, сколько FLTK занимает, если он не будет работать?
Вот у вас есть х-сервер голый и есть прикладное приложение. А все, что между ними — вам надо тянуть в зависимостях. Это не мегабайт. И даже не 10 мегабайт. И не 20 и не 50.
Ну и да, кому нужен ваш fltk если он говно и кроме маленького размера в нем ничего хорошего нет? все должны теперь будут использовать только говно? Прекрасный подход!
Кстати, в этот 1мб все зависимости входят?
В те времена, когда об этом думали в 3-5 мегабайт влазила целая электронная таблица с графиками и прочими красивостями
Всего лишь одна уродливая таблица из 80-х с нулевым юзабилити и минимальными возможностями для программиста целые 3-5 мегабайт? Ну извините, а полноценный гуй сколько тогда будет весить?
Кроме того — а сколько весит окружение, которое нужно установить, чтобы эта таблица вам нарисовалась?
Кстати, напоминаю что в то время на пеках было меньше 1мб оперативной памяти. Т.е. сегодняшний аналог этих 2-3мб — это 50+гб.
И не надо рассказывать про безопасность
ну, раз так, может вы расскажете? Вот вы перешли по ссылке и получили исполняемый бинарник. Какие Ваши дальнейшие действия? Поместили его под карантин в песочницу? Выделили ему виртуальных ресурсов? Сколько? Дополнительных затрат ресурсов на виртуализацию у вас, конечно же, никаких нет? Песочница общая для всех, или своя для каждого? Доступ к внешним ресурсам как организован? К сетевому стеку, кэшу? А вам не нужен OpenGL какой-нибудь? А динамически запрашиваемые зависимости как разруливать? Как отслеживать активность процессов в фоне? Размер экрана у вас один на всех устройствах? Доступны мышь и клавиатура? Приложение будет так работать, или ему нужно распаковать свои файлы и записать их в файловую систему? Куча людей долгое время пыталась ответить на все эти вопросы, в итоге мы имеем современный браузер. Но они просто идиоты и комментариев на Хабре не читали: нужно было все делать на QT. И вообще, зачем веб, если есть нативные приложения, верно?
Выделили ему виртуальных ресурсов? Сколько?Столько, сколько он запросил, очевидно. Ну или если столько нет — сказал бы, что «опа — ресурсов нету».
Дополнительных затрат ресурсов на виртуализацию у вас, конечно же, никаких нет?Почему нет. Есть. Где 10-15%. Сильно меньше чем разница между самым наирахэффективнейшим компилятором JS и нормальным C++ кодом.
А динамически запрашиваемые зависимости как разруливать?А как они разруливаются в современных веб-приложениях?
Размер экрана у вас один на всех устройствах?Давно вы видели приложения, которые поддерживают одно разрешение? Я только игры такие видел — и довольно-таки давно. Эту проблему нативные прилоежния решили задолго до того, как Web-приложения её решили: какой-нибудь WinHelp из Windows 3.1 прекрасно занимает весь мой 30" 2560x1600 экран и прекрасно живёт в лоскутке на ¼ его, а вот Хабр — увы, ни так, ни так не умеет.
Куча людей долгое время пыталась ответить на все эти вопросы, в итоге мы имеем современный браузер.Вот только современный браузер — это ни разу не результат попыток «ответить на этот вопрос», а результат попытки превратить банальный редактор гипертекста в что-то, для чего он никогда не предназначался.
И вообще, зачем веб, если есть нативные приложения, верно?Нет, неверно. Ответ как раз на этот вопрос известен: веб потребовался из-за того, что, в своё время, когда Microsoft делала ActiveX она уделила недостаточно внимания безопасности, а потом — и вовсе перешла в чистую архитектурную астронавтику, кончившуюся мертворождённым высером. В результате единственный способ обеспечить запуск кода, которому вы не доверяете, на большинстве OS — это браузер.
Но это не значит, что это хороший способ. Более того — это не значит, что он будет оставаться долгое время единственным.
Ой, да ладно, в чём же Silverlight был мертворожденным-то? Убил-то его лишь отказ браузеров от NPAPI.
Вот что правда было мертворожденным, так это встроенная песочница CLR.
Убил-то его лишь отказ браузеров от NPAPI.Как раз наоборот — от NPAPI удалось отказаться из-за того, что Silverlight «не взлетел».
Ой, да ладно, в чём же Silverlight был мертворожденным-то?А как? Плагин для порождения «чего-то такого в браузере» уже был (это и Flash и Java), возможность делать приложения сразу и для браузера и для десктопа и для Windows CE не реализовалась… так за счёт чего он мог выжить? Чего он позволял сделать такого, что без его использования нельзя было сделать с меньшими проблемами и гораздо быстрее?
Ни Flash, ни Java не позволяли писать на C# или VB.NET. Там не было XAML. И WCF RIA там тоже не было.
С#, VB.NET, XAML, WCF RIA и прочее — это всё инструменты. Которые имеет смысл выбирать, если нет способа решить ту же задачу другими, более отлаженными и знакомыми разработчикам, инструментами.
Первая версия GMail (с асинхронной подгрузкой писем и кучей разных других плюшек) — вышла в 2004м, первая версия Silverlight вышла в 2007м.
То есть к моменту выхода Silverlight все бизнес-задачи уже имели то или иное решение. Никто не будет менять работающиее решение на другое, несовместимое с ним без крайней необходимости.
Вот если бы Silverlight вышел где-нибудь в 2001м-2002м году… да вместе с новой версией Windows… да с приложениями на C#… фиг его знает, что было бы — но шанс имелся бы. В 2007м? Поезд ушёл…
Почему вы не допускаете возможности, что некоторое решение некоторой задачи может быть попросту проще других альтернатив?
Вы вообще ну хоть один пример можете вспомнить, когда более простое решение, требующее, однако, переписывания всего-всего-всего (это принципиально) — вытеснило бы более сложное?
Единственный пример, который навскидку вспоминается — это переход с Python 2 на Python 3. Но тут и полного переписывания не требовалось и, главное, старое решение быстро и решительно искусственно подавили, «загнали в гетто» — и то пришлось десять лет «засовывать новшества в глотку», чтобы люди «оценили»…
Нет, более простое решение — это хорошо, приятно, полезно, это замечательный бонус… но это ни разу не повод на него перейти.
Это может быть поводом перейти на совместимую платформу (C ⇒ C++, Java ⇒ Kotlin и т.п.), но если старые разработки нужно выкинуть и всё реализовать заново… ну не знаю — приведите примеры, можно будет обсудить.
А что, новыми проекты не бывают никогда? Всегда есть что-то старое, нуждающееся в сохранении?
Всегда есть что-то старое, нуждающееся в сохранении?Почти всегда. Даже если вы начинаете что-то новое, свежее, вкусное… через какое-то время оказывается, что вот там есть библиотечка, которую можно поиспользовать, тут какая-то утилитка, которую можно прикрутить и так далее.
Единственное исключение — это появление новой ниши, куда, по той или иной причине, имеющийся код «прикрутить» нельзя вообще… никак, никому (в том числе вашим конкурентам)… но, как уже было замечено, к 2007му Web уже стал сам по себе местом, где появилось много полезного легаси — теперь на JS.
А что, новыми проекты не бывают никогда?Их недостаточно много для того, чтобы целая платформа могла выжить.
Да вспомните Windows. Почему Windows 1.0 и 2.0 были чем-то, что люди видели на выставке, но не использовали, а Windows 3.x и Windows 9X — стали безумно популярными? Потому что в Windows 3.x и Windows 9X была хорошая поддержка MS DOS.
Да, со временем, когда ваша платформа уже доминирует на рынке, можно от легаси и отказаться (современные версии Windows x64 не поддерживают MS DOS ни в каком виде)… но это можно сделать после завоевания популярности, никак не до.
По вашей логике, у языка Java не было никаких шансов, ведь у него не было нормальной обратной совместимости с Си.
И у C# тоже не было шанса выжить, ведь у него не было совместимости с Java.
По вашей логике, у языка Java не было никаких шансов, ведь у него не было нормальной обратной совместимости с Си.Java — это вообще великолепный пример. Если вы помните — её двигали в массу разных мест: аплеты, мидлеты, криптокарты и бог знает что ещё. Однако удалось взлететь ей либо там, где можно было её внедрять постепенно и использоввать легаси-код (Enterprise и Android), либо там, где альтернативы просто не было (JavaCard или Blu-Ray диск вы можете программировать только на Java — и никак иначе… см. Web и JavaScript).
Для ниши «приложения, которые сегодня работают только под AIX/HP-UX/Solaris, но нам нужна версия под Windows тоже» — оно вообще подошло идеально.
Ну Sun, конечно, хотел бы, чтобы движение пошло в обратном направлении… но не всегда наши желания совпадают с нашими возможностями.
И у C# тоже не было шанса выжить, ведь у него не было совместимости с Java.Совместимость с Java как раз была. Был J#, был JLCA, были места где C# был безальтернативен (расширения для MS Office, к примеру).
Во всех этих случаях вам не приходилось сразу выкидывать ваш legacy код, вы могли переходить на новый язык помодульно (в частности OpenOffice.org в резултате имел несколько компонент на Java… DocumentFoundation потребовалось несколько лет, чтобы от них избавиться).
Переход же на Silverlight требовал переписать всё — и сразу. Для того, чтобы получить продукт, который мог делать то, что вы и так уже могли делать без Silverlight. Кому это нужно?
Однако удалось взлететь ей либо там, где можно было её внедрять постепенно и использоввать легаси-код
А Silverlight что, нельзя внедрять постепенно?
Совместимость с Java как раз была. Был J#, был JLCA
Вот только первый инструмент не позволяет взять готовую библиотеку и использовать её, а насчёт второго у меня есть сомнения в сохранении поведения при портировании.
Скорее нет, чем да. Он не работал с DOM и CSS, общение с JavaScript было весьма сложным… а легаси-компоненты, написанные на C++ и Fortran нельзя было использовать вообще никак.Однако удалось взлететь ей либо там, где можно было её внедрять постепенно и использоввать легаси-кодА Silverlight что, нельзя внедрять постепенно?
Всё так. Но тут, как я уже говорил, вопрос в сроках. Java Swing (после которого только и появились первые успешные проекты на Java) — это 1998й год. C# — это 2000й год.Совместимость с Java как раз была. Был J#, был JLCAВот только первый инструмент не позволяет взять готовую библиотеку и использовать её, а насчёт второго у меня есть сомнения в сохранении поведения при портировании.
За эти два года люди просто не успели наработать критическую массу проектов, которые требовали бы 100% совместимости. Разработчики, писавшие этот код — всё ещё были на месте, да и не были они «синьорами с 10 годами стажа», опыт Java их не сильно напрягал ещё.
Собственно откуда берутся всё более жёсткие требования к совместимости? Оссификация софта. Пока у вас 10'000 строк легаси-кода, вы можете вообще всё выкинуть и переписать с нуля. Если у вас 100'000 строк — тут уже нужно это делать в несколько этапов. А если у вас 100'000'000 строк кода — то любой новый инструмент должен встраиваться так, чтобы его мало кто, кроме тех, кто с ним экспериментирует, вообще замечал.
Как я сказал ранее:
Вот если бы Silverlight вышел где-нибудь в 2001м-2002м году… да вместе с новой версией Windows… да с приложениями на C#… фиг его знает, что было бы — но шанс имелся бы. В 2007м? Поезд ушёл…
Всё еще не понимаю, откуда у меня есть 100'000'000 строк старого кода в новом проекте...
Все проекты будут у вас новыми, если они под новую, до того не существовавшую, платформу.
А если платформа старая (а Silverlight выходил для покорения Web'а, который к тому времени существовал уже более 10 лет) — то у вас будут проекты на 100'000 строк и на 100'000'000 строк.
Ничего не знаю про покорение веба, в моём мире Silverlight конкурировал с Flash и Java-апплетами, а не с сайтами на HTML.
Идея Microsoft (project Avalon) заключалась в том, чтобы на C# и XAML делалось всё — и локальные приложения и игры и веб-сайты тоже.
Однако из-за такой всеобъемлющей идеи разработку безбожно затянули, Longhorn вообще кончился крахом, на C# и XAML массового перехода так и не было… А Silverlight, Flash и Java-апплеты оказались никому толком не нужны… когда всё необходимое стало возможно на HTML/CSS+JS…
Ну так вымерли-то они примерно одновременно, проиграв HTML5. И когда Silverlight только появлялся — это ещё не было ни разу предопределено, напротив — развитие HTML в то время застряло намертво, и даже движок V8 ещё не был изобретен.
Так что не был Silverlight мертворождённым.
И когда Silverlight только появлялся — это ещё не было ни разу предопределено, напротив — развитие HTML в то время застряло намертво, и даже движок V8 ещё не был изобретен.V8 ещё не был изобретён, но Firefox и Safari уже открызали потихоньку market share у MS IE 6.
А Microsoft затевал авантюру с Windows Phone 7 (где как раз всё должно было на C# и XAML было быть сделано).
Но как я сказал — он опоздал. Так же, как WebAssembly опоздал. Если вы в 2009м Mozilla не выкаблучивалась, помогла бы портировать легаси-код NaCl — всё моглы бы быть по другому.
А сегодня — легаси это уже груды JS-библиотек и, главное, разработчиков.
А при чём тут вообще IE6 и Windows Phone 7?
Ну вот примерно как первая замена процессора у Маков: модели на 68040 были заменены на модели на PowerPC, что позволило избежать «отката» — а 68060 ради этого был проигнорирован.
Но Microsoft с этой «заморозкой» и переходом затянул — и успела появиться альтернатива. В 2007м альтернативные, более продвинутые, браузеры хотя и не вытеснили ещё MS IE 6, но уже существовали и было понятно, что за ними — будущее. А программы для Win32 прекрасно выпускались без всяких новых API, поддерживаемых только в C#.
Потому крутой SDK для Windows Phone 7 чисто на базе C# и XAML вызвал не кучу желающих всё переписывать, а, скорее, кручение пальцем у виска.
Какая разница что там были за глобальные идеи, когда обсуждается конкретно Silverlight?
А чудесного мира, придуманного Microsoft где всё вокруг — C# и XAML… не случилось.
Собственно даже то, что Silverlight появился — это уже признание его мёртворождённости.
В том мире, который планировался в Microsoft — его не должно было быть. Вместо этого программы на C# и XAML должны были исполняться единой средой исполнения, вокруг которой весь Longhorn должен был быть построен.
Вместо этого куски этого проекта слепили в плагин для браузера и отправили «в свободное плавание»: а вдруг выстрелит? Не выстрелило…
Он никак не может заменить HTML+JS
Но мог заменить большую долю Flash
потому что не работает на iOS и Android
iOS — ровесник Silverlight, а не нечто, существовавшее до начала разработки
В том мире, который планировался в Microsoft — его не должно было быть.
Ну вот вы сами признали, что "мир, который планировался в Microsoft" и Silverlight — два отдельных проекта. А значит, недостатки первого никак не относятся ко второму.
Именно в этом и проблема: iOS and Android — ровесники (или почти ровесники) Silverlight, а для выживания — Silverlight должен был появиться за 2-3 года как минимум до их появления.потому что не работает на iOS и AndroidiOS — ровесник Silverlight, а не нечто, существовавшее до начала разработки
Чтобы накопить критическую массу проектов. Flash долго боролся и если бы Adobe тупо не отказалась выпускать Flash для Android 4.4+ — то у него был бы шанс (хотя 100% уверенности нет — это была бы эпическая битва Android & Chrome против iOS).
А Silverlight оказался сразу в состоянии, когда у него ещё нет ничего, что могло бы удерживать его на плаву — а его уже пытаются удушить…
Нет. «Мир, который планировался в Microsoft» должен был быть построен на движке CRL и XAML встроенным в самый центр операционной системы.В том мире, который планировался в Microsoft — его не должно было быть.Ну вот вы сами признали, что «мир, который планировался в Microsoft» и Silverlight — два отдельных проекта.
А Silverlight — попытка «продать» куски этой системы. Ну примерно как H-1 и НК-33. Только из НК-33 сделали AJ-26, которому удалось найти применение, а Silverlight оказался метворождённой поделкой.
А значит, недостатки первого никак не относятся ко второму.Относятся конечно. Если у всей ракетной программы был достаточно чёткий план (который не удалось выдержать по срокам и от которого пришлось, в конце-концов, отказаться), то Silverlight — это в чистом виде «на тебе, боже, что нам негоже». У него не было никаких шансов с самого начала.
Так что не был Silverlight мертворождённым.
Он не был кроссплатформенным и опенсорсным же, правильно? Moonlight с mono стремились быть совместимыми, но не очень хорошо.
Он не был кроссплатформенным и опенсорсным же, правильно?Ну дык он же до известного события появился.
Предполагалось, что Microsoft будет везде и всюду (по крайней мере на клиенте, вроде как надежду захватить сервер они уже тогда оставили), так что никакая кроссплатформенность была не нужна в принципе.
Столько, сколько он запросил, очевидно. Ну или если столько нет — сказал бы, что «опа — ресурсов нету».
Запросил когда? Динамически, во время исполнения? Или резервируем с запасом и получаем примерно туже схему работы с памятью, что и в JS? Вы забыли, что мы в песочнице?
В результате единственный способ обеспечить запуск кода, которому вы не доверяете, на большинстве OS — это браузер.
Угу, об этом и речь. И возможно это благодаря JS. А попытки изменить ситуацию предпринимались далеко не только MS. Очень странно, что вы вспомнили только их, и тут же обвинили в неудачах индустрии: они уже никакого особого влияния не имели в то время. В итоге, никто проблемы с безопасностью так и не решил. К чему бы это?
Запросил когда?В момент запуска. Эта проблема была решена в MacOS первой версии. В 1984м году.
Вы забыли, что мы в песочнице?Кто помешает нам запросить от неё ресурсов?
И возможно это благодаря JS.Нет, не годится. JS начали использовать годы спустя после Flash и Java Applet'ов.
Причём, что иронично, многие «безумно тяжёлые» странички на Flash и даже на Java — по современным меркам «почти ничего не весят». Так, 2-3-5 мегабайт. С учётом того, что главная страница Хабра весит 6 мегабайт, а страничка, где мы с вами перепираемся 3 мегабайта… это немного.
В итоге, никто проблемы с безопасностью так и не решил.Почему «никто не решил»? Решили. Просто это уже никому особо не нужно.
К чему бы это?К тому что на рынке с положительной обратной связью побеждает не самое качественное решение, а то, которое первым достигнет стадии «этим ужасом уже-таки можно кое-как пользоваться»?
Ну подумайте сами: если бы ваши проблемы с безопасностью были бы такими ужасными и совершенно неразрешимыми — то появилась бы на Google Play кнопка Try Now? А она там есть…
В момент запуска.
Как можно запустить приложение в песочнице, не выделив память для самой песочницы? Причем тут максось?
Почему «никто не решил»? Решили.
Кто? Как?
если бы ваши проблемы с безопасностью были бы такими ужасными и совершенно неразрешимыми — то появилась бы на Google Play кнопка Try Now? А она там есть…
Правила публикации в плейсторе можно экстраполировать на веб? Или кто-то будет сканировать весь веб на зловредность? Или вам, чтобы открыть сайт, нужно будет сначала предоставить исходники для анализа?
У меня, как раз, никаких неразрешимых и ужасных проблем и нет, есть браузеры и JS, я могу собрать очень компактное приложение, ничуть не более тяжелое чем на flash или silverlight, ибо в свое время работал и с тем и с другим.
Как можно запустить приложение в песочнице, не выделив память для самой песочницы?Довольно очевидно, что в системе должен быть какой-то менеджер, который умеет читать заголовки и выделять память. Ваш К.О.
Причем тут максось?Уже там в заголовке программы писалось — сколько ресурсов она требует для запуска. Простое решение, дешёвое и сердитое.
Правила публикации в плейсторе можно экстраполировать на веб?А почему нет, собственно? Web сегодня — это в большой степени горстка крупнейших сайтов и так.
Или кто-то будет сканировать весь веб на зловредность?Дык уже.
Или вам, чтобы открыть сайт, нужно будет сначала предоставить исходники для анализа?А что — кто-то начал просить у разработчиков «исходники для анализа» при публикации на Google Play? Новая инициатива, никогда не слышал про такое…
У меня, как раз, никаких неразрешимых и ужасных проблем и нет, есть браузеры и JS, я могу собрать очень компактное приложение, ничуть не более тяжелое чем на flash или silverlight, ибо в свое время работал и с тем и с другим.Рад за вас. Искренне. А вот почему-то всякие разные Google'ы и Facebook'и так не умеют. Приходится бедняжкам делать нативные приложения. Хотя, казалось бы — они в Web'е родились и выросли. А Google — так даже браузеры делает… но нет, чтобы на мобильнике было удобно работать и батарейка не вытекала за минуты… делаются нативные приложения под все мобильные платформы…
Откуда в заголовке появится требуемый размер памяти? Мы доверяем разработчику? Этот указанный размер учитывает память, необходимую для получения данных через API? Учитывает размер пользовательских данных?
Мы доверяем разработчику?А какие альтернативы? Сколько JavaScript выделает памяти под вкладку?
Как только мы решили запустить файл в песочнице, мы потеряли преимущество контроля памяти, ибо вынуждены резервировать с запасом (как в JS), после чего, зарезервированная память стала недоступна остальной системе. Для работы с любыми внешними API, мы пробросили в песочницу свой экземпляр окружения (заняв еще ресурсы). Помимо этого, подняли различные службы для контроля активности, ибо песочница наша изолирована не абсолютно (API) и дополнительно может переходить в "спящий режим", для освобождения ресурсов процессора остальным песочницам, плюс организовали сборку мусора и вот мы имеем обычную вкладку Хрома, в которой уже эффективнее компилировать код на лету, чем анализировать неизвестный ранее скомпилированный код. И JS — на сегодняшний момент — лучший вариант для этих целей. В Google
робко пытались зайти с нативной поддержкой Dart, но не взлетело, поскольку никто так и не увидел особых преимуществ. Вот так и разбиваются мечты о "хороших" языках в вебе о вопросы безопасности. JS — прекрасный язык, и, как мы видим, его нельзя винить в том, что ему обычно приписывают хейтеры: он не является сам по себе основным источником проблем с расходом памяти и процессора. И в прототипном наследовании я также не вижу проблемы, это, на мой взгляд, лучший вариант для скриптового языка.
плюс организовали сборку мусораСборка мусора-то вам зачем? iOS вон и до сих пор без неё вне браузера отлично обходится.
и вот мы имеем обычную вкладку Хрома, в которой уже эффективнее компилировать код на лету, чем анализировать неизвестный ранее скомпилированный код.Вот только не надо рассказывать сказок, а? NaCl какой-нибудь уже 10 лет назад поддерживал SIMD и многопоточность. По скорости никакая система с компиляцией кода и близко не лежала.
И JS — на сегодняшний момент — лучший вариант для этих целей.Дык с этим я не спорю. Он убог, коряв и вообще отвратителен. Но да — он, конечно, лучший. Потому что единственный.
В Google робко пытались зайти с нативной поддержкой Dart, но не взлетело, поскольку никто так и не увидел особых преимуществ.Не взлетело именно потому что не пытались они «зайти». В какой версии Chrome есть нативная поддержка Dart для Web'а? Ни в какой? Ну значит и не было захода — были эксперименты.
Вы ещё скажите, что Microsoft пытался отказаться от поддержки нативного кода, выпустив Singularity. Нет — мечты такие были. Но реальных попыток что-то внедрить — не было.
То же самое и с Dart'ом (а до того — с Java).
Вот так и разбиваются мечты о «хороших» языках в вебе о вопросы безопасности.Вот только не о вопросы безопасности они разбиваются. А о бюрократию. «Работает — не трогай».
К безопасности это всё отношения не имеет.
И в прототипном наследовании я также не вижу проблемы, это, на мой взгляд, лучший вариант для скриптового языка.Вот только «скриптовый язык» — это сразу, с места в карьер, чудовищные затраты ресурсов. Пустая вкладка Хрома занимает больше 10 мегабайт — это больше, чем требует для своей работы какой-нибудь ClarisWorks. С текстовым редактором, электронными таблицами, графиками и кучей всего ещё.
Пустая вкладка Хрома занимает больше 10 мегабайт
Вкладка ПУСТАЯ, но виноват JS? Вы сами то читаете что пишите?
Когда вы запускаете приложение в песочнице — оно потребляет столько памяти, сколько требуется ПЕСОЧНИЦЕ.Оно потребляет сколько дадут. Главное — оно заставляет разработчиков вообще думать об этом. Чем большинство фронтэдеров сегодня себя не утруждает.
Конечно. Я, просто, в отличие от вас знаю чем заняты эти 10 мегабайт. Так вот: большая часть — это JS-рантайм. Да, DOM-дерево и всё, что с ним связано — тоже занимают место. Но большая часть потребляемой памяти — уходит на V8.Пустая вкладка Хрома занимает больше 10 мегабайтВкладка ПУСТАЯ, но виноват JS? Вы сами то читаете что пишите?
Для песочницы, позволяющей запускать скомпилированный код тоже нужны затраты, вы правы… но тут речь идёт о мегабайте или, если постараться, сотне килобайт.
Затраты ресурсов просто несопоставимы… и даже при всё при этом V8 — всё равно существенно медленнее и прожорливее C/C++.
В контексте обычного клиентского веба 1, 10 или 100 мб жрёт рантайм особого значения не имеет в наше время, по-моему
В контексте обычного клиентского веба 1, 10 или 100 мб жрёт рантайм особого значения не имеет в наше время, по-моемуИ это — самая большая проблема «современного веба». То, что должно занимать пару мегабайт — занимает не то 10, не то 100, может и 1000 — и всем пофигу.
P.S. Я, собственно, не призываю никого бросать то, что они делают и срочно устраивать революцию. Но не надо думать, что дерьмо становится фиалкой, если вы на него сверху красивую обёртку налепили и объяснили что делаете то, что сказал заказчик. Платят вам за кучу дерьма больше, чем за конфетку — ну и ради бога. Я даже могу понять почему так. А вот острого желания назвать дерьмо конфеткой — извините, но понять не могу.
Кому оно должно? С какой целью? Почему вы называете это дерьмом, если оно удовлетворяет и пользователей (раз пользуются), и заказчиков (раз платят), и разработчиков (раз разрабатывают)?
Почему вы называете это дерьмом, если оно удовлетворяет и пользователей (раз пользуются), и заказчиков (раз платят), и разработчиков (раз разрабатывают)?
Вообще, оно не удовлетворяет пользователей. Просто альтернативы нет.
Значительная часть современного софта действительно с точки зрения качества дерьмо. Это абсолютно объективно. Мы имеем, грубо говоря, функционал, который раза в два превосходит функционал того софта, что работал на компьютерах 20 лет назад, но при этом потребляет на два порядка больше ресурсов. Основную часть времени ведь современный компьютер на самом деле не делает ничего. Ну, в смысле, ничего полезного. Он тупо прокручивает код нескольких сотен наваленных уровней абстракций между данными и какой-то функцией, которая их обработает.
Мы имеем, грубо говоря, функционал, который раза в два превосходит функционал того софта, что работал на компьютерах 20 лет назад, но при этом потребляет на два порядка больше ресурсов.
всё ещё хуже. Функционал кода дублируется 100 на разных языках или платформах, чтобы потом делать ещё мосты между этими платформами. И да, если есть функция как абстракция не значит что её надо вызывать в стеке а потом возвращаться. И если есть обьект в коде как абстракция не значит что в коде должна быть такая же структура.
Подавляющему большинству софта есть альтернатива не пользоваться софтом.
Вы, кажется, определяете качество как эффективность использования вычислительных ресурсов. Редкое, по-моему, в наше время определение.
И да, основную часть времени современный компьютер (вернее его процессор прежде всего) на самом деле не делает ничего. Но не "ничего полезного", а "ничего" в полном смысле слова. Простаивает, ожидая каких-то событий.
И да, основную часть времени современный компьютер (вернее его процессор прежде всего) на самом деле не делает ничего
Я имею в виду тот момент, когда он выполняет приложение.
Вы, кажется, определяете качество как эффективность использования вычислительных ресурсов.
А почему бы и нет? Легковой автомобиль, который затрачивает 100 литров бензина на 100 км, потому, что его конструкторы слепили его по-быстрому из самых дешевых компонент, мы не задумываясь назовём некачественным, даже если там комфортный салон, кондиционер, удобные сиденья, и в остальном он вполне решает задачу пользователя «доехать из пункта А в пункт Б».
Возможно, вы возразите, что за бензин пользователь платит, а гигагерцы/гигабайте у него вот, лежат мёртвым грузом. Но нет же, и они далеко не бесплатные. Мы все вынужденно регулярно обновляем железо, хотя подавляющее большинство задач на самом деле не требуют бОльших вычислительных мощностей или большего дискового пространства, чем у нас было 10-15 лет назад. Ваш телефон, к примеру, имеет на порядок меньше функций, чем имел персональный компьютер, скажем, 20-летней давности. При этом он будет вяло ворочаться, если у него там на борту будет один жалкий гигабайт памяти. Вы не сможете даже мессенджерами нормально пользоваться. А компьютер 20-летней давности, минуточку, обходился 64 мегабайтами памяти и одноядерным процессором этак на 300-450 МГц
Я имею в виду тот момент, когда он выполняет приложение.
И какая особо разница, тратит компьютер 10% мощности в среднем или 1%? Чаще всего обычный пользователь физически этого не заметит, по-моему.
Легковой автомобиль, который затрачивает 100 литров бензина на 100 км, потому, что его конструкторы слепили его по-быстрому из самых дешевых компонент, мы не задумываясь назовём некачественным
А если не из дешевых, а наоборот? Ну не знаю, со свинцовым кузовом, поэтому тяжелый, поэтому много тратит. И ремонтопригодность на высшем уровне за счёт того, что мало больших деталей, всё разъёмное.
Ваш телефон, к примеру, имеет на порядок меньше функций, чем имел персональный компьютер, скажем, 20-летней давности.
Вот не факт. Сходу не могу сказать каких функций нет в моём телефоне сейчас, которых не было бы в моём ПК 20 лет назад. Даже если брать тот ПК со всей имевшейся у меня периферией. Более того, в телефоне функций больше, в частности:
- GSM голос
- LTE интернет
- WiFi
- параллельное выполнение программ (многоядерность)
- автономность больше суток (ИБП мой 10 минут держал)
ПК разве что мог теле- и радиоэфир принимать и в DOCSYS сети работать.
Ну и 4 Гб памяти сейчас стоит дешевле чем тогда 64 Мб. Ну и вроде бы именно в 1999 64 было именно "обходился". Вышедшая в начале 2000 Win2k рекомендованными имела 64, что означает, что на 64 только сама Windows нормально работала, что-то тяжелее Сапёра требовало доппамять для себя.
Сходу не могу сказать каких функций нет в моём телефоне сейчас, которых не было бы в моём ПК 20 лет назад.
Я могу сказать. Нет полноценного текстового процессора, который работал в WYSIWYG, и в общем-то легко решал те же задачи, которые решают современные браузеры, жрущие по гигабайту на вкладку. Нет функционального почтового клиента, аналогичного хотя бы Outlook 97, со всякими правилами обработки, макросами и т.д. Нет графических редакторов уровня Corel Draw/Photoshop. Нет инструментов разработки уровня Delphi 4. Да ничего практически нет, только игры технологически более продвинутые, ибо есть неплохое ускорение OpenGL. А в остальном, софт на смартфоне куда примитивнее, нежели был на ПК 20-летней давности. Но при этом развивается медленно, жрёт много.
Ну и вроде бы именно в 1999 64 было именно «обходился».
64 в 1999 был «выше среднего». NT и 98 на таком объеме летали вместе со всем софтом, который вы там могли найти. Чуть позже, на Win2K, уже было не так вольготно, но вполне юзабельно. Сама ОС тогда отъедала примерно 22-25 метров после старта. Пока не начали выходить сервис-паки :)
И ремонтопригодность на высшем уровне за счёт того, что мало больших деталей, всё разъёмное.Какая разница, какая у него ремонтопригодность, если при любом неосторожном движении от него норовят отвалиться целые блоки? А если дёрнуть рычаги не в том порядке, то его заклинить нафиг может и нужно будет мастера вызывать?
Вы видели терминалы для заказа в Макдональдсе? Так вот периодически пропадают картинки гамбургеров. И если нажать кнопку «назад» во время редактирования набора ингридиентов (не перевоначального выбора, а редактирования потом), то оно пытается выдать какой-то стек трейс, но посредине процесса его прерывают и весь интерфейс перезапускают.
Это у нас называется «качество»? Извините — но это куча дерьма, которую менеджеры впариват под видом конфетки.
Но не «ничего полезного», а «ничего» в полном смысле слова.Серьёзно?
В том-то и дело, что ни GIMP (где открыто с полсотни разных картинок, в некоторых по полсотне слоёв), ни LibreOffice, ни, даже, внезапно, Vim с кучей окошек, действительно ничего не делают. И памяти требуют… умеренно. А вот это ваши «фиалки», над которыми вьются навозные мухи — они требует гигабайтов памяти и занимают процессор, даже когда вкладка не в фокусе.
На десктопе, с его 36 ядрами и 192GB памяти — это не очень заметно, а вот лаптоп… на нём это весьма и весьма чувствуется.
Вы, кажется, определяете качество как эффективность использования вычислительных ресурсов. Редкое, по-моему, в наше время определение.Ну вот в этом и проблема. Это всё равно как если бы какую-нибудь соковыжималку оценивали не по тому, сколько сока она может выдать в минуту, а исключительно по красоте дизайна и по скорости, с которой её можно превратить в кофемолку.
У меня во всех вкладках всех закладок текста меньше, чем в одном документе, открытом в LibreOffcice. Почему LibreOffice жрёт меньше гигабайта (и вообще не виден в top'е), а «фиалки» — жрут больше десяти гигабайти и создают загрузку процессора в 300% «на постоянной основе»?
На десктопе, с его 36 ядрами и 192GB памяти — это не очень заметно, а вот лаптоп… на нём это весьма и весьма чувствуется.
Хм, а что мешает вам на лаптопе(или вообще везде) использовать «правильный» софт вроде либры или гимпа? Вас кто-то заставляет использовать «фиалки»?
Это всё равно как если бы какую-нибудь соковыжималку оценивали не по тому, сколько сока она может выдать в минуту, а исключительно по красоте дизайна и по скорости, с которой её можно превратить в кофемолку.
Насчёт «скорости превращения не знаю», а вот дизайн и внешний вид соковыжималки для многих это один из самых важных критериев при выборе. И в этом на мой взгляд нет ничего зазорного. И так же нет ничего странного что индустрия ориентируется и на таких людей. И если их большинство, то ориентируются в первую очередь на них.
Вас кто-то заставляет использовать «фиалки»?Да вот вы же и заставляете. Хабр, к примеру, даже рассылает мне ответы в почту. Но вот ответить вам без захода на «пахнущий» сайт, увы, не даёт. Так что либо пользоваться «фиалками», либо отказаться от общения вообще.
В некоторых случаях я таки выбираю второй вариант, кстати.
Насчёт «скорости превращения не знаю», а вот дизайн и внешний вид соковыжималки для многих это один из самых важных критериев при выборе.Угу. А через месяц начинается плачь, когда оная соковыжималка развалилась.
А через пару лет — я везу несчастную овощерезку Börner V3 из Германии, потому что тут она точно должна быть немецкого производства.
И если их большинство, то ориентируются в первую очередь на них.Да даже если не большинство. Пока «впарить» блестящие стекляшки проще и выгоднее, чем сделать что-то качественно — будет происходить именно это.
Должно пройти какое-то время и пара экономических кризисов, чтобы люди научились ценить качество.
Развитие идёт по спирали — во многом именно по этой причине.
Но это всё равно не делает дерьмо конфеткой.
И тут я с одной стороны могу вас обрадовать: вы не один такой с подобными претензиями к современному обществу.
А с другой стороны несмотря на кучу людей с претензиями вряд ли при нашей жизни что-то кардинально изменится.
если оно удовлетворяет и пользователей (раз пользуются), и заказчиков (раз платят), и разработчиков (раз разрабатывают)?За коровий навоз — тоже платят и заказчики и пользователи. Что не делает его конфеткой.
Почему вы называете это дерьмом,Потому что это — дерьмо. Продукт без дизайна и внутренней структуры. Полученный примерно так же, как получается коровье или собачье дерьмо. И да, если «приcпичит» — его даже можно в топливо превратить или в стройматериал (см. кизяк), но вот только из такого материала ни крупный цех, ни небоскрёб не построить: развалится.
И да, софт сейчвс конечно часто кривой, но с другой стороны посмотрите как быстро он «устаревает» и меняется на новый по той или иной причине. И много ли фирм могут себе позволить вкладывать кучу времени и денег в софт, который будет использоваться/продаваться всего год-два-три?
А это в принципе кому-то надо? Ну «небоскрёб строить»?А это — уже другой вопрос. Ответ такой: пока не хватает специалистов для того, чтобы сделать всё удобно и хорошо — и такое «чудо сгодится».
Я про это уже писал: Платят вам за кучу дерьма больше, чем за конфетку — ну и ради бога. Я даже могу понять почему так. А вот острого желания назвать дерьмо конфеткой — извините, но понять не могу.
И да, софт сейчвс конечно часто кривой, но с другой стороны посмотрите как быстро он «устаревает» и меняется на новый по той или иной причине.А почему он, собственно, меняется? Вот что такого научился делать новый GMail, что он теперь ресурсов жрёт раз в 10 больше, чем версия 2009го года?
И много ли фирм могут себе позволить вкладывать кучу времени и денег в софт, который будет использоваться/продаваться всего год-два-три?То есть мы выпускаем дерьмо, потому что нет ресурсов всё сделать по-людски, а ресурсов нет, потому что нам нужно очень-очень быстро заменять одно дерьмо на другое дерьмо?
Perpetuum Mobile какой-то получается. Бессмысленный и беспощадный.
А когда надо что-то хорошее и качественное и за это платят как за хорошее и качественное, то «мы» обычно и делаем хорошее и качественное.
Потому что обычно глупо делать одноразовые салфетки из шёлка, а зубочистки из чёрного дерева.
Извините, но тут я с вами не согласен. В данном контексте я не вижу принципиальной разницы между софтом и скажем бытовой техникой.
Любой софт рано или поздно всё равно придётся переписывать. Может это будет через пять лет, может через десять, но придётся. Мало какой софт живёт без кардинальных изменений 15-20 лет.
С другой стороны бытовая техника тоже вполне себе работает по 5-10 лет. А иногда по 15-20. А иногда и дольше :)
Любой софт рано или поздно всё равно придётся переписывать.это из за убогости современного подхода. Теоретически (пока что), если описать решение задачи максимально полно и нужной архитектурой, она будет пахать на любой платформе, хоть паралельной хоть кватновой. Щас софт меняется как бабочки одновневки заместо редких исключений вроде db2.
Изменения могут быть разного типа. Можно изменять только модель данных без изменения алгоритмов обработки. При этом написание софта развосильно не «производству конкретной штуки техники», а «производству чертежа/конструкции техники»
А самое главное невозможно на 10-15-20-50 лет вперёд предсказать какие фичи захочет иметь пользователь.
А пытаться в своём софте изначально заложить возможность для всех вариантов, которые теоретически могут понадобиться через 20-30-50 лет… Ну тогда уже в DOS надо было бы о хорошему изначально предусмотреть возможность работы с cloud или гигабайтами памяти :)
На мой взгляд невозможно на 10-15-20-50 лет вперёд предсказать какие технологии будут использоваться.
как раз щас пытаются так делать, прямо говорят когда делают какую то ERP чтоб она и через 20 лет работала, а апдейт делается новыми данными а не самой прогой, а методы реакции на данные могут быть такие же.
DOS от рождения до своей кончины было уродливым детищем лиш бы что то сделать, а Unix который был раньше и остался позже долго был работоспособным. Собственно
DOS от рождения до своей кончины было уродливым детищем лиш бы что то сделатьО какой кончине DOS мы говорим? Он ведь ещё жив, курилка.
Собственно потому и жив, что «современные Web-технологии» — далеко не всегда нужны…
И Unix, насколько бы работрспособным и удачным он не ьыл всё равно имел те же самые проблемы и тоже не смог всё предусмотреть.
П. С. И если вам хочется немного упражнений для ума, то попытайтесь например предсказать перейлём ли мы когда нибудь на 128-архитектуру и если да, то когда :)
прямо говорят когда делают какую то ERP чтоб она и через 20 лет работала, а апдейт делается новыми данными а не самой прогой
По сути такая прога это транслятор языка, программы на котором пишутся в этих данных. И как показывает практика, та же история Си, языки "данных" тоже развиваются с потерей обратной совместимости и рано или поздно прогу обработки этих данных захочется поменять
Может это будет через пять лет, может через десять, но придётся. Мало какой софт живёт без кардинальных изменений 15-20 лет.
Это было благодаря закону Мура. Когда ваш компьютер каждые пару лет становился в разы быстрее, получал больше аппаратных фич и всяких примочек. Сейчас, минуточку, компьютер пятилетней давности уступает современному аналогу процентов на 30. И не за горами момент, когда рост производительности ещё более замедлится.
И вот тогда, возможно, начнут делать эффективный в плане утилизации ресурсов софт. Если это станет заметным конкурентным преимуществом на массовых рынках. Новые "свистоперделки" добавить без заметного падения эффективности будет невозможно и надо будет вылизывать существующие, чтобы высвободить ресурсы на новые.
возможности использования «условных дешёвых индусов»
вы, вообще, давно зарплаты фронтов видели?
вы, вообще, давно зарплаты фронтов видели?Я фронтов не нанимаю… зато я хорошо слышу вой людей, которые стонут «ну нафига мне это Android-приложение, когда Web-сайта бы хватило»… это значит что развитие идёт ровно тем путём, каким оно и должно было идти.
Просто… всему своё время. Если «условно дешёвые индусы» кончились — так это не просто хорошо, это ж прекрасно! Значит скоро, наконец, эра увлечения Электроном, наконец, закончится… и можно надеяться на что-то, чем реально можно будет пользоваться…
А то, что для бизнеса в 3 раза дешевле сделать PWA, чем собирать нейтивы под каждую платформу — так это «безобразие» скоро закончится, ага.Вы уж определитесь: «вы, вообще, давно зарплаты фронтов видели?» или «для бизнеса в 3 раза дешевле»…
А то оно как-то не очень сочетается.
А так-то, собственно, да, как в 80е всё, в конечном итоге, свелось к тому, что было достаточно выпускать только приложение для Windows — так и тут, в конечном итоге, получится.
Просто Apple в этот раз очень глубоко в карманы покупателей залезла, так что ещё долгое время будут нужны два приложения, а не одно…
А то оно как-то не очень сочетается.
Вполне сочетается: двойная зарплата одному разработчику выгоднее для бизнеса чем одинарная для троих.
iOS, Android, десктопы… Добавьте гемор с публикацией в сторы...
Во первых, не требуют, UI может (и должен) быть адаптивным. А во вторых, даже если дизайн разный, бизнес-логика может быть одна.
А во вторых, даже если дизайн разный, бизнес-логика может быть одна.А бизнес-логику и в нативных приложениях несложно одну сделать. Хотя бы в том же Delphi.
в Delphi под iOS и Android? Хм, интересно...
Я, кстати, тоже не особых любитель адаптивных UI. Адаптивный UI — это не для пользователя, а для разработчика. Позволяет писать один раз нечто компромиссное вместо двух удобных специализированных интерфейсов. Где, например, вы видели адаптивный интерфейс, который на десктопе приобретает привычные там панели инструментов и шорткаты ;) Вот то-то и оно.
Скорее не для разработчика, а для бизнеса.
При этом разработчики обычно говорят, что универсальный и адаптивный — это быстрее, дешевле, лучше. Это не совсем так, вернее, верно только для простого UI и/или на начальных этапах разработки. Для развитого UI поддержка полноценной адаптивности обходится, кстати, нередко существенно дороже, чем параллельное сопровождение мобильной и десктопной версии.
И, более, того, скорее всего это будет дешевле, чем PWA.
Однако — да, это не будет достаточно хайпово, потому в мире «шальных денег», где реальные расходы не значат ничего, а хайповость — значит всё… выбирают PWA.
Не понял вот этого пассажа:
Итак, теперь мы мотивировали, почему можно использовать babel.
Было: "до недавнего времени JavaScript и Web API имели множество ограничений"
Стало: ECMAScript и улучшенный WebAPI.
Т.е., babel мы используем только для того, чтобы наш новый код понимался старыми браузерами? Из статьи я другого мотива использовать babel не увидел.
Я противник обратной совместимости (с нынешними-то возможностями управления зависимостями и их версиями). IMHO, не разрабы должны использовать babel, чтобы дотянуться до отсталых пользователей, а пользователи должны обновлять браузеры, чтобы успевать соответствовать текущему моменту. Но… за всё платит бизнес, поэтому и babel.
Остаётся только надеяться, что с развитием языка и рабочего окружения транспиляторы постигнет та же участь, что и jQuery, а старые браузеры — судьба Netscape Navigator'а (светлая ему память!)
а пользователи должны обновлять браузеры, чтобы успевать соответствовать текущему моменту.
Понимаете, фишка в том, что никто никому не должен. Просто каждое решение чего-то стоит. Например, тут вы (ну или заказчик) решаете, что лучше — добавить поддержку старых браузеров или потерять сколько-то процентов потенциальных клиентов.
Понимаю. Пользователи не должны обновлять браузеры, разрабы не должны использовать babel, а музыку заказывает тот, кто платит.
Ну скажем если Facebook, Youtube, Twitter и условные Одноклассники внезапно заявят, что поддерживают только N последних версий Chrome/Safary/Firefox, научатся пользователи обновлять браузеры?С учётом того, что для них несколько процентов пользователей — это сотни миллионов, а то и миллиард долларов в год? Вряд ли.
Помните историю про YouTube и IE 6? Если бы разработчики не разместили баннер «тихой сапой» — и сейчас бы ещё IE 6 в разных фреймворках бы поддерживался…
Т.е., babel мы используем только для того, чтобы наш новый код понимался старыми браузерами?
Ну и ещё для того, чтобы иметь возможность использовать новые фичи языка ещё до их попадания в стандарт.
а пользователи должны обновлять браузеры, чтобы успевать соответствовать текущему моменту
А ещё пользователи должны вовремя обновлять ОС (чтобы новая версия браузера заработала) и железо (чтобы заработала свежая версия ОС)?
Я так понял, что слово "должен" в наше время имеет отрицательную энергетику, стало токсичным. Нет, не должен. Может, если хочет, но не должен.
Одному моему ноуту 2-3 года, второму — лет 5-6. На обоих стоит Ubuntu 18. Эта версия браузера — Chrome Version 76.0.3809.100 (Official Build) (64-bit). Я лично успеваю, а остальные никому ничего не должны. Кто хочет — изучает babel, кто не хочет — не изучает. Кто хочет — использует нестандартные фичи языка, кто не хочет — не использует. Лично я предпочитаю не множить сущности и по максимуму использовать стандартные вещи. Как-то так.
А заодно и организацию, в которой кроме как IE8 благодаря политикам ты использовать ничего не сможешь :)
Действительно — мне, как только что завершившему обучение студенту и углубляющемуся пока что в мир десктопа и распределённых систем и .Net — очень и очень интересно было бы понять, откуда ТАКОЙ зоопарк технологий/фреймворков/названий в веб-разработке.
Считаю, что статья крайне хороша хотя бы тем, что позволяет мне и любому другому незнающему читателю понять причины(проблемы) — по которым развелось столько всего разного.
Желаю автору не терять запала и с нетерпением жду следующей части!:)
Простите, но накипело.
Задолбали ныть.
Ну серьезно, не в первый раз приходят и начинают осуждать естественный процесс эволюции веба, который десятилетиями шел своим путем с участием тысяч (миллионов?) людей, компаний, которые решали задачи, развивали бизнес и прочее.
Никто ничего не усложнил. Ну не нравится babel, react, webpack — открывайте <script> и пишите. Обратная совместимость со старьем поддерживается если не абсолютно, то близко к тому.
В андроиде тоже самое, за 10 лет существования появился сахарный язык разработки kotlin (аkа typesript), поддерживаются разные версии java 1.6, 1.7, 1.8 (aka ECMAScript). Оба могут транслироваться, например, в java 6 байткод (aka babel). И так далее… gradle/maven/ant aka webpack/другие сборщики (правда не могу найти аналогию react/vue/angular, в андроиде скорее нет таких глобальных и монопольных фреймворков). История показывает, что любой гигантский продукт, которым реально пользуются миллиарды людей, проходит по примерно такому сложному пути. Для новичка это всегда сложно, но если начать разбираться, то все станет на свои места
В андроиде место react/vue занимает Android Platform. Это, практически говоря, все пакеты, начинающиеся с android. или androidx.. Очень монопольная штука. Насколько в своё время удалось найти — даже если основная логика приложения на C++, будет куда проще пользоваться JNI и писать интерфейс на Java, чем пилить прилично выглядящий интерфейс на C++.
чем пилить прилично выглядящий интерфейс на C++
Месье знает толк в извращениях)
Это я в контексте монопольности платформы.
Мне самому пока ни лично, ни профессионально не приходилось сталкиваться с необходимостью писать под Андроид на C++ в принципе. Для меня очень логично считать, что раз ядро приложения на C++ — то логичным было бы и интерфейс тоже написать на C++ (ведь не от хорошей же жизни там пишут на NDK, значит экономить приходится на многом, и доставка сообщений через JNI тоже не бесплатная), но вот тут-то и происходит столкновение с реальностью.
Но вот ведь какая фигня: Web-технологии ведь тоже не позволяют так просто сделать интерфейс, похожий на нативный!
Вообще, всё сходится. На Android нативный интерфейс делается на Android Platform, а не C+++OpenGL. Точно так же, как же нативный интерфейс на Windows должен быть сделан через WinAPI (или UWP?), а не на Javascript'е.
Вообще-то Internet Explorer до версии 10 включительно был способен выполнять скрипт на любом языке, который был установлен в систему в виде некой скрипт-машины с неким стандартным для системы интерфейсом. Таких машин всегда было предустановлено две — JavaScript и VBScript. Но в принципе можно было поставить и Perl от ActiveState. Но это было давно.
А зачем вы их подсчитываете?
Из объяснения нужды в использовании babel следует лишь желание разработчика использовать новые фишки языка, но так как хочется охватить пользовательскую группу по шире, то нужна совместимость со старыми стандартами. Пример приведенный в статье неубедителен: вместо var используется let и const, и применено деструктурирующее присваивание, которое легко было записать двумя строчками. Лично мне на данном примере не видно зачем нужно было это все использовать. Это ничем не отличается от того как для пары функций использовали (да и до сих пор грешат использованием) jquery. Нагляднее был бы пример с async/await.
В другую крайность, конечно, тоже ударяться не стоит: что пользователи что-то (обновляться до самой последней версии) должны разработчику. Если у вас сайт с рецептами, то ожидать, что «бабушки» и «блондинки» будут отслеживать новшества в мире браузеров, наверное, не стоит :), и вы уповая на это потеряете большую часть аудитории.
Но вообще современная разработка усложняется не только обилием редакторов, IDE, утилит, библиотек, фреймворков и т.д., но их частой сменой, а также множеством совршенно не нужной терминологией. Взять тот же транспайлер. Зачем ввели новое понятие, если старые: компилятор или транслятор, вполне подходили.
Для всей современной разработки не хватает бритвы Оккама — «Не следует множить сущее без необходимости».
При чём тут Flash? Если вы об Action Script, то он был не "реализацией" ECMAScript, а его надмножеством.
С каких пор черновик невышедшего стандарта может считаться стандартом?
Ну ладно, представим что ES4 таки вышел. И что вышел соответствующий ему JavaScript.
В чём в таком случае будет разница между JavaScript "той версии" и EcmaScript?
Да не вышел JavaScript той версии. Javascript в браузерах очень сильно отличается от стандарта EcmaScript. И даже ES6 не поддерживают браузеры, babel — kangax.github.io/compat-table/es6. Поэтому проще всего ECMAScript рассматривать именно как стандарт, а JavaScript- как реализацию в браузере, node, babel/
Если, грубо говоря, все тесты ES4 проходили на Action Script трансляторе, то вполне себе реализация: скорми ему валидный ES4 код и он его выполнит в соотвествие со спекой.
пример перегруженного, зависающего — 74.ru
(это наш местный, челябинский, для местных дебилов ))) — заходите осторожно, повиснет что угодно, даже 10-ка на SSD.
После ухода оттуда — почистите кэш от гавна (ctrl+shift+del/ OK в Хроме).
Я туда давно не заходил. Не мог поверить вашему сообщению, что всё — норм. Сейчас да — даже рекламы умеренно. У меня комп просто вешался навзничь (старый 2004 года на XPsp3 — работает уверенно везде, кроме этого 74).
Но хозяева всё теже, так что говно на страницах — останется. :))
Зачем современную веб-разработку так усложнили? Часть 1