Про принцип единственной ответственности (The Single Responsibility Principle, SRP) уже было написано множество статей. В большинстве из них даётся лишь поверхностное его описание мало чем отличающееся от информации в википедии. А те немногие статьи что затрагивают ключевые особенности SRP делают это вскользь, не акцентируя на них внимания и не развивая тему дальше.
Эта статья — попытка дать более глубокое объяснение принципу единственной ответственности, а также показать как его всё таки можно применять на практике. Кому интересно — добро пожаловать под кат.
Первоначально, автор принципа — Дядя Боб, дал ему такую формулировку:
Рассмотрим следующий пример класса и попробуем оценить (субъективно конечно же) соответствует ли он SRP согласно определению выше:
Примечание: весь код в статье не высосан из пальца, а взят из реальных проектов автора.
Как нетрудно догадаться этот класс умеет строить SELECT запрос и выполнять его. Сразу же бросается в глаза что у класса есть две группы методов: методы для генерации SQL кода и методы для выполнения этого кода. А значит у нас могут появиться две разных причины для изменения этого класса. Например, мы можем добавить новый метод having() для генерации HAVING условий. Это изменение никак не затронет методы выполняющие запрос. С другой стороны, мы можем добавить метод groupByKey() позволяющий группировать извлечённые данные по ключу и это в свою очередь никак не скажется на первой группе методов.
Налицо нарушение SRP. Решить проблему можно было бы, например, разделением класса на два:
Теперь вроде всё в порядке. Каждый класс делает ровно одну вещь и имеет ровно одну причину для изменений.
А вот другой пример:
Как следует из названия класс используется для поиска различных сущностей и больше ничего не делает, а значит соответствует SRP. Ведь так?
А как вам такой пример:
Ну ActiveRecord известный антипатерн. Он точно нарушает SRP. Или нет?
На самом деле во всех этих примерах нарушение или не нарушение SRP зависит от того, что мы будем считать причиной для изменений. При этом, варьируя широту этого понятия мы сможем обосновать как создание классов содержащих ровно по одному методу (из одной строки кода), так и создание «божественных объектов». А значит озвученное выше определение принципа единственной ответственности бесполезно.
По видимому, Дядя Боб в какой-то момент пришёл к тому же выводу и поэтому в своей недавней книге Clean Architecture даёт новое определение этого принципа:
Это определение гораздо лучше предыдущего, т.к., во-первых, оно акцентирует внимание не на классе, а на модуле, что явно указывает на то, что SRP применим к любой части системы и не зависит от используемой парадигмы программирования. Во-вторых, из него следует важное практическое следствие:
Оценим с этой точки зрения наш первый пример — класс SelectQuery. Объективно он может использоваться в двух контекстах (т.е. у него есть два актора): генерация SQL кода и выполнение этого кода. Если у нас есть оба этих актора, т.е. если класс в каких-то сценариях используется только для генерации SQL, а в каких-то для выполнения запросов, то первая реализация класса не соответствует SRP. Если же у нас лишь один актор (как в проекте автора) — контекст выполнения запросов, то тогда исходная реализация не противоречит SRP. Действительно, в этом случае с точки зрения применения SelectQuery не будет никакой разницы содержится ли весь нужный функционал для построения и выполнения запросов в одном классе или в двух связанных классах. Сценарий использования будет всегда одним и тем же — строим запрос и потом выполняем:
Заметим, что классы из второй реализации SelectQuery не противоречат принципу единственной ответственности как для одного так и для двух акторов. А значит в случае одного актора отвечающего за выполнение запросов обе реализации эквивалентны с точки зрения следования SRP.
Что на счёт следующего класса SearchService. Одного кода класса недостаточно. Во-первых, неизвестно, что представляют собой сущности Athlete, Association и т.д. А во-вторых, неясен контекст использования класса. Например, может быть такой вариант что сущности это простые DTO, а контекст использования поиск различимых, но почти однородных данных. Тогда этот класс имеет одного актора и следовательно удовлетворяет SRP. Но если возвращаемые сущности это бизнес сущности, а методы класса используются в разных контекстах соответствующих каждой бизнес сущности (как в проекте автора), то тогда класс имеет кучу акторов, по одному на каждый метод, и следовательно жёстко нарушает принцип единственной ответственности.
В каких контекстах может использоваться наш ActiveRecord? На самом деле только в одном — сохранение записи в источнике данных. Никак иначе использовать этот класс нельзя. Таким образом, ActiveRecord прекрасно согласуется с SRP.
Постойте! Что мы вообще делаем? На каком основании мы выделяем контексты (акторов) использования модуля. Каков критерий разграничения акторов? Чем это принципиально отличается от «причины для изменений»? Собственно ничем. Да, мы теперь знаем, что нужно изучать то как мы используем программные модули, но в остальном трактовка принципа единственной ответственности в его актуальной формулировке всё также субъективна и находится в прямой зависимости от опыта и интуиции разработчика. Хотелось бы какого-то более формального подхода к проблеме, что-нибудь померить и посчитать в конце концов. Что ж, такой подход есть.
Принцип единственной ответственности возник как попытка объединения двух важных понятий структурного анализа и проектирования: coupling (сопряжение, зацепление, связанность) и cohesion (сплочённость, связность, прочность модуля).
Оба понятия неформально определяются следующим образом:
В стандарте ISO/IEC/IEEE 24765-2010 определены (неформально) следующие виды связности и сопряжения (от худшего к лучшему):
Несмотря на обилие метрик, не существует какого-то единственного способа для вычисления сопряжения и связности модулей. Отчасти это связано с отсутствием строгой формализации этих понятий. С другой стороны разновидностей связей между программными модулями великое множество. Какие-то связи считаются «полезными», а какие-то «вредными» (зависимости). И какую связь какой считать во многом зависит от того на каком языке программирования написана программа, какая парадигма программирования использовалась или в каком архитектурном стиле велась разработка.
Тем не менее не всё так плохо. Существуют интегральные метрики позволяющие объединить всё, что мы считаем «полезным» в отношении связей и рассчитать связность и сопряжение для всей системы. Один из таких подходов описан в Measuring Software Coupling. Хотя этот метод предлагается использовать для вычисления сопряжения, он также подходит и для вычисления связности модулей.
Суть метода заключается в следующем: необходимо составить список того, что мы считаем зависимостями, далее по формулам рассчитываем связность или сопряжение. Расчёт будет настолько точным насколько адекватным и полным будет наш список видов зависимостей. Из-за диалектической природы сопряжения и связности списки зависимостей для них могут быть противоположными.
Описание алгоритма расчёта
Пользуясь вышеописанным алгоритмом попробуем рассчитать сопряжение и связность. Для примера возьмём код на PHP:
Прежде чем рассчитывать сопряжение составим список возможных связей между классами в PHP. Каждому типу связи присвоим вес в диапазоне от 0 до 1 (0 — соответствует отсутствию связи, 1 — соответствует максимально «жёсткой» связи).
Приведённый список зависимостей не является исчерпывающим, а скорее показывает качественную картину: какая из зависимостей является более «жёсткой» по отношению к другой. Можно также спорить по поводу весов. Однако наша задача получить не точное значение сопряжения, а качественно оценить на сколько код плох или хорош в этом отношении.
Итак, описание зависимостей есть, можно приступать к расчёту сопряжения. Всего у нас есть 11 модулей:
Составим матрицу описания связей, где будет определять степень зависимости между
будет определять степень зависимости между  и
и  . Таким образом столбцы в матрице связей это веса рёбер графа зависимостей рассчитанные в прямом и обратном направлении:
. Таким образом столбцы в матрице связей это веса рёбер графа зависимостей рассчитанные в прямом и обратном направлении:

Матрица описания связей:
Выполняем расчёты и получаем матрицу зависимостей:
Общая зависимость классов , а средняя степень зависимости
, а средняя степень зависимости 
Как и следовало ожидать, самым зависимым модулем оказался ChatSessionApplicationService, за ним следуют репозитории, UserAccessService, AbstractApplicationService и наконец все остальные классы. Средняя степень зависимости между классами небольшая, что говорит нам о том, что в основном классы слабо связанны между собой.
Попробуем теперь вычислить связность ChatSessionApplicationService и понять на сколько он удовлетворяет SRP. Здесь также можно было бы составить иерархию видов связей внутри модуля (класса) с точки зрения связности его подмодулей (методов). Но поскольку в нашем случае методы внутри ChatSessionApplicationService связаны исключительно через зависимости класса условимся в целях упрощения расчётов считать использование конкретной зависимости методом за 1. Таким образом, строки матрицы описаний связей будут соответствовать методам класса, а столбцы — использованию конкретной зависимости:
Матрица связей:
Матрица зависимостей:
Общая связность класса , а средняя степень связности методов
, а средняя степень связности методов 
Сразу бросается в глаза низкая степень связности методов друг с другом. Об этом также свидетельствует средняя связность. При этом первый метод почти не связан с третьим, а второй в два раза сильнее связан с первым методом чем с третьим. Третий метод слабо связан с первыми двумя. Всё это означает, что ChatSessionApplicationService плохо соответствует SRP и, следовательно, должен быть разбит на три класса. К тому же такое разбиение только улучшит показатели сопряжения между классами (кто не верит — посчитайте сами) в силу слабой независимости сервиса с остальными классами.
Едва ли. Исследования в области контроля качества и сложности программного кода ведутся до сих пор и останавливаться не собираются. А значит применение принципов управления сложностью программного кода, к которым в частности относится SRP, будет становиться всё более приближенным к стандартным инженерным практикам.
Эта статья — попытка дать более глубокое объяснение принципу единственной ответственности, а также показать как его всё таки можно применять на практике. Кому интересно — добро пожаловать под кат.
Уровень 0
Первоначально, автор принципа — Дядя Боб, дал ему такую формулировку:
A class should have one, and only one, reason to change.
Класс должен иметь лишь одну причину для изменений.Это наиболее часто цитируемое определение принципа и оно крайне туманно. Проблема в том, что никто точно не понимает, что есть причина для изменений. Отсюда возникают различные субъективные трактовки «причины», а также стойкое ощущение того, что применение принципа единственной ответственности в разработке ПО это удел матёрых архитекторов и вообще что-то из области искусства. А ведь применение принципов проектирования на практике это именно то, что хочется в первую очередь освоить в процессе их изучения.
Рассмотрим следующий пример класса и попробуем оценить (субъективно конечно же) соответствует ли он SRP согласно определению выше:
Примечание: весь код в статье не высосан из пальца, а взят из реальных проектов автора.
class SelectQuery
{
public function __construct(QueryExecutor $executor) {...}
public function select($column, $alias = null): self {...}
public function from($table, $alias = null): self {...}
public function join(string $type, $table, $conditions = null): self {...}
public function where($column, $operator = null, $value = null): self {...}
public function orderBy($column, $order = null): self {...}
public function groupBy($column, $order = null): self {...}
public function limit(?int $limit): self {...}
public function offset(?int $offset): self {...}
public function build(): string {...}
public function rows(): array {...}
public function row(): array {...}
public function column(): array {...}
public function scalar() {...}
public function count() {...}
}
Как нетрудно догадаться этот класс умеет строить SELECT запрос и выполнять его. Сразу же бросается в глаза что у класса есть две группы методов: методы для генерации SQL кода и методы для выполнения этого кода. А значит у нас могут появиться две разных причины для изменения этого класса. Например, мы можем добавить новый метод having() для генерации HAVING условий. Это изменение никак не затронет методы выполняющие запрос. С другой стороны, мы можем добавить метод groupByKey() позволяющий группировать извлечённые данные по ключу и это в свою очередь никак не скажется на первой группе методов.
Налицо нарушение SRP. Решить проблему можно было бы, например, разделением класса на два:
class SelectQuery
{
public function select($column, $alias = null): self {...}
public function from($table, $alias = null): self {...}
public function join(string $type, $table, $conditions = null): self {...}
public function where($column, $operator = null, $value = null): self {...}
public function orderBy($column, $order = null): self {...}
public function groupBy($column, $order = null): self {...}
public function limit(?int $limit): self {...}
public function offset(?int $offset): self {...}
public function build(): string {...}
}
class ExecutableSelectQuery extends SelectQuery
{
public function __construct(QueryExecutor $executor) {...}
public function rows(): array {...}
public function row(): array {...}
public function column(): array {...}
public function scalar() {...}
public function count() {...}
}
Теперь вроде всё в порядке. Каждый класс делает ровно одну вещь и имеет ровно одну причину для изменений.
А вот другой пример:
@Transactional
class SearchService {
public List<Athlete> searchAthlete(SearchCriteria criteria)
public List<User> searchUser(SearchCriteria criteria)
public List<Association> searchAssociation(SearchCriteria criteria)
public List<Orgaization> searchOrganization(SearchCriteria criteria)
public List<Club> searchClub(SearchCriteria criteria)
public List<Team> searchTeam(SearchCriteria criteria)
public List<Game> searchGame(SearchCriteria criteria)
}
Как следует из названия класс используется для поиска различных сущностей и больше ничего не делает, а значит соответствует SRP. Ведь так?
А как вам такой пример:
class ActiveRecord
{
private $properties = [];
public function __get($property) {...}
public function __set($property, $value) {...}
public function create() {...}
public function update() {...}
public function delete() {...}
public function read() {...}
}
Ну ActiveRecord известный антипатерн. Он точно нарушает SRP. Или нет?
На самом деле во всех этих примерах нарушение или не нарушение SRP зависит от того, что мы будем считать причиной для изменений. При этом, варьируя широту этого понятия мы сможем обосновать как создание классов содержащих ровно по одному методу (из одной строки кода), так и создание «божественных объектов». А значит озвученное выше определение принципа единственной ответственности бесполезно.
Уровень -1
По видимому, Дядя Боб в какой-то момент пришёл к тому же выводу и поэтому в своей недавней книге Clean Architecture даёт новое определение этого принципа:
A module should be responsible to one, and only one, actor.
Модуль должен отвечать перед одним и только одним актором.Под актором здесь понимается группа, состоящая из одного или нескольких лиц, желающих изменения поведения программного модуля.
Это определение гораздо лучше предыдущего, т.к., во-первых, оно акцентирует внимание не на классе, а на модуле, что явно указывает на то, что SRP применим к любой части системы и не зависит от используемой парадигмы программирования. Во-вторых, из него следует важное практическое следствие:
Для определения соответствия программного модуля принципу единственной ответственности не всегда достаточно изучения лишь кода этого модуля. Требуется изучить также как этот модуль используется во внешнем по отношению к нему коде.Иными словами, каждый актор определяет контекст использования модуля или, что тоже самое, набор сценариев использования модуля. Это может показаться неочевидным сразу, но каждый сценарий использования модуля отражает чьё-либо желание зафиксированное в коде.
Докажем это
Каждый актор, или что тоже самое, группа лиц желающих изменения поведения модуля выступает в роли заказчика этого изменения. Чтобы изменение не было бесполезным оно должно как-то и где-то проявляться. Единственный способ это сделать это задействовать это изменение в одном или нескольких сценариях использования модуля. Если же изменение поведения программного модуля никак не проявляет себя в сценариях использования, то это означает одно из двух: либо это изменение не касается поведения модуля (например, рефакторинг приватных методов класса), а значит не относится к SRP вообще, либо оно сделано «на перспективу», что напрямую нарушает принцип YAGNI и следовательно такое изменение бесполезно.
Оценим с этой точки зрения наш первый пример — класс SelectQuery. Объективно он может использоваться в двух контекстах (т.е. у него есть два актора): генерация SQL кода и выполнение этого кода. Если у нас есть оба этих актора, т.е. если класс в каких-то сценариях используется только для генерации SQL, а в каких-то для выполнения запросов, то первая реализация класса не соответствует SRP. Если же у нас лишь один актор (как в проекте автора) — контекст выполнения запросов, то тогда исходная реализация не противоречит SRP. Действительно, в этом случае с точки зрения применения SelectQuery не будет никакой разницы содержится ли весь нужный функционал для построения и выполнения запросов в одном классе или в двух связанных классах. Сценарий использования будет всегда одним и тем же — строим запрос и потом выполняем:
$rows = (new SelectQuery(new QueryExecutorImpl()))
->select(...)
->from(...)
->where(...)
->rows();
Заметим, что классы из второй реализации SelectQuery не противоречат принципу единственной ответственности как для одного так и для двух акторов. А значит в случае одного актора отвечающего за выполнение запросов обе реализации эквивалентны с точки зрения следования SRP.
Что на счёт следующего класса SearchService. Одного кода класса недостаточно. Во-первых, неизвестно, что представляют собой сущности Athlete, Association и т.д. А во-вторых, неясен контекст использования класса. Например, может быть такой вариант что сущности это простые DTO, а контекст использования поиск различимых, но почти однородных данных. Тогда этот класс имеет одного актора и следовательно удовлетворяет SRP. Но если возвращаемые сущности это бизнес сущности, а методы класса используются в разных контекстах соответствующих каждой бизнес сущности (как в проекте автора), то тогда класс имеет кучу акторов, по одному на каждый метод, и следовательно жёстко нарушает принцип единственной ответственности.
В каких контекстах может использоваться наш ActiveRecord? На самом деле только в одном — сохранение записи в источнике данных. Никак иначе использовать этот класс нельзя. Таким образом, ActiveRecord прекрасно согласуется с SRP.
Для тех кто не верит
Приведённая выше реализация ActiveRecord действительно не нарушает SRP (кто думает иначе, приведите пример использования отличный от сохранение данных в источнике данных). Однако в оригинальном определении этого патерна заложено нарушение SRP: как минимум два контекста — бизнес логика и взаимодействие с источником данных.
Постойте! Что мы вообще делаем? На каком основании мы выделяем контексты (акторов) использования модуля. Каков критерий разграничения акторов? Чем это принципиально отличается от «причины для изменений»? Собственно ничем. Да, мы теперь знаем, что нужно изучать то как мы используем программные модули, но в остальном трактовка принципа единственной ответственности в его актуальной формулировке всё также субъективна и находится в прямой зависимости от опыта и интуиции разработчика. Хотелось бы какого-то более формального подхода к проблеме, что-нибудь померить и посчитать в конце концов. Что ж, такой подход есть.
Уровень -2
Принцип единственной ответственности возник как попытка объединения двух важных понятий структурного анализа и проектирования: coupling (сопряжение, зацепление, связанность) и cohesion (сплочённость, связность, прочность модуля).
Как это было
- В 1972 году Дэвид Парнас публикует статью в которой он высказывает идею декомпозиции системы на модули основываясь на том как они могут изменяться в будущем.
- В 1974 Эдсгер Дейкстра
вводит новый термин: The Separation of Concerns (Разделение ответственности). - В конце 70х Том Демарко популяризирует понятия coupling и cohesion предложенные ранее (в 1974) Ларри Константином.
- В конце 90х — начале 2000х Дядя Боб объединяет все эти идеи в принцип единственной ответственности.
Оба понятия неформально определяются следующим образом:
Coupling — степень взаимозависимости между программными модулями.
Cohesion — степень взаимозависимости между структурными составляющими программного модуля (подмодулями).Введём также определение связи и зависимости между программными модулями:
Модуль A связан с модулем B, или что тоже самое, модуль B связан с модулем А, только тогда когда существует передача информации между ними.
Модуль A зависит от модуля B, а модуль B не зависит от A, если изменения в спецификации А никогда не приведут к изменениям кода в B, а изменения в спецификации B могут приводить к изменениям кода в A.Где под спецификацией модуля понимается некоторая его часть доступная для прямого обращения извне (программный интерфейс модуля). Существует также альтернативная формулировка:
Модуль A зависит от модуля B, а модуль B не зависит от A, если удаление модуля B приводит к нарушениям в работе A.Таким образом программные модули могут быть связанными, но при этом независимыми. При этом несвязанные модули всегда независимы. Чего не скажешь про зависимые модули, они всегда связанны. Заметим, что информация (например, вызов метода, класса, обращение к переменной, отправка сообщения и т.д.) может передаваться как от зависимого модуля к независимому так и наоборот. Обратите также внимание на то, что связность это по сути то же самое что и сопряжение, но применительно к подмодулям рассматриваемых модулей. При этом в хорошо спроектированной системе низкое сопряжение между модулями подразумевает высокую связность внутри этих модулей (смотри, например, GRASP).
Нет ли тут подвоха?
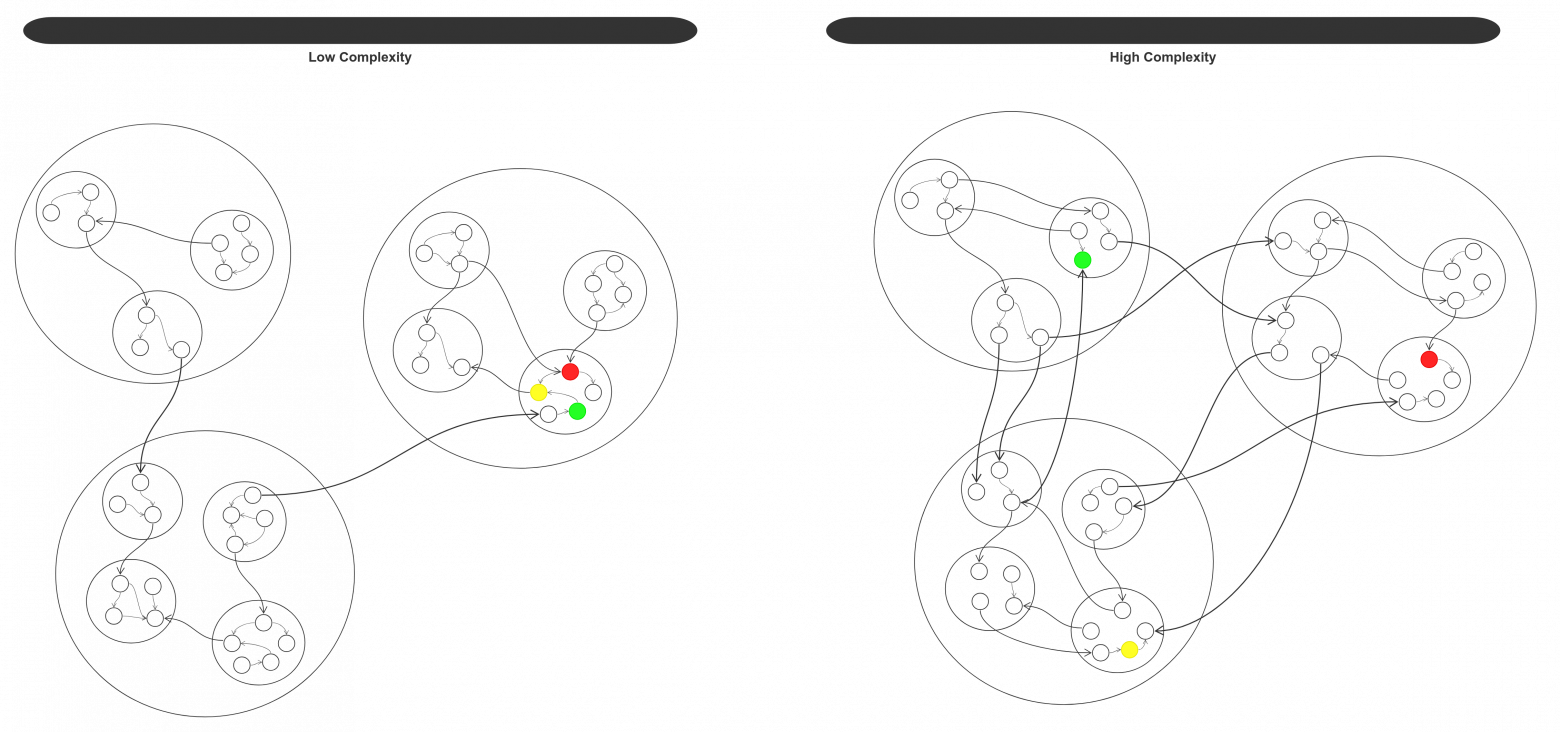
Если связность это тоже самое что и сопряжение, то получается, что для некоторого набора модулей входящих в состав более крупного модуля их взаимозависимость должна быть одновременно высокой (модули являются подмодулями более крупного модуля, а значит должны обладать высокой связностью) и низкой (сопряжение между модулями). Как такое возможно? Возможно, если взаимозависимость подмодулей каждого модуля будет не меньше взаимозависимости между модулями более высокого уровня. При этом самые низкоуровневые модули будут обладать наибольшей взаимозависимостью, а самые высокоуровневые (из которых состоит вся программа) — наименьшей. Следующий рисунок демонстрирует хорошую и плохую декомпозицию программы на модули (разноцветные модули изменяются в одно и то же время):
В стандарте ISO/IEC/IEEE 24765-2010 определены (неформально) следующие виды связности и сопряжения (от худшего к лучшему):
- Связность
- Случайная (coincidental)
Подмодули модуля в этом случае никак не взаимодействуют друг с другом и выполняют функционально не связанные задачи. Примером такой связности может быть весь тот код, который часто приводят для демонстрации нарушения принципа единственной ответственности:
class UserManager { public function writeToFile(...) {...} public function calculatePaymentAmount(...) {...} public function authenticateUser(...) {...} }
- Логическая (logical)
Также как и в случае случайной связности подмодули модуля никак не взаимодействуют друг с другом (либо взаимодействуют слабо), однако наблюдается их логическое сходство по какому-либо признаку (например, по сходству решаемых подмодулями задач). Примером логической связности может служить класс SearchService, при условии, что все его методы возвращают различные экземпляры бизнес сущностей. Тогда все методы класса имеют одно общее свойство — все они выполняют поиск некоторой сущности хотя каждый метод функционально принадлежит разным модулям.
- Временная (temporal)
Тип связности при котором подмодули объединены в модуль по причине их совместного использования в некоторый момент времени выполнения программы, а порядок обращения к ним не важен. При этом подмодули никак функционально не связаны между собой.
class ExceptionProcessor { public function logException(Exception $e) {...} public function notifyAdminAboutException(Exception $e) {...} public function showFormattedException(Exception $e) {...} } // Далее, где-то в коде $exceptionProcessor = new ExceptionProcessor(); ... try { ... } catch (Exception $e) { $exceptionProcessor->logException($e); $exceptionProcessor->notifyAdminAboutException($e); $exceptionProcessor->showException($e); }
- Процедурная (procedural)
Тип связности при котором подмодули объединены в модуль по причине их совместного использования в некоторый момент времени выполнения программы. Обращение к модулям происходит в определённом порядке. Подмодули могут быть функционально связаны между собой.
class Concole { public static function hasColorSupport(): bool {...} public static function highlight(string $text): string {...} } // Далее, где-то в коде $consoleText = '...'; if (Console::hasColorSupport()) { $consoleText = Console::highlight($consoleText); } $this->write($consoleText);
- Коммуникационная/информационная (communicational/informational)
Подмодули модуля функционально связаны между собой и обрабатывают одни и те же данные. Порядок обращения к подмодулям не имеет значения. Примером этого типа связности может служить класс SelectQuery (до разделения), ActiveRecord (только CRUD), большинство классов бизнес сущностей и сервисов, при условии их правильной реализации, воплощающих сценарии использования бизнес логики.
- Последовательностная (sequential)
Подмодули модуля функционально связаны между собой. При этом выходные данные одного подмодуля становятся входными данными другого подмодуля, т.е. важен порядок обращения к подмодулям. Как правило такой модуль имеет одну точку входа.
class ExpressionExecutor { public function execute(string $expression) { $ast = $this->parse( $this->lexer( $this->characterIterator($expression) ) ); return $ast->evaluate(); } protected function parse(Lexer $lexer) {...} protected function lexer(Iterator $iterator): Lexer {...} protected function characterIterator($expression): Iterator {...} }
- Функциональная (functional)
Все подмодули модуля функционально связаны между собой и выполняют одну хорошо определённую задачу. Этот тип связности прямая противоположность случайной связности.
class Lexer { public function __construct(CharacterIterator $charIterator) {...} public function getTokens(): Generator {...} }
- Случайная (coincidental)
- Сопряжение
- Патологическое (pathological)
Программный модуль оказывает влияние или зависит от внутренней реализации другого модуля. Как правило, этот тип зацепления связан с нарушением принципа сокрытия информации (information hiding).
class Hash: ... def hashOfText(self, text): self.__hashFromCache(text, self.__textHashCache) def __hashFromCache(text, cache): ... class OrderId: ... def hash(self): return Hash()._Hash__hashFromCache(self.__id, dict())
- По содержимому (content)
Часть или все содержимое одного программного модуля включены в содержимое другого модуля. Примером такого зацепления могут служить вложенные или анонимные классы.
public class BitSet implements Cloneable, java.io.Serializable { ... public IntStream stream() { class BitSetSpliterator implements Spliterator.OfInt { ... } return StreamSupport.intStream( new BitSetSpliterator(0, -1, 0, true), false ); } }
class EventPublisher { private $subscribers = []; public function __construct() { $this->subscribers[] = new EventSubscriberContract { public function handle(Event $event) { ... } } } }
- По общей области данных (common, common-environment)
Два или более модулей совместно используют общую область данных (глобальную по отношению к модулям).
$board = []; class Bot implements Player { ... public function move() { global $board; ... if ($board[$x][$y] === $this->shape['o']) { ... } ... $board[$x][$y] = $this->shape['x']; ... } } class Game { private $player1; private $player2; public function __construct(Player $player1, Player $player2) { $this->player1 = $player1; $this->player2 = $player2; } public funciton next(): bool { $this->player1->move(); if ($this->isGameOver()) { return true; } $this->player2->move(); if ($this->isGameOver()) { return true; } return false; } public function isGameOver(): bool { global $board; if ($board[$x][$y] === 'x' || ... ) { return true; } return false; } }
- Смешанное (hybrid)
Различные подмножества значений некоторого элемента данных используются в нескольких программных модулях для разных и несвязанных целей. Тут можно придумать такой искусственный пример: есть некоторый DTO содержащий данные потребляемыми двумя совершенно разными модулями.
- По управлению (control coupling)
Один модуль взаимодействует с другим модулем с целью повлиять на его поведение путём передачи ему управляющей информации.
class SortedCollection { private $items; private $comparator; public function __construct(array $items, callable $comparator) { $this->items = $items; $this->comparator = $comparator; } public function items(): array { $this->sort(); return $this->items; } private function sort(): void { usort($this->items, $this->comparator); } } ... $collection = new SortedCollection([3, 5, 2, 1], function (int $a, int $b) { return $a <=> $b; }); $sortedItems = $collection->items();
- По данным (data)
Данные одного программного модуля поступают на вход другого модуля.
class UserController { public function userDetails(string $userId, UserQueryService $service) { return $service->getUserDetails($userId); } }
- Патологическое (pathological)
Ссылки для примера
Несмотря на обилие метрик, не существует какого-то единственного способа для вычисления сопряжения и связности модулей. Отчасти это связано с отсутствием строгой формализации этих понятий. С другой стороны разновидностей связей между программными модулями великое множество. Какие-то связи считаются «полезными», а какие-то «вредными» (зависимости). И какую связь какой считать во многом зависит от того на каком языке программирования написана программа, какая парадигма программирования использовалась или в каком архитектурном стиле велась разработка.
Уровень — 3
Тем не менее не всё так плохо. Существуют интегральные метрики позволяющие объединить всё, что мы считаем «полезным» в отношении связей и рассчитать связность и сопряжение для всей системы. Один из таких подходов описан в Measuring Software Coupling. Хотя этот метод предлагается использовать для вычисления сопряжения, он также подходит и для вычисления связности модулей.
Суть метода заключается в следующем: необходимо составить список того, что мы считаем зависимостями, далее по формулам рассчитываем связность или сопряжение. Расчёт будет настолько точным насколько адекватным и полным будет наш список видов зависимостей. Из-за диалектической природы сопряжения и связности списки зависимостей для них могут быть противоположными.
Описание алгоритма расчёта
- Составляем матрицу описания связей для m модулей связанных посредством n видов связей:
где
 число характеризующее степень влияния вида связи j на модуль i. Чем больше это число тем сильнее модуль i связан с какими-то другими модулями через связь j. Если равен нулю, то это означает что вид связи j не относится к модулю i.
число характеризующее степень влияния вида связи j на модуль i. Чем больше это число тем сильнее модуль i связан с какими-то другими модулями через связь j. Если равен нулю, то это означает что вид связи j не относится к модулю i.
Следует заметить, что матрица описаний применима только к модулям граф зависимостей которых связный, т.е. есть существует путь передачи информации из любого модуля в любой другой модуль. Или другими словами в матрице описаний не должно быть строк или колонок состоящих из одних нулей.
- Вычисляем матрицу зависимостей:
по следующим формулам:



где — сумма всех элементов i-й строки матрицы описаний, а
— сумма всех элементов i-й строки матрицы описаний, а  — величина обратная сумме элементов k-го столбца матрицы связей.
— величина обратная сумме элементов k-го столбца матрицы связей.
- Анализируем получившуюся матрицу зависимостей. При этом имеем:
 , для всех i и j.
, для всех i и j. — степень зависимости между модулями i и j, если
— степень зависимости между модулями i и j, если  .
.- — степень независимости модуля i от остальных модулей, если
 .
.  — зависимость модуля от других модулей.
— зависимость модуля от других модулей. — общая степень взаимозависимости модулей.
— общая степень взаимозависимости модулей. — средняя степень взаимозависимости модулей.
— средняя степень взаимозависимости модулей.
Пользуясь вышеописанным алгоритмом попробуем рассчитать сопряжение и связность. Для примера возьмём код на PHP:
<?php
class User {...}
class Chat {...}
class ChatSession {...}
interface UserRepository
{
public function getMostLowLoadedOperator(): ?User;
}
interface ChatRepository
{
public function chatFrom($chatId): Chat;
}
interface ChatSessionRepository
{
public function sessionFrom($sessionId): ChatSession;
public function save(ChatSession $session): void;
}
interface BotService {...}
class ChatSessionApplicationService extends AbstractApplicationService
{
public function __construct(
ChatSessionRepository $sessionRepository,
ChatRepository $chatRepository,
UserRepository $userRepository,
BotService $botService,
UserAccessService $accessService
) {
...
}
public function startSession(StartSessionCommand $command): string
{
// Используются Chat, ChatRepository, ChatSession, ChatSessionRepository,
// BotService и функционал из AbstractApplicationService
...
}
public function switchChatSessionToFreeOperator($sessionId): void
{
// Используются ChatSession, ChatSessionRepository, User и UserRepository
// и функционал из AbstractApplicationService
...
}
public function changeName($sessionId, string $name): void
{
// Используются ChatSession, ChatSessionRepository и UserAccessService
...
}
}
Прежде чем рассчитывать сопряжение составим список возможных связей между классами в PHP. Каждому типу связи присвоим вес в диапазоне от 0 до 1 (0 — соответствует отсутствию связи, 1 — соответствует максимально «жёсткой» связи).
| Вид связи | Вес связи |
|---|---|
| Класс наследует не абстрактный класс или использует каким либо образом не абстрактный класс. | 1.0 |
| Класс использует трейт. | 0.8 |
| Класс наследует абстрактный класс или использует каким либо образом абстрактный класс. | 0.6 |
| Класс реализует интерфейс или использует каким либо образом интерфейс. | 0.4 |
| Класс взаимодействует с другим классом через посредника — функцию или другой класс или используется каким-либо образом другим классом будучи при этом независимым от него. | 0.2 |
| Класс взаимодействует с другим классом через несколько посредников или не взаимодействует вовсе. | 0.0 |
Итак, описание зависимостей есть, можно приступать к расчёту сопряжения. Всего у нас есть 11 модулей:
 — User
— User — Chat
— Chat — ChatSession
— ChatSession — UserRepository
— UserRepository — ChatRepository
— ChatRepository — ChatSessionRepository
— ChatSessionRepository — ChatSessionApplicationService
— ChatSessionApplicationService — AbstractApplicationService
— AbstractApplicationService — BotService
— BotService — UserAccessService
— UserAccessService — StartSessionCommand
— StartSessionCommand
Составим матрицу описания связей, где
будет определять степень зависимости между и . Таким образом столбцы в матрице связей это веса рёбер графа зависимостей рассчитанные в прямом и обратном направлении:Матрица описания связей:
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
 |
0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 |
 |
0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
 |
0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
 |
0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.4 | 0.2 | 0 | 0 | 0 | 0 |
 |
0 | 0 | 0 | 0 | 0.4 | 0.2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
 |
0 | 0 | 0.4 | 0.2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
 |
0.2 | 0.2 | 0.2 | 0 | 0.2 | 0 | 0.2 | 0.2 | 0.2 | 0 | 0.2 | 0 | 0.2 | 0.2 |
 |
0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.6 |
 |
0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
 |
0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0.2 | 0 | 0 |
 |
1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
Выполняем расчёты и получаем матрицу зависимостей:

Общая зависимость классов
, а средняя степень зависимости Как и следовало ожидать, самым зависимым модулем оказался ChatSessionApplicationService, за ним следуют репозитории, UserAccessService, AbstractApplicationService и наконец все остальные классы. Средняя степень зависимости между классами небольшая, что говорит нам о том, что в основном классы слабо связанны между собой.
Попробуем теперь вычислить связность ChatSessionApplicationService и понять на сколько он удовлетворяет SRP. Здесь также можно было бы составить иерархию видов связей внутри модуля (класса) с точки зрения связности его подмодулей (методов). Но поскольку в нашем случае методы внутри ChatSessionApplicationService связаны исключительно через зависимости класса условимся в целях упрощения расчётов считать использование конкретной зависимости методом за 1. Таким образом, строки матрицы описаний связей будут соответствовать методам класса, а столбцы — использованию конкретной зависимости:
- Метод использует UserRepository
- Метод использует ChatRepository
- Метод использует ChatSessionRepository
- Метод использует UserAccessService
- Метод использует BotService
- Метод использует AbstractApplicationService
Матрица связей:

Матрица зависимостей:

Общая связность класса
, а средняя степень связности методов Сразу бросается в глаза низкая степень связности методов друг с другом. Об этом также свидетельствует средняя связность. При этом первый метод почти не связан с третьим, а второй в два раза сильнее связан с первым методом чем с третьим. Третий метод слабо связан с первыми двумя. Всё это означает, что ChatSessionApplicationService плохо соответствует SRP и, следовательно, должен быть разбит на три класса. К тому же такое разбиение только улучшит показатели сопряжения между классами (кто не верит — посчитайте сами) в силу слабой независимости сервиса с остальными классами.
Дно?
Едва ли. Исследования в области контроля качества и сложности программного кода ведутся до сих пор и останавливаться не собираются. А значит применение принципов управления сложностью программного кода, к которым в частности относится SRP, будет становиться всё более приближенным к стандартным инженерным практикам.
