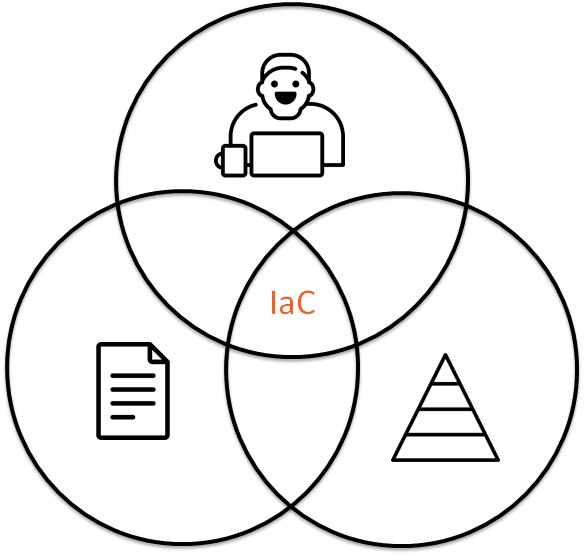
IaC (Infrastructure as Code) is a modern approach and I believe that infrastructure is code. It means that we should use the same philosophy for infrastructure as for software development. If we are talking that infrastructure is code, then we should reuse practices from development for infrastructure, i.e. unit testing, pair programming, code review. Please, keep in mind this idea while reading the article.
It is the translation of my speech (video RU) at DevopsConf 2019-05-28.
Infrastructure as bash history

Let us imagine that you are on-boarding on a project and you hear something like: "We use Infrastructure as Code approach". Unfortunately, what they really mean is Infrastructure as bash history or Documentation as bash history. This is almost a real situation. For example, Denis Lysenko described this situation in his speech How to replace infrastructure and stop worrying(RU). Denis shared the story on how to convert bash history into an upscale infrastructure.
Let us check source code definition: a text listing of commands to be compiled or assembled into an executable computer program. If we want we can present Infrastructure as bash history like code. This is a text & a list of commands. It describes how a server was configured. Moreover, it is:
- Reproducible: you can get bash history, execute commands and probably get working infrastructure.
- Versioning: you know who logged in, when and what was done.
Unfotunately, if you lose server, you will be able to do nothing because there is no bash history, you lost it with the server.
What is to be done?
Infrastructure as Code

On the one hand, this abnormal case, Infrastructure as bash history, can be presented as Infrastructure as Code, but on the other hand, if you want to do something more complex than LAMP server, you have to manage, maintain and modify the code. Let us chat about parallels between Infrastructure as Code development and software development.
D.R.Y.

We were developing SDS (software-defined storage). The SDS consisted of custom OS distributive, upscale servers, a lot of business logic, as a result, it had to use real hardware. Periodically, there was a sub-task install SDS. Before publishing new release, we had to install it and check out. At first, it looked as if it was a very simple task:
- SSH to host and run command.
- SCP a file.
- Modify a configuration.
- Run a service.
- ...
- PROFIT!
I believe that Make CM, not bash is a good approach. However, bash is only used in extreme, limited cases, like at the very beginning of a project. So, bash was a pretty good and reasonable choice at the very beginning of the project. Time was ticking. We were facing different requests to create new installations in a slightly different configuration. We were SSHing into installations, and running the commands to install all needed software, editing the configuration files by scripts and, finally, configuring SDS via Web HTTP rest API. After all that the installation was configured and working. This was a pretty common practice, but there were a lot of bash scripts and installation logic was becoming more complex every day.
Unfortunately, each script was like a little snowflake depending on who was copy-pasting it. It was also a real pain when we were creating or recreating the installation.
I hope you have got the main idea, that at this stage we had to constantly tweak scripts logic until the service was OK. But, there was a solution for that. It was D.R.Y.
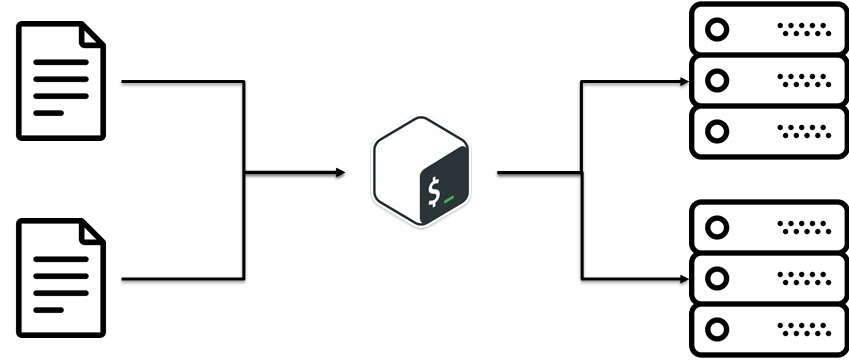
There is D.R.Y. (Do not Repeat Yourself) approach. The main idea is to reuse already existing code. It sounds extremely simple. In our case, D.R.Y. was meaning: split configs and scripts.
S.O.L.I.D. for CFM

The project was growing, as a result, we decided to use Ansible. There were reasons for that:
- Bash should not contain complex logic.
- We had some amount of expertise in Ansible.
There was an amount of business logic inside the Ansible code. There is an approach for putting things in source code during the software development process. It is called S.O.L.I.D.. From my point of view, we can re-use S.O.L.I.D. for Infrastructure as Code. Let me explain step by step.
The Single Responsibility Principle

A class should only have a single responsibility, that is, only changes to one part of the software's specification should be able to affect the specification of the class.
You should not create a Spaghetti Code inside your infrastructure code. Your infrastructure should be made from simple predictable bricks. In other words, it might be a good idea to split immense Ansible playbook into independent Ansible roles. It will be easier to maintain.
The Open-Closed Principle
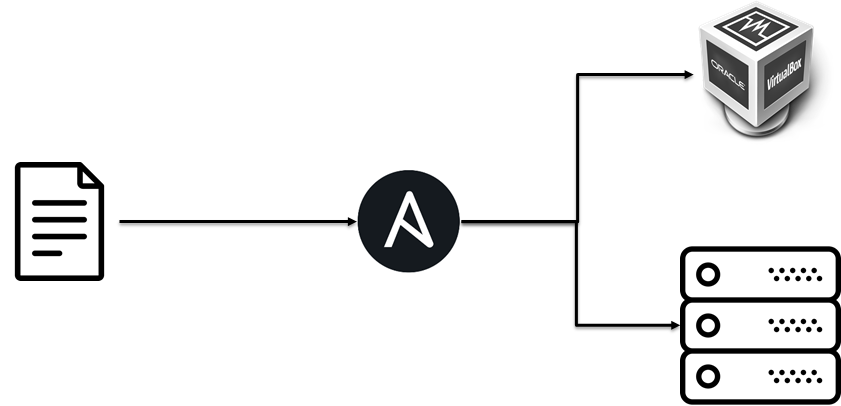
Software entities… should be open for extension, but closed for modification.
In the beginning, we were deploying the SDS at virtual machines, a bit later we added deploy to bare metal servers. We had done it. It was as easy as pie for us because we just added an implementation for bare metal specific parts without modifying the SDS installation logic.
The Liskov Substitution Principle

Objects in a program should be replaceable with instances of their subtypes without altering the correctness of that program.
Let us be open-minded. S.O.L.I.D. is possible to use in CFM in general, it was not a lucky project. I would like to describe another project. It is an out of box enterprise solution. It supports different databases, application servers and integration interfaces with third-party systems. I am going to use this example for describing the rest of S.O.L.I.D.
For example in our case, there is an agreement inside infrastructure team: if you deploy ibm java role or oracle java or openjdk, you will have executable java binary. We need it because top*level Ansible roles depend on that. Also, it allows us to swap java implementation without modifying application installing logic.
Unfortunately, there is no syntax sugar for that in Ansible playbooks. It means that you must keep it in mind while developing Ansible roles.
The Interface Segregation Principle

Many client-specific interfaces are better than one general-purpose interface.
In the beginning, we were putting application installation logic into the single playbook, we were trying to cover all cases and cutting edges. We had faced the issue that it is hard to maintain, so we changed our approach. We understood that a client needs an interface from us (i.e. https at 443 port) and we were able to combine our Ansible roles for each specific environment.
The Dependency Inversion Principle

One should "depend upon abstractions, [not] concretions."
- High-level modules should not depend on low-level modules. Both should depend on abstractions (e.g. interfaces).
- Abstractions should not depend on details. Details (concrete implementations) should depend on abstractions.
I would like to describe this principle via anti-pattern.
- There was a customer with a private cloud.
- We were requesting VMs in the cloud.
- Our deploying logic was depending on which hypervisor a VM was located.
In other words, we were not able to reuse our IaC in another cloud because top-level deploying logic was depending on the lower-level implementation. Please, don't do it
Interaction

Infrastructure is not only code, it is also about interaction code <-> DevOps, DevOps <-> DevOps, IaC <-> people.
Bus factor
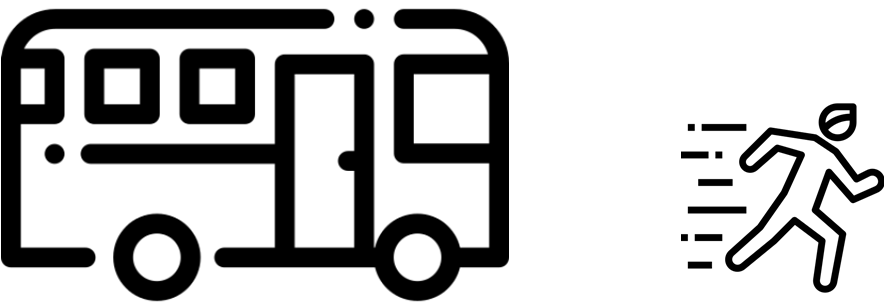
Let us imagine, there is DevOps engineer John. John knows everything about your infrastructure. If John gets hit by a bus, what will happen with your infrastructure? Unfortunately, it is almost a real case. Some time things happen. If it has happened and you do not share knowledge about IaC, Infrastructure among your team members you will face a lot of unpredictable & awkward consequences. There are some approaches for dealing with that. Let us chat about them.
Pair DevOpsing
It is like pair programming. In other words, there are two DevOps engineers and they use single laptop\keyboard for configuring infrastructure: configuring a server, creating Ansible role, etc. It sounds great, however, it did not work for us. There were some custom cases when it partially worked.
- Onboarding: Mentor & new person get a real task from a backlog and work together — transfer knowledge from mentor to the person.
- Incident call: During troubleshooting, there is a group of engineers, they are looking for a solution. The key point is that there is a person who leads this incident. The person shares screen & ideas. Other people are carefully following him and noticing bash tricks, mistakes, logs parsing etc.
Code Review
From my point of view, Code review is one of the most efficient ways to share knowledge inside a team about your infrastructure. How does it work?
- There is a repository which contains your infrastructure description.
- Everyone is doing their changes in a dedicated branch.
- During merge request, you are able to review delta of changes in your infrastructure.
The most interesting thing is that we were rotating a reviewer. It means that every couple of days we elected a new reviewer and the reviewer was looking through all merge requests. As a result, theoretically, every person had to touch a new part of the infrastructure and had an average knowledge about our infrastructure in general.
Code Style

Time was ticking, we were sometimes arguing during the review because the reviewer and the committer might use a different code style: 2 spaces or 4, camelCase or snake_case. We implemented it, however, it was not a picnic.
- The first idea was to recommend using linters. Everyone had his own development environment: IDE, OS… it was tricky to sync & unify everything.
- The idea evolved into a slack bot. After each commit, the bot was checking source code & pushing into slack messages with a list of problems. Unfortunately, in the vast majority of cases, there were no source code changes after the messages.
Green Build Master
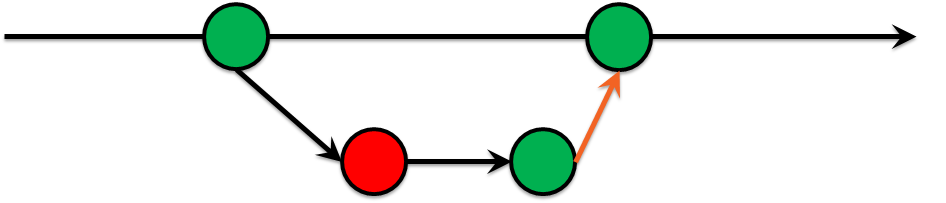
Next, the most painful step was to restrict pushing to the master branch for everyone. Only via merge requests & green tests have to be ok. This is called Green Build Master. In other words, you are 100% sure that you can deploy your infrastructure from the master branch. It is a pretty common practice in software development:
- There is a repository which contains your infrastructure description.
- Everyone is doing their changes in a dedicated branch.
- For each branch, we are running tests.
- You are not able to merge into the master branch if tests are failing.
It was a tough decision. Hopefully, as a result during review process, there was no arguing about the code style and the amount of code smell was decreasing.
IaC Testing

Besides code style checking, you are able to check that you can deploy or recreate your infrastructure in a sandbox. What's for? It is a sophisticated question and I would like to share a story instead of an answer. Were was a custom auto-scaler for AWS written in Powershell. The auto-scaler did not check cutting edges for input params, as a result, it created tons of virtual machines and the customer was unhappy. It is an awkward situation, hopefully, it is possible to catch it on the earliest stages.
On the one hand, it is possible to test the script & infrastructure, but on the other hand, you are increasing an amount of code and making the infrastructure more complex. However, the real reason under the hood for that is that you are putting your knowledge about infrastructure to the tests. You are describing how things should work together.
IaC Testing Pyramid
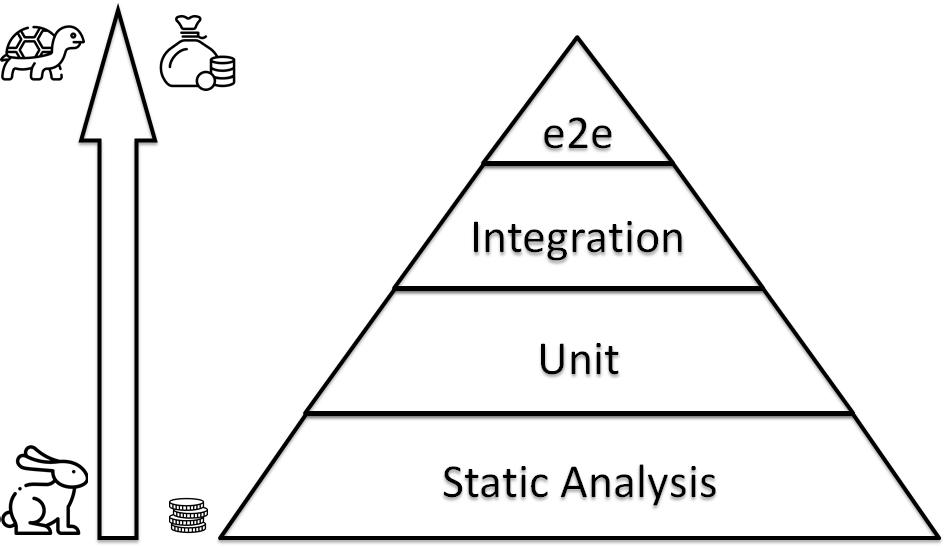
IaC Testing: Static Analysis
You can create the whole infrastructure from scratch for each commit, but, usually, there are some obstacles:
- The price is stratospheric.
- It requires a lot of time.
Hopefully, there are some tricks. You should have a lot of simple, rapid, primitive tests in your foundation.
Bash is tricky
Let us take a look at an extremely simple example. I would like to create a backup script:
- Get all files from the current directory.
- Copy the files into another directory with a modified name.
The first idea is:
for i in * ; do cp $i /some/path/$i.bak done
Pretty good. However, what if the filename contains space? We are clever guys, we use quotes:
for i in * ; do cp "$i" "/some/path/$i.bak" done
Are we finished? Nope! What if the directory is empty? Globing fails in this case.
find . -type f -exec mv -v {} dst/{}.bak \;
Have we finished? Not yet… We forgot that filename might contain \n character.
touch x mv x "$(printf "foo\nbar")" find . -type f -print0 | xargs -0 mv -t /path/to/target-dir
Static analysis tools
You can catch some issues from the previous example via Shellcheck. There are a lot of tools like that, they are called linters and you can find out the most suitable for your IDE, stack and environment.
| Language | Tool |
|---|---|
| bash | Shellcheck |
| Ruby | RuboCop |
| python | Pylint |
| Ansible | Ansible Lint |
IaC Testing: Unit Tests
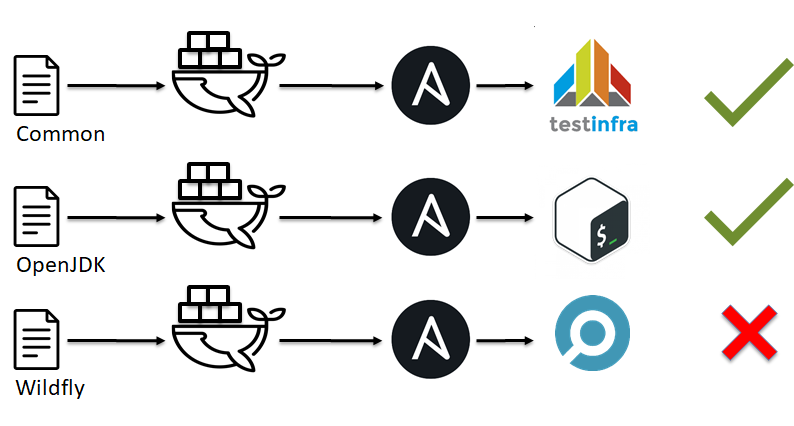
As you can see linters can not catch everything, they can only predict. If we continue to think about parallels between software development and Infrastructure as Code we should mention unit tests. There are a lot of unit tests systems like shunit, JUnit, RSpec, pytest. But have you ever heard about unit tests for Ansible, Chef, Saltstack, CFengine?
When we were talking about S.O.L.I.D. for CFM, I mentioned that our infrastructure should be made from simple bricks/modules. Now the time has come:
- Split infrastructure into simple modules/breaks, i.e. Ansible roles.
- Create an environment i.e. Docker or VM.
- Apply your one simple break/module to the environment.
- Check that everything is ok or not.
... - PROFIT!
IaC Testing: Unit Testing tools
What is the test for CFM and your infrastructure? i.e. you can just run a script or you can use production-ready solution like:
| CFM | Tool |
|---|---|
| Ansible | Testinfra |
| Chef | Inspec |
| Chef | Serverspec |
| saltstack | Goss |
Let us take a look at testinfra, I would like to check that users test1, test2 exist and their are part of sshusers group:
def test_default_users(host): users = ['test1', 'test2' ] for login in users: assert host.user(login).exists assert 'sshusers' in host.user(login).groups
What is the best solution? There is no single answer for that question, however, I created the heat map and compared changes in this projects during 2018-2019:

IaC Testing frameworks
After that, you can face a question how to run it all together? On the one hand, you can do everything on your own if you have enough great engineers, but on the other hand, you can use opensource production-ready solutions:
| CFM | Tool |
|---|---|
| Ansible | Molecule |
| Chef | Test Kitchen |
| Terraform | Terratest |
I created the heat map and compared changes in this projects during 2018-2019:

Molecule vs. Testkitchen
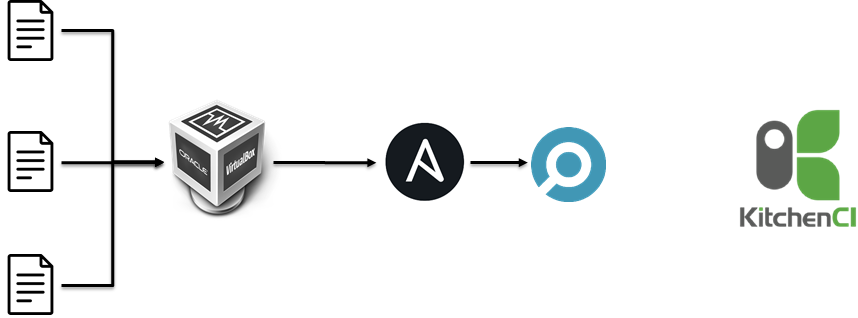
In the beginning, we tried to test ansible roles via testkitchen inside hyper-v:
- Create VMs.
- Apply Ansible roles.
- Run Inspec.
It took 40-70 minutes for 25-35 Ansible roles. It was too long for us.
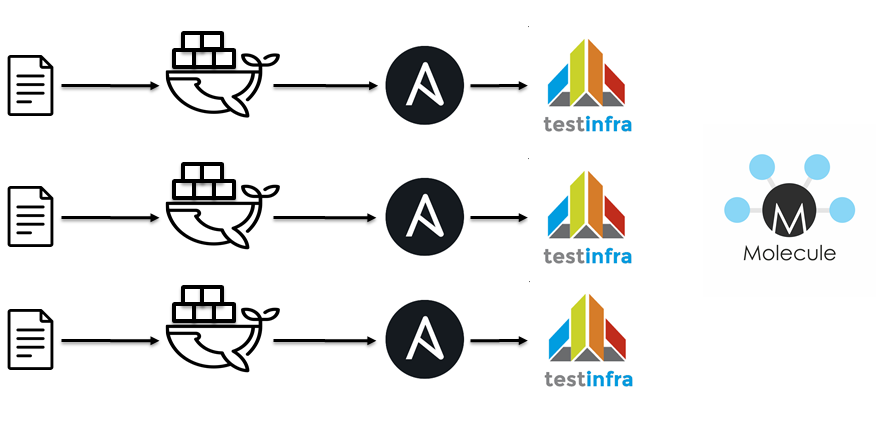
The next step was use Jenkins / docker / Ansible / molecule. It is approximately the same idea:
- Lint Ansible playbooks.
- Lint Ansible roles.
- Run a docker container.
- Apply Ansible roles.
- Run testinfra.
- Check idempotency.
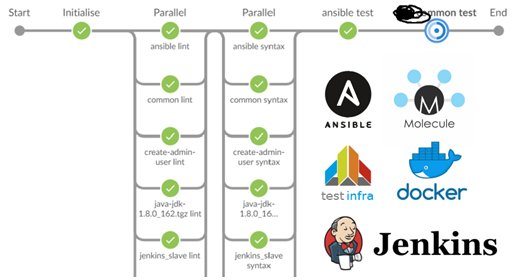
Linting for 40 roles and testing for ten of them took about 15 minutes.

What is the best solution? On the one hand, I do not want to be the final authority, but on the other hand, I would like to share my point of view. There is no silver bullet exists, however, in case of Ansible molecule is a more suitable solution then testkitchen.
IaC Testing: Integration Tests

On the next level of IaC testing pyramid, there are integration tests. Integration tests for infrastructure look like unit tests:
- Split infrastructure into simple modules/breaks, i.e. Ansible roles.
- Create an environment i.e. Docker or VM.
- Apply a combination of simple break/module to the environment.
- Check that everything is ok or not.
... - PROFIT!
In other words, during unit tests, we check one simple module(i.e. Ansible role, python script, Ansible module, etc) of an infrastructure, but in the case of integration tests, we check the whole server configuration.
IaC Testing: End to End Tests
On top of the IaC testing pyramid, there are End to End Tests. In this case, we do not check dedicated server, script, module of our infrastructure; We check the whole infrastructure together works properly. Unfortunately, there is no out of the box solution for that or I have not heard about them(please, flag me if you know about them). Usually, people reinvent the wheel, because, there is demand on end to end tests for infrastructure. So, I would like to share my experience, hope it will be useful for somebody.

First of all, I would like to describe the context. It is an out of box enterprise solution, it supports different databases, application servers and integration interfaces with third-party systems. Usually, our clients are an immense enterprise with a completely different environment. We have knowledge about different environments combinations and we store it as different docker-compose files. Also, there matching between docker-compose files and tests, we store it as Jenkins jobs.
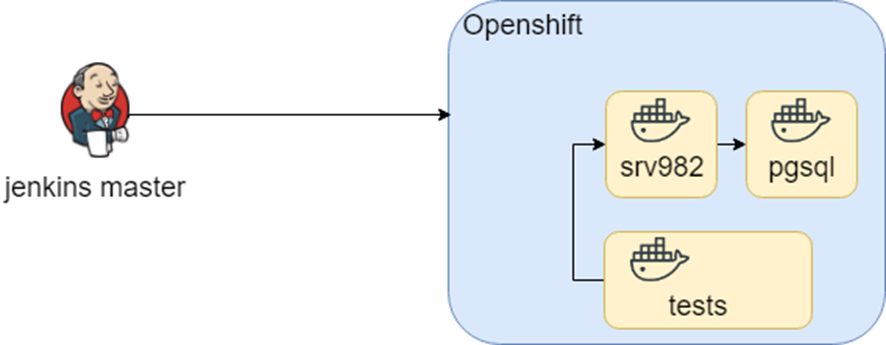
This scheme had been working quiet log period of time when during openshift research we tried to migrate it into Openshift. We used approximately the same containers (hell D.R.Y. again) and change the surrounding environment only.
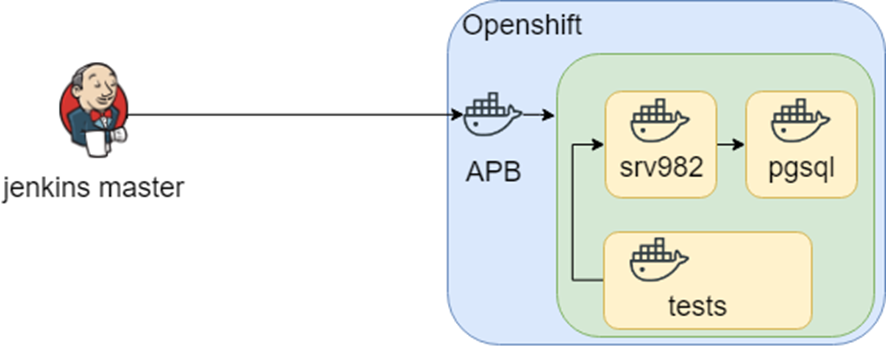
We continue to research and found APB (Ansible Playbook Bundle). The main idea is that you pack all needed things into a container and run the container inside Openshift. It means that you have a reproducible and testable solution.

Everything was fine until we faced one more issue: we had to maintain heterogeneous infrastructure for testing environments. As a result, we store our knowledge of how to create infrastructure and run tests in the Jenkins jobs.
Conclusion
Infrastructure as Code it is a combination of:
- Code.
- People interaction.
- Infrastructure testing.
- It's cross post from personal blog
- Russian version
- Dry run 2019-04-24 SpbLUG
- Video(RU) from DevopsConf 2019-05-28
- Video(RU) from DINS DevOps EVENING 2019-06-20
- Lessons Learned From Writing Over 300,000 Lines of Infrastructure Code & text version
- Integrating Infrastructure as Code into a Continuous Delivery Pipeline
- Тестируем инфраструктуру как код
- Эффективная разработка и сопровождение Ansible-ролей
- Ansible — это вам не bash!
- Ansible идемпотентный
