Quintet is a way to present atomic pieces of data indicating their role in the business area. Quintets can describe any item, while each of them contains complete information about itself and its relations to other quintets. Such description does not depend on the platform used. Its objective is to simplify the storage of data and to improve the visibility of their presentation.
We will discuss an approach to storing and processing information and share some thoughts on creating a development platform in this new paradigm. What for? To develop faster and in shorter iterations: sketch your project, make sure it is what you thought of, refine it, and then keep refining the result.
The quintet has properties: type, value, parent, and order among the peers. Thus, there are 5 components including the identifier. This is the simplest universal form to record information, a new standard that could potentially fit any programming demands. Quintets are stored in the file system of the unified structure, in a continuous homogeneous indexed bulk of data. The quintet data model — a data model that describes any data structure as a single interconnected list of basic types and terms based on them (metadata), as well as instances of objects stored according to this metadata (data).
Not bit or electronic impulse that orient the magnetic spin.
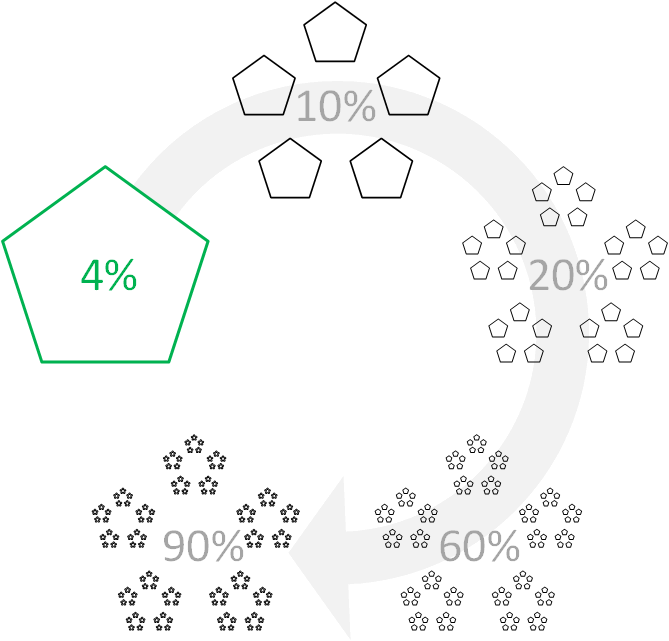
We are accustomed to measure the data in bytes, whether it is a document or photo size, internet traffic limit, or available space on your mobile device. We propose another measure — Quintet — which does not have a fixed size like Byte does, but represents an atomic amount of data, which is of some value to the user.
For example, you can say that your database occupies 119 megabytes of the storage or you can state that this database stores 1.37 mega-quintets. You do not care much what a byte is in this context, but you understand that this database contains 1.37 million of your term descriptions, objects, their attributes, links, events, queries with their details, etc. To possess 1.37 million valuable pieces of data sounds sexier than having 119 megabytes of stuff on you.
Thus, this is not to replace the way the information is stored on the data medium, but to shift to another level of abstraction.
The main idea of this article is to replace machine types with human terms and replace variables with objects. Not by those objects that need a constructor, destructor, interfaces, and a garbage collector, but by crystal-clear units of information that a customer handles. That is, if the customer says «Client», then to save the essence of this statement on the medium would not require expertise of a programmer.

It makes sense to focus the user’s attention only on the value of the object, while its type, parent, order (among equals in subordination) and identifier should be obvious from the context or simply hidden. This means that the user does not know anything about quintets at all, he simply gives out a task, makes sure that it is accepted correctly, and then starts its execution.
There is a set of data types everyone understands: string, number, file, text, date, and so on. Such a simple set is quite enough to sketch the solution, and to «program» it along with the terms necessary for its implementation. The basic types represented by quintets may look like this:
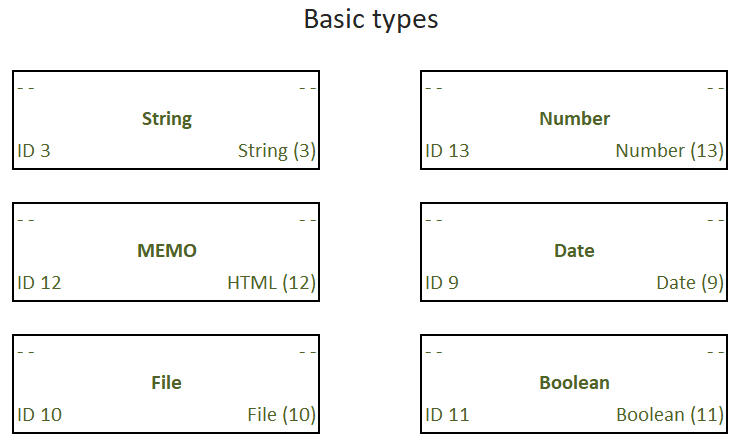
In this case, some of the components of the quintet are not used, while the quintet itself is used as the basic type. This makes the system kernel easier to navigate when collecting metadata.
Due to the analytic gap between the user and the programmer, a significant deformation of concepts occurs at the stage of outlining a project. The understatement, incomprehensibility and unsolicited initiative often turns a simple and reasonable idea of the customer into a logically impossible mess, if being evaluated from the the user’s point of view.

Knowledge transfer should occur without loss and distortion. Furthermore, organizing the storage of this knowledge, you should better get rid of the restrictions imposed by the data management system chosen.
Typically, there are many databases on the server; each of them contains a description of the data scheme with a specific set of details — logically interconnected data. They are stored on the data medium in a specific order, ideally — optimal to reduce the retrieval efforts.
The proposed information storage system is a compromise between various well-known methods: column-oriented, relational and NoSQL. It is designed to solve the tasks usually performed by one of these approaches.
For example, the theory of column-oriented DBMS looks beautiful: we read only the desired column, but not all the rows of records as a whole. However, in practice, it is unlikely that data will be placed on the media so that it is convenient to retrieve dozens of different analytic dimensions. Note that attributes and analytical metrics can be added and removed, sometimes faster than we can rebuild our columnar storage. Not to mention that the data in the database can be amended, which will also violate the beauty of the storage schema due to inevitable fragmentation.
We introduced a concept — a term — to describe any objects that we operate with: entity, property, request, file, etc. We will define all the terms that we use in our business area. And with their help, we will describe all entities that have details, including the form of relationships between entities. For example, an attribute — a link to a status dictionary entry. The term is written as a quintet of data.
A set of term descriptions is metadata like the same represented by the structure of tables and fields in a regular database. For example, there is the following data structure: a service request on some date that has the content (request description) and a status, to which the participants of a production process add comments indicating the date. In a traditional database constructor it will look something like this:

Since we decided to hide from the user all non-essential details, such as binding IDs, for example, the scheme will be somewhat simplified: the mentions of IDs are removed and the names of entities and their key values are combined.
The user «draws» the task: a request from today’s date which has a state (reference value) and to which you can add comments indicating the date:
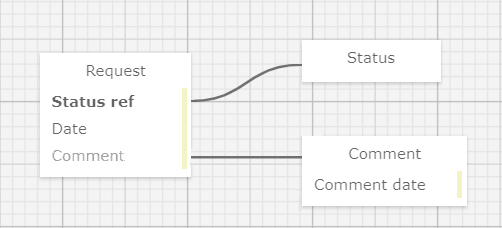
Now we see 6 different data fields instead of 9, and the whole scheme offers us to read and comprehend 7 words instead of 13. Although this is not the main thing, of course.
The following are the quintets generated by the quintet-processing kernel to describe this structure:
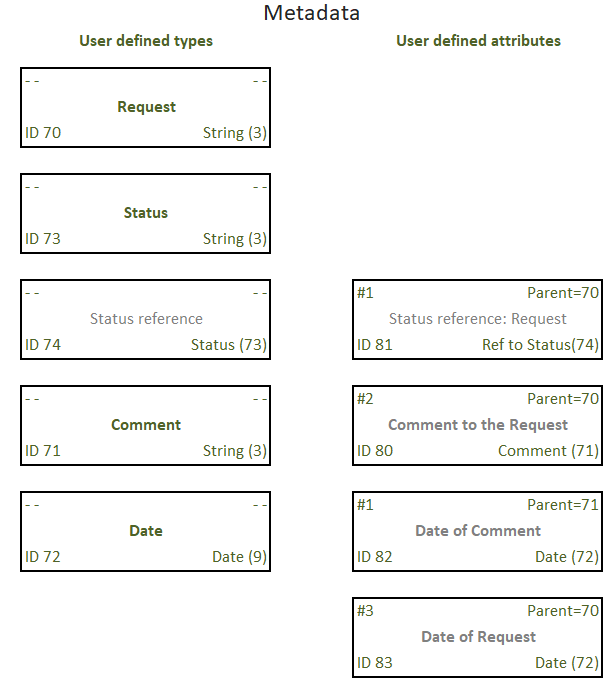
Explanations in place of quintet values highlighted in gray are provided for clarity. These fields are not filled out, because all the necessary information is unambiguously determined by the remaining components.
This might look slightly complicated for humans, but the good news is — a human will never see this. The kernel will represent the metadata as comprehensible diagrams and the data as simple flat tables.
Let me show how we store such a data set for the above task:
The data itself is stored in quintets according to the metadata. We can visualize them the same way we did above:

We see a familiar hierarchical structure written down using something like the Adjacency List method.
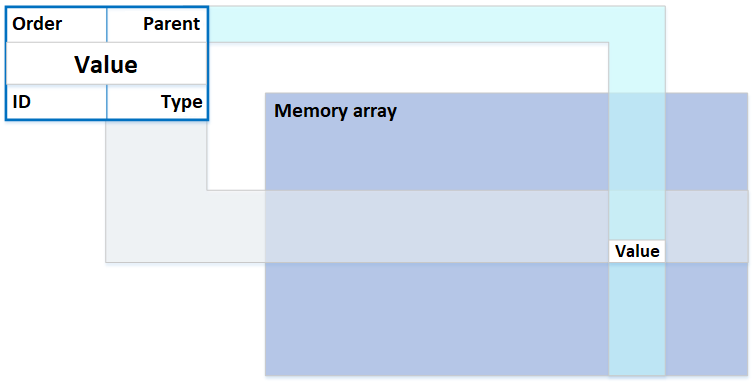
The data is written to the memory as a sequence of quintet items in bytes of data. In order to search by index the kernel treats those bytes of data according to the data type defined for them by basic types.
That’s it: a huge list of five of data items.
The storage principles are not much different from the same in RDBMS, which enables us building SQL queries to the data to make data retrieval, JOINs, aggregate functions and other things we like in relational databases.
The above example is very simple, but what will be when the structure is thousand times more complex and there are gigabytes of data?
What we need:
Thus, all records in our database will be indexed, including both data and metadata. Such indexing is necessary to get the benefits of a relational database — the simplest and most popular tool. The parent index is actually composite (parent ID + type). The index by type is also composite (type + value) for quick search of objects of a given type.
Metadata allows us to get rid of recursion: for example, to find all the details of a given object, we use the index by parent ID. If you need to search for objects of a certain type, then we use the index by type ID. Type is an analog of a table name and a field in a relational DBMS.
In any case, we do not scan the entire data set, and even with a large number of values of any type, the desired value can be found in a small number of steps.
In itself, such a database is not self-sufficient for application programming, and is not complete, as they say, according to Turing. However, we are talking here not only about the database, but are trying to cover all aspects: objects are, among other things, arbitrary control algorithms that can be launched, and they will work.
As a result, instead of complex database structures and separately stored source code of control algorithms, we get a uniform information field, limited by the volume of the storage space and governed with metadata. The data itself is presented to the user in an understandable form to him — the structure of the subject area and the corresponding entries in it. The user arbitrarily changes the structure and data, including making bulk operations with them.
To work with this data representation, you will need a very compact kernel software — our database engine is of the size smaller than a computer BIOS, and, therefore, it can be made if not in hardware, then at least as fast and bug-free as possible. For security reasons, it also could be read-only.
Adding a new class to an assembly in my favorite .Net, we can observe the loss of 200-300 MB of RAM only on the definition of this class. These megabytes will not fit into the cache of the proper level, causing the system to swap on disk with all the consequent overhead. A similar situation is with Java. The description of the same class with quintets will take tens or hundreds of bytes, since the class uses only primitive operations for working with data that the kernel already knows.
The prototype of the platform we built has four components:
As it was intended, working with the prototype no user would think there are quintets inside — this looks just like an ordinary constructor.
You may test a working prototype implementation by the link in the first comment to this article.
The described approach is not limited only to the usage of quintets, but promotes a different paradigm than the one that programmers are used to. Instead of an imperative, declarative, or object language, we propose the query language as more familiar to humans and allowing us to set the task directly to the computer, bypassing programmers and the impenetrable layer of existing development environments.
Of course, a translator from a layman user language to a language of clear requirements will still be necessary in most cases.
This topic will be described in more detail in separate articles with examples and existing developments.
So, shortly, it works as follows:
The Turing completeness of the entire system is ensured by the embodiment of the basic requirements: the kernel can do sequential operations, conditionally branch, process the data and stop work when a certain result is achieved.
For a person, the benefit is simplicity of perception, for example, instead of declaring a cycle involving variables
a more understandable form is used, like
We dream of abstracting from the low-level subtleties of information systems: loops, constructors, functions, manifests, libraries — all these take up too much space in the brain of a programmer, leaving little room for creative work and development.
An application is often useless without means of scaling: an unlimited ability to expand the load capacity of an information system is required. In the described approach, taking into consideration the extreme simplicity of data organization, scaling turns out to be organized no more complicated than in existing architectures.
In the above example with the service requests, you can separate them, for example, by their ID, making the generation of ID with fixed HIGH bytes for different servers. That is, when using 32 bits for storing ID, the left two-three-four or more bits, as needed, will indicate the server on which these applications are stored. Thus, each server will have its own pool of IDs.
The kernel of a single server can function independently of other servers, without knowing anything about them. When creating an object, it will be given a high priority to the server with the minimum number of IDs used, to ensure the even load distribution.
Given a limited set of possible variations of requests and responses in such data organization, you will need a fairly compact dispatcher that distributes requests across servers and aggregates their results.
We will discuss an approach to storing and processing information and share some thoughts on creating a development platform in this new paradigm. What for? To develop faster and in shorter iterations: sketch your project, make sure it is what you thought of, refine it, and then keep refining the result.
The quintet has properties: type, value, parent, and order among the peers. Thus, there are 5 components including the identifier. This is the simplest universal form to record information, a new standard that could potentially fit any programming demands. Quintets are stored in the file system of the unified structure, in a continuous homogeneous indexed bulk of data. The quintet data model — a data model that describes any data structure as a single interconnected list of basic types and terms based on them (metadata), as well as instances of objects stored according to this metadata (data).
Half a minute of lyrics
Nowadays there are an infinite number of standards to record data, numerous approaches and rules, the knowledge of which is necessary for working with these records. Standards are described separately and do not directly relate to the corresponding data. In the case of quintets, taking any of them, you can get relevant information about its nature, properties and processing rules in the user’s business area. Its standard is unified and fixed for all areas. The quintet is hidden from the user — metadata and data are available to the latter in a common comprehensible manner.
Quintet is not only information, it could also represent executable code. But above all, it is the data that you want to record, store, and retrieve. Since in our case quintets are directly addressable, interconnected and indexed, we will store them in a kind of database.
Quintet is not only information, it could also represent executable code. But above all, it is the data that you want to record, store, and retrieve. Since in our case quintets are directly addressable, interconnected and indexed, we will store them in a kind of database.
Why Quintet instead of Byte?
Not bit or electronic impulse that orient the magnetic spin.
We are accustomed to measure the data in bytes, whether it is a document or photo size, internet traffic limit, or available space on your mobile device. We propose another measure — Quintet — which does not have a fixed size like Byte does, but represents an atomic amount of data, which is of some value to the user.
For example, you can say that your database occupies 119 megabytes of the storage or you can state that this database stores 1.37 mega-quintets. You do not care much what a byte is in this context, but you understand that this database contains 1.37 million of your term descriptions, objects, their attributes, links, events, queries with their details, etc. To possess 1.37 million valuable pieces of data sounds sexier than having 119 megabytes of stuff on you.
Thus, this is not to replace the way the information is stored on the data medium, but to shift to another level of abstraction.
Quintet structure
The main idea of this article is to replace machine types with human terms and replace variables with objects. Not by those objects that need a constructor, destructor, interfaces, and a garbage collector, but by crystal-clear units of information that a customer handles. That is, if the customer says «Client», then to save the essence of this statement on the medium would not require expertise of a programmer.
It makes sense to focus the user’s attention only on the value of the object, while its type, parent, order (among equals in subordination) and identifier should be obvious from the context or simply hidden. This means that the user does not know anything about quintets at all, he simply gives out a task, makes sure that it is accepted correctly, and then starts its execution.
Basic concepts
There is a set of data types everyone understands: string, number, file, text, date, and so on. Such a simple set is quite enough to sketch the solution, and to «program» it along with the terms necessary for its implementation. The basic types represented by quintets may look like this:
In this case, some of the components of the quintet are not used, while the quintet itself is used as the basic type. This makes the system kernel easier to navigate when collecting metadata.
The background
Due to the analytic gap between the user and the programmer, a significant deformation of concepts occurs at the stage of outlining a project. The understatement, incomprehensibility and unsolicited initiative often turns a simple and reasonable idea of the customer into a logically impossible mess, if being evaluated from the the user’s point of view.
Knowledge transfer should occur without loss and distortion. Furthermore, organizing the storage of this knowledge, you should better get rid of the restrictions imposed by the data management system chosen.
How we store the data now
Typically, there are many databases on the server; each of them contains a description of the data scheme with a specific set of details — logically interconnected data. They are stored on the data medium in a specific order, ideally — optimal to reduce the retrieval efforts.
The proposed information storage system is a compromise between various well-known methods: column-oriented, relational and NoSQL. It is designed to solve the tasks usually performed by one of these approaches.
For example, the theory of column-oriented DBMS looks beautiful: we read only the desired column, but not all the rows of records as a whole. However, in practice, it is unlikely that data will be placed on the media so that it is convenient to retrieve dozens of different analytic dimensions. Note that attributes and analytical metrics can be added and removed, sometimes faster than we can rebuild our columnar storage. Not to mention that the data in the database can be amended, which will also violate the beauty of the storage schema due to inevitable fragmentation.
Metadata
We introduced a concept — a term — to describe any objects that we operate with: entity, property, request, file, etc. We will define all the terms that we use in our business area. And with their help, we will describe all entities that have details, including the form of relationships between entities. For example, an attribute — a link to a status dictionary entry. The term is written as a quintet of data.
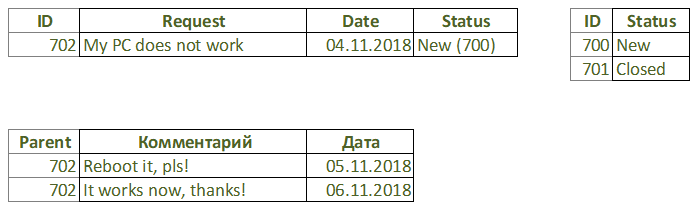
A set of term descriptions is metadata like the same represented by the structure of tables and fields in a regular database. For example, there is the following data structure: a service request on some date that has the content (request description) and a status, to which the participants of a production process add comments indicating the date. In a traditional database constructor it will look something like this:
Since we decided to hide from the user all non-essential details, such as binding IDs, for example, the scheme will be somewhat simplified: the mentions of IDs are removed and the names of entities and their key values are combined.
The user «draws» the task: a request from today’s date which has a state (reference value) and to which you can add comments indicating the date:
Now we see 6 different data fields instead of 9, and the whole scheme offers us to read and comprehend 7 words instead of 13. Although this is not the main thing, of course.
The following are the quintets generated by the quintet-processing kernel to describe this structure:
Explanations in place of quintet values highlighted in gray are provided for clarity. These fields are not filled out, because all the necessary information is unambiguously determined by the remaining components.
See how quintets are related
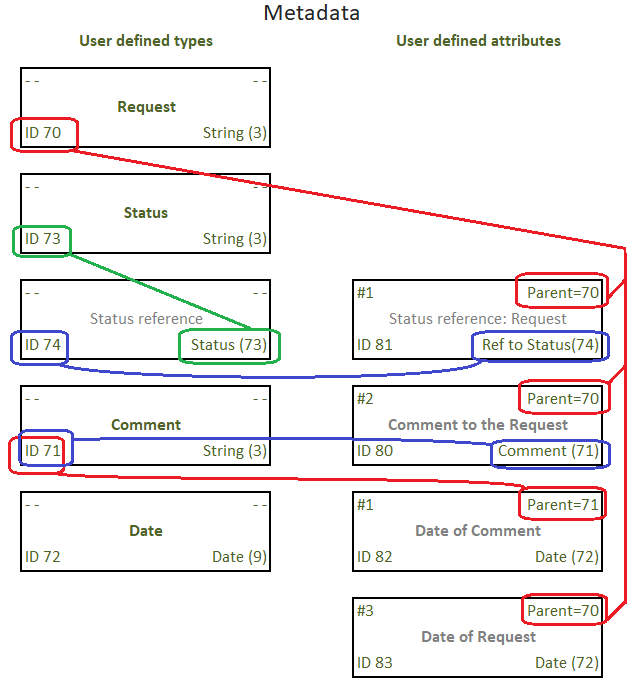
What we have here:
What we have here:
- the attributes with IDs 80, 81, 83 has the same parent — Request
- quintet #82 is the attribute of Comment, which is in turn an attribute of Request
- attribute #74 is a reference to the type described by quintet #73 and is used as attribute #81 of Request
This might look slightly complicated for humans, but the good news is — a human will never see this. The kernel will represent the metadata as comprehensible diagrams and the data as simple flat tables.
User data
Let me show how we store such a data set for the above task:
The data itself is stored in quintets according to the metadata. We can visualize them the same way we did above:
We see a familiar hierarchical structure written down using something like the Adjacency List method.
Physical storage
The data is written to the memory as a sequence of quintet items in bytes of data. In order to search by index the kernel treats those bytes of data according to the data type defined for them by basic types.
That’s it: a huge list of five of data items.
The storage principles are not much different from the same in RDBMS, which enables us building SQL queries to the data to make data retrieval, JOINs, aggregate functions and other things we like in relational databases.
To test the prototype of a development platform based on the quintet storage system we use a relational database.
Performance
The above example is very simple, but what will be when the structure is thousand times more complex and there are gigabytes of data?
What we need:
- The discussed hierarchical structure — 1 pc.
- B-tree for searching by ID, parent and type — 3 pcs.
Thus, all records in our database will be indexed, including both data and metadata. Such indexing is necessary to get the benefits of a relational database — the simplest and most popular tool. The parent index is actually composite (parent ID + type). The index by type is also composite (type + value) for quick search of objects of a given type.
Metadata allows us to get rid of recursion: for example, to find all the details of a given object, we use the index by parent ID. If you need to search for objects of a certain type, then we use the index by type ID. Type is an analog of a table name and a field in a relational DBMS.
In any case, we do not scan the entire data set, and even with a large number of values of any type, the desired value can be found in a small number of steps.
The basis for the development platform
In itself, such a database is not self-sufficient for application programming, and is not complete, as they say, according to Turing. However, we are talking here not only about the database, but are trying to cover all aspects: objects are, among other things, arbitrary control algorithms that can be launched, and they will work.
As a result, instead of complex database structures and separately stored source code of control algorithms, we get a uniform information field, limited by the volume of the storage space and governed with metadata. The data itself is presented to the user in an understandable form to him — the structure of the subject area and the corresponding entries in it. The user arbitrarily changes the structure and data, including making bulk operations with them.
We did not invent anything new: all the data is already stored in the file system and the search in them is carried out using B-trees, either in the file system, or in the database. We just reorganized the presentation of the data so that it is easier and clear to work with.
To work with this data representation, you will need a very compact kernel software — our database engine is of the size smaller than a computer BIOS, and, therefore, it can be made if not in hardware, then at least as fast and bug-free as possible. For security reasons, it also could be read-only.
Adding a new class to an assembly in my favorite .Net, we can observe the loss of 200-300 MB of RAM only on the definition of this class. These megabytes will not fit into the cache of the proper level, causing the system to swap on disk with all the consequent overhead. A similar situation is with Java. The description of the same class with quintets will take tens or hundreds of bytes, since the class uses only primitive operations for working with data that the kernel already knows.
You might think that this approach is already implemented many times in various applications, but that is not true.
We made a deep search in both internet and intellectual property (patents) bases, and no one claims to do exactly the same solution to break the performance limit of constructors, single-table solutions, and other EAV-based systems. Nevertheless, we put hundreds of gigabytes in such quintet application and found it working quite well. In case you want to see evidences, create and test your own instance, feel free to visit our github account.
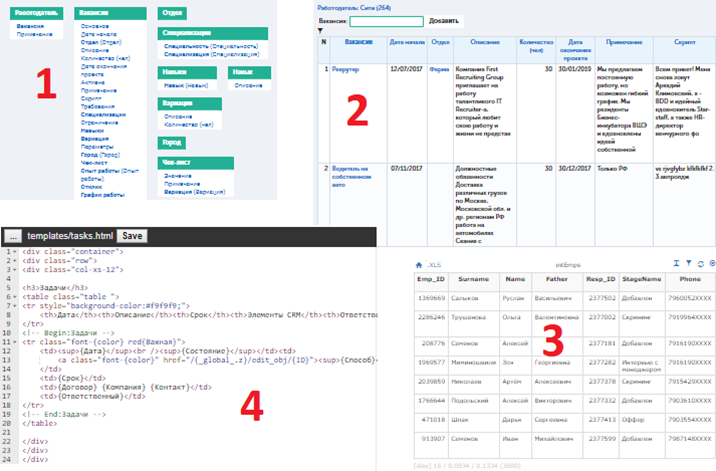
The prototype of the platform we built has four components:
- Visual Type editor to define the metadata
- Data navigation tool like a simple SQL navigator
- Visual Report designer to build SQL queries to the data
- A Template processor to combine templates with data retrieved by queries
As it was intended, working with the prototype no user would think there are quintets inside — this looks just like an ordinary constructor.
You may test a working prototype implementation by the link in the first comment to this article.
How to deal with different formats: RDBMS, NoSQL, column bases
The discussed approach covers two main areas: RDBMS and NoSQL. When solving problems that take advantage of columnar databases, we need to tell the kernel that certain objects should be stored, taking into account the optimization of mass sampling of the values of a certain data type (our term). Therefore, the kernel will be able to place data on disk in the most profitable way.
Thus, for a columnar DB, we can significantly save the space occupied by quintets: use only one or two of its components to store useful data instead of five, and also use the index only to indicate the beginning of data chains. In many cases, only the index will be used for sampling from our analogue of a columnar base, without the need to access the data of the quintet list itself.
It should be noted that the idea is not intended to collect all the advanced developments from these three types of databases. On the contrary, the engine of the new system will be reduced as much as possible, embodying only the necessary minimum of functions — everything that covers DDL and DML requests in the concept described here.
Thus, for a columnar DB, we can significantly save the space occupied by quintets: use only one or two of its components to store useful data instead of five, and also use the index only to indicate the beginning of data chains. In many cases, only the index will be used for sampling from our analogue of a columnar base, without the need to access the data of the quintet list itself.
It should be noted that the idea is not intended to collect all the advanced developments from these three types of databases. On the contrary, the engine of the new system will be reduced as much as possible, embodying only the necessary minimum of functions — everything that covers DDL and DML requests in the concept described here.
Programming paradigm
The described approach is not limited only to the usage of quintets, but promotes a different paradigm than the one that programmers are used to. Instead of an imperative, declarative, or object language, we propose the query language as more familiar to humans and allowing us to set the task directly to the computer, bypassing programmers and the impenetrable layer of existing development environments.
Of course, a translator from a layman user language to a language of clear requirements will still be necessary in most cases.
This topic will be described in more detail in separate articles with examples and existing developments.
So, shortly, it works as follows:
- We once described primitive data types using quintets: string, number, file, text and others, and also trained the kernel to work with them. Training means the correct presentation of data and the implementation of simple operations with them.
- Now we describe user terms (data types) — in the form of metadata. The description is just specifying a primitive data type for each user type and determining the relations.
- We enter data quintets according to the structure specified by metadata. Each quintet of data contains a link to its type and parent, which allows you to quickly find it in the data storage.
- The kernel tasks come down to fetching data and performing simple operations with them to implement arbitrarily complex algorithms defined by the user.
- The user manages data and algorithms using a visual interface that presents both of them.
The Turing completeness of the entire system is ensured by the embodiment of the basic requirements: the kernel can do sequential operations, conditionally branch, process the data and stop work when a certain result is achieved.
For a person, the benefit is simplicity of perception, for example, instead of declaring a cycle involving variables
for (i = 0; i <length (A); i ++) if A [i] meets a condition do something with A [i]
a more understandable form is used, like
with every A, that match a condition, do something
We dream of abstracting from the low-level subtleties of information systems: loops, constructors, functions, manifests, libraries — all these take up too much space in the brain of a programmer, leaving little room for creative work and development.
Scalability
An application is often useless without means of scaling: an unlimited ability to expand the load capacity of an information system is required. In the described approach, taking into consideration the extreme simplicity of data organization, scaling turns out to be organized no more complicated than in existing architectures.
In the above example with the service requests, you can separate them, for example, by their ID, making the generation of ID with fixed HIGH bytes for different servers. That is, when using 32 bits for storing ID, the left two-three-four or more bits, as needed, will indicate the server on which these applications are stored. Thus, each server will have its own pool of IDs.
The kernel of a single server can function independently of other servers, without knowing anything about them. When creating an object, it will be given a high priority to the server with the minimum number of IDs used, to ensure the even load distribution.
Given a limited set of possible variations of requests and responses in such data organization, you will need a fairly compact dispatcher that distributes requests across servers and aggregates their results.
