
Введение
Здравствуйте, уважаемые хабровчане!
Последние два года моей работы в компании Synesis были тесно связаны с процессом создания и развития Synet — открытой библиотеки для запуска предварительно обученных сверточных нейронных сетей на CPU. В процессе этой работы мне пришлось столкнуться с рядом интересных моментов, которые касаются вопросов оптимизации алгоритмов прямого распространения сигнала в нейронных сетях. Как мне кажется, описание этих моментов было бы весьма интересным для читателей Хабрахабра. Чему я и хочу посвятить цикл своих статей. Продолжительность цикла будет зависеть от вашего интереса к данной теме ну и конечно же от моей способности побороть лень. Начать цикл хочется с описания самого
- Сверточный слой: методы оптимизации основанные на матричном умножении
- Сверточный слой: быстрая свертка по методу Шмуэля Винограда
Ответы на вопросы
Прежде, чем начинать подробное описание фреймворка, постараюсь сразу ответить на ряд вопросов, которые наверняка возникнут у читателей. Опыт подсказывает, что лучше это сделать заранее, так как многие сразу начинают писать гневные комментарии, не дочитав до конца.
Первый вопрос, который обычно возникает в таких случаях: Да кто сейчас запускает сети на обычных процессорах, когда есть графические ускорители и тензорные (матричные) ускорители?
Отвечу, что да — обучение нейросетей действительно не целесообразно выполнять на CPU, но вот запускать уже готовые нейросети — вполне себе востребованная задача, особенно если сеть достаточно небольшого размера. Причины для этого могут быть разные, но основные:
- CPU более широко распространены. GPU есть далеко не на всех машинах, особенно это касается серверов.
- На небольших нейросетях выигрыш от использования GPU мал, а иногда полностью отсутствует.
- Эффективное задействование GPU для ускорения нейросетей, как правило, требует существенно более сложной структуры приложения.
Следующий возможный вопрос: A зачем использовать для запуска специализированное решение, когда есть Tensorflow, Caffe или MXNet?
Ответить на это можно следующее:
- Разнообразие фреймворков не всегда хорошо — так если в проекте есть несколько моделей, обученных разными фреймворками, то потом придется их всех встраивать в готовое решение, что очень неудобно.
- Классические фреймворки разрабатывались для обучения моделей на GPU — и в этом они безусловно хороши! Но для запуска обученных моделей на CPU их функционал избыточен и не оптимален.
- Подтверждением необходимости специализированного решения служит популярность OpenVINO — фреймворка от Интел, который выполняет ту же функцию.
Тут сразу логично возникает вопрос про изобретение велосипеда: Зачем использовать свою поделку, когда есть вполне профессиональное решение от признанного мирового лидера?
Отвечу так:
- На момент начала работ над Synet, OpenVINO был еще в зачаточном состоянии. И по правде говоря, если бы в то время OpenVINO был в его нынешнем состоянии, то я с высокой долей вероятности не стал бы ввязываться в свой собственный проект.
- Собственный фреймворк можно адаптировать под свои нужды. Так в моем случае, основным требованием была максимальная однопоточная производительность.
- Можно максимально быстро обеспечить поддержку новой функциональности, если она вдруг потребовалась (например, добавить новый слой и ли устранить ошибку с производительностью).
- Легкость встраивания в готовое решение.
- Функционирование библиотеки на платформах, отличных от x86/x86_64 — например на ARM.
Вероятно, у читателей возникнут и другие вопросы или возражения — но их я пока предугадать не могу и потому отвечу в комментариях к статье. А пока приступим к непосредственному описанию Synet.
Краткое описание Synet
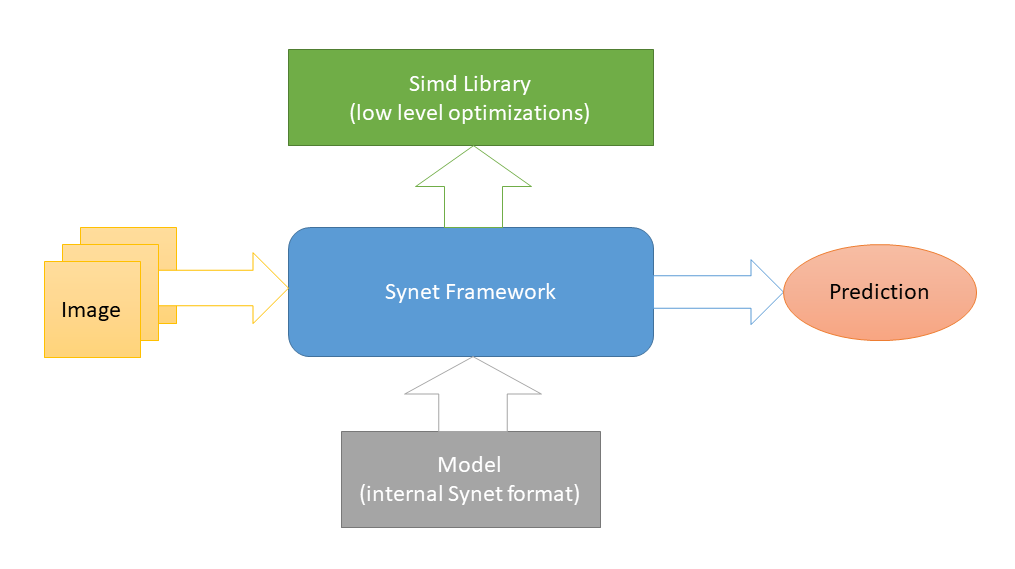
Synet написан на С++ и содержит только заголовочные файлы. Низкоуровневые платформозависимые оптимизации реализованы в Simd — другом open-source проекте, посвященном ускорению обработки изображений на CPU. И это единственная внешняя зависимость Synet (такая схема выбрана с целью облегчения интеграции библиотеки в сторонние проекты). Для запуска нейросетей используются модели собственного внутреннего формата.
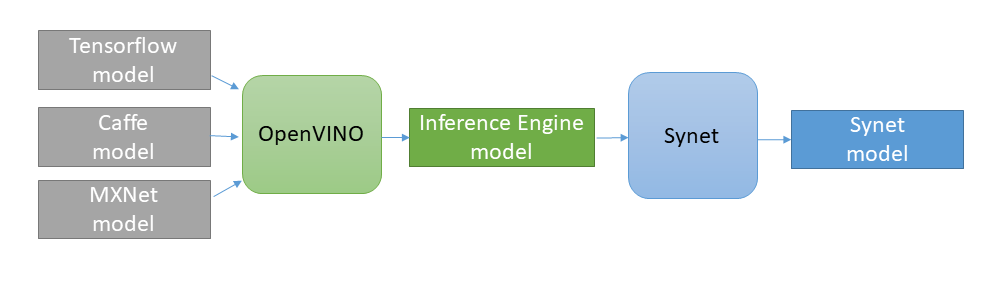
Конвертация предварительно обученных моделей во внутренний формат осуществляется по двухшаговой схеме: 1) Сначала конвертируем модель в формат Inference Engine (благо
в OpenVINO есть для этого все необходимые инструменты). 2) Затем из этого промежуточного представления конвертируем непосредственно во внутренний формат Synet.
Модель Synet содержит два файла: 1) *.XML — файл с описанием структуры модели. 2) *.BIN — файл с обученными весами.

Пример использования Synet
Ниже приведен пример, использования Synet для детектирования лиц. Оригинальная модель Inference Engine взята здесь.
#define SYNET_SIMD_LIBRARY_ENABLE
#include "Synet/Network.h"
#include "Synet/Converters/InferenceEngine.h"
#include "Simd/SimdDrawing.hpp"
typedef Synet::Network<float> Net;
typedef Synet::View View;
typedef Synet::Shape Shape;
typedef Synet::Region<float> Region;
typedef std::vector<Region> Regions;
int main(int argc, char* argv[])
{
Synet::ConvertInferenceEngineToSynet("ie_fd.xml", "ie_fd.bin",
true, "synet.xml", "synet.bin");
Net net;
net.Load("synet.xml", "synet.bin");
net.Reshape(256, 256, 1);
Shape shape = net.NchwShape();
View original;
original.Load("faces_0.ppm");
View resized(shape[3], shape[2], original.format);
Simd::Resize(original, resized, ::SimdResizeMethodArea);
net.SetInput(resized, 0.0f, 255.0f);
net.Forward();
Regions faces = net.GetRegions(original.width, original.height, 0.5f, 0.5f);
uint32_t white = 0xFFFFFFFF;
for (size_t i = 0; i < faces.size(); ++i)
{
const Region & face = faces[i];
ptrdiff_t l = ptrdiff_t(face.x - face.w / 2);
ptrdiff_t t = ptrdiff_t(face.y - face.h / 2);
ptrdiff_t r = ptrdiff_t(face.x + face.w / 2);
ptrdiff_t b = ptrdiff_t(face.y + face.h / 2);
Simd::DrawRectangle(original, l, t, r, b, white);
}
original.Save("annotated_faces_0.ppm");
return 0;
}
В результате работы примера должна появится картинка с аннотированными лицами:

Теперь давайте разберем пример по шагам:
- В начале идет преобразование модели из формата Inference Engine в Synet:
Synet::ConvertInferenceEngineToSynet("ie_fd.xml", "ie_fd.bin", true, "synet.xml", "synet.bin");
В реальности это шаг делается один раз, а потом везде используется уже сконвертированная модель. - Загрузка сконвертированной модели:
Net net; net.Load("synet.xml", "synet.bin"); - Необязятельный шаг по изменению размера входного изображения и батча (естественно, что модель должна поддерживать изменение входного размера):
net.Reshape(256, 256, 1); - Загрузка картинки и ее приведение в входному размеру модели:
View original; original.Load("faces_0.ppm"); View resized(net.NchwShape()[3], net.NchwShape()[2], original.format); Simd::Resize(original, resized, ::SimdResizeMethodArea); - Загрузка изображения в модель:
net.SetInput(resized, 0.0f, 255.0f); - Запуск прямого распространения сигнала в сети:
net.Forward(); - Получение набора регионов с найденными лицами:
Regions faces = net.GetRegions(original.width, original.height, 0.5f, 0.5f);
Сравнение производительности
Наверное было бы не совсем корректно сравнивать Synet с классическими фреймворками для машинного обучения, например Inference Engine на ряде тестов их обходит в разы.
Потому ниже приведен пример сравнения однопоточной производительности Inference Engine (продукта схожей функциональности) и Synet на выборке из набора открытых моделей:
| Test | Description | i7-6700 3.4GHz 4c/8t FMA/AVX-2 | i9-7900X 3.3GHz 10c/20t AVX-512 |
|---|---|---|---|
| test_000 | Vehicle attributes recognition (2.4 MB) | 1.520 / 1.597 ms (-5%) | 0.772 / 0.690 ms (+12%) |
| test_001 | Age gender recognition (8.2 MB) | 1.659 / 1.418 ms (+17%) | 0.988 / 0.804 ms (+23%) |
| test_002 | Face detection (4.0 MB) | 34.26 / 43.17 ms (-21%) | 26.72 / 24.57 ms (+9%) |
| test_003f | Face detection (2.2 MB) | 12.63 / 14.87 ms (-15%) | 8.680 / 9.326 ms (-7%) |
| test_004 | Licence plate recognition (4.6 MB) | 4.350 / 4.871 ms (-11%) | 2.838 / 2.432 ms (+17%) |
| test_005 | Licence plate recognition (0.7 MB) | 0.339 / 0.260 ms (+30%) | 0.200 / 0.142 ms (+41%) |
| test_006 | Face reidentification (4.2 MB) | 11.82 / 9.052 ms (+31%) | 8.200 / 4.559 ms (+80%) |
| test_007 | Person reidentification (3.1 MB) | 3.567 / 3.402 ms (+5%) | 2.471 / 1.679 ms (+47%) |
| Average | +2% | +25% |
Как видно из таблицы, на данных тестах на машине с поддержкой AVX2 (i7-6700) производительность Synet в целом соответствует производительности Inference Engine (хотя и сильно варьируется от модели к модели). На машине с поддержкой AVX-512 (i9-7900X) производительность Synet в среднем на 25% превышает таковую у Inference Engine.
Все измерения проводились тестовым приложением, которое есть в Synet. Так что при желании, читатели смогут воспроизвести тесты у себя:
git clone -b master --recurse-submodules -v https://github.com/ermig1979/Synet.git synet
cd synet
./build.sh inference_engine
./test.sh
Достоинства и недостатки
Начну с плюсов:
- Проект небольшой по размеру, легко внедряется в сторонние проекты.
- Показывает высокую однопоточную производительность.
- Работает на мобильных процессорах (поддерживает ARM-NEON).
Ну и минусы, куда же без них:
- Нет поддержки GPU и других специальных ускорителей.
- Плохое распараллеливание одной задачи на многоядерных CPU.
- Нет поддержки INT8 (квантизации весов).
Заключение
В настоящее время Synet используется в рамках проекта Kipod — облачной платформы для видеоаналитики. Возможно у него есть и другие пользователи, но это не точно :). В дальнейшем, по мере развития проекта, в него хотелось бы добавить следующие вещи:
- Поддержку новых моделей, слоев, алгоритмов.
- Поддержкy целочисленных вычислений в формате INT8 (квантизированных весов).
- Поддержкy вычислений на GPU.
- Конвертация из формата ONNX.
Этот список далеко не полный, и дополнять его хотелось бы с учетом мнения сообщества — потому жду ваших отзывов! Чтобы инструмент был полезным не только нашей компании, но и широкому кругу пользователей. Также автор не отказался бы от помощи сообщества в процессе разработки.
При описании Synet, которое я сделал в этой статье, я намеренно не углублялся в детали ее внутренней реализации — под капотом много вкусных алгоритмов, но детали их реализации хотелось бы раскрыть в следующих статьях цикла:
