Firebird является очень популярной открытой СУБД в России, и, несмотря на отсутствие шумных маркетинговых акций, используется в большом количестве ответственных систем, особенно в медицинских и государственных системах автоматизации.
Размер БД и количество активных пользователей в таких системах обычно достаточно большие, поэтому в этой статье я расскажу об опыте оптимизации настроек Firebird и Linux, основываясь на конкретных примерах больших БД Firebird в компаниях БудьЗдоров (Ингосстрах), АльфаЗдрав, и затрону опыт других компаний по оптимизации Firebird+Linux.
Давайте подробнее познакомимся с предметом оптимизации — СУБД Firebird 3.0.5 (с расширениями HQbird), обслуживает БД размером 691Гб (на текущий момент) с ежедневными 1000-1100 пользователями, работает на Linux CentOS 7, сервер — железный HP DL380. Для БД настроена репликация на резервный сервер (вопрос о репликации вне рамок этой статьи).
СУБД обслуживает медицинскую информационную систему Инфоклиника (производства российской компании Smart Delta Systems), которая является одной из самых популярных медицинских информационных систем в России.
Давайте взглянем на подробности (скриншоты далее взяты из HQbird) работы этой базы данных:
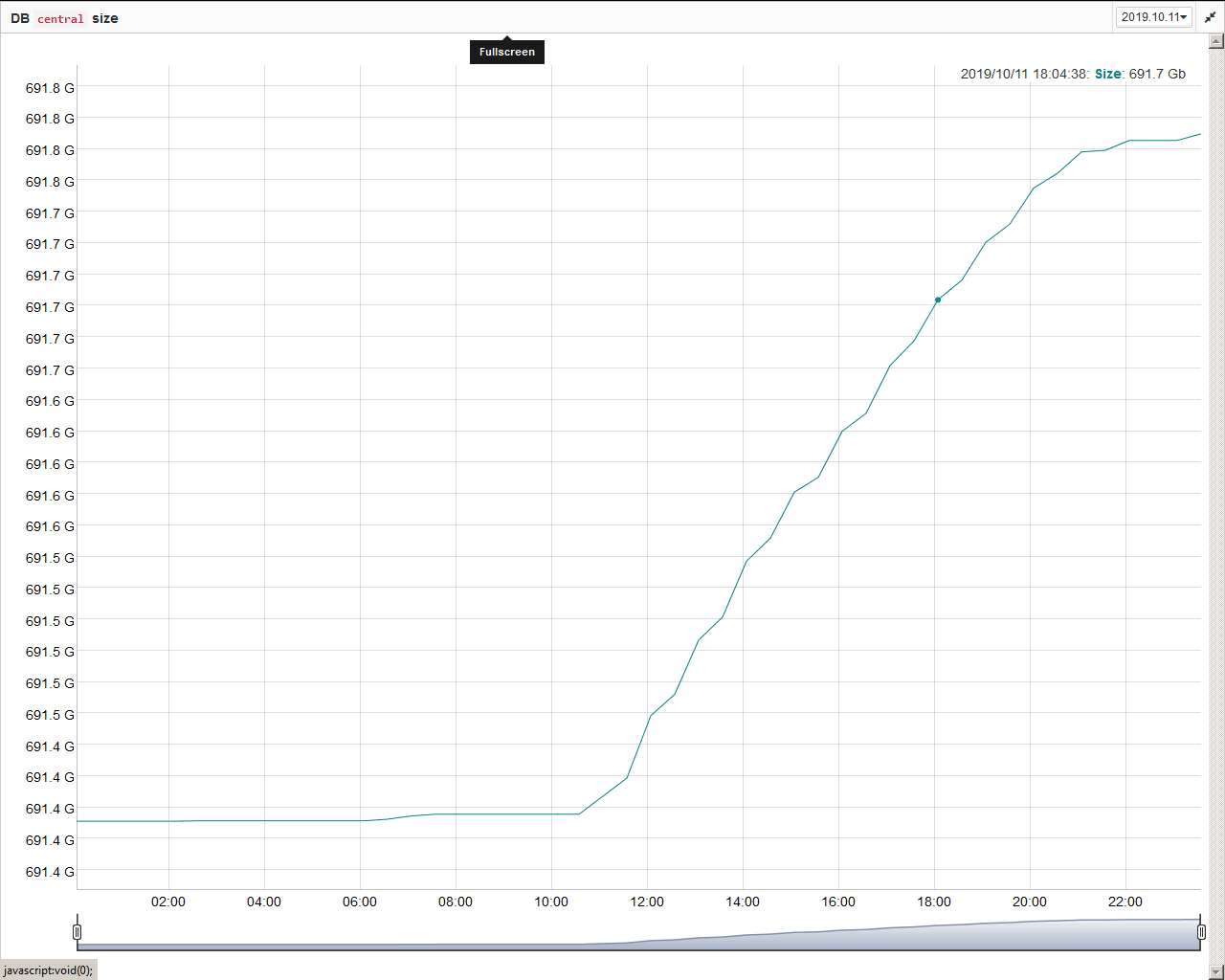
Данные интенсивно вставляются в БД — ежедневный прирост около 0.4 — 0.5 Гб
1000-1100 соединений это обычная дневная нагрузка:

Несмотря на интенсивный рост и активную работу, база данных не содержит сколько-нибудь значительного количества мусорных версий записей — как благодаря приложениям, написанным с хорошим знанием многоверсионной архитектуры, так и благодаря адекватно настроенной сборке мусора:

Маркеры транзакций в «зеленой» зоне:

Кстати, обратите внимание, что данные в БД — строковые, блобы присутствуют, но их мало — всего 10Гб из 690Гб общего размера.
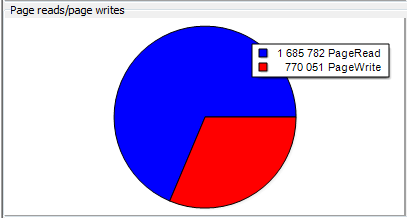
Характер нагрузки на БД смешанный, 75% операций чтения и 25% записи:
Сервер, который обслуживает эту систему, неплохой, но далеко не топовый:
Дисковая подсистема состоит из двух частей: локальный диск на 745Gb и двойной 2 fibre-channel connection к SAN, с разделом на 1.8Тб.
Используется CentOS 7, версия ядра:
На логичный вопрос, почему не используется самое современное ядро и CentOS 8, ответ тоже логичный — миграция ответственных систем происходит только после выпуска нескольких минорных релизов и тщательного тестирования — это один из тех случаев, когда известный баг лучше двух неизвестных.
Однако, надо отметить, что до 2017 года система работала на CentOS 6.x, и после миграции было отмечено значительное улучшение показателей производительности.
Есть 2 параметра, которые нужно обязательно увеличить на всех серверах Linux, где работает Firebird — число виртуальных областей памяти (virtual memory areas, VMA) и число открытых файлов для процесса Firebird.
1. VMA
Число VMA по умолчанию 64K, его необходимо увеличить в 4 раза, для этого в sysctl.conf надо добавить строку
Чтобы проверить текущее значение, используйте команду
2. Max Open Files
На каждое соединение к БД Firebird открывает до 20 описателей (файловых хэндлов) включительно (учитывая тот факт, что в Linux все ресурсы выглядят как файлы), поэтому максимальное количество открытых файлов по умолчанию (обычно 4096) может очень быстро исчерпаться.
Чтобы проверить доступное количество файлов для Firebird, лучше всего посмотреть лимиты исполняемого файла Firebird:
где проверить значение для Max Open Files и увеличить их при необходимости.
Чтобы увеличить параметр Max Open Files для Firebird, в файл firebird-superserver.service в секцию [service] мы добавили строку:
На этом сервере мы также сделали следующие настройки
1. Уменьшили swapiness
Так как сервер является выделенным эксклюзивно для СУБД Firebird, и мы желаем эффективно использовать RAM под кэш СУБД и кэш файлов операционной системы, то уменьшаем swapiness c дефолтных 60% до 10%, для этого в sysctl.conf добавили
2. Увеличили минимальный зарезервированный размер памяти для специальных процессов ОС
т. е. 1Гб памяти. Эта настройка косвенно влияет на дефрагментацию памяти.
Обратите внимание, что эта настройка индивидуальна — с учетом того, что у нас 320Гб RAM, 1Гб это не так уж и много, но в случае небольшого количества памяти (например, 32Гб), 1Гб мог бы быть перебором.
3. Уменьшили keepalive
Firebird полагается на keepalive интервалы, чтобы проверять состояние соединения, и по умолчанию значение keepalive может быть очень большим. Ограничивая его до 300 секунд, мы избавляемся от зависших соединений
Почему мы ограничились таким небольшим количество настроек Linux?
Во-первых, мы придерживаемся консервативного подхода к тюнингу серверов с Linux (который становится все лучше и лучше с каждой новой версией), во-вторых, эта база данных Firebird не является ни экстремально большой, ни самой нагруженной, и Linux с указанными настройками справляется со своими задачами.
Конечно, существует еще несколько настроек, которые можно использовать для оптимизации работы Firebird на Linux — например, ряд интересных вещей был представлен в презентации о 3 Тб базе данных Firebird (РедБаза) в Федеральной Службе Приставов.
Конфигурационные файлы коммьюнити дистрибутива Firebird с firebirdsql.org настроены очень консервативно, и на мало-мальски мощном сервере необходимо изменять конфигурационные файлы, а также тщательно выбирать используемую архитектуру (в Firebird 3.0 существует 2 вида подключения: Embedded и NetworkServer, и 3 вида архитектур: SuperServer, SuperClassic, Classic).
Также, необходимо использовать настройки для каждой БД — т.е. помещать критические настройки в databases.conf, с привязкой к конкретной базе данных.
В нашем случае выбрана архитектура SuperServer, наиболее популярная в версии 3.0, т.к. она эффективно использует многоядерные процессоры и имеет совместный для всех соединений кэш (но отдельный на каждую БД).
Ниже приведены конфигурационные файлы (только значения, относящиеся к производительности):
firebird.conf — конфигурационный файл для всех БД на сервере
С точки зрения производительности, ключевыми параметрами здесь являются следующие:
1. DefaultDbCachePages = 50K # измеряется в страницах, на БД, при странице 16К = 0.8Gb
Размер страничного кэша DefaultDbCachePages в firebird.conf специально установлен по умолчанию в 800Mb — для того, чтобы случайно затесавшаяся на сервере тестовая БД не попыталась занять огромное количество оперативной памяти.
2. FileSystemCacheThreshold = 300K # pages
Важно устанавливать этот параметр в значение большее, чем DefaultDBCachePages, чтобы разрешить использование файлового кэша ОС.
3. TempCacheLimit = 20480M # bytes
Это параметр устанавливает размер памяти для запросов с сортировками (и некоторыми другими операциями), и является индивидуальным для каждой системы.
В результате мониторинга размеров сортировок мы выяснили, что 20Гб является оптимальным для данной БД.
4. LockMemSize и LockHashSlots — параметры таблицы блокировок
Эти параметры определяют начальный размер таблицы блокировок и количество слотов для вычисления хэш функции.
5. WireCompression=True
Настройка сжимает трафик между клиентами и серверов, особенно это полезно при интенсивных Execute Statement On External, которые выполняет клиентское приложение.
Остальные параметры описаны в самом firebird.conf и сопутствующей документации Firebird и HQbird.
Наиболее важные настройки мы вынесли в databases.conf, с точным указанием БД
Как вы можете догадаться, основная сложность в данном случае состоит в том, как верно рассчитать размер памяти, выделяемой нашей большой БД.
Для Firebird 3.0 c архитектурой SuperServer существует два подхода — консервативный, который используется на серверах с небольшим количеством оперативной памяти (до 32Гб включительно), который заключается в том, чтобы выделять под страничный кэш не более 25% RAM, и в остальном полагаться на файловый операционной системы, и тонкая настройка, когда мы точно определяем оптимальный размер для сортировок, выделяем определенный размер памяти для ядра ОС, резервируем определенный объем памяти для массивных файловых операций (например, резервное копирование), и остаток выделяем на страничный кэш.
Во втором случае нет возможности сразу получить оптимальный размер кэша, т. к. характер нагрузки может сильно отличаться для разных типов БД, но после нескольких итераций можно добиться отличного результата.
К типичным ошибкам относятся следующие:
1) Явно указанный на странице заголовка БД размер страничного кэша, который переопределяет значения, указанные в firebird.conf и databases.conf.
Особенно часто эта ошибка возникает при смене архитектуры с Classic/SuperClassic на SuperServer — если при явно указанном небольшом (500-2000 страниц) размере кэша на соединение Classic/SuperClassic работают нормально, то для SuperServer необходим гораздо больший кэш.
Чтобы проверить, выполните команду
и проверьте значение
Для сброса установки страничного кэша на заголовочной странице выполните команду
2) При увеличении страничного кэша забывают увеличить FileSystemCacheThreshold, что ведет к отключению файлового кэша, что снижает производительность.
3) Использование размера страницы БД по умолчанию (4096 или 8192), в то время как для больших БД необходимо использовать 16К.
В целом, 1000+ пользователей Firebird на железе, соответствующем нагрузке, настроенном Linux и сконфигурированном Firebird, работают без проблем. На данном сервере по производительности есть запас, который был протестирован в пиках нагрузки до 1500-1800 пользователей.
Среди Linux-дистрибутивов для БД Firebird c подобной нагрузкой наиболее популярен CentOS 7, рекомендуемая версия — Firebird 3.0.
Если есть вопросы, буду рад ответить в комментариях, или по email ak@ibase.ru.
Размер БД и количество активных пользователей в таких системах обычно достаточно большие, поэтому в этой статье я расскажу об опыте оптимизации настроек Firebird и Linux, основываясь на конкретных примерах больших БД Firebird в компаниях БудьЗдоров (Ингосстрах), АльфаЗдрав, и затрону опыт других компаний по оптимизации Firebird+Linux.
Давайте подробнее познакомимся с предметом оптимизации — СУБД Firebird 3.0.5 (с расширениями HQbird), обслуживает БД размером 691Гб (на текущий момент) с ежедневными 1000-1100 пользователями, работает на Linux CentOS 7, сервер — железный HP DL380. Для БД настроена репликация на резервный сервер (вопрос о репликации вне рамок этой статьи).
СУБД обслуживает медицинскую информационную систему Инфоклиника (производства российской компании Smart Delta Systems), которая является одной из самых популярных медицинских информационных систем в России.
Давайте взглянем на подробности (скриншоты далее взяты из HQbird) работы этой базы данных:
Данные интенсивно вставляются в БД — ежедневный прирост около 0.4 — 0.5 Гб
1000-1100 соединений это обычная дневная нагрузка:
Несмотря на интенсивный рост и активную работу, база данных не содержит сколько-нибудь значительного количества мусорных версий записей — как благодаря приложениям, написанным с хорошим знанием многоверсионной архитектуры, так и благодаря адекватно настроенной сборке мусора:
Маркеры транзакций в «зеленой» зоне:
Кстати, обратите внимание, что данные в БД — строковые, блобы присутствуют, но их мало — всего 10Гб из 690Гб общего размера.
Характер нагрузки на БД смешанный, 75% операций чтения и 25% записи:
Железо
Сервер, который обслуживает эту систему, неплохой, но далеко не топовый:
HP ProLiant DL380p Gen8, Gen8 2x Xeon(R) CPU E5v2 @ 2.60GHz, 24 logical cores with HT
320Gb RAM, 4 network cardsДисковая подсистема состоит из двух частей: локальный диск на 745Gb и двойной 2 fibre-channel connection к SAN, с разделом на 1.8Тб.
Операционная система
Используется CentOS 7, версия ядра:
Linux version 3.10.0-957.21.3.el7.x86_64 (mockbuild@kbuilder.bsys.centos.org) (gcc version 4.8.5 20150623 (Red Hat 4.8.5-36) (GCC) ) #1 SMP Tue Jun 18 16:35:19 UTC 2019
На логичный вопрос, почему не используется самое современное ядро и CentOS 8, ответ тоже логичный — миграция ответственных систем происходит только после выпуска нескольких минорных релизов и тщательного тестирования — это один из тех случаев, когда известный баг лучше двух неизвестных.
Однако, надо отметить, что до 2017 года система работала на CentOS 6.x, и после миграции было отмечено значительное улучшение показателей производительности.
Настройка Linux
Абсолютно необходимая настройка Linux для Firebird
Есть 2 параметра, которые нужно обязательно увеличить на всех серверах Linux, где работает Firebird — число виртуальных областей памяти (virtual memory areas, VMA) и число открытых файлов для процесса Firebird.
1. VMA
Число VMA по умолчанию 64K, его необходимо увеличить в 4 раза, для этого в sysctl.conf надо добавить строку
vm.max_map_count=262144Чтобы проверить текущее значение, используйте команду
sysctl vm.max_map_count2. Max Open Files
На каждое соединение к БД Firebird открывает до 20 описателей (файловых хэндлов) включительно (учитывая тот факт, что в Linux все ресурсы выглядят как файлы), поэтому максимальное количество открытых файлов по умолчанию (обычно 4096) может очень быстро исчерпаться.
Чтобы проверить доступное количество файлов для Firebird, лучше всего посмотреть лимиты исполняемого файла Firebird:
cat /proc/$(pgrep firebird)/limitsгде проверить значение для Max Open Files и увеличить их при необходимости.
Чтобы увеличить параметр Max Open Files для Firebird, в файл firebird-superserver.service в секцию [service] мы добавили строку:
LimitNOFILE=49999Опциональная настройка Linux
На этом сервере мы также сделали следующие настройки
1. Уменьшили swapiness
Так как сервер является выделенным эксклюзивно для СУБД Firebird, и мы желаем эффективно использовать RAM под кэш СУБД и кэш файлов операционной системы, то уменьшаем swapiness c дефолтных 60% до 10%, для этого в sysctl.conf добавили
vm.swappiness=102. Увеличили минимальный зарезервированный размер памяти для специальных процессов ОС
vm.min_free_kbytes=1048576т. е. 1Гб памяти. Эта настройка косвенно влияет на дефрагментацию памяти.
Обратите внимание, что эта настройка индивидуальна — с учетом того, что у нас 320Гб RAM, 1Гб это не так уж и много, но в случае небольшого количества памяти (например, 32Гб), 1Гб мог бы быть перебором.
3. Уменьшили keepalive
Firebird полагается на keepalive интервалы, чтобы проверять состояние соединения, и по умолчанию значение keepalive может быть очень большим. Ограничивая его до 300 секунд, мы избавляемся от зависших соединений
net.ipv4.tcp_keepalive_time=300
net.ipv4.tcp_keepalive_probes=5
net.ipv4.tcp_keepalive_intvl=15Еще больше тюнинга Linux
Почему мы ограничились таким небольшим количество настроек Linux?
Во-первых, мы придерживаемся консервативного подхода к тюнингу серверов с Linux (который становится все лучше и лучше с каждой новой версией), во-вторых, эта база данных Firebird не является ни экстремально большой, ни самой нагруженной, и Linux с указанными настройками справляется со своими задачами.
Конечно, существует еще несколько настроек, которые можно использовать для оптимизации работы Firebird на Linux — например, ряд интересных вещей был представлен в презентации о 3 Тб базе данных Firebird (РедБаза) в Федеральной Службе Приставов.
Настройка Firebird
Конфигурационные файлы коммьюнити дистрибутива Firebird с firebirdsql.org настроены очень консервативно, и на мало-мальски мощном сервере необходимо изменять конфигурационные файлы, а также тщательно выбирать используемую архитектуру (в Firebird 3.0 существует 2 вида подключения: Embedded и NetworkServer, и 3 вида архитектур: SuperServer, SuperClassic, Classic).
Также, необходимо использовать настройки для каждой БД — т.е. помещать критические настройки в databases.conf, с привязкой к конкретной базе данных.
В нашем случае выбрана архитектура SuperServer, наиболее популярная в версии 3.0, т.к. она эффективно использует многоядерные процессоры и имеет совместный для всех соединений кэш (но отдельный на каждую БД).
Ниже приведены конфигурационные файлы (только значения, относящиеся к производительности):
firebird.conf — конфигурационный файл для всех БД на сервере
DefaultDbCachePages = 50K # pages
FileSystemCacheThreshold = 300K # pages
TempBlockSize = 2M # bytes
TempCacheLimit = 20480M # bytes
LockMemSize = 30M # bytes
LockHashSlots = 30011
WireCompression = true
ServerMode = Super
ExtConnPoolSize = 500 # HQBird
ExtConnPoolLifeTime = 14200 # HQBird
SortDataStorageThreshold = 8192 #HQbird reports queriesС точки зрения производительности, ключевыми параметрами здесь являются следующие:
1. DefaultDbCachePages = 50K # измеряется в страницах, на БД, при странице 16К = 0.8Gb
Размер страничного кэша DefaultDbCachePages в firebird.conf специально установлен по умолчанию в 800Mb — для того, чтобы случайно затесавшаяся на сервере тестовая БД не попыталась занять огромное количество оперативной памяти.
2. FileSystemCacheThreshold = 300K # pages
Важно устанавливать этот параметр в значение большее, чем DefaultDBCachePages, чтобы разрешить использование файлового кэша ОС.
3. TempCacheLimit = 20480M # bytes
Это параметр устанавливает размер памяти для запросов с сортировками (и некоторыми другими операциями), и является индивидуальным для каждой системы.
В результате мониторинга размеров сортировок мы выяснили, что 20Гб является оптимальным для данной БД.
4. LockMemSize и LockHashSlots — параметры таблицы блокировок
Эти параметры определяют начальный размер таблицы блокировок и количество слотов для вычисления хэш функции.
5. WireCompression=True
Настройка сжимает трафик между клиентами и серверов, особенно это полезно при интенсивных Execute Statement On External, которые выполняет клиентское приложение.
Остальные параметры описаны в самом firebird.conf и сопутствующей документации Firebird и HQbird.
Наиболее важные настройки мы вынесли в databases.conf, с точным указанием БД
database1 = /data/database1.fdb {
DefaultDbCachePages = 14080K # 16K pages, 220 GB
FileSystemCacheThreshold = 15361K
TempSpaceCacheThreshold=2G #HQbird only, track big sorts
LockHashSlots = 40099
LockMemSize = 50M
}Как вы можете догадаться, основная сложность в данном случае состоит в том, как верно рассчитать размер памяти, выделяемой нашей большой БД.
Для Firebird 3.0 c архитектурой SuperServer существует два подхода — консервативный, который используется на серверах с небольшим количеством оперативной памяти (до 32Гб включительно), который заключается в том, чтобы выделять под страничный кэш не более 25% RAM, и в остальном полагаться на файловый операционной системы, и тонкая настройка, когда мы точно определяем оптимальный размер для сортировок, выделяем определенный размер памяти для ядра ОС, резервируем определенный объем памяти для массивных файловых операций (например, резервное копирование), и остаток выделяем на страничный кэш.
Во втором случае нет возможности сразу получить оптимальный размер кэша, т. к. характер нагрузки может сильно отличаться для разных типов БД, но после нескольких итераций можно добиться отличного результата.
Типичные ошибки в настройке Firebird
К типичным ошибкам относятся следующие:
1) Явно указанный на странице заголовка БД размер страничного кэша, который переопределяет значения, указанные в firebird.conf и databases.conf.
Особенно часто эта ошибка возникает при смене архитектуры с Classic/SuperClassic на SuperServer — если при явно указанном небольшом (500-2000 страниц) размере кэша на соединение Classic/SuperClassic работают нормально, то для SuperServer необходим гораздо больший кэш.
Чтобы проверить, выполните команду
gstat -h databasepathnameи проверьте значение
Page Buffers — оно должно быть равно 0, тогда Firebird будет использовать значения из databases.conf или firebird.conf. Для сброса установки страничного кэша на заголовочной странице выполните команду
gfix -buff 0 databasepathname2) При увеличении страничного кэша забывают увеличить FileSystemCacheThreshold, что ведет к отключению файлового кэша, что снижает производительность.
3) Использование размера страницы БД по умолчанию (4096 или 8192), в то время как для больших БД необходимо использовать 16К.
Заключение
В целом, 1000+ пользователей Firebird на железе, соответствующем нагрузке, настроенном Linux и сконфигурированном Firebird, работают без проблем. На данном сервере по производительности есть запас, который был протестирован в пиках нагрузки до 1500-1800 пользователей.
Среди Linux-дистрибутивов для БД Firebird c подобной нагрузкой наиболее популярен CentOS 7, рекомендуемая версия — Firebird 3.0.
Если есть вопросы, буду рад ответить в комментариях, или по email ak@ibase.ru.
