If you utilize Apache Spark, you probably have a few applications that consume some data from external sources and produce some intermediate result, that is about to be consumed by some applications further down the processing chain, and so on until you get a final result.
We suspect that because we have a similar pipeline with lots of processes like this one:

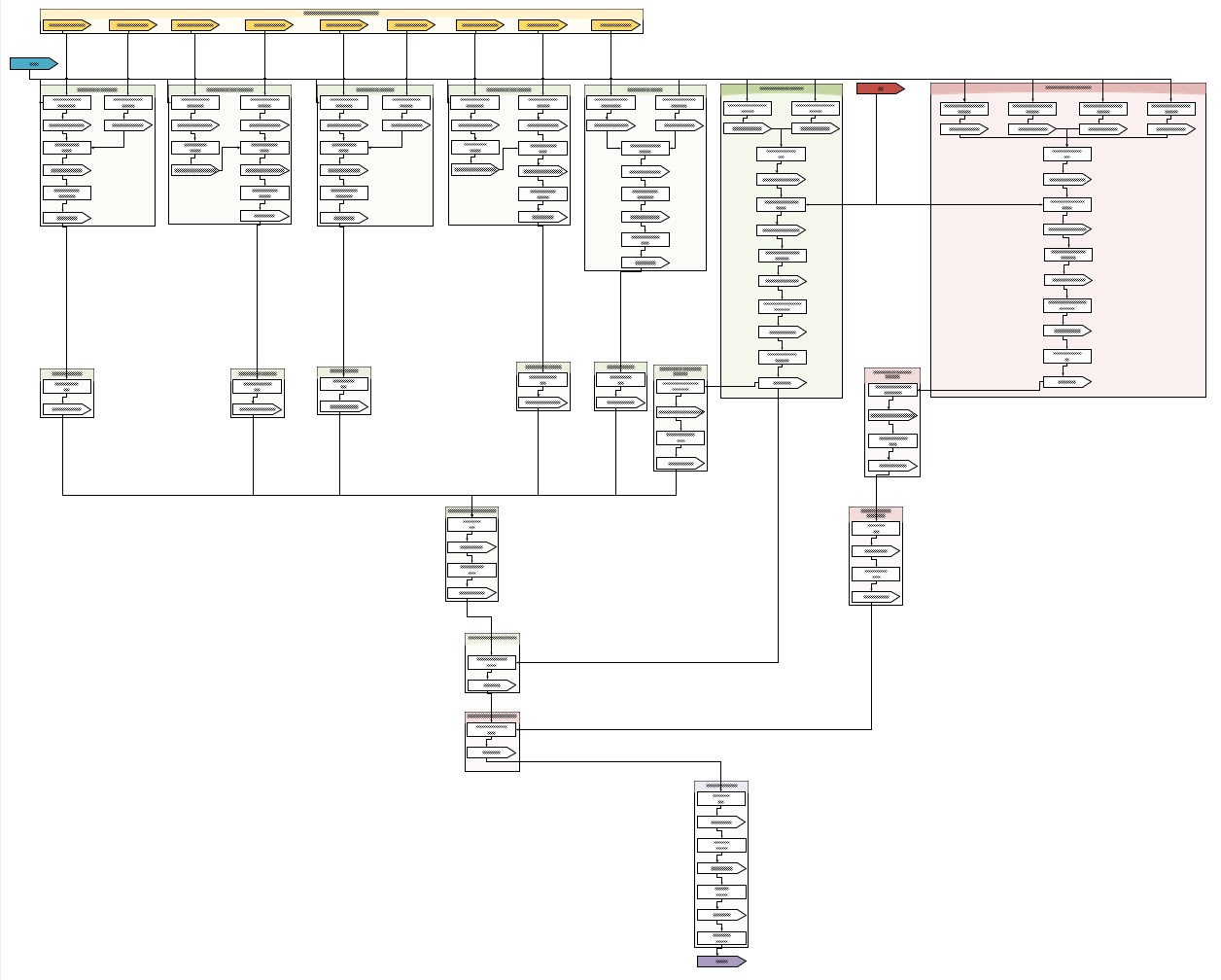
Click here for a bit larger version
Each rectangle is a Spark application with a set of their own execution parameters, and each arrow is an equally parametrized dataset (externally stored highlighted with a color; note the number of intermediate ones). This example is not the most complex of our processes, it’s fairly a simple one. And we don’t assemble such workflows manually, we generate them from Process Templates (outlined as groups on this flowchart).
So here comes the One Ring, a Spark pipelining framework with very robust configuration abilities, which makes it easier to compose and execute a most complex Process as a single large Spark job.
And we just made it open source. Perhaps, you’re interested in the details.
Let we speak about Spark applications. This document explains how to use...
- One Ring to unify them all,
- One Ring to unite them,
- One Ring to bind them all
- And in the Clouds run them
...in parametrized chains.
Each Application in terms of One Ring is an Operation — an entity with its own configuration space and input / output data streams, described with a minimal set of metadata. That abstraction allows a developer to flexibly compose complex process pipelines from a set of standard subroutines without writing more glue code, just a simple configuration in DSL. Or even generate a very complex ones from shorter Template fragments.
Let us start with a description how to build and extend One Ring, then proceed to configuration and composition stuff.
One Ring to unify them all
To build One Ring you need Apache Maven, version 3.5 or higher.
Make sure you've cloned this repo with all submodules:
git clone --recursive https://github.com/PastorGL/OneRing.git
One Ring CLI
If you're planning to compute on an EMR cluster, just cd to OneRing directory and execute Maven in the default profile:
mvn clean package
The ./TaskWrapper/target/one-ring-cli.jar is a fat executable JAR targeted at the Spark environment provided by EMR version 5.23.0.
If you're planning to build a local artifact with full Spark built-in, execute build in 'local' profile:
mvn clean package -Plocal
Make sure the resulting JAR is about ~100 MB in size.
It isn't recommended to skip tests in the build process, but if you're running Spark locally on your build machine, you could add -DskipTests to Maven command line, because they will interfere.
After you've built your CLI artifact, look into './RESTWrapper/docs' for the automatically generated documentation of available Packages and Operations (in Markdown format).
One Ring Dist
The ./DistWrapper/target/one-ring-dist.jar is a fat executable JAR that generates Hadoop's dist-cp or EMR's s3-dist-cp script to copy the source data from the external storage (namely, S3) to cluster's internal HDFS, and the computation's result back.
It is an optional component, documented a bit later.
One Ring REST
The ./RESTWrapper/target/one-ring-rest.jar is a fat executable JAR that serves a REST-ish back-end for the not-yet-implemented but much wanted Visual Template Editor. It also serves the docs via dedicated endpoint.
One Ring is designed with extensibility in mind.
Extend Operations
To extend One Ring built-in set of Operations, you have to implement an Operation class according to a set of conventions described in this doc.
First off, you should create a Maven module. Place it at the same level as root pom.xml, and include your module in root project's <modules> section. You can freely choose the group and artifact IDs you like.
To make One Ring know your module, include its artifact reference in TaskWrapper's pom.xml <dependencies>. To make your module know One Ring, include a reference of artifact 'ash.nazg:Commons' in your module's <dependencies> (and its test-jar scope too). For an example, look into Math's pom.xml.
Now you can proceed to create an Operation package and describe it.
By convention, Operation package must be named your.package.name.operations and have package-info.java annotated with @ash.nazg.config.tdl.Description. That annotation is required by One Ring to recognize the contents of your.package.name. There's an example.
Place all your Operations there.
If your module contains a number of Operation that share same Parameter Definitions, names of these parameters must be placed in a public final class your.package.name.config.ConfigurationParameters class as public static final String constants with same @Description annotation each. An Operation can define its own parameters inside its class following the same convention.
Parameter Definitions and their default value constants have names, depending on their purpose:
DS_INPUT_for input DataStream references,DS_OUTPUT_for output DataStream references,OP_for the operation's Parameter,DEF_for any default value, and the rest of the name should match a correspondingOP_orDS_,GEN_for any column, generated by this Operation.
References to columns of input DataStreams must end with _COLUMN suffix, and to column lists with _COLUMNS.
An Operation in essence is
public abstract class Operation implements Serializable { public abstract Map<String, JavaRDDLike> getResult(Map<String, JavaRDDLike> input) throws Exception; }
...but enlightened with a surplus metadata that allows One Ring to flexibly configure it, and to ensure the correctness and consistency of all Operation configurations in the Process chain.
It is up to you, the author, to provide all that metadata. In the lack of any required metadata the build will be prematurely failed by One Ring Guardian, so incomplete class won't fail your extended copy of One Ring CLI on your Process execution time.
At least, you must implement the following methods:
abstract public String verb()that returns a short symbolic name to reference your Operation instance in the config file, annotated with a@Description,abstract public TaskDescriptionLanguage.Operation description()that defines Operation's entire configuration space in TDL2 (Task Description Language),- the
getResult()that contains an entry point of your business code. It'll be fed with all DataStreams accumulated by the current Process at the moment of your Operation invocation, and should return any DataStreams your Operation should emit.
Also you must override public void setConfig(OperationConfig config) throws InvalidConfigValueException, call its super() at the beginning, and then read all parameters from the configuration space to your Operation class' fields. If any of the parameters have invalid value, you're obliged to throw an InvalidConfigValueException with a descriptive message about the configuration mistake.
You absolutely should create a test case for your Operation. See existing tests for a reference.
There is a plenty of examples to learn by, just look into the source code for Operation's descendants. For your convenience, there's a list of most notable ones:
- FilterByDateOperation with lots of parameters of different types that have defaults,
- SplitByDateOperation — its sister Operation generates a lot of output DataStreams with wildcard names,
- DummyOperation — this one properly does nothing, just creates aliases for its input DataStreams,
- SubtractOperation can consume and emit both RDDs and PairRDDs as DataStreams,
- WeightedSumOperation generates a lot of columns that either come from input DataStreams or are created anew,
- and the package Proximity contains Operations that deal with Point and Polygon RDDs in their DataStreams.
Extend Storage Adapters
To extend One Ring with a custom Storage Adapter, you have to implement a pair of InputAdapter and OutputAdapter interfaces. They're fairly straightforward, just see existing Adapter sources for the reference.
For example, you could create an Adapter for Spark 'parquet' files instead of CSV if you have your source data stored that way.
A single restriction exists: you can't set your Adapter as a fallback one, as that is reserved to One Ring Hadoop Adapter.
Hopefully this bit of information is enough for the beginning.
One Ring to bind them
Now entering the configuration space.
There is a domain specific language named TDL3 that stands for One Ring Task Definition Language. (There also are DSLs named TDL1 and TDL2, but they're fairly subtle.)
For the language's object model, see TaskDefinitionLanguage.java. Note that the main form intended for human use isn't JSON but a simple non-sectioned .ini (or Java's .properties) file. We refer to this file as tasks.ini, or just a config.
A recommended practice is to write keys in paragraphs grouped for each Operation, preceded by its Input DataStreams and succeeded by Output DataStreams groups of keys.
Namespace Layers
As you could see, each key begins with a prefix spark.meta.. One Ring can (and first tries to) read its configuration directly from Spark context, not only a config file, and each Spark property must start with a spark. prefix. We add another prefix meta. (by convention; this can be any unique token of your choice) to distinguish our own properties from Spark's. Also a single tasks.ini may contain a number of Processes if properly prefixed, just start their keys with spark.process1_name., spark.another_process. and so on.
If you run One Ring in Local mode, you can supply properties via .ini file, and omit all prefixes. Let assume that we've stripped all Spark's prefixes in mind and now look directly into namespaces of keys.
The config is layered into several namespaces, and all parameter names must be unique in the corresponding namespace. These layers are distinguished, again, by some prefix.
Foreign Layers
First namespace layer is One Ring DistWrapper's distcp. which instructs that utility to generate a script file for the dist-cp calls:
distcp.wrap=both distcp.exe=s3-dist-cp
Let us discuss it a bit later. CLI itself ignores all foreign layers.
Variables
If a key or a value contains a token of the form {ALL_CAPS}, it'll be treated by the CLI as a configuration Variable, and will be replaced by the value supplied via command line or variables file.
ds.input.part_count.signals={PARTS}
If the Variable's value wasn't supplied, no replacement will be made, unless the variable doesn't include a default value for itself in the form of {ALL_CAPS:any default value}. Default values may not contain the '}' symbol.
ds.input.part_count.signals={PARTS:50}
There are a few other restrictions to default values. First, each Variable occurrence has a different default and does not carry one over entire config, so you should set them each time you use that Variable. Second, if a Variable after a replacement forms a reference to another Variable, it will not be processed recursively. We do not like to build a Turing-complete machine out of tasks.ini.
It is notable that Variables may be encountered at any side of = in the tasks.ini lines, and there is no limit of them for a single line and/or config file.
CLI Task of the Process
Next layer is task., and it contains properties that configure the CLI itself for the current Process' as a Spark job, or a CLI Task.
task.operations=range_filter,accuracy_filter,h3,timezone,center_mass_1,track_type,type_other,track_type_filter,remove_point_type,iron_glitch,slow_motion,center_mass_2,aqua2,map_by_user,map_tracks_non_pedestrian,map_pedestrian,map_aqua2,count_by_user,count_tracks_non_pedestrian,count_pedestrian,count_aqua2 task.input.sink=signals task.tee.output=timezoned,tracks_non_pedestrian,pedestrian,aqua2,count_by_user,count_tracks_non_pedestrian,count_pedestrian,count_aqua2
task.operations (required) is a comma-separated list of Operation names to execute in the specified order. Any number of them, but not less than one. Names must be unique.
task.input.sink (required too) is an input sink. Any DataStream referred here is considered as one sourced from outside storage, and will be created by Storage Adapters of CLI (discussed later) for the consumption of Operations.
task.tee.output (also required) is a T-connector. Any DataStream referred here can be consumed by Operations as usual, but also will be diverted by Storage Adapters of CLI into the outside storage as well.
Operation Instances
Operations share the layer op., and it has quite a number of sub-layers.
Operation of a certain name is a certain Java class, but we don't like to call Operations by fully-qualified class names, and ask them nicely how they would like to be called by a short name.
So, you must specify such short names for each of your Operations in the chain, for example:
op.operation.range_filter=rangeFilter op.operation.accuracy_filter=accuracyFilter op.operation.h3=h3 op.operation.timezone=timezone op.operation.center_mass_1=trackCentroidFilter op.operation.track_type=trackType op.operation.map_by_user=mapToPair op.operation.map_pedestrian=mapToPair op.operation.count_pedestrian=countByKey op.operation.count_aqua2=countByKey
You see that you may have any number of calls of the same Operation class in your Process, they'll be all initialized as independent instances with different reference names.
Operation Inputs and Outputs
Now we go down to Operations' namespace op. sub-layers.
First is op.input. that defines which DataStreams an Operation is about to consume as named. They names are assigned by the Operation itself internally. Also, an Operation could decide to process an arbitrary number (or even wildcard) DataStreams, positioned in the order specified by op.inputs. layer.
Examples from the config are:
op.inputs.range_filter=signals op.input.accuracy_filter.signals=range_accurate_signals op.inputs.h3=accurate_signals op.inputs.timezone=AG op.input.center_mass_1.signals=timezoned op.input.track_type.signals=if_step1 op.inputs.type_other=tracks
Note that the keys end with just a name of an Operation in the case of positional Inputs, or 'name of an Operation' + '.' + 'its internal name of input' for named ones. These layers are mutually exclusive for a given Operation.
All the same goes for the op.output. and op.outputs. layers that describe DataStreams an Operation is about to produce. Examples:
op.outputs.range_filter=range_accurate_signals op.output.accuracy_filter.signals=accurate_signals op.outputs.h3=AG op.outputs.timezone=timezoned op.output.center_mass_1.signals=if_step1 op.output.track_type.signals=tracks op.outputs.type_other=tracks_non_pedestrian op.output.track_type_filter.signals=pedestrian_typed
A wildcard DataStream reference is defined like:
op.inputs.union=prefix*
It'll match all DataStreams with said prefix available at the point of execution, and will be automatically converted into a list with no particular order.
Parameters of Operations
Next sub-layer is for Operation Parameter Definitions, op.definition.. Parameters names take the rest of op.definition. keys. And the first prefix of Parameter name is the name of the Operation it is belonging to.
Each Parameter Definition is supplied to CLI by the Operation itself via TDL2 interface (Task Description Language), and they are strongly typed. So they can have a value of any Number descendant, String, enums, String[] (as a comma-separated list), and Boolean types.
Some Parameters may be defined as optional, and in that case they have a default value.
Some Parameters may be dynamic, in that case they have a fixed prefix and variable ending.
Finally, there is a variety of Parameters that refer specifically to columns of input DataStreams. Their names must end in .column or .columns by the convention, and values must refer to a valid column or list of columns, or to one of columns generated by the Operation. By convention, generated column names start with an underscore.
Look for some examples:
op.definition.range_filter.filtering.column=signals.accuracy op.definition.range_filter.filtering.range=[0 50] op.definition.h3.hash.level=9 op.definition.timezone.source.timezone.default=GMT op.definition.timezone.destination.timezone.default={TZ} op.definition.timezone.source.timestamp.column=AG.timestamp op.definition.type_other.match.values=car,bike,non_residential,extremely_large op.definition.track_type_filter.target.type=pedestrian op.definition.track_type_filter.stop.time=900 op.definition.track_type_filter.upper.boundary.stop=0.05 op.definition.map_pedestrian.key.columns=pedestrian.userid,pedestrian.dow,pedestrian.hour op.definition.map_aqua2.key.columns=aqua2.userid,aqua2.dow,aqua2.hour
Parameter filering.column of an Operation named range_filter points to the column accuracy from the DataStream signals, as well as source.timestamp.column of timezone is a reference to AG column timestamp. And map_pedestrian's key.columns refers to list of pedestrian columns.
Parameter hash.level of h3 is of type Byte, type_other's match.values is String[], and track_type_filter's upper.boundary.stop is Double.
To set an optional Parameter to its default value, you may omit that key altogether, or, if you like completeness, comment it out:
#op.definition.another_h3.hash.level=9
For the exhaustive table of each Operation Parameters, look for the docs inside your 'RESTWrapper/docs' directory (assuming you've successfully built the project, otherwise it'll be empty).
Parameters of DataStreams
Next layer is the ds. configuration namespace of DataStreams, and its rules are quite different.
First off, DataStreams are always typed. There are types of:
CSV(column-basedTextRDD with freely defined, but strongly referenced columns)Fixed(CSV, but column order and format is considered fixed)Point(object-based, contains Point coordinates with metadata)Polygon(object-based, contains Polygon outlines with metadata)KeyValue(PairRDD with an opaque key and column-based value likeCSV)Plain(RDD is generated by CLI as just opaque HadoopText, or it can be a custom-typed RDD handled by Operation)
Each DataStream can be configured as input for a number of Operations, and as an output of only one of them.
DataStream name is always the last part of any ds. key. And the set of DataStream Parameters is fixed.
ds.input.path. keys must point to some abstract paths for all DataStreams listed under the task.input.sink key. The format of the path must always include the protocol specification, and is validated by a Storage Adapter of the CLI (Adapters are discussed in the last section of this document).
For example, for a DataStream named 'signals' there is a path recognized by the S3 Direct Adapter:
ds.input.path.signals=s3d://{BUCKET_NAME}/key/name/with/{a,the}/mask*.spec.?
Notice the usage of glob expressions. '{a,the}' token won't be processed as a Variable, but it is expanded to list of 'a' and 'the' directories inside '/key/name/with' directory by Adapter.
Same true for ds.output.path. keys, that must be specified for all DataStreams listed under the task.tee.output key. Let divert DataStream 'scores' to Local filesystem:
ds.output.path.scores={OUTPUT_PATH:file:/tmp/testing}/scores
But you may cheat here. There are all-input and all-output default keys:
ds.input.path=jdbc:SELECT * FROM scheme. ds.output.path=aero:output/
In that case, for each DataStream that doesn't have its own path, its name will be added to the end of corresponding cheat key value without a separator. We don't recommend usage of these cheat keys in the production environment.
ds.input.columns. and ds.output.columns. layers define columns for column-based DataStreams or metadata properties for object-based ones. Column names must be unique for that particular DataStream.
Output columns must always refer to valid columns of inputs passed to the Operation that emits said DataStream, or its generated columns (which names start with an underscore).
Input columns list just assigns new column names for all consuming Operations. It may contain a single underscore instead of some column name to make that column anonymous. Anyways, if a column is 'anonymous', it still may be referenced by its number starting from _1_.
There is an exhaustive example of all column definition rules:
ds.input.columns.signals=userid,lat,lon,accuracy,idtype,timestamp ds.output.columns.AG=accurate_signals.userid,accurate_signals.lat,accurate_signals.lon,accurate_signals.accuracy,accurate_signals.idtype,accurate_signals.timestamp,_hash ds.input.columns.AG=userid,lat,lon,accuracy,idtype,timestamp,gid ds.output.columns.timezoned=AG.userid,AG.lat,AG.lon,AG.accuracy,AG.idtype,AG.timestamp,_output_date,_output_year_int,_output_month_int,_output_dow_int,_output_day_int,_output_hour_int,_output_minute_int,AG.gid ds.input.columns.timezoned=userid,lat,lon,accuracy,idtype,timestamp,date,year,month,dow,day,hour,minute,gid ds.output.columns.tracks=if_step1.userid,if_step1.lat,if_step1.lon,if_step1.accuracy,_velocity,if_step1.timestamp,if_step1.date,if_step1.year,if_step1.month,if_step1.dow,if_step1.day,if_step1.hour,if_step1.minute,if_step1.gid,_track_type ds.input.columns.tracks=userid,lat,lon,_,_,_,_,_,_,_,_,_,_,_,track_type ds.output.columns.pedestrian_typed=if_step1.userid,if_step1.lat,if_step1.lon,if_step1.accuracy,if_step1.velocity,if_step1.timestamp,if_step1.date,if_step1.year,if_step1.month,if_step1.dow,if_step1.day,if_step1.hour,if_step1.minute,if_step1.gid,_point_type ds.input.columns.pedestrian_typed=_,_,_,_,_,_,_,_,_,_,_,_,_,_,point_type ds.output.columns.pedestrian=pedestrian_typed._1_,pedestrian_typed._2_,pedestrian_typed._3_,pedestrian_typed._4_,pedestrian_typed._5_,pedestrian_typed._6_,pedestrian_typed._7_,pedestrian_typed._8_,pedestrian_typed._9_,pedestrian_typed._10_,pedestrian_typed._11_,pedestrian_typed._12_,pedestrian_typed._13_,pedestrian_typed._14_ ds.input.columns.pedestrian=userid,lat,lon,_,_,timestamp,_,_,_,_,_,_,_,_
In CSV varieties of DataStreams, columns are separated by a separator character, so there are ds.input.separator. and ds.output.separator. layers, along with cheat keys ds.input.separator and ds.output.separator that set them globally. The super global default value of column separator is the tabulation (TAB, 0x09) character.
The final ds. layers control the partitioning of DataStream underlying RDDs, namely, ds.input.part_count. and ds.output.part_count.. These are quite important because the only super global default value for the part count is always 1 (one) part, and no cheats are allowed. You must always set them for at least initial input DataStreams from task.input.sink list, and may tune the partitioning in the middle of the Process according to the further flow of the Task.
If both part_count. are specifies for some intermediate DataStream, it will be repartitioned first to the output one (immediately after the Operation that generated it), and then to input one (before feeding it to the first consuming Operation). Please keep that in mind.
Storage Adapters
Input DataStreams of an entire Process come from the outside world, and output DataStreams are stored somewhere outside. CLI does this job via its Storage Adapters.
There are following Storage Adapters currently implemented:
- Hadoop (fallback, uses all protocols available in your Spark environment, i.e. 'file:', 's3:')
- HDFS (same Hadoop, but just for 'hdfs:' protocol)
- S3 Direct (any S3-compatible storage with a protocol of 's3d:')
- Aerospike ('aero:')
- JDBC ('jdbc:')
The fallback Hadoop Adapter is called if and only if another Adapter doesn't recognize the protocol of the path, so the priority of 'hdfs:' protocol is higher than other platform-supplied ones.
Storage Adapters share two namesake layers of input. and output., and all their Parameters are global.
Hadoop Adapter has no explicit Parameters. So does HDFS Adapter.
S3 Direct uses standard Amazon S3 client provider and has only the Parameter for output:
output.content.typewith a default of 'text/csv'
JDBC Adapter Parameters are:
input.jdbc.driverandoutput.jdbc.driverfor fully qualified class names of driver, available in the classpath. No default.input.jdbc.urlandoutput.jdbc.urlfor connection URLs. No default.input.jdbc.userandoutput.jdbc.userwith no default.input.jdbc.passwordandoutput.jdbc.passwordwith no default.output.jdbc.batch.sizefor output batch size, default is '500'.
Aerospike Adapter Parameters are:
input.aerospike.hostandoutput.aerospike.hostdefaults to 'localhost'.input.aerospike.portandoutput.aerospike.portdefaults to '3000'.
This concludes the configuration of One Ring CLI for a single Process. After you've assembled a library of basic Processes, you'll may want to know how to Compose them into larger workflows.
One Ring to unite them
There is an utility in the CLI to merge (or Compose) two or more One Ring Process Templates into one larger Template.
This action is final and should be performed only when the pipeline of all participating Processes is fully established, as it mangles most of named entities from the composed tasks.inis and emits a much less readable config.
Name mangling is necessary because tasks.ini from different Processes may contain Operations and DataStreams with same names, and we want to avoid reference clashes. DataStreams may persist they names and carry over the resulting config, though.
Command line invocation of Composer is as follows (also available via REST):
java -cp ./TaskWrapper/target/one-ring-cli.jar ash.nazg.composer.Composer -X spark.meta -C "/path/to/process1.ini=alias1,/path/to/process2.ini=alias2" -o /path/to/process1and2.ini -M /path/to/mapping.file -v /path/to/variables.file -F
-C parameter is a list of config files path=alias pairs, separated by a comma. Order of Operations in the resulting config follows the order of this list. Source configs may be in .ini and JSON formats, and even freely mixed, just use .json extension for JSON configs.
-X lists task prefix(es), if they're present. If each is different, specify them all in a comma-separated list. If all are the same, specify it only once. If there are no prefixes, just omit this switch.
-V same as CLI: name=value pairs of Variables for all configs, separated by a newline and encoded to Base64.
-v same as CLI: path to variables file, name=value pairs per each line.
-M path to a DataStream mapping file used to pass DataStreams from one Process to other(s).
The syntax of that file is like this:
alias1.name1 alias2.name1 alias1.name2 alias2.name5 alias3.name8
This example's first line means that the DataStream 'name1' from the Process 'alias2' will be replaced by DataStream 'name1' from 'alias1' and retain the 'name1' in the resulting config. Second line replaces 'name5' in 'alias2' and 'name8' in 'alias3' with 'name2' from 'alias1', and persists 'name2' across the merged config. So the principle is simple: if you want to merge several DataStreams from different Processes, place the main one first, and then list the DataStreams to be replaced.
-o path to the composed output config file, in .ini format by default. For JSON output use .json extension.
-F perform a Full Compose, if this switch is given. Resulting task.tee.outputs will only contain same outputs as the very last config in the chain, otherwise it'll contain outputs from all merged tasks.
And in the Clouds run them
There are two supported ways to execute One Ring Tasks. It's always better to start with a Local mode, debug the whole process on smaller verified datasets, and them move it to the Cloud.
Local Execution
After you've composed the Process configuration, you definitely should test it locally with a small but reasonably representative sample of your source data. It is much easier to debug a new Process locally rather than on the real cluster.
After you've built the local artifact, as described above, call it like:
java -jar ./RestWrapper/target/one-ring-cli.jar -c /path/to/tasks.ini -l -m 6g -x spark.meta -S /path/to/dist_interface.file
-c sets the path to tasks.ini.
-l means the local execution mode of Spark context ('local[*]', to be precise).
-m sets the amount of Spark memory, like '4g' or '512m'.
-x sets the current task prefix, if needed. If you're planning to pass tasks.ini to your cluster via Spark context, you should use prefixed tasks.ini locally too.
-S to interface with One Ring Dist, discussed a bit further.
Also you should pass all the input and output paths via Variables, to ease transition between your local file system storage and the cluster's storage.
For example, let us assume your Process has two source datasets and one result, stored under paths specified by SOURCE_SIGNALS, SOURCE_POIS and OUTPUT_SCORES Variables. Just prepare a newline-separated list of name=value pairs of them, and then you have two ways to pass them to One Ring CLI:
- Encode as Base64 string and pass with
-Vcommand line key - Place into a file (or other Adapter-supported Storage) and pass its path with
-vcommand line key
If both keys are specified, -V has higher priority, and -v will be ignored.
For example,
cat > /path/to/variables.ini SIGNALS_PATH=file:/path/to/signals POIS_PATH=file:/path/to/pois OUTPUT_PATH=file:/path/to/output ^D base64 -w0 < /path/to/variables.ini U0lHTkFMU19QQVRIPWZpbGU6L3BhdGgvdG8vc2lnbmFscwpQT0lTX1BBVEg9ZmlsZTovcGF0aC90by9wb2lzCk9VVFBVVF9QQVRIPWZpbGU6L3BhdGgvdG8vb3V0cHV0Cg== java -jar ./RestWrapper/target/one-ring-cli.jar -c /path/to/tasks.ini -l -m 6g -V U0lHTkFMU19QQVRIPWZpbGU6L3BhdGgvdG8vc2lnbmFscwpQT0lTX1BBVEg9ZmlsZTovcGF0aC90by9wb2lzCk9VVFBVVF9QQVRIPWZpbGU6L3BhdGgvdG8vb3V0cHV0Cg== java -jar ./RestWrapper/target/one-ring-cli.jar -c /path/to/tasks.ini -l -m 6g -v /path/to/variables.ini
You'll see a lot of Spark output, as well as the dump of your Task. If everything is successful, you'll see no exceptions in that output. If not, read exception messages carefully and fix your tasks.ini and/or check the source data files.
Execution on a Compute Cluster
One Ring officially supports the execution on EMR Spark clusters via TeamCity continuous deployment builds, but it could be relatively easy adapted for other clouds, continuous integration services, and automation scenarios.
We assume you're already familiar with AWS and have the utility EC2 instance in that cloud. You may have or may not have to set up TeamCity or some other CI service of your preference on that instance. We like it automated though.
First off, you need to set up some additional environment on the utility instance, starting with latest version of PowerShell (at the very least, version 6 is required) and AWS Tools for PowerShell. Please follow the official AWS documentation, and register your AWS API access key with these Tools.
Get the scripts and CloudFormation deployment template:
git clone https://github.com/PastorGL/one-ring-emr.git
Also get a template of configuration files:
git clone https://github.com/PastorGL/one-ring-emr-settings.git
And there are TC configs you may import into your TC:
git clone https://github.com/PastorGL/one-ring-tc-builds.git
Don't forget to customize VCS roots, and always use your own private copy of one-ring-emr-settings, because there'll go most sensitive data. In the case of other CI service, you may extract build steps from TC's XMLs. Their structure is pretty straightforward, just dig into them.
The environment set up by build configurations is a directory, where the contents of one-ring-emr is augmented with addition of one-ring-emr-settings and One Ring artifacts one-ring-cli.jar and one-ring-dist.jar, so it looks like this (you also may use symlinks to place them into manually):
/common /presets /settings one-ring-cli.jar one-ring-dist.jar create-cluster.ps1 list-jobs.ps1 preset-params.ps1 remove-cluster.ps1 run-job.ps1 set-params.ps1 cluster.template
You place your tasks.ini into /settings subdirectory alongside other .ini files. Also, you must fill in all required values in all .ini files inside this directory, that conform to your AWS account environment.
We usually put presets for all our Processes in different branches of our copy if the one-ring-emr-settings repo, and just switch to the required branch of that repo for each Process' build configuration.
Build steps are executed in the following order:
- Ask for Variables on TC UI
preset-params.ps1set-params.ps1create-cluster.ps1- Encode Variables to Base64
run-job.ps1remove-cluster.ps1
Let we explain what each step does.
TC has a feature to define 'build configuration parameters', and provides an UI to set them at build execution time (along with corresponding REST methods). We use these build parameters to set Variables in our Process template, and ask the user for their values. Also we ask for any additional parameters specific for the environment, such as for a preset of cluster size.
At the next step we select one of four cluster size presets from /preset directory (S, M, L, XL .ini files) if it was selected on the previous step, and place its contents into build parameters.
set-params.ps1 has an ability to override any line of any existing .ini file from /settings subdirectory by replacing it with a custom build parameter named as 'filename.ini' + '.' + 'parameter.name', which gives you another level of build parametrization flexibility. This script overwrites .ini files with these parameters, so all further scripts receive augmented configurations.
At the next step we create a Spark cluster in the EMR by deploying CloudFormation template augmented with all parameters gathered to this moment, and parameters from /settings/create.ini.
Then we encode Variables with Base64, just as we did in Local mode.
At this moment everything is ready to run the Process on the cluster. run-job.ini sets up all required environment (from the per-component .ini files from /settings), calls Livy REST method on the cluster, and waits for the completion. If tasks.ini contains more than one Task, all of them will be ran in the order of definition. Its own parameters are set by /settings/run.ini.
Even if any of previous steps fail, remove-cluster.ps1 should be called. This script does the cleanup, and is controlled by /settings/remove.ini.
All scripts that deal with the cluster also share parameters from /settings/aws.ini global file.
It is possible to execute every PowerShell script in the interactive mode and manually copy-paste their output variables between steps via command line parameters. It may be helpful to familiarize yourself with that stuff before going fully automated.
We also usually go on the higher level of automation and enqueue TC builds with their REST API.
Anyways, closely watch your CloudFormation, EMR and EC2 consoles for at least few first tries. There may be insufficient access rights, and a lot of other issues, but we assume you are already experienced with AWS and EMR, if you are here.
And if you are, you already know that the S3 object storage is not too well suited for Spark because of its architectural peculiarities like 'eventual consistency' and response time dependency on the number of objects in the bucket. To avoid timeout errors, it is recommended to always copy the source data from S3 to HDFS on the cluster before Spark invocation, and, vice versa, to copy the result back from HDFS to S3 after it has been computed.
EMR provides an utility named s3-dist-cp, but its usage is cumbersome because you must know the exact paths.
One Ring provides a Dist wrapper to automate handling of s3-dist-cp while focusing around your Task config, so you can still use Variables for source paths and generate result paths dynamically while not bothering yourself with s3-dist-cp command line.
One Ring Dist also can be used with other flavors of dist-cp, if it is required by your environment.
Calling One Ring Dist
The syntax is similar to CLI:
java -jar ./DistWrapper/target/one-ring-dist.jar -c /path/to/tasks.ini -o /path/to/call_distcp.sh -S /path/to/dist_interface.file -d DIRECTION -x spark.meta
-c, -x, -v/-V switches have the same meaning for Dist as to CLI.
-d specifies the direction of the copying process:
- 'from' to copy the source data from S3 to HDFS,
- 'to' to copy the result back.
-S specifies the path to interface file with a list of HDFS paths of Task outputs generated by the CLI.
-o is the path where to output the script with full s3-dist-cp commands.
Dist Configuration
Dist has its own layer in tasks.ini, prefixed with distcp., with a small set of keys.
distcp.exe specifies which executable should be used. By default, it has a value of 's3-dist-cp'.
distcp.direction sets which copy operations are implied to be performed. In addition to -d switch 'from' and 'to' there are:
- 'both' to indicate the copy in both directions is required,
- 'nop' (default) to suppress the copying.
Boolean distcp.move directs to remove files after copying. By default it is set to true.
distcp.dir.to and distcp.dir.from specify which HDFS paths are to be used to store files gathered from HDFS and for the results respectively, with the defaults of '/input' and '/output'. Subdirectories named after DataStreams will be automatically created for their files under these paths.
distcp.store and distcp.ini provide another way to set -S and -o values (but command line switches always have higher priority and override these keys if set).
Dist Usage
When CLI encounters distcp.direction directive in the config, it transparently replaces all its S3 input and output paths with HDFS paths according to the provided direction.
This is useful for multi-Process tasks.ini. If the outputs from the first Task are stored in HDFS, it allows next Tasks to consume them without a round-trip to S3 while still providing the paths pointing to S3:
spark.task1.distcp.direction=to spark.task2.distcp.direction=nop spark.task3.distcp.direction=from
...and if same Task is executed solo, it should just use bi-directional copy:
spark.task1.distcp.direction=both
...without further changes to path Variables and other configuration parameters.
For any DataStream that goes to distcp.dir.from the CLI adds a line with the resulting HDFS path to Dist interface file (under distcp.store / -S path). That allows Dist to gather them and generate commands for the from direction.
Actually you should never invoke Dist manually, it is a job of automation scripts to call it before and after the execution of CLI.
Join the Fellowship
If you want to contribute, please refer to a list of One Ring issues first.
An issue for your most desired feature may have already been created by someone, but if it has not, you're free to create one. Do not attach any assignees, labels, projects and so on, just provide a detailed explanation of its use case and write a simple initial specification.
If you have some spare programming horsepower and just want to code something, you can select an issue labeled as 'Help Wanted', 'Wishlist' and assigned priority — one of priority ('Px') labels. There are labels 'Okay to tackle' and 'Good first issue' that designate the complexity of an issue. Just assign it to yourself and ask for complete specification, if it doesn't exist yet.
Do not choose issues labeled as 'Caution advised' unless you become really familiar with entire One Ring codebase.
Note that One Ring has an established code style. Your contributions must firmly adhere to coding patterns we use so they don't feel alien.
Make sure your pull requests don't touch anything outside the scope of an issue, and don't add or change versions of any external dependencies. At least, discuss these topics with original authors before you contribute.
We won't accept any code that has been borrowed from any sources that aren't compatible by license. Ours is New BSD with do no evil clause. Just do not use One Ring as a weapon, okay?
This project has no Code of Conduct and never will. You can be as sarcastic as you want but stay polite and don't troll anyone if you don't want to be trolled in return.
Happy data engineering!

{kind=link}