Периодически натыкаясь на статьи, посвященные оптимизации кода на JS (вот одна из популярных) я ловил себя на мысли, что информации в них катастрофически мало. Перечислены 2-3 конструкции, 1-2 браузера и все на этом.
Как говорится, если хочешь сделать что-то хорошо, сделай это сам.
Я решил протестировать, в первую очередь для себя, скорость работы различных языковых конструкций (начиная с самых базовых) в основных современных браузерах и на основе этого сделать выводы о том, что и как использовать в скриптах, требовательных к производительности.
Ну и раз уж результаты получены, почему бы не выложить их для всеобщего пользования?
Upd: добавил графики результатов, предоставленные хабраюзером deerua (для тех, кто воспринимает визуальную подачу информации лучше чем табличную)
Итак, машина для тестирования — P4 3GHz (двухядерный), 1.5RAM, Vista 32-bit.
Набор браузеров — FF3, Opera 9.62, Chrom 1.0, IE7, IE8b2
Скажу сразу, что IE8 — не оригинальный, а запущенный через программу IETester
Насколько он соответствует оригинальному я не знаю, но по крайней мере от IE7 результаты отличаются довольно сильно, причем в различные стороны.
Если кто-то хочет протестировать IE6 или любой другой браузер — собственно, welcome )
Все нижеописанные языковые конструкции тестировались путем повторения 1 миллион раз в цикле. Данное действие повторялось несколько раз в каждом браузере, дабы выявить некий средний результат (он обычно колеблется в пределах +-2-5% в зависимости от текущей загрузки системы). Средний результат (в миллисекундах) записывался в таблицу.
Везде (где явно не указано другое) использовался инвертированный цикл for(var i=1000000; i--;) как наиболее быстрый.
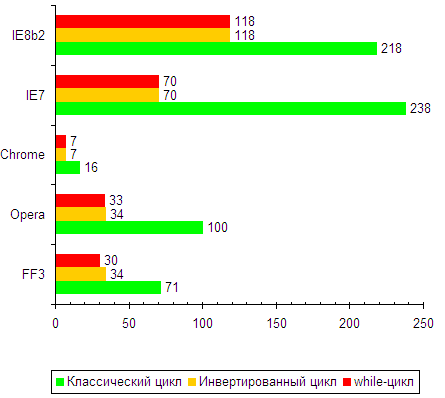
Итак, для начала я решил протестировать сами циклы (просто пустые циклы без выполняемого кода внутри). Т.к. сказать основу нашего тестирования )
Про циклы уже было написано довольно много, так что результаты вполне предсказуемы.
Как видно, инвертированный цикл for(var i=1000000; i--;) как минимум вдвое быстрее классического for(var i=0; i<1000000; i++), поэтому именно он использовался в дальнейшем тестировании.
Также можно заметить что while цикл практически не отличается по скорости от инвертированного for, видимо потому что это фактически одна и та же конструкция (по логике работы).
Эта часть посвящена работе с массивами и объектами-заменителями. Под объектом-заменителем в данном тесте имеется ввиду объект (типа Object), использующийся исключительно как замена массиву (т.е. не содержащий никаких свойств, кроме элементов как-бы массива). Интересовала скорость работы таких заменителей.
Массив (или объект) 1M — имеется ввиду массив (или его заменитель) с кол-вом элементом равным 1000000, ну и индексами (ключами) соответственно от нуля до миллиона (точнее, 999999).
В первом тесте мы полностью перебираем такой массив в инвертированном цикле, т.е. примерно вот так:
var a=0;
for(var i=1000000; i--;) {a=big_array[i];}
Во втором тесте мы также делаем миллион итераций цикла, но на каждом шаге получаем одно и то же значение из маленького массива (размером 100 элементов). Этот тест я сделал для проверки того, насколько размер массива влияет на скорость получения из него значений.
Как показал тест, во всех браузерах кроме Chrome время поиска значения в массиве может значительно возрасти с ростом кол-ва его элементов.
В третьем тесте делается полный for-in цикл по объекту-заменителю массива.
Хорошо видно что цикл for-in является очень медленным во всех браузерах (по сравнению с инвертированным for), и ОЧЕНЬ медленным в IE для больших объемов данных. Никогда не используйте его для перебора массивов или объектов, где можно обойтись циклом for (т.е. ключи числовые и упорядоченные).
Четвертый тест — полный аналог первого теста, кроме того что big_array является не массивом а объектом.
Заметно, что скорость перебора через цикл слабо зависит от того, массив у нас или объект-заменитель. Ощутимая разница только в IE8, но это еще бета, так что все может измениться.

Также стоит заметить, что если перед нами стоит задача выбрать диапазон элементов массива то использование метода array.slice() в любом браузере в несколько раз быстрее, чем просто перебор массива в цикле с выборкой нужных элементов по условию. Разница настолько очевидна, что я даже не стал включать это в тест.
Помимо перебора массивов, часто приходится их заполнять, поэтому следующие 5 тестов как раз об этом.
В принципе, из таблицы все должно быть понятно:
В первую очередь, я протестировал вызов пустой функции в цикле.
var f=function(){}
for(var i=1000000; i--;) {f();}
В большинстве браузеров вызов функции является довольно дешевой операцией (на миллион вызовов всего несколько сотен добавленных миллисекунд, по сравнению с полностью пустым циклом).
Однако IE, как всегда, преподносит неприятные сюрпризы. Любителям оборачивать код во множество функций-оберток будет над чем подумать )
Отмечу, что медленный вызов функции как таковой отрицательно влияет и на другие тесты, связанные с вызовом функций (например, создание объекта или вызов метода), поэтому время их выполнения в IE еще сильнее увеличивается.
Следующие 2 теста посвящены созданию миллиона объектов, в одном случае все методы создаются через конструктор, в другом — через прототип.
Разница, я думаю, очевидна.
Три следующих теста вызывают свойство объекта: собственное свойство (созданное через this.prop=value), свойство прототипа и приватное свойство (созданное через замыкание из функции конструктора). Очевидно, что последний вариант получаем через геттер.
Результат, в общем, предсказуем — собственное свойство объекта можно получить значительно быстрее.
Далее следует 3 теста, вызывающих инкрементный метод объекта (т.е. метод, которая при каждом вызове увеличивает свойство объекта на единицу). Собственно, разница здесь опять же в том, как именно данное свойство было создано (т.е. тестируется скорость доступа к свойствам объекта из его же методов).
Наглядно видно, что в данном случае скорость изменения приватного свойства выше везде, кроме Firefox, однако нужно помнить, что такое свойство является общим для всех однотипных объектов и имеет худшее время чтения снаружи (через геттер).
Первые два теста в этой таблице я думаю комментировать не нужно, на третьем остановимся поподробнее.
Хэш функций — это объект, эмулирующий своим поведением switch.
Например, у нас есть такой кусок кода:
switch(a) {
case 0: b=6+2; break;
case 1: b=8*3; break;
}
Тогда хэш функций будет выглядеть так:
hash={
'0': function() {return 6+2;},
'1': function() {return 8*3;}
}
И использоваться так b=hash[a]();
При таких простых действиях хэш показывает худшие результаты по сравнению со switch (что обусловлено необходимостью вызова функции). Однако, если вы из switch все равно собираетесь вызывать функции, то хэш возможно будет быстрее.
Опять же все предсказуемо. Chrome уверенно лидирует с отрывом в несколько парсеков, огнелис и опера делят друг с другом второе и третье место (в разных тестах по разному), ослик уныло плетется в конце, однако бета-ослик подает некоторые надежды на то, что пациент скорее жив, чем мертв.
Первое, на что хотелось бы обратить внимание — все вышеприведенные тесты являются синтетическими, причем тестируется нагрузка значительно превышающая обычную для веб-приложениях (не так уж и часто приходится иметь дело с массивами по миллиону значений, например).
Следовательно, относиться к ним стоит именно как к синтетическим тестам со специально завышенной нагрузкой — т.е. осознавать, что из этого важно для вашего конкретного скрипта, а что не принципиально.
С другой стороны, тот метод, который сегодня вызывается сто раз, завтра может вызываться уже десять тысяч раз, так что совсем уж махать рукой на это дело не стоит. И если что-то где-то начало тормозить, будет хотя бы понимание, в какую сторону следует «копать» )
Как говорится, если хочешь сделать что-то хорошо, сделай это сам.
Я решил протестировать, в первую очередь для себя, скорость работы различных языковых конструкций (начиная с самых базовых) в основных современных браузерах и на основе этого сделать выводы о том, что и как использовать в скриптах, требовательных к производительности.
Ну и раз уж результаты получены, почему бы не выложить их для всеобщего пользования?
Upd: добавил графики результатов, предоставленные хабраюзером deerua (для тех, кто воспринимает визуальную подачу информации лучше чем табличную)
Введение
Итак, машина для тестирования — P4 3GHz (двухядерный), 1.5RAM, Vista 32-bit.
Набор браузеров — FF3, Opera 9.62, Chrom 1.0, IE7, IE8b2
Скажу сразу, что IE8 — не оригинальный, а запущенный через программу IETester
Насколько он соответствует оригинальному я не знаю, но по крайней мере от IE7 результаты отличаются довольно сильно, причем в различные стороны.
Если кто-то хочет протестировать IE6 или любой другой браузер — собственно, welcome )
Методология тестирования
Все нижеописанные языковые конструкции тестировались путем повторения 1 миллион раз в цикле. Данное действие повторялось несколько раз в каждом браузере, дабы выявить некий средний результат (он обычно колеблется в пределах +-2-5% в зависимости от текущей загрузки системы). Средний результат (в миллисекундах) записывался в таблицу.
Везде (где явно не указано другое) использовался инвертированный цикл for(var i=1000000; i--;) как наиболее быстрый.
Переходим к делу
Циклы
| Тесты/Браузеры | FF3 | Opera | Chrome | IE7 | IE8b2 |
| Циклы | |||||
| Классический цикл | 71 | 100 | 16 | 238 | 218 |
| Инвертированный цикл | 34 | 34 | 7 | 70 | 118 |
| while-цикл | 30 | 33 | 7 | 70 | 118 |
Итак, для начала я решил протестировать сами циклы (просто пустые циклы без выполняемого кода внутри). Т.к. сказать основу нашего тестирования )
Про циклы уже было написано довольно много, так что результаты вполне предсказуемы.
Как видно, инвертированный цикл for(var i=1000000; i--;) как минимум вдвое быстрее классического for(var i=0; i<1000000; i++), поэтому именно он использовался в дальнейшем тестировании.
Также можно заметить что while цикл практически не отличается по скорости от инвертированного for, видимо потому что это фактически одна и та же конструкция (по логике работы).
Работа с массивами и объектами
| Тесты/Браузеры | FF3 | Opera | Chrome | IE7 | IE8b2 |
| Перебор массивов и объектов | |||||
| Получение значений большого массива (1M) по индексу (полный перебор в обратном порядке) | 430 | 170 | 18 | 790 | 1020 |
| Получение значения маленького массива (100) по индексу | 124 | 146 | 18 | 428 | 515 |
| For-in цикл по объекту (1M) | 2020 | 2160 | 385 | 39400 | 35400 |
| Перебор объекта (1M) через инвертированный цикл | 390 | 170 | 18 | 745 | 746 |
| Заполнение массивов и объектов | |||||
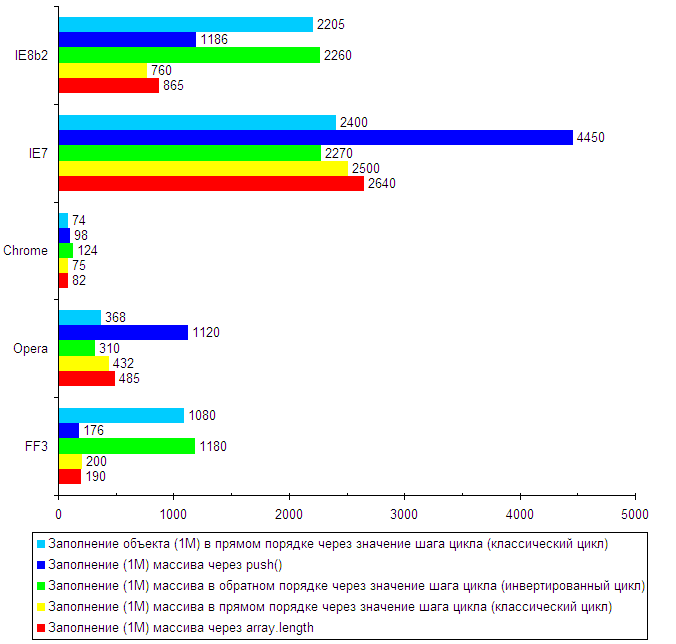
| Заполнение (1M) массива через array.length | 190 | 485 | 82 | 2640 | 865 |
| Заполнение (1M) массива в прямом порядке через значение шага цикла (классический цикл) | 200 | 432 | 75 | 2500 | 760 |
| Заполнение (1M) массива в обратном порядке через значение шага цикла (инвертированный цикл) | 1180 | 310 | 124 | 2270 | 2260 |
| Заполнение (1M) массива через push() | 176 | 1120 | 98 | 4450 | 1186 |
| Заполнение объекта (1M) в прямом порядке через значение шага цикла (классический цикл) | 1080 | 368 | 74 | 2400 | 2205 |
Эта часть посвящена работе с массивами и объектами-заменителями. Под объектом-заменителем в данном тесте имеется ввиду объект (типа Object), использующийся исключительно как замена массиву (т.е. не содержащий никаких свойств, кроме элементов как-бы массива). Интересовала скорость работы таких заменителей.
Массив (или объект) 1M — имеется ввиду массив (или его заменитель) с кол-вом элементом равным 1000000, ну и индексами (ключами) соответственно от нуля до миллиона (точнее, 999999).
В первом тесте мы полностью перебираем такой массив в инвертированном цикле, т.е. примерно вот так:
var a=0;
for(var i=1000000; i--;) {a=big_array[i];}
Во втором тесте мы также делаем миллион итераций цикла, но на каждом шаге получаем одно и то же значение из маленького массива (размером 100 элементов). Этот тест я сделал для проверки того, насколько размер массива влияет на скорость получения из него значений.
Как показал тест, во всех браузерах кроме Chrome время поиска значения в массиве может значительно возрасти с ростом кол-ва его элементов.
В третьем тесте делается полный for-in цикл по объекту-заменителю массива.
Хорошо видно что цикл for-in является очень медленным во всех браузерах (по сравнению с инвертированным for), и ОЧЕНЬ медленным в IE для больших объемов данных. Никогда не используйте его для перебора массивов или объектов, где можно обойтись циклом for (т.е. ключи числовые и упорядоченные).
Четвертый тест — полный аналог первого теста, кроме того что big_array является не массивом а объектом.
Заметно, что скорость перебора через цикл слабо зависит от того, массив у нас или объект-заменитель. Ощутимая разница только в IE8, но это еще бета, так что все может измениться.
Также стоит заметить, что если перед нами стоит задача выбрать диапазон элементов массива то использование метода array.slice() в любом браузере в несколько раз быстрее, чем просто перебор массива в цикле с выборкой нужных элементов по условию. Разница настолько очевидна, что я даже не стал включать это в тест.
Помимо перебора массивов, часто приходится их заполнять, поэтому следующие 5 тестов как раз об этом.
В принципе, из таблицы все должно быть понятно:
- Заполнение массива через метод push значительно медленнее во всех браузерах, кроме FF, по сравнению с заполнением через array[array.length]=value. (Разработчики огнелиса видимо единственные поняли, что это полное безобразие, когда вместо родного метода используется громоздкая конструкция.)
- В некоторых браузерах бывает важно, заполняете ли вы массив в прямом или обратном порядке.
- Заполнение объекта-заменителя значительно медленнее в FF и IE8, видимо потому что операция заполнения массива специально оптимизирована, а заполнения объекта — нет (что и понятно, потому что объект не должен использоваться вместо массива для хранения больших объемов однородных данных).
Функции, объекты, переменные
| Функции, объекты, переменные | |||||
| Тесты/Браузеры | FF3 | Opera | Chrome | IE7 | IE8b2 |
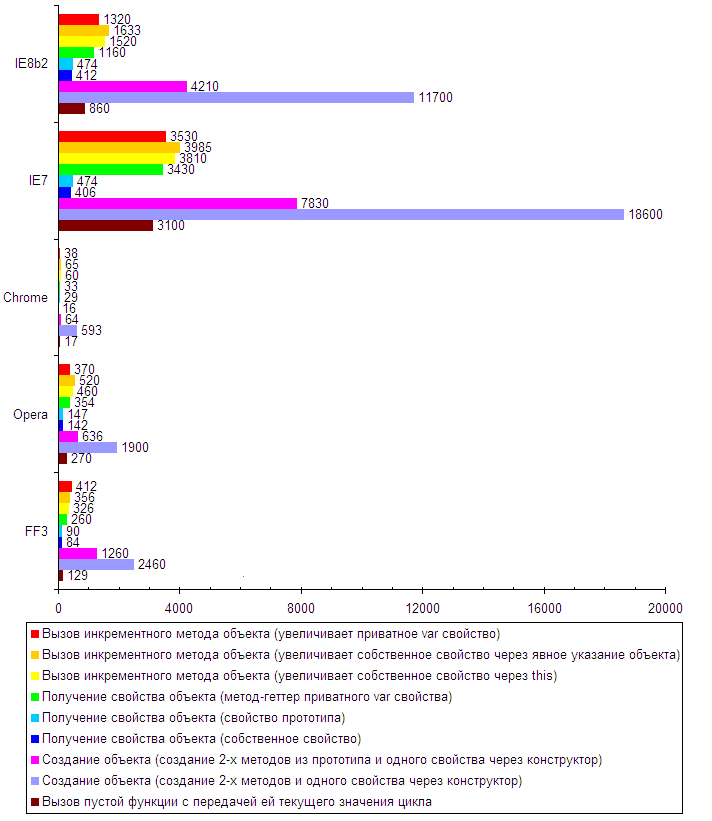
| Вызов пустой функции с передачей ей текущего значения цикла | 129 | 270 | 17 | 3100 | 860 |
| Создание объекта (создание 2-х методов и одного свойства через конструктор) | 2460 | 1900 | 593 | 18600 | 11700 |
| Создание объекта (создание 2-х методов из прототипа и одного свойства через конструктор) | 1260 | 636 | 64 | 7830 | 4210 |
| Получение свойства объекта (собственное свойство) | 84 | 142 | 16 | 406 | 412 |
| Получение свойства объекта (свойство прототипа) | 90 | 147 | 29 | 474 | 474 |
| Получение свойства объекта (метод-геттер приватного var свойства) | 260 | 354 | 33 | 3430 | 1160 |
| Вызов инкрементного метода объекта (увеличивает собственное свойство через this) | 326 | 460 | 60 | 3810 | 1520 |
| Вызов инкрементного метода объекта (увеличивает собственное свойство через явное указание объекта) | 356 | 520 | 65 | 3985 | 1633 |
| Вызов инкрементного метода объекта (увеличивает приватное var свойство) | 412 | 370 | 38 | 3530 | 1320 |
В первую очередь, я протестировал вызов пустой функции в цикле.
var f=function(){}
for(var i=1000000; i--;) {f();}
В большинстве браузеров вызов функции является довольно дешевой операцией (на миллион вызовов всего несколько сотен добавленных миллисекунд, по сравнению с полностью пустым циклом).
Однако IE, как всегда, преподносит неприятные сюрпризы. Любителям оборачивать код во множество функций-оберток будет над чем подумать )
Отмечу, что медленный вызов функции как таковой отрицательно влияет и на другие тесты, связанные с вызовом функций (например, создание объекта или вызов метода), поэтому время их выполнения в IE еще сильнее увеличивается.
Следующие 2 теста посвящены созданию миллиона объектов, в одном случае все методы создаются через конструктор, в другом — через прототип.
Разница, я думаю, очевидна.
Три следующих теста вызывают свойство объекта: собственное свойство (созданное через this.prop=value), свойство прототипа и приватное свойство (созданное через замыкание из функции конструктора). Очевидно, что последний вариант получаем через геттер.
Результат, в общем, предсказуем — собственное свойство объекта можно получить значительно быстрее.
Далее следует 3 теста, вызывающих инкрементный метод объекта (т.е. метод, которая при каждом вызове увеличивает свойство объекта на единицу). Собственно, разница здесь опять же в том, как именно данное свойство было создано (т.е. тестируется скорость доступа к свойствам объекта из его же методов).
Наглядно видно, что в данном случае скорость изменения приватного свойства выше везде, кроме Firefox, однако нужно помнить, что такое свойство является общим для всех однотипных объектов и имеет худшее время чтения снаружи (через геттер).
Ветви
| Ветви | |||||
| Тесты/Браузеры | FF3 | Opera | Chrome | IE7 | IE8b2 |
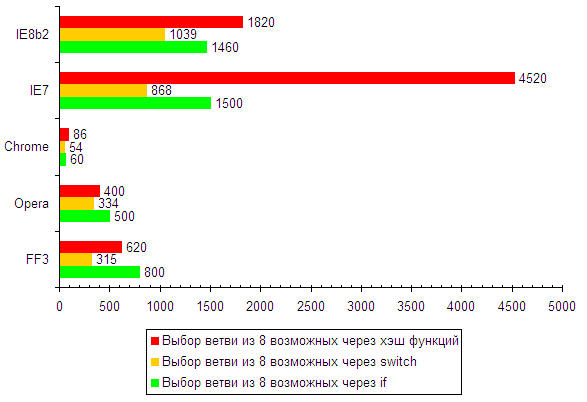
| Выбор ветви из 8 возможных через if | 800 | 500 | 60 | 1500 | 1460 |
| Выбор ветви из 8 возможных через switch | 315 | 334 | 54 | 868 | 1039 |
| Выбор ветви из 8 возможных через хэш функций | 620 | 400 | 86 | 4520 | 1820 |
Первые два теста в этой таблице я думаю комментировать не нужно, на третьем остановимся поподробнее.
Хэш функций — это объект, эмулирующий своим поведением switch.
Например, у нас есть такой кусок кода:
switch(a) {
case 0: b=6+2; break;
case 1: b=8*3; break;
}
Тогда хэш функций будет выглядеть так:
hash={
'0': function() {return 6+2;},
'1': function() {return 8*3;}
}
И использоваться так b=hash[a]();
При таких простых действиях хэш показывает худшие результаты по сравнению со switch (что обусловлено необходимостью вызова функции). Однако, если вы из switch все равно собираетесь вызывать функции, то хэш возможно будет быстрее.
Общий вывод по браузерам
Опять же все предсказуемо. Chrome уверенно лидирует с отрывом в несколько парсеков, огнелис и опера делят друг с другом второе и третье место (в разных тестах по разному), ослик уныло плетется в конце, однако бета-ослик подает некоторые надежды на то, что пациент скорее жив, чем мертв.
Заключение
Первое, на что хотелось бы обратить внимание — все вышеприведенные тесты являются синтетическими, причем тестируется нагрузка значительно превышающая обычную для веб-приложениях (не так уж и часто приходится иметь дело с массивами по миллиону значений, например).
Следовательно, относиться к ним стоит именно как к синтетическим тестам со специально завышенной нагрузкой — т.е. осознавать, что из этого важно для вашего конкретного скрипта, а что не принципиально.
С другой стороны, тот метод, который сегодня вызывается сто раз, завтра может вызываться уже десять тысяч раз, так что совсем уж махать рукой на это дело не стоит. И если что-то где-то начало тормозить, будет хотя бы понимание, в какую сторону следует «копать» )
