
В интернете полно статей на тему основанных на N-граммах языковых моделей. При этом, готовых для работы библиотек довольно мало.
Есть KenLM, SriLM и IRSTLM. Они популярны и используются во многих крупных проектах. Но есть проблемы:
- Библиотеки старые, не развиваются.
- Плохо поддерживают русский язык.
- Работают только с чистым, специально подготовленным, текстом
- Плохо поддерживают UTF-8. Например, SriLM с флагом tolower ломает кодировку.
Из списка немного выделяется KenLM. Регулярно поддерживается и не имеет проблем с UTF-8, но она также требовательна к качеству текста.
Когда-то мне потребовалась библиотека для сборки языковой модели. После многих проб и ошибок пришёл к выводу, что подготовка датасета для обучения языковой модели — слишком сложный и долгий процесс. Особенно, если это русский язык! А ведь хотелось как-то всё автоматизировать.
В своих исследованиях отталкивался от библиотеки SriLM. Сразу отмечу, что это не заимствование кода и не fork SriLM. Весь код написан полностью с нуля.
Небольшой текстовый пример:
Неожиданно из подворотни в Олега ударил яркий прожектор патрульный трактор!С лязгом выкатился и остановился возле мальчика.
Отсутствие пробела между предложениями — довольно частая опечатка. Такую ошибку сложно найти в большом объеме данных, при этом она ломает токенизатор.
После обработки, в языковой модели появится такая N-грамма:
-0.3009452 трактор!С лязгом выкатилсяРазумеется, существует множество других проблем, опечаток, спецсимволов, аббревиатур, различных математических формул… Всё это нужно правильно обрабатывать.
ANYKS LM (ALM)
Библиотека поддерживает только операционные системы Linux, MacOS X и FreeBSD. Windows у меня нет и поддержка не планируется.
Краткое описание функционала
- Поддержка UTF-8 без сторонних зависимостей.
- Поддержка форматов данных: Arpa, Vocab, Map Sequence, N-grams, Binary alm dictionary.
- Поддержка алгоритмов сглаживания: Kneser-Nay, Modified Kneser-Nay, Witten-Bell, Additive, Good-Turing, Absolute discounting.
- Нормализация входных корпусов, приведение слов к нижнему регистру, умная токенизация, поддержка чёрного и белого списков.
- Замена частот, замена N-грамм, добавление новых N-грамм с частотами, удаление N-грамм.
- Прунинг — сокращение числа N-грамм, которые не соответствуют указанным критериям качества.
- Смешивание языковых моделей: статическое, алгоритмом Байеса и линейно-логарифмическое.
- Чистка плохих N-грамм — удаление N-грамм, у которых обратная частота backoff выше основной частоты.
- Восстановление повреждённых N-грамм в языковой модели с последующим перерасчётом их backoff-частот.
- Поддержка специализированных токенов слов, таких как: числа, римские числа, диапазоны чисел, аббревиатуры, любые другие пользовательские токены с помощью скриптов написанных на языке Python3.
- Обработка «грязных текстов», извлечение правильного контекста из текстовых файлов.
- Переопределение 〈unk〉 токена в другое слово.
- Предобработка N-грамм перед добавлением в языковую модель с помощью скриптов на языке Python3.
- Бинарный контейнер языковой модели поддерживает сжатие, шифрование и установку копирайтов.
- Удобная визуализация хода процесса сборки языковой модели. Реализовано несколько видов визуализаций: текстовая, графическая в виде индикатора процесса, логирование в файлы или консоль.
- В отличие от остальных языковых моделей, ALM гарантированно собирает все N-граммы из текста независимо от их длины (кроме Modified Kneser-Nay). Также есть возможность принудительного учёта всех редко-встречаемых N-грамм, даже если они встретились всего 1 раз.
Из стандартных форматов языковых моделей поддерживается только формат ARPA. Честно, не вижу смысла поддерживать весь зоопарк всевозможных форматов.
Формат ARPA чувствителен к регистру символов и это тоже определённая проблема.
Иногда полезно знать только наличие в N-грамме конкретных данных. Например, нужно понимать наличие в N-грамме цифр, а их значение не столь важно.
Пример:
Спешите купить, распродажа в нашем магазине только 2 дня
В результате в языковую модель попадёт N-грамма:
-0.09521468 только 2 дня
Конкретное число, в данном случае, значения не имеет. Распродажа в магазине может идти и 1 и 3 и сколько угодно дней.
Для решения подобной задачи в ALM применяется классовая токенизация.
Поддерживаемые токены
Стандартные:
〈s〉 — Токен начала предложения
〈/s〉 — Токен конца предложения
〈unk〉 — Токен неизвестного слова
Нестандартные:
〈url〉 — Токен url адреса
〈num〉 — Токен чисел (арабское или римское)
〈date〉 — Токен даты (18.07.2004 | 07/18/2004)
〈time〉 — Токен времени (15:44:56)
〈abbr〉 — Токен аббревиатуры (1-й | 2-е | 20-я)
〈anum〉 — Токен псевдо-числа (T34 | 895-M-86 | 39km)
〈math〉 — Токен математической операции (+ | — | = | / | * | ^)
〈range〉 — Токен диапазона чисел (1-2 | 100-200 | 300-400)
〈aprox〉 — Токен приблизительного числа (~93 | ~95.86 | 10~20)
〈score〉 — Токен числового счёта (4:3 | 01:04)
〈dimen〉 — Токен габаритных размеров (200x300 | 1920x1080)
〈fract〉 — Токен числовой дроби (5/20 | 192/864)
〈punct〉 — Токен знаков пунктуации (. |… |, |! |? |: | ;)
〈specl〉 — Токен спецсимвола (~ | @ | # | № | % | & | $ | § | ±)
〈isolat〉 — Токен символов изоляции (" | ' | « | » | „ | “ | ` | ( | ) | [ | ] | { | })
Конечно, поддержку каждого из токенов можно отключить, если такие N-граммы нужны.
Если необходимо обрабатывать другие теги (например, нужно находить в тексте названия стран), ALM поддерживает подключение внешних скриптов на Python3.
Пример скрипта детектирования токенов:
# -*- coding: utf-8 -*-
def init():
"""
Метод инициализации: выполняется только один раз при запуске приложения
"""
def run(token, word):
"""
Метод запуска обработки: запускается при извлечении слова из текста
@token название токена слова
@word обрабатываемое слово
"""
if token and (token == "<usa>"):
if word and (word.lower() == "сша"): return "ok"
elif token and (token == "<russia>"):
if word and (word.lower() == "россия"): return "ok"
return "no"
Такой скрипт добавляет к списку стандартных тегов еще два тега:〈usa〉 и 〈russia〉.
Кроме скрипта детектирования токенов есть поддержка скрипта предобработки обрабатываемых слов. Этот скрипт может изменить слово перед добавлением слова в языковую модель.
Пример скрипта предобработки слов:
# -*- coding: utf-8 -*-
def init():
"""
Метод инициализации: выполняется только один раз при запуске приложения
"""
def run(word, context):
"""
Метод запуска обработки: запускается при извлечении слова из текста
@word обрабатываемое слово
@context последовательность предыдущих слов в виде массива
"""
return word
Такой подход может быть полезен, если необходимо собрать языковую модель, состоящую из лемм или стемм.
Текстовые форматы языковой модели, поддерживаемые ALM
ARPA:
\data\
ngram 1=52
ngram 2=68
ngram 3=15
\1-grams:
-1.807052 1-й -0.30103
-1.807052 2 -0.30103
-1.807052 3~4 -0.30103
-2.332414 как -0.394770
-3.185530 после -0.311249
-3.055896 того -0.441649
-1.150508 </s>
-99 <s> -0.3309932
-2.112406 <unk>
-1.807052 T358 -0.30103
-1.807052 VII -0.30103
-1.503878 Грека -0.39794
-1.807052 Греку -0.30103
-1.62953 Ехал -0.30103
...
\2-grams:
-0.29431 1-й передал
-0.29431 2 ложки
-0.29431 3~4 дня
-0.8407791 <s> Ехал
-1.328447 после того -0.477121
...
\3-grams:
-0.09521468 рак на руке
-0.166590 после того как
...
\end\
ARPA — стандартный текстовый формат языковой модели естественного языка, используемый в Sphinx/CMU и Kaldi.
| Частота | N-грамма | Обратная частота |
| -1.328447 | после того | -0.477121 |
NGRAMS:
\data\
ad=1
cw=23832
unq=9390
ngram 1=9905
ngram 2=21907
ngram 3=306
\1-grams:
<s> 2022 | 1
<num> 117 | 1
<unk> 19 | 1
<abbr> 16 | 1
<range> 7 | 1
</s> 2022 | 1
А 244 | 1
а 244 | 1
б 11 | 1
в 762 | 1
выборах 112 | 1
обзорах 224 | 1
половозрелые 1 | 1
небесах 86 | 1
изобретали 978 | 1
яблочную 396 | 1
джинсах 108 | 1
классах 77 | 1
трассах 32 | 1
...
\2-grams:
<s> <num> 7 | 1
<s> <unk> 1 | 1
<s> а 84 | 1
<s> в 83 | 1
<s> и 57 | 1
и классные 82 | 1
и валютные 11 | 1
и несправедливости 24 | 1
снилось являлось 18 | 1
нашлось никого 31 | 1
соответственно вы 45 | 1
соответственно дома 97 | 1
соответственно наша 71 | 1
...
\3-grams:
<s> <num> </s> 3 | 1
<s> а в 6 | 1
<s> а я 4 | 1
<s> а на 2 | 1
<s> а то 3 | 1
можно и нужно 2 | 1
будет хорошо </s> 2 | 1
пейзажи за окном 2 | 1
статусы для одноклассников 2 | 1
только в одном 2 | 1
работа связана с 2 | 1
говоря про то 2 | 1
отбеливания зубов </s> 2 | 1
продолжение следует </s> 3 | 1
препараты от варикоза 2 | 1
...
\end\
Ngrams – нестандартный текстовый формат языковой модели, является модификацией формата ARPA.
| N-грамма | Встречаемость в корпусе | Встречаемость в документах |
| только в одном | 2 | 1 |
Описание:
- ad - Количество документов в корпусе
- cw - Количество слов во всех документах корпуса
- unq - Количество уникальных собранных слов
VOCAB:
\data\
ad=1
cw=23832
unq=9390
\words:
33 а 244 | 1 | 0.010238 | 0.000000 | -3.581616
34 б 11 | 1 | 0.000462 | 0.000000 | -6.680889
35 в 762 | 1 | 0.031974 | 0.000000 | -2.442838
40 ж 12 | 1 | 0.000504 | 0.000000 | -6.593878
330344 был 47 | 1 | 0.001972 | 0.000000 | -5.228637
335190 вам 17 | 1 | 0.000713 | 0.000000 | -6.245571
335192 дам 1 | 1 | 0.000042 | 0.000000 | -9.078785
335202 нам 22 | 1 | 0.000923 | 0.000000 | -5.987742
335206 сам 7 | 1 | 0.000294 | 0.000000 | -7.132874
335207 там 29 | 1 | 0.001217 | 0.000000 | -5.711489
2282019644 похожесть 1 | 1 | 0.000042 | 0.000000 | -9.078785
2282345502 новый 10 | 1 | 0.000420 | 0.000000 | -6.776199
2282416889 белый 2 | 1 | 0.000084 | 0.000000 | -8.385637
3009239976 гражданский 1 | 1 | 0.000042 | 0.000000 | -9.078785
3009763109 банкиры 1 | 1 | 0.000042 | 0.000000 | -9.078785
3013240091 геныч 1 | 1 | 0.000042 | 0.000000 | -9.078785
3014009989 преступлениях 1 | 1 | 0.000042 | 0.000000 | -9.078785
3015727462 тысяч 2 | 1 | 0.000084 | 0.000000 | -8.385637
3025113549 позаботьтесь 1 | 1 | 0.000042 | 0.000000 | -9.078785
3049820849 комментарием 1 | 1 | 0.000042 | 0.000000 | -9.078785
3061388599 компьютерная 1 | 1 | 0.000042 | 0.000000 | -9.078785
3063804798 шаблонов 1 | 1 | 0.000042 | 0.000000 | -9.078785
3071212736 завидной 1 | 1 | 0.000042 | 0.000000 | -9.078785
3074971025 холодной 1 | 1 | 0.000042 | 0.000000 | -9.078785
3075044360 выходной 1 | 1 | 0.000042 | 0.000000 | -9.078785
3123271427 делаешь 1 | 1 | 0.000042 | 0.000000 | -9.078785
3123322362 читаешь 1 | 1 | 0.000042 | 0.000000 | -9.078785
3126399411 готовится 1 | 1 | 0.000042 | 0.000000 | -9.078785
…
Vocab – нестандартный текстовый формат словаря в языковой модели.
| Идентификатор слова | Слово | Встречаемость в корпусе | Встречаемость в документах | tf | tf-idf | wltf |
| 2282345502 | новый | 10 | 1 | 0.000420 | 0.000000 | -6.776199 |
Описание:
- oc - встречаемость в корпусе
- dc - встречаемость в документах
- tf - (term frequency — частота слова) — отношение числа вхождений некоторого слова к общему числу слов документа. Таким образом, оценивается важность слова в пределах отдельного документа, рассчитывается как: [tf = oc / cw]
- idf - (inverse document frequency — обратная частота документа) — инверсия частоты, с которой некоторое слово встречается в документах коллекции, рассчитывается как: [idf = log(ad / dc)]
- tf-idf - рассчитывается как: [tf-idf = tf * idf]
- wltf - рейтинг слова, рассчитывается как: [wltf = 1 + log(tf * dc)]
MAP:
1:{2022,1,0}|42:{57,1,0}|279603:{2,1,0}
1:{2022,1,0}|42:{57,1,0}|320749:{2,1,0}
1:{2022,1,0}|42:{57,1,0}|351283:{2,1,0}
1:{2022,1,0}|42:{57,1,0}|379815:{3,1,0}
1:{2022,1,0}|42:{57,1,0}|26122748:{3,1,0}
1:{2022,1,0}|44:{6,1,0}
1:{2022,1,0}|48:{1,1,0}
1:{2022,1,0}|51:{11,1,0}|335967:{3,1,0}
1:{2022,1,0}|53:{14,1,0}|371327:{3,1,0}
1:{2022,1,0}|53:{14,1,0}|40260976:{7,1,0}
1:{2022,1,0}|65:{68,1,0}|34:{2,1,0}
1:{2022,1,0}|65:{68,1,0}|3277:{3,1,0}
1:{2022,1,0}|65:{68,1,0}|278003:{2,1,0}
1:{2022,1,0}|65:{68,1,0}|320749:{2,1,0}
1:{2022,1,0}|65:{68,1,0}|11353430797:{2,1,0}
1:{2022,1,0}|65:{68,1,0}|34270133320:{2,1,0}
1:{2022,1,0}|65:{68,1,0}|51652356484:{2,1,0}
1:{2022,1,0}|65:{68,1,0}|66967237546:{2,1,0}
1:{2022,1,0}|2842:{11,1,0}|42:{7,1,0}
…
Map — содержимое файла, имеет чисто техническое значение. Используется совместно с файлом vocab, можно объединять несколько языковых моделей, модифицировать, хранить, распространять и экспортировать в любые форматы (arpa, ngrams, binary alm).
Вспомогательные форматы текстовых файлов, которые поддерживает ALM
Часто, при сборке языковой модели в тексте встречаются опечатки, которые представляют из себя замены букв (на визуально-похожие буквы другого алфавита).
ALM решает эту проблему при помощи файла с внешне-похожими буквами.
p р
c с
o о
t т
k к
e е
a а
h н
x х
b в
m м
| Искомая буква | Разделитель | Буква на замену |
| t | \t | т |
Если, при обучении языковой модели, передать файлы со списком доменов первого уровня и аббревиатур, то можно помочь ALM с более точным детектированием классовых тегов 〈url〉 и 〈abbr〉.
Файл списка аббревиатур:
г
р
США
ул
руб
рус
чел
…
Файл списка доменных зон:
ru
su
cc
net
com
org
info
…
Для более точного детектирования токена 〈url〉 следует добавить свои доменные зоны первого уровня (все доменные зоны из примера уже предустановлены).
Бинарный контейнер языковой модели ALM
Для сборки бинарного контейнера языковой модели необходимо составить файл в формате JSON с описанием своих параметров.
Параметры JSON:
{
"aes": 128,
"name": "Name dictionary",
"author": "Name author",
"lictype": "License type",
"lictext": "License text",
"contacts": "Contacts data",
"password": "Password if needed",
"copyright": "Copyright author"
}
Описание:
- aes — Размер шифрования AES (128, 192, 256) бит
- name — Название словаря
- author — Автор словаря
- lictype — Тип лицензии
- lictext — Текст лицензии
- contacts — Контактные данные автора
- password — Пароль шифрования (если требуется), шифрование производится только при установки пароля
- copyright — Копирайт владельца словаря
Все параметры являются опциональными кроме названия контейнера.
Примеры работы библиотеки ALM
Работа токенизатора
На входе токенизатор получает текст, а на выходе формирует JSON.
$ echo 'Hello World?' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyzабвгдеёжзийклмнопрстуфхцчшщъыьэюя" -method tokens
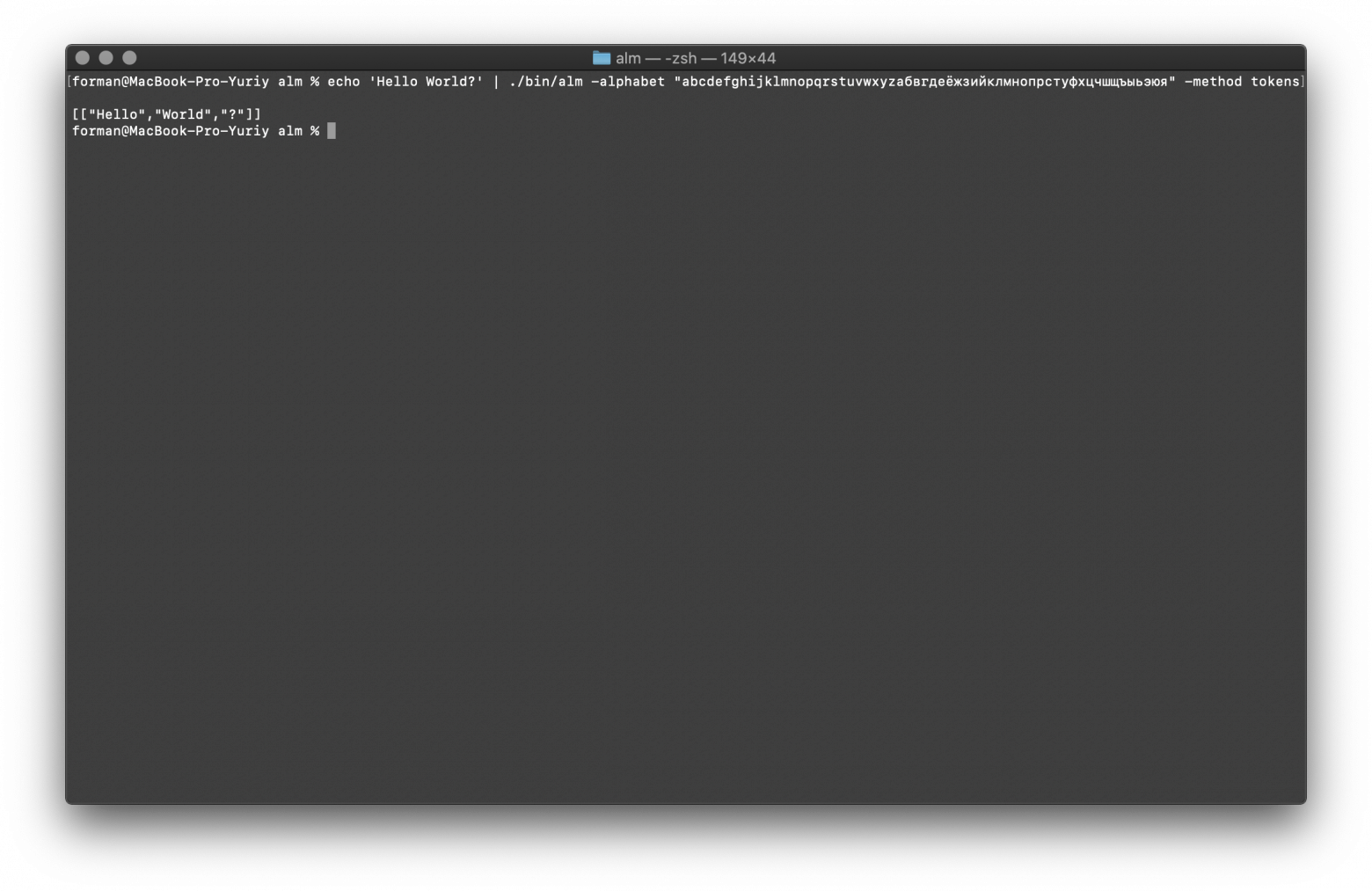
Тест:
Hello World?
Результат:
[
["Hello","World","?"]
]
Попробуем что-то сложнее…
$ echo 'неожиданно из подворотни в Олега ударил яркий прожектор патрульный трактор???с лязгом выкатился и остановился возле мальчика....' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyzабвгдеёжзийклмнопрстуфхцчшщъыьэюя" -method tokens
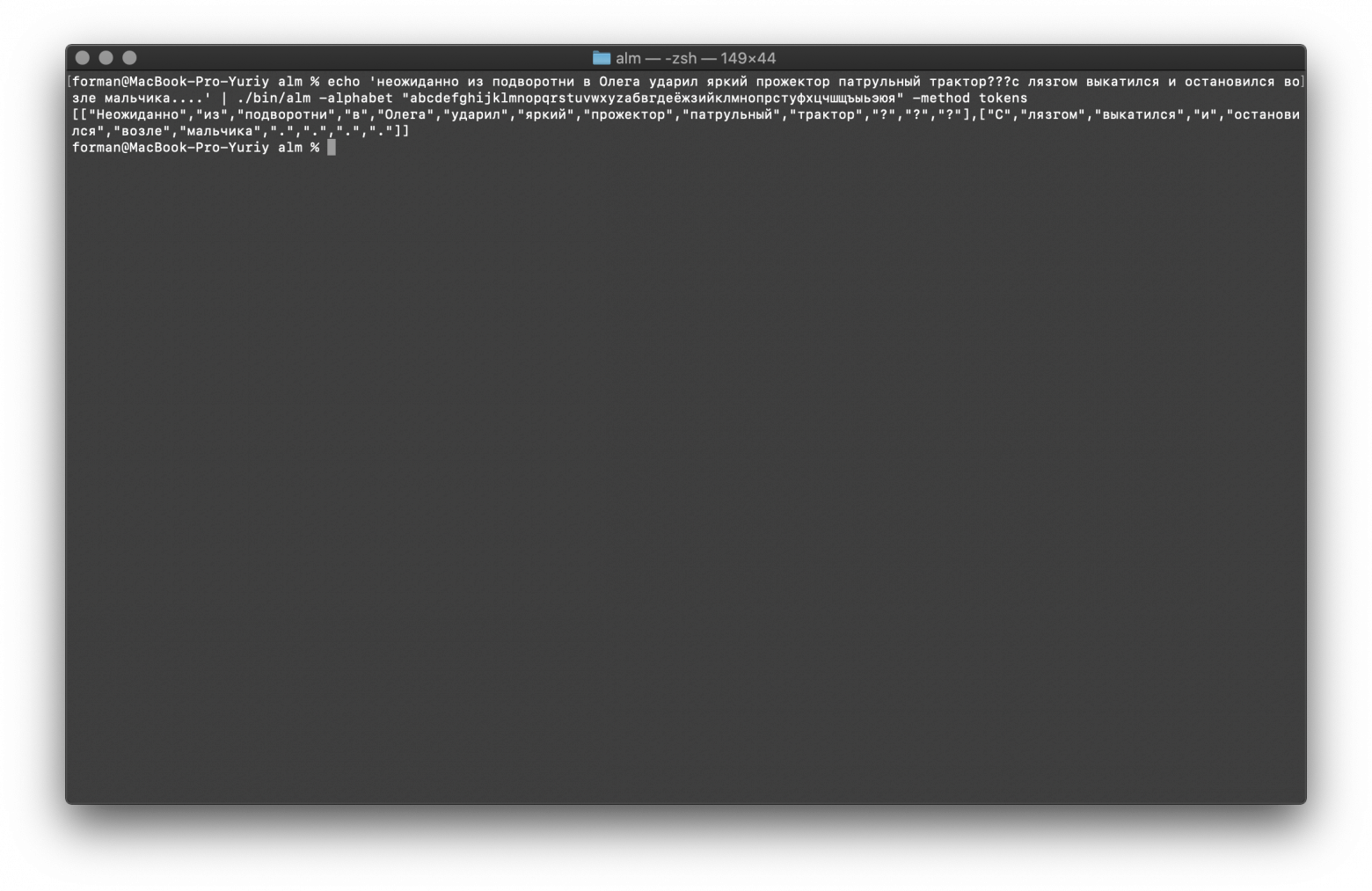
Тест:
неожиданно из подворотни в Олега ударил яркий прожектор патрульный трактор???с лязгом выкатился и остановился возле мальчика....
Результат:
[
[
"Неожиданно",
"из",
"подворотни",
"в",
"Олега",
"ударил",
"яркий",
"прожектор",
"патрульный",
"трактор",
"?",
"?",
"?"
],[
"С",
"лязгом",
"выкатился",
"и",
"остановился",
"возле",
"мальчика",
".",
".",
".",
"."
]
]
Как видите, токенизатор корректно отработал и исправил основные ошибки.
Немного поменяем текст и посмотрим результат.
$ echo 'неожиданно из подворотни в Олега ударил яркий прожектор патрульный трактор...с лязгом выкатился и остановился возле мальчика.' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyzабвгдеёжзийклмнопрстуфхцчшщъыьэюя" -method tokens
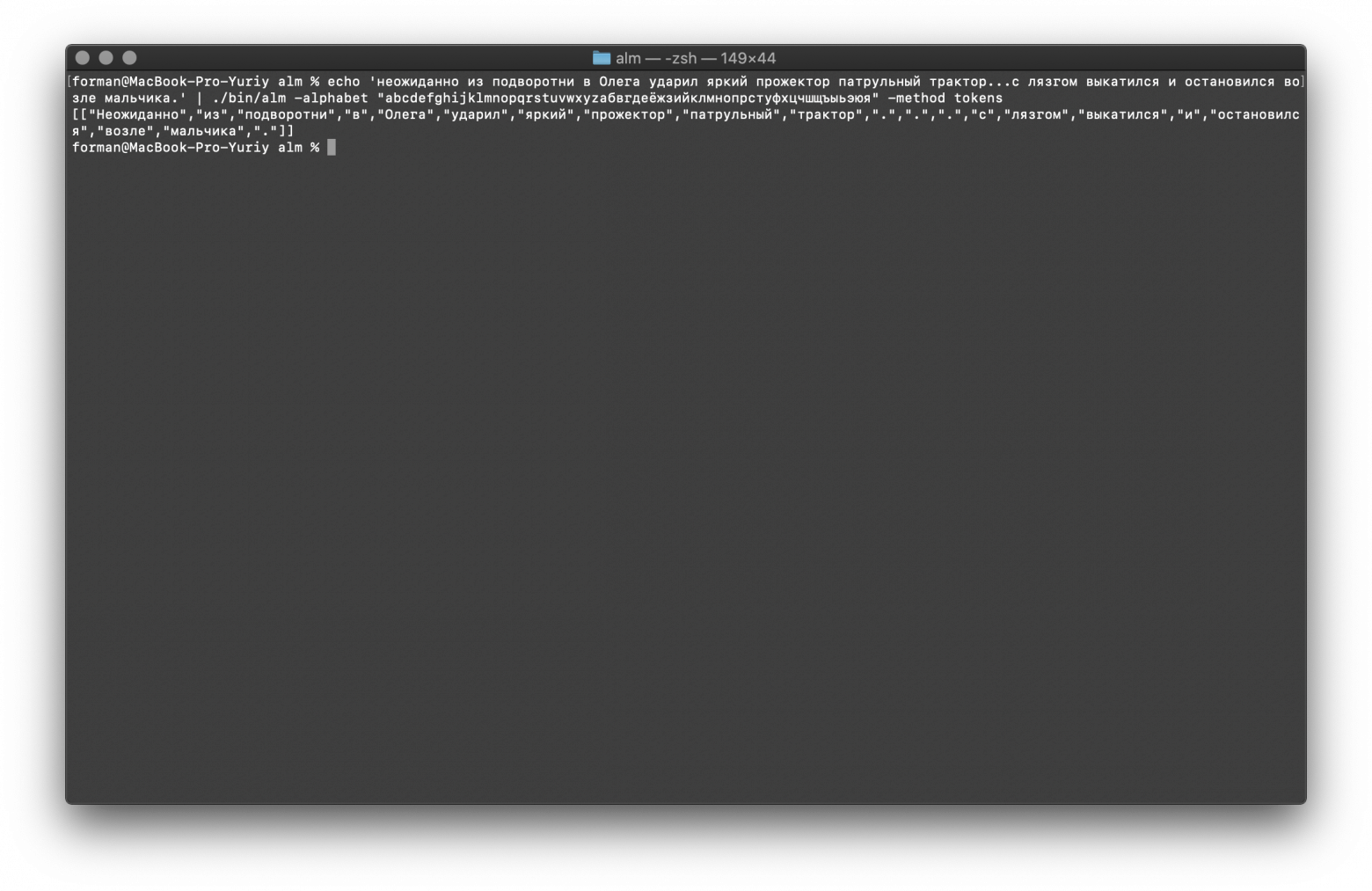
Тест:
неожиданно из подворотни в Олега ударил яркий прожектор патрульный трактор...с лязгом выкатился и остановился возле мальчика.
Результат:
[
[
"Неожиданно",
"из",
"подворотни",
"в",
"Олега",
"ударил",
"яркий",
"прожектор",
"патрульный",
"трактор",
".",
".",
".",
"с",
"лязгом",
"выкатился",
"и",
"остановился",
"возле",
"мальчика",
"."
]
]
Как видим, результат изменился. Теперь попробуем что-то другое.
$ echo 'Контрастный душ в течение 5–7 мин. также может стать простым средством восстановления в процессе тренировки при следующей методике применения: 1 мин. горячая вода ( +37–38°), затем 5–10 сек. – холодная вода ( +12–15°) и т.д.»| |()' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyzабвгдеёжзийклмнопрстуфхцчшщъыьэюя" -method tokens
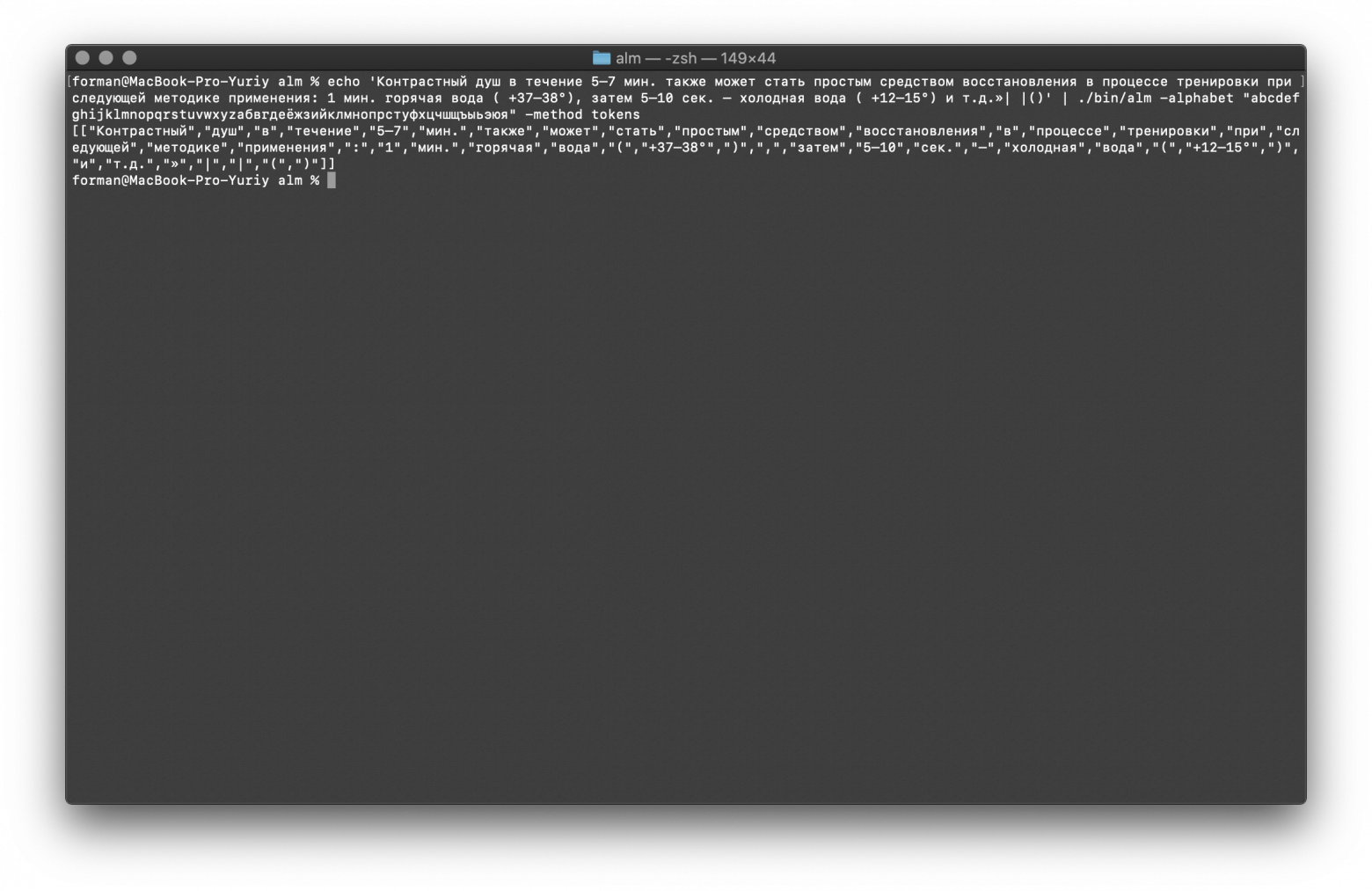
Тест:
Контрастный душ в течение 5–7 мин. также может стать простым средством восстановления в процессе тренировки при следующей методике применения: 1 мин. горячая вода ( +37–38°), затем 5–10 сек. – холодная вода ( +12–15°) и т.д.»| |()
Результат:
[
[
"Контрастный",
"душ",
"в",
"течение",
"5–7",
"мин.",
"также",
"может",
"стать",
"простым",
"средством",
"восстановления",
"в",
"процессе",
"тренировки",
"при",
"следующей",
"методике",
"применения",
":",
"1",
"мин.",
"горячая",
"вода",
"(",
"+37–38°",
")",
",",
"затем",
"5–10",
"сек.",
"–",
"холодная",
"вода",
"(",
"+12–15°",
")",
"и",
"т.д.",
"»",
"|",
"|",
"(",
")"
]
]
Объединим все обратно в текст
Сначала восстановим первый тест.
$ echo '[["Hello","World","?"]]' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyzабвгдеёжзийклмнопрстуфхцчшщъыьэюя" -method tokens

Тест:
[["Hello","World","?"]]Результат:
Hello World?Восстановим теперь более сложный тест.
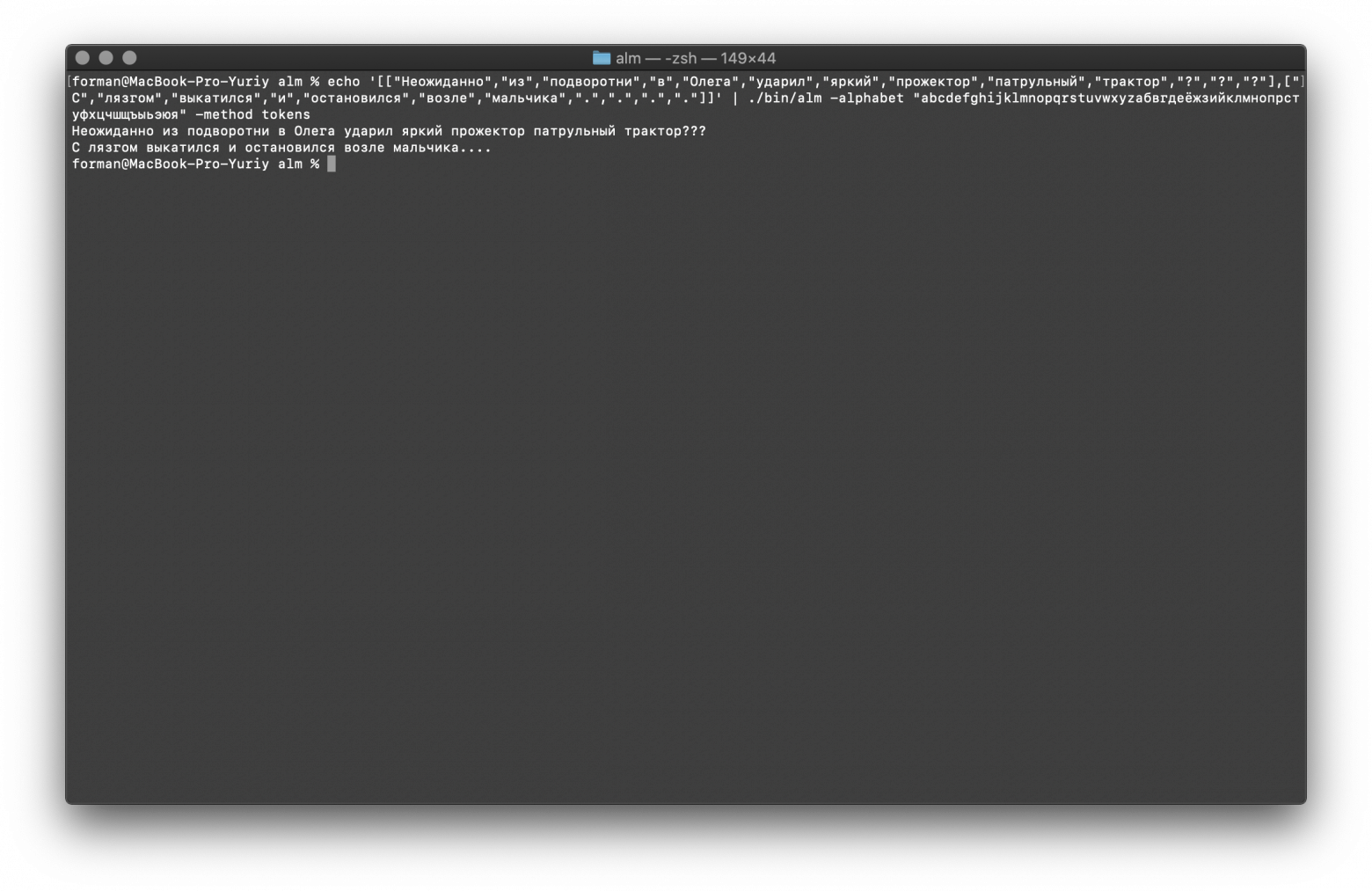
$ echo '[["Неожиданно","из","подворотни","в","Олега","ударил","яркий","прожектор","патрульный","трактор","?","?","?"],["С","лязгом","выкатился","и","остановился","возле","мальчика",".",".",".","."]]' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyzабвгдеёжзийклмнопрстуфхцчшщъыьэюя" -method tokens
Тест:
[["Неожиданно","из","подворотни","в","Олега","ударил","яркий","прожектор","патрульный","трактор","?","?","?"],["С","лязгом","выкатился","и","остановился","возле","мальчика",".",".",".","."]]Результат:
Неожиданно из подворотни в Олега ударил яркий прожектор патрульный трактор???
С лязгом выкатился и остановился возле мальчика….
Как видим, токенизатор смог восстановить сломанный изначально текст.
Продолжаем дальше.
$ echo '[["Неожиданно","из","подворотни","в","Олега","ударил","яркий","прожектор","патрульный","трактор",".",".",".","с","лязгом","выкатился","и","остановился","возле","мальчика","."]]' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyzабвгдеёжзийклмнопрстуфхцчшщъыьэюя" -method tokens

Тест:
[["Неожиданно","из","подворотни","в","Олега","ударил","яркий","прожектор","патрульный","трактор",".",".",".","с","лязгом","выкатился","и","остановился","возле","мальчика","."]]
Результат:
Неожиданно из подворотни в Олега ударил яркий прожектор патрульный трактор... с лязгом выкатился и остановился возле мальчика.
Ну и наконец, проверим самый сложный вариант.
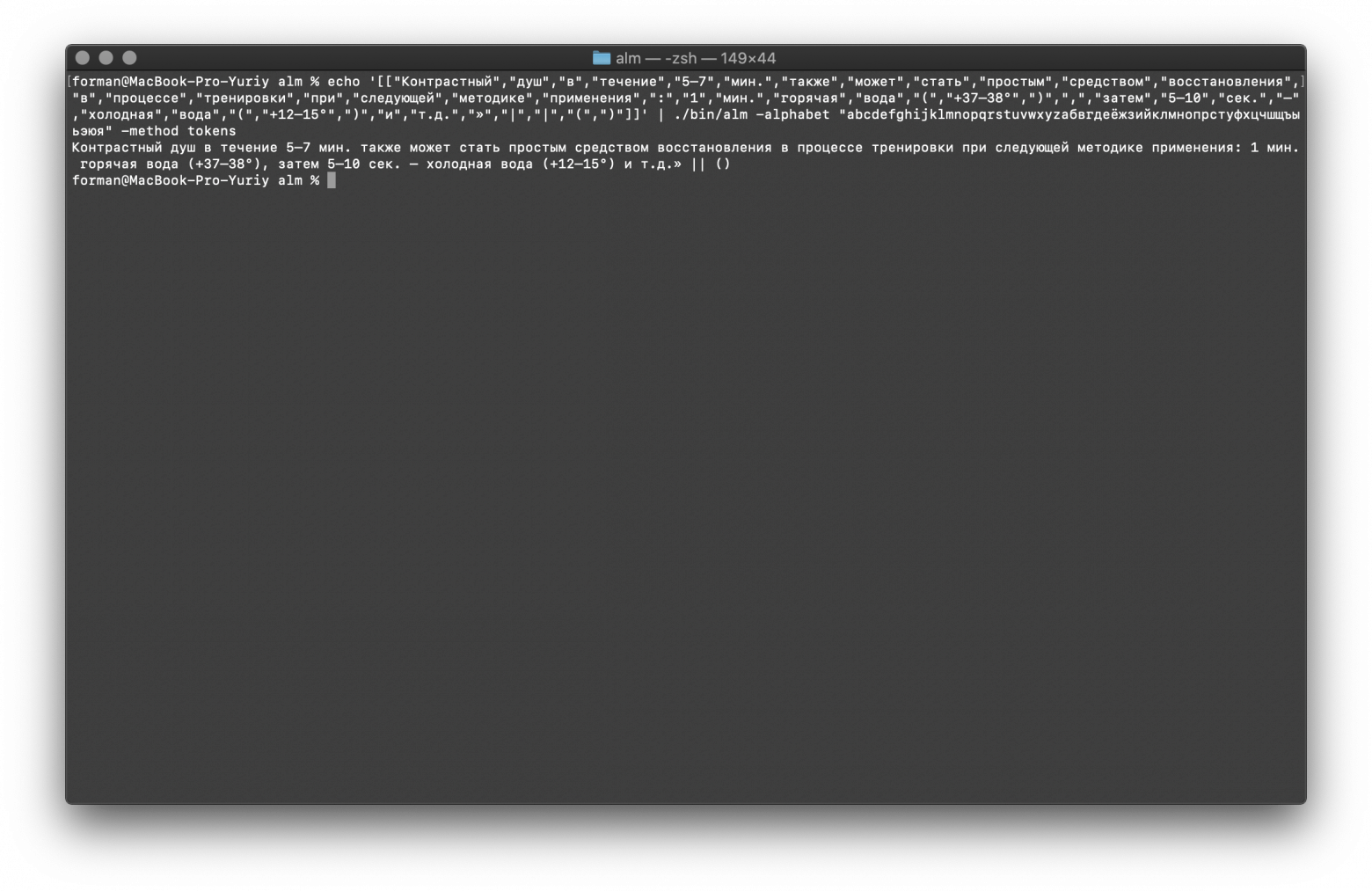
$ echo '[["Контрастный","душ","в","течение","5–7","мин.","также","может","стать","простым","средством","восстановления","в","процессе","тренировки","при","следующей","методике","применения",":","1","мин.","горячая","вода","(","+37–38°",")",",","затем","5–10","сек.","–","холодная","вода","(","+12–15°",")","и","т.д.","»","|","|","(",")"]]' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyzабвгдеёжзийклмнопрстуфхцчшщъыьэюя" -method tokens
Тест:
[["Контрастный","душ","в","течение","5–7","мин.","также","может","стать","простым","средством","восстановления","в","процессе","тренировки","при","следующей","методике","применения",":","1","мин.","горячая","вода","(","+37–38°",")",",","затем","5–10","сек.","–","холодная","вода","(","+12–15°",")","и","т.д.","»","|","|","(",")"]]
Результат:
Контрастный душ в течение 5–7 мин. также может стать простым средством восстановления в процессе тренировки при следующей методике применения: 1 мин. горячая вода (+37–38°), затем 5–10 сек. – холодная вода (+12–15°) и т.д.» || ()
Как видно из полученных результатов, токенизатор может исправить большую часть ошибок оформления текста.
Обучение языковой модели
$ ./alm -alphabet "abcdefghijklmnopqrstuvwxyzабвгдеёжзийклмнопрстуфхцчшщъыьэюя" -size 3 -smoothing wittenbell -method train -debug 1 -w-arpa ./lm.arpa -w-map ./lm.map -w-vocab ./lm.vocab -w-ngram ./lm.ngrams -allow-unk -interpolate -corpus ./text.txt -threads 0 -train-segments
Опишу подробнее параметры сборки.
- size — Размер длины N-граммы (размер установлен в 3 граммы)
- smoothing — Алгоритм сглаживания (алгоритм выбран Witten-Bell)
- method — Метод работы (метод указан обучение)
- debug — Режим отладки (установлен индикатор статуса обучения)
- w-arpa — После обучения будет произведён экспорт языковой модели в файл ARPA
- w-map — После обучения будет произведён экспорт языковой модели в файл MAP
- w-vocab — После обучения будет произведён экспорт словаря в файл VOCAB
- w-ngram — После обучения будет произведён экспорт языковой модели в файл NGRAM
- allow-unk — В языковой модели разрешено использовать тег 〈unk〉
- interpolate — Необходимо при обучении выполнять интерполяцию
- corpus — Адрес текстового корпуса для обучения. Это может быть и текстовый файл, и каталог содержащий текстовые файлы
- threads — Использовать при обучении многопоточность (0 — для обучения будут отданы все доступные ядра процессора, > 0 количество ядер участвующих в обучении)
- train-segments — Обучающий корпус будет равномерно сегментирован по всем ядрам
Более подробную информацию можно получить с помощью флага [-help].
Расчёт перплексии
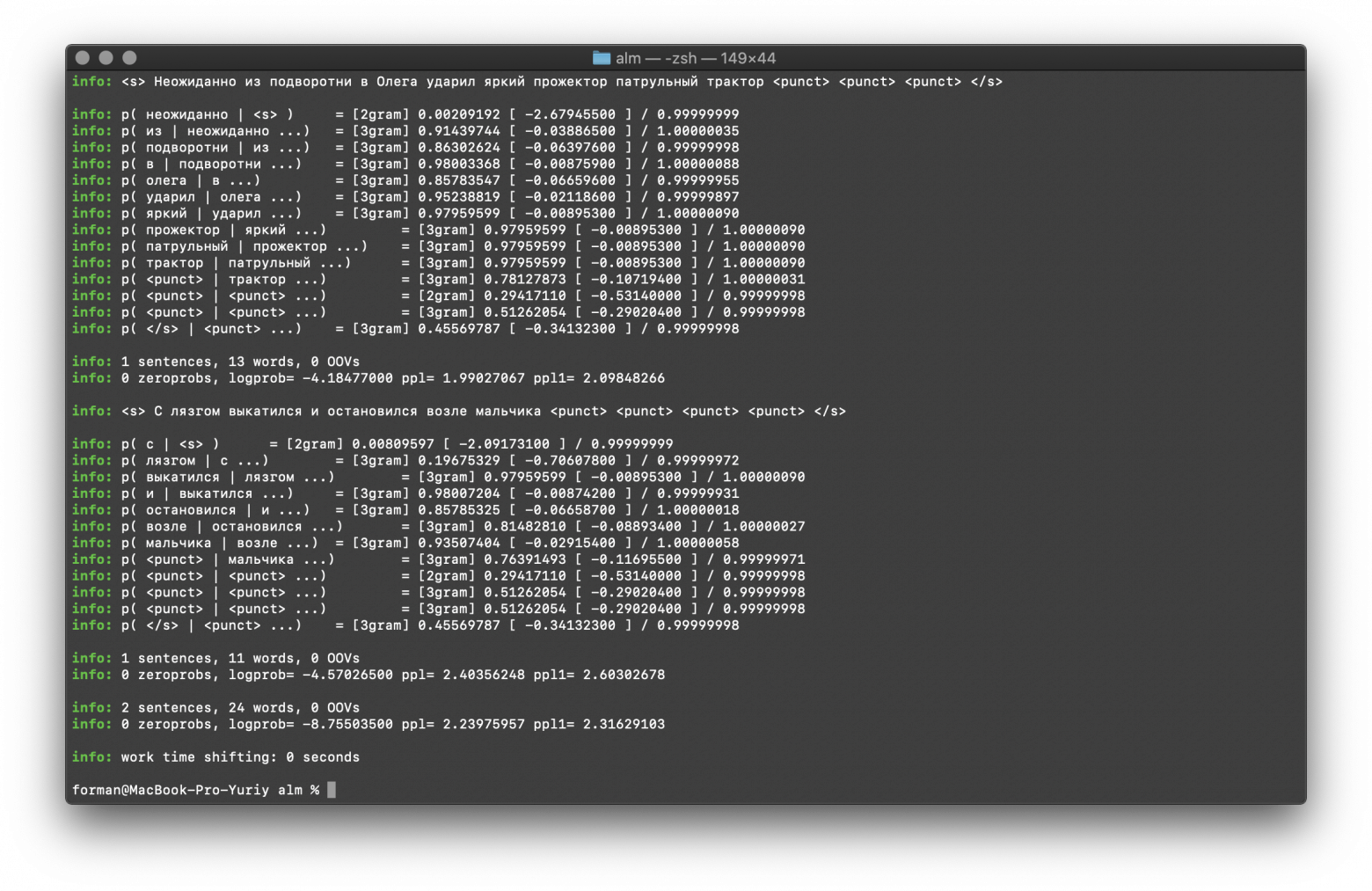
$ echo "неожиданно из подворотни в Олега ударил яркий прожектор патрульный трактор???с лязгом выкатился и остановился возле мальчика...." | ./alm -alphabet "abcdefghijklmnopqrstuvwxyzабвгдеёжзийклмнопрстуфхцчшщъыьэюя" -method ppl -debug 2 -r-arpa ./lm.arpa -confidence -threads 0
Тест:
неожиданно из подворотни в Олега ударил яркий прожектор патрульный трактор???с лязгом выкатился и остановился возле мальчика….
Результат:
info: <s> Неожиданно из подворотни в олега ударил яркий прожектор патрульный трактор <punct> <punct> <punct> </s>
info: p( неожиданно | <s> ) = [2gram] 0.00209192 [ -2.67945500 ] / 0.99999999
info: p( из | неожиданно ...) = [3gram] 0.91439744 [ -0.03886500 ] / 1.00000035
info: p( подворотни | из ...) = [3gram] 0.86302624 [ -0.06397600 ] / 0.99999998
info: p( в | подворотни ...) = [3gram] 0.98003368 [ -0.00875900 ] / 1.00000088
info: p( олега | в ...) = [3gram] 0.85783547 [ -0.06659600 ] / 0.99999955
info: p( ударил | олега ...) = [3gram] 0.95238819 [ -0.02118600 ] / 0.99999897
info: p( яркий | ударил ...) = [3gram] 0.97959599 [ -0.00895300 ] / 1.00000090
info: p( прожектор | яркий ...) = [3gram] 0.97959599 [ -0.00895300 ] / 1.00000090
info: p( патрульный | прожектор ...) = [3gram] 0.97959599 [ -0.00895300 ] / 1.00000090
info: p( трактор | патрульный ...) = [3gram] 0.97959599 [ -0.00895300 ] / 1.00000090
info: p( <punct> | трактор ...) = [3gram] 0.78127873 [ -0.10719400 ] / 1.00000031
info: p( <punct> | <punct> ...) = [2gram] 0.29417110 [ -0.53140000 ] / 0.99999998
info: p( <punct> | <punct> ...) = [3gram] 0.51262054 [ -0.29020400 ] / 0.99999998
info: p( </s> | <punct> ...) = [3gram] 0.45569787 [ -0.34132300 ] / 0.99999998
info: 1 sentences, 13 words, 0 OOVs
info: 0 zeroprobs, logprob= -4.18477000 ppl= 1.99027067 ppl1= 2.09848266
info: <s> С лязгом выкатился и остановился возле мальчика <punct> <punct> <punct> <punct> </s>
info: p( с | <s> ) = [2gram] 0.00809597 [ -2.09173100 ] / 0.99999999
info: p( лязгом | с ...) = [3gram] 0.19675329 [ -0.70607800 ] / 0.99999972
info: p( выкатился | лязгом ...) = [3gram] 0.97959599 [ -0.00895300 ] / 1.00000090
info: p( и | выкатился ...) = [3gram] 0.98007204 [ -0.00874200 ] / 0.99999931
info: p( остановился | и ...) = [3gram] 0.85785325 [ -0.06658700 ] / 1.00000018
info: p( возле | остановился ...) = [3gram] 0.81482810 [ -0.08893400 ] / 1.00000027
info: p( мальчика | возле ...) = [3gram] 0.93507404 [ -0.02915400 ] / 1.00000058
info: p( <punct> | мальчика ...) = [3gram] 0.76391493 [ -0.11695500 ] / 0.99999971
info: p( <punct> | <punct> ...) = [2gram] 0.29417110 [ -0.53140000 ] / 0.99999998
info: p( <punct> | <punct> ...) = [3gram] 0.51262054 [ -0.29020400 ] / 0.99999998
info: p( <punct> | <punct> ...) = [3gram] 0.51262054 [ -0.29020400 ] / 0.99999998
info: p( </s> | <punct> ...) = [3gram] 0.45569787 [ -0.34132300 ] / 0.99999998
info: 1 sentences, 11 words, 0 OOVs
info: 0 zeroprobs, logprob= -4.57026500 ppl= 2.40356248 ppl1= 2.60302678
info: 2 sentences, 24 words, 0 OOVs
info: 0 zeroprobs, logprob= -8.75503500 ppl= 2.23975957 ppl1= 2.31629103
info: work time shifting: 0 seconds
Думаю, тут особо нечего комментировать, поэтому продолжим дальше.
Проверка существования контекста
$ echo "<s> Сегодня сыграл и в Олега ударил яркий прожектор патрульный трактор с корпоративным сектором </s>" | ./alm -alphabet "abcdefghijklmnopqrstuvwxyzабвгдеёжзийклмнопрстуфхцчшщъыьэюя" -method checktext -debug 1 -r-arpa ./lm.arpa -confidence
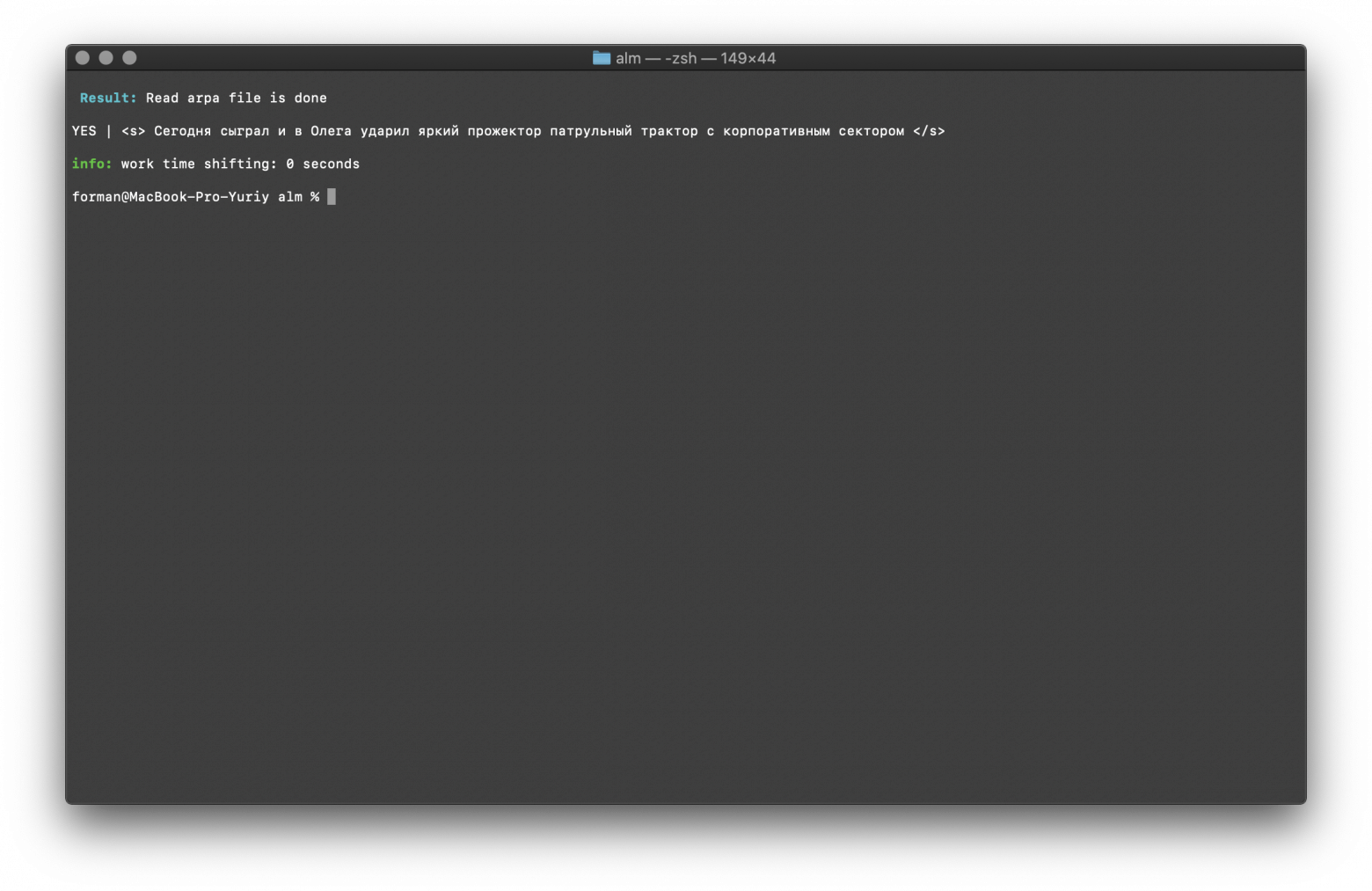
Тест:
<s> Сегодня сыграл и в Олега ударил яркий прожектор патрульный трактор с корпоративным сектором </s>
Результат:
YES | <s> Сегодня сыграл и в Олега ударил яркий прожектор патрульный трактор с корпоративным сектором </s>
Результат показывает, что проверяемый текст имеет верный контекст с точки зрения собранной языковой модели.
Флаг [-confidence] — означает, что языковая модель будет загружена так, как она была собрана, без перетокенизации.
Исправление регистров слов
$ echo "неожиданно из подворотни в Олега ударил яркий прожектор патрульный трактор???с лязгом выкатился и остановился возле мальчика...." | ./alm -alphabet "abcdefghijklmnopqrstuvwxyzабвгдеёжзийклмнопрстуфхцчшщъыьэюя" -method fixcase -debug 1 -r-arpa ./lm.arpa -confidence
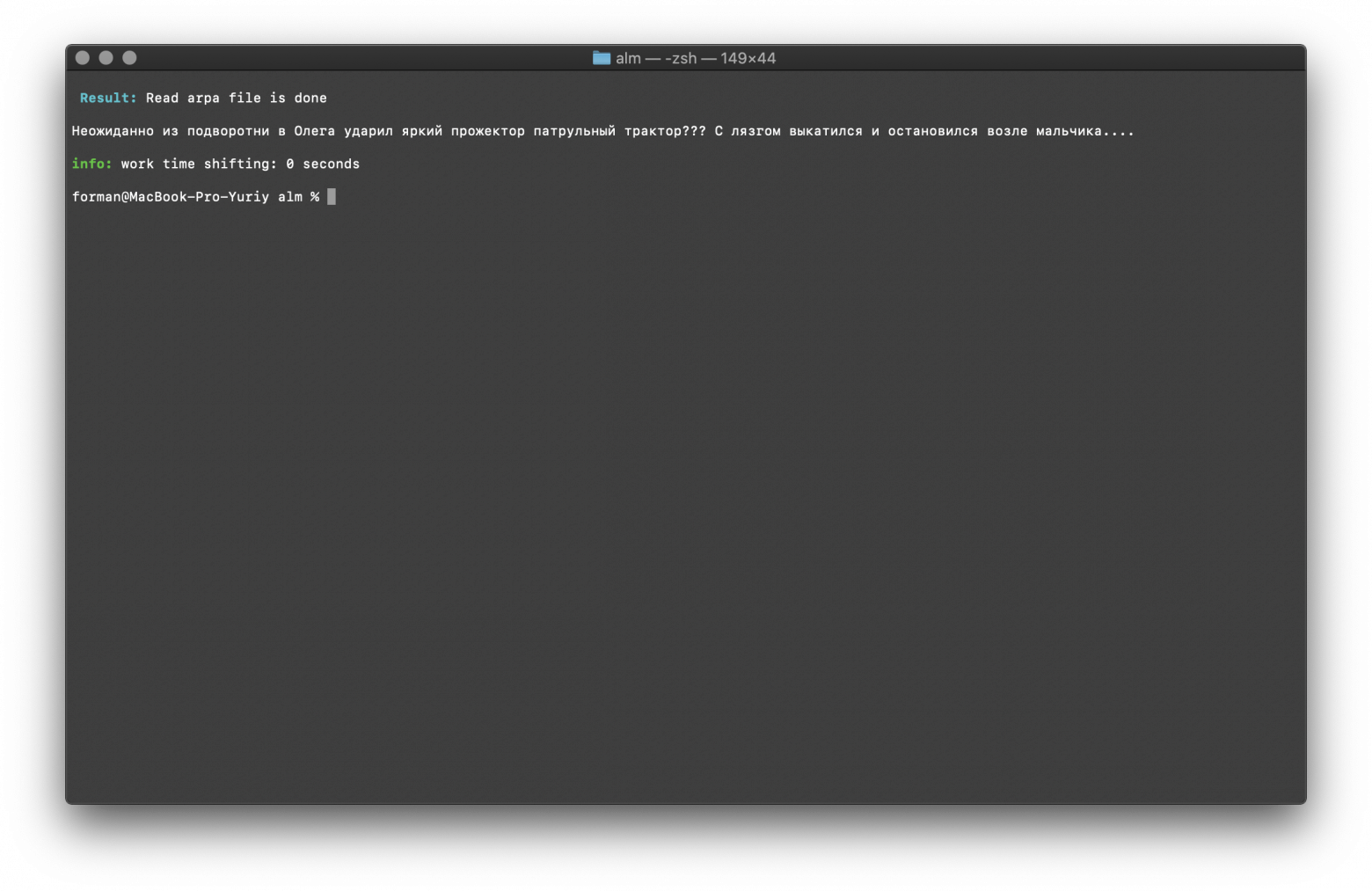
Тест:
неожиданно из подворотни в Олега ударил яркий прожектор патрульный трактор???с лязгом выкатился и остановился возле мальчика....
Результат:
Неожиданно из подворотни в Олега ударил яркий прожектор патрульный трактор??? С лязгом выкатился и остановился возле мальчика....
Регистры в тексте восстанавливаются с учётом контекста языковой модели.
Вышеописанные библиотеки для работы со статистическими языковыми моделями чувствительны к регистру слов. Например, N-грамма «в Москве завтра дождь» не то же самое, что N-грамма «в москве завтра дождь», это совершенно разные N-граммы. Но как быть, если требуется учёт регистров слов и, в то же время, дублировать одни и те же N-граммы нерационально? ALM все N-граммы представляет в нижнем регистре. Тем самым исключается возможность дублирования N-грамм. ALM также ведёт свой рейтинг регистров слов в каждой N-грамме. При экспорте в текстовый формат языковой модели, регистры восстанавливаются в зависимости от их рейтинга.
Проверка количества N-грамм
$ echo "неожиданно из подворотни в Олега ударил яркий прожектор патрульный трактор???с лязгом выкатился и остановился возле мальчика...." | ./alm -alphabet "abcdefghijklmnopqrstuvwxyzабвгдеёжзийклмнопрстуфхцчшщъыьэюя" -method counts -debug 1 -r-arpa ./lm.arpa -confidence
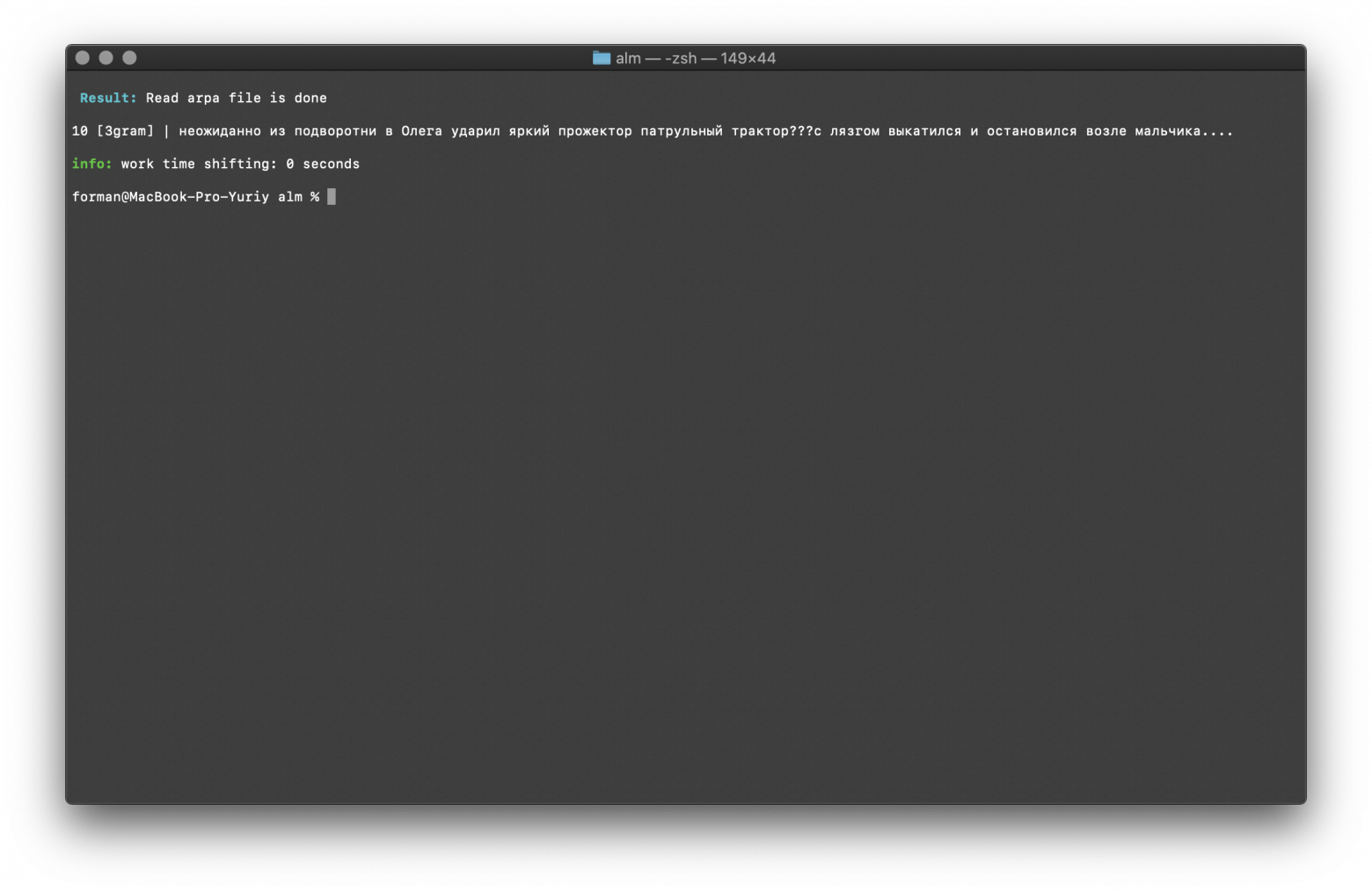
Тест:
неожиданно из подворотни в Олега ударил яркий прожектор патрульный трактор???с лязгом выкатился и остановился возле мальчика....
Результат:
10 [3gram] |
выполняется по размеру N-граммы в языковой модели, есть возможность выполнять проверку по биграммам и триграммам.
Проверка количества N-грамм выполняется по размеру N-граммы в языковой модели. Ещё есть возможность выполнить проверку по биграммам и триграммам.
Проверка по биграммам
$ echo "неожиданно из подворотни в Олега ударил яркий прожектор патрульный трактор???с лязгом выкатился и остановился возле мальчика...." | ./alm -alphabet "abcdefghijklmnopqrstuvwxyzабвгдеёжзийклмнопрстуфхцчшщъыьэюя" -method counts -ngrams bigram -debug 1 -r-arpa ./lm.arpa -confidence

Тест:
неожиданно из подворотни в Олега ударил яркий прожектор патрульный трактор???с лязгом выкатился и остановился возле мальчика....
Результат:
12 [2gram] | неожиданно из подворотни в Олега ударил яркий прожектор патрульный трактор???с лязгом выкатился и остановился возле мальчика….
Проверка по триграммам
$ echo "неожиданно из подворотни в Олега ударил яркий прожектор патрульный трактор???с лязгом выкатился и остановился возле мальчика...." | ./alm -alphabet "abcdefghijklmnopqrstuvwxyzабвгдеёжзийклмнопрстуфхцчшщъыьэюя" -method counts -ngrams trigram -debug 1 -r-arpa ./lm.arpa -confidence
Тест:
неожиданно из подворотни в Олега ударил яркий прожектор патрульный трактор???с лязгом выкатился и остановился возле мальчика....
Результат:
10 [3gram] | неожиданно из подворотни в Олега ударил яркий прожектор патрульный трактор???с лязгом выкатился и остановился возле мальчика….
Поиск N-грамм в тексте
$ echo "Особое место занимает чудотворная икона Лобзание Христа Иудою" | ./alm -alphabet "abcdefghijklmnopqrstuvwxyzабвгдеёжзийклмнопрстуфхцчшщъыьэюя" -method find -debug 1 -r-arpa ./lm.arpa -confidence

Тест:
Особое место занимает чудотворная икона Лобзание Христа Иудою
Результат:
<s> Особое
Особое место
место занимает
занимает чудотворная
чудотворная икона
икона Лобзание
Лобзание Христа
Христа Иудою
Иудою </s>
Список N-грамм, которые найдены в тексте. Пояснять тут особо нечего.
Переменные окружения
Все параметры можно передавать через переменные окружения. Переменные начинаются с префикса ALM_ и должны записываться в верхнем регистре. В остальном названия переменных соответствуют параметрам приложения.
Если одновременно указаны и параметры приложения, и переменные окружения, то приоритет отдаётся параметрам приложения.
$ export $ALM_SMOOTHING=wittenbell
$ export $ALM_W-ARPA=./lm.arpa
Таким образом, можно автоматизировать процесс сборки. Например, через BASH-скрипты.
Заключение
Понимаю, что есть более перспективные технологии вроде RnnLM или Bert. Но уверен, что статистические N-граммные модели еще долго будут актуальными.
На эту работу ушло много времени и сил. Занимался библиотекой в свободное от основной работы время, по ночам и выходным. Тестами код не покрывал, возможны ошибки и баги. Буду благодарен за тестирование. Также я открыт к предложениям по доработке и новому функционалу библиотеки. ALM распространяется под лицензией MIT, что позволяет использовать её практически без ограничений.
Надеюсь получить комментарии, критику, предложения.
Сайт проекта
Репозиторий проекта
