
Многие помнят что сериал «Кремниевая долина» рассказывает о программисте Ричарде
Хендриксе, который случайно придумал революционный алгоритм сжатия данных и решил
построить свой стартап.
Консультанты сериала даже предложили метрику, с помощью которой можно оценивать
подобные алгоритмы – вымышленный коэфициент Вайзмана (Weissman Score).
Далее по сюжету стартап сделал видеочат, используя это решение.
Уважаемому сообществу предлагается к обсуждению другой, совершенно необычный
принцип сжатия данных для аудио и видеозвонков, который решает проблему с новой,
неожиданной стороны.
Если вы хотите поучаствовать в обсуждении этого решения, а также узнать что общего у этой
концепции с Джонатаном Свифтом и произведениями Льва Толстого, прошу под кат.
Немного теории
Опишем в общих чертах как работает современная аудиосвязь – принцип одинаков как для
звонков по GSM сети, так и для мессенджеров и VOIP сетей.
Звуковые колебания поступают на микрофон смартфона, далее в аналого-цифровой
преобразователь (АЦП или ADC):
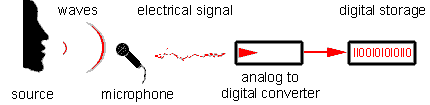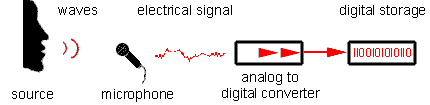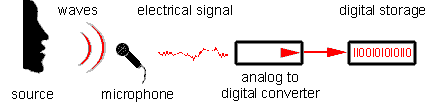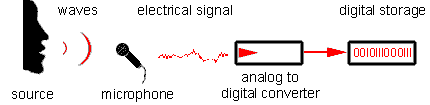
Далее происходит кодирование разнообразными кодеками (G711, G729, OPUS, GSM и т.д.),
добавляется или не добавляется шифрование (SRTP, ZPTP и т.д.) и отправляется в среду
передачи данных.
Например почти все мессенджеры (WhatsApp, Viber и т.д.) пользуются одними и теми же кодеками (в последнее время это как правило Opus), и практически одними и теми же слегка
измененными протоколами ( на основе SIP, WebRTC).
В качестве сети передачи данных может выступать и паблик интернет и GSM сеть или
интранет:
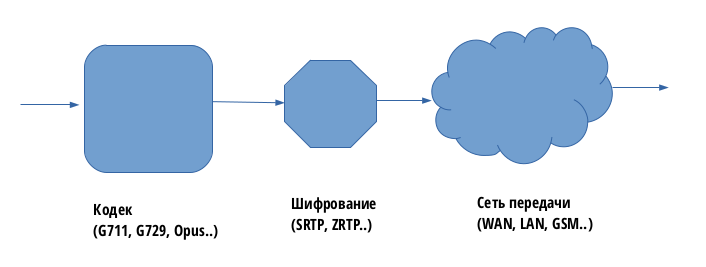
Шифрование – необязательный элемент в этой схеме, например в большинстве случаев для
SIP телефонии шифрование не используется.
А вот в мессенджерах наоборот — как правило используются своих проприеритарные
протоколы для шифрования голоса и видео.
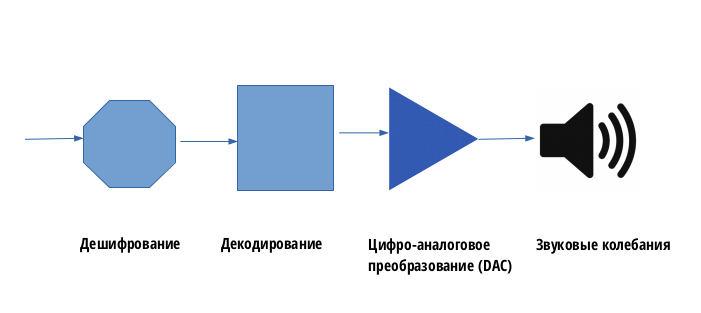
Далее происходит обратный процесс – адресат, получив данные, декодирует полученную информацию, затем сигнал поступает на ЦАП (цифро-аналоговый преобразователь) и потом поступает в звуковой усилитель, подключенный к динамику:
Характеристики современных кодеков:
G.711 64 Кб/сек.
G.726 16, 24, 32 или 40 Кб/ сек.
G.729А 8 Кб/ сек.
GSM 13 Кб/ сек.
iLBC 13.3 Кб/ сек. (30 мс фрейма); 15.2 Кб/ сек. (20 мс фрейма)
Speex Диапазон от 2.15 до 22.4 Кб/ сек.
G.722 64 Кб/сек.
Таким образом например при 7 минутном разговоре по WhatsApp или Скайп будет
израсходовано порядка 1 МБ.
Запомним эти цифры — 1Мб на 7 минут разговора, вскоре они нам понадобятся.
“Лев Толстой как зеркало… революции...”
Давайте вспомним самый знаменитый роман этого великого русского писателя:
«Война́ и мир» — роман-эпопея Льва Николаевича Толстого, описывающий русское
общество в эпоху войн против Наполеона в 1805—1812 годах. Эпилог романа доводит
повествование до 1820 года.
Роману «Война и мир» Л.Н. Толстой посвятил семь лет напряженного и упорного труда.О том, как создавалось одно из крупнейших мировых творений, свидетельствуют рукописи
«Войны и мира»: в архиве писателя сохранилось свыше 5200 мелко исписанных листов.
Если вы сейчас захотите прочитать этот роман, то его можно легко скачать.
И это файл весит всего… 1 МБ:

Форматы fb2 и epub, ровно как и zip, rar в принципе можно рассмартивать как своего рода
кодеки.
Давайте задумаемся – 7 минут нашего разговора по WhatsApp равны по объему трафика
великому произведению, которое писалось 7 лет!
Разговор 7 минут кодировался кодеком opus, роман кодировался ePub, объем один и тот же –
1Мб, но какая колоссальная разница!
Путешествия Гулливера
Все знают это произведение Джонатана Свифта с детства, но на самом деле эта книга не для
детей.
“Путешествия Гулливера” — это политическая сатира для взрослых, конечно в контексте 18
века.
Удивительно то, что Свифт, будучи ярым противником другого своего современника –
Ньютона, в своих “Путешествиях Гулливера” не только предсказал открытие спутников
Марса (с довольно точным описанием их характеристик), но и описал довольно интересный
способ коммуникаций между людьми:
“… проект требовал полного упразднения всех слов;
автор этого проекта ссылался главным образом на его пользу для здоровья и сбережение
времени.
Ведь очевидно, что каждое произносимое нами слово сопряжено с некоторым изнашиванием
легких и, следовательно, приводит к сокращению нашей жизни.
А так как слова суть только названия вещей, то автор проекта высказывает предположение,
что для нас будет гораздо удобнее носить при себе вещи, необходимые для выражения наших
мыслей и желаний.
… многие весьма ученые и мудрые люди пользуются этим новым способом выражения своих
мыслей при помощи вещей.
Единственным его неудобством является то обстоятельство, что, в случае необходимости
вести пространный разговор на разнообразные темы, собеседникам приходится таскать на
плечах большие узлы с вещами, если средства не позволяют нанять для этого одного или
двух дюжих парней. Мне часто случалось видеть двух таких мудрецов, изнемогавших под
тяжестью ноши, подобно нашим торговцам вразнос. При встрече на улице они снимали с
плеч мешки, открывали их и, достав оттуда необходимые вещи, вели таким образом беседу в
продолжение часа; затем складывали свою утварь, помогали друг другу взваливать груз на
плечи, прощались и расходились.
Впрочем, для коротких и несложных разговоров можно носить все необходимое в кармане
или под мышкой, а разговор, происходящий в домашней обстановке, не вызывает никаких
затруднений. Поэтому комнаты, где собираются лица, применяющие этот метод, наполнены
всевозможными предметами, пригодными служить материалом для таких искусственных
разговоров.
Другим великим преимуществом этого изобретения является то, что им можно пользоваться
как всемирным языком, понятным для всех цивилизованных наций, ибо мебель и домашняя
утварь всюду одинакова или очень похожа, так что ее употребление легко может быть понято.
Таким образом, посланники без труда могут говорить с иностранными королями или
министрами, язык которых им совершенно неизвестен...”
Итак, вы наверное уже догадываетесь к чему я веду :)
Зачем передавать сотрясения воздуха (звуки) на многие сотни и тысячи километров,
заморачиваться с кодированием (для того чтобы как можно точнее и качественнее передать эти сотрясения воздуха адресату), держать необходимую полосу пропускания, если смысловая
нагрузка этой передачи – минимальна, а то и вовсе стремится к нулю?
Ведь люди коммуницируют между собой не звуками, а значением, контентом, семантикой, мыслями…
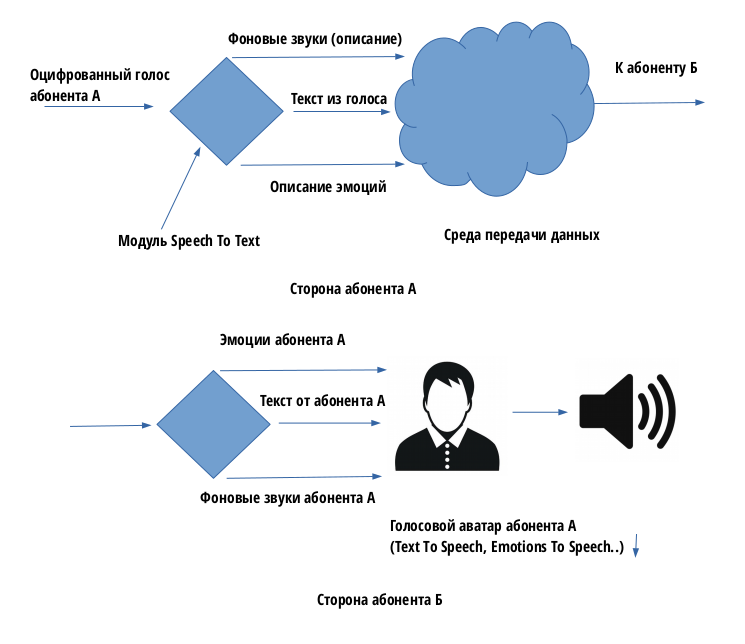
Концепт новой системы коммуникации довольно прост – на стороне источника А звуковые
колебания также оцифровываются, но не передаются сразу же другой стороне, а
преобразуются в текст (Speech To Text) и далее передается уже осмысленный текст от
абонента А, который:
- может быть передан с минимальной требуемой полосой передачи данных (возможна даже радиосвязь типа КВ и т.д.)
- может быть зашифрован любым сильными алгоритмом шифрования
На стороне Б полученные сообщения расшифровываются и воспроизводятся уже как голос от
абонента А (Text To Speech).
Также можно загрузить на стороне Б т.н. голосовой аватар абонента А, который бы в
точности повторял манеру речи абонента А.
Отдельным каналом можно передавать фоновые шумы и эмоции.
Все тоже самое справедливо и для видеосвязи – тем более отдельные элементы уже давно
существуют в приложениях (разнообразные маски, задний фон в Zoom и т.д.).
Да, есть технические моменты, которые сейчас до конца не реализованы в должном виде –
например критичной будет скорость преобразования Speech To Text, но используя
предиктивные AI алгоритмы преобразования можно эту скорость существенно повысить.
Самое главное преимущество – требуется минимальная полоса пропускания в среде передачи
данных.
Т.е. такой принцип можно использовать не только для обычных повседневных
коммуникаций, но также и для военных и для дальней связи с большими задержками
(космическая связь, межпланетная – Луна, Марс и т.д. :) )
Хотя это и описание концепта, но на самом деле в одном нашем проекте уже несколько
месяцев используется прототип с этим принципом.
Но об этом в следующий раз…
