When Alex Garland’s series Devs (on FX and Hulu) came out this year, it gave developers their own sexy Hollywood workup. Who knew that coders could get snarled into murder plots and love triangles just for designing machine learning programs? Or that their software would cause a philosophical crisis? Sure, the average day of a developer is more code writing than murder but what a thrill to author powerful new program.

Machine learning, big data and AI advancements seem like a giant leap forward both for technology and human experience. In 2017 CEO’s of major companies told MIT’s Sloan Management Review that AI, machine learning and big data will be the biggest disruptions (in a good way!) of the future.

Already the big 3 are revolutionizing industries. For example, Metlife uses these machine learning to improve speech recognition so doctors can file their patient notes in real time. Medical offices can now transfer information faster to improve decision-making and care. B2C corporations use it to analyze audiences for engagement and leverage marketing to reduce time and money on intermittent customers. B2B corporations want to analyze the massive data they collect, so they hire developers to create programs that anticipate their clients’ needs before anyone sends an order. Imagine how that might have played in the COVID 19 crisis, if manufacturers saw Google searches or subtle demand spikes for certain products. What if software helped them "identify new local suppliers" so they could pivot production within hours instead of weeks.
So it may not sound sexy to say that every development towards openness and transcendence in SDKs is transformative, but it is. It’s why we should celebrate Microsoft’s development vision to ramp up their Azure SQL partnerships and then to integrate Apache Spark into their .NET offerings.
A Short History of Lakes, Factories, and Analytics
Late in 2019, Microsoft’s Azure SQL Data Warehouse got a snappy new branding, Synapse Analytics. Synapse integrated its Azure Data Lake Storage, Azure Data Factory and the popular Apache Spark. Spark, which began in 2009, is the premier big data framework. It distributes the power to crunch enormous data sets across computers through an API that eases the workload of developers. Developers love Spark because it provides native bindings across Java, Scala, Python and R programming. What was missing was .NET SDK, and Microsoft’s participation in the world of big data processing. That is until recently.
In November 2019, Microsoft released a new version of SQL Server and made it available for Linux, which open-source developers love, and don’t show any signs of abandoning. Working with the open-source community is always a step toward computing transcendence, but also something of a gamble. It offers growth and feedback from developers but also reduces ownership (thus it may affect profit). Yet when companies like Microsoft choose to transcend, everyone benefits. This time, the improvements in SQL Server 2019, which dovetailed with Azure Synapse Analytics, laid the foundation for opening up to .NET frameworks. For the time being, it empowers .NET 3.1 but when .NET 5 is released later this year, Microsoft’s capacities will expand further. .NET 5 will be a unified code with new technology enhancements.
Microsoft Moves In with Apache Spark
The 2019 integration of Azure SQL Data Warehouse (2015-2018) with other services, including data warehouse, data lake, machine learning, and data pipelines allows the data bricks to be bound together. Here’s how it works: Spark tables are queryable without code calling for the creation of an external table. This works at the provisioning of a Synapse cluster. The Azure Data Lake Storage (ADLS) now stores Spark SQL tables and requisitions those along with native ADLS tables. The engines powering this query integrate with Apache Parquet as well. Furthermore, Azure Synapsis accommodates the development and execution of non-C# or other languages such as Python, Scala and native Spark SQL. The integration improves Synapse's ability to manage machine learning (it works with Spark Mllib), and makes Synapse’s studio competitive with AWS (Amazon Web Services).
Apache Spark and .NET
What the world needs is for every major coding language to marry Apache Spark to its own popular frameworks. Why? Because Spark eclipses all other software for big data crunching and machine learning. Apache Spark maintains a reputation for speed compared to other software programs. It offers in-memory functions. It supports SQL along with real-time data and graph processing. If organizations need machine learning, Apache Spark enables it. It’s hard to name an industry that doesn’t employ Apache Spark. Think financial institutions, gaming, telecoms, tech giants, and government sources, which brings us to .NET news. Microsoft announced .NET for Apache Spark with bindings for C# and F# languages.
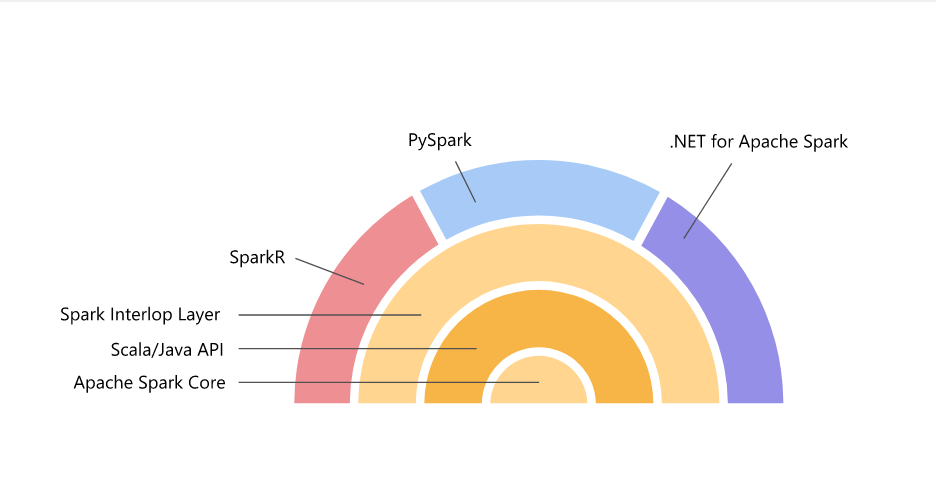
Considering that twenty years of lines of .NET code could be unified with big data through this move, the evolution of Microsoft’s once soiled systems are crumbling. This is the opposite of an empire crumbling. Rather it’s a case study in how to build longevity and power so that one of the leading empires of software can remain powerful in the fast-changing software geography. What does this mean for .NET based software systems? First, big data analysis, with the power to stream data and enhance machine learning cannot be ignored. We live in a data-driven, data-science culture. Data science improves every enterprise. The integration of Apache Spark with .NET makes it pop. ZDNet reports that it “seems to be more than just a bundling of the open-source big data analytics framework.” It’s a “true” integration.
2020 Developments | Microsoft
In Spring 2020, Microsoft added support of in-memory .NET Dataframes for and created Spark.NET. In-memory functions allow for faster management, return, and analysis of big data sets. Spark.NET boasts new convenience APIs specifically for two kinds of user-defined functions (UDFs): vector and scalar. Spark works through Arrow format, which standardizes a language-independent format for working with data in-memory. The two new APIs should speed up serialization and make data transfers more efficient. Because of these APIs, Spark.NET eliminates the overhead of converting data in and out of formats to process. Also, the APIs for vector and scalar can reduce lines of code for .NET developers to write.
In Microsoft’s blog, Brigit Murtaugh provides several examples of how the new API’s will make for cleaner code and more efficient programs. But that’s not all that Microsoft has done to make Spark.NET accessible to coders. Andrew Brust, developer and writer for ZDNet, gives a solid run-down of all the ways that Microsoft makes it easy for developers to fire up Spark.NET. First, Microsoft provides robust onboarding guidance. Framework installation support leads to the creation of a sample application and running it. It guides developers through the required dependencies to install, the configuration steps for the framework, then the installation of Spark.NET, including the creation and execution of the Spark sample application. This is a ten- minute process. Developers who prefer to work in Visual Studio can access Spark.NET as well.
What’s not to love? No one was murdered in the making of this union. I’m sure there’s healthy jealousy about which language and framework is best, but I cannot prove any love triangles have estranged actual humans. While .NET’s integration with Apache Spark may not solve the philosophical conundrum of determinism, it does move forward functions and capacities that transform a multitude of industries. With thousands of .NET code, now those programs can leverage the efficiency and power of big data to make transcendental changes to the industry.
