This is a fourth article in the series of works (see also first one, second one, and third one) describing Machine Learning system based on Lattice Theory named 'VKF-system'. The program uses Markov chain algorithms to generate causes of the target property through computing random subset of similarities between some subsets of training objects. This article describes bitset representations of objects to compute these similarities as bit-wise multiplications of corresponding encodings. Objects with discrete attributes require some technique from Formal Concept Analysis. The case of objects with continuous attributes asks for logistic regression, entropy-based separation of their ranges into subintervals, and a presentation corresponding to the convex envelope for subintervals those similarity is computed.

1 Discrete attributes
To encode object with only discrete attributes we need to compute an auxiliary bitset representations of values of each attribute. We assume that an expert is able to relate these values with respect to some 'general/special' partial order. The ordering must form a low semi-lattice after addition the special value 'null' (with shorthand '_' in some cases) to denote a trivial (absent) similarity between values of the given attribute of comparable objects.
The representation of whole object is a concatenation of encodings of values of its attributes in some fixed order. Then bit-wise multiplication over long bitset strings reduces to multiplications over values of each attribute. Hence encoding must replace similarity between values by bit-wise multiplication.
Since any low semi-lattice easily converts into a lattice (with additional top element, if it is absent), Formal Concept Analysis (FCA) provides all essential tools.
Modern formulation of Fundamental Theorem of FCA asserts that
For every finite lattice  let
let  be a (super)set of all
be a (super)set of all  -irreducible elements and
-irreducible elements and  be a (super)set of all
be a (super)set of all  -irreducible elements. For
-irreducible elements. For  the sample
the sample  generates the all candidates lattice
generates the all candidates lattice  that is isomorphic to the original lattice .
that is isomorphic to the original lattice .
Element  of lattice is called -irreducible, if
of lattice is called -irreducible, if  and for all
and for all 
 and
and  imply
imply  .
.
Element of lattice is called -irreducible, if  and for all
and for all  and
and  imply
imply  .
.
The lattice below contains red vertices as -irreducible elements and blue vertices as -irreducible ones.
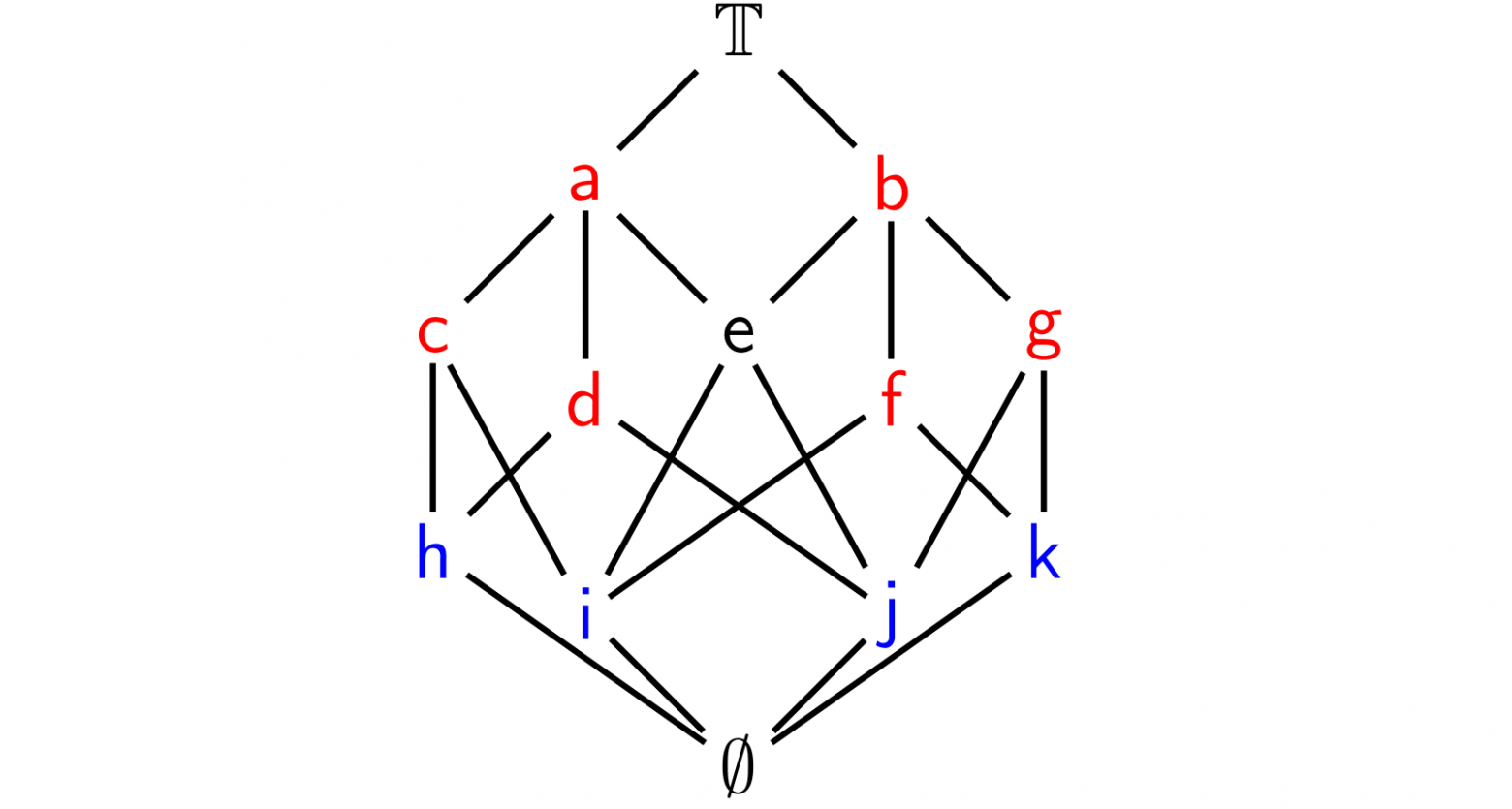
Fundamental theorem (initially proved by Prof. Rudolf Wille through the sample  ) implies minimal sample of the form
) implies minimal sample of the form
| G\M | h | i | j | k |
|---|---|---|---|---|
| a | 1 | 1 | 1 | 0 |
| b | 0 | 1 | 1 | 1 |
| c | 1 | 1 | 0 | 0 |
| d | 1 | 0 | 1 | 0 |
| f | 0 | 1 | 0 | 1 |
| g | 0 | 0 | 1 | 1 |
to generate the lattice of all the candidates that is isomorphic to the original lattice.
Note, that the Wille's sample uses 121 bites, and the new one needs only 24 bites!
The author proposed the following algorithm to encode values by bitsets:
- Topological sort of elements of the semi-lattice.
- In the matrix of order
 look for columns that coincide with bit-wise multiplication of previous ones (every such column corresponds to -reducible element).
look for columns that coincide with bit-wise multiplication of previous ones (every such column corresponds to -reducible element). - All founded (-reducible) columns are removed.
- Rows of remaining matrix form codes of the corresponding values.
This algorithm is a part of both 'vkfencoder' (as vkfencoder.XMLImport class constructor) and 'vkf' (as vkf.FCA class constructor) CPython libraries. The difference is sources: vkf.FCA reads a MariaDB database table and vkfencoder.XMLImport reads an XML file.
2 Continuous attributes
We discuss steps of encodings of continuous attributes case in the order of their inventions. At first, we apply an idea of C4.5 system of decision trees learning to separation of variable's domain into subintervals through entropy considerations.
After that we encode appearance of value in some subinterval by bitset in such a way that bit-wise multiplication corresponds to convex envelope of compared subintervals.
At last, we consider how to combine several attributes to obtain their disjunction and implications. The key is to compute logistic regression between them.
2.1 Entropy approach
When we have a continuous attribute its range must be separated into several subintervals of possible different influence on the target property. To choose correct thresholds we relate this attribute and the target property through entropy.
Let  be a disjoint union of training examples and counter-examples
be a disjoint union of training examples and counter-examples  . Interval
. Interval  of values of continuous attribute
of values of continuous attribute  generates three subsets
generates three subsets 
 , and
, and
 .
.
Entropy of interval of values of continuous attribute is

Mean information for partition  of interval of values of continuous attribute is
of interval of values of continuous attribute is

Threshold is a value  with minimal mean information.
with minimal mean information.
For continuous attribute denote  by
by  and let
and let  be an arbitrary number greater than
be an arbitrary number greater than  .
.
Thresholds  are computed sequentially by splitting the most entropy subinterval.
are computed sequentially by splitting the most entropy subinterval.
2.2 Bitset encodings for convex envelope
We represent continuous attribute value by bitset string of length  , where
, where  is a number of thresholds. Bitset may be considered as a string of indicator (Boolean) variables
is a number of thresholds. Bitset may be considered as a string of indicator (Boolean) variables

where  .
.
Then string  is a bitset representation of continuous attribute
is a bitset representation of continuous attribute  on element
on element  .
.
The next Lemma asserts that the result of bit-wise multiplication of bitset representations is convex envelope of its arguments' intervals.
Let  represent
represent  and
and  represent
represent  . Then
. Then

corresponds to  .
.
Note that the trivial similarity  corresponds to the trivial condition
corresponds to the trivial condition  .
.
2.3 Relations between continuous attributes
The FCA-based approach to Machine Learning naturally considers a conjunction of several binary attributes as a possible cause of the target property. In the case of discrete attribute an expert has opportunity to express disjunction of the values through additional values (see lattice structures in paragraph 1). The case of continuous attributes is different. So we need some technique to include this case too.
The key was the following Lemma
The disjunction of propositional variables  is equivalent to satisfaction of inequality
is equivalent to satisfaction of inequality  for any
for any  .
.
Since we restrict ourselves to two target classes, we look for a classifier
Classifier is a map  R
R , where
, where  is a domain of objects to classify (described by
is a domain of objects to classify (described by  continuous attributes) and
continuous attributes) and  are the target labels.
are the target labels.
As usual, we assume the existence of some probability distribution of  which can be decomposed as
which can be decomposed as

where  is a marginal distribution of objects and
is a marginal distribution of objects and  is a conditional distribution of labels on given object, i.e. for every
is a conditional distribution of labels on given object, i.e. for every  the following decomposition
the following decomposition

holds.
Error probability of classifier  is
is

Bayes classifier  with respect to
with respect to
corresponds to

We remind well-known Theorem on optimality of Bayes classifier
The Bayes classifier  has the minimal error probability:
has the minimal error probability:
![$ \forall{c:\textbf{R}^{d}\to\lbrace{0,1}\rbrace}\left[R(b)=\textbf{P}\lbrace{b(\vec{X})\neq{K}}\rbrace\leq{R(c)}\right] $](https://habrastorage.org/getpro/habr/formulas/3b2/81c/ce7/3b281cce77af34cfbc084d9cae41b616.svg)
Bayes Theorem implies

where  and
and  is the well-known logistic function.
is the well-known logistic function.
2.4 Logistic regression between attributes
Let approximate unknown by linear combination  of basis functions
of basis functions  (
( ) with respect to unknown weights
) with respect to unknown weights  .
.
For training sample  introduce signs
introduce signs  . Then
. Then
![$ \log\lbrace{p(t_{1},\dots,t_{n}\mid\vec{x}_{1},\ldots,\vec{x}_{n},\vec{w})}\rbrace=-\sum_{j=1}^{n}\log\left[1+\exp\lbrace{-t_{j}\sum_{i=1}^{m}w_{i}\varphi_{i}(\vec{x}_{j})}\rbrace\right]. $](https://habrastorage.org/getpro/habr/formulas/b98/339/0cd/b983390cd4d07ed53f58aca73e8046af.svg)
Hence the logarithm of likelihood
![$ L(w_{1},\ldots,w_{m})=-\sum_{j=1}^{n}\log\left[1+\exp\lbrace{-t_{j}\sum_{i=1}^{m}w_{i}\varphi_{i}(\vec{x}_{j})}\rbrace\right]\to\max $](https://habrastorage.org/getpro/habr/formulas/8dd/ad1/27e/8ddad127e0d499fd04f92371cec1348b.svg)
is concave.
Newton-Raphson method leads to iterative procedure

With help of  we obtain
we obtain

where  is diagonal matrix with elements
is diagonal matrix with elements
 and
and  is vector with coordinates
is vector with coordinates  .
.

where  are iterative calculated weights.
are iterative calculated weights.
As usual, the ridge regression helps to avoid ill-conditioned situation

In the computer program 'VKF system' we use standard basis: constant 1 and attributes themselves.
At last, we need a criterion for significance of regression. For logistic regression two types of criteria were applied:
Criterion of Cox-Snell declares attribute  significant, if
significant, if

McFadden criterion declares attribute significant, if

Conclusion
The 'VKF-system' was applied to Wine Quality dataset from Machine Learning repository (University California Irvine). The experiments demonstrated the prospects of the proposed approach. For high-quality red wines (with rating >7), all examples were classified correctly.
The disjunction situation (from paragraph 2.3) arose with 'alcohol' and 'sulphates' relationship. Positive (although slightly different) weights correspond to different scales of measurement of different attributes, and the threshold was strictly between 0 and 1. The situation with 'citric acid' and 'alcohol' was similar.
The situation with the pair ('pH', 'alcohol') was radically different. The weight of 'alcohol' was positive, whereas the weight for 'pH' was negative. But with an obvious logical transformation we get the implication ('pH'  'alcohol').
'alcohol').
The author would like to thanks his colleagues and students for support and stimulus.
