Я много раз слышал, как программисты смеются над тиммейтами, которые написали медленный код. Резкие, самодовольные фразы в стиле "этот болван четыре раза пробежался по коллекции, хотя можно было один", и тому подобное. Когда слышишь такое, сразу думаешь — ну тут все по делу, зачем делать лишние итерации? Почему нельзя изучить пару элементарных вещей, вроде принципов работы LINQ выражений в C#, и писать нормальный код? Ты смеешься над некомпетентными тупицами до тех пор, пока смеяться не начнут над тобой. И можете мне поверить — никакие знания в программировании не спасут вас от ситуации, когда вы по незнанию зафигачили квадратичный алгоритм вместо линейного.
Я не знаю, смеялся ли кто-то над моим кодом, но я точно уверен — не раз и не два я писал решение, которое было в сто раз медленнее, чем могло бы быть. Но в этих случаях я сознательно писал неоптимально. Например в C# есть цикл for, и есть метод коллекции Select (в других япах он чаще называется map). Цикл быстрее, но я считаю функциональный подход более эстетичным — и использую его. Я знаю, что данных мало, тут не будет ботлнека, и пишу код, который по-моему красивей, читабельней и потому лучше. Таких решений при разработке очень много — и я выбираю писать производительный код только когда точно знаю, что иначе просадки станут проблемой.
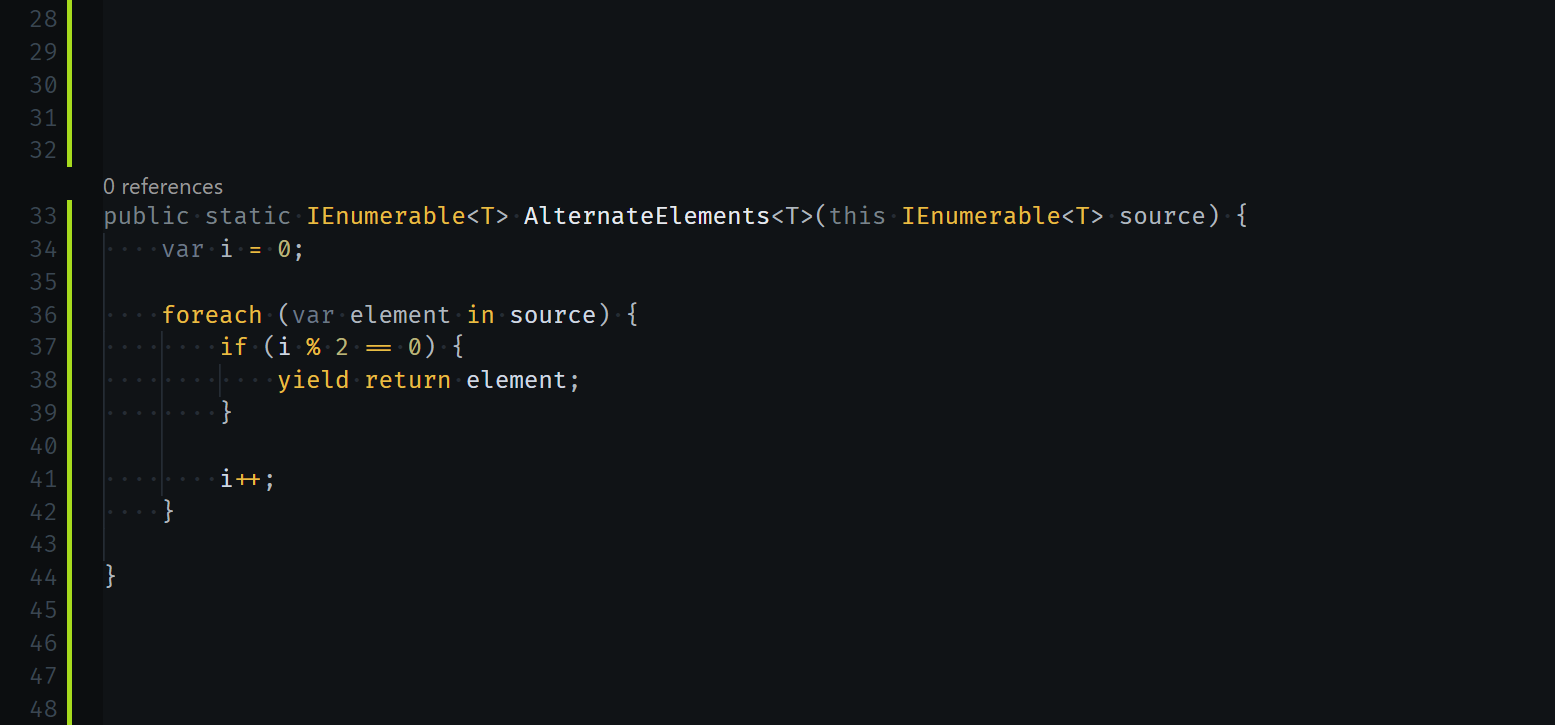
Есть очень много разрабов, которые делают по-другому, и искренне считают, что такие как я — дерьмовые инженеры. У меня есть друг, опытный разраб высокого класса, который на днях выпнул человека с собеса, потому что тот предоставил медленное решение. Задача была — реализовать специфичный LINQ метод. В C# эти методы следует делать ленивыми — через итераторы и yield — а парень просто зафигачил новый список, и стал пихать в него значения, чем сломал ленивость. На больших срезах данных это может создать крупные — и главное неожиданные — просадки в производительности, достаточные, чтобы на доске завелся баг. По большому счету, тут дело даже не в снижении производительности, а в перемещении ботлнека в неожиданное место — не самая приятная хрень.
Я бы никогда не поставил крест на разработчике из-за такого, потому что сам не заморачиваюсь с yield, пока данных не становится по-настоящему много. С новым листом сделать интуитивно проще, принципы работы LINQ я хорошо понимаю. У меня нет задачи писать какой-то совершенный, абсолютно отказоустойчивый код заранее, и даже тогда, когда мне оптимизация ничего не стоит, я не всегда её применю. И я такой не один. В майкрософтской доке по LINQ пример добавления своего метода предложен именно с новым списком — потому что у создателя примера были дела поважнее, чем возиться с итераторами.
Мы позвали в подкаст Андрея Акиньшина — человека, который действительно разбирается в производительности. Создатель BenchmarkDotNet, автор книги Pro .NET Benchmarking, топовый докладчик на темы производительности, поведения рантайма и бенчмаркинга в дотнете, и просто очень, очень, очень крутой инженер. Мой друг, который прогнал человека с собеса — слепой котеночек в вопросах перформанса по сравнению с ним.
Знаете, что нам сказал Андрей? Что эстетика важнее производительности, пока у тебя нет ботлнеков.
Что если тебе больше нравится Select — ты пишешь Select. Потому что когда ты действительно узнаешь, сколько вещей у тебя работают неоптимально, ты перестаешь верить, что сможешь поправить их все, и начинаешь верить, что исправлять их надо только тогда, когда тебе это действительно нужно.
Есть много разрабов, которые с этим согласны. Они даже придумали термин "преждевременные оптимизации" — который как бы намекает, что этого делать не нужно. Ещё мы часто говорим "экономия на спичках". Так мы высмеиваем дурачков, которые тратят кучу времени и сил на то, чтобы сэкономить одну миллионную долю секунды.
И эти спичечники считают, что они крутые парни, а все остальные — вшивые говноделы. Мне есть что им сказать. Если ты взял for вместо select, хотя оба варианта нас устраивают по скорости, то почему ты тогда остановился на этом? Какой ещё C#, братан, C# — это медленно. Давай возьмем C++. А лучше ассемблер. Нет, стоп, ассемблер неоптимален — давай сразу фигачить машинные коды. Эстетика, поддерживаемость, читабельность — это же все х**ня собачья. Важно, чтобы все четыре элемента связного списка были выведены на экран наиболее быстрым способом.
Но машинные коды мы не хотим, потому что на них невозможно делать большие и сложные проекты. Мы хотим приятный, удобный и понятный C#. Его создатели разрулили сто тысяч трейдофов за нас. Мы получили дофига плюшек — надежность, поддерживаемость, инструменты для переиспользования кода — и заплатили за это производительностью. И наши приложения все ещё достаточно быстры, чтобы не думать об этом.
Хорошо, когда скорость и красивость не противоречат друг другу. Если по условиям задачи тебе больше подходит Queue, а не List — взять очередь будет и эстетичнее, и производительнее. Но люди, которым совершенно не интересно быстродействие, никогда об этом не узнают. Вы легко отличите их шарповый код — там везде будут листы.
Идея, что ты не должен оптимизировать свой код заранее понятна и справедлива. Но тут есть одна проблема. Иногда я пишу тормозной код не потому что все обдумал и принял решение — иногда я понятия не имею, как его ускорить. Одно дело, когда сознательно выбираешь эстетику вместо производительности, другое — когда ты ничего не выбираешь, потому что не умеешь делать производительно. Это очень, очень разные вещи.
Все эти понятия — “преждевременные оптимизации”, “экономия на спичках” — создают иллюзию, что оптимизации — штука неважная, и поэтому разрабы могут их не изучать. Такая иллюзия опасна, ведь изучать тонкости рантаймов, устройства ЯПов, алгоритмы и структуры данных — долго и сложно. И если ты выращиваешь поколение разработчиков, которые это не делали — ты получаешь отвратительную инженерную культуру, ужасные, супер медленные инструменты и приложения. И людей, которые в сто раз опаснее спичечников.
За примерами далеко ходить не надо — достаточно просто посмотреть на современных фронтендеров. Большая часть из них, когда увидят "производительность, C#, LINQ" захлопнут эту статью, и не дочитают до этого места. Так что теперь мы можем поговорить, что у них нет никакой инженерной культуры. Они делают самые тормозные вещи в мире — вроде всяких электронов — у них в языке из коробки всего два вида коллекций — они про другие и знать не знают. Их инструменты для билдов и управления пакетами работают так медленно, что после ввода "yarn start" можно смело идти смотреть сериал. Итоговые файлы, которые получаются после компиляции весят раз в сто больше, чем должны были. Создается эффект снежного кома. Как теперь не переучивай их, какую культуру не прививай — с большинством проблем фронтенд инфраструктуры особо ничего и не сделаешь — если только не переписать её с нуля.
Мы не можем забить на производительность совсем — это крайность. Но и сказать, что все должны полностью в ней разбираться, мы тоже не можем. Вопросов перфоманса — бесконечность. Да, окей, я могу запомнить, какие структуры данных для чего подходят, усвоить, какие оптимизации умеет делать конкретный компилятор, и как не наступить в общеизвестные грабли в конкретном ЯПе. Но это самая верхушечка гигантского айсберга. И в мире нет человека, который бы продвинулся в этом направлении достаточно, чтобы с уверенностью писать код без потенциальных проблем с быстродействием. И вот поэтому я говорю про инженерную культуру.
Культура — это когда стремление знать не становится культом, а невозможность познания не ведет к отказу от изучения. Это всегда компромиссы, но осознанные.
Нет ничего страшного, что ты выбрал покрасивее, а не побыстрее. И нет трагедии, когда ты просто не знал, что твое решение — супер неоптимальное. Проблема начинается тогда, когда ты говоришь, что производительность — это чушь, и пусть этим занимаются отдельные люди. Нет братан. Изучать, как можно ускорить код — это не удел перформанс задротов, это часть нашей работы. Когда от твоего нежелания изучать сложные вещи твой код становится и медленным, и уродливым — вот тогда у тебя большие проблемы.
Смотрите мой подкаст
