
Academic data warehouse design recommends keeping everything in a normalized form, with links between. Then the roll forward of changes in relational math will provide a reliable repository with transaction support. Atomicity, Consistency, Isolation, Durability — that's all. In other words, the storage is explicitly built to safely update the data. But it is not optimal for searching, especially with a broad gesture on the tables and fields. We need indices, a lot of indices! Volumes expand, recording slows down. SQL LIKE can not be indexed, and JOIN GROUP BY sends us to meditate in the query planner.
The increasing load on one machine forces it to expand, either vertically into the ceiling or horizontally, by purchasing more nodes. Resiliency requirements cause data to be spread across multiple nodes. And the requirement for immediate recovery after a failure, without a denial of service, forces us to set up a cluster of machines so that at any time any of them can perform both writing and reading. That is, to already be a master, or become them automatically and immediately.
The problem of quick search was solved by installing a number of second storage optimized for indexing. Full-text search, faceted, stemming and blackjack. The second store accepts records from the first table as an input, analyzes and builds an index. Thus, the data storage cluster was supplemented with another cluster for solely for searching purposes. Having similar master configuration to match the overall SLA. Everything is good, business is happy, admins sleep at night… until the machines in the master-master cluster become more than three.
Elastic
The NoSQL movement has significantly expanded the scaling horizon for both small and big data. NoSQL cluster nodes are able to distribute data among themselves so that the failure of one or more of them does not lead to a denial of service for the entire cluster. The cost for the high availability of distributed data was the impossibility of ensuring their complete consistency on the record at each point in time. Instead, NoSQL promotes the eventual consistency. That is, it is believed that once all the data will disperse across the cluster nodes, and they will become consistent eventually.
Thus, the relational model was supplemented with a non-relational one and gave power to many database engines that solve the problems of the CAP triangle with one success or another. Developers got into the hands modent tools to build their own perfect persistence layer — for every taste, budget and profile of the load.
ElasticSearch is a NoSQL cluster with RESTful JSON API on the Lucene engine, open-source, written in Java, that can not only build a search index, but also store the original document. This trick helps to rethink the role of a separate database management system for storing the originals, or even completely abandon it. The end of the intro.
Mapping
Mapping in ElasticSearch is something like a schema (table structure, in terms of SQL), which tells you exactly how to index incoming documents (records, in terms of SQL). Mapping can be static, dynamic, or absent. Static mapping does not allow the schema to change. Dynamic allows you to add new fields. If mapping is not specified, ElasticSearch will make it automatically, receiving the first document for writing. It analyzes the structure of fields, makes some assumptions about the types of data in them, skips through the default settings and writes down. At first glance, this schema-less behavior seems very convenient. But in fact, its more suitable for experiments than for surprises in production.
So, the data is indexed, and this is a one-directional process. Once created, the mapping cannot be changed dynamically as ALTER TABLE in SQL. Because the SQL table stores the original document to which you can attach the search index. And vice-versa in ElasticSearch. ElasticSearch is a search index to which you can attach the original document. That is why the index scheme is static. Theoretically, you could either create a field in the mapping or delete it. But in practice, ElasticSearch only allows you to add fields. An attempt to delete a field leads to nothing.
Alias
The alias is an optional name for the ElasticSearch index. Aliases can be many for a single index. Or one alias for many indices. Then the indices seem to be logically combined and look the same from the outside. Alias is very convenient for services that communicate with the index throughout its lifetime. For example, the pseudonym of products can hide both products_v2 and products_v25 behind, without the need to change the names in the service. Alias is handy for data migration when they are already transferred from the old scheme to the new one, and you need to switch the application to work with the new index. Switching an alias from index to index is an atomic operation. It is performed in one step without data loss.
Reindex API
The data scheme, the mapping, tends to change from time to time. New fields are added, unnecessary fields are deleted. If ElasticSearch plays the role of a single repository, then you need a tool to change the mapping on the fly. For this, there is a special command to transfer data from one index to another, the so-called _reindex API. It works with created or empty mapping of the recipient index, on the server side, quickly indexing in batches of 1000 documents at a time.
The reindexing can do a simple type conversion of the field. For example, long to text and back to long, or boolean to text and back to boolean. But -9.99 to boolean is no longer able, this is not PHP. On the other hand, type conversion is an insecure thing. Service written in a language with dynamic typing may forgive such sin. But if the reindex cannot convert the type, the whole document will not be saved. In general, data migration should take place in 3 stages: add a new field, release a service with it, remove the old field.
A field is added like this. Take the scheme of the source-index, insert new property, create empty index. Then, start the reindexing:
{ "source": { "index": "test" }, "dest": { "index": "test_clone" } }
A field is removed like this. Take the scheme of the source-index, remove the field, create empty index. Then, start the reindexing with the list of fields to be copied:
{ "source": { "index": "test", "_source": ["field1", "field3"] }, "dest": { "index": "test_clone" } }
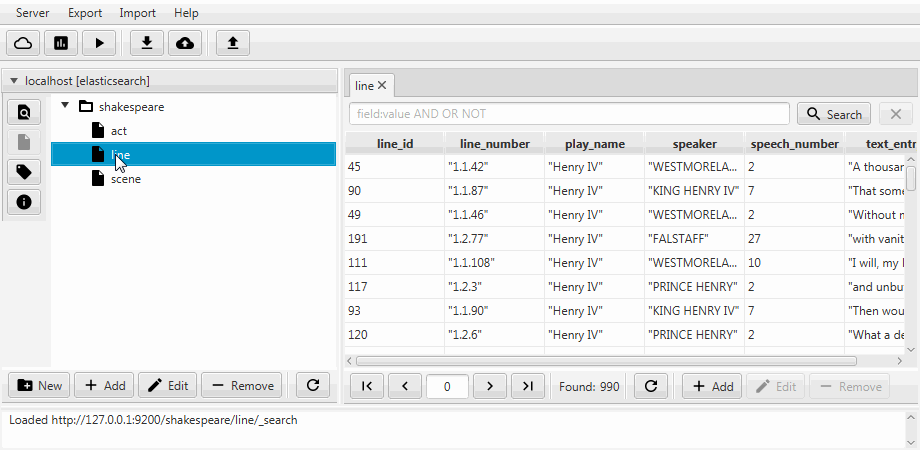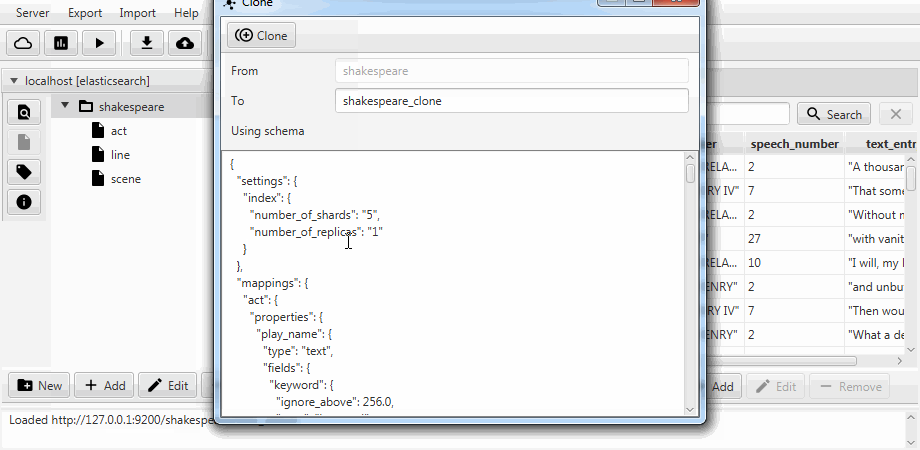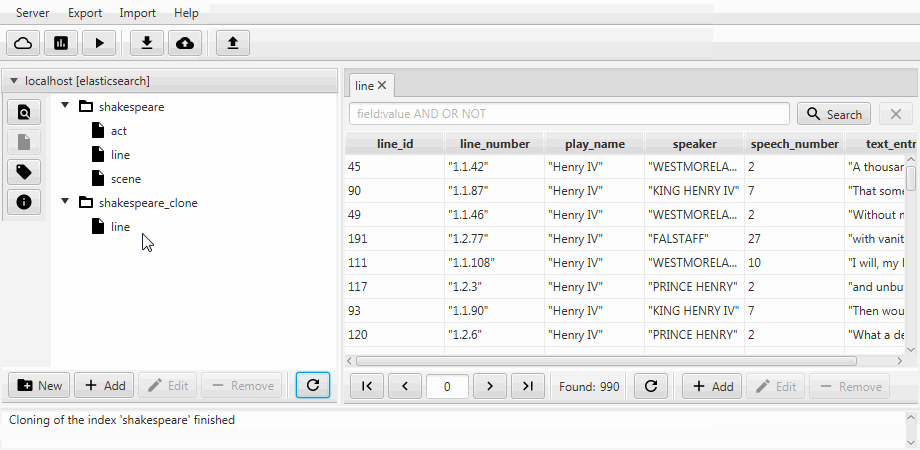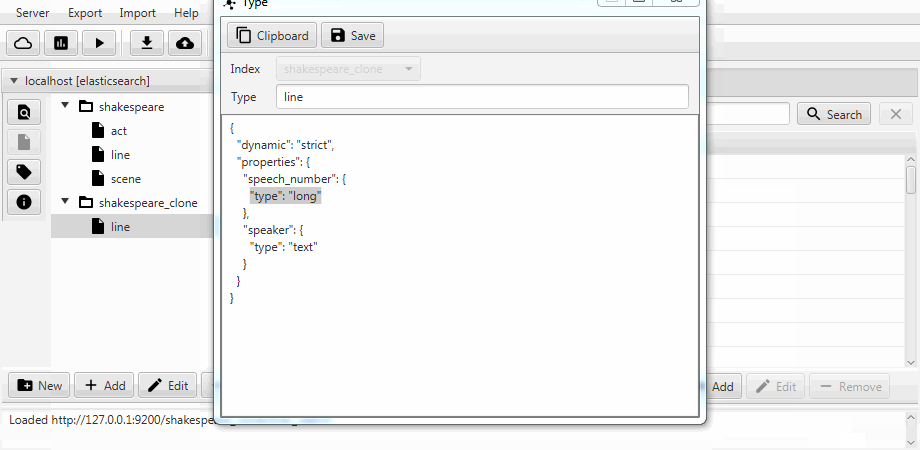
For convenience, both cases were combined into the cloning function in Kaizen, a desktop client for ElasticSearch. Cloning can recognize the mapping of the recipient index. The example below shows how a partial clone is made from an index with three collections (types, in terms of ElasticSearch) act, line, scene. The clone contains line with two fields, static mapping is enabled, and the speech_number field text becomes long .
Migration
The reindex API has one unpleasant feature — it does not know how to monitor possible changes in the source index. If after the start of reindexing something changed, then the changes are not reflected in the recipient index. To solve this problem, ElasticSearch FollowUp Plugin was developed, that adds logging commands. The plugin can follow the index, returning the actions performed on the documents in chronological order, in JSON format. The index, type, document ID and operation on it — INDEX or DELETE — are logged. The FollowUp Plugin is published on GitHub and compiled for almost all versions of ElasticSearch.
So, for the lossless data migration, you will need FollowUp installed on the node on which the reindexing will be launched. It is assumed that the alias index is already available, and all applications run through it. Before reindexing the plugin must be turned on. When reindexing is complete, the plugin is turned off, and alias is transferred to a new index. Then, the recorded actions are reproduced on the recipient index, catching up with its state. Despite of the high speed of the reindexing, two types of collisions may occur during playback:
- in the new index there is no more document with such _id. This means, that the document has been deleted after switching of the alias to the new index.
- in the new index there is a document with the same _id, but with the version number higher than in the source index. This means, that the document has been updated after switching of the alias to the new index..
In these cases, the action should not be reproduced in the recipient index. The remaining changes are reproduced.
Happy coding!
