Текстуры делают компьютерную графику насыщенной. Размер текстур имеет значение, маленькие текстуры при сильном приближении дают картинку с огромными пикселями, или мылом. Про то, как же рисовать огроменные текстуры и будет эта статья.

Сама по себе идея выводить гигантские текстуры не нова. Казалось бы, что может быть проще — загружаем огромную текстуру в миллион мегапикселей, и рисуем с ней объект. Но, как всегда, есть нюансы:
Раз изображение не влезает в лимиты, само собой напрашивается решение — просто разбить его на куски (тайлы):

Разные вариации этого подхода используются до сих пор для аналитической геометрии. Это не универсальный подход, он требует нетривиальных расчетов на ЦПУ. Каждый тайл рисуется отдельным объектом, что добавляет накладных расходов и исключает возможность применять билинейную фильтрацию текстур (между границами тайла будет видимая линия). Однако ограничение на размер текстуры можно обойти текстурными массивами! Да, у такой текстуры ширина и высота все еще ограниченны, но появились дополнительные слои. Число слоёв также ограниченно, но можно рассчитывать на 2048, хоть спецификация вулкана обещает только 256. На видеокарте 1060 GTX можно создать текстуру содержащую 32768*32768*2048 пикселей. Просто так её создать не получится, ведь она занимает 8 терабайт, а столько видеопамяти нет. Если применить к ней аппаратное блочное сжатие BC1, то такая текстура будет занимать «всего» 1 терабайт. В видеокарту она все равно не влезет, но, что с этим делать я расскажу дальше.
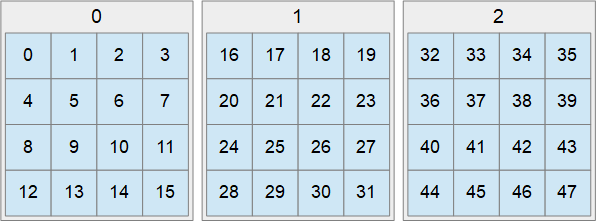
Итак, мы по прежнему режем исходное изображение на куски. Но теперь это будет не отдельная текстура на каждый тайл, а просто кусочек внутри огромного текстурного массива, содержащей все тайлы. У каждого куска есть свой индекс, все куски располагаются последовательно. Сперва по столбцам, потом по строкам, затем по слоям:
Для примера — я взял изображение земли отсюда. Его исходный размер 43200x2160 я увеличил до 65536х32768. Это, конечно, не добавило деталей, однако я получил нужное мне изображение, которое не умещается в одном слое текстуры. Потом я его рекурсивно уменьшал вдвое с билинейной фильтрацией, до тех пор, пока не получил тайл размером 512 на 256 пикселей. Далее я бил получившиеся слои на тайлы размером 512х256. Сжимал их BC1 и записывал последовательно в файл. Как-то так:

В итоге получился файл размером 1 431 633 920 байт, состоящий из 21845 тайлов. Размер 512 на 256 — не случайный. Изображение 512 на 256 сжатое BC1 занимает ровно 65536 байт, а это размер блока разреженного изображения (sparse image) — героя этой статьи. Для рендеринга размер тайла не важен.
Итак мы загрузили текстурный массив в котором тайлы лежат последовательно по стобцам/строкам/слоям.
Тогда шейдер, который рисует эту самую текстуру может выглядеть так:
Разберем этот шейдер. Первым делом, нам нужно определить какой уровень детализации стоит выбрать. В этом нам поможет замечательная функция dFdx. Если сильно упростить, то она возвращает значение, на которое переданный атрибут больше в соседнем пикселе. В демке я рисую плоский прямоугольник у которого заданы текстурные координаты в пределах 0..1. Когда этот прямоугольник занимает X пикселей по ширине — dFdx(v_uv.x) будет возвращать 1/X. Таким образом тайл первого уровня попадет пиксель в пиксель при dFdx == 1/512. Второго при 1/1024, третьего при 1/2048 и т.д. Сам уровень детализации можно вычислить так: log2(1.0f / (512.0f * dFdx(v_uv.x))). Отрежем от него дробную часть. Затем считаем сколько тайлов по ширине/высоте в уровне.
Рассмотрим расчет остального на примере:

тут lod = 2, u = 0.65, v = 0.37
так как lod равен двум, то cellsSize равен четырём. В картинке видно, что этот уровень состоит из 16 тайлов (4 строки 4 столбца) — всё правильно.
tX = int(0.65 * 4) = int(2.6) = 2
tY = int(0.37 * 4) = int(1.48) = 1
т.е. внутри уровня этот тайл находится на третьем столбце и второй строке (индексация с нуля).
Также нам нужны локальные координаты фрагмента (желтые стрелки на рисунке). Их легко посчитать просто домножив исходные текстурные координаты на число ячеек в строке/столбце и взяв дробную часть. В вычислениях выше они уже есть — 0.6 и 0.48.
Теперь нам нужен глобальный индекс этого тайла. Для этого я использую предрасчитанный массив lodBase. В нем по индексу хранятся значения сколько всего было тайлов во всех предыдущих (меньших) уровнях. Прибавляем к нему локальный индекс тайла внутри уровня. Для примера получается lodBase[2] + 1 * 4 + 2 = 5+4+2 = 11. Что тоже правильно.
Зная глобальный индекс нам теперь нужно найти координаты тайла в нашем текстурном массиве. Для этого нам надо знать сколько у нас тайлов влазит по ширине и высоте. Их произведение — это сколько тайлов влезет в слой. В этом примере я эти константы зашил прямо в коде шейдера, для простоты. Далее мы получаем координаты текстуры и читаем по ним тексель. Обратите внимание, что в качестве семплера используется sampler2DArray. Поэтому и texelFetch мы передаем трехкомпонентный вектор, в третьей координате — номер слоя.
Как я писал выше, огроменные текстуры потребляют очень много видеопамяти. Причем используются из этой текстуры очень небольшое число пикселей. Решение проблемы — Partial Residency Textures появилось в 2011 году. Его суть в кратце — тайла физически в памяти может и не быть! При этом спецификация гарантирует, что приложение не упадет, а все известные имплементации гарантируют что вернутся нули. Также, спецификация гарантирует, что если поддерживается расширение, то поддерживается и гарантированный размер блока в байтах — 64 кибибайта. К этому размеру привязаны разрешения стандартных блоков в текстуре:
На самом деле в спецификации про 4-bit тексели ничего нет, но мы всегда сможем про них узнать с помощью vkGetPhysicalDeviceSparseImageFormatProperties.
Создание такой разреженной текстуры отличается от обычной.
Во-первых у VkImageCreateInfo в flags должны быть указаны VK_IMAGE_CREATE_SPARSE_BINDING_BIT и VK_IMAGE_CREATE_SPARSE_RESIDENCY_BIT
Во-вторых, привязывать память через vkBindImageMemory не надо.
Нужно узнавать какие типы памяти можно использовать через vkGetImageMemoryRequirements. Она еще скажет сколько нужно памяти, чтобы загрузить текстуру целиком, но эта цифра нам не нужна.
Вместо этого нам нужно на уровне приложения решить, а сколько тайлов могут быть одновременно видимы?
Ведь загружая одни тайлы, другие будут выгружаться, так как они более не нужны. Я в демке просто ткнул пальцем в небо и выделил памяти на тысячу двадцать четыре тайла. Звучит расточительно, но это всего 50 мегабайт, против 1.4ГБ полностью загруженной текстуры. Также нужно выделить память на хосте, для staging — буфера.
Таким образом у нас будет огромная текстура, в которой загружены лишь некоторые части. Выглядеть это будет примерно так:

Далее я буду использовать термин тайл для обозначения кусочка текстуры (темно зеленые и серые квадраты на рисунке) и термин страница для обозначения кусочка в заранее выделенном в видеопамяти большого блока (светло зеленые и светло синии прямоугольники на рисунке).
После создания такого разреженного VkImage, его можно использовать через VkImageView в шейдере. Конечно, это будет бесполезно — сэмплинг вернет нули, данных-то нет, но в отличии от обычного VkImage ничего не упадет и отладочные слои не будут ругаться. Данные в эту текстуру нужно будет не только загружать, но и выгружать, так как мы экономим видеопамять.
Подход OpenGL, который предусматривает выделение дравйвером памяти на каждый блок, мне кажется не правильным. Да, возможно там используется какой-то хитрый и быстрый аллокатор, ведь размер блока фиксированный. На это намекает и то, что похожий подход используется в примере по sparse residency текстурам в вулкане. Но в любом случае выделить большой линейный блок страниц и уже на стороне приложения привязывать эти страницы к конкретным тайлам текстуры и заливать в них данные будет точно не медленнее.
Таким образом интерфейс нашей разреженной текстуры будет включать методы типа:
Последний метод нужен для того, чтобы заливку/освобождение тайлов сгруппировать. По одному обновлять тайлы довольно дорого, достаточно раз в кадр. Разберем их по порядку.
Для начала нам нужно найти свободный блок. Я просто пробегаюсь по массиву этих самых страниц и ищу первую, в которой находится число заглушка -1. Это и будет индекс свободной страницы. Копирую данные с диска в staging буфер с помощью memcpy. Источником служит отображенный в память файл (memory mapped file) со смещением для конкретного тайла. Далее по ID тайла считаю его позицию (x,y,layer) в текстурном массиве.
Далее начинается самое интересное — заполнение структуры VkSparseImageMemoryBind. Именно она привязывает видеопамять к тайлу. Вот ее важные поля:
memory. Это объект VkDeviceMemory. В нем заранее выделена память для всех страниц.
memoryOffset. Это смещение в байтах до нужной нам страницы.
Далее, нам нужно будет в эту свежепривязанную память скопировать данные со staging буфера. Это делается с помощью vkCmdCopyBufferToImage.
Так как мы будем копировать сразу множество участков, то в этом месте мы лишь заполняем структуру, с описанием откуда и куда мы будем копировать. Здесь важен bufferOffset который указывает на смещение уже в staging буфере. В данном случае это совпадает и со смещением в видеопамяти, но стратегии могут быть разные. Например разделить тайлы на горячие, теплые и холодные. Горячие лежат в видеопамяти, теплые в оперативной, а холодные на диске. Тогда staging буфер может быть больше, и смещение будет другим.
Тут мы отвязываем память от тайла. Для этого присвоим memory VK_NULL_HANDLE.
Основная работа происходит в этом методе. На момент его вызова мы уже имеем два массива с VkSparseImageMemoryBind и VkBufferImageCopy. Заполняем структурки для вызова vkQueueBindSparse и вызываем её. Это не блокирующая функция (как и почти все функции в Vulkan), поэтому нам нужно будет дождаться ее выполнения явно. Для этого последним параметром ей передается VkFence, выполнение которого мы и будем ждать. На самом деле, в моем случае ожидание этой фенсы никак не влияло на работоспособность программы. Но, в теории, она тут нужна.
После того как мы привязали к тайлам память — нужно позаливать в них картинки. Это делается функцией vkCmdCopyBufferToImage.
Заливать данные можно в текстуру с layout VK_IMAGE_LAYOUT_TRANSFER_DST_OPTIMAL, а получать их в шейдере с layout VK_IMAGE_LAYOUT_SHADER_READ_ONLY_OPTIMAL. Следовательно нам нужны два барьера. Обратите внимание, что мы в VK_IMAGE_LAYOUT_TRANSFER_DST_OPTIMAL переводим строго с VK_IMAGE_LAYOUT_SHADER_READ_ONLY_OPTIMAL, не с VK_IMAGE_LAYOUT_UNDEFINED. Так как мы заливаем лишь часть текстуры, нам важно не потерять те её части, что были заполнены ранее.
Вот видео, как это работает. Одна текстура. Один объект. Десятки тысяч тайлов.
За кадром осталось то, а как собственно в приложении определять как собственно узнать, какой тайл пора загрузить, а какой выгрузить. В секции с описанием преимуществ нового подхода одним из пунктов было то, что можно использовать сложную геометрию. В этом же тесте я сам использую простейшую ортографическую проекцию и прямоугольник. И считаю id тайлов аналитически. Неспортивненько.
На самом деле, id видимых тайлов считаются два раза. Аналитически на ЦПУ и честно — во фрагментном шейдере. Казалось бы, почему их не забрать с фрагментного шейдера? Но все не так просто. Об этом будет вторая статья.
Проблемы больших текстур
Сама по себе идея выводить гигантские текстуры не нова. Казалось бы, что может быть проще — загружаем огромную текстуру в миллион мегапикселей, и рисуем с ней объект. Но, как всегда, есть нюансы:
- Графические АПИ ограничивают максимальный размер текстуры по ширине и высоте. Это может зависеть как от железа, так и от драйверов. Максимальный размер на сегодня — 32768x32768 пикселей.
- Даже если бы мы влезли в эти лимиты — все равно 32768х32768 RGBA текстура займет 4 гигабайта видеопамяти. Видеопамять быстрая, лежит на широкой шине, но относительно дорогая. Поэтому ее как правило меньше, чем памяти системной и гораздо меньше чем памяти на диске.
1. Современный рендеринг больших текстур
Раз изображение не влезает в лимиты, само собой напрашивается решение — просто разбить его на куски (тайлы):
Разные вариации этого подхода используются до сих пор для аналитической геометрии. Это не универсальный подход, он требует нетривиальных расчетов на ЦПУ. Каждый тайл рисуется отдельным объектом, что добавляет накладных расходов и исключает возможность применять билинейную фильтрацию текстур (между границами тайла будет видимая линия). Однако ограничение на размер текстуры можно обойти текстурными массивами! Да, у такой текстуры ширина и высота все еще ограниченны, но появились дополнительные слои. Число слоёв также ограниченно, но можно рассчитывать на 2048, хоть спецификация вулкана обещает только 256. На видеокарте 1060 GTX можно создать текстуру содержащую 32768*32768*2048 пикселей. Просто так её создать не получится, ведь она занимает 8 терабайт, а столько видеопамяти нет. Если применить к ней аппаратное блочное сжатие BC1, то такая текстура будет занимать «всего» 1 терабайт. В видеокарту она все равно не влезет, но, что с этим делать я расскажу дальше.
Итак, мы по прежнему режем исходное изображение на куски. Но теперь это будет не отдельная текстура на каждый тайл, а просто кусочек внутри огромного текстурного массива, содержащей все тайлы. У каждого куска есть свой индекс, все куски располагаются последовательно. Сперва по столбцам, потом по строкам, затем по слоям:
Небольшое отступление про исходники тестовой текстуры
Для примера — я взял изображение земли отсюда. Его исходный размер 43200x2160 я увеличил до 65536х32768. Это, конечно, не добавило деталей, однако я получил нужное мне изображение, которое не умещается в одном слое текстуры. Потом я его рекурсивно уменьшал вдвое с билинейной фильтрацией, до тех пор, пока не получил тайл размером 512 на 256 пикселей. Далее я бил получившиеся слои на тайлы размером 512х256. Сжимал их BC1 и записывал последовательно в файл. Как-то так:
В итоге получился файл размером 1 431 633 920 байт, состоящий из 21845 тайлов. Размер 512 на 256 — не случайный. Изображение 512 на 256 сжатое BC1 занимает ровно 65536 байт, а это размер блока разреженного изображения (sparse image) — героя этой статьи. Для рендеринга размер тайла не важен.
Описание техники рисования больших текстур
Итак мы загрузили текстурный массив в котором тайлы лежат последовательно по стобцам/строкам/слоям.
Тогда шейдер, который рисует эту самую текстуру может выглядеть так:
layout(set=0, binding=0) uniform sampler2DArray u_Texture;
layout(location = 0) in vec2 v_uv;
layout(location = 0) out vec4 out_Color;
int lodBase[8] = { 0, 1, 5, 21, 85, 341, 1365, 5461};
int tilesInWidth = 32768 / 512;
int tilesInHeight = 32768 / 256;
int tilesInLayer = tilesInWidth * tilesInHeight;
void main() {
float lod = log2(1.0f / (512.0f * dFdx(v_uv.x)));
int iLod = int(clamp(floor(lod),0,7));
int cellsSize = int(pow(2,iLod));
int tX = int(v_uv.x * cellsSize); //column index in current level of detail
int tY = int(v_uv.y * cellsSize); //row index in current level of detail
int tileID = lodBase[iLod] + tX + tY * cellsSize; //global tile index
int layer = tileID / tilesInLayer;
int row = (tileID % tilesInLayer) / tilesInWidth;
int column = (tileID % tilesInWidth);
vec2 inTileUV = fract(v_uv * cellsSize);
vec2 duv = (inTileUV + vec2(column,row)) / vec2(tilesInWidth,tilesInHeight);
out_Color = texelFetch(u_Texture,ivec3(duv * textureSize(u_Texture,0).xy,layer),0);
}
Разберем этот шейдер. Первым делом, нам нужно определить какой уровень детализации стоит выбрать. В этом нам поможет замечательная функция dFdx. Если сильно упростить, то она возвращает значение, на которое переданный атрибут больше в соседнем пикселе. В демке я рисую плоский прямоугольник у которого заданы текстурные координаты в пределах 0..1. Когда этот прямоугольник занимает X пикселей по ширине — dFdx(v_uv.x) будет возвращать 1/X. Таким образом тайл первого уровня попадет пиксель в пиксель при dFdx == 1/512. Второго при 1/1024, третьего при 1/2048 и т.д. Сам уровень детализации можно вычислить так: log2(1.0f / (512.0f * dFdx(v_uv.x))). Отрежем от него дробную часть. Затем считаем сколько тайлов по ширине/высоте в уровне.
Рассмотрим расчет остального на примере:
тут lod = 2, u = 0.65, v = 0.37
так как lod равен двум, то cellsSize равен четырём. В картинке видно, что этот уровень состоит из 16 тайлов (4 строки 4 столбца) — всё правильно.
tX = int(0.65 * 4) = int(2.6) = 2
tY = int(0.37 * 4) = int(1.48) = 1
т.е. внутри уровня этот тайл находится на третьем столбце и второй строке (индексация с нуля).
Также нам нужны локальные координаты фрагмента (желтые стрелки на рисунке). Их легко посчитать просто домножив исходные текстурные координаты на число ячеек в строке/столбце и взяв дробную часть. В вычислениях выше они уже есть — 0.6 и 0.48.
Теперь нам нужен глобальный индекс этого тайла. Для этого я использую предрасчитанный массив lodBase. В нем по индексу хранятся значения сколько всего было тайлов во всех предыдущих (меньших) уровнях. Прибавляем к нему локальный индекс тайла внутри уровня. Для примера получается lodBase[2] + 1 * 4 + 2 = 5+4+2 = 11. Что тоже правильно.
Зная глобальный индекс нам теперь нужно найти координаты тайла в нашем текстурном массиве. Для этого нам надо знать сколько у нас тайлов влазит по ширине и высоте. Их произведение — это сколько тайлов влезет в слой. В этом примере я эти константы зашил прямо в коде шейдера, для простоты. Далее мы получаем координаты текстуры и читаем по ним тексель. Обратите внимание, что в качестве семплера используется sampler2DArray. Поэтому и texelFetch мы передаем трехкомпонентный вектор, в третьей координате — номер слоя.
Текстуры, загруженные не полностью (partial residency images)
Как я писал выше, огроменные текстуры потребляют очень много видеопамяти. Причем используются из этой текстуры очень небольшое число пикселей. Решение проблемы — Partial Residency Textures появилось в 2011 году. Его суть в кратце — тайла физически в памяти может и не быть! При этом спецификация гарантирует, что приложение не упадет, а все известные имплементации гарантируют что вернутся нули. Также, спецификация гарантирует, что если поддерживается расширение, то поддерживается и гарантированный размер блока в байтах — 64 кибибайта. К этому размеру привязаны разрешения стандартных блоков в текстуре:
| TEXEL SIZE (bits) | Block Shape (2D) | Block Shape (3D) |
|---|---|---|
| ?4-Bit ? | ?512 × 256 × 1 ? | not support |
| 8-Bit | 256 × 256 × 1 | 64 × 32 × 32 |
| 16-Bit | 256 × 128 × 1 | 32 × 32 × 32 |
| 32-Bit | 128 × 128 × 1 | 32 × 32 × 16 |
| 64-Bit | 128 × 64 × 1 | 32 × 16 × 16 |
| 128-Bit | 64 × 64 × 1 | 16 × 16 × 16 |
На самом деле в спецификации про 4-bit тексели ничего нет, но мы всегда сможем про них узнать с помощью vkGetPhysicalDeviceSparseImageFormatProperties.
VkSparseImageFormatProperties sparseProps;
ermy::u32 propsNum = 1;
vkGetPhysicalDeviceSparseImageFormatProperties(hphysicalDevice, VK_FORMAT_BC1_RGB_SRGB_BLOCK, VkImageType::VK_IMAGE_TYPE_2D,
VkSampleCountFlagBits::VK_SAMPLE_COUNT_1_BIT, VkImageUsageFlagBits::VK_IMAGE_USAGE_SAMPLED_BIT | VkImageUsageFlagBits::VK_IMAGE_USAGE_TRANSFER_DST_BIT
, VkImageTiling::VK_IMAGE_TILING_OPTIMAL, &propsNum, &sparseProps);
int pageWidth = sparseProps.imageGranularity.width;
int pageHeight = sparseProps.imageGranularity.height;
Создание такой разреженной текстуры отличается от обычной.
Во-первых у VkImageCreateInfo в flags должны быть указаны VK_IMAGE_CREATE_SPARSE_BINDING_BIT и VK_IMAGE_CREATE_SPARSE_RESIDENCY_BIT
Во-вторых, привязывать память через vkBindImageMemory не надо.
Нужно узнавать какие типы памяти можно использовать через vkGetImageMemoryRequirements. Она еще скажет сколько нужно памяти, чтобы загрузить текстуру целиком, но эта цифра нам не нужна.
Вместо этого нам нужно на уровне приложения решить, а сколько тайлов могут быть одновременно видимы?
Ведь загружая одни тайлы, другие будут выгружаться, так как они более не нужны. Я в демке просто ткнул пальцем в небо и выделил памяти на тысячу двадцать четыре тайла. Звучит расточительно, но это всего 50 мегабайт, против 1.4ГБ полностью загруженной текстуры. Также нужно выделить память на хосте, для staging — буфера.
const int sparseBlockSize = 65536;
int numHotPages = 512; //максимальное число тайлов в видеопамяти
VkMemoryRequirements memReqsOpaque;
vkGetImageMemoryRequirements(device, mySparseImage, &memReqsOpaque); //отсюда нам нужны только memoryTypeBits. Хотя может и полный размер для чего-нибудь пригодится
VkMemoryRequirements image_memory_requirements;
image_memory_requirements.alignment = sparseBlockSize ; //выравниваем по блоку
image_memory_requirements.size = sparseBlockSize * numHotPages;
image_memory_requirements.memoryTypeBits = memReqsOpaque.memoryTypeBits;
Таким образом у нас будет огромная текстура, в которой загружены лишь некоторые части. Выглядеть это будет примерно так:
Менеджмент тайлов
Далее я буду использовать термин тайл для обозначения кусочка текстуры (темно зеленые и серые квадраты на рисунке) и термин страница для обозначения кусочка в заранее выделенном в видеопамяти большого блока (светло зеленые и светло синии прямоугольники на рисунке).
После создания такого разреженного VkImage, его можно использовать через VkImageView в шейдере. Конечно, это будет бесполезно — сэмплинг вернет нули, данных-то нет, но в отличии от обычного VkImage ничего не упадет и отладочные слои не будут ругаться. Данные в эту текстуру нужно будет не только загружать, но и выгружать, так как мы экономим видеопамять.
Подход OpenGL, который предусматривает выделение дравйвером памяти на каждый блок, мне кажется не правильным. Да, возможно там используется какой-то хитрый и быстрый аллокатор, ведь размер блока фиксированный. На это намекает и то, что похожий подход используется в примере по sparse residency текстурам в вулкане. Но в любом случае выделить большой линейный блок страниц и уже на стороне приложения привязывать эти страницы к конкретным тайлам текстуры и заливать в них данные будет точно не медленнее.
Таким образом интерфейс нашей разреженной текстуры будет включать методы типа:
void CommitTile(int tileID, void* dataPtr); //размер данных строго равен 64 кибибайтам
void FreeTile(int tileID);
void Flush();
Последний метод нужен для того, чтобы заливку/освобождение тайлов сгруппировать. По одному обновлять тайлы довольно дорого, достаточно раз в кадр. Разберем их по порядку.
//void CommitTile(int tileID, void* dataPtr)
int freePageID = _getFreePageID();
if (freePageID != -1)
{
tilesByPageIndex[freePageID] = tileID;
tilesByTileID[tileID] = freePageID;
memcpy(stagingPtr + freePageID * pageDataSize, tileData, pageDataSize);
int pagesInWidth = textureWidth / pageWidth;
int pagesInHeight = textureHeight / pageHeight;
int pagesInLayer = pagesInWidth * pagesInHeight;
int layer = tileID / pagesInLayer;
int row = (tileID % pagesInLayer) / pagesInWidth;
int column = tileID % pagesInWidth;
VkSparseImageMemoryBind mbind;
mbind.subresource.aspectMask = VK_IMAGE_ASPECT_COLOR_BIT;
mbind.subresource.mipLevel = 0;
mbind.subresource.arrayLayer = layer;
mbind.extent.width = pageWidth;
mbind.extent.height = pageHeight;
mbind.extent.depth = 1;
mbind.offset.x = column * pageWidth;
mbind.offset.y = row * pageHeight;
mbind.offset.z = 0;
mbind.memory = optimalTilingMem;
mbind.memoryOffset = freePageID * pageDataSize;
mbind.flags = 0;
memoryBinds.push_back(mbind);
VkBufferImageCopy copyRegion;
copyRegion.bufferImageHeight = pageHeight;
copyRegion.bufferRowLength = pageWidth;
copyRegion.bufferOffset = mbind.memoryOffset;
copyRegion.imageExtent.depth = 1;
copyRegion.imageExtent.width = pageWidth;
copyRegion.imageExtent.height = pageHeight;
copyRegion.imageOffset.x = mbind.offset.x;
copyRegion.imageOffset.y = mbind.offset.y;
copyRegion.imageOffset.z = 0;
copyRegion.imageSubresource.aspectMask = VK_IMAGE_ASPECT_COLOR_BIT;
copyRegion.imageSubresource.baseArrayLayer = layer;
copyRegion.imageSubresource.layerCount = 1;
copyRegion.imageSubresource.mipLevel = 0;
copyRegions.push_back(copyRegion);
return true;
}
return false;
Для начала нам нужно найти свободный блок. Я просто пробегаюсь по массиву этих самых страниц и ищу первую, в которой находится число заглушка -1. Это и будет индекс свободной страницы. Копирую данные с диска в staging буфер с помощью memcpy. Источником служит отображенный в память файл (memory mapped file) со смещением для конкретного тайла. Далее по ID тайла считаю его позицию (x,y,layer) в текстурном массиве.
Далее начинается самое интересное — заполнение структуры VkSparseImageMemoryBind. Именно она привязывает видеопамять к тайлу. Вот ее важные поля:
memory. Это объект VkDeviceMemory. В нем заранее выделена память для всех страниц.
memoryOffset. Это смещение в байтах до нужной нам страницы.
Далее, нам нужно будет в эту свежепривязанную память скопировать данные со staging буфера. Это делается с помощью vkCmdCopyBufferToImage.
Так как мы будем копировать сразу множество участков, то в этом месте мы лишь заполняем структуру, с описанием откуда и куда мы будем копировать. Здесь важен bufferOffset который указывает на смещение уже в staging буфере. В данном случае это совпадает и со смещением в видеопамяти, но стратегии могут быть разные. Например разделить тайлы на горячие, теплые и холодные. Горячие лежат в видеопамяти, теплые в оперативной, а холодные на диске. Тогда staging буфер может быть больше, и смещение будет другим.
//void FreeTile(int tileID)
if (tilesByTileID.count(tileID) > 0)
{
i16 hotPageID = tilesByTileID[tileID];
int pagesInWidth = textureWidth / pageWidth;
int pagesInHeight = textureHeight / pageHeight;
int pagesInLayer = pagesInWidth * pagesInHeight;
int layer = tileID / pagesInLayer;
int row = (tileID % pagesInLayer) / pagesInWidth;
int column = tileID % pagesInWidth;
VkSparseImageMemoryBind mbind;
mbind.memory = optimalTilingMem;
mbind.subresource.aspectMask = VK_IMAGE_ASPECT_COLOR_BIT;
mbind.subresource.mipLevel = 0;
mbind.subresource.arrayLayer = layer;
mbind.extent.width = pageWidth;
mbind.extent.height = pageHeight;
mbind.extent.depth = 1;
mbind.offset.x = column * pageWidth;
mbind.offset.y = row * pageHeight;
mbind.offset.z = 0;
mbind.memory = VK_NULL_HANDLE;
mbind.memoryOffset = 0;
mbind.flags = 0;
memoryBinds.push_back(mbind);
tilesByPageIndex[hotPageID] = -1;
tilesByTileID.erase(tileID);
return true;
}
return false;
Тут мы отвязываем память от тайла. Для этого присвоим memory VK_NULL_HANDLE.
//void Flush();
cbuff = hostDevice->CreateOneTimeSubmitCommandBuffer();
VkImageSubresourceRange imageSubresourceRange;
imageSubresourceRange.aspectMask = VK_IMAGE_ASPECT_COLOR_BIT;
imageSubresourceRange.baseMipLevel = 0;
imageSubresourceRange.levelCount = 1;
imageSubresourceRange.baseArrayLayer = 0;
imageSubresourceRange.layerCount = numLayers;
VkImageMemoryBarrier bSamplerToTransfer;
bSamplerToTransfer.sType = VK_STRUCTURE_TYPE_IMAGE_MEMORY_BARRIER;
bSamplerToTransfer.pNext = nullptr;
bSamplerToTransfer.srcAccessMask = 0;
bSamplerToTransfer.dstAccessMask = VK_ACCESS_TRANSFER_WRITE_BIT;
bSamplerToTransfer.oldLayout = VK_IMAGE_LAYOUT_SHADER_READ_ONLY_OPTIMAL;
bSamplerToTransfer.newLayout = VK_IMAGE_LAYOUT_TRANSFER_DST_OPTIMAL;
bSamplerToTransfer.srcQueueFamilyIndex = VK_QUEUE_FAMILY_IGNORED;
bSamplerToTransfer.dstQueueFamilyIndex = VK_QUEUE_FAMILY_IGNORED;
bSamplerToTransfer.image = opaqueImage;
bSamplerToTransfer.subresourceRange = imageSubresourceRange;
VkSparseImageMemoryBindInfo imgBindInfo;
imgBindInfo.image = opaqueImage;
imgBindInfo.bindCount = memoryBinds.size();
imgBindInfo.pBinds = memoryBinds.data();
VkBindSparseInfo sparseInfo;
sparseInfo.sType = VK_STRUCTURE_TYPE_BIND_SPARSE_INFO;
sparseInfo.pNext = nullptr;
sparseInfo.waitSemaphoreCount = 0;
sparseInfo.pWaitSemaphores = nullptr;
sparseInfo.bufferBindCount = 0;
sparseInfo.pBufferBinds = nullptr;
sparseInfo.imageOpaqueBindCount = 0;
sparseInfo.pImageOpaqueBinds = nullptr;
sparseInfo.imageBindCount = 1;
sparseInfo.pImageBinds = &imgBindInfo;
sparseInfo.signalSemaphoreCount = 0;
sparseInfo.pSignalSemaphores = nullptr;
VkImageMemoryBarrier bTransferToSampler;
bTransferToSampler.sType = VK_STRUCTURE_TYPE_IMAGE_MEMORY_BARRIER;
bTransferToSampler.pNext = nullptr;
bTransferToSampler.srcAccessMask = 0;
bTransferToSampler.dstAccessMask = VK_ACCESS_SHADER_READ_BIT;
bTransferToSampler.oldLayout = VK_IMAGE_LAYOUT_TRANSFER_DST_OPTIMAL;
bTransferToSampler.newLayout = VK_IMAGE_LAYOUT_SHADER_READ_ONLY_OPTIMAL;
bTransferToSampler.srcQueueFamilyIndex = VK_QUEUE_FAMILY_IGNORED;
bTransferToSampler.dstQueueFamilyIndex = VK_QUEUE_FAMILY_IGNORED;
bTransferToSampler.image = opaqueImage;
bTransferToSampler.subresourceRange = imageSubresourceRange;
vkQueueBindSparse(graphicsQueue, 1, &sparseInfo, fence);
vkWaitForFences(device, 1, &fence, true, UINT64_MAX);
vkResetFences(device, 1, &fence);
vkCmdPipelineBarrier(cbuff, VK_PIPELINE_STAGE_TOP_OF_PIPE_BIT, VK_PIPELINE_STAGE_TRANSFER_BIT, 0, 0, nullptr, 0, nullptr, 1, &bSamplerToTransfer);
if (copyRegions.size() > 0)
{
vkCmdCopyBufferToImage(cbuff, stagingBuffer, opaqueImage, VkImageLayout::VK_IMAGE_LAYOUT_TRANSFER_DST_OPTIMAL, copyRegions.size(), copyRegions.data());
}
vkCmdPipelineBarrier(cbuff, VK_PIPELINE_STAGE_TRANSFER_BIT, VK_PIPELINE_STAGE_FRAGMENT_SHADER_BIT, 0, 0, nullptr, 0, nullptr, 1, &bTransferToSampler);
hostDevice->ExecuteCommandBuffer(cbuff);
copyRegions.clear();
memoryBinds.clear();
Основная работа происходит в этом методе. На момент его вызова мы уже имеем два массива с VkSparseImageMemoryBind и VkBufferImageCopy. Заполняем структурки для вызова vkQueueBindSparse и вызываем её. Это не блокирующая функция (как и почти все функции в Vulkan), поэтому нам нужно будет дождаться ее выполнения явно. Для этого последним параметром ей передается VkFence, выполнение которого мы и будем ждать. На самом деле, в моем случае ожидание этой фенсы никак не влияло на работоспособность программы. Но, в теории, она тут нужна.
После того как мы привязали к тайлам память — нужно позаливать в них картинки. Это делается функцией vkCmdCopyBufferToImage.
Заливать данные можно в текстуру с layout VK_IMAGE_LAYOUT_TRANSFER_DST_OPTIMAL, а получать их в шейдере с layout VK_IMAGE_LAYOUT_SHADER_READ_ONLY_OPTIMAL. Следовательно нам нужны два барьера. Обратите внимание, что мы в VK_IMAGE_LAYOUT_TRANSFER_DST_OPTIMAL переводим строго с VK_IMAGE_LAYOUT_SHADER_READ_ONLY_OPTIMAL, не с VK_IMAGE_LAYOUT_UNDEFINED. Так как мы заливаем лишь часть текстуры, нам важно не потерять те её части, что были заполнены ранее.
Вот видео, как это работает. Одна текстура. Один объект. Десятки тысяч тайлов.
За кадром осталось то, а как собственно в приложении определять как собственно узнать, какой тайл пора загрузить, а какой выгрузить. В секции с описанием преимуществ нового подхода одним из пунктов было то, что можно использовать сложную геометрию. В этом же тесте я сам использую простейшую ортографическую проекцию и прямоугольник. И считаю id тайлов аналитически. Неспортивненько.
На самом деле, id видимых тайлов считаются два раза. Аналитически на ЦПУ и честно — во фрагментном шейдере. Казалось бы, почему их не забрать с фрагментного шейдера? Но все не так просто. Об этом будет вторая статья.
