
Представьте что у вас команда специалистов, которая по принципу code-first делает систему с множеством бизнес-историй на базе микросервисов. Все люди опытные, всем есть что делать кроме того как писать документации или спецификации на разработанный API. И все изначально знают, что если захотел использовать какой сервис, то надо заглянуть в код и потом спросить в общем чате если что непонятно. Знакомая ситуация не так ли? -))) И в целом все нормально, если бы со временем не росла команда, не росло количество сервисов и функций, не появлялись баги от бизнеса и тестеров, не требовалось предоставлять API для интеграции смежным командам...
Эта статья, на момент написания, является моим личным мнением о минимальной структуре документирования микросервисов в условиях его отсутствия. Личное мнение родилось в ходе мозгового штурма реальной ситуации и поисков повышения качества в разработке среднего по масштабу бизнес приложения.
Итак. Что мы имеем на входе? А на входе мы имеем процесс разработки, который выглядит как очень быстрый и оптимальный.
- На входе процесса есть бизнес-истории которые описывают функциональные требования на уровне бизнес активностей и кейсов по типу… Я как А хочу получить Б. Так сказать классика которая описывается в Confluence.
- Далее бизнес-история обрабатывается аналитиком который превращает ее в задание в Jira с вложениями макетов форм и описанием сценария в терминах пользовательского интерфейса.
- Теперь задача падает на разработчика, который пишет уже код. После чего реализация уходит аналитику на тестирование.
- Дополнительно есть архитектор, который занимается решением нефункциональных требований, но организационно его решения оформляются как и бизнес-истории и попадают в разработку аналогичным путем — через Jira
Что у нас тут особенного? Очень быстрый и прямой процесс. Но нет никаких артефактов обеспечивающих поддержку принятия технических решений без заглядывания в код. И выглядит это так:
Решение о р- еализации новой функции уровня микросервиса принимается конкретным разработчиком при реализации конкретного бизнес-сценария (описанного в Jira)
- После реализации все его решения остаются только в коде (какой микросервис он выбрал, как назвал параметры REST и какой json у нашего DTO, какие поля добавил в базу и те пе.
- Теперь при реализации клиента для этого реста, его модернизации или реализации нового REST другой разработчик на старте шерстит код чтобы посмотреть как этот рест был реализован или вообще где он реализован.
При этом модель в принципе рабочая, плюс никто не желает переходить на contract-first разработку, но процесс начинает работать в холостую с ростом числа микросервисов и разработчиков. И хочется как в том анекдоте ничего не разать, а дать таблетку, чтобы все само отвалилось.
Далее будет много букв и восемь страниц сухого текста TO-DO без каких либо обоснований и сентенций. Решение предлагает минимально возможную модель выстраивания документирования микросервисов в условиях абсолютного нежелания этого делать. В решении представлена исключительно модель документов, их сзязности и менеджмента без описаний собственно как эти документы писать. В решении много открытых вопросов к конкретной имплементации. Если вас интерисует сама имплементация — пишите вопросы в коментах.
Цели документирования
- Обеспечить комплексное решение для документирования микросервисов в случае разработки кода по принципу «сначала код»
- Предоставление разработчикам и другим техническим специалистам четкие инструкции, как читать и где искать информацию о микросервисах и реализации
- Предоставление "Single source of true" для спецификации кода
Стратегия решения
Решение использует следующие подходы к документированию микросервисов:
- Файл Readme.md — это основная часть документации по микросервисам, которая содержит все общее описания и ссылки на другую часть документации.
- Конечные точки REST документируются с помощью аннотаций Swagger. Затем он будет опубликован как спецификация Swagger Hub
- Микросервис имеет предопределенные высокоуровневые определения иерархии пакетов, которые обеспечивают дополнительный уровень понимания кода
- Задачи Jira являются источником информации обо всех разработках, связанных с конкретными микросервисами. Связывание осуществляется с помощью объекта Jira — Component
- все дополнительные источники документации по микросервисам могут быть где угодно, но должны быть упомянуты в файле Readme.md
Модель документации
Общая модель документации изображена на следующей диаграмме. Подробнее о реализации см. В главе о реализации.
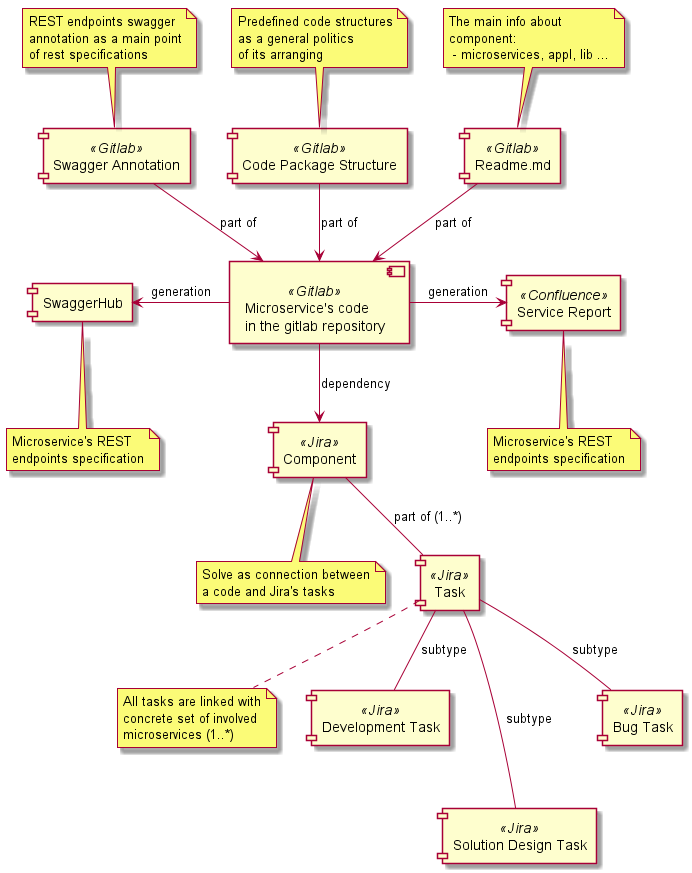
Gitlab
Файл Readme.md
Файл Readme.md — важная часть принципов документации. Файл является отправной точкой для знаний о микросервисах и «единой точкой доверия». Этот файл должен присутствовать во всех репозиториях кода для предоставления наиболее важной информации о программном компоненте (тут микросервисе) и отвечать на следующие вопросы:
- Какой статус у компонента?
- Кто является владельцем компонента?
- О чем компонент? Какова цель его использования?
- Какую область данных он обслуживает и за что отвечает?
- Какие варианты использования он реализует?
- Как это использовать? Как его построить? Как это настроить?
- Какая документация существует и где она находится?
Файл Readme .md должен быть частью мерж реквеста и аудита качества кода, особенно в части новых сценариев использования. Информация о том, «что делает этот микросервис», должна быть легко доступной без необходимости чтения кода.
Аннотации Swagger для служб REST
Аннотации Swagger для служб REST используются для конечных точек REST и документирования их моделей данных. Затем все аннотированные конечные точки будут экспортированы в Swagger Hub в качестве спецификации REST. Аналитики, тестировщики, архитекторы могут использовать эту спецификацию, а также для автоматичиской настройки шлюза API и предоставления спецификации внешним контракторам.
Аннотации Swagger должны быть исчерпывающими и правильными. Полнота аннотаций должна быть неотъемлемой частью проверки кода. В идеале определение REST должно предоставлять всю информацию, необходимую для его использования, без необходимости читать код или некоторые внешние документы.
Предопределенная структура пакета кода
С точки зрения документации, структура предопределенного пакета кода должна помочь определить назначение конкретных частей кода на основе их размещения в пакете /src. Это может помочь при аудите кода и во время утверждения запросов на слияние.
Другие источники документации в репозитории кода
Было бы неплохо иметь определенный пакет, например /doc, для хранения других документов как часть кода. Например, это могут быть AsciiDoc (https://asciidoc.org/) и PlanUML (https://plantuml.com/).
Дополнительно для меня остается открытым вопрос как наиболее оптимально документировать уровень DAO, JPA и других интерфейсов не связанных с REST. Обязательно напишите если у вас есть рецепт в комент.
Jira
Jira — это основной источник информации обо всех изменениях, которые были применены к настоящему микросервису. Все задачи Jira должны быть связаны с конкретным микросервисом, который был изменен конкретной задачей. Таким образом, все микросервисы станут связаны с конкретными реализациями и работами и журналом изменений.
Поскольку в текущем процессе разработки задача Jira является основным источником информации о необходимых изменениях, улучшениях и результатах, задача Jira является важным источником информации о том, какие варианты использования были реализованы, какой документ проектирования (архитектурные решения) связан с конкретным микросервисы и так далее.
Объект "Компонент" Jira работает как ссылка от задач Jira к определенному микросервису. Его название должно соответствовать конкретному названию микросервиса. Так что определить местонахождение всех задач, связанных с конкретным микросервисом, будет достаточно просто.
Задачи Jira должны относиться к затронутым микросервисам соответствующими объектами компонентов:
- задача разработки — должна быть связанна хотя бы с одним затронутым микросервисом. В целом, это будет хороший шаблон для создания для всех затронутых микросервисов отдельных задач в рамках некоторых задач высокого уровня, которые должны относиться к конкретной реализации варианта использования. За эту задачу высокого уровня может отвечать архитектор программного обеспечения.
- устранение бага — должна быть подключена хотя бы к одному затронутому микросервису
- дизайн решения (задача архитектора) — было бы хорошей практикой, если бы все документы по проектированию решения основывались на всех микросервисах, которые были частью этого решения. Таким образом, все микросервисы автоматически подключаются к библиотеке проектирования решений
Confluence
Service Report (см диаграмму) — это сводный отчет обо всех микросервисах в одном месте. Основная идея этого документа — предоставить автоматически собираемый отчет, основанный на информации из файла Readme.md.
Отчет должен содержать информацию обо всех микросервисах в Gitlab, включая локальную копию файла Readme.md. Таким образом, его могут использовать люди, не имеющие доступа к репозиторию Gitlab
Swagger Hub
Swagger Hub служит сводным отчетом обо всех конечных точках REST и формируется автоматически на основе Swagger аннотаций.
Продолжение следует во второй части в которой описаны основные подходы к реализации
Часть 2 тут
