Стандарт ASCII был принят в 1963, и сейчас вряд ли кто-нибудь использует кодировку, первые 128 символов которой отличались бы от ASCII. Тем не менее, до конца прошлого века активно использовалась EBCDIC — стандартная кодировка для мейнфреймов IBM и их советских клонов ЕС ЭВМ. EBCDIC остаётся основной кодировкой в z/OS — стандартной ОС для современных мейнфреймов IBM Z.
То, что сразу бросается в глаза при взгляде на EBCDIC — то, что буквы идут не подряд: между I и J и между R и S остались неиспользованные позиции (на ЕС ЭВМ по этим промежуткам распределили символы кириллицы). Кому могло придти в голову кодировать буквы с неравными пропусками между соседними буквами?
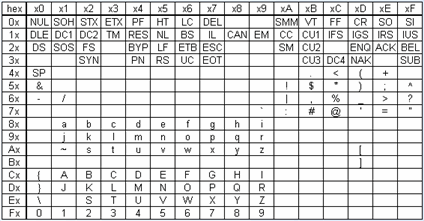
Само название EBCDIC ("Extended BCDIC") намекает на то, что эта кодировка — в отличие от ASCII — создавалась не на пустом месте, а на основе шестибитной кодировки BCDIC, которая использовалась начиная с IBM 704 (1954):
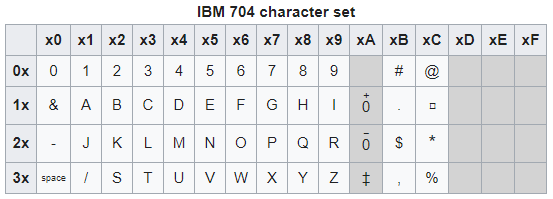
Непосредственной обратной совместимости нет: удобной чертой BCDIC, утраченной при переходе к EBCDIC, было то, что цифрам 0-9 соответствуют коды 0-9. Тем не менее, разрывы в семь кодов между I и J и в восемь кодов между R и S в BCDIC уже были. Откуда же они взялись?
История (E)BCDIC начинается одновременно с историей IBM — задолго до электронных компьютеров. IBM образовалась в результате слияния четырёх компаний, из которых самой технологически продвинутой была "Tabulating Machine Company", основанная в 1896 Германом Холлеритом — изобретателем табулятора. Первые табуляторы просто подсчитывали число перфокарт, пробитых в определённом месте; но в 1905 Холлерит начал производство десятичных табуляторов. Каждая карта для десятичного табулятора состояла из полей произвольной длины, и чи́сла, записанные в этих полях в привычной десятичной форме, суммировались по всей колоде. Разбивка карты на поля задавалась соединением проводов на коммутационной панели табулятора. Например, на этой перфокарте Холлерита, хранящейся в Библиотеке Конгресса, очевидным образом выбито число 23456789012345678, неизвестно как разделённое на поля:
Самые внимательные могли заметить, что на карте Холлерита 12 рядов для отверстий, хотя для цифр достаточно десяти; а в BCDIC для каждого значения старших двух битов используются только 12 кодов из 16 возможных.
Конечно же, это не случайное совпадение. Изначально Холлерит предназначал дополнительные ряды для "специальных отметок", которые не суммировались, а просто подсчитывались — как в самых первых табуляторах. (Сегодня мы бы назвали их "битовыми полями".) Кроме того, среди "специальных отметок" можно было задать group indicators: если при табуляции требовались не только окончательные суммы, но и промежуточные, то табулятор останавливался, когда обнаруживал изменение любого из group indicators, и оператор должен был переписать промежуточные суммы с цифровых табло на бумагу, обнулить табло, и возобновить табуляцию. Например, при подсчёте бухгалтерских балансов группа карт могла соответствовать одной дате или одному контрагенту.
К 1920, когда Холлерит уже ушёл на пенсию, вошли в употребление "печатающие табуляторы", которые подключались к телетайпу и могли сами печатать промежуточные суммы, не требуя вмешательства оператора. Сложность теперь заключалась в том, чтобы определить, к чему относится каждое из напечатанных чисел. В 1931 IBM решила при помощи "специальных отметок" обозначать буквы: отметка в 12-том ряду обозначала букву от A до I, в 11-том — от J до R, в нулевом — от S до Z. Новый "алфавитный табулятор" мог печатать название каждой группы карт вместе с промежуточными суммами; при этом непробитый столбец превращался в пробел между символами. Заметьте, что S обозначается комбинацией отверстий 0+2, а комбинация 0+1 изначально не использовалась из опасения, что два отверстия рядом в одном столбце могут вызвать механические проблемы в считывателе.

Теперь на таблицу BCDIC можно посмотреть немного под другим углом:

За исключением того, что 0 и пробел переставлены местами, старшие два бита определяют "специальную отметку", которую с 1931 пробивали в перфокарте для соответствующего символа; а младшие четыре бита определяют цифру, пробиваемую в основной части карты. Поддержка символов & - / добавилась в табуляторы IBM в 1930-х, и кодировка этих символов в BCDIC соответствует пробиваемым для них комбинациям отверстий. Когда понадобилась поддержка ещё большего числа символов, то в качестве дополнительной "специальной отметки" стали пробивать ряд 8 — таким образом, в одном столбце могло быть до трёх отверстий. Такой формат перфокарт сохранился практически неизменным до конца века. В СССР оставили IBM-овские кодировки латиницы и пунктуации, а для букв кириллицы пробивали сразу по нескольку "специальных отметок" в рядах 12, 11, 0 — не ограничиваясь тремя отверстиями в одном столбце.
Когда создавался компьютер IBM 704, то над кодировкой символов для него долго не думали: взяли кодировку, уже используемую тогда в перфокартах, и лишь 0 "поставили на место". В 1964, при переходе от BCDIC к EBCDIC, младшие четыре бита каждого символа оставили без изменений, хотя немного перетасовали старшие биты. Таким образом формат перфокарт, выбранный Холлеритом в начале прошлого века, оказал влияние на архитектуру всех компьютеров IBM, до IBM Z включительно.
