Intro
So you are writing some CPU-intensive code in Python and really trying to find ways out of its single-threaded prison. You might be looking towards Numba's "nopython parallel" mode, you might be using forked processes with multiprocessing, you might be writing microservices with database-like coordinators, or even writing your own multithreaded programs in C/C++ just like creators of TensorFlow did.
In this article I'm describing a rationale for my pet project where I try to implement facilities for general purpose multitasking to be used in a form of simple python code, employing a database-like approach for interpreters communication, while keeping the GIL (Global Interpreter Lock) and trying to be as pythonic as possible.
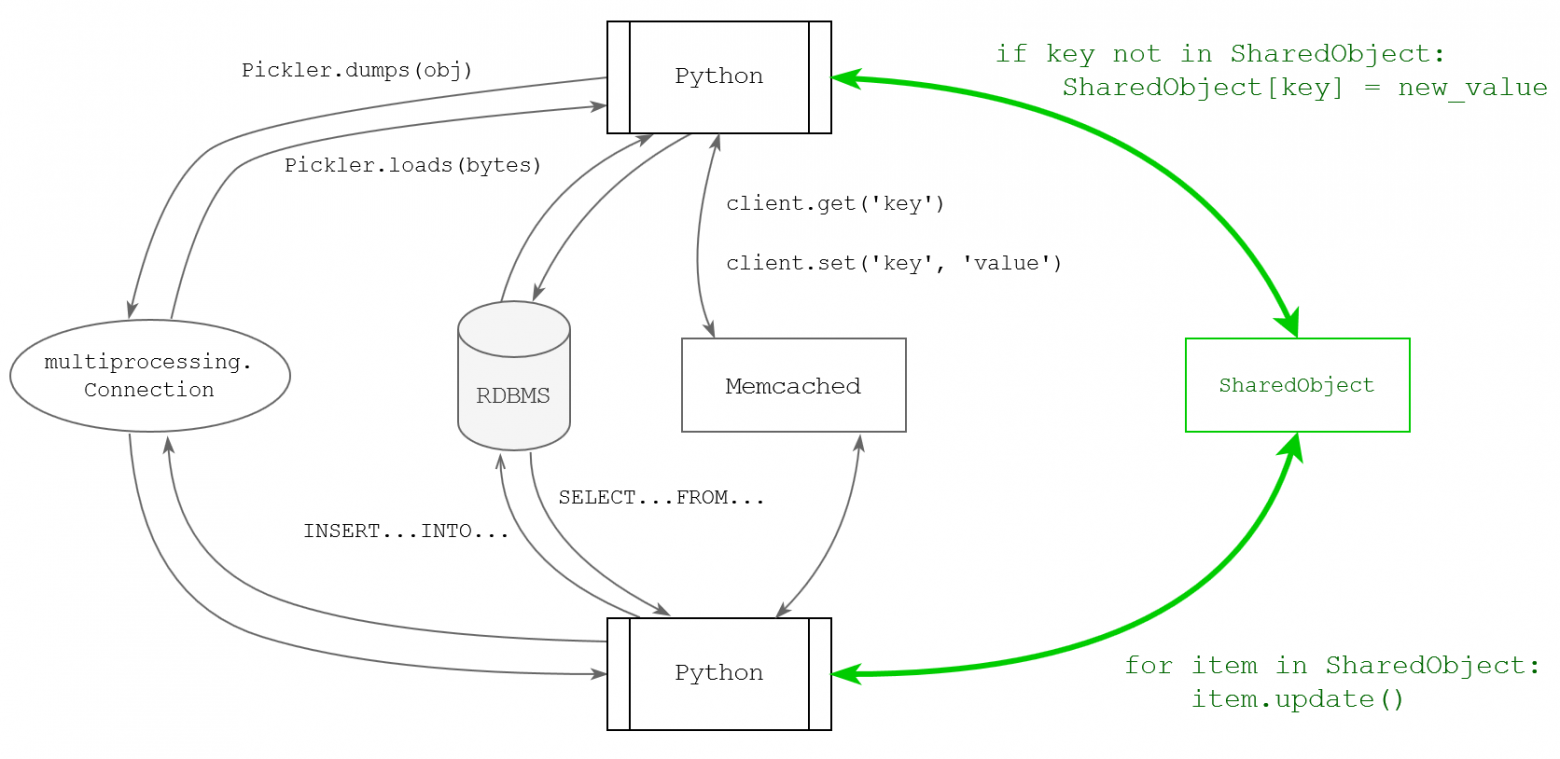
It could also become handy in the light of upcoming multiple interpreters support in CPython.
As far as I know, nobody came that far in trying to provide Python program with native shareable storage. The last closest attempt was Python Object Sharing which is pretty much dead by now. I hope my project won't meet the same fate.
GIL?
Suppose, tomorrow someone has released a python version having no GIL. What's you gonna do next? Write a multithreaded code with tons of race conditions and deadlocks? Because you know you can't just access same object from multiple threads. Eventually, in simple scenarios you would access some big chunk of common state using an actual single or effectively single lock — thus reinventing GIL. Python's mutable objects, iterators, generators, exception handling are all about a state machine, strict step-by-step execution with inherent lack of concurrency.
That's another dead end: you cannot make the program efficient without modifying the language. However, I believe I found a way to make the change as small as possible, keeping most of the usual python code, C extensions, GIL, but introducing a restricted amount of data structures in a shared memory for sharing common data between separate interpreter processes while ensuring their concurrent execution will have the same effect as sequential execution. Some of you might have already guessed — that's something very close to what RDBMS does.
Close example could be a python server-side programming in PostgreSQL. However, this one is more about "Python in Postgres", while we really want a "Postgres in Python", kind of casual access to the "database", like it is a regular python object. Like Clojure language does, which inspired me to implement a similar trick for Python. We also would like to pass these "database objects" to some third-party functions the way third-party code doesn't encounter a difference between regular python objects and database objects.
Unfortunately, I see no easy way to convert a general sequential execution of Python into concurrent effectively-sequential one. Let's look at the example:
a = CreateSharedDict() def func(SharedDict): SharedDict['a'] = 1 SharedDict['b'] = 2 return SharedDict print(func(a))
Although the code don't seem to be troubling, some big questions arise in concurrent environment. What happens when another thread reads SharedObject at the same time? What happens when other thread modifies SharedObject at the same time? Despite the code above does not use SharedObject's fields for any conditional execution or evaluation of other values, it could have e.g.:
def func(SharedDict): SharedDict['a'] = 1 SharedDict['b'] = 1 SharedDict['b'] += SharedDict['a'] return SharedDict
The programmer really wants to see the output:
{ a: 1, b: 2 }
However, with another thread doing the same "func(a)" we might see the output:
{ a: 1, b: 3 }
Which is not what programmer usually expects. So we really want to isolate two threads, make them feel like they are the only users of SharedObject. Most common solution is to use transactional memory. But when would the transaction start and finish? The "a = CreateSharedDict()" variable is global and will not go out of scope unless the program finishes — we cannot just keep transaction running forever because that means other transactions will never see changes to SharedDict. Most likely programmer wants something like this:
def func(SharedDict): start_transaction() try: SharedDict['a'] = 1 SharedDict['b'] = 1 SharedDict['b'] += SharedDict['a'] return copy(SharedDict) finally: commit_transaction()
Which requires the programmer to explicitly mark the transaction's start and commit points. What really can ease this task is some decorator for wrapping a function into transaction:
@transacted def func(SharedDict): SharedDict['a'] = 1 SharedDict['b'] = 1 SharedDict['b'] += SharedDict['a'] return SharedDict
In a language with clear data dependencies it's possible to preliminary determine the required data cells and, for example, lock them for duration of transaction, so the transaction will always succeed if it started successfully. However, in python code some unexpected actions might arise here and there, so we might require a rollback on conflict with other transaction. Which brings us two key requirements for this transactional memory to work:
- ability to cancel the changes
- absence of uncancelable side-effects
The first one can be implemented with magical data objects made specially for our shared data. The second one brings us back to how we declare the transaction in our code. When we have declared some function with "@transacted" decorator, we have to ensure only "magical objects" are used inside. I'm not completely sure on how to implement that, but one of ideas is to create a separate "global scope" for transacted functions using exec() function which allows setting custom scopes and is accepting code objects (so there's no need to recompile the function from text into bytecode). This way we can translate regular python objects into shareable objects when entering the transaction and possibly translate them back when leaving the transaction. Of course, calling some external function from within the transaction does not count as "leaving the transaction", so we can avoid translation here.
Immutable data and strict typing (would be great to have)
Although python is mostly based on mutable data, having some immutable data really helps in multitasking environment. Immutable data is fundamentally uncontended, because you cannot modify it and readers don't conflict with each other. But immutable data is not ideamatic for python, that's why programmer would need to explicitly declare non-ideomatic concept with something like:
@transacted def func(SharedDict): SharedDict['a'] = 1 SharedDict['b'] = 1 SharedDict['b'] += SharedDict['a'] return immutable(SharedDict)
Predefined object structure is of similar importance for multitasking — having to manage locks during structure modification is a burden. Unfortunately, solutions for defining types around Python kind of all suck — they garble the code and make it look unpythonic. So any ideas are welcome.
Lazy vs Eager
Common implementations of software transactional memory (STM) use lazy transaction model, where you make a copy of data at the begginning of transaction, run the transaction, and finally atomically check the data cells to be unmodified while committing the changes into these cells. The major problem of this approach is handling high contention scenarious: when you have 10 threads running for 100 ms inside transaction and 10 ms outside transaction, you are going to have like 99%+ rollbacks i.e. multitasking program running slower than single task. Because Python can be slow e.g. someone carelessly doing HTTP requests inside transactions or just significant calculations, lazy transactions are really no-go for our purpose, at least as a main conflict resolution algorithm.
Eager transaction model is really similar to a regular fine-grained locking access, with the exception of "deadlock" handling: when a transaction encounters already locked reasource, one transaction keeps the lock and other transaction releases the lock. As I already mentioned, in Python we cannot determine all the required resources before the transaction starts. So I actually implemented plural cancelable read-write locks with ticket-based fairness. Something unprecedented as far as I know. For a reason though — this thing is really hard to implement efficiently i.e. using not only naive spinlocks but also putting a younger waiting thread to sleep so OS (Operating System) can use CPU (you know) for some other work including running the conflicting high-priority (older) transaction. In simple words it works like this:

Thus on heavy contentions you get a single tasks performance, while on seldom contentions you get a good concurrent performance. And readers don't block each other at all, just like in lazy transaction model (because of read-write lock).
Now you might be asking: what if I want some kind of simple non-blocking access? This task is supposed to be solved by dirty-reads and immutable data structures. I don't feel like a full-blown multiversion concurrency control is suitable here, because it's just not ideomatic for python code (which only expects a single state) and would become an unnecessary and heavy burden.
Memory management
The most appropriate memory manager for shared memory I found was Boost's "Managed Shared Memory", although it only implements a small subset of features required for a complete working memory manager, so I implemented a simple memory manager consisting of thread-bound heaps (thus threads don't block each other), each heap consisting of several sectors of either "medium" block size or "small" block size. Small blocks are combined into segments, each containing blocks of same size. This is similar to Hoard-like memory managers, although my current implementation is really naive and is unable to release pages back to OS (still can reuse freed blocks from these pages).
The most interesting part starts at memory reclamation. We could have used a plain reference counting, but it only works for simple immutable objects. Things get more complicated with complex objects referencing other objects. Consider following code:
myvar = someobject.a
What happens here with reference counting is:
dereference(someobject)->increment_reference_count local_var_1 = dereference(someobject)->a dereference(local_var_1)->increment_reference_count myvar = local_var_1 dereference(someobject)->decrement_reference_count
Now in between "local_var_1 = dereference(someobject)->a" and "dereference(local_var_1)->increment_reference_count" we can't be sure "someobject.a" has not been changed. It could have been cleared, thus reference count decremented and object released. So we need to postpone memory reclamation until the dereferenced cells are 100% not used. And you might have already guessed when this happens — when the transaction finishes. We just need to wait for finishing of all the transactions which possibly saw the reference. It can be done with any worker out of transaction, or using a separate worker dedicated to this specific task. As I found over time, it's called "epoch-based reclamation" and it's is already used e.g. in Linux kernel for memory reclamation in RCU data structures, though Linux kernel uses different mechanism for determining epoch border.
There's also a small advantage of this reclamation process: we can group the blocks so there would be less frequent accesses across thread-bound heaps, which is the main source of contentions when reclamation is performed right when the reference count drops to zero.
You might say: why reference counting in the first place and not tracing garbage collectors (GC)? Tracing GC can eliminate the need for reference counting altogether, thus eliminating cache misses caused by modification of reference count. Unfortunately, currently I can't see any viable way to organize tracing GC without ruining the system performance. Yes, JVM, CLR, Go, V8 have concurrent GC. However, they usually execute managed code filled with barriers to notify a concurrent GC about modified references which are traced once again under stop-the-world conditions. So they all require stopping of every thread to perform final actions. However, stopping all the python workers can potentially take eternity because some of them are stuck in native code outside GIL, out of our reach.
Also, epoch-based reclamation enables us to postpone the reference count modification until the end of transaction, because no object can be destroyed if it was visible before the start of transaction.
Despite all that, I don't want to say the garbage collection is impossible here — it might still be possible some way or another.
Possible applications
Fundamental modes of workers' cooperation I see are: producer to many consumers; many producers to consumer; parallel processing of bulk prepartitioned data; a big shared storage (cache). The first three could be merged into a single "channel" primitive. Those can be used right away for websites and HTTP-services to implement a complete system with message brokers in pure Python, and to implement cache for Django/Pyramid, or even a fully-fledged in-memory database with durability ensured by existence of multiple nodes instead of classic RDBMS's ACID guarantees.
There is an effort for introducing support of multiple interpreters in CPython:
https://www.python.org/dev/peps/pep-0554/
This would bring some more breathing room by returning back to address space and kernel objects of a single process, thus automatically solving problems like pointer translation and copying kernel objects across processes.
I'd really be glad to see more Python in GUI development, because that's what I've been writing the most in my carrier. Unfortunately, classic GUI libraries such as GTK+, Qt, WPF, native Win32 wrappers (ATL, MFC, VCL) are all single threaded. I mean: you can have many threads, but you should never touch any GUI object outside the main thread. Which is kinda weird if you just think about how many auxiliary things in GUI can work concurrently, and how small the main logic of application usually is.
The current status of implementation
I have some basic implementation of list and dictionary (hash map) containers with rollback support, as well as basic immutable types: string, integer, boolean. I really wish I could have implemented more, but I do that in my spare time and these things also required me to implement some fundamental stuff first: shared memory manager, memory reclamation thread, synchronization objects (shared memory mutex, two flavours of events), and the most complex one is a plural read-write lock. Particulary, channel implementation is still lacking due missing implementation of transacted queue (I cannot simply use something like std::deque because it does not support rollbacks directly).
It's like 11k lines of C code already, with approximately 3k lines of comments and debugging routines. At present moment I'm trying to do some kind of alpha-preview-prerelease as soon as possible, so it can be tested outside of my IDE. However, before releasing the code I would be really glad to hear some of your ideas, suggestions, and critique.
Particulary I'd like to mention the problem of system stability. Corruption of shared memory most likely leads to a crash of the whole system. For example, to deal with this problem LMDB uses read-only file mapping and modifies shared memory using file I/O operations, thus utilizing unified buffer cache in OS. To address the problem currently I restrict the amount of code allowed to directly access shared memory. Also I'm thinking on some kind of detection for hanged/crashed workers, which would otherwise bring memory reclaimer's work to a halt, and crashes are a common thing during testing.
byko3y_at_gmail_com
