В данной статье рассматривается пример реализации распределенной микросервисной авторизации доступа для множества пользователей к множеству ресурсов или операций. Уровень подготовки читателя может быть любой, кто знаком с программированием и проектированием. Так же рассматриваются примеры использования на практике и одна из задач реализована в виде небольшой микросервисной системы.
Основной задачей авторизации доступа является разграничение доступа к целевому объекту на основании данных о субъекте, запрашивающем доступ, и свойствах объекта.
При проектировании любой системы авторизации следует обращать внимания на характеристики, описываемые ниже.
Авторизация принимает решение о разграничении доступа на основе множества входных параметров. Если таковых будет слишком много, либо мерность множеств окажется слишком большой, то авторизация будет терять слишком много ресурсов на выполнение ненужных операций. Это как сортировать данные пузырьком и qsort. Не следует выполнять ненужные операции.
Если у вашей системы есть на входе A,B,C,D,E,F — факты о пользователе, то если вы будете объединять все в одно, то получите A * B * C * D * E * F комбинаций, которые невозможно эффективно кешировать. По возможности следует найти такую комбинацию входных, что бы у вас было A * B * C и D * E * F комбинаций, а еще лучше A * B, C * D, E * F, которые вы уже легко сможете вычислять и кешировать.
Эта характеристика очень важна так же для построения системы правил, которые будут предоставлять пользователям доступы.
Второй характеристикой является предел детализации авторизации, когда дальнейшее разграничение доступа становится уже невозможным. Например вы можете разграничивать доступ к ручкам микросервиса, но уже не иметь возможности ограничить доступ к сущностям, которые она выдает. Либо доступ к сущности вы ограничиваете, но вот операции доступны все и всем. И т.д.
От того, насколько детально нужно работать авторизации зависит как время восстановления, так и энтропия входных данных, т.к. работать вам придется со все увеличивающимся массивом входных данных. Разумеется, если вы не предпринимаете попытки для того, что бы уровни детализации друг на друга влияли аддитивно, а не мультипликативно.
Прежде чем проектировать, необходимо договориться о терминах и структурах данных с их взаимосвязями.

Вы можете убрать ненужные вам связи, главное — это то, что вам необходимо ограничивать.
Детально опишем все имеющиеся определения с которыми будем дальше работать.
Субъект, чей доступ необходимо авторизовать.
Данное определение задает субъекты, которые могут быть как людьми, так и автоматическими системами, которые получают доступ к вашим ресурсам. У любого пользователя могут быть свои роли, разрешения и группы.
Множество ресурсов объединенных в единое целое, как пример сервис проектов.
В рамках микросервисной архитектуры основным направлением разработки является выделение таких множеств ресурсов, которые можно назвать сервисом, так что бы программно-аппаратная часть могла эффективно обрабатывать заданный объем данных.
Единичный объем информации для работы авторизации, например проект.
В рамках сервиса могут существовать ресурсы, доступ к которым необходимо ограничивать. Это может быть как файл в облачном сервисе, так и заметка, видимая ограниченному кругу лиц.
Право пользователя выполнять операцию над сервисом и/или ресурсом.
Множество разрешений, по сути под словом роль всегда подразумевается множество разрешений.
Следует отметить, что в системе может не быть ролей и напрямую задаваться набор разрешений для каждого пользователя в отдельности. Так же в системе могут отсутствовать разрешения (речь про хранение их в виде записей БД), но быть роли, при этом такие роли будут называться статичными, а если в системе существуют разрешения, тогда роли называются динамическими, так как можно в любой момент поменять, создать или удалить любую роль так, что система все равно продолжит функционировать.
Ролевые модели позволяют как выполнять вертикальное, так и горизонтальное разграничение доступа (описание ниже). Из типа разграничения доступа следует, что сами роли делятся на типы:
Но отсюда следует вопрос, если у пользователя есть глобальная роль и локальная, то как определить его эффективные разрешения? Поэтому авторизация должна быть в виде одной из форм:
Подробное описание использования типа ролей и формы авторизации ниже.
Роль имеет следующие связи:
Следует отметить, что реализация статичных ролей требует меньше вычислительных ресурсов (при определении эффективных разрешений пользователя будет на один джойн меньше), но вносить изменения в такую систему можно только релизным циклом, однако при большом числе ролей гораздо выгоднее использовать разрешения, так как чаще всего микросервису нужно строго ограниченное их число, а ролей с разрешением может быть бесконечное число. Для больших проектов, стоит задуматься о том, что бы работать только с динамическими ролями.
Используя группы можно объединить множество ресурсов, в том числе расположенных в разных сервисах в одно целое, и управлять доступом к ним используя одну точку. Это позволяет гораздо проще и быстрее реализовывать предоставление доступа пользователя к большим массивам информации, не требуя избыточных данных в виде записи на каждый доступ к каждому ресурсу по отдельности вручную или автоматически. По сути вы решаете задачу предоставления доступа к N ресурсам создавая 1 запись.
Группы используются исключительно для горизонтального разграничения доступа (описание ниже). Даже если вы будете использовать группы для доступа к сервисам, то это все равно горизонтальное разграничение доступа, потому что сервис — это совокупность ресурсов.
Группа имеет следующие связи:
Самым простым способом представить себе работу авторизации — это нарисовать таблицы на каждого пользователя и каждый сервис, где колонки будут задавать разрешения, а строки — ресурсы, на пересечении ставятся галочки там, где доступ разрешен (привет excel-warrior'ам).
Для обеспечения доступа вы можете либо связать пользователя с ролью, что даст вам заполнение соответствующих разрешению ролей колонок в таблицах — такое разграничение называется вертикальным. Либо вы можете связать пользователя, роль и ресурс, что ограничит доступ до отдельного ресурса — такое предоставление доступ является горизонтальным. Вторым вариантом горизонтального доступа являются группы, когда вы заполняете множество строк соответствующими разрешениями, когда включаете пользователя в эту группу.
Несмотря на то, что все роли могут хранится в единой БД, то вот связи между ними и пользователями хранить все вместе на всю вашу огромную систему — это типичный антипаттерн, делать так является грубейшей ошибкой, это все равно что POSIX права на файлы хранить в облачном сервисе, вместе с таблицей inode. Так же вы теряете огромную часть важного функционала, который вам могла бы предоставлять ваша БД сразу, например пагинация ресурсов с разграничением доступа к строкам.
Связи пользователя с глобальными ролями хранить следует в самом сервисе ролей. Связь же пользователя с локальной ролью необходимо хранить там же, где лежат ресурсы соответствующей роли. Например если у вас есть глобальная роль Менеджер проектов, то хранить ее будем в сервисе ролей, а локальная роль Менеджер проекта (окончание у них разное) — уже в сервисе проектов, при этом связь будет не (Пользователь, Роль), а (Пользователь, Роль, Проект). Либо в случае групп — (Группа, Проект). Под это дело можно будет написать специальный авторизационный клиент, и когда в другом микросервисе, например документов, вам нужно будет авторизовать доступ к проекту, то вы всего лишь повесите 2 аннотации @RequireRole(User) @ProjectAccess. Все остальное уже сделано либо самим спрингом, либо авторизационными клиентами.
При таком подходе вы можете фильтровать видимость данных уже на уровне вашей БД, в сам запрос вам нужно будет отдать массив групп и ролей пользователя, что бы дополнительно отфильтровать данные. Вам ничто не мешает теперь показывать страницу только тех ресурсов, которые пользователь может видеть! Даже если этих ресурсов миллионы.
Из-за того, что у теперь у нас существуют два варианта наборов разрешений пользователя, то можно выделить два варианта, как объединить все вместе:
Одним из важных преимуществ конъюнктивной формы является жесткий контроль за всеми операциями, которые может выполнять пользователь, а именно — без глобального разрешения пользователь не сможет получить доступ в следствие ошибки на месте. Так же реализация в виде программного продукта горазо проще, так как достаточно сделать последовательность проверок, каждая из которых либо успешна, либо бросает исключение.
Дизъюнктивная форма позволяет гораздо проще делать супер-админов и контролировать их численность, однако на уровне отдельных сервисов потребует написания своих алгортмов авторизации, которые в начале получит все разрешения пользователя, а уже потом либо успешно пройдет, либо бросит исключение. Однако преимуществом является тот факт, что можно использовать первый положительный ответ, что бы дать зеленый свет запросу.
Рекомендуется всегда использовать только конъюнктивную форму авторизации в виду ее большей гибкости и возможности снизить вероятность появления инцидентов по утечке данных. Так же именно конъюнктивная форма авторизации имеет большую устойчивость к ДДОС атакам в виду использования меньшего объема ресурсов. Ее проще реализовать и использовать, отлаживать. Разумеется можно и дизъюнктивную форму натравить на анализ аннотаций метода и поиск соответствующих сервисов, но запросы вы отправлять будете скорее всего синхронно, один за другим, если же будете делать асинхронные вызовы, то много ресурсов будет уходить в пустоту, оно вам надо?
Основной проблемой при работе авторизации является точка в которой необходимо кешировать результаты, что бы работало быстрее все, да еще желательно так, что бы нагрузка на ЦПУ не была высокой. Вы можете поместить все ваши данные в память и спокойно их читать, но это дорогое решение и не все готовы будут себе его позволить, особенно если требуется всего лишь пара ТБ ОЗУ. Второй крайностью является попытка кешировать входные параметры и результат (или запрос и ответ), в результате опять же потребуется пара ТБ ОЗУ, но уже для хранения всех ваших вариантов.
Правильным решением было бы найти такие места, которые бы позволяли с минимальными затратами по памяти давать максимум быстродействия.
Предлагаю решить такую задачу на примере ролей пользователя и некоего микросервиса, которому нужно проверять наличие роли у пользователя. Разумеется в данном случае можно сделать карту (Пользователь, Роль) -> Boolean. Проблема в том, что все равно придется на каждую пару делать запрос на удаленный сервис. Даже если вам данные будут предоставлять за 0,1 мс, то ваш код будет работать все равно медленно. Очевидным решением будет кешировать сразу роли пользователя! В итоге у нас будет кеш Пользователь -> Роль[]. При таком подходе на какое-то время микросервис сможет обрабатывать запросы от пользователя без необходимости нагружать другие микросервисы. Разумеется читатель спросит, а что если ролей у пользователя десятки тысяч? Ваш микросервис всегда работает с ограниченным количеством ролей, которые он проверяет, соответственно вы всегда можете либо захардкодить список, либо найти все аннотации, собрать все используемые роли и фильтровать только их.
Полагаю, что ход мыслей, которому стоит следовать, стал понятен.
Предложенная модель дает возможность сделать масштабируемую систему авторизации. Позволяет сделать глобальное разграничение один раз и далее только корректировать, добавляя новые роли, разрешения, группы, все более детализируя доступ к каждому конкретному ресурсу каждому пользователю.
Теперь, определившись с терминами, можно разобрать несколько задачек, для того, что бы видеть как на практике применить материал.
Организатор может создать аукцион, пригласить участников. Участник может принять приглашение, сделать ставку.
Для того, что бы организатор мог создавать аукционы — нужно создать глобальную роль Организатор и при попытке создать аукцион — требовать эту роль. Созданные приглашения уже хранят в себе идентификаторы пользователей, поэтому когда пользователь делает ставку в аукционе, то это будет простейший запрос наличия записи перед вставкой ставки в аукцион.
Огромная логистическая компания требует разграничить доступы для супервизоров и продавцов да еще с учетом региона. Работа такова, что продавец может выставить заявку на получение товара, а супервизор уже решает кому и сколько достанется. Соответственно продавец может видеть свой магазин и все товары в нем, а так же созданные им заявки, статус их обработки. Супервизор может видеть все магазины региона, в котором он работает, их заявки и историю исполнения заявок, так же он может перевести заявку в состояние исполнения для непосредственно доставки в магазин нужного товара.
Для реализации такого функционала нам потребуется реестр регионов и магазинов в качестве отдельного микросервиса, назовем его С1. Заявки и историю будем хранить на С2. Авторизация — А.
Далее при обращении продавца для получения списка его магазинов (а у него может быть их несколько), С1 вернет только те, в которых у него есть меппинг (Пользователь, Магазин), так как ни в какие регионы он не добавлен и для продавца регионы всегда пустое множество. Разумеется при условии, что у пользователя есть разрешение просматривать список магазинов — посредством микросервиса А.
При получении заявок магазина, проверка в А разрешений смотреть заявки, а затем С2 отравляет запрос в С1 и получает разрешение или запрет на доступ к магазину.
Работа супервизора будет выглядеть немного иначе, вместо регистрации супервизора на каждый магазин региона, мы сделаем меппинги (Пользователь, Регион) и (Регион, Магазин) в этом случае для супервизора у нас всегда будет список актуальных магазинов с которыми он работает.
В таком случае, когда супервизор решит перевести заявку на поставку в исполнение, то после проверки, что у него есть разрешение в А, С2 отправит проверку, что у супервизора есть доступ к магазину.
Некое министерство обязано выкладывать документы в общественный доступ, но часть документа является не предназначенной для показа любому желающему (назовем эту часть — номер телефона). Сам документ состоит из блоков, каждый из которых может быть либо текстом, либо номером телефона — скрытой частью, которую видеть могут только особые пользователи, подписавшие соглашение о неразглашении.
Когда пользователь обращается в сервис для получения блоков документа, микросервис в авторизации проверяет роль пользователя на чтение документов, далее в БД каждый блок имеет флаг — секрет. У документа есть меппинг (Пользователь, Документ) — список пользователей, которые подписали соглашение. В этом случае при получении из БД блоков документа можно сразу отфильтровать невидимые для пользователя блоки одним запросом.
Если у вас большая команда, и много проектов, и такая команда у вас не одна, то координировать работу их будет той еще задачей. Особенно если таких команд у вас тысячи. Каждому разработчику вы доступы не пропишите, а если у вас человек еще и в нескольких командах работает, то разграничивать доступ станет еще сложнее. Например если 2 команды работают над одним проектом, и разработчик в обоих командах присутствует, из одной его пнули, как теперь определять актуальный состав его проектов?
Такую проблему проще всего решить при помощи групп.
Группа будет объединять все необходимые проекты в одно целое. При добавлении участника в команду, добавляем меппинг (Пользователь, Группа, Роль).
Допустим, что Вася — разработчик и ему нужно вызвать метод develop на микросервисе для выполнения своих обязанностей. Этот метод потребует у Васи роли в проекте — Разработчик.
Как мы уже договаривались — регистрация пользователя в каждый проект для нас недопустима. Поэтому микросервис проектов обратится в микросервис групп, что бы получить список групп, в которых Вася — Разработчик. Получив список этих групп можно легко проверить уже в БД микросервиса проектов — есть ли у проекта какая-нибудь из полученных групп и на основании этого предоставлять или запрещать ему доступ.
Компания ОАО «ПьемЧай» ежедневно требует работы от миллиона сотрудников и сотни тысяч гостей. Все сотрудники пьют чай и в этом состоит их работа. В компании есть гости, которые пить чай не могут, для них доступны опции, которые позволяют им видеть какой чай они смогут пить на своей будущей работе, а так же лучших сотрудников года, месяца и недели. Некоторые сотрудники в пандемию работают удаленно и доступ к чаю им предоставляет курьерская служба Кракен, прямо к точке доставки. Удаленные сотрудники могут получать чай только из той точки доставки, к которой они привязаны. Находясь в офисе они все равно могут пить чай как обычные сотрудники.
Для решения поставленной задачи нам необходимы следующие микросервисы:
Графически это будет выглядеть так:

В качестве БД будем использовать PostgreSQL.
Предусмотрим следующие обязательные для решения задачи роли:
Для реализации воспользуемся Spring фреймворком, он довольно медленный, но зато на нем легко и быстро можно реализовывать приложения. Так как за перформансом мы не гонимся, то попробуем на нем достичь скромных 1к рпс авторизованных пустых запросов (хотя люди на спринге умудрялись 100к пустых запросов проворачивать [1]).
Весь проект поделен на несколько репозиториев:
Для начала разберемся с базой данных ролевой модели:
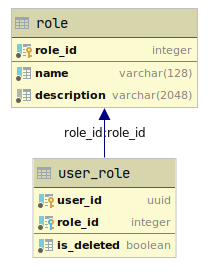
Пользователи задаются другим сервисом, который в нашем случае даже не реализован, так же как аутентификация. Сделано для упрощения примера.
Обратите внимание на поле is_deleted, оно необходимо, так же как и индекс на (user_id,role_id,is_deleted), иначе работать ничего не будет — удаление записей из больших таблиц приведет к снижению производительности (а у нас расчет на 5 млн строк). Если у вас окажется слишком много записей с флагом is_deleted=true (например 1 млн строк), то гораздо выгоднее будет в техническое окно запустить скрипт на удаление таких записей разом, чем удалять по запросу.
Для работы с таблицами нам потребуется сделать REST API, причем одно для пользователей — людей, второе для пользователей — сервисов.
Само апи довольно легко в понимании, но оно работает медленно (в районе 4к-7к рпс из-за БД), причем как получение ролей пользователя, так и проверка наличия ролей. Для ускорения работы необходимо сделать кеширование, поэтому добавляем в конфигурацию mafp.role.cache.enable. Кеш можно сделать в виде карты, но лучше использовать уже готовое решение com.google.common.cache.Cache и сэкономить себе кучу нервов, потому что через HashMap или WeakHashMap сделать быстро не удастся.
И в данный момент у нас появляется вопрос, а что именно нужно кешировать? В данном случае лучшим вариантом будет — сами роли, вернее их имена на каждого пользователя, так мы сэкономим запросы к БД.
В абстрактном классе заведем кеш под эти данные, но есть одно но. Если хранить Set, то нам придется столкнуться с тем, что поиск в случае большого количества ролей у пользователя будет работать медленно (в JVM строки никогда не работали быстро и не будут). Так же проблемой будет то, что строки, которые мы получим из хибернейта не будут интернированными или каким-то образом преобразованными до синглтонов в рамках нашего кеша, т.е. «a» == «a» всегда для нас будет ложно, и соответственно будет сравнение строк, а нужно — указателей или простых значений, например целых чисел. Это помимо того, что у нас память будет забиваться одними и теми же строками.
Поэтому необходимо добавить карту, в которой будем хранить меппинг (Строка, Целое). И в кеше хранить уже не набор имен ролей пользователя, а набор идентификаторов ролей пользователя, причем эти числа могут не совпадать с идентификаторами в вашей БД. Поиск Integer в HashSet выполняется намного быстрее, чем строки, при этом у вас де факто все строки будут интернированными, что в нашем случае является обязательным шагом — иначе потребление памяти будет расти неконтролируемым образом.
Получив абстрактный класс, можно реализовать его для самого ролевого сервиса, что бы авторизовать доступы к нему, а так же для клиента, что бы проще было пользоваться в других сервисах. Обратите внимание, что на клиенте мы кешируем не все роли, а только те, что зарегистрированы в белом списке, это позволит нам на каждом сервисе при желании хранить хоть 100к строк кеша, потратив чуть больше 10 мб хипа.
Если инициализировать БД 500к пользователями, 10к ролей и каждому пользователю выдать до 10 ролей, то можно провести нагрузочное тестирование. Результат на выданных 4 ядрах от моего i7-9700k получится скоромный — среднее 12992, минимум 12832, максимум 13088 rps. Результат получен на 16 потоках клиента.
Но основная проблема при тестировании вашей авторизации — это тот факт, что авторизовать надо работу чужого сервиса, вы можете рисовать любые цифры, но другие сервисы не будут работать с приемлемой производительностью.
Идеальным тестом для авторизации — является отношение количества пустых запросов за единицу времени к количеству авторизованных пустых запросов за единицу времени для N (желаемое число под в вашей системе, требующих авторизацию, хотя вы можете вычислять это значение от 1 до N и показывать в виде графика). При этом записывать будем в виде Ка1 коэффициент авторизации 1, если количество под равно 1. Чем ближе к 1 это значение, тем лучше работает ваша авторизация как слой. Именно поэтому полученные выше 13к рпс не имеют никакого значения, даже если вы сделаете авторизацию, которая выдает 10e100 rps, она будет бесполезна, если коэффициент авторизации окажется скажем 1000, потому что плохим результатом является уже 100 — т.е. ваша авторизация в 100 раз замедляет ничего не делающее приложение.
В данной статье будет измеряться только Ка1, потому что железа нет.
Приступим к чайному сервису. Для тестирования авторизации у нас создан в нем ендпоинт POST /api/v1/tea/dummy.
Если отключить авторизацию (/noauth в конец добавить), то тестирование покажет нам на выданные 2 ядра чайному сервису и 2 ролевому — среднее 18208, минимум 18048, максимум 18560 на 32 потоках клиента — это количество запросов, которое может обработать наша система с заданными настройками, исключая какую либо бизнес логику, быстрее работать у нас уже ничего не будет. Включив же авторизацию, которая заключается в проверке у пользователя роли User, получим следующие показания на 6 потоках клиента — среднее 1062, минимальное 1062, максимальное 1068.
При этом тестировалось на 100к случайно выбираемых пользователях! Ка1 = 17.1.
И напоследок попьем чай (делаем инсерты в БД) в 6 потоков клиента на POST /api/v1/tea получим среднее 1086, минимум 1086, максимум 1086 (а должно быть ~4к). О чем это говорит нам? О том что авторизация является для нас боттлнеком, который замедляет работу системы (из-за сильной нагрузки на ЦПУ, что говорит о том, что алгоритм кеширования у нас не очень). Еще о том, что погрешности измерений огромные.
Коэффициент авторизации позволит вам не только оценить работу алгоритмов авторизации, но и очертить границы в которых может работать весь ваш комплекс микросервисов, а так же сообщить вам — имеет ли смысл оптимизировать код конкретного микросервиса или нет, потому что может так оказаться, что выигрыш будет 0.
Если же всего лишь включить роль в JWT токен, то с 12 потоками клиента можно получить от dummy среднее 6396, минимум 6372, максимум 6444. Т.е. Ка1 оказался равен 2.8!
А что будет, если отключить кеширование на клиенте, не использовать роли JWT и оставить его только на ролевой модели? Производительность вырастет, потому что сетевые задержки около нулевые и нагрузка на ЦПУ для dummy станет минимальной — среднее 3817, минимум 3806, максимум 3828, что говорит нам о Ка1 = 4.7. Однако следует учитывать, что такое решение не будет масштабируемым, потому что каждый клиент будет обращаться постоянно к сервису ролевой модели и увеличивать на него нагрузку, уже при сотне под начнутся серьезные проблемы, делающие невозможной работу авторизации, разве что у вас на каждый сервис, которому нужна авторизация будет пода авторизации, которая эту функцию будет выполнять, есть в интернете такие сетевые инженеры, которые любую проблему готовызалить водой решить добавив под.
А выпустить кракена так и не удалось, потому что железо не выдержит испытаний. Может быть в другой раз, когда будет бюджет недельку-другую погонять кластер на сотню машинок по 2-4 ядра с парой гиг памяти.
В статье предложена универсальная модель для авторизации доступа множеству пользователей к множеству ресурсов с минимальными потерями по производительности, позволяющая делать эффективное кеширование и хранение промежуточных данных на микросервисах, для сборки результата авторизации just-in-time. Предложена метрика (в виде коэффициента), для оценки работы авторизации микросервисов с учетом требований работы всего комплекса и показано, как он может меняться в зависимости от подхода, а именно наличия/отсутствия кеша, хранения ролей в JWT токене и т.д. Не показано, что этот коэффициент всегда растет с увеличением количества под в системе.
Предложенная модель данных позволяет разделить данные между частями микросервисной архитектуры, тем самым снизив требования к железу, дает возможность работать только с теми данными, которые нужны в конкретный момент времени конкретному сервису, не пытаться искать в огромном массиве все подряд или пытаться искать данные в полностью обобщенном хранилище.
Показано, что при малом количестве микросервисов нет смысла проводить кеширование на клиенте авторизации, так как это приведет к большей нагрузке на ЦПУ. Предоставлены данные, которые позволяют сделать вывод, что необходимо балансировать ресурсы в зависимости от размеров системы, если она слишком мала, то есть смысл нагружать больше сеть, но при увеличении и разрастании выгоднее добавить пару ядер в микросервисы, для обеспечения работы кешей и разгрузки сети, микросервисов авторизационных данных. Вопрос больше в том, что для вас дешевле, найти дополнительные ядра или сеть улучшать с гигабитной до десятигигабитной, особенно если можно сделать авторизацию, когда достаточно для ее работы 100 мбит сети.
1 Немного теории
Основной задачей авторизации доступа является разграничение доступа к целевому объекту на основании данных о субъекте, запрашивающем доступ, и свойствах объекта.
При проектировании любой системы авторизации следует обращать внимания на характеристики, описываемые ниже.
1.1 Время восстановления/энтропия входных параметров
Авторизация принимает решение о разграничении доступа на основе множества входных параметров. Если таковых будет слишком много, либо мерность множеств окажется слишком большой, то авторизация будет терять слишком много ресурсов на выполнение ненужных операций. Это как сортировать данные пузырьком и qsort. Не следует выполнять ненужные операции.
Если у вашей системы есть на входе A,B,C,D,E,F — факты о пользователе, то если вы будете объединять все в одно, то получите A * B * C * D * E * F комбинаций, которые невозможно эффективно кешировать. По возможности следует найти такую комбинацию входных, что бы у вас было A * B * C и D * E * F комбинаций, а еще лучше A * B, C * D, E * F, которые вы уже легко сможете вычислять и кешировать.
Эта характеристика очень важна так же для построения системы правил, которые будут предоставлять пользователям доступы.
1.2 Детализация авторизации
Второй характеристикой является предел детализации авторизации, когда дальнейшее разграничение доступа становится уже невозможным. Например вы можете разграничивать доступ к ручкам микросервиса, но уже не иметь возможности ограничить доступ к сущностям, которые она выдает. Либо доступ к сущности вы ограничиваете, но вот операции доступны все и всем. И т.д.
От того, насколько детально нужно работать авторизации зависит как время восстановления, так и энтропия входных данных, т.к. работать вам придется со все увеличивающимся массивом входных данных. Разумеется, если вы не предпринимаете попытки для того, что бы уровни детализации друг на друга влияли аддитивно, а не мультипликативно.
2 Обобщенная модель данных
Прежде чем проектировать, необходимо договориться о терминах и структурах данных с их взаимосвязями.
Вы можете убрать ненужные вам связи, главное — это то, что вам необходимо ограничивать.
Детально опишем все имеющиеся определения с которыми будем дальше работать.
2.1 Пользователь
Субъект, чей доступ необходимо авторизовать.
Данное определение задает субъекты, которые могут быть как людьми, так и автоматическими системами, которые получают доступ к вашим ресурсам. У любого пользователя могут быть свои роли, разрешения и группы.
2.2 Сервис
Множество ресурсов объединенных в единое целое, как пример сервис проектов.
В рамках микросервисной архитектуры основным направлением разработки является выделение таких множеств ресурсов, которые можно назвать сервисом, так что бы программно-аппаратная часть могла эффективно обрабатывать заданный объем данных.
2.3 Ресурс
Единичный объем информации для работы авторизации, например проект.
В рамках сервиса могут существовать ресурсы, доступ к которым необходимо ограничивать. Это может быть как файл в облачном сервисе, так и заметка, видимая ограниченному кругу лиц.
2.4 Разрешение
Право пользователя выполнять операцию над сервисом и/или ресурсом.
2.5 Роль
Множество разрешений, по сути под словом роль всегда подразумевается множество разрешений.
Следует отметить, что в системе может не быть ролей и напрямую задаваться набор разрешений для каждого пользователя в отдельности. Так же в системе могут отсутствовать разрешения (речь про хранение их в виде записей БД), но быть роли, при этом такие роли будут называться статичными, а если в системе существуют разрешения, тогда роли называются динамическими, так как можно в любой момент поменять, создать или удалить любую роль так, что система все равно продолжит функционировать.
Ролевые модели позволяют как выполнять вертикальное, так и горизонтальное разграничение доступа (описание ниже). Из типа разграничения доступа следует, что сами роли делятся на типы:
- Глобальные — роли применимые ко всем сервисам — для вертикального разграничения;
- Локальные — применяются только к ресурсу — горизонтальное разграничение.
Но отсюда следует вопрос, если у пользователя есть глобальная роль и локальная, то как определить его эффективные разрешения? Поэтому авторизация должна быть в виде одной из форм:
- Конъюнктивная
- Дизъюнктивная
Подробное описание использования типа ролей и формы авторизации ниже.
Роль имеет следующие связи:
- Пользователь — у каждого пользователя может быть множество ролей;
- Разрешение — каждая роль объединяет в себе несколько разрешений всегда вне зависимости от типа ролей.
Следует отметить, что реализация статичных ролей требует меньше вычислительных ресурсов (при определении эффективных разрешений пользователя будет на один джойн меньше), но вносить изменения в такую систему можно только релизным циклом, однако при большом числе ролей гораздо выгоднее использовать разрешения, так как чаще всего микросервису нужно строго ограниченное их число, а ролей с разрешением может быть бесконечное число. Для больших проектов, стоит задуматься о том, что бы работать только с динамическими ролями.
2.6 Группа
Используя группы можно объединить множество ресурсов, в том числе расположенных в разных сервисах в одно целое, и управлять доступом к ним используя одну точку. Это позволяет гораздо проще и быстрее реализовывать предоставление доступа пользователя к большим массивам информации, не требуя избыточных данных в виде записи на каждый доступ к каждому ресурсу по отдельности вручную или автоматически. По сути вы решаете задачу предоставления доступа к N ресурсам создавая 1 запись.
Группы используются исключительно для горизонтального разграничения доступа (описание ниже). Даже если вы будете использовать группы для доступа к сервисам, то это все равно горизонтальное разграничение доступа, потому что сервис — это совокупность ресурсов.
Группа имеет следующие связи:
- Пользователи — множество пользователей участвующих в группе, сама связь может быть при этом:
- Безусловной — связь определяется только пользователем и группой, такая связь всегда уникальна;
- Условной — связь определяет роль/разрешение пользователю в группе, например вы можете добавить пользователя с разрешением модерировать ресурсы группы, таких связей может быть сколько угодно.
- Ресурсы — список ресурсов этой группы.
2.7 Вертикальное и горизонтальное разграничение доступа.
Самым простым способом представить себе работу авторизации — это нарисовать таблицы на каждого пользователя и каждый сервис, где колонки будут задавать разрешения, а строки — ресурсы, на пересечении ставятся галочки там, где доступ разрешен (привет excel-warrior'ам).
Для обеспечения доступа вы можете либо связать пользователя с ролью, что даст вам заполнение соответствующих разрешению ролей колонок в таблицах — такое разграничение называется вертикальным. Либо вы можете связать пользователя, роль и ресурс, что ограничит доступ до отдельного ресурса — такое предоставление доступ является горизонтальным. Вторым вариантом горизонтального доступа являются группы, когда вы заполняете множество строк соответствующими разрешениями, когда включаете пользователя в эту группу.
2.8 Глобальность/локальность авторизации доступа в микросервисах
Несмотря на то, что все роли могут хранится в единой БД, то вот связи между ними и пользователями хранить все вместе на всю вашу огромную систему — это типичный антипаттерн, делать так является грубейшей ошибкой, это все равно что POSIX права на файлы хранить в облачном сервисе, вместе с таблицей inode. Так же вы теряете огромную часть важного функционала, который вам могла бы предоставлять ваша БД сразу, например пагинация ресурсов с разграничением доступа к строкам.
Связи пользователя с глобальными ролями хранить следует в самом сервисе ролей. Связь же пользователя с локальной ролью необходимо хранить там же, где лежат ресурсы соответствующей роли. Например если у вас есть глобальная роль Менеджер проектов, то хранить ее будем в сервисе ролей, а локальная роль Менеджер проекта (окончание у них разное) — уже в сервисе проектов, при этом связь будет не (Пользователь, Роль), а (Пользователь, Роль, Проект). Либо в случае групп — (Группа, Проект). Под это дело можно будет написать специальный авторизационный клиент, и когда в другом микросервисе, например документов, вам нужно будет авторизовать доступ к проекту, то вы всего лишь повесите 2 аннотации @RequireRole(User) @ProjectAccess. Все остальное уже сделано либо самим спрингом, либо авторизационными клиентами.
При таком подходе вы можете фильтровать видимость данных уже на уровне вашей БД, в сам запрос вам нужно будет отдать массив групп и ролей пользователя, что бы дополнительно отфильтровать данные. Вам ничто не мешает теперь показывать страницу только тех ресурсов, которые пользователь может видеть! Даже если этих ресурсов миллионы.
2.9 Конъюнктивная/дизъюнктивная форма авторизации
Из-за того, что у теперь у нас существуют два варианта наборов разрешений пользователя, то можно выделить два варианта, как объединить все вместе:
- Конъюнкция — требуем, что бы пользователь имел как глобальное разрешение, так и локальное, в этом случае можно закрыть доступ сотруднику сразу после его увольнения, не тратя время и ресурсы на чистку его записей в БД;
- Дизъюнкция — если у пользователя есть глобальное разрешение, то предоставляем доступ ко всем ресурсам, если есть доступ только к конкретному ресурсу, то только к нему.
Одним из важных преимуществ конъюнктивной формы является жесткий контроль за всеми операциями, которые может выполнять пользователь, а именно — без глобального разрешения пользователь не сможет получить доступ в следствие ошибки на месте. Так же реализация в виде программного продукта горазо проще, так как достаточно сделать последовательность проверок, каждая из которых либо успешна, либо бросает исключение.
Дизъюнктивная форма позволяет гораздо проще делать супер-админов и контролировать их численность, однако на уровне отдельных сервисов потребует написания своих алгортмов авторизации, которые в начале получит все разрешения пользователя, а уже потом либо успешно пройдет, либо бросит исключение. Однако преимуществом является тот факт, что можно использовать первый положительный ответ, что бы дать зеленый свет запросу.
Рекомендуется всегда использовать только конъюнктивную форму авторизации в виду ее большей гибкости и возможности снизить вероятность появления инцидентов по утечке данных. Так же именно конъюнктивная форма авторизации имеет большую устойчивость к ДДОС атакам в виду использования меньшего объема ресурсов. Ее проще реализовать и использовать, отлаживать. Разумеется можно и дизъюнктивную форму натравить на анализ аннотаций метода и поиск соответствующих сервисов, но запросы вы отправлять будете скорее всего синхронно, один за другим, если же будете делать асинхронные вызовы, то много ресурсов будет уходить в пустоту, оно вам надо?
2.10 О кешировании данных
Основной проблемой при работе авторизации является точка в которой необходимо кешировать результаты, что бы работало быстрее все, да еще желательно так, что бы нагрузка на ЦПУ не была высокой. Вы можете поместить все ваши данные в память и спокойно их читать, но это дорогое решение и не все готовы будут себе его позволить, особенно если требуется всего лишь пара ТБ ОЗУ. Второй крайностью является попытка кешировать входные параметры и результат (или запрос и ответ), в результате опять же потребуется пара ТБ ОЗУ, но уже для хранения всех ваших вариантов.
Правильным решением было бы найти такие места, которые бы позволяли с минимальными затратами по памяти давать максимум быстродействия.
Предлагаю решить такую задачу на примере ролей пользователя и некоего микросервиса, которому нужно проверять наличие роли у пользователя. Разумеется в данном случае можно сделать карту (Пользователь, Роль) -> Boolean. Проблема в том, что все равно придется на каждую пару делать запрос на удаленный сервис. Даже если вам данные будут предоставлять за 0,1 мс, то ваш код будет работать все равно медленно. Очевидным решением будет кешировать сразу роли пользователя! В итоге у нас будет кеш Пользователь -> Роль[]. При таком подходе на какое-то время микросервис сможет обрабатывать запросы от пользователя без необходимости нагружать другие микросервисы. Разумеется читатель спросит, а что если ролей у пользователя десятки тысяч? Ваш микросервис всегда работает с ограниченным количеством ролей, которые он проверяет, соответственно вы всегда можете либо захардкодить список, либо найти все аннотации, собрать все используемые роли и фильтровать только их.
Полагаю, что ход мыслей, которому стоит следовать, стал понятен.
2.11 Выводы по обобщенной модели
Предложенная модель дает возможность сделать масштабируемую систему авторизации. Позволяет сделать глобальное разграничение один раз и далее только корректировать, добавляя новые роли, разрешения, группы, все более детализируя доступ к каждому конкретному ресурсу каждому пользователю.
3 Как использовать обобщенную модель данных
Теперь, определившись с терминами, можно разобрать несколько задачек, для того, что бы видеть как на практике применить материал.
3.1 Закрытый онлайн аукцион
Организатор может создать аукцион, пригласить участников. Участник может принять приглашение, сделать ставку.
Для того, что бы организатор мог создавать аукционы — нужно создать глобальную роль Организатор и при попытке создать аукцион — требовать эту роль. Созданные приглашения уже хранят в себе идентификаторы пользователей, поэтому когда пользователь делает ставку в аукционе, то это будет простейший запрос наличия записи перед вставкой ставки в аукцион.
3.2 Логистика
Огромная логистическая компания требует разграничить доступы для супервизоров и продавцов да еще с учетом региона. Работа такова, что продавец может выставить заявку на получение товара, а супервизор уже решает кому и сколько достанется. Соответственно продавец может видеть свой магазин и все товары в нем, а так же созданные им заявки, статус их обработки. Супервизор может видеть все магазины региона, в котором он работает, их заявки и историю исполнения заявок, так же он может перевести заявку в состояние исполнения для непосредственно доставки в магазин нужного товара.
Для реализации такого функционала нам потребуется реестр регионов и магазинов в качестве отдельного микросервиса, назовем его С1. Заявки и историю будем хранить на С2. Авторизация — А.
Далее при обращении продавца для получения списка его магазинов (а у него может быть их несколько), С1 вернет только те, в которых у него есть меппинг (Пользователь, Магазин), так как ни в какие регионы он не добавлен и для продавца регионы всегда пустое множество. Разумеется при условии, что у пользователя есть разрешение просматривать список магазинов — посредством микросервиса А.
При получении заявок магазина, проверка в А разрешений смотреть заявки, а затем С2 отравляет запрос в С1 и получает разрешение или запрет на доступ к магазину.
Работа супервизора будет выглядеть немного иначе, вместо регистрации супервизора на каждый магазин региона, мы сделаем меппинги (Пользователь, Регион) и (Регион, Магазин) в этом случае для супервизора у нас всегда будет список актуальных магазинов с которыми он работает.
В таком случае, когда супервизор решит перевести заявку на поставку в исполнение, то после проверки, что у него есть разрешение в А, С2 отправит проверку, что у супервизора есть доступ к магазину.
3.3 Секретные части документа
Некое министерство обязано выкладывать документы в общественный доступ, но часть документа является не предназначенной для показа любому желающему (назовем эту часть — номер телефона). Сам документ состоит из блоков, каждый из которых может быть либо текстом, либо номером телефона — скрытой частью, которую видеть могут только особые пользователи, подписавшие соглашение о неразглашении.
Когда пользователь обращается в сервис для получения блоков документа, микросервис в авторизации проверяет роль пользователя на чтение документов, далее в БД каждый блок имеет флаг — секрет. У документа есть меппинг (Пользователь, Документ) — список пользователей, которые подписали соглашение. В этом случае при получении из БД блоков документа можно сразу отфильтровать невидимые для пользователя блоки одним запросом.
3.4 Команда и ее проекты
Если у вас большая команда, и много проектов, и такая команда у вас не одна, то координировать работу их будет той еще задачей. Особенно если таких команд у вас тысячи. Каждому разработчику вы доступы не пропишите, а если у вас человек еще и в нескольких командах работает, то разграничивать доступ станет еще сложнее. Например если 2 команды работают над одним проектом, и разработчик в обоих командах присутствует, из одной его пнули, как теперь определять актуальный состав его проектов?
Такую проблему проще всего решить при помощи групп.
Группа будет объединять все необходимые проекты в одно целое. При добавлении участника в команду, добавляем меппинг (Пользователь, Группа, Роль).
Допустим, что Вася — разработчик и ему нужно вызвать метод develop на микросервисе для выполнения своих обязанностей. Этот метод потребует у Васи роли в проекте — Разработчик.
Как мы уже договаривались — регистрация пользователя в каждый проект для нас недопустима. Поэтому микросервис проектов обратится в микросервис групп, что бы получить список групп, в которых Вася — Разработчик. Получив список этих групп можно легко проверить уже в БД микросервиса проектов — есть ли у проекта какая-нибудь из полученных групп и на основании этого предоставлять или запрещать ему доступ.
4 Проектируем микросервисы для работы чайников
4.1 Словесное описание решаемой задачи
Компания ОАО «ПьемЧай» ежедневно требует работы от миллиона сотрудников и сотни тысяч гостей. Все сотрудники пьют чай и в этом состоит их работа. В компании есть гости, которые пить чай не могут, для них доступны опции, которые позволяют им видеть какой чай они смогут пить на своей будущей работе, а так же лучших сотрудников года, месяца и недели. Некоторые сотрудники в пандемию работают удаленно и доступ к чаю им предоставляет курьерская служба Кракен, прямо к точке доставки. Удаленные сотрудники могут получать чай только из той точки доставки, к которой они привязаны. Находясь в офисе они все равно могут пить чай как обычные сотрудники.
4.2 Архитектура решения
Для решения поставленной задачи нам необходимы следующие микросервисы:
- Ролевая модель для глобальной авторизации запросов
- Чайный сервис для предоставления возможности пить чай и получать статистику по выпитому
- Кракен — гейт с проверкой доступа к точке, все остальные проверки совершит чайный сервис
Графически это будет выглядеть так:
В качестве БД будем использовать PostgreSQL.
Предусмотрим следующие обязательные для решения задачи роли:
- Сотрудник — для возможности пить чай;
- Удаленный сотрудник — для доступа к микросервису кракена (так как сотрудники в офисе не должны иметь возможности пить чай через точки распрастранения чая);
- Кракен — учетная запись микросервиса, что бы была возможность обращаться к API чайного сервиса;
- Авторизационная учетная запись — для предоставления доступа микросервисов к ролевой модели.
5 Реализация микросервисов
Для реализации воспользуемся Spring фреймворком, он довольно медленный, но зато на нем легко и быстро можно реализовывать приложения. Так как за перформансом мы не гонимся, то попробуем на нем достичь скромных 1к рпс авторизованных пустых запросов (хотя люди на спринге умудрялись 100к пустых запросов проворачивать [1]).
Весь проект поделен на несколько репозиториев:
Как работать с проектами
У всех проектов есть общая зависимость — ее нужно скачать и выполнить mvn clean install.
Далее нужно собрать докер образы каждого микросервиса, что выполяется командой sh buildDocker.sh — автоматически выполнит mvn clean install и сборку образа докера.
В каждом проекте есть кофигурация docker-compose с минимальной для каждого сервиса конфигурацией, лучшим вариантом запуска будет sh start.sh. Остановить сервисы можно при помощи docker-compose down, если этого не сделать, то выполнить скрипт из папок других сервисов вы не сможете.
В скрипте инициализации БД ролевой модели выставлено немного пользователей — 10к всего лишь, рекомендую для тестов увеличить до 500к хотя бы. Инициализация займет примерно 100 секунд.
Далее нужно собрать докер образы каждого микросервиса, что выполяется командой sh buildDocker.sh — автоматически выполнит mvn clean install и сборку образа докера.
В каждом проекте есть кофигурация docker-compose с минимальной для каждого сервиса конфигурацией, лучшим вариантом запуска будет sh start.sh. Остановить сервисы можно при помощи docker-compose down, если этого не сделать, то выполнить скрипт из папок других сервисов вы не сможете.
В скрипте инициализации БД ролевой модели выставлено немного пользователей — 10к всего лишь, рекомендую для тестов увеличить до 500к хотя бы. Инициализация займет примерно 100 секунд.
Как устроены test suites
Создаете конфигурацию запуска с мейн классом org.lastrix.perf.tester.PerfTester, в аргумент задаете имя класса test suite, через vm аргументы задаете параметры -Dperf.tester.warmup.round.time=PT1S -Dperf.tester.test.round.time=PT60S -Dperf.tester.test.threads.max=32 -Dperf.tester.test.threads.min=4 -Dperf.tester.test.round.count=1
Для начала разберемся с базой данных ролевой модели:
Пользователи задаются другим сервисом, который в нашем случае даже не реализован, так же как аутентификация. Сделано для упрощения примера.
Обратите внимание на поле is_deleted, оно необходимо, так же как и индекс на (user_id,role_id,is_deleted), иначе работать ничего не будет — удаление записей из больших таблиц приведет к снижению производительности (а у нас расчет на 5 млн строк). Если у вас окажется слишком много записей с флагом is_deleted=true (например 1 млн строк), то гораздо выгоднее будет в техническое окно запустить скрипт на удаление таких записей разом, чем удалять по запросу.
Для работы с таблицами нам потребуется сделать REST API, причем одно для пользователей — людей, второе для пользователей — сервисов.
Само апи довольно легко в понимании, но оно работает медленно (в районе 4к-7к рпс из-за БД), причем как получение ролей пользователя, так и проверка наличия ролей. Для ускорения работы необходимо сделать кеширование, поэтому добавляем в конфигурацию mafp.role.cache.enable. Кеш можно сделать в виде карты, но лучше использовать уже готовое решение com.google.common.cache.Cache и сэкономить себе кучу нервов, потому что через HashMap или WeakHashMap сделать быстро не удастся.
И в данный момент у нас появляется вопрос, а что именно нужно кешировать? В данном случае лучшим вариантом будет — сами роли, вернее их имена на каждого пользователя, так мы сэкономим запросы к БД.
В абстрактном классе заведем кеш под эти данные, но есть одно но. Если хранить Set, то нам придется столкнуться с тем, что поиск в случае большого количества ролей у пользователя будет работать медленно (в JVM строки никогда не работали быстро и не будут). Так же проблемой будет то, что строки, которые мы получим из хибернейта не будут интернированными или каким-то образом преобразованными до синглтонов в рамках нашего кеша, т.е. «a» == «a» всегда для нас будет ложно, и соответственно будет сравнение строк, а нужно — указателей или простых значений, например целых чисел. Это помимо того, что у нас память будет забиваться одними и теми же строками.
Поэтому необходимо добавить карту, в которой будем хранить меппинг (Строка, Целое). И в кеше хранить уже не набор имен ролей пользователя, а набор идентификаторов ролей пользователя, причем эти числа могут не совпадать с идентификаторами в вашей БД. Поиск Integer в HashSet выполняется намного быстрее, чем строки, при этом у вас де факто все строки будут интернированными, что в нашем случае является обязательным шагом — иначе потребление памяти будет расти неконтролируемым образом.
Получив абстрактный класс, можно реализовать его для самого ролевого сервиса, что бы авторизовать доступы к нему, а так же для клиента, что бы проще было пользоваться в других сервисах. Обратите внимание, что на клиенте мы кешируем не все роли, а только те, что зарегистрированы в белом списке, это позволит нам на каждом сервисе при желании хранить хоть 100к строк кеша, потратив чуть больше 10 мб хипа.
Если инициализировать БД 500к пользователями, 10к ролей и каждому пользователю выдать до 10 ролей, то можно провести нагрузочное тестирование. Результат на выданных 4 ядрах от моего i7-9700k получится скоромный — среднее 12992, минимум 12832, максимум 13088 rps. Результат получен на 16 потоках клиента.
Но основная проблема при тестировании вашей авторизации — это тот факт, что авторизовать надо работу чужого сервиса, вы можете рисовать любые цифры, но другие сервисы не будут работать с приемлемой производительностью.
Идеальным тестом для авторизации — является отношение количества пустых запросов за единицу времени к количеству авторизованных пустых запросов за единицу времени для N (желаемое число под в вашей системе, требующих авторизацию, хотя вы можете вычислять это значение от 1 до N и показывать в виде графика). При этом записывать будем в виде Ка1 коэффициент авторизации 1, если количество под равно 1. Чем ближе к 1 это значение, тем лучше работает ваша авторизация как слой. Именно поэтому полученные выше 13к рпс не имеют никакого значения, даже если вы сделаете авторизацию, которая выдает 10e100 rps, она будет бесполезна, если коэффициент авторизации окажется скажем 1000, потому что плохим результатом является уже 100 — т.е. ваша авторизация в 100 раз замедляет ничего не делающее приложение.
В данной статье будет измеряться только Ка1, потому что железа нет.
Приступим к чайному сервису. Для тестирования авторизации у нас создан в нем ендпоинт POST /api/v1/tea/dummy.
Если отключить авторизацию (/noauth в конец добавить), то тестирование покажет нам на выданные 2 ядра чайному сервису и 2 ролевому — среднее 18208, минимум 18048, максимум 18560 на 32 потоках клиента — это количество запросов, которое может обработать наша система с заданными настройками, исключая какую либо бизнес логику, быстрее работать у нас уже ничего не будет. Включив же авторизацию, которая заключается в проверке у пользователя роли User, получим следующие показания на 6 потоках клиента — среднее 1062, минимальное 1062, максимальное 1068.
При этом тестировалось на 100к случайно выбираемых пользователях! Ка1 = 17.1.
И напоследок попьем чай (делаем инсерты в БД) в 6 потоков клиента на POST /api/v1/tea получим среднее 1086, минимум 1086, максимум 1086 (а должно быть ~4к). О чем это говорит нам? О том что авторизация является для нас боттлнеком, который замедляет работу системы (из-за сильной нагрузки на ЦПУ, что говорит о том, что алгоритм кеширования у нас не очень). Еще о том, что погрешности измерений огромные.
Коэффициент авторизации позволит вам не только оценить работу алгоритмов авторизации, но и очертить границы в которых может работать весь ваш комплекс микросервисов, а так же сообщить вам — имеет ли смысл оптимизировать код конкретного микросервиса или нет, потому что может так оказаться, что выигрыш будет 0.
Если же всего лишь включить роль в JWT токен, то с 12 потоками клиента можно получить от dummy среднее 6396, минимум 6372, максимум 6444. Т.е. Ка1 оказался равен 2.8!
А что будет, если отключить кеширование на клиенте, не использовать роли JWT и оставить его только на ролевой модели? Производительность вырастет, потому что сетевые задержки около нулевые и нагрузка на ЦПУ для dummy станет минимальной — среднее 3817, минимум 3806, максимум 3828, что говорит нам о Ка1 = 4.7. Однако следует учитывать, что такое решение не будет масштабируемым, потому что каждый клиент будет обращаться постоянно к сервису ролевой модели и увеличивать на него нагрузку, уже при сотне под начнутся серьезные проблемы, делающие невозможной работу авторизации, разве что у вас на каждый сервис, которому нужна авторизация будет пода авторизации, которая эту функцию будет выполнять, есть в интернете такие сетевые инженеры, которые любую проблему готовы
А выпустить кракена так и не удалось, потому что железо не выдержит испытаний. Может быть в другой раз, когда будет бюджет недельку-другую погонять кластер на сотню машинок по 2-4 ядра с парой гиг памяти.
Заключение
В статье предложена универсальная модель для авторизации доступа множеству пользователей к множеству ресурсов с минимальными потерями по производительности, позволяющая делать эффективное кеширование и хранение промежуточных данных на микросервисах, для сборки результата авторизации just-in-time. Предложена метрика (в виде коэффициента), для оценки работы авторизации микросервисов с учетом требований работы всего комплекса и показано, как он может меняться в зависимости от подхода, а именно наличия/отсутствия кеша, хранения ролей в JWT токене и т.д. Не показано, что этот коэффициент всегда растет с увеличением количества под в системе.
Предложенная модель данных позволяет разделить данные между частями микросервисной архитектуры, тем самым снизив требования к железу, дает возможность работать только с теми данными, которые нужны в конкретный момент времени конкретному сервису, не пытаться искать в огромном массиве все подряд или пытаться искать данные в полностью обобщенном хранилище.
Показано, что при малом количестве микросервисов нет смысла проводить кеширование на клиенте авторизации, так как это приведет к большей нагрузке на ЦПУ. Предоставлены данные, которые позволяют сделать вывод, что необходимо балансировать ресурсы в зависимости от размеров системы, если она слишком мала, то есть смысл нагружать больше сеть, но при увеличении и разрастании выгоднее добавить пару ядер в микросервисы, для обеспечения работы кешей и разгрузки сети, микросервисов авторизационных данных. Вопрос больше в том, что для вас дешевле, найти дополнительные ядра или сеть улучшать с гигабитной до десятигигабитной, особенно если можно сделать авторизацию, когда достаточно для ее работы 100 мбит сети.
