
Patroni и Stolon — два наиболее известных и продвинутых решения для оркестрации PostgreSQL и обеспечения высокой доступности (автофейловера) кластеров Leader-Followers конфигурации. Однако инженеры, переходящие со старых проверенных решений (Corosync&Pacemaker) и встроенных из других СУБД, сталкиваются со сложностями в инсталляции этих инструментов и непониманием ролей каждого из компонентов. В данном мастер-классе будет рассмотрен типичный процесс инсталляции кластеров Patroni и Stolon на виртуальных машинах (не в контейнерах), а также разобрано поведение этих кластеров при различных фейлах в инфраструктуре. Весь процесс будет демонстрироваться на трёх виртуальных машинах под управлением vagrant с использованием предварительно подготовленных образов. При желании слушатель может следовать за процессом, предварительно подготовив своё окружение.
Видео доступно на сайте PGConf.Russia
Всем привет! Меня зовут Максим Милютин. На данный момент я работаю в компании Ozon Технологии. Занимаюсь преимущественно разработкой. И занимался в техподдержке Postgres Pro кластерными решениями Patroni и Stolon. И сегодня я бы хотел поделиться опытом.

Немножко про план текущего мастер-класса. Я попытаюсь с нуля настроить компоненты, которые составляют кластера Stolon, Patroni поэтапно. И разобрать основные случаи падения.
Тут стоит отметить, что инсталляция сделана по экспериментальным Ansible плейбукам и ролям, которые в свое время мы разрабатывали в Postgres Pro для того, чтобы экспериментировать с кластерами и предлагать их заказчику.
Но если вы хотите поставить в Patroni кластер полностью готовый под ключ, то я могу рекомендовать вам плейбуки, который разработал Виталик Кухарик — https://github.com/vitabaks/postgresql_cluster. Они до недавнего времени были достаточно популярны в русскоязычном сообществе.

Начнем немного с матчасти, с введения.
- Все высокодоступные кластера на базе PostgreSQL – это все про архитектуру shared-nothing, то бишь без разделения данных.
- И все они построены на физической репликации. На той репликации, где у нас мигрируют физические изменения страниц с мастера на реплики.
- Также поддерживается режим hot standby, т. е. чтение из реплик.
- И имеются зарекомендовавшие себя готовые инструменты управления узлами:
- Это pg_basebackup для того, чтобы сделать бэкап с мастера на реплику, не прерывая нагрузку на мастер.
- Можно запромоутить узел. Перевести из standby режима в мастер.
- Также есть полезная утилита pg_rewind, которая позволяет перевести из мастера обратно в режим standby.
- И для мониторинга две вьюхи, которые показывают текущие остановленные слоты репликации и статусы всех реплик.

https://eng.uber.com/mysql-migration/
https://github.com/sorintlab/stolon/issues/519
https://github.com/zalando/patroni/issues/538
С 10-ой в PostgreSQL добавилась встроенная логическая репликация. И в целом хорошо бы иметь кластерное решение на ее базе, как минимум, для того, чтобы снизить трафик репликации. Потому что, как известно, логические изменения в разы меньше, чем изменения на уровне страниц. Это связано не только с Write amplification, что изменения распространяются помимо дата-файлов на все индексы, но и с тем, что в WAL попадает и full page images, полный образ страниц после checkpoint. Туда попадают изменения по hit beat и т. д. Все это многократно увеличивает размер WAL. И в частности Убер в своей знаменитой статье «Мигрируя с PostgreSQL на MySQL» апеллировал именно к такому качеству физической репликации.
Однако при построении кластеров на логической репликации есть некоторые ограничения.
И дело тут не только в том, что логическая репликация ограничена, не реплицируется DDL, позиции по sequence, но и в то, что если у нас происходит перепозиционирование реплик на новый мастер, то эту реплику надо заново перезаливать. Позиция репликации привязана к указателю в физическом WAL. А в каждом узле WAL развивается по-своему. Нет аналога GTID как в MySQL, CSN как в MS SQL Server.
И также нет аналога pg_rewind.
Однако в кластерные решения Stolon и Patroni хотят добавить поддержку логической репликации, как минимум, для того, чтобы rolling upgrade Postgres узлов без простоя.

Как бы выглядел примитивный автофейловер, когда у нас имеется простой мастер и реплика? Мы сверху можем поставить Арбитр, т. е. третий какой-то сервис, который просто бы выполнял health checks узлов и еще передавал какие-то управляющие сигналы.
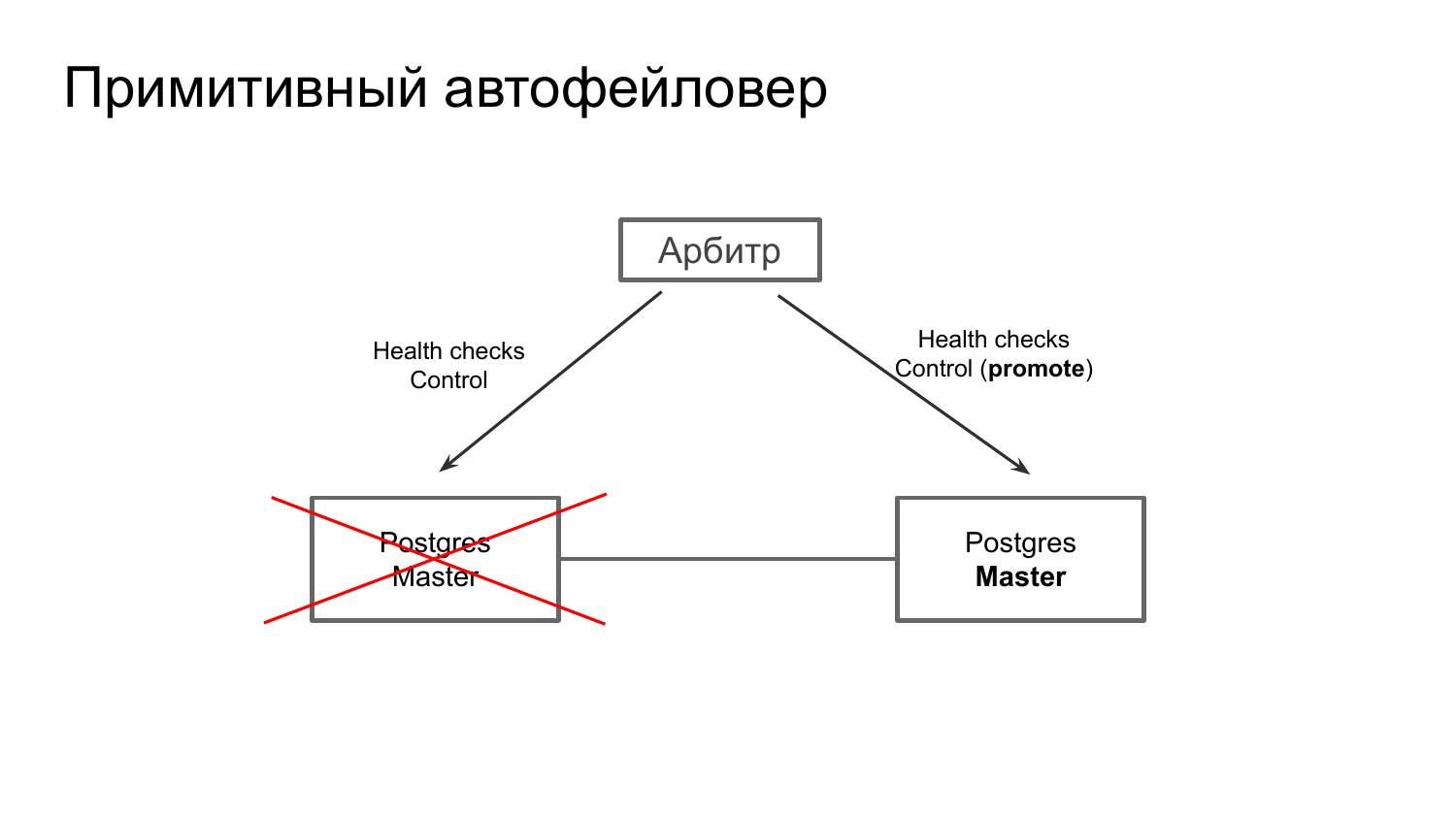
И в случае, если у нас мастер упал, то арбитр сделал бы простую вещь – подал бы promote сигнал реплике. И она перешла в мастер.
Но, к сожалению, такая архитектура, не стабильная.

Что будет, если мастер изолируется? Произойдет то, что сигнал promote дойдет до реплики. Реплика станет мастером и у нас будет два мастера.

И в целом как бы ничего, но можно здесь добиться split brain при двух условиях. Если у нас на старом мастере также существуют какие-то клиенты и, если у нас настроена асинхронная репликация.
В случае синхронной репликации все коммиты, которые приходят на бывший мастер, зависнут, ожидая подтверждения с реплики.
Чуть позже я объясню, как это можно сломать. Но это будет чуть позже.

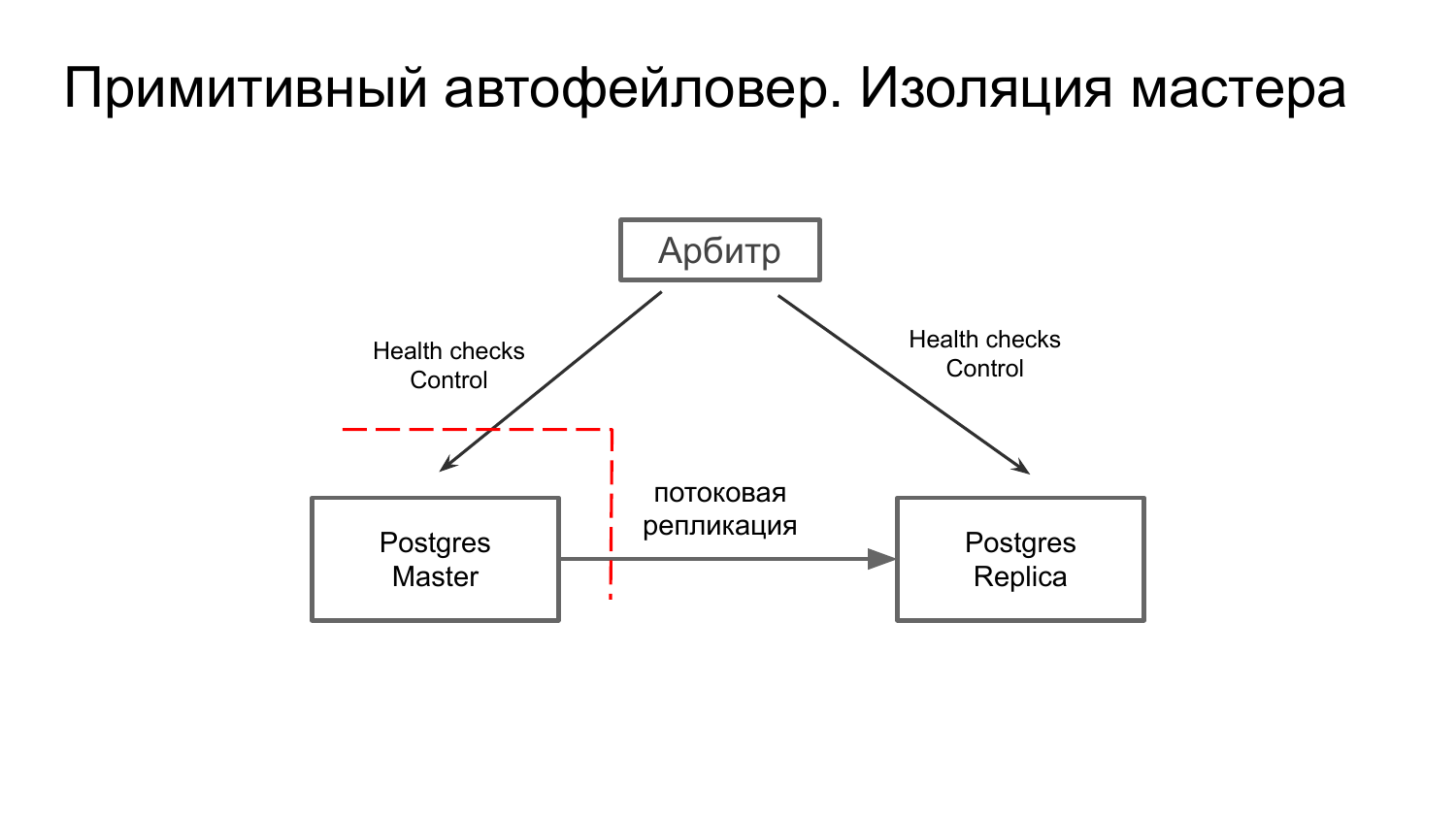
Как этот случай побороть? Можно поверх Postgres внедрить специальные агенты, которые бы управляли нашими узлами. И помимо того, чтобы просто общались с арбитром, посылали свой статус и реагировали на управляющие сигналы, они бы еще фенсили мастер, если он окажется в изоляции.

Что такое фенсинг? Это, по сути, ограждение изолированного мастера от того, чтобы к нему не приходили какие-то изменения и не разводили его с основным узлом.
В классической интерпретации – это выключение всего узла. Также можно разорвать соединение к изолированному мастеру, либо перевести его в read only. Это самый лайтовый режим.

И здесь напрашивается второй fail. Это то, что у арбитра единая точка отказа. Если он упадет, то кластером никто не управляет.

https://github.com/citusdata/pg_auto_failover
https://github.com/citusdata/pg_auto_failover/issues/12#issuecomment-490551255
Однако такие архитектуру существуют. И они вполне себе работоспособны. Как пример можно привести решение pg_auto_failover от Citus Data.
И тут действует специальная политика на фенсинг изолированного мастера. Он фенсится в случае, если у нас от него недоступен арбитр и недоступна остальная реплика. Статус реплики можно проверить pg_stat_replication.
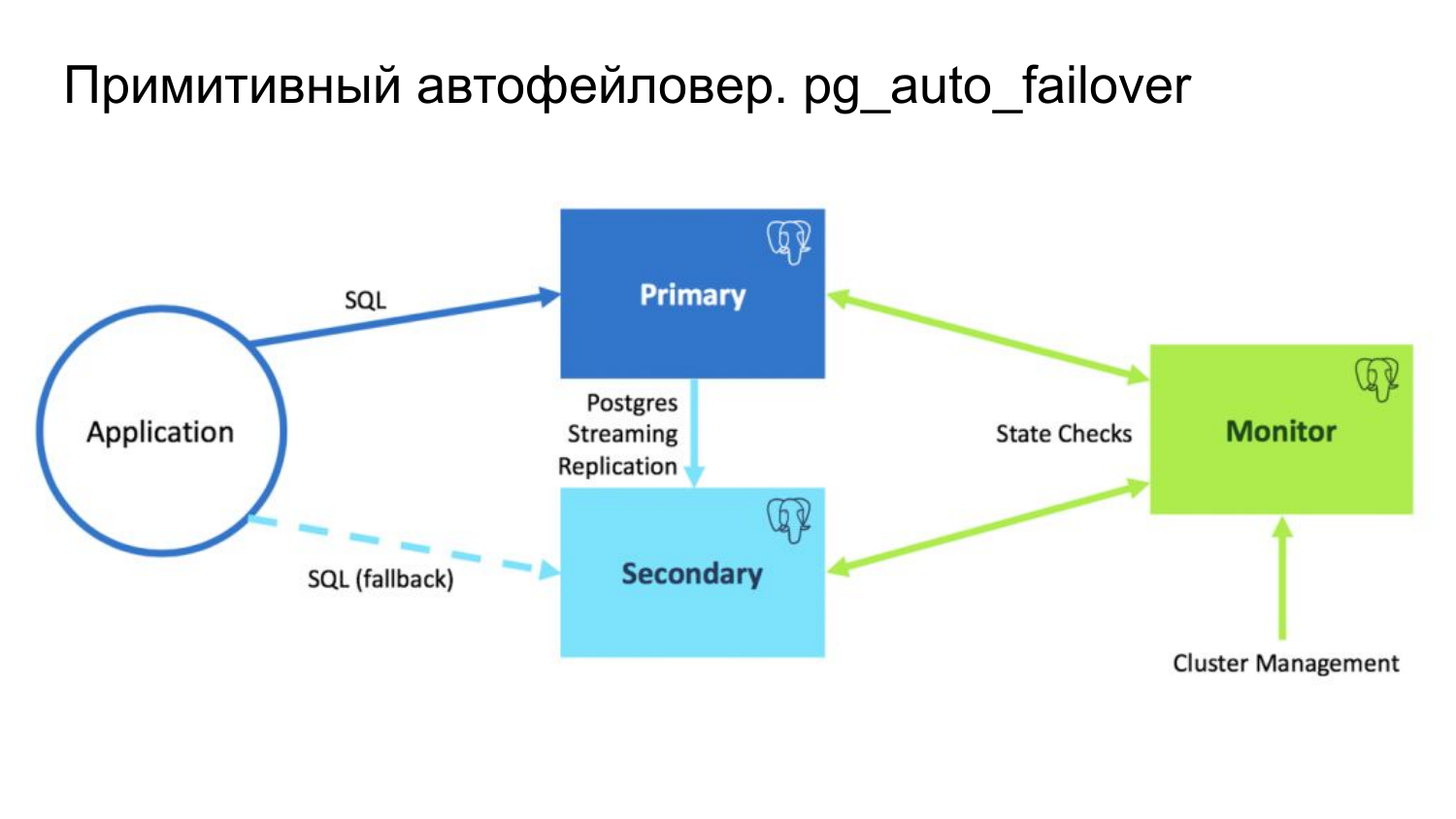
Я покажу картинку, как построен этот мастер. У нас есть два узла. Есть мастер, реплика, есть третий монитор. И primary (ведущий узел) зафенсится в случае, если от него недоступен монитор и недоступен второй узел.
В случае, если у нас монитор падает, то вся конфигурация замораживается. И те агенты, которые управляют мастером и репликой, ничего не делают.
И в таком кластере допускается всего лишь один fail. Если больше одного, то это считается фатальным.
И тут я привел ссылки, где можно почитать про автофейловер и о том, как работает фенсинг.

Но мы хотим иметь более универсальный кластер, который бы выдерживал больше одного падения. И для этого мы должны построить кластер из арбитров.
Но мало сделать этот кластер высокодоступным, нужно арбитры соединить в протокол консенсуса. Поскольку они принимают достаточно важно решение, нужно, чтобы решения были согласованы между всеми узлами.
И в данной схеме имеются прокси чисто для балансировки.

И есть готовые решения, которые реализует протокол консенсуса. Они называются DCS (Distributed Configuration System – распределенная система конфигурации). Они предоставляют универсальный IP сторонним компонентам, которые строят решения вокруг него.
И эти DCS – это Consul, Etcd, которые реализуют протокол Raft и Zookeeper, который реализует протокол Zab. Протокол Zab – это адаптация Paxos.
Все управление кластера осуществляется сторонним инструментом, который может непосредственно менять конфигурацию хранимых DCS.
И эта схема является основополагающей для кластеров классов Patroni/ Stolon.
Агенты на Postgres подключаются к этой конфигурации и настраивают Postgres в соответствии с ней.

Давайте подытожим, что же представляет собой кластера Patroni/ Stolon.
- Во-первых, это autofailover. У нас в кластере всегда должен присутствовать какой-то один активный узел.
- И также это оркестратор БД. И они еще представляют некую автоматику вокруг PostgreQSL.
- Они также интегрируются с облачными решениями, в частности Kubernetes.
- И представляют DBaaS (database as a service).
- И мотивация использования таких решений – это если у вас слишком много баз данных и кластеров в корпорации. И хотелось бы, чтобы внутри этих кластеров была какая-то автоматика. И также, если есть какие-то требования на простой кластера и хочется спать по ночам.
Распределенная система конфигурации (DCS) на примере Etcd

Давайте перейдем к настройке и установке всех компонентов. Постепенно начнем с DCS. Этот компонент является основополагающим. И важно отметить, что это «единая» распределенная точка отказа кластеров вокруг него. Если у нас вдруг выходит из строя этот DCS, то в итоге все узлы должны прекратить принимать транзакции, должны зафенсится.
Почему так? Это очень интересный вопрос. Потому что с точки зрения узлов, которые управляют Postgres, совершенно неразличима ситуация, когда у нас DCS полностью упал и недоступен, либо, когда случился split и они оказались в минорной части кластера и должно зафенсится, чтобы предотвратить split brain. Такая ситуация неразличима с точки зрения узлов, поэтому любой fail DCS чреват.
Важно отметить, что сам DCS должен устанавливаться на 3-5-7 узлах, как минимум, в 3-х зонах доступности. Почему так? Потому что его устойчивость гарантируется способностью большом узлов кластера. Если у нас произойдет net split, то активна будет именно та часть, где большинство узлов DCS.
Etcd реализует классический протокол RAFT между узлами. Давайте на него посмотрим.

Все узлы DCS в стабильном режиме становятся либо лидером, либо follower как в обычном кластере PostgreSQL. Однако сам механизм перевыборов лидера интегрирован внутрь протокола RAFT.
И выделяется еще третье состояние. Это состояние кандидат. В состояние кандидата узлы выбирают нового лидера.
И важно отметить, что любая запись проходит через кворум узлов. Если она поступает на follower, то она перенаправляется на лидер. И лидер дальше ее распространяет на все остальные реплики и собирает кворум ответов с этих реплик. Поэтому к обычному коммиту записи добавляется еще задержка в виде одного-двух RTT и одного fsync.
Чтение может быть как устаревшим, как чтение непосредственно с follower, либо с лидера. Но еще лучше, если оно также проходит через кворум, т. е. точно проходит через актуального лидера.
И внизу я еще отметил пару временных характеристик, но о них чуть-чуть позже.
С 14 минуты 42 секунды начинается демо.
vagrant status
Current machine states:
node1 running (virtualbox)
node2 running (virtualbox)
node3 running (virtualbox)
This environment represents multiple VMs. The VMs are all listed
above with their current state. For more information about a specific
VM, run `vagrant status NAME`.Давайте перейдем к практической части. Тут я для вас подготовил три виртуальные машины под управлением vagrant.
И выделил два сетевых интерфейса: один рабочий, а второй чисто для подключения. Рабочий интерфейс я буду включать, всячески с ним экспериментировать, а через второй смотреть на результат. У меня уже на виртуальных машинах установлены все компоненты. И я бы хотел пробежаться по инсталляции.

Тут все стандартно. Мы сделали инсталляцию по минимуму. Просто ставим бинарники, прокладываем конфиги.
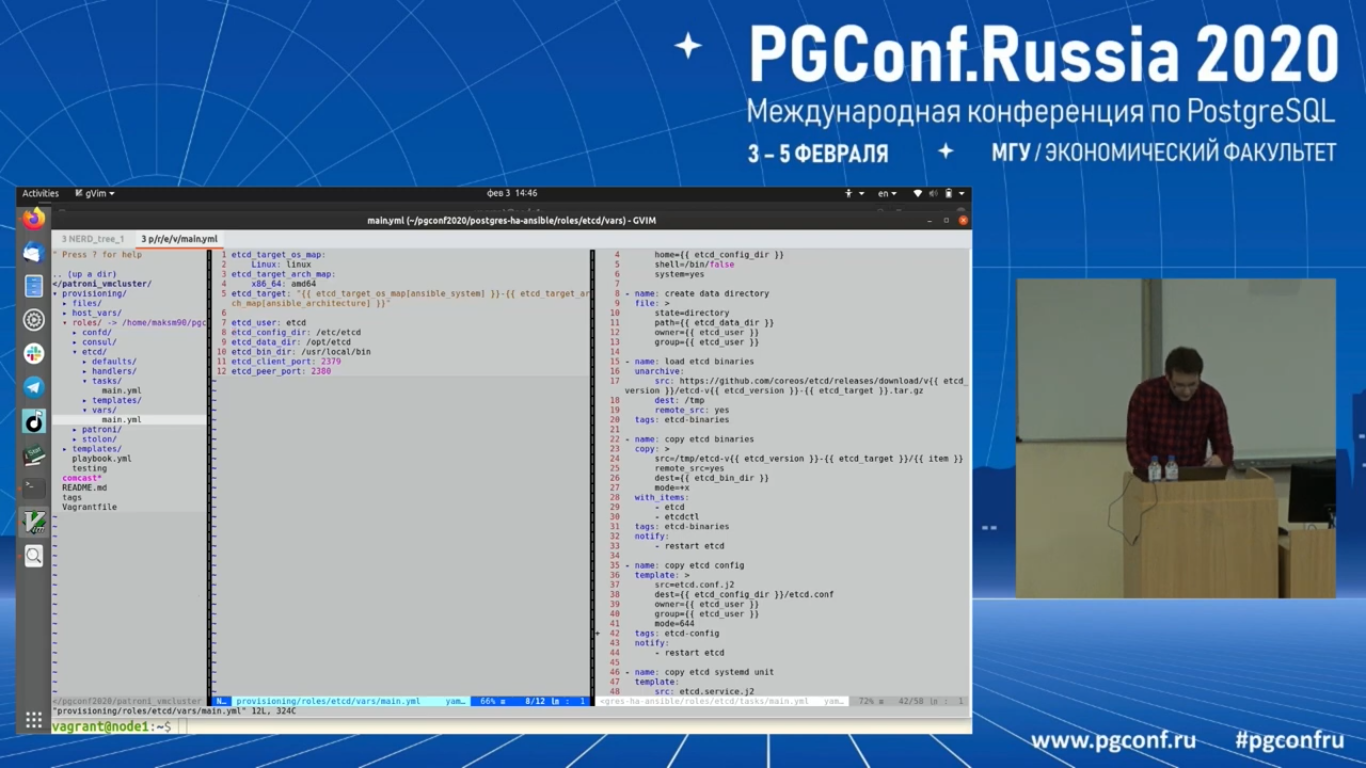
Они у нас расположены в соответствующих путях в Etcd каталоге. И дальше Etcd сервисы, которые запускают агента Etcd.
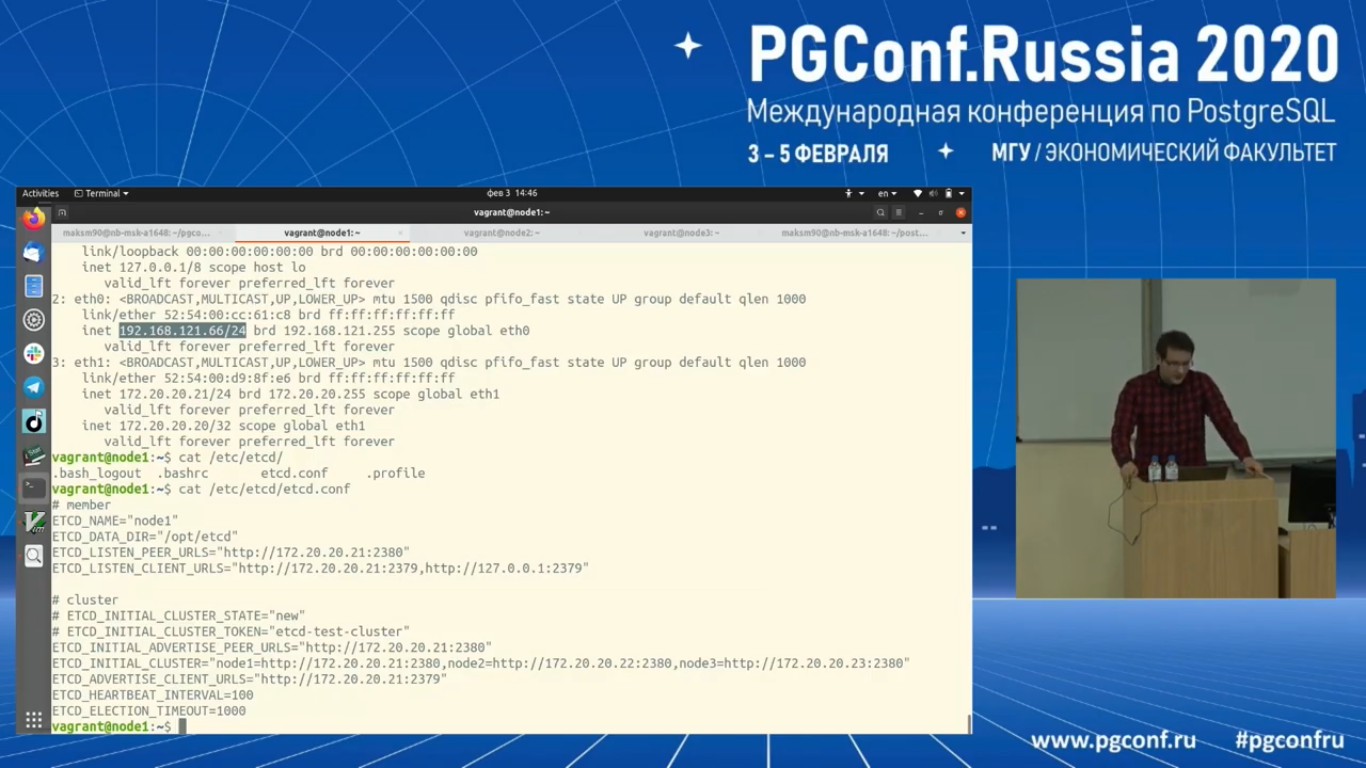
Давайте посмотрим на config Etcd. Я все параметры, с которыми запускается Etcd, объявляю через переменное окружение, где объявляю те IP адреса, к которым мы подключаемся на прослушивание. Они представлены в двух экземплярах. Первый ETCD_LISTEN_CLIENT_URLS для клиентских подключений. Второй ETCD_LISTEN_PEER_URLS для подключения сторонних узлов.
Дальше выделяются еще два адреса ETCD_ADVERTISE_CLIENT_URLS и ETCD_INITIAL_ADVERTISE_PEER_URLS. Эти адреса тоже надо указывать. Они заносятся в конфигурацию кластера и через них происходит discovery, как к текущему узлу нам подступиться от других узлов.
И также есть два параметра: ETCD_HEARTBEAT_INTERVAL и ETCD_ELECTION_TIMEOUT.
Давайте запустим эти сервисы на всех трех узлах. Они у меня не запущены. И активизируем их. Я это делаю через Ansible. У меня есть специально заготовленная команда. Все, активизировал я сервисы.

Давайте посмотрим на логи. Вот Etcd у нас стартовал.
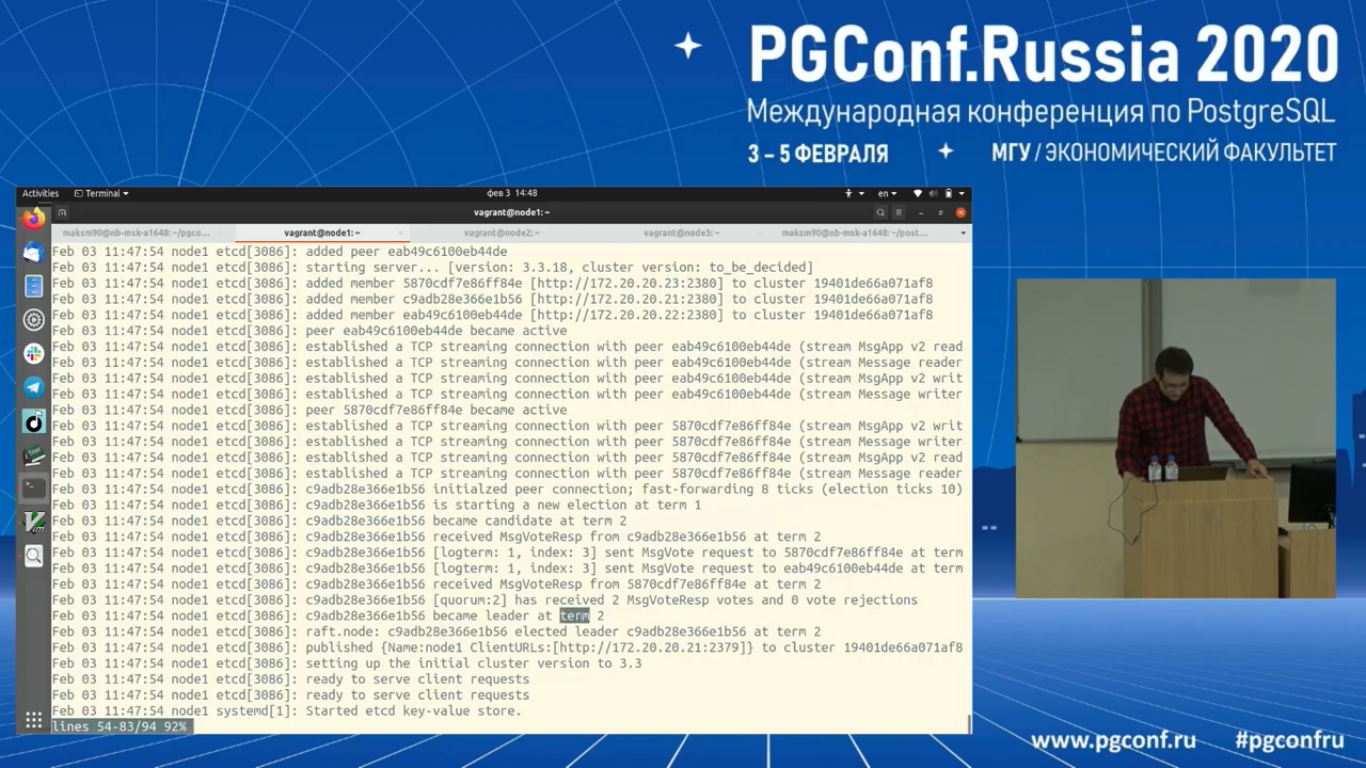
И видно, что он у нас стал лидером на term 2. Term – это в некотором роде аналог timeline в PostgreSQL. При каждом выборе нового лидера номер term увеличивается.
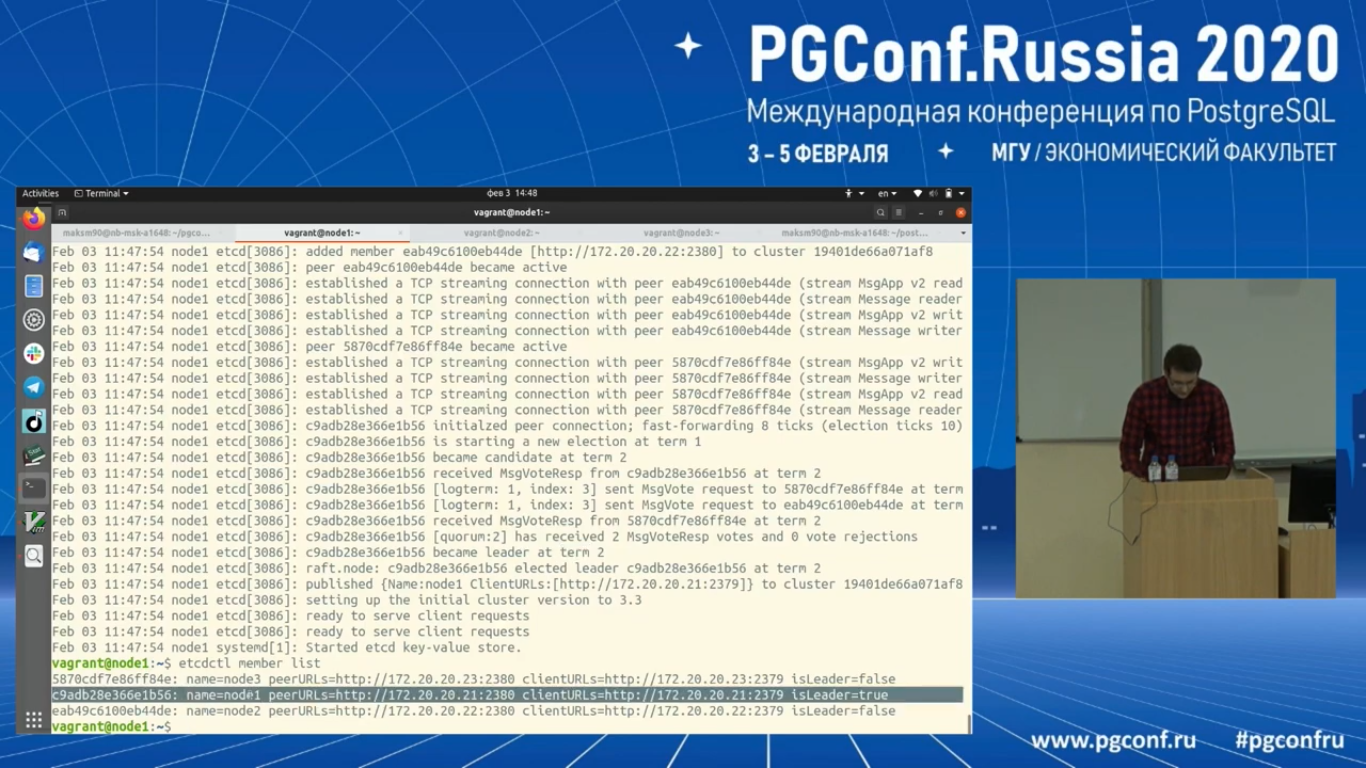
Также состояние кластера можно посмотреть через утилиту etcdctl member list. И тут видно, что первый (второй) узел у нас стал лидером, остальные followers.
sudo pkill -STOP etcdДавайте немножко поиграемся с этим кластером. В частности, давайте сымитируем fail лидера и посмотрим, что будет с остальными узлами. Для этого я не буду Etcd выключать, а просто его остановлю. Стоп. Ок.
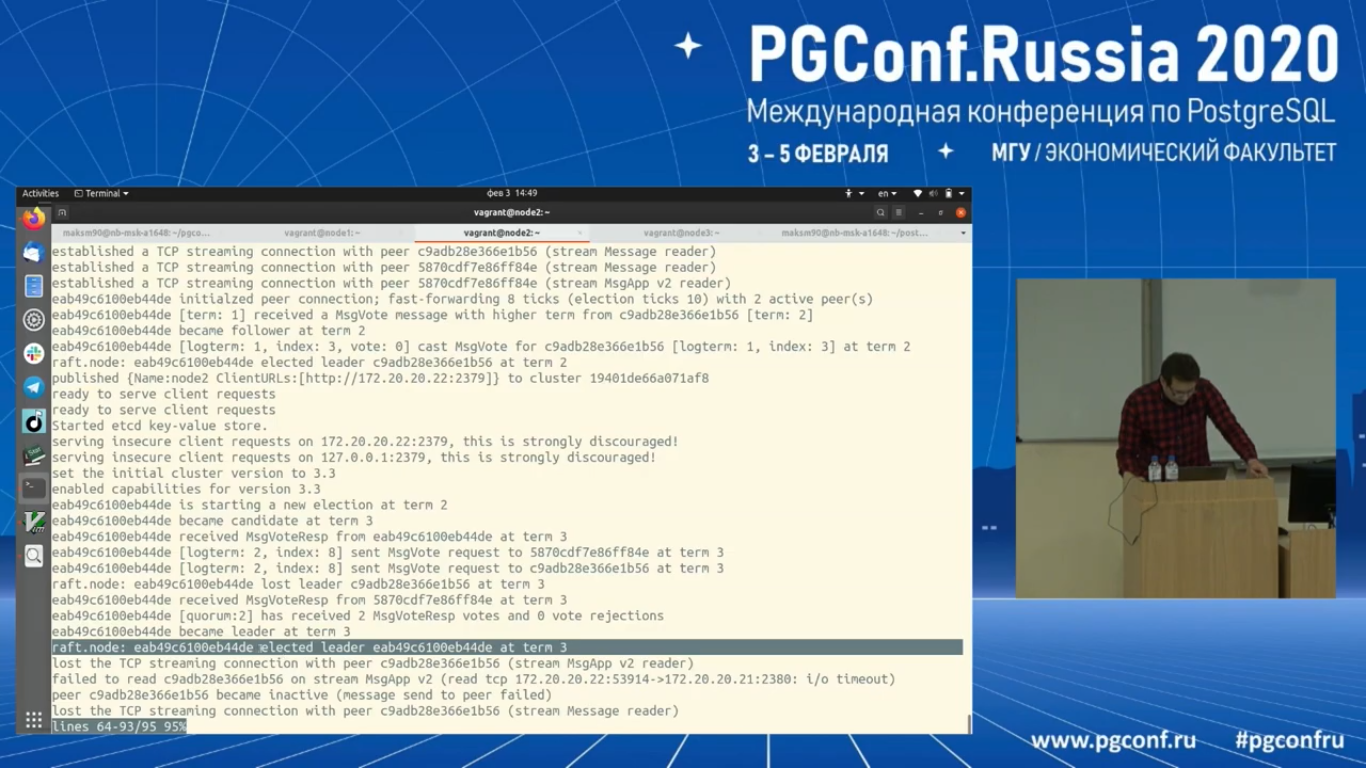
Давайте посмотрим логи. Посмотрим его реакцию. Видно, что второй узел стал лидером уже на следующем term.

Если мы посмотрим состояние кластера, то видно, что второй узел перехватил лидерство.
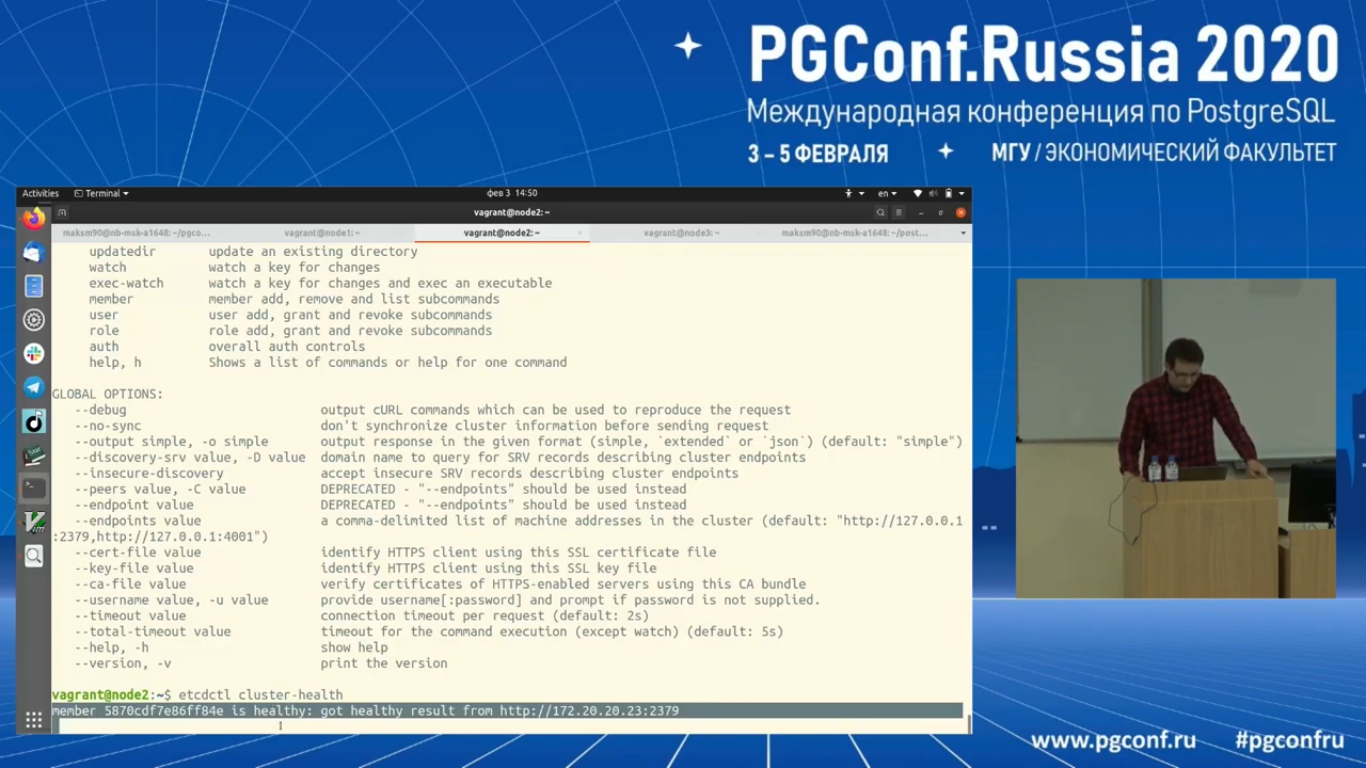
И также можно статусы узлов посмотреть командой «etcdctl cluster-health». И видно, что третий узел вполне себе работоспособный. Но второй у нас завис.
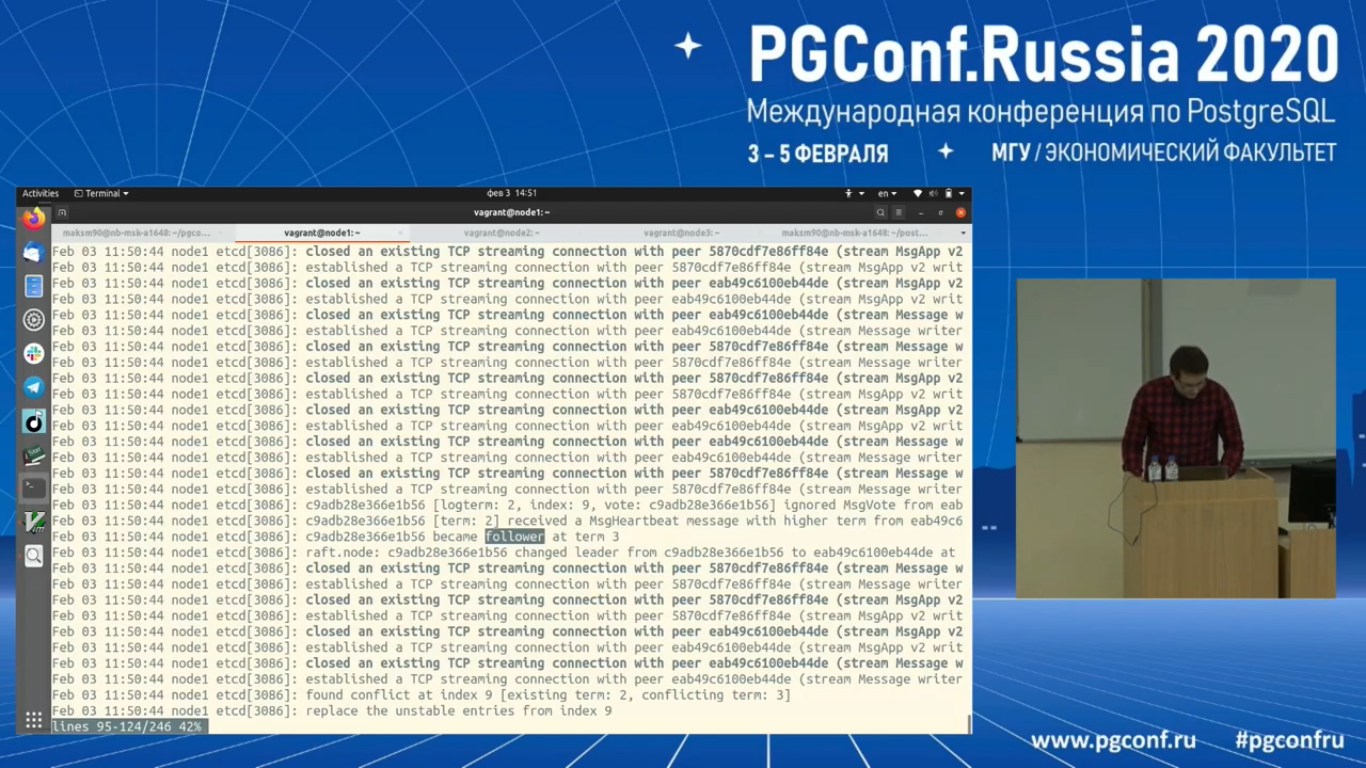
Давайте активизируем и посмотрим логи Etcd. Видно, что он пытается соединиться с другими коллегами. И на третьем term он стал follower’ом.
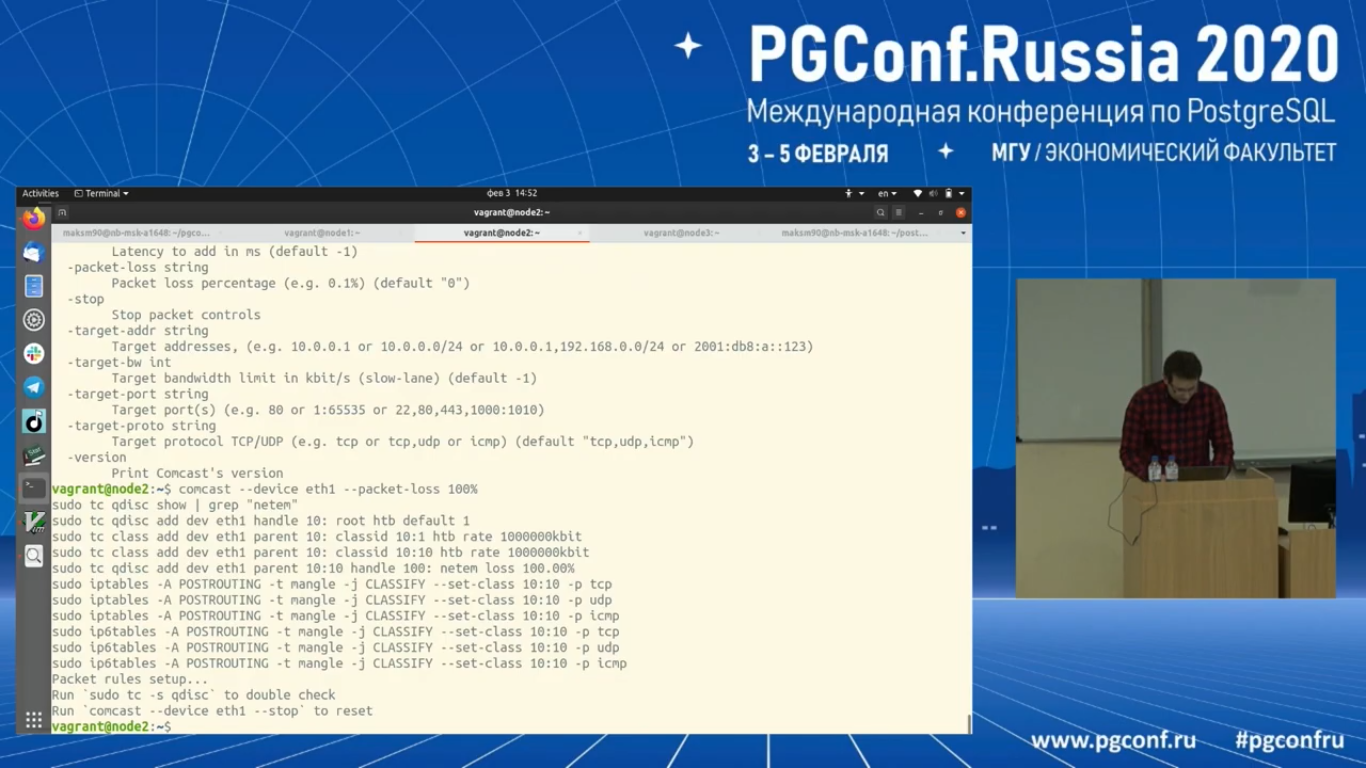
Давайте посмотрим что-нибудь поинтереснее. Попробуем изолировать лидера от остальных узлов. Что с ним будет? В данном случае лидер – это второй узел. И для изоляции Etcd я использую специальную утилиту. Она называется «comcast». Это обертка поверх API tables Etcd. Она позволяет всячески экспериментировать с трафиком, который уходит и приходит к узлу.
Что я сделаю? Я просто закрою интерфейс на рассылку и прием пакетов специальной командой «Comcast — - device eth1 – packet – loss 100 %».

Давайте посмотрим на логи второго узла. Нам показывает, что он не может подключиться ко второму узлу. И дальше должны быть перевыборы нового лидера на новом time line. Выборы, по-моему, уже даже произошли. Да, вот он стал лидером на новом term 4.
Давайте вернемся к нашим временным характеристикам. Я говорил, что есть heartbeat_interval и election_timeout. Дело в том, что от лидера постоянно к followers проходят пустые пакеты, пустые записи heartbeat так, чтобы followers знали о том, что лидер еще жив. И в случае если у нас follower не получит этот heartbeat или какую-то другую запись с лидера за какой-то тайм-аут, то он переходит в состояние кандидата. И начинаются выборы нового лидера.
В частности, эти параметры важны, если вы собираетесь ставить кластер в гео-распределенную конфигурацию. На слайде я упомянул, чему должны быть равны эти параметры. По умолчанию heartbeat_interval – это 100 миллисекунд. И в целом, если кластер у вас расположен в локальном дата-центра, то этого достаточно. А election_timeout – это обычно десятикратное увеличение первого параметра.
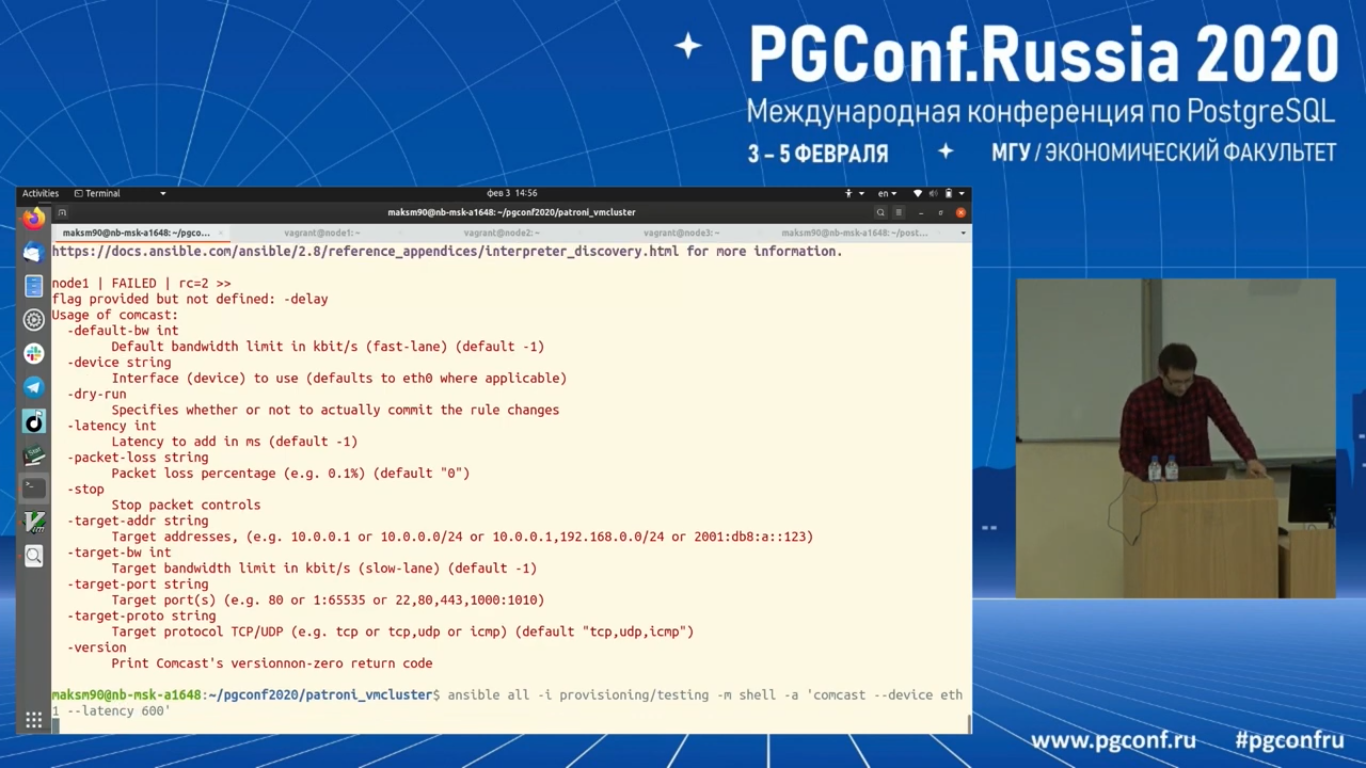
Давайте проведем тест. Я попытаюсь сымитировать задержки в сети. В частности, сделаю так, чтобы у нас RTT был больше, чем election_timeout. Election_timeout равен одной секунде. Для этого я воспользуюсь Ansible. Это нужно сделать для всех узлов.
Давайте для всех узлов отключу и заново включу `comcast --device eth1 --stop
И в частности давайте сделаем вот так: comcast --device eth1 --latency 600. Работаем с первым интерфейсом.
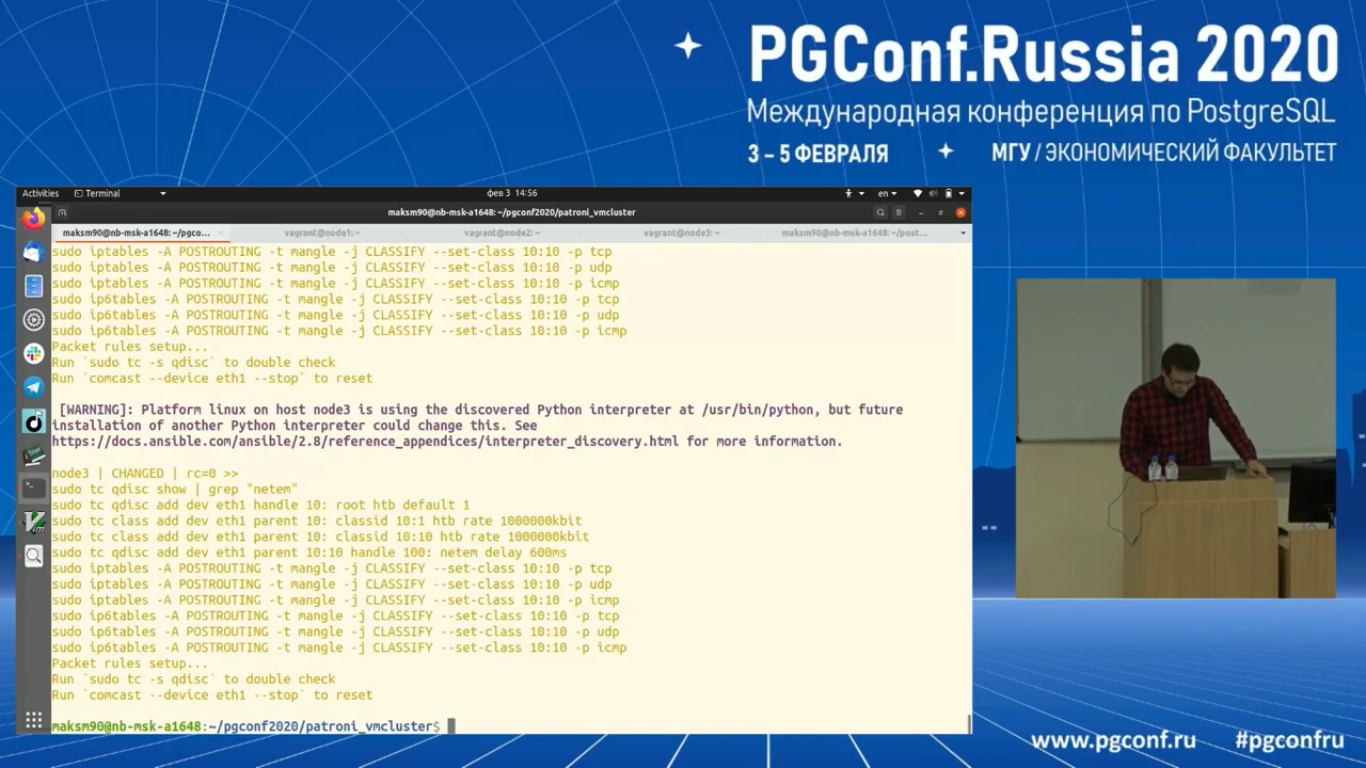
И задаем параметр latency на 600 миллисекунд. 600 миллисекунд – это задержка исходящего трафика. И при этом RTT будет равен секунде и 200 миллисекундам.

Попробуем ping ко второму узлу. Вот у нас RTT между узлами больше 1 секунды.

Давайте посмотрим на логи по второму узлу. Видно, что term все время превращается. Ничего не меняется. Тут должно быть, что тайм-аут в одну секунду должен протекать и каждый узел должен переводиться в состояние кандидата, каждый раз увеличивая номер term. И в итоге кластер должен деградировать полностью.
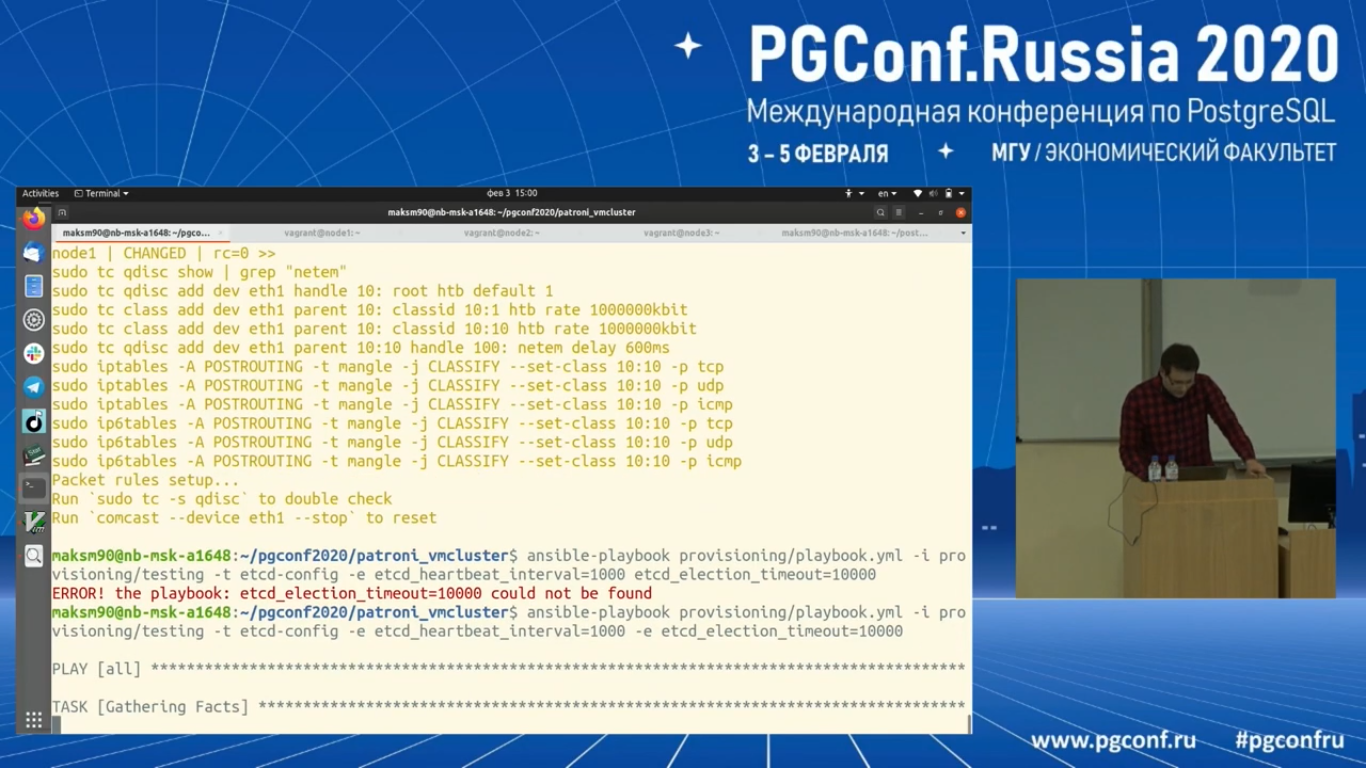
Чтобы поправить эту ситуацию, давайте поменяем параметры heartbeat_interval и election_timeout. В частности, heartbeat сделаем в одну секунду, а election_timeout в 10 секунд. Я это сделаю через Ansible. Я использую свои плейбуки. Etcd-config. И в частности, задам отдельные параметры для всех узлов. Важно, чтобы на всех узлах были одинаковы эти параметры. Я экспортирую эти параметры. Все, по-моему. Здесь у нас Etcd рестартуется.

Давайте посмотрим на логи. Все. Первый узел у нас стал follower’ом.

И если посмотрим кластер member list, то видно, что лидером у нас стал третий узел, а fallowers остальные.
Тут надо заметить, что в случае падения лидера, у нас длительность автофейловера увеличится, потому что прежде чем начнется этап выбора нового лидера, должен пройти тайм-аут в 10 секунд.
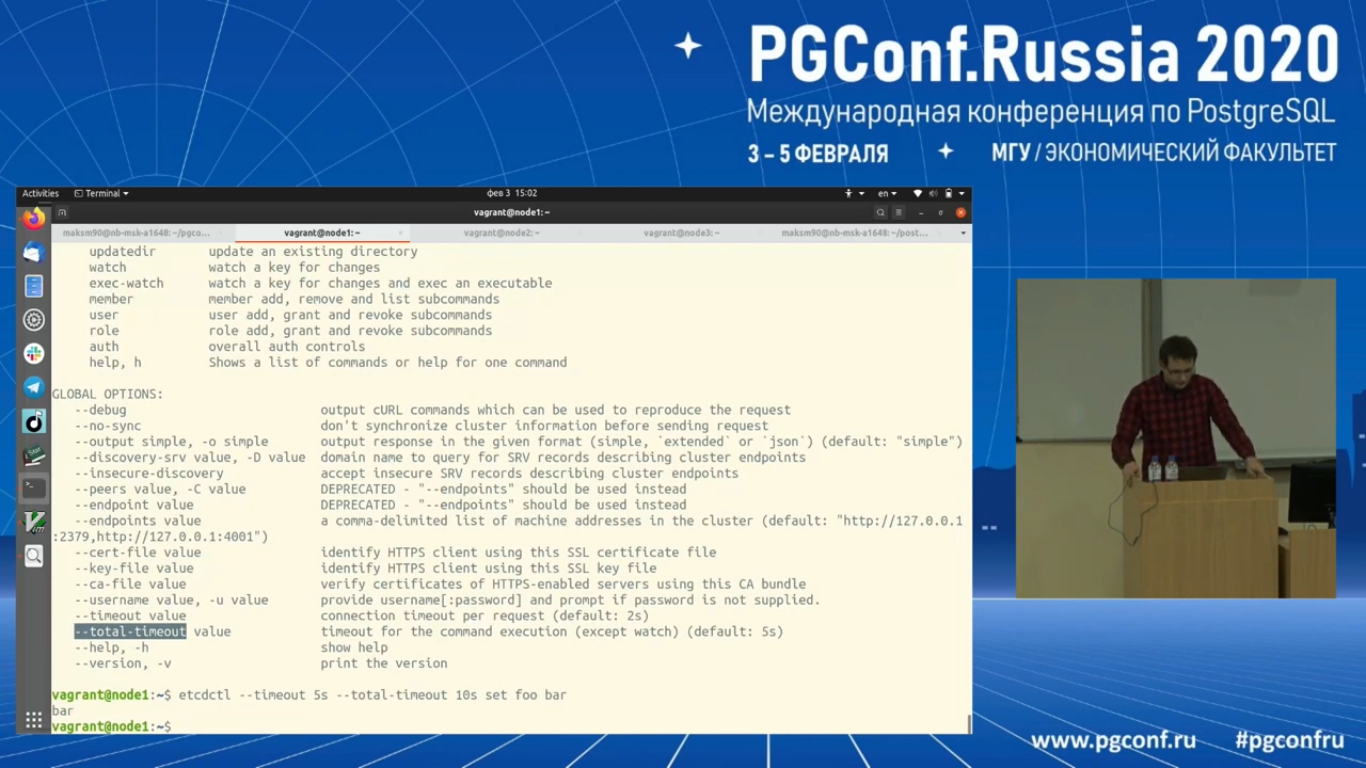
Давайте я запишу что-нибудь в Etcd, чтобы проверить длительность операции. Напишу значение bar. Deadline exceeded – это, в принципе, нормально. Тут есть два параметра в Etcd. Это сам timeout на коннект. Поставим его в 5 секунд. И total_timeout на операцию, который мы поставим на 10 секунд в нашем случае.
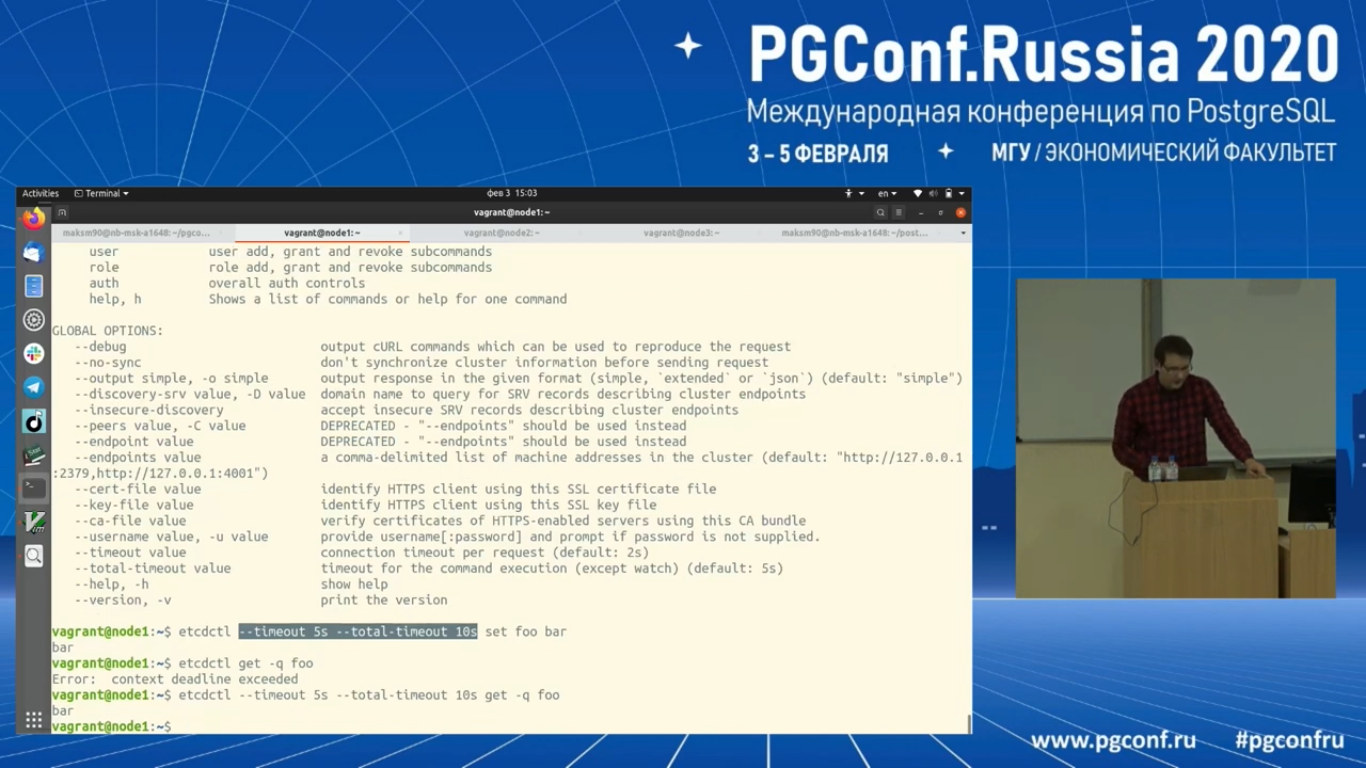
И для тестирования длительности операции по кворуму я буду использовать операцию «get», которая будет прогонятся через кворум кластера. И два тайм-аута. Операция небыстрая.

Давайте вернем сеть нашу обратно. В частности, остановим наше правило.
И обратно вернем наши настройки. Election_timeout в одну секунду, а heartbeat на 100 миллисекунд.
Также важно заметить, что в RAFT кластере на устойчивость кластера может влиять работоспособность какого-то узла. Допустим, если пул стабильный: то существует, то не существует, то в этом случае кластер также может деградировать. И давайте эту ситуацию проверим.
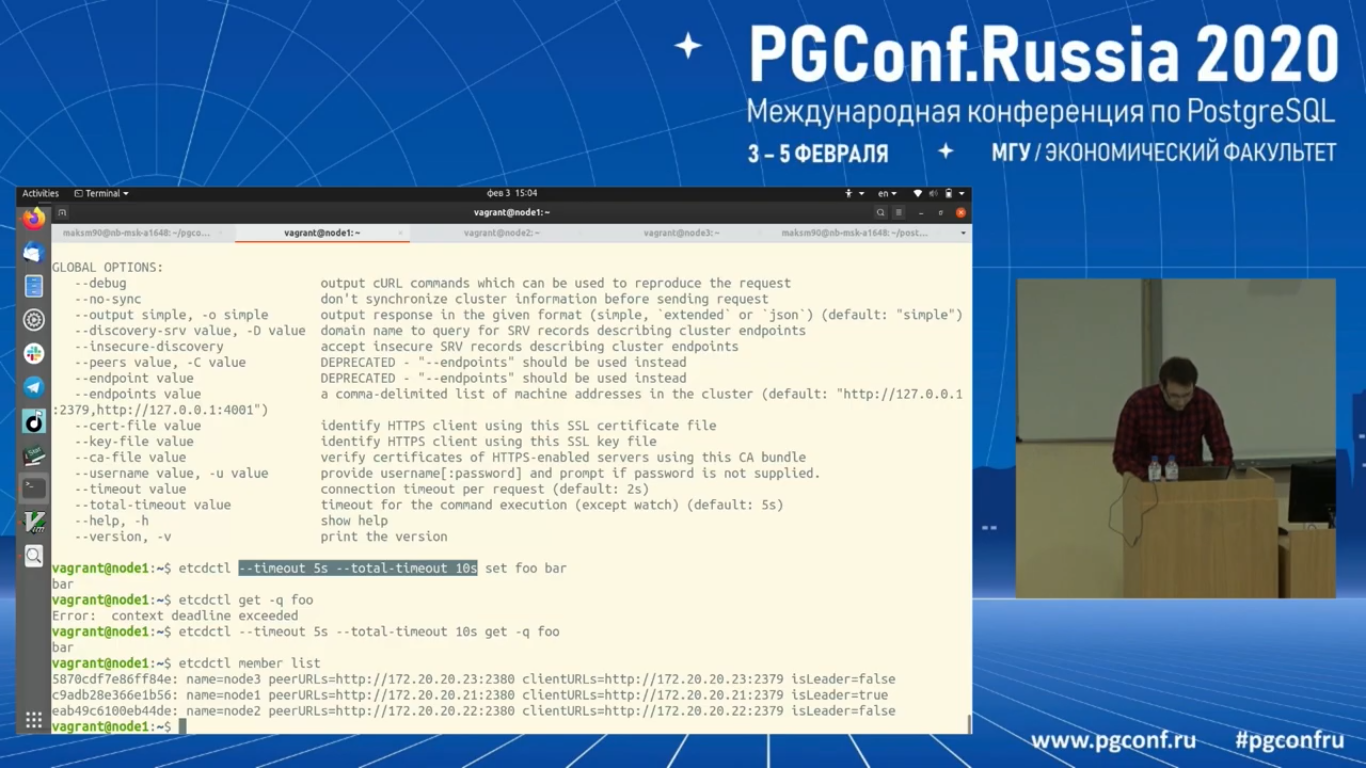
Настройки мы вернули. Etcdctl member list. Первый узел у нас является лидером. Второй – follower.
И давайте для второго узла мы будем эмулировать его периодическую изоляцию и включение в кластер. Сделаем это через bash скрипт – comcast – device, т. е. будем выключать интерфейс. А дальше через какой-то sleep в полтора секунды будем его включать. Comcast – device eth1 – stop и тоже sleep 1,5. Тут done я забыл. Ох, опять неправильно я набрал, опечатка. Вот так вот.

Давайте посмотрим логи Etcd. Видно, что у нас term все время увеличивается, потому что мы изолируем узел, а тайм-аут у него истекает, он поднимает term, пытается заново подключиться к нашему кластеру. Term у нас увеличен. Начинаются новые перевыборы лидера. Он снова отключается. И этот процесс продолжается непрерывно.

И если, допустим, замерить операцию на кворуме Etcd, то она у нас должна быть нестабильной. Вот больше 1 секунды. Поэтому важно, чтобы все узлы были работоспособны. И это касается не только сетевого соединения. Это также может касаться и дисков. А, как я уже говорил, Etcd делает fsync на диск. И если он нестабилен, то агент у нас зависает.
Давайте я остановлю. Comcast – device eth1 – stop.

https://github.com/etcd-io/etcd/blob/master/Documentation/tuning.md#time-parameters
https://github.com/etcd-io/etcd/blob/master/Documentation/op-guide/hardware.md#example-hardware-configurations
И подытожим. Я в последнем слайде по Etcd выписал основные моменты, касающиеся этого кластера.
Реагируем не только на мигание сети, но и на то, стабилен ли у нас диск по времени записи.
И также важно понимать, что кластер Etcd нужно поддерживать, мониторить, делать бэкапы, настраивать и желательно, чтобы это делали отдельные люди и даже выделенная команда.
И также можно использовать этот один кластер для нескольких кластеров Patroni и Stolon. Так это делается в таких приватных облаках, в публичных облаках.

И важно еще помнить одну вещь. Если у нас происходит netsplit, то активная часть кластера окажется там, где будет у нас кворум DCS. На слайде я привел картинку, где разбил кластер так, что у нас кворум Postgres с одной стороны, кворум DCS с другой стороны. И там, где кворум Postgres, эта часть неактивная.
В данной картинке у нас мастер и синхронная реплика находится в минорной части DCS. И фейловер на синхронную не должен происходить, т. е. в такой конфигурации у нас кластер ляжет. И это является тем недостатком, когда DCS выводим наружу от кластеров Patroni и Stolon.

Теперь поговорим про Stolon.
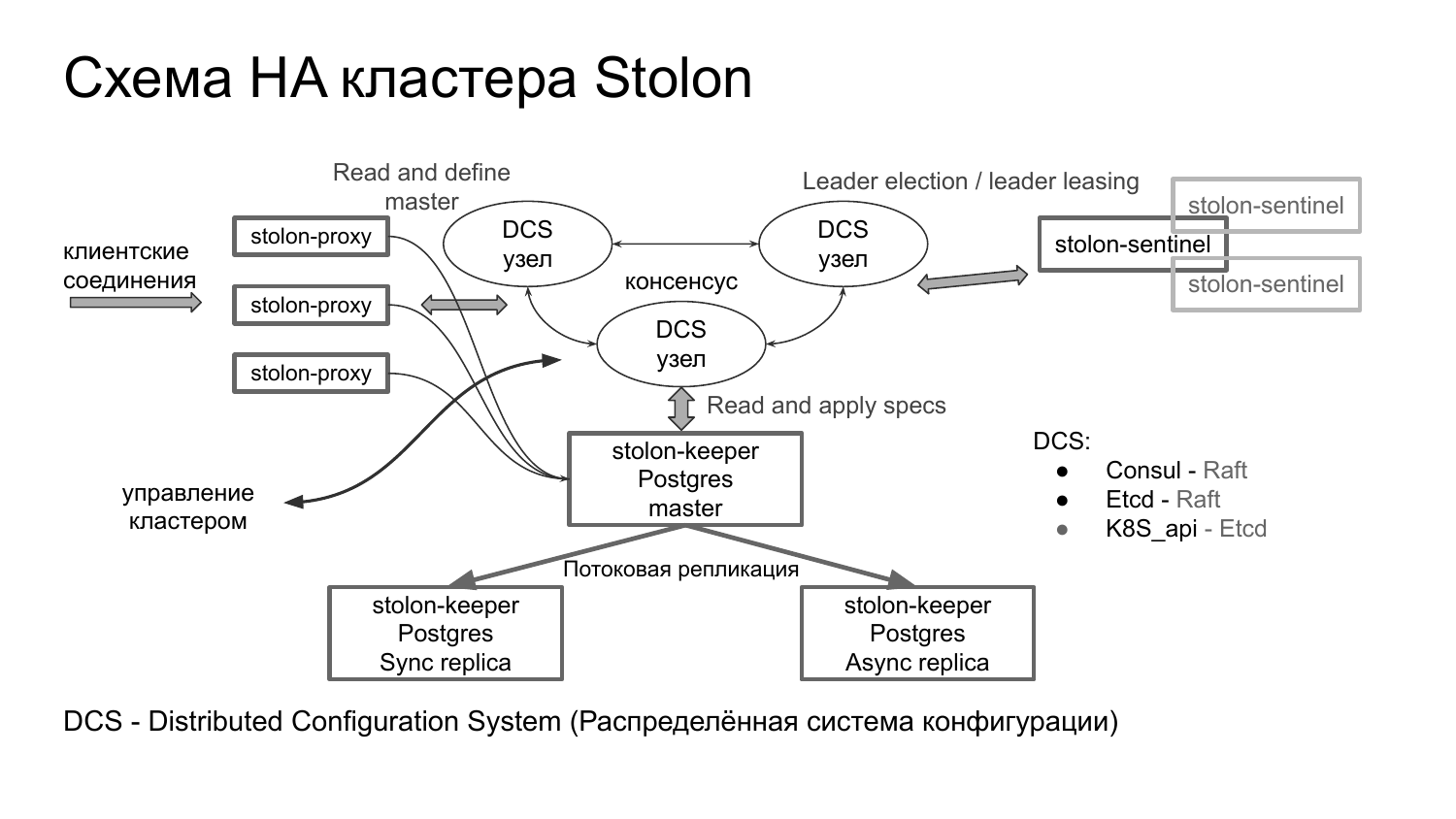
Он устроен следующим образом. Вокруг DCS мы инсталлируем несколько агентов stolon-sentinel, которые являются нашими арбитрами. Они взаимодействуют с DCS через механизмы: лидер election, выбор лидера, поддержка ключа лидера и являются statefull сервисами.
Postgres’ом управляют сервисы Stolon-keeper. А все соединение к кластеру проходят через специальные прокси – stolon-proxy, которые читают конфигурацию и перенаправляют все соединения на мастер.
https://github.com/sorintlab/stolon/issues/313
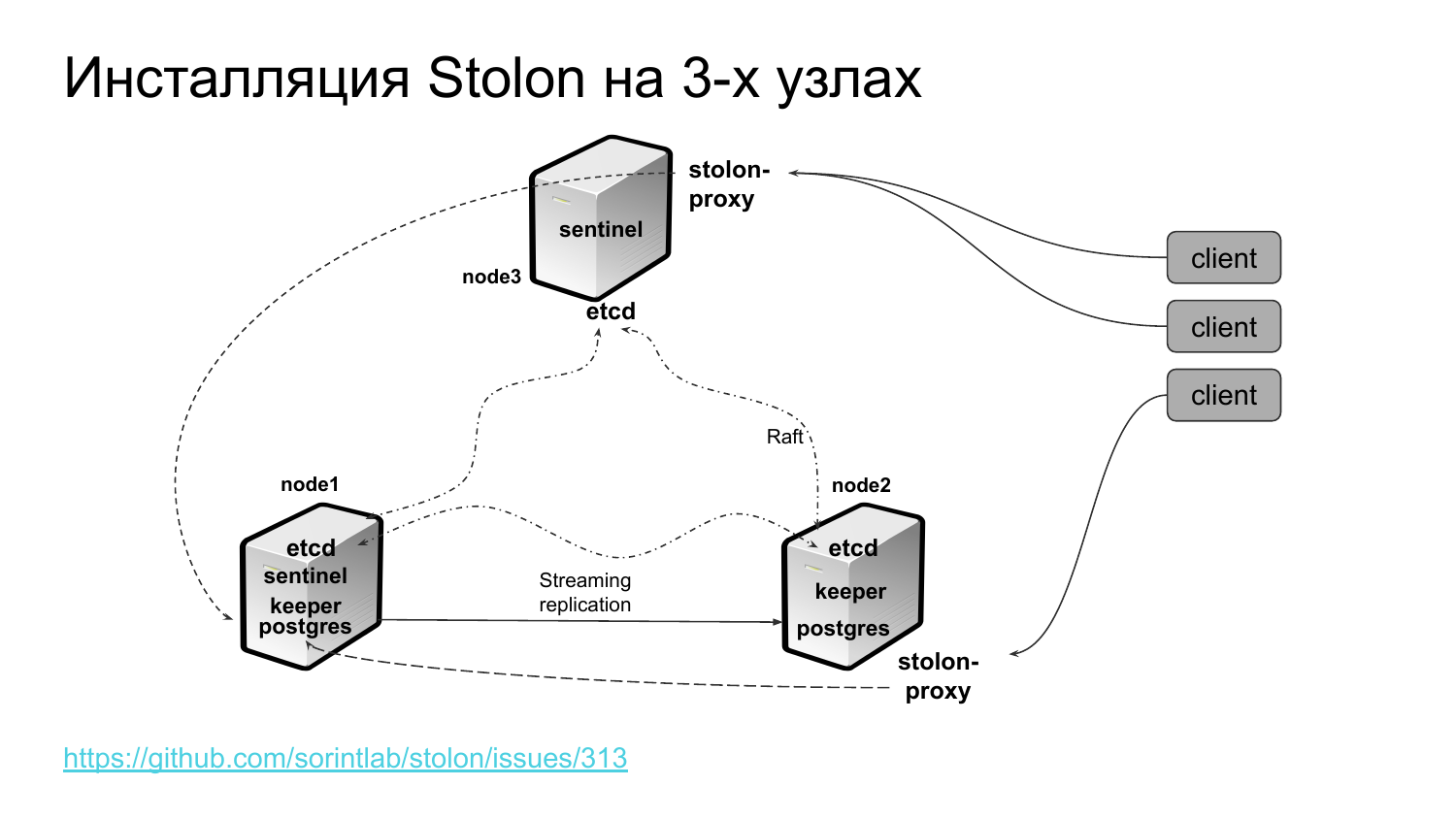
Если смотреть на физическую инсталляцию на 3-х узлах, то это будет выглядеть следующим образом. Мы, как минимум, на 2-х узлах ставим sentinel, обеспечивая его избыточность. Как минимум, на 2-х узлах ставим stolon-proxy. И, допустим, на 2-х узлах баз данных ставим Stolon-keeper, которые управляют postgres-экземплярами.
Демо начинается с 41 минуты 20 секунды
Давайте посмотрим, как происходит инсталляция. Тут все достаточно стандартно. Мы распаковываем бинарники, ставим их в нужных путях. Дальше файл конфигурации, где я объявляю переменное окружение для stolon’овских агентов. Заводим дата-директорию, где у нас будет присутствовать база данных. И Etcd сервисы. Они у нас достаточно специфичные. Я вам это сейчас покажу. И у нас заводятся два пользователя. Один пользователь – это superuser, он управляющий. А второй для репликации. Для них также мы можем завести специальный файл, куда закинем пароли доступа.
Давайте посмотрим на конфигурацию Stolon. Он находится в stolon.d/test-cluster.conf. Сейчас я объясню, почему мы назвали именно «test.cluster» и почему здесь имя важно. Тут я объявляю все переменные окружения для всех агентов, которые подаются на вход, чтобы здесь можно было в одном месте их конфигурировать. Здесь мы объявляем пути до бинарников Postgres, путь в дата-директорию. Тут у меня базовый путь, потому что путь для
дата-директории я отдельно настраиваю. Конфигурирую, какие интерфейсы прослушиваю. Superuser, который будет со стороны Stolon-keeper и других компонентов подключаться к базе. Пользователи репликации и т. д. В документации можете посмотреть, что означает каждое такое переменное окружение.
Почему мы называем «test.cluster»? Давайте посмотрим на system/system/Stolon-keeper@.service. У нас сделано в виде template-сервиса, чтобы мы могли названия инсталлируемого кластера передавать в качестве параметра. И это название используется, когда нужно вычитать нужный конфиг для этого кластера и где у нас будет инсталлирована дата-директория фактическая. Почему именно так? Это нам позволяет на одном узле поддерживать несколько кластеров Stolon, управляясь одним … сервисом. Например, это будет востребовано, если мы хотим восстановить наш кластер из какого-то бэкапа, при этом оставив на текущем узле все настройки и дата-файлы, чтобы потом можно было обратно вернуться.
Давайте поставим через Ansible. Запустим наши сервисы. Я вернусь к этой картинке. Я сделал все так, как на ней изображено. Т. е. на первом и втором узле мы инсталлируем Stolon-keeper. Name=Stolon-keeper@test-cluster state=started enable=on. Поехали.
Давайте посмотрим логи. Test-cluster. Видно, что он запустился. Взял lock на дата-директорию и дальше ожидает конфигурацию кластера. Тут надо отметить, что каждый компонент: Stolon-keeper, sentinel и proxy можно запускать независимо друг от друга. Они никак ничего не поломают.
Давайте на первом и третьем узле запустим sentinel. Давайте посмотрим логи. Видно, что мы запустили на первом узле и то, что он пытался получить лидерство через DCS. Но он не получил. А получил его как раз третий узел. Посмотрим на него. У нас на третьем узле sentinel является лидером, а на первом узле sentinel на подхвате. И давайте поставим на всех узлах прокси. State=started enabled=on. Но что-то он не стартовал. Интересно, почему. Тороплюсь, забыл написать test-cluster. Вот он у нас стартовал. И при этом важно отметить, что все они стартовали и чего-то ждут. А ждут они именно конфигурации всего кластера.
Давайте вернемся к нашей презентации.

https://postgrespro.ru/docs/postgrespro/12/server-shutdown
https://github.com/sorintlab/stolon/issues/707
Тут я выписал workflow работы с кластером Stolon:
- Инициализируется весь кластер через отдельную команду «stolonctl init».
- Изменение всех параметров PostgreSQL и pg_hba происходит тоже снаружи через команду update.
- И важно отметить, как PostgreSQL перезагружается, допустим, применяя параметр, требующий перезагрузки. Это можно сделать вручную. Допустим, рестартовав Keeper, либо завершая post-master. При этом Stolon-keeper перезагрузит PostgreSQL.
- Также в новых версиях добавили специальный параметр «automaticPgRestart», который позволяет автоматически сделать рестарт postgres-узлов при получении параметров на обновление.
- Но тут важно заметить, что он не отрабатывает нужный порядок рестарта при изменении специальных параметров. Например, max_connections, max_lock_per_transaction требуют специального порядка рестарта postgres-узлов. И в релизе этого параметра не затронули эту проблему. И в частности, реплика может отвалиться может навсегда, если мы уменьшаем параметры «max_connections» или «max_lock_per_transaction». Если увеличиваем, то, в принципе, последующий рестарт реплики вернет узел в нормальное русло. Поэтому тут будьте осторожно.
- И добавление узлов – это просто запуск Stolon-keeper. Удаление – мы завершаем Stolon-keeper. Узел у нас помечается как удаленный через отдельную команду. Мы можем ее фактически удалить из кластера с очисткой всех ресурсов, которые были выделены под нее.
Я сейчас покажу, как обновить pg_pba. Посмотрим, чему сейчас равен pba. Вот у нас каталог /opt/stolon/test-cluster. У нас еще базы данных не инициализировались. Давайте их сначала инициализируем. Stolon-test-cluster-spec.json. Здесь мы задаем спецификацию, т. е. параметры для нового кластера и то, как он будет у нас инициализироваться.
Давайте вернемся к презентации.

https://github.com/sorintlab/stolon/blob/master/doc/initialization.md
https://github.com/sorintlab/stolon/blob/master/doc/standbycluster.md
У Stolon существуют три режима инициализации:
- Первый – это с нуля.
- Второй – это PITR, восстановление из бэкапа. Также из него инсталлируется standby cluster.
- Третий – это existing. Этот режим позволяет восстановить кластер, если у нас потерялись данные из DCS. Если они из DCS теряются, то кластер не может функционировать, его надо заново переинициализировать. И чтобы не терять данные, мы можем воспользоваться опцией «existing».
У меня инициализация кластера с нуля. Дальше я задаю опцию unitdb, включая checksums, пустые параметры, включая синхронную репликацию и pgrewind по умолчанию. Давайте это сделаем. Stolonctl. У меня уже все готово. И я на вход подаю файл с конфигурацией.
Давайте посмотрим на логи Keeper, к примеру. У нас лог записи сменился. Keeper ожидает свою роль, которая задается арбитрами sentinel, и пытается их применить. Все, вот он выполнил unitdb, стартовал базу данных. И этот экземпляр у нас standby.
Давайте посмотрим состояние кластера. Есть специальная команда «status». Здесь показано, какие у нас есть Keepers, heaths check на сами Keepers и на Postgres, которыми они управляются. Собственно, кто у нас мастер, кто у нас реплика. Активный прокси и sentinel.
И тут важно заметить, что есть два поля. Это wantedgeneration и currentgeneration. И Stolon-keeper работает по следующему принципу. От арбитров sentinel приходит спецификация, где определяется, какова роль узла, какие у него параметры. И также Keeper поддерживает свое собственное состояние. И свое собственное состояние он должен привести в соответствии со спецификацией.
Можно посмотреть значения всех этих спецификаций. Это большой json, сейчас мы его разобьем. Вот у нас общая кластерная информация. Вот его спецификация. Дальше информация по каждому Keepers и по каждой базе данных. Здесь как раз выделяется отдельное поле, которое отвечает за то, к чему должен стремиться текущий узел. И показывается текущий его статус, т. е. кем по факту он является. Это можно использовать для мониторинга, для машинного разбора. И эту информацию также можно достать через Etcd по ключам.
А мы идем дальше. В целом мы можем сделать так: мы можем останавливать Etcd для интереса. Тут надо отметить, что все агенты могут подключаться к каждому из узлов Etcd. Если у нас один выключается, то подключение меняется на другой. Это, кстати, не выполняется для Consul. В Consul мы можем подключаться только к одному узлу, к одному агенту. Если он падает, то считайте, что агент, допустим, Stolon-keeper остается вне кластера. Если мы убиваем Postgres, то Stolon его рестартует. И также, если убиваем Stolon-keeper. А он у нас поставлен на рестарт в systemd, там опция on abort, поэтому kill -9 он должен обработать.
Давайте для интереса прибьем Postgres. Сделаем kill -9 и посмотрим, что действительно он перезапускается. Сделаем это на мастере. Мастер – это у нас сейчас второй узел. Давайте его прибьем. Stolon-keeper, Ok.
И посмотрим логи. Вот он стартовал. Сейчас вернемся чуть-чуть обратно. Вот у нас Postgres был убит. И Stolon-keeper его рестартовал. В этом плане он является таким супервайзером Postgres. И роли у нас в кластере не поменялись.
Давайте поиграемся сейчас чуть поинтереснее. Попробуем эмулировать реальный fail. Остановим Postgres-мастер. И остановим так, чтобы снаружи у нас была еще нагрузка на этот мастер. Я эту нагрузку эмулирую через pgbench.
Мы можем попробовать удалить какой-нибудь файл, отвечающий за страницу в Postgres, чтобы испортился блок? И во время select выпала ошибка, что испорчен блок, не могу выполнить select.
Если у нас блок испорчен, и мы включили checksums, то мы поймем, что у нас checksums не совпадают по этому блоку, и операция прервется. И в целом в логе внутри Postgres покажется, что блок у нас испорчен. Также, допустим, если у нас checksums не включены, то мы можем спокойно нарваться на какую-то ошибку. Но это уже скажет непосредственно Postgres. Тут никакого отношения Patroni/Stolon не имеют к этому.
Давайте я сейчас запущу pgbench. Я сейчас инициализирую базу. Подключусь я к прокси, который перенаправит соединение в мастер. Они у меня запущены на порту 25432. И у меня сейчас в базе инсталлированы две роли. Давайте сейчас их посмотрим. Stolon/test-cluster/postgres/pg_hba.conf.
Тут видно, что Stolon по умолчанию записал только пользователя superuser, который подключается к базе, и пользователя репликации. Я хочу сейчас добавить третьего пользователя, через которого я буду запускать нагрузку.
Для этого давайте посмотрим на спецификацию. Есть опция «default», которая показывает все параметры по умолчанию. И мне нужно поменять опцию «pg_hba». Я выполняю команду «update». И в json-формате я завожу все строки pgHBA для подключения. Давайте откроем local all posters. Я завожу пользователя Posters trust. И также для всех узлов текущей подсети – host all postgres 172.20.20.0/24 trust.
И сейчас можно оценить, как применились эти настройки. Появились. Давайте я сейчас зайду в базу, создам пользователя Postgres. Зайду локально. Create user postgres superuser. Все, Postgres у нас есть. И в целом можем нашу базу для pg_bench инициализировать. HBA user test. Тест я задавал для Patroni. Базу я инициализировал.
А дальше я запущу нагрузку в цикле while. У меня 20 минут, давайте я отложу эксперименты. Я о них расскажу, но продолжим доклад до конца. А то у меня слишком долго это получается.

Stolon выделяет три параметра. Это:
- SleepInterval – период срабатывания каждого из компонентов.
- RequestTimeout – deadline к PostgreSQL. Deadline операций к DCS – 5 секунд.
- FailInterval – это когда узел у нас крошится, sentinel ловит это событие, то фейловер срабатывает не сразу. Sentinel начинает отсчитывать этот failInterval, чтобы удостовериться в том, что узел действительно у нас упал и необходимо сделать фейловер. При этом нужно учесть, если у нас узел будет ни живым, ни мертвым, т. е. будет выдавать какие-то признаки жизни, т. е. этот failInterval будет отсчитываться заново.
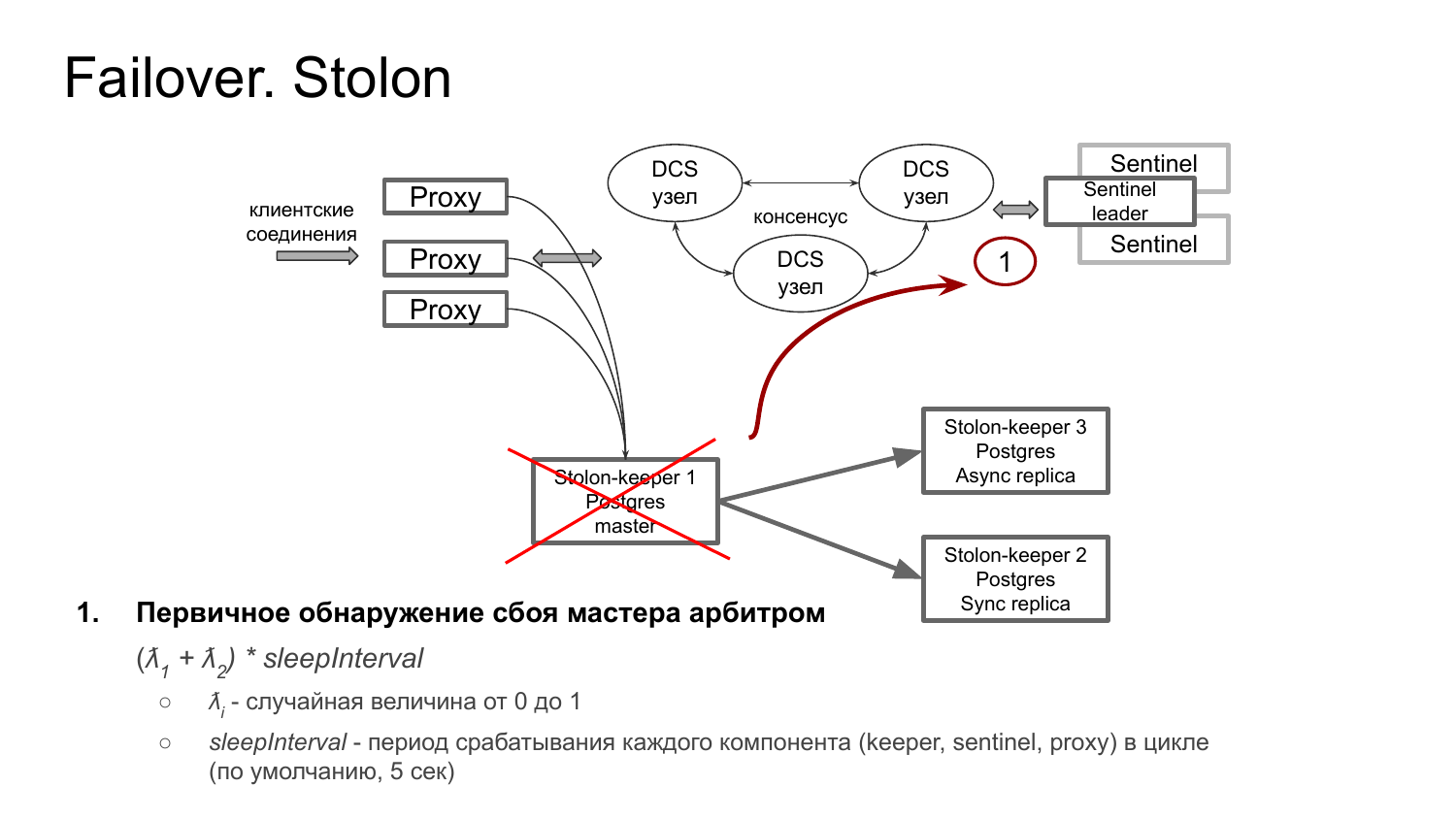
Как происходит autofailover в кластере Stolon?
1 этап – fail нужно обнаружить. У нас либо сам Stolon-keeper помечает Postgres неживым. И это доходит до sentinel. Либо он перестает обновлять свой статус периодически, и это тоже подхватывает sentinel. Замораживание его статуса. И этот этап длится до двух значений sleepInterval. По умолчанию до 10 секунд.

2 этап – запускается тайм-аут подтверждения сбоя, как я уже говорил, на стороне sentinel. Проверяется, что упавший Keeper не дает признаков жизни.

3 этап – вычисляется новая конфигурация кластера на стороне sentinel. И распространяется по остальным Keepers. Этот этап длится тоже до двух циклов sleepInterval.
Я тут привел значение: (λ1 + λ2) * sleepInterval. Это случайная величина от нуля до единицы. Тут как карты упадут.
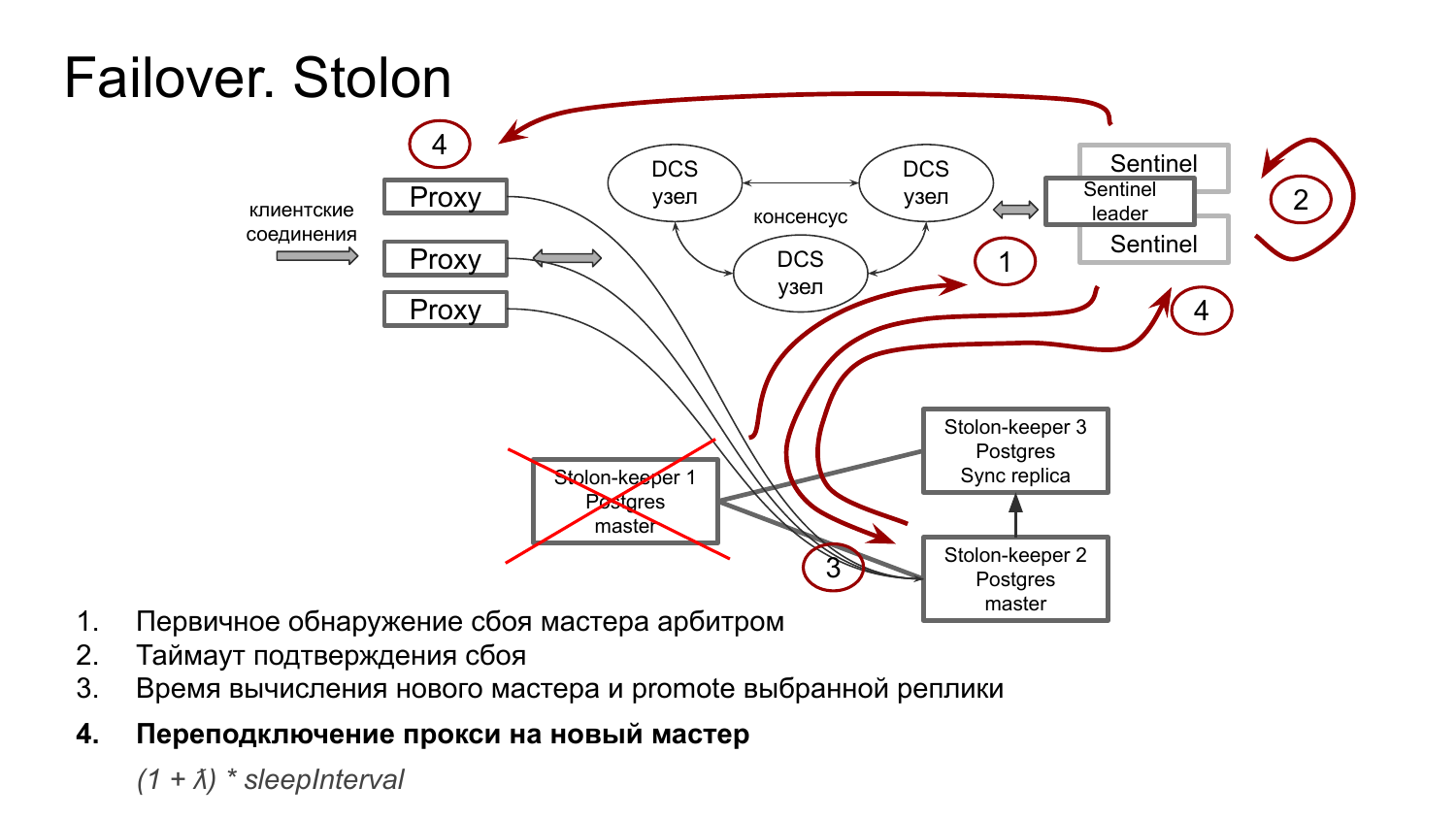
4 этап – переподключение прокси на новый мастер. Это изменение также пробрасывается в DCS. И дальше через sentinel пробрасывается к прокси, которые его подхватывают и переподключаются к новому мастеру.

И суммарно с настройками по умолчанию можно сказать, что при условии, если у нас DCS достаточно стабилен и лидер sentinel у нас не менялся, failover длится от 25 до 50 секунд.
Если у нас происходит fail sentinel’а, то происходит failover по sentinel. Активным становится другой sentinel. И все этапы failover запускаются заново.

И еще стоит отметить, что если у нас Stolon-proxy и Keeper окажутся в изоляции, то Keeper не переводит узел в read only режим. Он никак не фенсит Postgres. Весь фенсинг Postgres выполняет у нас Stolon-proxy.
В нем реализована дополнительная полезная функция. Если он не может подключиться к DCS, а это значит, что он находится в изоляции, то он должен заблокировать все свои соединения, иначе он бы мог писать спокойно в мастер.

Я тут упомянул позитивную вещь про Stolon. Stolon очень хорошо управляется со слотами репликации. Когда у нас узел удаляется из кластера, то его слот репликации и его запись в DCS сразу не удаляется. Запускается отдельный таймер, в который задается параметр «deadKeeperRemovalInterval». По умолчанию он равен 48 часам. И если узел не подает жизни, то удаляется его слот репликации и запись из DCS. А также узел можно удалить вручную, чтобы не ждать этого интервала. Тут надо понимать, что если у нас удерживается слот репликации на мастере и реплика не активна, то на мастере будет накапливаться WAL. И 48 часов это слишком большой интервал для высоконагруженной базы, чтобы диск переполнился.
Тут надо отметить, что Stolon старается максимально все автоматизировать. И это порой плохо. И в частности, он заводит специальные тайм-ауты, deadlines на какие-то длительные процессы внутри Postgres. Например, dbWaitReadyTimeout задают deadline на восстановление при старте базы. Это значение по умолчанию – 60 секунд. Если у нас далеко разнесены checkpoints, то такой deadline очень оптимистичным может быть.
syncTimeout – это deadline на восстановление базы из бэкапа. По умолчанию это значение равно 30 минутам. Но если мы восстанавливаемся из терабайтной базы, то восстановление может занимать часы. И с новой версией этот параметр будет отключен.
InitTimeout – это deadline на инициализацию базы, на initdb фактически.
И еще я здесь не упомянул один тайм-аут. Это conversion timeout. Как я уже говорил, Keeper старается привести состояние в соответствие со спецификацией. И на эти процессы также задается свой тайм-аут. И при эксплуатации кластера Stolon это нужно иметь в виду. Если какой-то процесс не уложится в тайм-аут, то Stolon его заново перезапустит.

Теперь кластер Patroni.
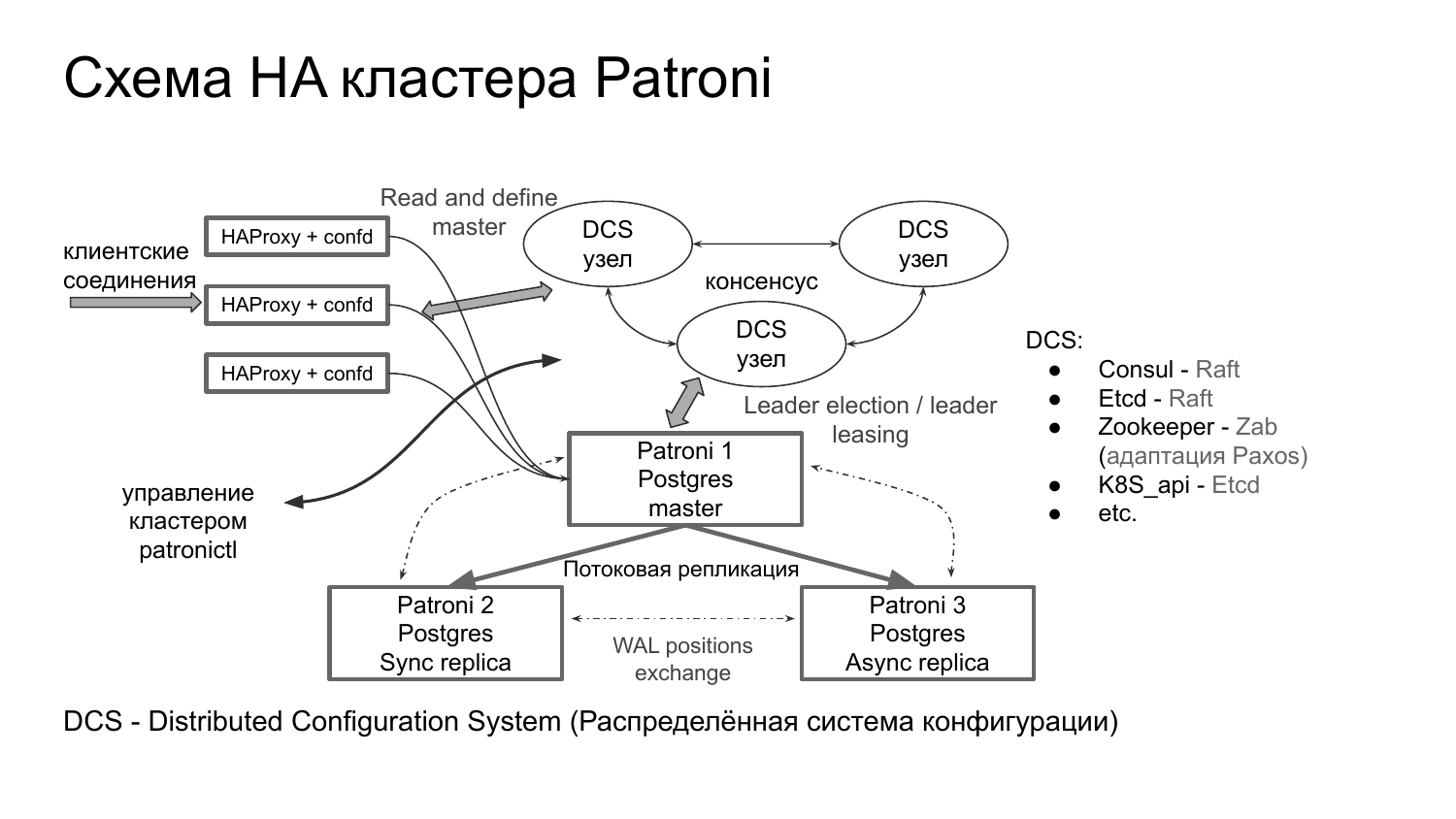
Когда я показывал общую схему кластера Patroni, то я, конечно, слукавил. Почему? Потому что эта схема больше соответствует кластеру Stolon. В Patroni как такового отдельного компонента арбитра нет. Потому что функция арбитража делегирована с одной стороны DCS, на функционал, который предоставляет консенсусный движок и на сами агенты Patroni.

Что из себя представляют различные агенты в Patroni, перечислено на слайде. Я лишь упомяну про арбитраж кластера. С одной стороны, DCS предоставляет функционал выбора нового лидера и поддержку time to live на ключе лидера. С другой стороны, это позволяет в целом системе выбрать текущего лидера, т. е. лидирующий процесс, который будет выполнять какие-то критические операции. Но это все актуально для s… сервисов. Patroni эту парадигму дополняет, вводя отдельный этап выбора нового лидера через взаимообмен WAL-позициями, через REST API, чтобы понять, какой в итоге узел у нас должен стать мастером. И узел с самым большим WAL должен стать мастером. Proxy – это сторонний настраиваемый компонент.

Классическая инсталляция на трех узлах выглядела бы следующим образом. Т. е. на 3-х узлах кластер Etcd. В виде прокси в Postgres Pro рекомендовали связку HAProxy и confd, которая способна приписываться к Etcd и забирать текущую конфигурацию кластера.
На 2-х узлах у нас кластера Patroni. Узлы Patroni с Postgres.

https://patroni.readthedocs.io/en/latest/existing_data.html
Сам Patroni при инициализации позволяет нам не просто с нуля инициализировать базу, но еще описывать кастомизированное восстановление реплик. И реплики вытягиваются basebackup’ом с мастера. В Patroni можно отдельно описывать этапы восстановления реплик, например, из бэкапа.
И также можно выгодно задать кастомные опции самому basebackup. Например, это выгодно, если мы хотим восстановить tablespace.

https://www.postgresql.org/docs/current/hot-standby.html#HOT-STANDBY-ADMIN
Типичный workflow работы с кластером Patroni. Мы запускаем один узел, в котором есть секция bootstrap. В ней описано, как кластер будет инсталлироваться, т. е. это не как в Stolon, где мы запускаем все агенты, и они ожидают конфигурацию, и далее инициализируем кластер. Здесь все можно объявить в bootstrap. И этот узел все инициализирует.
Что хорошо в Patroni? Конфигурацию postgres.conf и pg_hba.conf, и recovery.conf можно менять как глобально в секции DCS наподобие того, как это происходит в Stolon. И можно задавать локально для каждого узла. Локальные настройки имеют больший приоритет над глобальными.
Patroni предоставляет специальные команды по рестарту postgres-узлов. Более того, это можно делать, соблюдая очередность.
Запуск, добавление узлов – это через запуск, установку Patroni.

https://github.com/zalando/patroni/blob/master/haproxy.cfg
https://github.com/zalando/patroni/tree/master/extras/confd
Теперь давайте погорим о прокси.
Прокси – это сторонний настраиваемый компонент. Тут вариативность достаточно широка. Можно использовать различные комбинации. Каждый Patroni-агент наружу предоставляет REST API и специальные endpoints, по которым можно проверить то, что узел в данный момент является мастером, либо репликой.
И в стандарте поставляется конфиг HAProxy, где описываются все узлы и их healthchecks на агенты Patroni.
Также в Patroni реализованы callbacks. Правда, они запускаются асинхронно. Через них можно также менять конфигурацию сторонних прокси.
Мы рекомендуем связку HAProxy и компонент, который бы подписывался к изменениям DCS и менял конфигурацию нашего HAProxy. Здесь HAProxy + confd. Можно использовать consul-temlate. Можно даже собственноручно написать этот компонент. Он не такой сложный.
Начиная с 10-ой версии Postgres в стандартный драйвер libpq добавили возможность перечислять несколько хостов для подключения к узлам, более того, можно даже задавать специальный параметр «target_session_attrs», который будет выбирать мастера. Что будет делать клиент? Он будет последовательно пробегаться по всем хостам и проверять – соответствует ли хост тем условиям, которые описаны в target_session_attrs.
Однако, в целом мы такой подход не очень рекомендуем при условии, если у нас настроен watchdog и не реализован фенсинг Postgres, при условии, если мы убиваем, усыпляем Patroni-агент. Почему? Потому что в этом плане у нас Postgres становится бесхозным, никто его не задемоутит. И он сможет принимать соединения от клиентов на запись.
Слабое место в таких решениях у Stolon и Patroni в том, что фенсинг узла завязан на работоспособности агентов. Мы можем что-то с этими агентами сделать, и никто нам узел не зафенсит.

https://www.consul.io/docs/guides/forwarding.html
https://learn.hashicorp.com/consul/day-2-operations/advanced-operations/dns-caching
https://pgconf.ru/2019/242817 https://pgconf.ru/2019/242821
https://github.com/cybertec-postgresql/vip-manager
Также можно узнать, где является у нас мастер через сервис на DNS. И Consul из коробки предоставляет нам возможность зарегистрировать сервисы и привязать к ним доменные имена. Но тут надо пробрасывать DNS конфигурацию в локальное окружение клиентов. Но на это не каждый пойдет.
И немножко хочу сказать про виртуальный IP-адрес. Это можно сделать через связку HAProxy + keepalived. Либо через vip-manager, где агенты подписываются на DCS, и поднимается виртуальный IP-адрес там, где у нас мастер. Однако, в Postgres Pro мы не рекомендуем такой способ, потому что можно спровоцировать ситуацию, когда у нас будут подняты два виртуальных IP-адреса. К примеру, если мы сделаем kill stop keepalived’у, то через протокол VRRP поднимется IP-адрес на другом прокси HAProxy, и будут два IP-адреса активных на двух узлах. Это, наверное, не хорошо. И тоже самое и со vip-manager. Если мы заморозим агент vip-manager над мастером, осуществим switchover, то никто нам не отпустит виртуальный IP на старом узле. И здесь выгодна ситуация, когда у нас узел физически убивается другим узлом.

И я хотел бы поговорить про фейловер, о том, как он осуществляется. В Stolon выделяются следующие параметры:
- Это ttl – время жизни ключа мастера.
- Loop_wait – период срабатывания Patroni-агента.
- Retry-timeout – максимальная длительность операции к DCS и PostgreSQL.
- Master_start_timeout- максимальная длительность восстановления после падения PostgreSQL экземпляра (не Patroni-агента).
И внизу я еще выписал формулу, которую важно соблюдать, чтобы не было фейковых переключений. Смысл ее таков, что в цикле обновления ключа лидера Patroni-агент осуществляет обращение к Postgres, осуществляет обращение к DCS. Выдерживает тайм-аут loop_wait. И важно, чтобы время жизни ключа лидера укладывалось суммарно во все эти события.
И как срабатывает failover в Patroni?

- Узел у нас пропадает, и ключ лидера в DCS экспарится. Другие Patroni-агенты получают идентификацию. Все это занимает вот такую длительностью по формуле. По умолчанию – 20-30 секунд.

- Дальше Patroni-агенты начинают обмениваться друг с другом по REST API, по endpoint Patroni начинают обмениваться WAL-позициями. При этом тайм-аут этих обменов составляет 2 секунду. Если за 2 секунды узел у нас не ответил, то считается, что он уже недоступен. И среди узлов выбираются те, которые понимают, что у них самая большая WAL-позиция.

- Дальше они начинают гонку за ключ лидера через DCS. И кто-то из них получает этот ключ лидера.

- И дальше все клиенты должны переподключиться к новому мастеру.

Если с настройками по умолчанию и при этом DCS у нас стабилен, то это занимает где-то полминуты, при условии, что у нас все прокси переподключаются за 5 секунд.

Теперь немножко хотел поговорить про ситуацию с фенсингом, когда у нас клиентское подключение не через прокси, а через объявление множества хостов.
Тут как раз изображена ситуация, когда мы убиваем, либо усыпляем Patroni-агент. И какое-то соединение остается на бывшем мастере и может туда что-то писать.

https://www.postgresql.org/message-id/C1F7905E-5DB2-497D-ABCC-E14D4DEE506C@yandex-team.ru
https://github.com/zalando/patroni/blob/master/docs/watchdog.rst
Здесь я выписал все варианты обхода этой ситуации.
- Можно включить синхронную репликацию. Но тут надо понимать, что даже при синхронной репликации можно сделать локальный коммит, например, рестартовав Postgres. Дело в том, что Postgres даже при синхронной репликации сбрасывает WAL-commit на свой диск и только потом дожидается ответов от синхронных реплик.
- Рекомендация от Zalando – это настройка watchdog. Если у нас Patroni-агент не отвечает в какие-то заданные промежутки времени, то весь узел у нас фенсится: рестартуется, либо завершается.
- Мы предлагаем заказчикам обход ситуации через HAProxy и Confd, т. е. умный прокси, который переподключался бы к нужному мастеру.
- И рекомендация от Corosync & Pacemaker — это явный фенсинг узла (от мастера узла к будущему мастеру) до того, как он запромоутится. Т. е. сначала мы гасим второй узел, гарантируем, что у нас не будет второго мастера, а потом мы промоутимся.

Вот я нарисовал, как будет выглядеть через HAProxy и Confd ситуация.
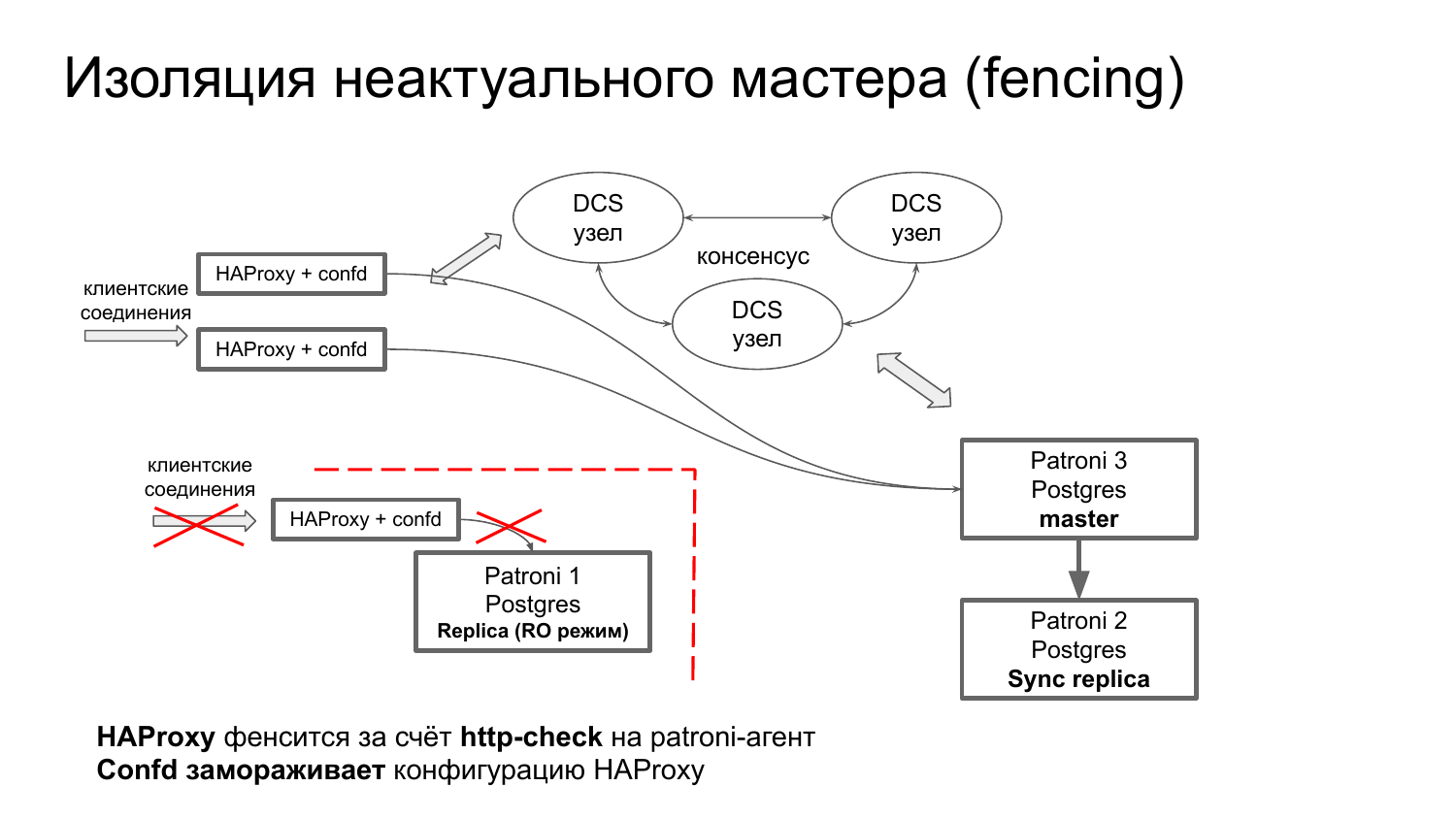
А что будет, если у нас произойдет netsplit? HAProxy с Patroni окажутся в изоляции. Эта связка оборвет все соединения к старому мастеру. И оборвет за счет health check’а на Patroni-агент.
Но есть нюанс у Confd. Confd замораживает конфигурацию, если он оказывается в изоляции от кластера DCS.

Это может привести к плачевной ситуации, если вместо HAProxy у нас используется PgBouncer. В PgBouncer не реализована логика фенсинга во время изоляции от DCS. Конфигурация замораживается и при этом все соединения могут спокойно отправляться на наш мастер, который не задемоутен, потому что Patroni у нас не работает.

- Скажу, в чем Patroni слаб. Он достаточно плохо работает со слотами. Дело в том, что когда узел у нас пропадает, то он через небольшой тайм-аут удаляет запись об узле из DCS и удаляет слот репликации. Если узел был долго в downtime и возвращаясь обратно в кластер, то он может не подключиться к мастеру. Чтобы обойти эту ситуацию тут надо настраивать wal_keep_stgments, либо опираться на восстановление из архива.
- Также важно отметить, что при синхронной репликации лишь одна реплика по факту становится синхронной, т. е. не осуществляется поддержка кворума из нескольких синхронных реплик. Если у нас количество узлов слишком большое, запущена синхронная репликация, мастер и синхронная реплика окажутся в изоляции от основного кластера, то фейловера не будет. Все остальные реплики будут асинхронными.
- И чем хорош Patroni? Patroni по сравнению со Stolon поддерживает очень полезные фичи, особенно для enterprise приложений. Среди них я выделю следующие:
- Это восстановление реплик из бэкапа. Особенно актуально для больших терабайтных баз.
- Нестрогий синхронный режим. Это при синхронной репликации, когда у нас выпадают все синхронные реплики, мастер может переключится в асинхронный режим и дальше продолжать принимать запись. В случае, если попадает этот мастер, то никакой failover не происходит, пока какая-то реплика не синхронизируется с этим мастером. Это аналог Max Availability в Oracle Data Guard.
- И более гибкие настройки для PostgreSQL по сравнению со Stolon.
Спасибо за внимание!
Вопросы.
Вы рассказывали про Etcd, про требования к дискам. Мне интересно, у вас есть уже какой-то опыт?
Да-да, есть. Мы разворачивали, правда, не Etcd, а Consul в mail облаке, на виртуальных дисках. В итоге у нас нестабильность именно по fsync операциям на диск приводила к тому, что кластер у нас деградировал.
А есть требования какие-то? Вы нарисовали, что у вас на одном хосте сразу и то и то стоит. Я так понимаю, что там, как минимум, надо отдельные точки монтирования делать, да?
Как вариант, да-да.
Потому что, как только Postgres начинает переключаться, он очень много на диск дает нагрузки. И если там DCS будет стоять, то он просто станет недоступным.
Согласен, да.
У вас есть по этому поводу настройки? Как вы это делали? Я тоже пробовал. Там, например, Consul менее требователен к изоляции. А Etcd нужен очень хороший диск высокодоступный. Что-то можете про это рассказать?
Я бы не стал различать здесь Consul и Etcd. Они работают по одному и тому же алгоритму RAFT. Обе системы делают fsync на диск при записи. Что касается разнесения хранилищ Postgres и DCS на разные диски, то да, вариант. Мы так особо не советуем, т. е. у нас клиенты сами принимали решения, как управлять дисками.
Я понял, спасибо!
Что на счет Zookeeper? Пробовали, слышали? Как с ним?
Zookeeper я не трогал, не поддерживал. В основном Etcd кластер. Он в Stolon даже не поддерживается, а в Patroni – да.
Есть ли с вашей стороны какие-то рекомендации по использованию слотов именно в Patroni? Потому что вы озвучили проблему. Как-то можно эту проблему избежать?
Со слотами никак. Тут надо либо настраивать wal_keep_segments, т. е. удерживать специальное количество WAL-сегментов на мастере, либо опираться на восстановление из архива. Надо отметить, что недавно я видел в issue жаловались на эту особенность в Patroni. Может быть, в будущем поправят и сделают как в Stolon, чтобы слот сохранялся и удалялся, когда явно об этом пользователь попросит, либо при каком-то другом условии.
Здравствуйте! Спасибо за мастер-кластер! Я добавлю комментарий, касательно слотов репликации. В Patroni есть возможность создания своих кастомных перманентных слотов репликации, которыми вы вручную управляете. Если вы его создали, он не удалится, он останется в кластере.
Эти слоты для других клиентов, как я понимаю. Для реплик остаются отдельные слоты. Эти слоты для других систем.
Спасибо большое за комментарий. В данном функционале для реплик я его не использовал. Я понял его именно так. Возможно, я ошибаюсь. Конкретно я эту проблему решаю лишь увеличением количества хранимых WAL-сегментов, исходя из нагрузки для каждого кластера индивидуально. И если на небольшое количество времени у меня будет не доступна реплика, она сможет эти WALs получить. Обычно этого хватает. Острой такой необходимости не было, но это нужно проверить. Спасибо!
Я еще по слотам добавлю. Я забыл упомянуть, что изначально слоты разрабатывались для какой-то фиксированной конфигурации мастер-реплика. И совсем они не приспособлены, если у нас мастер приходящий. Т. е. когда мы выполняем switchover или failover, то мы должны заново создавать слоты репликации на новом мастере. И в этот самый момент у нас при promote происходит checkpoint, у нас WALs могут потеряться. И реплики могут не встать под новый мастер. Эта проблема известная, думаю, в будущем ее поправят.
Спасибо за презентацию! Вы исследовали все направления из имеющихся технологий, где-то что-то использовали. На ваше усмотрение, какая из них на данный момент является самой надежной и более перспективной на ближайшее время?
Если хочется здесь и сейчас под enterprise, то это Patroni. Хотя ваш покорный слуга участвует в разработке Stolon. Я верю, что мы его сможем довести до ума. Мне там импонирует архитектура. Она точь-в-точь срисована с кластера Kubernetes, где у нас явно выделяются управляющие сервисы, которые управляют непосредственно узлами. Это Keeper, Sentinel. И в этом плане, если доработать этот продукт, то он будет перспективнее.
В Patroni есть еще одно слабое место при выборе нового мастера. Там обмен WAL-позициями, когда вычисляется узел с наибольшим значением, это все проходит не через DCS. DCS про это не знает. И мы сталкивались с такой проблемой (ее, правда, пофиксили), когда узел у нас был изолирован от DCS, но при этом участвовал в выборе нового лидера. И мешал выбрать этого самого лидера. Я даже могу скинуть issue, это была с Consul история. На мой взгляд этот механизм слабо проработан в Patroni. А в Stolon все сделали по науке. Там срисовывали все с Kubernetes.
Еще один вопрос. Вы сказали, что Stolon именно разрабатываете?
Да.
У меня была задача – существующую базу master-slave засунуть именно в под Stolon.
Все, я понял. Не получится без переливки данных, только через standby кластер. У меня есть задача – сделать отдельную опцию Stolon, которая подхватывает существующие. Но сейчас нет, это только через миграцию, через standby кластер.
Я понял. Я с этим и столкнулся. Я нашел один способ.
Вручную, да?
Да, вручную. Но в этом и проблема. Он настолько автоматизирован, что если ты буквально ошибаешься даже в строке, то получается, что он просто убивает все данные и заново создает пустой.
Это недостаток, конечно.
Т. е. сейчас это не решено?
Нет, не решено.
У Patroni как раз с этим хорошо. Там можно отключить, подсунуть, он видит, что есть существующие данные. Соответственно, подхватывает и начинает с ними работать. Спасибо.
Тут надо понять, что каталог для Patroni должен спокойно модифицироваться, в том числе и удаляться. В Stolon специально пошли на то, чтобы в Postgres засунуть вовнутрь keeper data, чтобы с ним можно было спокойно манипулировать.
Можете сказать, когда это в Stolon будет сделано?
Это open source, не могу сказать.
Но там есть уже такое понимание, что это нужно, да?
Да, был issue. Я в том числе пришел к этому.
Я даже писал в какой-то чат, в котором много вопросов об этом задают. И они как-то остаются без ответа. Я понял, что эта проблема есть.
Вы можете об этом поискать в issue. Даже автор ответил, как это сделать вручную, но он упомянул, что это может быть потом не актуально.
Да-да, это опасно. Спасибо.
Здравствуйте! Два небольших вопроса. Первый. Вы говорили, что есть проблема с HAProxy, когда у нас список нод указан в приложение через запятую. Т. е. приложение может остаться на старом мастере. У HAProxy есть опция "on-marked-down shutdown-sessions", которая призвана как раз закрывать все соединения после того, как это нода признана более не мастером.
А как она определит, что не мастер? Через health checks?
Да, через http check на REST API.
Я, по-моему, упоминал непосредственно о HAProxy, когда прописано несколько IP-адресов в строке подключения. И второй вариант – это PgBouncer, где нет health checks. В HAProxy – да, health checks позволяют зафенсить текущий узел на основании того, что он уже не мастер. Однако, я думаю, более правильное решение – это не опираться на мнение Patroni, поскольку его действительно можно усыпить и что-то с ним такое сделать.
Но Patroni берется через Etcd через REST API.
Да, чтобы через Etcd подхватывалось и фенсилось, если у нас нет возможности подключиться через Etcd.
Если у нас нет возможности подключиться к Etcd? Вы сказали, что есть проблема, когда агент недоступен и фенсинг не происходит. И как раз watchdog, который Patroni поддерживает, призван решать эту проблему, если у нас агент не может возобновить ключ, то таймер watchdog заканчивается и случается reboot.
Да, watchdog – это надежный фенсинг. Однако есть проблемы с watchdog. В случае Patroni там надо назначать пользователя PostgreSQL, который управляется Patroni. А watchdog – это общедоступный девайс, его могут использовать и другие приложения, а мы ему такие ограничения назначаем. Поэтому мы в этом плане не особо на него опираемся.
Я понял, спасибо.
Потом еще watchdog сработает по тайм-ауту, т.е. если у нас, допустим, завис Patroni-агент безобидно, то все равно узел уйдет на reboot. Проблему фенсинга такого изолированного узла мы решаем через умный прокси.
По идее watchdog должен случиться, когда случится переезд на другой мастер, потому что, если агент завис, failover все равно случится, он не сможет ключ обновить. Мастер в любом случае сменится.
Мастер изменится, я не спорю. Но задемоутится ли старый мастер? Вот в чем вопрос.
Он либо задемоутится, либо уйдет…
Он не задемоутится, если остановим Patroni, т. е. убьем его или что-то с ним сделаем. Но watchdog – это как защита от этого.
Если Patroni сможет обновить информацию в Etcd о том, что он больше не лидер, тогда он переведет ноду в режим standby. А если сможет, то таймер watchdog закончится и все для этой ноды тоже закончится.
Это понятно. Тут основном момент в том, что мы Patroni усыпляем, чтобы не было демоута как такового, чтобы оставить в том положении, в котором он был ранее. Я понял вашу мысль. Тут два варианта: либо watchdog, либо умный HAProxy.
Спасибо.
Есть еще один вопрос по поводу нестабильного узла и Etcd. Это может привести к деградации всего кластера?
Да-да.
С этим мы что-то можем сделать?
Увеличить тайм-аут.
И все? А увеличение числа узлов это не поможет, да?
Да-да.
Т. е. единственный сервер может, по сути, весь кластер уложить?
Да. Я об этом упомянул в одном тезисе для неустойчивой конфигурации. И тайм-аут – это единственный способ. Это heartbeat_interval и election_timeout в частности.
Спасибо!

