Задача граба информации с веб страниц, всегда актуальна. Как для какого-то проекта, так и в целях более удобного использования ресурса. Я имею ввиду юзабилити или просто необходимость увидеть данные в другом разрезе. Грабить чужую информацию и использовать ее в коммерческих целях всегда плохо, за это обычно пытаются наказать и наказывают. А в личных целях, использовать ее можно свободно. Это, наверно, можно сравнить с использованием карандаша или цветных маркеров при чтении газет и журналов. Например, если я обвожу объявления то красным, то желтым цветом, а некоторые перечеркиваю жирным, то я просто качественно изменяю отображение информации в нужном для моих задач свете. Но юристов надо бояться.
Около полугода назад в Киеве было намечено проведение BlogcampCEE и все, кто хотел принять участие в ивенте, должны были зарегистрироваться и заполнить свой профиль. С локальным рынком интернет проектов на тот момент я был мало знаком, как и с тем, кто и что делает на украинском рынки ИТ и Интернет. Публичные профили участников этого мероприятия как раз и позволят составить некоторую картину участников рынка (тусовки). Удобно пользоваться такой информацией, когда она находится на одной странице. Для того, что бы собрать все эти данные вручную необходимо было бы потратить много времени на переходы по страницами и копи-паст, да еще и обновлять со временем пришлось бы тоже ручками.
Программерские скилы есть, значит что-то придумать можно. А лень, как известно, это двигатель прогресса. Как раз недавно коллеги по работе решали задачу получения с html страницы на Алексе рейтинг сайта. А он был скрыт за кучей подставных спанов с генерируемыми стилями, что не давало возможности напрямую вытянуть это значение. Вот и познакомились тогда с WebHarvest-ом. И отлично решили эту задачу, да еще и с кучей подобных, которые возникают при написании тулзы для SEOшников. Им ведь надо много данных, пейдж ранков, стойкости ключевых слов, анализ конкурентов и т.д. и т.п. И на процентов 80% задач связанный с сбором информации API не существует, надо просто бегать по страничкам и собирать эту инфу.
Итак, хочу поделиться своим опытом получения нужной информации в удобочитаемом виде с сайта BlogcampCEE (просто пример из жизни) с использованием библиотеки WebHarvest, языка программирования Java (в бекграунде), средства сборки Ant и процессора XSLT для преобразования XML в HTML.
Нашел на тот момент страницу blogcampcee.com/ru/group/tracker на которой трекаются все открытые события происходящие на сайте. Среди них есть событие типа Usernode, которое означает регистрацию нового пользователя и содержит ссылку на профиль пользователя.
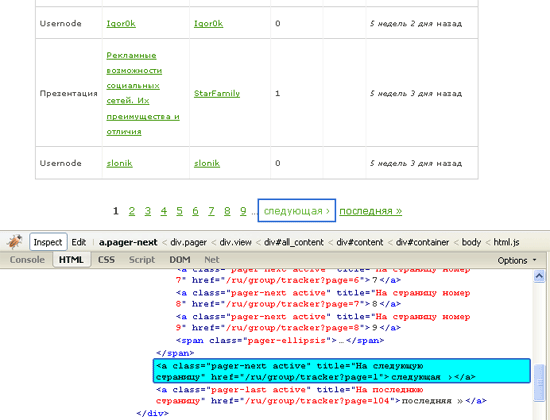
Позже, обнаружил страницу blogcampcee.com/ru/userlist, где показываются исключительно пользователи, и именно ее было бы логичнее взять за точку входа в задачу. Но было уже поздно, все уже сделано. Она и не очень то помогла бы, разве что ускорила работу за счет отсутствия неинтересующих ивентов и дополнительной проверки типа. От кликов не спасла бы точно.
Задача состояла в том, что нужно было пролистать все возможные страницы, достать все ссылки на страницы пользователей и потом по каждому пользователю пройтись и собрать необходимую информацию.
Писать файл конфигурации приходится в GUI от Webharvest, не ахти среда разработки, но лучше чем вообще ничего. Отлаживать тоже непросто. Но как минимум состояние переменных можно посмотреть в любой точке выполнения. А это уже много.
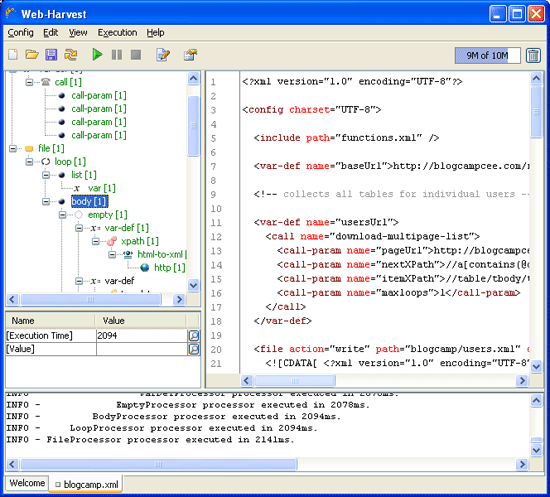
WebHarvest GUI
В файл functions.xml выносятся фунции, которые потом будут использоваться в основном файле конфигурации. В отдельную функцию вынесено хождение по листалке и выдирание линков на страницы пользователей (позаимствована с некоторыми изменениями с примеров по WebHarvest-у).
Основной файл конфигурации blogcamp.xml содержит логику прохода по страницам пользователей и выдергивание некоторых полей, включая ссылки на личные страницы и сайты проектов, а это меня интересовало больше всего. И вся эта информация в формате кастомного xml (users-samples.xml) сохраняется в файл.
Файл в формате XML читать не совсем удобно, поэтому для него был написан users-style.xsl, чтобы придать читаемый и удобный вид.
И вот такую страницу получаем на выходе XSLT процессора.
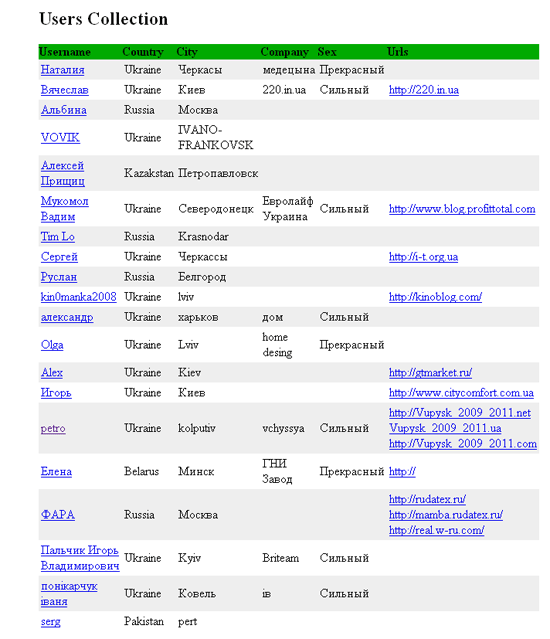
Желаемый формат представления списка пользователей.
WebHarvest — это чисто программерская тулза, которую как библиотеку удобно юзать в своих проектах скармливая ей нужные файлы конфигурации и получая желаемый результат. Поэтому свяжем граб и XSL преобразование в единый процесс с помощью Ant, как будто оно будет дальше развиваться в сложный продукт или чтобы в будущем не пришлось вспоминать, а как же это все дело вызывалось и куда складывалось. Так получился build.xml и такая структура.

Теперь, когда в будущем придется вспоминать, что и к чему тут происходит, и повторять эти процедуры (а это происходит не редко и через много времени, когда успеешь напрочь забыть, что это вообще такое) будет очень просто это возобновить, повторить, править и т.д. и т.п.
Задача решена. Необходимая информация находится на одной странице в удобном для меня виде. Весь процесс легко повторяется нажатием одной кнопки, что очень важно так как количество пользователей увеличивается и со временем надо будет обновить свой лист.
Самый главный — это отсутствие многопоточности в процессе граба. Командная тулза работает только так. Это не было критично для моей задачи. Программно вы вольны делать, что хотите. И организовывать многопоточность, распараллеливание и работу в распределенном режиме на кластере из N компов — пожалуйста. Все в ваших руках.
Не совсем удачная структура самого решения. Когда сразу делается проход для определения всех ссылок пользователей, а потом по ним уже делается процессинг. Лучше сделать процессинг ссылки пользователя сразу, как только она получена и сохранить результат в файл. Тогда, при обрыве коннекта или еще чего-то, не придется запускать граб с самого начала, а можно будет продолжить с того места где все повалялось.
Нет порядкового номера в результирующем HTML, это я уже заметил потом и лень было доделывать, ведь это снова вспоминать XSLT.
Мало комментариев во всех файлах конфигурации. Сорри, но это бич, который преследует меня постоянно. Обычно они начинают писаться после отмечания полугода работы над проектом и ты понимаешь, что ресурс памяти исчерпал себя, а навороты в проекте и не думают останавливаться :)
И еще много других можно найти.
Не люблю, когда читая статью нельзя сразу все попробовать в жизни. Поэтому выкладываю архив с полным проектом, включая WebHarvest. Для удобной работы необходимо чтобы с командной строки в любом месте вашей системы запускался Ant. Важно! Не мучайте сайт блогкемпа. Хоть ивент и прошел, но все равно, это ж ведь хостинг и трафик не обязательно анлим.
Если не работаешь много с XPath, то это все быстро забывается. Вот пара ресурсов, которые мне помогли освежить (изучить) особенности этих технологий.
Спецификация XPath
Примеры написания XPath
Основная цель — показать возможность использования тулзы WebHarvest, в качестве граббера в своих проектах достигнута.
Фич и наворотов у тулзы достаточно, включая использование Javascript и XQuery, сохранение куки, базовая аутентификация, подмена юзер-агента, кастомные хидеры запроса и т.д. Да и переписать часть API можно или аспектами закастомить до неузнаваемости, что папа создатель потом не узнает.
Возникновение задачи
Около полугода назад в Киеве было намечено проведение BlogcampCEE и все, кто хотел принять участие в ивенте, должны были зарегистрироваться и заполнить свой профиль. С локальным рынком интернет проектов на тот момент я был мало знаком, как и с тем, кто и что делает на украинском рынки ИТ и Интернет. Публичные профили участников этого мероприятия как раз и позволят составить некоторую картину участников рынка (тусовки). Удобно пользоваться такой информацией, когда она находится на одной странице. Для того, что бы собрать все эти данные вручную необходимо было бы потратить много времени на переходы по страницами и копи-паст, да еще и обновлять со временем пришлось бы тоже ручками.
Поиск пути
Программерские скилы есть, значит что-то придумать можно. А лень, как известно, это двигатель прогресса. Как раз недавно коллеги по работе решали задачу получения с html страницы на Алексе рейтинг сайта. А он был скрыт за кучей подставных спанов с генерируемыми стилями, что не давало возможности напрямую вытянуть это значение. Вот и познакомились тогда с WebHarvest-ом. И отлично решили эту задачу, да еще и с кучей подобных, которые возникают при написании тулзы для SEOшников. Им ведь надо много данных, пейдж ранков, стойкости ключевых слов, анализ конкурентов и т.д. и т.п. И на процентов 80% задач связанный с сбором информации API не существует, надо просто бегать по страничкам и собирать эту инфу.
Итак, хочу поделиться своим опытом получения нужной информации в удобочитаемом виде с сайта BlogcampCEE (просто пример из жизни) с использованием библиотеки WebHarvest, языка программирования Java (в бекграунде), средства сборки Ant и процессора XSLT для преобразования XML в HTML.
Первый подход
Нашел на тот момент страницу blogcampcee.com/ru/group/tracker на которой трекаются все открытые события происходящие на сайте. Среди них есть событие типа Usernode, которое означает регистрацию нового пользователя и содержит ссылку на профиль пользователя.
Позже, обнаружил страницу blogcampcee.com/ru/userlist, где показываются исключительно пользователи, и именно ее было бы логичнее взять за точку входа в задачу. Но было уже поздно, все уже сделано. Она и не очень то помогла бы, разве что ускорила работу за счет отсутствия неинтересующих ивентов и дополнительной проверки типа. От кликов не спасла бы точно.
Задача состояла в том, что нужно было пролистать все возможные страницы, достать все ссылки на страницы пользователей и потом по каждому пользователю пройтись и собрать необходимую информацию.
Писать файл конфигурации приходится в GUI от Webharvest, не ахти среда разработки, но лучше чем вообще ничего. Отлаживать тоже непросто. Но как минимум состояние переменных можно посмотреть в любой точке выполнения. А это уже много.
WebHarvest GUI
В файл functions.xml выносятся фунции, которые потом будут использоваться в основном файле конфигурации. В отдельную функцию вынесено хождение по листалке и выдирание линков на страницы пользователей (позаимствована с некоторыми изменениями с примеров по WebHarvest-у).
Основной файл конфигурации blogcamp.xml содержит логику прохода по страницам пользователей и выдергивание некоторых полей, включая ссылки на личные страницы и сайты проектов, а это меня интересовало больше всего. И вся эта информация в формате кастомного xml (users-samples.xml) сохраняется в файл.
Модернизация
Файл в формате XML читать не совсем удобно, поэтому для него был написан users-style.xsl, чтобы придать читаемый и удобный вид.
И вот такую страницу получаем на выходе XSLT процессора.
Желаемый формат представления списка пользователей.
Структура минипроекта
WebHarvest — это чисто программерская тулза, которую как библиотеку удобно юзать в своих проектах скармливая ей нужные файлы конфигурации и получая желаемый результат. Поэтому свяжем граб и XSL преобразование в единый процесс с помощью Ant, как будто оно будет дальше развиваться в сложный продукт или чтобы в будущем не пришлось вспоминать, а как же это все дело вызывалось и куда складывалось. Так получился build.xml и такая структура.
Теперь, когда в будущем придется вспоминать, что и к чему тут происходит, и повторять эти процедуры (а это происходит не редко и через много времени, когда успеешь напрочь забыть, что это вообще такое) будет очень просто это возобновить, повторить, править и т.д. и т.п.
Задача решена. Необходимая информация находится на одной странице в удобном для меня виде. Весь процесс легко повторяется нажатием одной кнопки, что очень важно так как количество пользователей увеличивается и со временем надо будет обновить свой лист.
Недостатки
Самый главный — это отсутствие многопоточности в процессе граба. Командная тулза работает только так. Это не было критично для моей задачи. Программно вы вольны делать, что хотите. И организовывать многопоточность, распараллеливание и работу в распределенном режиме на кластере из N компов — пожалуйста. Все в ваших руках.
Не совсем удачная структура самого решения. Когда сразу делается проход для определения всех ссылок пользователей, а потом по ним уже делается процессинг. Лучше сделать процессинг ссылки пользователя сразу, как только она получена и сохранить результат в файл. Тогда, при обрыве коннекта или еще чего-то, не придется запускать граб с самого начала, а можно будет продолжить с того места где все повалялось.
Нет порядкового номера в результирующем HTML, это я уже заметил потом и лень было доделывать, ведь это снова вспоминать XSLT.
Мало комментариев во всех файлах конфигурации. Сорри, но это бич, который преследует меня постоянно. Обычно они начинают писаться после отмечания полугода работы над проектом и ты понимаешь, что ресурс памяти исчерпал себя, а навороты в проекте и не думают останавливаться :)
И еще много других можно найти.
Материалы
Не люблю, когда читая статью нельзя сразу все попробовать в жизни. Поэтому выкладываю архив с полным проектом, включая WebHarvest. Для удобной работы необходимо чтобы с командной строки в любом месте вашей системы запускался Ant. Важно! Не мучайте сайт блогкемпа. Хоть ивент и прошел, но все равно, это ж ведь хостинг и трафик не обязательно анлим.
Если не работаешь много с XPath, то это все быстро забывается. Вот пара ресурсов, которые мне помогли освежить (изучить) особенности этих технологий.
Спецификация XPath
Примеры написания XPath
Заключение
Основная цель — показать возможность использования тулзы WebHarvest, в качестве граббера в своих проектах достигнута.
Фич и наворотов у тулзы достаточно, включая использование Javascript и XQuery, сохранение куки, базовая аутентификация, подмена юзер-агента, кастомные хидеры запроса и т.д. Да и переписать часть API можно или аспектами закастомить до неузнаваемости, что папа создатель потом не узнает.
