Currently, there are hardly any high quality / modern / free / public voice activity detectors except for WebRTC Voice Activity Detector (link). WebRTC though starts to show its age and it suffers from many false positives.
Also in some cases it is crucial to be able to anonymize large-scale spoken corpora (i.e. remove personal data). Typically personal data is considered to be private / sensitive if it contains (i) a name (ii) some private ID. Name recognition is a highly subjective matter and it depends on locale and business case, but Voice Activity and Number Detection are quite general tasks.
Key features:
- Modern, portable;
- Low memory footprint;
- Superior metrics to WebRTC;
- Trained on huge spoken corpora and noise / sound libraries;
- Slower than WebRTC, but fast enough for IOT / edge / mobile applications;
- Unlike WebRTC (which mostly tells silence from voice), our VAD can tell voice from noise / music / silence;
- PyTorch (JIT) and ONNX checkpoints;
Typical use cases:
- Spoken corpora anonymization;
- Can be used together with WebRTC;
- Voice activity detection for IOT / edge / mobile use cases;
- Data cleaning and preparation, number and voice detection in general;
- PyTorch and ONNX can be used with a wide variety of deployment options and backends in mind;
Getting Started
For each algorithm you can see the examples in the provided colab or in the repo itself. For VAD we also provide streaming examples for a single stream and multiple streams.
import torch
torch.set_num_threads(1)
from pprint import pprint
model, utils = torch.hub.load(repo_or_dir='snakers4/silero-vad',
model='silero_vad',
force_reload=True)
(get_speech_ts,
_, read_audio,
_, _, _) = utils
files_dir = torch.hub.get_dir() + '/snakers4_silero-vad_master/files'
wav = read_audio(f'{files_dir}/en.wav')
# full audio
# get speech timestamps from full audio file
speech_timestamps = get_speech_ts(wav, model,
num_steps=4)
pprint(speech_timestamps)Latency
All speed test were run on AMD Ryzen Threadripper 3960X using only 1 thread:
torch.set_num_threads(1) # pytorch
ort_session.intra_op_num_threads = 1 # onnx
ort_session.inter_op_num_threads = 1 # onnxStreaming latency depends on 2 factors:
- num_steps — number of windows to split each audio chunk into. Our post-processing class keeps previous chunk in memory (250 ms), so new chunk (also 250 ms) is appended to it. The resulting big chunk (500 ms) is split into num_steps overlapping windows, each 250 ms long;
- number of audio streams;
So batch size for streaming is num_steps * number of audio streams. Time between receiving new audio chunks and getting results is shown in picture:
| Batch size | Pytorch model time, ms | Onnx model time, ms |
|---|---|---|
| 2 | 9 | 2 |
| 4 | 11 | 4 |
| 8 | 14 | 7 |
| 16 | 19 | 12 |
| 40 | 36 | 29 |
| 80 | 64 | 55 |
| 120 | 96 | 85 |
| 200 | 157 | 137 |
Throughput
RTS (seconds of audio processed per second, real time speed, or 1 / RTF) for full audio processing depends on num_steps (see previous paragraph) and batch size (bigger is better).
| Batch size | num_steps | Pytorch model RTS | Onnx model RTS |
|---|---|---|---|
| 40 | 4 | 68 | 86 |
| 40 | 8 | 34 | 43 |
| 80 | 4 | 78 | 91 |
| 80 | 8 | 39 | 45 |
| 120 | 4 | 78 | 88 |
| 120 | 8 | 39 | 44 |
| 200 | 4 | 80 | 91 |
| 200 | 8 | 40 | 46 |
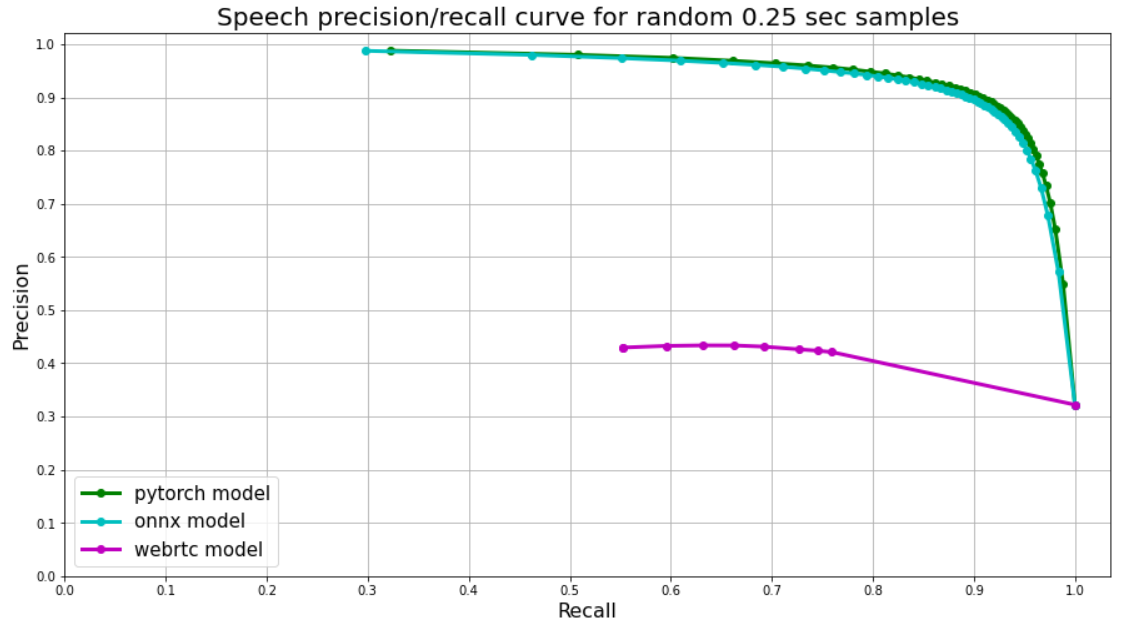
VAD Quality Benchmarks
We use random 250 ms audio chunks for validation. Speech to non-speech ratio among chunks is about ~50/50 (i.e. balanced). Speech chunks are sampled from real audios in four different languages (English, Russian, Spanish, German), then random background noise is added to some of them (~40%).
Since our VAD (only VAD, other networks are more flexible) was trained on chunks of the same length, model's output is just one float from 0 to 1 — speech probability. We use speech probabilities as thresholds for precision-recall curve. This can be extended to 100 — 150 ms. Less than 100 — 150 ms cannot be distinguished as speech with confidence.
Webrtc splits audio into frames, each frame has corresponding number (0 or 1). We use 30ms frames for webrtc, so each 250 ms chunk is split into 8 frames, their mean value is used as a treshold for plot.
