Comments 10
About use cases. In my project, a symbolic algebra library, I work with mathematical expressions. At the beginning of the project, I had method Evaluate(). Every time I called it I knew that it would take some time to process, so I wouldn't call it multiple times.
However, it's hard to track how many times it is called for an expression, there many methods, such as Simplify(), Solve() and many others which used this method. In fact, there were many cases when the same expression's Evaluate() was called.
With implementation of this pattern, I don't hesitate to address Evaluated property. This helps a lot when designing/developing new functional and makes the code faster and safer.
It really depends on the use cases. Personally, I would avoid introducing additional fields in types that are designed to be primitives. For instance, if I implement Int128 using 4 UInt32, the struct is 'blittable' and can be easily moved and copied in memory. Another important point is if for each instance of some type there may be several derived instances (like for each int you have 3 * int), the memory consumption of caching can explode if instances are distributed uniformly in some way (for int it means regular uniform distribution). If you have an array of YourInteger from 0 to 128, which you iterated over, cached and obtained Tripple, you have twice the memory footprint.
Perhaps the problem can be solved by some smart caching (e.g., depending on context), but I doubt there will be any benefit for small workloads (evaluating the same thing several times can be faster than doing all the fance caching). I can imagine that if you attempt to compute n terms of a series, and each term depends on, say, x, x^2, x^3, then for n > 10 (arbitrary limit) caching x^i could be beneficial.
Thank you for your answer. I should mention that here I consider a more or less high level of programming.
can be easily moved and copied in memory
Yes, that is a good point. But it is relevant for low-level programming. Also, struct is struct, here I'm talking more about records, which are reference types, and copying them by memory is… well, you know, unsafe and prohibited.
cached and obtained Tripple, you have twice the memory footprint.
If you address their Tripled property — yes, it is so. But you rarely need to process huge arrays of high-level objects (if you do, there might be something wrong with the architecture).
I can imagine that if you attempt to compute n terms of a series, and each term depends on, say, x, x^2, x^3, then for n > 10 (arbitrary limit) caching x^i could be beneficial.
You are about right, though the way it works in my case is that I frequently need the evaluated form of the same expression in many complicated methods.
So, the key point is: the pattern is more for immutable high-level objects rather than for super-fast calculations of primitive structures.
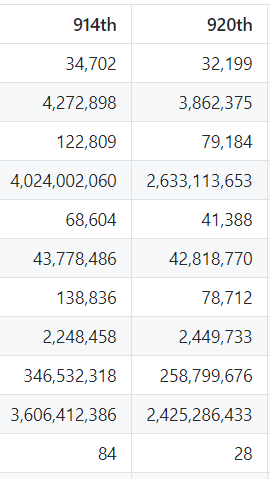
Then there is a very simple way to convince people that your approach is the best: take an example out of your domain (something that is more complicated than 3 * x) and benchmark naive computations vs caching on a typical workload size. The table you posted is not that informative to me, or perhaps I misread it. But a good summary table next to benchmarked code snippets will help a lot.
You need to be very cautious with mutable structs. Just a simple modification and the caching does not work:
public sealed record Number(int Value)
{
public int Tripled => Extract(this.tripled);
private int Extract(FieldCache<int> t)
=> t.GetValue(@this=> @this.Value * 3, this);
private FieldCache<int> tripled = new FieldCache<int>();
}public static void Main()
{
var n = new Number(7);
Console.WriteLine(n.Tripled);
Console.WriteLine(n.Tripled);
Console.WriteLine(n.Tripled);
}
...
value = factory(@this);
holder = @this;
Console.WriteLine("Factory");Output:
Factory
21
Factory
21
Factory
21I assume that the user knows the difference between value types and reference types. You can simply add ref to the argument's type to avoid this.
var n = new Number(7);
Console.WriteLine(n.Tripled);
Console.WriteLine(n.Tripled);
Console.WriteLine(n.Tripled);
public sealed record Number(int Value)
{
public int Tripled => Extract(ref this.tripled);
private int Extract(ref FieldCache<int> t)
=> t.GetValue(@this =>
{
Console.WriteLine("Factory");
return @this.Value * 3;
}, this);
private FieldCache<int> tripled;
}Factory
21
21
21By the way, since it's a struct, there is no need to initialize it. But in a case where you'd rather prefer an extra allocation over potential issues with copying the struct, you still can make it a reference type.
[Opinion] Lazy Properties Are Good. That Is How You Are to Use Them