Comments 178
А если мы применим немного матана?
Из пушки по воробьям. Это обычные двоичные дроби. Точно такие же как десятичные, но с основанием 2. Изучаются в 7-8 классе на информатике.

Что было бы интересно почитать, так это чем конкретно не подходят все перечисленные в "библиографии" альтернативы. Вроде ULID, например - он отлично подходит для ключей БД в том числе.
Кроме того, идея давать возможность разработчикам самим настраивать параметры - это просто совершенно лишний способ стрельбы себе в ногу (теперь - и ещё и для IDшек).
В общем, я Брэда уважаю, конечно, его Vugu штука интересная, но вот эта затея - странная.
Вроде ULID, например — он отлично подходит для ключей БД в том числе.
да, была статья на хабре:
https://habr.com/ru/company/ozontech/blog/564520/
задачи «получить timestamp из uuid» и «писать в горячую область индекса при добавлении новых записей» он решает не хуже.
UUIDv6 делает примерно то же что и ULID.
Главный момент заключается в том, что ULID это не стандарт. А тут народ не просто так играет. Они стандарты придумывают, чтобы всё было мягко и пушисто, прямо как по учебнику:

Нет, ну на самом деле, работа ведётся именно над RFC, а не холивор по поводу того, какой стандарт лучше.
UUIDv6 делает примерно то же что и ULID.
мда, действительно. и зачем нужны 100500 стандартов uuid с датой?
ULID это не RFC.
Да. Но что мешает его стандартизовать? Если он уже протестирован практикой, где-то работает и потихоньку движется к стандарту "де-факто", то почему не взять его и сделать стандартом "де-юре"?
Или в нем в процессе эксплуатации нашли какие-то проблемы в дизайне? Тогда это надо проанализировать и учесть в разработке нового стандарта.
в rfc4122 есть поля variant и version, в ulid они отсутствуют, на этих местах у него рандом.
на практике это может привести к тому, что, например, какое-то приложение распознает некий ulid как uuid v1 и начнёт извлекать оттуда время и мак-адрес, получит ерунду.
или (и, наверное, более вероятно) может сформироваться идентификатор с зарезервированными номерами версий и какое-то приложение посчитает этот uuid невалидным.
и то, и то, не особо вероятно, и, на мой взгляд, скорее является ошибкой приложений, но в качестве стандарта, очевидно, ulid не пройдёт.
также в нём есть слабое место с точки зрения безопасности: идентификаторы, сгенерированные на одной системе в пределах одной миллисекунды, будут иметь последовательные номера. впрочем, этот недостаток легко устраним.
А зачем получать дату создания записи и тем более сортировать по ней?
Когда ты пишешь данные в индекс базы, это может пригодиться.
Каким образом?
Ну говорю же, чтобы при записи большого количества данных не надо было раздувать индексы, потому что оные растут при увеличении разброса данных. А в данном случае этот разброс уменьшается.
Как раз наоборот, чем больше разброс, тем более равномерно распределены ключи, а следовательно дерево индекса имееет меньшую глубину и более плотное заполнение, а ребалансировка требуется реже.
нет-нет, @Nurkedвсё правильно пишет, что наиболее плотно ложатся в индекс, например, данные из последовательности (сиквенса). По крайней мере в Оракле, но, думаю, и в других СУБД тоже. Все дело в алгоритме деления блока. Если заполняется листовой блок в серединке, то он делится пополам (деление 50 на 50), а если это крайний блок, то просто добавится новый (хоть это деление часто называют 90 на 10, оно на самом деле 100 на 0). И таким образом, если мы будем писать разбросанные по индексу данные, то блоки будут не полностью заполнены. А если пишем из последовательности, то полностью.
Правда, на мой взгляд, разбросанность UUID – это, скорее, плюс, чтобы не получить задержки на записи в горячие блоки, при очень высоких нагрузках по записи. А платим мы за это местом на диске и худшей кэшируемостью этого индекса.
Самобалансирующиеся в-деревья всегда остаются немного недозаполненными, как бы вы их ни заполняли. Их заполненность растёт постепенно, пока не достигнет предела для данного уровня, после чего начинает заполняться следующий уровень.

Да, если заполнять их лишь с одной стороны, то будет небольшой перекос плотности именно в эту сторону. Но именно, что не большой. И он только замедляет поиск, хоть и не сильно.
когда вы вставляете с одной стороны, у вас образуется горячая область.
когда вы вставляете в рандомное место, у вас активность «размазывается» по всей таблице.
неужели нужно объяснять чем плох второй вариант? рассказывать, что хоть поиск/модификация индекса формально имеют логарифмическую сложность от числа записей, но его размер в лучшем случае растёт линейно; рисовать пирамиду latency/стоимости за мегабайт разных видов памяти…
Да, если только писать в базу, и ничего с ней больше не делать, эта горячая область всегда будет в кеше. Но в реальности обычно одновременно из базы ещё и читают по рандомным ключам, так что хвостик всё-равно постоянно вымывается. Однако, последовательная серия записей должна быть быстрее. С поправкой на то, что в этой "горячей" области будут постоянные ребалансировки из-за неравномерности распределения ключей.
Но в реальности обычно одновременно из базы ещё и читают по рандомным ключам, так что хвостик всё-равно постоянно вымывается
вы неправы. не встречал ещё ни одной большой БД, в которой активность обращений к данным из разных периодов времени была бы одинаковой.
Бывает, конечно, разная специфика. Но кейс с базой из которой читают только то, что вот только-только записали, кажется очень уж специфическим.
Но кейс с базой из которой читают только то, что вот только-только записали
нет, конечно же, речь не про это.
обычно есть период времени, обращение к которому более активны. скажем, у вас есть база операций по карте. сегодняшние операции люди смотрят часто, недельной давности тоже достаточно часто, месячной уже реже, полугодовой ещё реже, и т. д.
в случае рандомного uuid данные за последнюю неделю будут «размазаны» по всему индексу, в случае же упорядочненного они будут размещены компактно.
в первом случае мы не сможем эффективно работать с индексом, не помещающимся в оперативную память.
Ну вот, кстати, обратите внимание, что операции по карте попадают в базу сильно не в порядке их совершения пользователем (и порой с задержкой в неделю-другую). Более того, операции от одного человека почти никогда не попадают в базу по порядку. С довольно высокой вероятностью операции человека за неделю будут распределены по довольно большому участку хранилища. А за месяц - ни о каких кешах можно даже не мечтать.
Ваша ссылка про B-деревья, а я писал про B*-деревья в Оракле, они устроены несколько по-другому. И я опять же предполагаю, что и в других РСУБД реализация ближе к оракловой, чем к классическому B-дереву. Если кто знает точно, напишите, пожалуйста. В Оракле действительно есть параметр PCTFREE, который говорит, сколько свободного места оставлять в листовых блоках при инсертах, для будущих апдейтов. При PCTFREE=10 листовые блоки будут заполняться на 90%. И можно выставить PCTFREE=0, если мы точно знаем, что апдейтов не будет.
А про плотность заполнения можно провести следующий эксперимент. Сделать табличку с одним индексированным полем, и заполнять его из последовательности (сиквенса). Вставить, например, миллион записей. Посмотреть, сколько места занимает индекс, потом его перестроить, что перепишет записи плотно, и убедиться, что он занимает столько же места, сколько и до этого.
А потом провести тот же эксперимент с UUID-полем (в Оракле это будет raw(16)), и мы увидим, что после перестроения индекс уменьшится примерно на четверть, или на треть. Потому что на этот раз записи будут лежать плотно. Но это не естественное состояние для индекса по UUID, и при последующих вставках он вернется к своему нормальному состоянию, когда блоки не до конца заполнены.
B* мало чем от отличается от B, только алгоритм чуть сложнее (а значит медленнее), но узлы реже сплитятся, ибо плотнее заполняются, но и ребалансировка происходит чаще.
В B*-дереве вообще нет ребалансировки. Есть алгоритм деления блоков, который поддерживает дерево сбалансированным. Что если переполнился листовой блок в середине, делим 50 на 50, а на краю – 100 на 0. И в каких-то случаях это будет приводить к делению бранч-блока (или даже нескольких по цепочке), а это в свою очередь иногда будет приводить к делению корневого блока, и созданию нового. Деление корневого блока – единственный случай, когда высота B*-дерева растет.
Это и называется ребалансировка. Причём у В* их 2 вида:
перераспределение ключей между узлами без изменения структуры дерева
изменение структуры дерева
не, в B*-дереве ключи могут переехать в другой блок только при делении листового блока, то есть по вашей классификации при изменении структуры дерева.
As the most costly part of operation of inserting the node in B-tree is splitting the node, B*-trees are created to postpone splitting operation as long as they can.[14] To maintain this, instead of immediately splitting up a node when it gets full, its keys are shared with a node next to it. This spill operation is less costly to do than split, because it requires only shifting the keys between existing nodes, not allocating memory for a new one.
Да, но проблема в физике: при вставке придется идти в кучу мест на диске, расширять блоки. При этом это вызовет дополнительные чтения с диска, т.к. надо найти место куда вставлять данные, скорее всего это не попадет в кеш (если таблица довольно большая).
При запросах тоже часто приходится запрашивать последние данные (горячие). В случае если добавление в индекс идет только с одной стороны горячие данные лежат рядом, как следствие с большей вероятностью попадут в кеш и не будут оттуда вымыты.
Если ключи распределены равномерно - в некоторых случаях сделать больше чтений. Например если индекс кластерный, данные тоже будут распределены равномерно по диску, а с учетом того что читается сразу блок данных, это приводит к read amplification.
Далее, если положить рядом много одинаковых данных, некоторые БД умеют эти данные очень хорошо сжимать (см clickhouse). Индексы тоже получатся более компактными, что приведет к более быстрому поиску. В общем тут разве что возникает вопрос - почему в UUID изначально не был спроектирован с использованием человеческого unix timestampt
при вставке придется идти в кучу мест на диске, расширять блоки.
Расширять блоки при равномерной записи придётся как раз куда реже за счёт естественной сбалансированности.
если положить рядом много одинаковых данных, некоторые БД умеют эти данные очень хорошо сжимать (см clickhouse).
И часто вы пишете последовательно одинаковые данные? Кликхаус - колоночная бд со своей очень специфичной областью применения.
Расширять блоки при равномерной записи придётся как раз куда реже за счёт естественной сбалансированности.
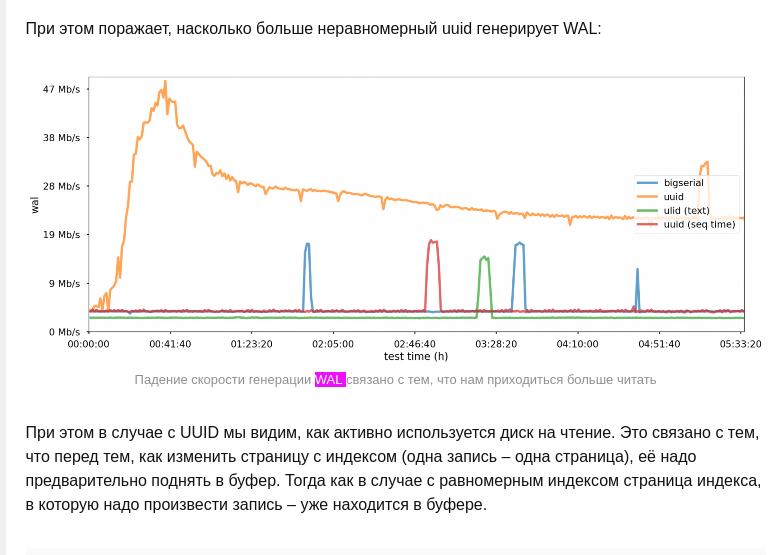
Подтвержено чем? Вот тут бенчмарк с графиками https://habr.com/ru/company/ozontech/blog/564520/. Условно WAL - количество измененных данных
скриншот
Не верим этой статье - пожалуйста, другая: https://habr.com/ru/post/316036/
скриншот
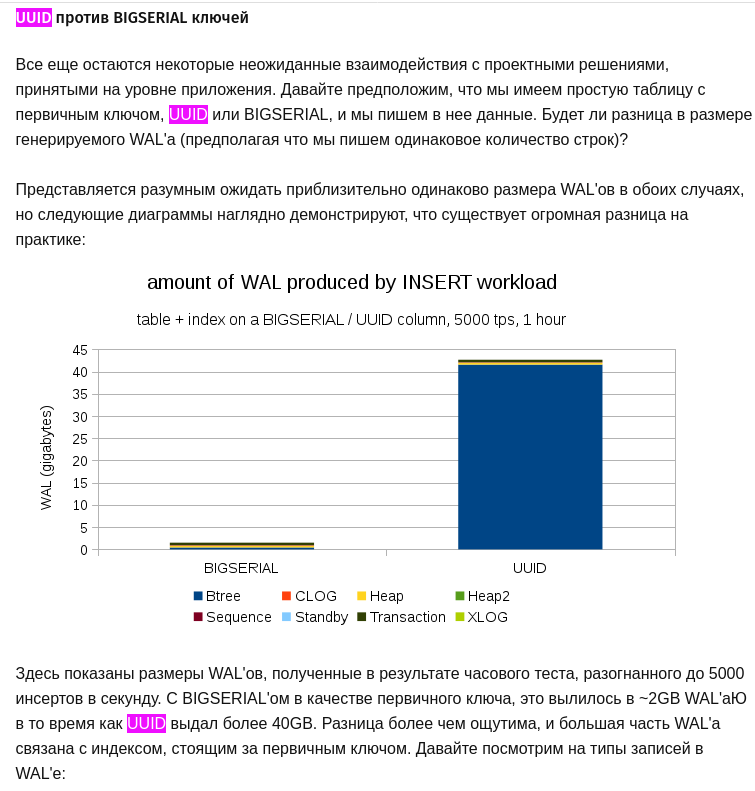
И часто вы пишете последовательно одинаковые данные?
Зависит от сценария. Но суть том не в ток как часто пишу я, а в том как часто пишет его БД. В случае последовательного uuid будет писать часто, в результате оверхед от хранения первых байт UUID в индексе может быть меньше.
Ваши скриншоты так-то ничего не говорят про частоту разделения блоков.
Размер WAL с размером индексов слабо коррелирует. Ну и да, в посгре WAL не особо оптимален, так что он сам по себе тот ещё источник тормозов.
UUID - 16 байт, BigSerial - 8.
Не говорил про разделение блоков, скорее расширение. У вас же не всегда есть место для новой записи. То есть при вставке все равно приходится раздвигать текущие блоки. (или менять ссылку если реализация на связном списке, что врядли используется для индексов, т.к. в индексе по своей похожие данные должны лежать рядом). Что приводит к увеличению записи. Плюс есть детали имплементации на всяких системах (wal, etc). Есть факт что не UUID без инкрементальной составляющей это боль и тормоза на большинстве систем.
Размер WAL с размером индексов слабо коррелирует. Ну и да, в посгре WAL не особо оптимален, так что он сам по себе тот ещё источник тормозов.
Ок, пример из mysql https://www.percona.com/blog/2014/12/19/store-uuid-optimized-way/
скриншот

For the table with UUID as PRIMARY KEY, you can notice that as the table grows big, the time taken to insert rows is increasing almost linearly. Whereas for other tables, the time taken is almost constant.
The size of the UUID table is almost 50% bigger than Ordered UUID table and 30% bigger than the table with BIGINT as PRIMARY KEY. Comparing the Ordered UUID table BIGINT table, the time is taken to insert rows and the size are almost the same. But they may vary slightly based on the index structure.
А, недопонял. Ну WAL от числа изменившихся блоков зависит, конечно. Влияние именно расширения тут сложно оценить.
UUIDv1 - это за гранью добра и зла.) А как у них там получилось, что индекс по 16-байтному (пусть и упорядоченному) UUID оказался меньше 8-байтного BIgInt?
как у них там получилось, что индекс по 16-байтному (пусть и упорядоченному) UUID оказался меньше 8-байтного BIgInt?
Сам удивился и залип пытаясь понять. В общем они используют bigint(20) для primary key и id binary(16) для UUID. Из за того что в mysql primary key кластеризован и вторичные индексы указывают на primary key примерно так и выходит.
Размер индексов это вторичных, т.к. первичный это и есть сама таблица.
этих
KEY index_events_on_actioned_at (actioned_at),
KEY index_events_unit_demand_partner (unit_id,demand_partner_id)
---
upd, наврал. bigint(20) все так же занимает 8 байт. Проблема в том что в этом тесте для Bigint есть лишний индекс: primary - count (bigint), плюс индекс на поле id.
PRIMARY KEY (
count),
KEYid(id),
обычно данные добавляются в порядке их генерации, т.е., в таблице дата создания обычно хорошо коррелирует с физическим адресом строки. Такая корреляция очень сильно облегчает поиск по индексу.
Тут недавно статья была, рекламирующая ulid на примере btree-индекса для postgresql. Не могу согласиться с идеей использования ulid (нестандартный тип => хреновая поддержка в библиотеках), но доводы про индекс там правильные.
С другой стороны, как мне кажется, более старые версии uuid-ов, основанных на дате, тоже должны давать неплохую корреляцию: всё-таки, как правило, достаточно кусочно-локальной корелляции. Если говорить о данных за большой период, то перемешивание части бит не должно играть большой роли. В крайнем случае, можно для postgresql написать поддержку перемешивания бит так, чтобы повысить корреляцию.
обычно данные добавляются в порядке их генерации
Крайне не надёжное и неявное предположение. Особенно в распределённой системе, где у каждого узла своё время на часах.
в таблице дата создания обычно хорошо коррелирует с физическим адресом строки. Такая корреляция очень сильно облегчает поиск по индексу.
Корреляция в лучшем случае может помочь при бинарном поиске физического адреса без индекса. Но куда проще и быстрее использовать какой-нибудь вариант б-дерева в виде индекса, которому от этой корреляции ни тепло, ни холодно.
Тут недавно статья была, рекламирующая ulid на примере btree-индекса для postgresql.
Вы про эту? На сколько я понял там оценивается последовательный проход по индексу. Ну да, индекс, который совпадает с физическим положением, будет работать быстрее и меньше засирать кеш. Но обычно клиенту нужны сортировки не связанные с физическим расположением данных: по дате изменения, по алфавиту и тд. Да и физическое положение для мутабельных данных может меняться без изменения ключа.
Кстати, не стоит забывать, что чем больше корреляция, тем больше вероятность совпадения идентификаторов.
Например, для UUIDv4 (128 бит) при вероятности получить коллизию не превышающей вероятность некорректируемого сбоя жёсткого диска можно спокойно нагенерить 10^12 идентификаторов, чего как правило хватает с головой.
В описанном в статье же UUIDv7 56 бит рандома позволяют нагенерить лишь порядка десятка идентификаторов при тех же условиях. Да, за 1 нс, на одном из 64 узлов. Но это, блин, почти половина всех бит идентификатора, которые с тем же успехом можно заменить четырёхбитовым счётчиком.
Насколько я понял там оценивается последовательный проход по индексу.
нет же, там оценивается и скорость вставки в таблицу.
Крайне не надёжное и неявное предположение. Особенно в распределённой системе, где у каждого узла своё время на часах.
синхронизация времени давно придумана же. и да, небольшая рассинхронизация не особо вредит.
Для единичной выборки можно пройтись в любой блок, это не важно. Хотя при нагрузке подобное отсутствие корелляции приведёт к забиванию буферов БД, т.к. индекс придётся в памяти целиком держать (а не только горячую его часть). Нередко надо отобрать тысячу...десяток тысяч записей по индексу и в этом случае прыгать по произвольным местам в индексе уже не столь приятно (заметно дороже, чем в индексе с нормальным распределением).
Еще есть такая штука как merge join. Это когда надо соединить две выборки не по индексу, при чём обе выборки достаточно большие (и тут вариант хеширования одной из выборок не подойдёт). В этом случае обе выборки сортируются и производится единичный проход по обеим выборкам с одновременным их соединением и отбросом строк, которые нельзя соединить. Для больших выборок - это самый быстрый путь. Так вот, при наличии B-tree индекса, можно сделать выборку из индекса, получив сразу отсортированные данные, но если позиции в индексе не кореллируют с физическим положением, это заметно понизит производительность такого варианта.
Что касается уменьшения числа битов рандома, я не понял, когда вероятность некорректируемого сбоя жесткого диска стала мерилом, к которому следует стремиться? Впрочем, меня больше всего интересует другое: вас что силком заставляют использовать удобный кому-то UUID? Генерируйте в своём проекте так, как вам удобно. Если UUID-ы генерируются на клиентских машинах, действительно, имеет смысл использовать UUIDv4. Если UUID-ы генерируются на паре серверов, почему бы не использовать более удобный для быстрого поиска вариант?
индекс придётся в памяти целиком держать (а не только горячую его часть).
Самая "горячая" часть любого индекса при чтении - около корня, а не у хвоста. Она постоянно будет в кеше, что позволяет гарантированно очень быстро перепрыгивать часть пути при поиске.
При разбалансировке запросы "не туда" мало того, что буду медленнее, чем при равномерной нагрузке, так ещё и всё равно будут периодически вымывать кеш из под хвоста.
Условно, в первом случае вы получаете стабильно 15 быстрых прыжков и 5 медленных, а во втором то 5 быстрых и 15 медленных, то 15 быстрых и 5 медленных. Конкретные цифры, конечно, сильно зависят от частоты запросов "не туда". Но чтобы разбалансировка давала больше пользы, чем вреда, разница должна быть на порядки.
Индекс поднимается в память блоками. И проблема не в том, что некоторые запросы будут приводить к чтению с диска, проблема в том, что прочитанные блоки (а в каждом из них будет не только один наш узел, но и еще десяток) помещаются в буфер, вытесняя от туда какие-то другие данные. Когда индекс занимает 5гб и больше, следующие два варианта очень сильно отличаются в плане потребления ресурсов сервера:
в памяти сидит корень + кусочек данных индекса, относящихся к строкам, добавленным за последнюю неделю (и все запросы идут через кеш, потому что подняв сотню блоков единожды мы суммарно подняли 1000 горячих записей)
в памяти сидит корень и 100500 блоков, в каждом из которых по 1 записи горячих данных, а к остальным не было ни одного обращения, но они занимают память, т.к. в том-же блоке есть запись, которая была в горячей зоне
Что касается уменьшения числа битов рандома, я не понял, когда вероятность некорректируемого сбоя жесткого диска стала мерилом, к которому следует стремиться?
Не стремиться, а который нет смысла превышать. Ну то есть можно обеспечить вероятность коллизии и меньше, за счёт увеличения длины идентификатора или сокращения числа возможных значений. Но какой в этом смысл, если с большей вероятностью данные повредятся самостоятельно непредсказуемым образом?
Обычно в большинстве систем после генерации uuid-а есть возможность организовать процесс проверки того, что он действительно уникален. В худшем случае упадёт транзакция и можно будет повторить всё заново, повторно сгенерировав uuid. Разница между тем, будет это происходить раз в месяц или раз в пару лет, в общем-то небольшая, если, конечно, мы не о системах с адской ценой одной ошибки говорим, а значит, уменьшение энтропии не сильно скажется на большинстве систем (учитывая то, что мы будем искать коллизии которые попадут в одну долю секунды).
Обычно в большинстве систем после генерации uuid-а есть возможность организовать процесс проверки того, что он действительно уникален.
в этом случае и нет особого смысла в uuid (или guid как его называет ms).
весь смысл этого идентификатора в том, что он глобально-уникальный, и мы можем быть уверены, что взяв uuid разных сущностей мы получим уникальные значения, будь то uuid файловой системы, uuid банковской транзакции, uuid товара в учётной системы.
Это имеет реальное значение только с того момента, когда мы все такие объекты попытаемся положить в одну информационную систему.
Для информационных систем гораздо важнее другое свойство - можно сгенерировать UUID-ы на целой куче разных устройств и относительно безопасно положить в единое хранилище (и коллизии появятся в пренебрежимо малом количестве случаев).
Для информационных систем гораздо важнее другое свойство — можно сгенерировать UUID-ы на целой куче разных устройств и относительно безопасно положить в единое хранилище (и коллизии появятся в пренебрежимо малом количестве случаев).
представляете, в 2021 году тоже бывает оффлайн, поэтому «в худшем случае упадёт транзакция и можно будет повторить всё заново» — не решение.
Но какой в этом смысл, если с большей вероятностью данные повредятся самостоятельно непредсказуемым образом?
мне кажется, что вас не в ту степь понесло. любое хранилище контрольными суммами и достаточной степенью избыточности (ceph, zfs) фактически сводит к нулю потери/искажения данных из-за «некорректируемого сбоя жесткого диска».
Думаю, настройку этих параметров нужно тоже оставить для UUIDv8. Надеюсь, скоро появится расширение для постгреса, но и сейчас вроде можно сортировать как строки или числа, просто генерировать не в базе. Раньше приходилось парсить для сортировки.
Сам RFC который мы разрабатываем, включает в себя все три версии. Мы как раз сейчас в стадии "каждый пишет один супербольшой коммент, и все сидят и думают".
На данный момент предполагается что можно будет использовать значение поля variant для того, чтобы отличать несколько разных версий UUIDv7, в каждой из которых будет чётко установленное количество бит точности.
Лучше б добавили в RFC строчку "Не распарси uuid соседа своего".
В смысле, правила генерации uuid задать можно, но любые попытки закладываться на что-то кроме его уникальности стОит пресекать. Нужна дата – храни дату, не uuid.
Я одно время плотно игрался с подобной темой.
В итоге пришел к такому — либо быстро и с коллизиям (причем я их реально постоянно ловил в тестах), либо долго и/или длинно и избыточно (не влезаем в 64 бита). В итоге проще и быстрее оказалось просто тупо генерить 64 битные случайные ID, а дату таки хранить в отдельной колонке.
В итоге пришел к такому — либо быстро и с коллизиям (причем я их реально постоянно ловил в тестах), либо долго и/или длинно и избыточно (не влезаем в 64 бита).
uuid 128-битный
А какой в этом смысл?
Ну т.е. какой профит я получу, если заменю 64 битный гарантированно уникальный ID, работающий на 64 битной архитектуре, на 128 битный (про ненужную избыточность я пока не спрашиваю)?
мне нравится идея uuid — это такой уникальный идентификатор, в котором не нужно сомневаться. при этом есть несколько вариантов генерации uuid, но прелесть в том, что читателю об этом не нужно задумываться.
по мере набивания шишок пришли к тому, что самым универсальным является uuidv4, так что на сегодня бест практис — это использовать его.
но у рандомного идентификатора есть проблема с btree, которая упоминалась, например в этой статье.
так что я вижу два подхода:
- включаем в uuid таймстамп чтобы у нас нормально работали индексы btree; да, энтропия падает, но длина uuid позволяет это пережить;
- включаем в uuid таймстамп чтобы использовать его и как таймстамп тоже.
первый пункт вызывает у меня полную поддержку, второй с одной стороны привлекает, но кажется потенциально граблесобирательным.
вот если бы изначально сделали так, что любой формат uuid имеет таймстамп в первых 36 битах — это было бы круто, но…
Мне не очень нравится идея делать огромный первичный ключ ради того чтобы он был одновременно последовательным и гарантированно уникальным.
Делались ли тесты на тему реального быстродействия и потребления памяти/cpu?
Да, результаты тестов можно посмотреть здесь: https://github.com/Sofya2003/ULID-with-sequence#benchmarks-of-sequential-uuid
Хотелось бы сравнения с полностью рандомным и не последовательным первичным ключом :) Чтобы оценить, какой реальный профит можно получить от этого.
И меня все еще смущает 64 бит vs 128 бит на ключ. А первичные ключи, насколько помню, всегда в оперативе лежат.
А первичные ключи, насколько помню, всегда в оперативе лежат.
странное заявление. а если размер первичных ключей больше объёма памяти?
Вроде, делали какой-то бенчмарк на postgresql, существенной разницы, которая бы мешала использовать uuid вместо bigint, не нашли. Ну да, лишних 8 байт на каждую запись, это гораздо меньше чем существующий оверхед на каждую строчку. Ссылку не подскажу, давно было.
По поводу первичных ключей и оперативы - это в какой СУБД такое? InMemory БД всё хранят в памяти, традиционные реляционки хранят кеш с горячими данными (и это не обязательно PK)
это гораздо меньше чем существующий оверхед на каждую строчку
Какой именно оверхед? Речь про btree, обсуждаемое выше?
это в какой СУБД такое
Я чуть выше ответил. Сейчас попробую поискать первоисточник, но сомневаюсь.
Я писал именно о физическом хранении. В PostgreSQL служебные данные по каждой строчке занимают более 23 байт на строку + есть небольшой дополнительный оверхед на каждый блок (размер блока - 8кб по умолчанию). Обсуждаемые выше проблемы из-за рандомного uuid-а
- это уже более высокоуровневая проблема.
1) Я считаю, что количество битов для суб-секундной точности должно определяться автоматически - исходя из точности системных часов, независимо от точности сигналов синхронизации. Количество битов счетчика также должно определяться автоматически. Чем точнее системные часы, тем меньше нужно битов счетчика. С другой стороны, чем больше идентификаторов в миллисекунду может быть создано данным компьютером, тем больше должно быть битов счетчика.
Если недоступны данные для автоматического расчета длины субсекундной части идентификатора и длины счетчика, то необходимые данные должны браться из параметров, передаваемых программно (программистом) в функцию генерации идентификатора. Если же нет и значений параметров, то должны браться значения точности по умолчанию: 1 миллисекунда и 15 битов для счетчика. См. https://github.com/Sofya2003/ULID-with-sequence
Если в результате перевода системных часов назад по сигналу синхронизации происходит повторная генерация идентификаторов в формально те же интервалы времени, то стойкость к коллизиям должна обеспечиваться случайной частью идентификатора, но монотонное возрастание идентификаторов не гарантируется. Из-за этого сгенерированный идентификатор не может служить кластерным индексом, и возможно незначительное замедление поиска в базе данных.
2) Чтобы генерация идентификаторов была мгновенной, она должна обеспечиваться непосредственно стандартными средствами СУБД/ORM (если идентификатор генерится на сервере) или JavaScript/WebAssembly (если идентификатор генерится на клиенте), но не на сервере приложений (для разных языков программирования). Поэтому нет смысла разрабатывать функции генерации UUIDv7 для огромного множества языков программирования, как это было сделано для ULID. В СУБД для UUIDv7 должны быть предусмотрены специальный бинарный тип данных, обеспечивающий быстрый поиск, а также функции для преобразования из/в строковые форматы UUID (c дефисами) и ULID (без дефисов, в кодировке Crockford's base32). Для использования в URL и для всех новых разработок строковый формат ULID должен быть предпочтительным. Строковый формат UUID нужен для обратной совместимости.
3) Еще я бы выкинул ver и var из стандарта, поскольку совершенно непонятна их роль, кроме обеспечения пресловутой совместимости с древним и непригодным для ключа БД стандартом. Ведь сами по себе идентификаторы, сгенерированные по разным стандартам, и без того совместимы, так как имеют одинаковую длину и имеют ничтожную вероятность коллизий.
4) Парсинг идентификаторов я считаю совершенно неприемлемым. Ведь если идентификаторы будут использоваться для извлечения из них какой-либо бизнес-информации, то при изменении этой бизнес-информации (например, при исправлении ошибки) потребуется хранение нескольких версий одного и того же идентификатора, что приведет к усложнению информационной системы. Поэтому не должно быть никаких стандартных функций парсинга и никаких точных данных о структуре конкретного идентификатора. Дата создания записи должна храниться в отдельном поле, а не извлекаться из идентификатора. В то же время, поскольку идентификаторы задуманы как сортируемые, то начальная часть идентификатора произвольной длины может быть использована для шардинга.
5) Использование квантово-механического аппаратного генератора случайных чисел, а при его отсутствии CSPRNG (криптографически стойкого генератора псевдослучайных чисел) должно быть безусловным требованием стандарта UUIDv7.
6) Идентификатор компьютера Node должен быть опциональным.
А криптографию-то зачем форсировать? Она так-то весьма не бесплатна. Даже для nonce она совсем не нужна.
Если в результате перевода системных часов назад по сигналу синхронизации происходит повторная генерация идентификаторов в формально те же интервалы времени, то стойкость к коллизиям обеспечивается лишь случайной частью идентификатора. Если же в такой ситуации псевдо-случайная часть идентификатора не будет криптографически-стойкой, то коллизии (дублирование) идентификаторов вполне возможны (при повторном запуске генератора псевдо-случайных чисел), а это закончится крахом приложения. Если несколько раз запустить приложение с установкой системных часов на одно и то же время и созданием записи с идентификатором, то крах приложения вообще неизбежен.
Проблема в том, что генераторы псевдослучайных чисел, кроме CSPRNG, генерят одну и туже последовательность при каждом запуске.
Я вообще не вижу существенных аргументов против CSPRNG. Так из 6 генераторов ULID для PostgreSQL только один не использует CSPRNG: https://github.com/sergeyprokhorenko/pg_ulid_comparison
В Python теперь считается предпочтительным использование нового криптографически стойкого модуля secrets вместо модуля random: https://docs-python.ru/standart-library/modul-secrets-python/
генераторы псевдослучайных чисел, кроме CSPRNG, генерят одну и туже последовательность при каждом запуске.
Нет, конечно, они при каждом запуске инициализируются случайным зерном.
Я вообще не вижу существенных аргументов против CSPRNG.
"Случайное" зерно тоже на самом деле псевдослучайное, и не гарантирует отсутствие повторов последовательностей после перезагрузок, инициализаций, синхронизаций и т.п. Если же зерно истинно случайное, то мы уже имеем дело с CSPRNG, как бы не назывался модуль генерации случайных чисел.
Если в JavaScript криптомодуль медленный, то значит для генерации идентификаторов на клиенте этого достаточно, либо этот криптомодуль нужно оптимизировать. Но это не повод пренебрегать надежностью и безопасностью. Node.js я не беру в расчет, так как на сервере идентификаторы UUIDv7 должны генериться непосредственно в СУБД.
Для зерна обычно используется системный источник энтропии. Обратите внимание на букву P в CSPRNG - это тот же псевдорандом, но с дополнительными гарантиями невозможности быстро вычислить новое значение по серии предыдущих.
Основная польза от гуидов как раз в возможности их генерации на клиенте. На сервере-то они не особо нужны - достаточно обычного монотонного счётчика и идентификатора узла.
Ну вот практическая задача: делаем мы свой гугл-докс, пользователь вставляет портянку текста на десятки-сотни страниц. Надо пройтись по всем словам, и для каждого сгенерировать уникальный идентификатор, не конфликтующий с другими пользователями. И сделать это надо как можно быстрее. Это десятки миллисекунд разницы только на генерации идентификаторов.
Пусть в стандарте будет требование CSPRNG. Если модуль в JavaScript не назван криптостойким, но по сути (благодаря зерну) выполняет его функции, то это CSPRNG, и он соответствует такому стандарту. Если другой модуль в JavaScript назван криптостойким, но делает то же самое, что и первый, в 10 раз медленнее, то и не будем его применять.

https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Math/random
Неужели так сложно принять, что криптостойкость никак с зерном не связана? Чего вы чушь-то несёте?
"Случайное" зерно тоже на самом деле псевдослучайное, и не гарантирует отсутствие повторов последовательностей после перезагрузок, инициализаций, синхронизаций и т.п.
Для данного конкретного случая (UUIDv7) это несущественно, потому что есть временная метка, чтобы они начались повторяться нужно выполнение двух условий — сбой системного времени с одновременным сбросом зерна ровно в то же самое состояние в котором оно было в тот самый момент времени, а это уже очень маловероятно.
Плюс, если у нас нет "железного" генератора, зерно можно сделать очень близким к "истинно случайному", например, если собирать по одному биту из TSC после каждого syscall, не говоря уже о других источниках — время выполнения чего угодно что связано с железом (не только ввод-вывод но и все процессы инициализации в процессе загрузки системы) — в этом случае вероятность того что к моменту начала использовалия CSPRNG оно будет ровно в том же состоянии что было когда-то будет стремиться к нулю (при достаточном размере, разумеется).
Но это не повод пренебрегать надежностью и безопасностью.
До тех пор пока зерно не покидает место генерации и тот-кому-не-нужно не имеет к нему доступа — риск стремится к нулю, разумеется, при использовании "правильного" CSPRNG. Грубо говоря, если у вас есть хороший CSPRNG в сейфе из вибраниума, и совсем неслучайное (но неизвестное) зерно — то результат с практической точки зрения не отличается от "истинно случайного". Если можете привести ссылку на работу которая это опровергает — буду признателен, я таковых не нашёл.
Я за CSPRNG в стандарте. Вы тоже за CSPRNG. О чем тогда спорим?
сбой системного времени с одновременным сбросом зерна ровно в то же самое состояние в котором оно было в тот самый момент времени, а это уже очень маловероятно.
Если в качестве зерна используется timestamp, то вероятность уже не такая маленькая.
зерно можно сделать очень близким к «истинно случайному», например, если собирать по одному биту из TSC после каждого syscall
Вот только в js, Math.random() не позволяет задать зерно самостоятельно. И как оно там должно быть реализовано внутри — стандарт, насколько мне известно, не уточняет.
Если в качестве зерна используется timestamp
Это очень плохая идея, зачем её обсуждать?
на сервере идентификаторы UUIDv7 должны генериться непосредственно в СУБД.
Только если у нас вся логика написана на хранимых процедурах, и нет отдельного серверного приложения. Если же за логику отвечает отдельное приложение, а СУБД — только хранилище, то любые, автоматически генерируемые в СУБД значения (ключи, даты и т.д.) — это антипаттерн, т.к. без фактической вставки в БД, сервис не сможет получить значение этих полей, а значит он не может сам, без участия СУБД, сконструировать новый объект. Можно, конечно, заранее запросить у СУБД пул идентификаторов. Последнее имеет смысл, например, для целочисленных ключей, которые просто генерируются по порядку. Запрашивать их у СУБД приходится, чтобы гарантировать их уникальность. Но как раз для UUID'ов это бессмысленно — они и так достаточно уникальны. Собственно, в этом основной плюс UUID'ов, что мы генерируем идентификаторы там, где нам удобно, с точки зрения нашей архитектуры, в том числе, можем генерировать их децентрализовано.
Если же за логику отвечает отдельное приложение, а СУБД — только хранилище, то любые, автоматически генерируемые в СУБД значения (ключи, даты и т.д.) — это антипаттерн, т.к. без фактической вставки в БД, сервис не сможет получить значение этих полей, а значит он не может сам, без участия СУБД, сконструировать новый объект
Ну так по сути объект существует только с того момента, как он записан в БД, так что не понимаю почему вы считаете это антипаттерном
И если у нас используются b-tree индекс по uuid (а обычно он и используются), и, особенно, если этот индекс кластеризован (что тоже весьма часто случается), то отсутствие монотонности может ощутимо негативно влиять на производительность.
Собственно, в этом основной плюс UUID'ов, что мы генерируем идентификаторы там, где нам удобно, с точки зрения нашей архитектуры, в том числе, можем генерировать их децентрализовано.
Вот тут соглашусь.
Ну так по сути объект существует только с того момента, как он записан в БД
В общем случае это не так. К примеру, у нас могут быть и такие объекты, которые существуют временно, в каком-нибудь словаре, а решение об их сохранении в репозиторий может приниматься позднее. Разумеется, можно придумать и другие примеры.
Но вообще, даже если в нашей системе, для всех клиентов, каждый объект «существует» только если он уже записан в БД, то для самого сервера, это условие всё равно не выполняется. Для сервера, создание объекта и сохранение его в репозиторий — это две разные операции. Помимо них, он должен ещё много чего делать, например логирование, кэширование, ответ клиенту и т.д. Для каких-то операций может быть нужно, чтобы объект уже лежал в базе. Для других, достаточно, чтобы он просто был создан. А учитывая, что запись в БД гораздо медленнее создания объекта в памяти, то пренебрегать этим неразумно.
Серверу, как правило, удобнее предоставлять клиентам «оптимистичный» API. Зачем нам ждать запись объекта в базу, если можно сразу вернуть клиенту ответ. Вот только в этом ответе, клиенту уже нужен id.
Перекладывание задачи по генерации некоторых полей на СУБД, размазывает серверную логику, между приложением и СУБД. Изначально, автогенерация, а так же хранимые процедуры и триггеры были добавлены в СУБД, чтобы была возможность обходиться без серверного приложения. Роль серверного приложения, в таком случае, берёт на себя СУБД. Если же у нас есть сервис, который предоставляет Web API для доступа к данным, а все остальные работают через него, то необходимость во всех этих наворотах отпадает, и самым разумным решением будет свести их использование к минимуму, а то и вовсе отказаться от них, чтобы не размазывать логику. Иногда, правда, подразумевается, что помимо приложения, с БД будут работать и люди, напрямую. В этом случае, нет нужды смешивать интерфейс для людей и для программы. Приложение может иметь полный доступ к таблицам, а люди — пользоваться хранимыми процедурами, через которые будет реализован контроль доступа для них. Единственный необходимый компромисс, в случае, если люди имеют возможность вносить изменения в базу напрямую — контроль целостности придётся по максимуму вынести в СУБД.
Есть ещё один важный аспект. Если логика размазана между СУБД и приложением, например, часть полей генерируется в СУБД, это, по сути, привязывает нас к модели разработки Data First, ведь без базы данных наш сервис становится инвалидом. Если же всё генерируется в приложении, то это развязывает нам руки — тут уже применимы как Data First, так и Code First.
Ну и в конце концов, независимость приложения от БД упрощает его тестирование.
Наверняка есть и ещё нюансы. Это всё, что пока пришло в голову.
отсутствие монотонности может ощутимо негативно влиять на производительность
Монотонность зависит от типа ключа, а не от того, кто его генерирует, будь то СУБД, серверное приложение, или клиенты. Другое дело, что если генерировать ключи будут клиенты, то монотонности добиться сложнее. Но обсуждаемый в статье UUID v7 как раз и решает эту задачу, т.к. является последовательным.
3) Еще я бы выкинул ver и var из стандарта, поскольку совершенно непонятна их роль, кроме обеспечения пресловутой совместимости с древним и непригодным для ключа БД стандартом. Ведь сами по себе идентификаторы, сгенерированные по разным стандартам, и без того совместимы, так как имеют одинаковую длину и имеют ничтожную вероятность коллизий.
это если мы их используем как идентификаторы. если мы пытаемся вытащить из них дополнительную информацию (тот же тиместамп), то нет совместимости.
Я уже писал выше, почему лучше не извлекать никакие бизнес-данные (в том числе, timestamp) из идентификатора. В таблицах связей (в транзакционных таблицах, в витринах данных), в которых первичный ключ состоит из нескольких UUID связанных таблиц, в любом случае необходимо отдельное поле с датой создания записи. Идентификатор должен иметь только две функции: быть глобально уникальным (чтобы быть первичным ключом или его частью - в таблицах связей) и быть по возможности монотонно возрастающим (чтобы поиск в базе данных был быстрым).
Я уже писал выше, почему лучше не извлекать никакие бизнес-данные (в том числе, timestamp) из идентификатора.
вопрос в том, что (наверное) уже есть какие-то приложения, которые так делают. и они могут пытаться извлекать данные оттуда, где их нет.
поэтому я бы использовал ver/var от uuidv4, чтобы точно этой проблемы не было.
потеря 6 бит немного ранит чувство прекрасного, но с практической точки зрения она несущественна.
Идентификатор должен иметь только две функции: быть глобально уникальным (чтобы быть первичным ключом или его частью — в таблицах связей) и быть по возможности монотонно возрастающим (чтобы поиск в базе данных был быстрым).
да я тоже писал, что склоняюсь к этой точке зрения. но вот авторы этого rfc, похоже, нет.
Не думаю, что нужно подгонять новый стандарт под старые кривые приложения, которые ему не соответствуют. Хочешь соответствовать новому стандарту - переписывай приложение. Ведь стандарт - это не только формат, но и стоящие за ним принципы, обеспечивающие надежную работу приложений. Один из этих принципов - не извлекать никакие бизнес-данные из идентификаторов. Это что-то вроде "Принципа единственной ответственности" в SOLID: не нужно навешивать на идентификаторы никакие дополнительные функции, чтобы не получить дополнительных проблем.
В данном случае авторы RFC ошибаются. Ну, это не в первый раз. Предыдущие версии UUID вообще ужасны. Рано или поздно ошибка вылезет и будет исправлена. На исправление предыдущих ошибок потребовалось 16 лет.
ну ограниченное использование времени из uuid ИМХО разумно.
например, при партицировании по дате планировщик может понять, что в эти секции вообще лезть не надо (достаточно хранить минимальное и максимальное значение индексного поля в секции, где-то я такое видел).
или, например, я часто добавляю в таблицы поле «время добавления записи». это поле никак не используется в работе, но иногда пригождается при отладке.
был бы у меня такой кот, я б может и не женился бы никогда uuid, мне бы отдельное поле и не понадобилось.
3) кроме СУБД есть и другие применения. Или вы хотите, чтобы генерящиеся новые UUID-ы случайно совпали с кем-то сгенерированным UUIDv4? Не думаю, что последний перестанет быть рекомендованным вариантом (да и в СУБД по UUIDv4 можно собрать hash-индекс).
Или вы хотите, чтобы генерящиеся новые UUID-ы случайно совпали с кем-то сгенерированным UUIDv4?
с v4 как раз почти наверняка не совпадёт (вероятность настолько мала, что ей можно полностью пренебречь). а вот трактоваться как v1/v2 вполне может, после чего приложение может начать пытаться извлечь оттуда какие-то данные.
Вероятность коллизии с UUIDv4 нулевая, так как в идентификаторе UUIDv7 есть случайная часть, да и совпадение timestamp UUIDv7 c левой (случайной) частью UUIDv4 практически невозможно. Поэтому для предотвращения коллизий ver и var совершенно не нужны.
Зависит от скорости генерации сущностей, идентифицируемых UUID-ом. Если общее число сущностей за всё время превысит примерно 2^65, вероятность коллизий, даже если выкинуть фиксированные биты, достигнет 50%. Если выкинуть зарезервированные биты (т.е. 122 бит рандома в UUIDv4), получим 2^62.
На самом деле, вероятность коллизий в 50% никого не устроит, должно быть минимум 10^(-9). Это всего 2^47 (UUIDv4). 15 дополнительных бит после превышения счётчика. Ну, то есть, для большинства проектов это ок, но какому-нибудь CERN-у использовать UUID для идентификации единичных измерений уже нежелательно.
Возьмём UUIDv7. Как я понял отсюда, у нас всего 62 бита случайности. Это 2^32 сущности при вероятности 50% и 2^17 при вероятности 10^(-9). Да, это небольшое число, если время остановится, очень быстро появится ненулевая вероятность коллизий. Но при нормальном течении времени, появление такого количества событий за 2^(-12) секунды (около 250мкс) можно только на очень большой распределённой системе. Плюс, там еще 12 бит берутся из счётчика тактов CPU, это, по сути, еще столько же бит энтропии, пусть они и завязаны на конкретный экземпляр CPU, но мы ведь про распределённую систему говорим. А это значит, что для вероятности 10^(-9) это уже 2^23 элементов.
Лично у меня претензия только одна: не слишком большая эффективность использования бит под штамп времени. Во-первых, один знаковый бит можно из него выкинуть - мы ведь говорим о событиях, которые генерируются сейчас. Во-вторых, для многих применений не нужен вечно работающий идентификатор, достаточно идентификатора, который будет работать, скажем, 10-20 лет. Зная это, можно было бы заметно сократить битность штампа времени, увеличив рандомную часть, если установить для конкретного применения опорную дату (и сдвигать её периодически).
Во-вторых, для многих применений не нужен вечно работающий идентификатор, достаточно идентификатора, который будет работать, скажем, 10-20 лет
Я думал про это, ломается вся идея uuid и появляется дополнительный источник потенциальных грабель.
Плюс, там еще 12 бит берутся из счётчика тактов CPU
Это вы где такое увидели?
Я думал про это, ломается вся идея uuid и появляется дополнительный источник потенциальных грабель.
Нередко UUID используют вообще для всех данных: как тех, которые должны быть универсальны, так и тех, которые можно выбросить через пару лет. Да вплоть до того, что используют UUID в качестве временно живущего токена, который просто из соображений безопасности должен уничтожаться через определённое время. Тупо чтобы не возиться с ГСЧ, тупо API генерации UUID-а удобнее и считается, что обо всём позаботились авторы библиотеки. В последнем случае генерация именно UUID-а отличного от v4 снижает его безопасность, но в других случаях вполне норм.
Это вы где такое увидели?
Я воспринял вот это как счётчик тактов, но мб. это следует интерпретировать по другому?
All 12 bits of subsec_b have been dedicated to a motonic clock sequence counter (seq).
Нередко UUID используют вообще для всех данных: как тех, которые должны быть универсальны, так и тех, которые можно выбросить через пару лет
поэтому-то и лучше делать сразу хорошо, чтобы потом не было больно
Я воспринял вот это как счётчик тактов, но мб. это следует интерпретировать по другому?
это счётчик для обеспечения монотонности внутри одного тика таймстампа
это счётчик для обеспечения монотонности внутри одного тика таймстампа
Довольно дорогостоящее удовольствие считать тики таймштампа и сбрасывать по ним счётчик (да еще и синхронизировать всё это между сотнями потоков), а значит во многих реализациях это будет просто циклический счётчик, значение которого будет сильно зависеть от начального вектора (рандом, при чём может быть свой в каждом потоке) и от потока запросов на генерацию uuid-а. Т.е., по сути не 12 бит рандома, но 6-8 - вполне реально.
Хотя не, можно просто хранить последний таймштамп + параметр, инкрементируемый через interlocked-функции. Самое дорогое в данном случае - системный вызов получения времени (но тоже можно соптимизировать, проверяя число тиков и делая syscall только если дельта по тикам больше определённого значения). Но на javascript такое уже не сгенерируешь эффективно (если запущенно несколько процессов ноды - у каждого процесса будет свой счётчик).
Мне больше интересно, существует ли надежный способ генерации id по hardware? Когда-то давно занимался этой темой, и оказалось, правильно идентифицировать произвольный компьютер не такто просто
Поэтому я и предложил идентификатор компьютера Node сделать опциональным. Кроме того, не всегда желательно раскрывать идентификатор компьютера по соображениям безопасности. И никакой особой необходимости в идентификаторе компьютера нет, так как коллизионная стойкость может быть обеспечена без него. Даже наоборот, гораздо выше риск коллизий у идентификаторов, сгенерированных на одном и том же компьютере, а не на разных. Поэтому лучше удлинить случайную часть за счет идентификатора компьютера.
Кстати, он опциональный. Забыл написать про это в статье, но в RFC он он как раз опциональный
Да, я заметил. В проекте стандарта говорится, что идентификатор компьютера Node обычно заполняется случайными числами :) . Мне кажется, что лучше его вообще выкинуть из стандарта. Осмысленными данными его заполнить невозможно - их просто нет. MAC-адрес в проекте стандарта заслуженно запрещен. А если бы и были данные, идентифицирующие компьютер, то для предотвращения коллизий они ничуть не лучше случайных чисел, и авторы стандарта это явно чувствуют. Раскрывать идентификатор компьютера - плохо с точки зрения безопасности. Идентификатор компьютера Node - это просто атавизм MAC-адреса, скопированный из прежних версий UUID.
Детальное ознакомление с проектом RFC показало, что на самом деле node вовсе не идентификатор компьютера, а по сути random. Просто, авторы RFC употребили неудачное слово node не в том смысле, в котором оно обычно употребляется. Проблема может быть решена заменой термина node на random или randomness
сортируемость получается только в пределах одной ноды??? Слитые данные из N нод - уже не сортируемы получается??? (если таймзоны у них разные у всех)
хорошим тоном считается везде использовать/хранить время в utc.
А не unix timestamp? :)
На тему неявного хранения и использования времени в utc мы уже напарывались в одном известном и популярном сервисе.
А не unix timestamp? :)
не понимаю противопоставления, unix timestamp — это один из способов хранения utc
The Unix epoch (or Unix time or POSIX time or Unix timestamp) is the number of seconds that have elapsed since January 1, 1970 (midnight UTC/GMT)
На тему неявного хранения и использования времени в utc мы уже напарывались в одном известном и популярном сервисе
что вы имеете в виду?
не понимаю противопоставления, unix timestamp — это один из способов хранения utc
UTC больше понимается в контексте "время в таймзоне со сдвигом 0", а unix timestamp фактически не привязан к таймзоне, и его удобнее хранить и использовать.
что вы имеете в виду?
Разработчики в одном сервисе принимали дату/время в некоторых сущностях в одном из эндпоинтов.
В документации было указано — в одном месте нужно слать таймстамп, а в другом "длинный" формат даты (уже довольно странно, ну да ладно).
Как-то пришел один из клиентов с жалобами что мол у него в одном месте время принятых данных в сервисе одно, а в другом другое. Пообщались с сервисом, и выяснилось, что хотя эндпоинт и допускает прием "длинной" даты с указанием таймзоны/сдвига, они фактически считают что принятая дата должна быть строго в UTC и указания других таймзон игнорируются. Своим багом это не признали.
Пообщались с сервисом, и выяснилось, что хотя эндпоинт и допускает прием "длинной" даты с указанием таймзоны/сдвига, они фактически считают что принятая дата должна быть строго в UTC и указания других таймзон игнорируютс
ну это совсем не то, что я имел в виду )
имелось в виду, что какой-нибудь timestamp with time zone в БД это не совсем (совсем не) unix timestamp, но он отлично подходит для хранения времени (можно без проблем сравнивать два времени из разных часовых поясов).
Судя по статье в Википедии https://ru.wikipedia.org/wiki/Unix-%D0%B2%D1%80%D0%B5%D0%BC%D1%8F подразумевается, что Unix time - это UTC, но лучше об этом написать в RFC явно. То есть, никаких разных таймзон в timestamp нет.
Почему нам необходимо генерировать UUID, а не просто брать случайные данные? Ну, ответов может быть множество. Сохранение данных о хосте, который сгенерировал последовательность, сохранение времени и тому подобных значений, позволяет сделать UUID более информативными. Подобный подход можно использовать при создании распределённых вычислительных систем. Например, вместо того, чтобы грузить базу данных запросами с датой, можно просто выбрать те идентификаторы, которые содержат в себе эту дату.
по размышлению я пришёл к выводу, что мне это категорически не нравится.
если с идеей извлекать timestamp из uuid я ещё могу как-то смириться, то хранить там прочие поля мне кажется глупостью.
если вам нужен отбор по этим полям, то вам нужен индекс. если вам нужна проверка этих полей, то вам, возможно, нужно что-то вроде hmac…
ничего этого uuid не предоставит, не надо пытаться объять необъятное.
есть простая цель: сделать btree-friendly вариант uuid, вот это и надо делать.
- всё-таки поддерживаем совместимость с uuid (поля ver и var), потеря 6 бит не критична;
- не пытаемся обеспечить строгую монотонность, для btree она не нужна; и в распределённой (и даже многопоточной) системе она если и возможна, то превращается в головную боль;
- с учётом предыдущего пункта, точность выше миллисекунд не нужна, тем более, что обычные протоколы синхронизации времени не обеспечивают особой точности;
- только timestamp и random, ничего больше не храним, ни идентификаторов, ни последовательных номеров. чем больше рандома — тем лучше;
- выделение timestamp из uuid категорически не рекомендуется для чего-то помимо отладки и т. п.
- в timestamp храним время генерации uuid, так что предусматривать кодирование «до нашей эры» и «через 5000 лет» не нужно;
итого, в первом приближении: 44 бита беззнаковый timestamp в миллисекундах (хватит примерно на 500 лет вперёд), 78 бит рандома.
остающиеся вопросы:
- достаточно ли 78 бит рандома для практического отсутствия коллизий? может быть лучше хранить время с секундной точностью, а поле рандома расширить на 10 бит? (хотя с первого взгляда это принципиально ничего не изменит — использование миллисекунд тоже снижают вероятность коллизий)
- нужно ли резервировать номер для новой версии, или «мимикрировать» под uuidv4 (если мы решаем, что извлечение даты из uuid — плохой тон, то для читающего приложения нет совершенно никакой разницы является ли uuid полностью случайным, или же включает в себя время).
На данный момент всё это как раз в обсуждениях на гитхабе. Присоединяйтесь. Вопрос о шести битах и временной точности открыт и обсуждается прямо сейчас.
Я потому и статью написал, чтобы народ подключился. Как это так, где-то делается стандарт, а его разрабатывают Американцы, Бразильцы, Венгры и Хабра даже не видать.
Я считаю, что за образец стандарта лучше всего взять не ту сборную солянку, которая сейчас в проекте (типичный плод работы комитета), а https://github.com/Sofya2003/ULID-with-sequence
Можете предложить это инициаторам стандарта?
а зачем этот уродливый sequence? как мне кажется, он только увеличивает вероятность коллизий. проблема монотонности решена в оригинальном ulid, можно взять идею оттуда и чуть доработать.
Решение проблемы монотонности в оригинальном ULID неудачно с точки зрения информационной безопасности. Ведь можно вычислить неизвестный ULID путем инкремента/декремента случайной части уже известного ULID'а. Если в течение миллисекунды нагенерится 5000 ULID'ов, то по одному известному ULID'у можно вычислить все 5000 ULID'ов. Если при генерации ULID'ов осуществляется инкремент не на 1, а на случайное число, то проблема становится не столь острой, но возникает риск переполнения случайной части, а на расчет случайного приращения и добавление его к длинной случайной части тратится время.
Скорость генерации ULID'ов с сиквенсом выше, чем в оригинальном ULID, так как в первом случае можно использовать заранее вычисленные случайные части (для каждого ULID'а - своя случайная часть), а скорость инкремента короткого счетчика выше, чем скорость приращения длинной случайной части.
Сиквенс (в большинстве случаев нулевой) отнимает у случайной части только 15 битов, поэтому вероятность коллизий повышается очень незначительно.
15 бит так-то - это очень даже значительное влияние на вероятность коллизии. Там экспоненциальная зависимость.
Решение проблемы монотонности в оригинальном ULID неудачно с точки зрения информационной безопасности
Это понятно, но легко устранимо, достаточно оставить рандомную часть.
Просто разработчики ulid заигрались с возможностью создания 2^80 записей внутри одного отсчёта timestamp, что ИМХО практической ценности не имеет. У меня в черновиках уже лежит вариант реализации, немного позже причешу формулировки и заеду, наверное, issue.
Если в течение миллисекунды нагенерится 5000 ULID'ов, то по одному известному ULID'у можно вычислить все 5000 ULID'ов.
А откуда такая информация? Я вот смотрю на https://pkg.go.dev/github.com/oklog/ulid#Monotonic - по умолчанию инкремент в рамках одной миллисекунды это случайное значение в интервале [1,MaxUint32) - этого более чем достаточно чтобы подбор ещё хотя бы одного ULID по известному стал достаточно мучительным (2 млрд. попыток в среднем). И делать инкремент с таким шагом случайному 80-битному значению обычно можно очень много раз до возможного переполнения.
На практике, со скоростью генерации порядка 30ns, за одну миллисекунду можно нагенерировать порядка 33 тысяч ULID - это совсем не много, учитывая "1.21e+24 unique ULIDs per millisecond (1,208,925,819,614,629,174,706,176 to be exact)".
Я потому и статью написал, чтобы народ подключился
увы, уровень моего английского не позволяет полноценно участвовать в обсуждениях сложных тем.
К пункту 4. : Если timestamp обеспечивает миллисекундную точность (я тоже склоняюсь к этому), то автоматические процессы могут за одну миллисекунду нагенерить десятки тысяч записей с уникальными идентификаторами. Эти записи, если не использовать счетчик (clock sequence), будут неупорядоченными, и поиск их будет медленным. Поэтому необходим счетчик (15 битов) после timestamp.
Эти записи, если не использовать счетчик (clock sequence), будут неупорядоченными, и поиск их будет медленным
так по умолчанию нужно предполагать, что генерация распределённая, тут уже никуда не деться от нарушения монотонности.
да, с кластерными индексами будут проблемы, надо смотреть насколько серьёзные. в любом случае это будет гораздо лучше рандомного uuid.
а с обычными btree, думаю, не будет особой разницы с монотонной последовательностью.
или какой поиск вы имели в виду?
Я совершенно не согласен с тем, что "по умолчанию нужно предполагать, что генерация распределённая". Зачем же отсекать огромную область генерации UUID в СУБД, на сервере, в корпоративной информационной системе? Нужно ориентироваться и на их потребности тоже. Да и в распределенной системе крупный узел может нагенерить десятки тысяч UUID в миллисекунду
Зачем же отсекать огромную область генерации UUID в СУБД, на сервере, в корпоративной информационной системе?
а зачем там uuid? не проще обычный автоинкремент использовать? uuid нужен там, где требуется распределённая генерация уникальных идентификаторов.
UUID - прекрасный инструмент для аналитика. Позволяет мгновенно найти что угодно (даже когда непонятно, что это, и в какой таблице лежит), быстро определить источник ошибки и т.д. Он также позволяет избежать множества операций и проверок, на которые уходят огромные ресурсы информационной системы. Он позволяет предотвратить ошибки. Облегчает исправление выявленных ошибок. Сильно облегчает разработку.
ну так-то оно так, только для этого uuid и должен быть глобально-уникальным.
а добавление sequence и прочего увеличивает вероятность коллизий.
хотя БД с кластерными индексами, наверное, достаточный аргумент за то, чтобы добавить возможность генерации монотонных uuid как опцию.
реализованный в ulid подход не пойдёт?
Реализованный в ULID подход вполне подойдет, также как и более правильный с точки зрения информационной безопасности подход "ULID with sequence" (https://github.com/Sofya2003/ULID-with-sequence).
Но проблема в том, что эти подходы не стандартизованы (нет RFC), и поэтому не поддерживаются разработчиками СУБД. Поддержка в некоторых фреймворках (https://laravel.demiart.ru/laravel-i-ulid/) и реализация во многих языках программирования не так важны, как реализация именно в СУБД. Ведь обмен данными между БД и сервером приложений отнимает время, и это не годится для высоконагруженных приложений.
Да и в распределенной системе крупный узел может нагенерить десятки тысяч UUID в миллисекунду
можете закончить мысль? ну нагенерировал он десятки тысяч uuid, что плохого?
Эти записи, если не использовать счетчик (clock sequence), будут неупорядоченными, и поиск их будет медленным
«не понимаю» )
СУБД очень медленно ищет записи в таблице по идентификаторам, если записи при добавлении в таблицу не были упорядочены по возрастанию (либо убыванию) идентификаторов. Упорядоченность идентификаторов при их создании (монотонность) легко реализовать по timestamp. Именно поэтому появились ULID и проект новых версий UUID.
При этом важна упорядоченность в целом, а не строгая упорядоченность, так как механизмы хранения данных в СУБД позволяют в значительной степени компенсировать небольшую неупорядоченность.
Если точность системных часов и timestamp в UUID 1 миллисекунда, то UUID, сгенерированные в течение этой миллисекунды, будут отличаться только случайной частью (random, или node в проекте новых версий UUID), то есть, будут крайне неупорядоченными. Если таких UUID будет много, то они замедлят поиск записей в БД, что критично для высоконагруженных систем. Счетчик (clock sequence) позволяет этого избежать, так как упорядочивает UUID, сгенерированные в течение миллисекунды.
СУБД очень медленно ищет записи в таблице по идентификаторам, если записи при добавлении в таблицу не были упорядочены по возрастанию (либо убыванию) идентификаторов
ИМХО весьма сомнительное утверждение.
Давайте сначала определимся какую именно БД и какие именно индексы вы имеете в виду.
Если брать кластеризованный b-tree в ms sql или mysql innodb, то вставка будет медленнее из-за более частых сплитов страниц нижнего уровня, однако на время выборки единичной записи по первичному ключу это практически не повлияет.
На некластеризованные индексы (а в том же постгресе других нет) влияние будет ещё меньше.
Время поиска зависит от упорядоченности UUID. Доказательства здесь: https://github.com/Sofya2003/ULID-with-sequence#benchmarks-of-sequential-uuid
Если бы это было не так, то можно было бы пользоваться только UUIDv4, и не нужны были бы ни ULID, ни новые версии UUID
Время поиска зависит от упорядоченности UUID
Не обязательно. Например, при поиске по хэш-таблицам упорядоченность роли не играет.
Я говорю, что нужно определиться какой именно сценарий использования UUID мы рассматриваем.
Доказательства здесь
ЕМНИП, в основном там рассматривается использование uuid для кластеризованного b-tree индекса. При этом сравниваются только две крайности: монотонный идентификатор и случайный uuid.
Не монотонный, но в целом упорядоченный идентификатор, как я ожидаю, не будет вызывать такой уж ужасной деградации производительности (хотя, очевидно, будет хуже монотонного из-за частого сплита страниц). В случае некластеризованного индекса потери должны быть ещё меньше, так как сплит страниц заметно дешевле.
Хотя вы меня убедили в том, что нужны тесты.
удивительно хорошая статья по uuid от 1с-ников:
https://infostart.ru/1c/articles/635159/
guid изначально был придуман для РАСПРЕДЕЛЕННЫХ систем, в которых ПРОБЛЕМА УНИКАЛЬНОСТИ идентификаторов решена полным ОТКАЗОМ ОТ АВТОИНКРЕМЕНТА в пользу СЛУЧАЙНЫХ чисел и специальных техник. GUIDы случайны и неповторяемы по определению и в этом его достоинство и недостаток.
Random UUIDs вызывают деградацию операций вставки. У таких гуидов индексы получаются плохо кластеризованы, дерево поиска максимально широкое
Почему нельзя использовать время из GUID?(второй пункт тут 1с-специфичен, впрочем, как я уже писал, в распределённых системах возникают проблемы с монотонностью)
Во-первых, гуид может быть случайным, а не основаным на времени.
Во-вторых, гуиды выдаются пулом по 32 штуки для каждого сеанса.
В-третьих, гуид случаен по своему стандарту и время в нем это лишь способ сгруппировать первичные ключи для уменьшения ширины В-дерева и ускорения операций вставки в кластерный индекс!
Прекрасное обоснование "Почему нельзя использовать время из GUID"!
UUID могут генериться впрок на случай пиковых нагрузок. Поэтому timestamp в UUID может отличаться от времени создания записи, и хотя бы поэтому timestamp не следует извлекать из UUID.
Боюсь, эти мысли не удастся втолковать авторам проекта стандарта, которые сильно продвинулись в противоположном направлении :(
Ну вот жеж, бабай, блин. Какое время? Какой стандарт? Вы статью читали?
Я сижу и растолковываю, что стандарт бинарно-сортируемый. Значит, что сгенерированные идентификаторы будут бинарно-сортируемые. Удобно, быстро, приятно. Когда у вас эластик на 200+ хостов, быстро можно собрать данные по примерно такому-то участку времени.
Единственная причина, почему там время вставлено, так это для сортировки. Вытягивать время из самого идентификатора вас никто не просит.
Он был создан в 2021-08-12 16:08:57 -0700 UTC-7 (с unix timestamp 1628809737)
Наносекунды записаны как 0.535995
Это не наносекунды записаны, а доли секунды. Кстати, 16 бит — это 5 неполных десятичных разрядов. Шести значащих цифр там точно нет, тем более наносекунд. Значение нужно округлить до пяти значащих цифр вот так: 0.53600. Кстати, 536 миллисекунд уже есть в полной записи даты двумя строчками выше, если смотреть на исходную картинку. Зачем там ещё неправильно округлённые «наносекунды»?
На самом деле документ описывает три версии новых идентификаторов. 6, 7 и 8. Версия шесть обратно-совместима с версией 4, и сохраняет дату в старом формате.
с версией 1?
и, честно говоря, мне непонятно зачем потребовалось добавлять сразу три новых версии стандарта.
Очень даже понятно: когда не можешь сделать один продукт качественно, то предлагаешь потребителю выбор из нескольких некачественных продуктов или вообще говоришь "сделай сам как знаешь, но с моими с потолка взятыми ограничениями" (UUIDv8). Так же было и с предыдущими версиями UUID (с 1 по 5). Обычный подход путем компиляции всего предыдущего в кучу с устранением только самых вопиющих прежних ошибок. Там, где необходимы расчеты (точность timestamp, длина sequence) или получение данных (точность системных часов, скорость генерации ULID'ов), забота об этом перекладывается на разработчиков. А затем "тяп-ляп и в продакшен". Кто не успел со своими замечаниями или слишком много захотел от авторов, тот опоздал. А через 15 лет уже другие люди будут исправлять новые ошибки, но при этом фанатично придерживаться унаследованных ограничений "для совместимости" с предыдущим кошмаром.
Для того обсуждение и есть.
Nurked а кто все эти люди? Насколько они квалифицированы? Имеют ли они достаточный авторитет, чтобы их вариант rfc вообще имел шансы быть принятым?
А то, быть может, это междусобойчик студентов, который закончится ничем.
напишу пока тут по-русски, так быстрее )
Optional, locally unique entity_type ending of the UUID (10 bit), corresponding to some database tables
уверены, что это нужно?
Mandatory quantum-mechanical TRNG or CSPRNG
ИМХО достаточно не слишком плохого RNG + CSPRNG в качестве сида
Crockford's base32 string representation recommended in URL and for all new projects (but 8-4-4-4-12 format for backward compartibulity only)
ну так-то хорошая идея, но точно обязательно именно в этот rfc тащить?
тем более, что КМК лучше использовать одинаковую запись для всех версий UUID, нет?
Calculation of random parts in advance, and buffering for high-load applications when needed
Calculation of UUIDs in advance within clock tick, and buffering for high-load applications when needed
есть сомнения, в любом случае это уже детали реализации, можно не тащить в стандарт
UUID creation independently for each database table
это отличается от первого пункта?
UUID creation directly in DBMS for better performance or on client side, but not in application server
стандарт-то тут причём?
Timestamp shift for sensitive information
имеется в виду сокрытие точного времени? ну тогда uuidv8, меня почти убедили в его необходимости
Prohibition on substitution of UUID in records from external sources, except sensitive information
по мне достаточно сказать, что только таймстамп и рандом, ничего больше
Entity_type ending нужен, например, для спецдепозитариев и банков. Регуляторы и ПИФы заставляют их формировать отчётность по огромному количеству правил, которые проще всего автоматизировать с помощью полиморфных связей таблиц. Entity_type ending позволит сразу найти таблицу, с которой необходимо соединение. Кроме того, можно мгновенно найти объект, не зная таблицу, где он содержится.
я считаю, что ничего хорошего из этого не выйдет, проблематично засунуть в 122 бита таймстамп, идентификатор типа объекта и достаточно рандома для глобальной уникальности.
Поэтому я и предложил выкинуть никому не нужные ver и var, а общую длину увеличить до 160 бит. Кстати, 160 бит в кодировке Crockford base 32 имеют ту же длину, что и 128 бит в обычной кодировке UUID. Так что во многих случаях сохранится совместимость.
часто uuid хранится в бинарном виде, так что совместимости не получится. и да, я прикидываю, 160 бит всё-таки маловато (дополнительный идентификатор типа объекта хочется иметь тоже глобально-уникальным, а это минимум 64 бита, а лучше 80)
Во многих СУБД (PostgreSQL) строковые UUID ищутся быстрее, поэтому хранятся в строковом виде. Поэтому некоторая совместимость есть. Глобально-уникальный идентификатор типа объекта уже есть. Это URL. И в него хорошо вставляется UUID. У URN нет перспективы, так как создать хороший единый справочник типов объектов невозможно. Вставлять тип объекта (имя таблицы) в URL можно, но СУБД будет сложно с этим работать, а вот короткий рациональный локальный признак типа объекта в UUID - удобная вещь.
UUID creation independently for each database table. Я, наверное, нечётко выразился. Смысл в параллельном запуске генераторов UUID для нескольких таблиц с целью увеличения производительности. Кроме того, допускаются UUID с одинаковыми таймстемпами и сиквенсами, но в разных таблицах. У них не будут совпадать рандомные части а также Entity_type ending
UUID creation directly in DBMS for better performance or on client side, but not in application server. У ULID'ов сложилась нехорошая ситуация: есть множество функций генерации ULID'ов для всевозможных языков программирования. Но нет стандартных средств генерации ULID'ов для СУБД. Пересылка ULID'ов из сервера приложений в БД отнимает время. Нельзя допустить такую ситуацию для новых версий UUID
можно подумать, что если включить эту волшебную фразу, то разработчики СУБД кинутся реализовывать )
UUID creation directly in DBMS for better performance or on client side, but not in application server.
Странная формулировка. Возможность создавать UUID в СУБД, конечно, должна быть. Но как из этого следует запрет на их создание в серверном приложении? Не говоря уж о том, что место и время генерации UUID — это архитектурное решение, которое принимает разработчик. Стандарт не должен в это дело влезать — это не его сфера ответственности.
Пересылка ULID'ов из сервера приложений в БД отнимает время.
Можете подробней описать, где вы тут видите существенную потерю времени. Лично я не вижу, как пересылка одного дополнительного поля, отнимает существенное время. Зато вижу, как тратится лишнее время, при необходимости, каждый раз, создавая новый объект, ждать ответа от СУБД, чтобы получить идентификатор, и наконец завершить создание объекта. Кстати об ответе. Если мы не шлём ULID из приложения в СУБД, значит нам придётся его прислать в ответе из СУБД в приложение. В обоих случаях, нам придётся пересылать этот злосчастный ULID, меняется лишь направление. Так в чём же выигрыш, от создания его в СУБД? Может я не учитываю какую-то оптимизацию, которую СУБД может в этом случае сделать, или ещё какой-то нюанс?
есть множество функций генерации ULID'ов для всевозможных языков программирования
Которые реализованы в сторонних библиотеках.
Но нет стандартных средств генерации ULID'ов для СУБД.
Но есть реализации в сторонних расширениях для этих СУБД, которые можно подключить и использовать. Так в чём проблема?
Стандартных средств, для генерации ULID, нет потому, что сам ULID не является стандартным типом. В отличие от него, UUID v7 будет стандартным, а значит и в СУБД, стандартные средства для его генерации появятся.
Зато вижу, как тратится лишнее время, при необходимости, каждый раз, создавая новый объект, ждать ответа от СУБД
Это не нужно. UUID должен генериться автоматически подобно автоинкременту при вставке новой записи в таблицу, где он является ключом.
Это не нужно.
Что именно не нужно? Ждать ответа от СУБД, как раз таки, нужно. Ведь UUID, который, был создан в СУБД, нужен и приложению тоже. Вот и получается, что где бы UUID ни создавался, его, в любом случае, придётся куда-то пересылать. Создал в СУБД — изволь отослать в приложение. Создал в приложении — придётся отсылать в СУБД.
UUID должен генериться автоматически подобно автоинкременту
То что вы придерживаетесь этой точки зрения, я ещё из предыдущего вашего комментария понял, на который, собственно, и отвечал. Хотелось бы понять, почему вы так считаете.
Монотонно возрастающие при генерации UUID, которым посвящен проект RFC, нужны в качестве первичных ключей БД, чтобы ускорить поиск записей в БД. Быстрая генерация таких UUID нужна при создании записей в БД. Для приращения сиквенса UUID нужно знать предыдущее значение сиквенса. Приложения его не знают. То есть, приращение сиквенса лучше делать средствами СУБД.
Для приращения сиквенса UUID нужно знать предыдущее значение сиквенса. Приложения его не знают.
А СУБД, разве, не такое же приложение? В стандарте сказано, что генератор должен иметь счётчик (clock sequence), чтобы усилить монотонность, на случай, если два UUID будут сгенерированы в один момент времени. Это касается любого генератора, в любом приложении. Там ничего не сказано конкретно про СУБД, что они какие-то особенные, в этом плане.
Проблемы с этим счётчиком могут быть, только если у вас работает несколько параллельных генераторов. Но это, в большей степени, касается генерации на стороне клиента. Там, кстати, ещё и проблема с синхронизацией времени между клиентами вылазит, которая запросто сломает монотонность, да так, что мало не покажется. Достаточно одного клиента со сбившимся временем. При этом, вы, почему-то, не против генерации на клиентах, но против генерации в серверном приложении.
Timestamp shift for sensitive information Возможно, что я здесь погорячился, и не стоит усложнять стандарт и провоцировать ошибки. Если нужно передать вовне ссылки, не содержащие истинную дату и время создания записи или очередность, то можно сгенерить дополнительно полностью рандомные внешние ссылки. За секретность придется немного заплатить производительностью.
Prohibition on substitution of UUID in records from external sources, except sensitive information Это очень распространенный способ наплодить ошибок и внести хаос в систему, когда при передаче в вышележащий слой производится подмена исходных идентификаторов записей из разных источников на сгенерированные. UUID должны генериться в самом нижнем слое и передаваться в вышележащие слои без изменений
можете привести примеры неправильного использования?
По работе я сталкивался с этим постоянно, особенно в случае составных бизнес-ключей. В одной учётной системе один ключ, в другой - другой, а в хранилище данных записи из обеих систем загружаются со третьим ключом, а прежние ключи теряются. Сопоставить ничто ни с чем невозможно.
а прежние ключи теряются
Ключи из других учётных систем, для базы данных, являются полноценными естественными ключами, такими же как артикулы товаров или номера документов. Следовательно, их надо хранить. То что их не сохранили — это просто ошибка в проектировании базы данных. С таким же успехом, можно любой другой важный параметр не добавить в сущность, и поиметь от этого проблем.
То, что я описал, это не отдельная ошибка, а широко распространенная негативная практика. Поэтому RFC должен указать предпочтительное место генерации UUID - самый нижний слой информационной системы, где сейчас во многих случаях создаются уродливые составные бизнес-ключи.
Раз уж речь зашла про уродливые решения, то на клиенте крайне не удобно работать с сущностями без идентификаторов. И если идентификатор задаётся сервером при сохранении, то на клиенте до сохранения приходится делать кучу уродливых костылей, вводя временные идентификаторы, потом подменяя временные на полученные от сервера, потом борясь с тем, что где-то в приложении ещё остались старые, а объекты с разными идентификаторами считаются разными объектами.
Отчасти поэтому, когда сервер в моей власти. Я первым делом выпиливаю неидемпотентный метод POST, заменяя его на идемпотентный метод PUT с записью по генерируемому на клиенте гуиду, а с клиента выпиливаю львиную часть костылей.
Вы не обратили внимание, что я описал два предпочтительных места генерации UUID: или СУБД, или клиент. Запрет касается только сервера приложений.
Вы сами-то прочитайте, что написали в комментарии, на который я отвечал.
Впрочем, все те же проблемы есть и на сервере приложений. Вот шлёт клиент вам файл. Байтики уже летят. А тут вы такие "http продождёт, сейчас схожу в базу получу идентификатор, а после загрузки схожу ещё раз в базу, сохранить мета-информацию"? Или всё же сгенерируете идентификатор для файла, направите стрим в файл, а по завершении запишете в базу вместе с мета-инфой?
RNG + CSPRNG. Возможно, но это нужно как-то сформулировать в RFC
Формат 8-4-4-4-12 уступает Crockford's base32 по читабельности, по длине, по возможности скопировать в один клик. Не стоит тащить его в новые проекты, но нужно оставить для совместимости со старыми. Оба текстовых формата должны быть в RFC
Вот хороший новый вариант UUID длиной 160 бит: Long ULID for high-load critical systems and IoT, в котором уникальность, монотонность и пригодность для первичного ключа не принесены в жертву 128-битной краткости. Длина всех составных частей UUID и точность времени (timestamp) обоснованы и позволяют достичь максимально возможной производительности. Используется надежный генератор случайных чисел и тактовая последовательность (clock sequence).
Принципиально новым является двухсимвольный локальный для базы данных тип сущности, указывающий на таблицу базы данных, в которой данный UUID является первичным ключом. Это удобно для установления полиморфных отношений между таблицами базы данных. В одном поле типа array или типа jsonb может быть несколько UUID c различными типами сущности. Тип сущности также помогает быстро найти все таблицы, где могут содержаться UUID с указанным типом сущности. Тип сущности опциональный, и может заполняться случайным числом.
Также используется кодировка Crockford's base32 и возможна обратная совместимость по длине и структуре с 128-битными UUID в строковом формате 8-4-4-4-12 с дефисами.
Хранение UUID возможно в любом формате: text, binary, UUID, integer, byte array, jsonb.
06115ad596-0873-0087-5764-c1f3730d90
хм, а разве первый символ в средней группе не должен равняться номеру спецификации (7) ?
ULID не корректно сортируется на MS SQL SERVER.
ULID предполагает сортировку слева на право (левая сторона дата)
Если вы создатите таблицу с uniqueidentifier и DateTime, а затем вставите в нее данные в хронологическом порядке (ULID и дата созданные в одно время)
То вы увидите что даты идут в случайном порядке.
Также мои тесты с бенчмарком показали что время вставки имеет большой разброс от 2 до 22 секунд на вставку 100_000 строк.
Если вы будете конвертировать ваш ULID в string => nvarchar(26) то он будет сортироватся корректно.
UUID версии 7, или как не потеряться во времени при создании идентификатора