Comments 21
Здраствуйте Андрей,
Спасибо, интересная работа. я совсем не из той области знаний, но стало интересно.
Есть ли инструменты для автоматического построения ковариационной матрицы исходя из статистических данных?
Здравствуйте! Спасибо за отзыв )
Построить ковариационную матрицу можно в excel, R и многих других инструментах. В основном это делается "автоматически" после соответствующей подготовки данных. Я использую python. В этом варианте с данными, на мой взгляд, наиболее удобно работать в pandas. Вот у них есть отличное руководство с примерами. После того как вы загрузили данные в DataFrame матрица строится одним простым методом. Ну а сами значения удобно рисовать функцией heatmap из пакета sns.
Вот пример для рисунка из статьи:
# print only rainfall correlation matrix
# clear plot object
plt.clf()
correlation_matrix_rainfall =\
DATA[['total_rainfall',
'cumm_year_rainfall',
'antecedent_rainfall',
'LANDSLIDE']].corr()
lables = ["Daily\nrainfall",
"Cumulative\nprecipitation",
"Antecedent\nrainfall",
"Landslide"]
correlation_matrix_rainfall.columns = lables
correlation_matrix_rainfall.index = lables
plt.figure(figsize=(10, 8))
# fix bug with text alignment on y-axes
# https://github.com/mwaskom/seaborn/issues/1820
plt.setp(plt.gca().yaxis.get_majorticklabels(), va="center")
ax_1 = sns.heatmap(
correlation_matrix_rainfall,
annot=True,
square=True,
linewidths=.5)
plt.savefig("../FIGS/correlation_matrix_rainfall.png", dpi=600, format='png')
plt.close()Наверное можно как то более изящно, но этот код кочует из одного скрипта в другой )
Хорошая работа. Вопрос про несбалансированные классы: после отсечения данных с малым количеством осадков - не пробовали вводить веса классов?
И ещё. Не пробовали ли применять upsampling (например с помощью imblearn)? Или для таких исследований это недопустимо?
Извините, можно для тупых немного пояснить, что означает ваша последняя формула? И пару примеров привести, если не трудно?
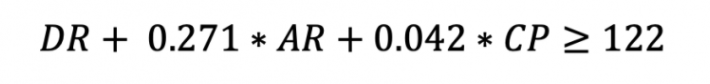
Берем конкретный день, например, вчера 15 августа 2021 года. Смотрим показания метеостанции, а именно:
DR - суточное значение осадков за 15 августа;
AR - значение предшествующих осадков. Если дождь лил непрерывно, то это будет кумулятивное значение за все дни непрерывных осадков. Если был один сухой день - 14 августа - то 0.
CP - кумулятивное значение осадков с начала года.
Теперь мы ставим все эти данные с метеостанции в формулу выше и если левая часть больше либо равна 122 то оползень будет (по модели).
Кстати! Здесь есть один очень интересный момент. Если AR и CP равны 0, то что бы сошел оползень (по модели) за день должно выпасть 122 мм осадков! Этот вывод отмечен в статье. И это ещё один аргумент в пользу статистического подхода - мы можем использовать исходные коэффициенты регрессии для таких выводов.
Спасибо. Двенадцать сантиметров осадков за сутки, наверное, нечастое явление, поэтому постоянно идущие дожди, видимо, чаще становятся причиной оползней. Делим 122 на 0,271, получаем 450 мм. Хм, тоже как бы немало. Трудно представить, что такая масса будет выльется непрерывно в течение, скажем, трёх дней. Предположим, что в день "всего" льется 30 мм, то сколько дней сплошного дождя приведет к оползню? (122-30)/0,271/30=11 дней.
Мы робко предположили, а можно уточнение, кто мы? Двфу?
В статье стоят авторы и аффилиация: ДВГИ ДВО РАН. В основном работа была выполнена силами сотрудников Сахалинского филиала.
Красиво! почитал с удовольствием
Очень интересная и сильная работа, но - насколько я понимаю для принятия конкретными службами правильным заблаговременных мер (а Вы же о предсказании говорите), нужно знать не только когда, но и где - причем второе куда существеннее первого.
Если бы я принимал решения о том, в какое место надо направить средства (а на все места средств никогда одновременно не хватит) в первую очередь для укрепления склонов от оползней, то полученная Вами информация мне бы никак не помогла.
Спасибо за отзыв!
Ну, с одной стороны, вы правы. С другой стороны, есть предупреждающие меры, а есть спасательные работы. Если уже 5 дней льёт дождь, и у вас есть в распоряжении прогноз погоды, то вы можете предсказать высокую вероятность оползней в городской черте. В этом случае, у вас есть время собрать силы и средства для возможных оползней: подготовить технику, проинструктировать спасателей и так далее. Передвижение готового отряда по городу - это часы. А если не подготовится и сойдёт много оползней, то до кого то помощь может во время не дойти.
"Если бы я принимал решения о том, в какое место надо направить средства (а на все места средств никогда одновременно не хватит) в первую очередь для укрепления склонов от оползней, то полученная Вами информация мне бы никак не помогла."
Это место известно, и называется оно Владивосток... ;)
И речь там, на мой взгляд, должна идти не о первоочередном месте укрепления склонов, а о принципиальной возможности такого укрепления в масштабах города, доступных технологиях и объёмах требующихся на это средств.
Надо видеть своими глазами Владивосток в период тайфунов...
Отвечу сразу на оба комментария.
"Владивосток" и "городской черте". Оползни безусловно во Владивостоке и в городской черте, но с точки зрения приложения сил и обеспечения безопасности - это всё равно что сказать, что они в России и внутри периметра.
Принципиальная возможность - есть технологии, которые позволяют обеспечить устойчивость склонов практически любой сложности. Вопрос только в средствах - и это не всегда деньги, это ещё и люди, и техника. Если одновременно на все потенциально опасные, с точки зрения оползней, места Владивостока (читай России внутри периметра) попытаться натянуть средства бюджета Владивостока (читай России внутри периметра), то именно в этом случае решение станет принципиально невозможным.
Именно поэтому, для стороны принятия решений, второй критерий - место, куда важнее первого - времени.
По поводу часов - это тоже на самом деле очень открытый вопрос. Давайте представим, что мы точно знаем прогноз погоды на предстоящую неделю и точно знаем, что Ваша формула показывает неизбежность оползней во Владивостоке. Как Вы думаете, какое количество дополнительных ресурсов (в смысле людей и техники) нужно пригнать во Владивосток, если оползни затронут XX% потенциально опасных мест?
Ключевой вопрос здесь - в XX%. Это величина от 0 до 100, причем непредсказуемая, но именно от неё зависит и количество дополнительных людей, и количество дополнительной техники, которые, кстати снова будут из бюджета Владивостока.
Я ни в коем случае не умиляю проделанную работу и повторю ещё раз, она интересная, сильная и важная - проблема оползней на 50% стала прозрачнее и предсказуемей, НО, к сожалению, всё так же далека от решения.
Оползни из автомобильных шин? Владивосток суров...
Вроде долго работали, составляли матрицы ковариаций.... А откуда у вас в строке Temp at a depth (80 cm) максимальная температура 45 градусов? (Аналогично в некоторых других местах таблицы.) Очистку данных не производили?
Мне кажется несколько надуманной идея использования именно логистической регрессии. В XGBoost можно узнать важность различных признаков. В любом случае было бы интересно взглянуть на точность и сравнить с "большими" дядями по типу XGBoost, нейросетями.
Очистку данных производили. Смотрите, пожалуйста, раздел таблицы после заголовка Data user for logistic regression.
Мне кажется несколько надуманной идея использования именно логистической регрессии.
В статье подробно объясняется почему мы использовали этот инструмент - нам нужна была значимость коэффициентов и их оценка. Если вы будете использовать подход ML вы получите модель "черный ящик", где параметры абсолютно ничего не значат.
Очистку данных производили
выкинули дни с дождями меньше 45 мм? Ok, пусть (или какую-то ещё очистку производили?).
Вместе с этим, мы хотели посмотреть как сильно влияют на оползни те или иные переменные.
https://habr.com/ru/post/428213/
"Рассчитываем важность фичей с помощью SHAP". Я думаю это может вполне подсветить "черный ящик".
И это не отменяет мысли о сравнении классического подхода и ML подхода для того, что бы узнать насколько сильно мы потеряли в точности. Также отмечу, что подбором гиперпараметров XGBoost и генерацией комбинированных фич можно построить достаточно компактное дерево, которое можно интерпретировать.
выкинули дни с дождями меньше 45 мм? Ok, пусть (или какую-то ещё очистку производили?).
Вообще то 54 мм. Все значения проверили, можете сами посмотреть, там всё в порядке.
"Рассчитываем важность фичей с помощью SHAP". Я думаю это может вполне подсветить "черный ящик".
SHAP отличная штука. Кроме этого, есть ещё байесовские нейронные сети - то же интересный подход в этом направлении. Лично меня эта тема очень захватывает. Но вы поймите, мы писали научную статью, рассчитанную на определённое научное сообщество геофизиков, поэтому выбор инструментов был соответсвующий. Кроме этого, положительных классов крайне мало.
Владивосток, оползни и логистическая регрессия