Comments 91
И если мозг уже поставлен десятилетиями программирования на Си и ассемблере, он упирается, потому что это ему контринтуитивно.
А если он поставлен ещё десятилетием игры со всякой функциональщиной (term reduction)?
Это мне трудно сказать. Я когда-то выучил лисп и смутно понимаю концепцию lazy evaluation, но что происходит с мозгом на хаскеле - не знаю
С мозгом происходит такое, что люди начинают программировать ПЛИСы на Хаскеле https://clash-lang.org/
У меня есть план изучить хаскель, но я пока не видел применения clash в индустрии. Вообще за последние 30 лет предпринималось много попыток поднять уровень абстракции в проектировании на уровне регистровых передач, но проектировщики этому сопротивлялись, так как не могли контролировать построение конвейера, получали плохой тайминг итд.
Ваши примеры создают ощущения какой-то низкоуровневости, избыточности. Но тут сложно сказать - это моё непонимание или язык действительно избыточен.
Вообще говоря, если не идти во всякие монады (ввод-вывод), то ядро Хаскеля очень просто. Достаточно ну недели максимум. А вот если хочется углубляться, то оно бездонное - эти гады всё время что-то добавляют!!! :-)
Там много родственных вещей. Конвейеры из lazy evaluation функций высших порядков с point free нотацией (некоторые злопыхатели называют ей point less); всякие комбинаторы асинхронщины - Conduit:
complicatedConduit = print $ runConduitPure
$ yieldMany [1..]
.| takeC 10
.| mapC (* 2)
.| takeWhileC (< 18)
.| sinkList"прийдете"
серьезно?

Самая важная концепция, которую я усвоил на примере этого поста -- gatekeeping. Своих различаем, чужих не пущаем.
Наоборот, в этом посте я на пальцах показываю, что нужно выучить, чтобы пущали.
Мне на днях показали учебное пособие, в котором преподаватель расписывает процессор на конечном автомате (как это делает Роберт Донне или как его (ссылку на которого я привел). И не вводит конвейера, как и Донне. Если студент выучится по такому, то он не будет понимать, почему он не проходит интервью в компании.
Все опытные программисты прекрасно знают что такое конвейер , предсказание переходов, переупорядочивание инструкций , спекулятивное исполнение и разделение нагрузки на арифметические блоки. Видимо у автора просто недостаточный опыт программирования на си и ассемблере.
Мне показалось, что это просто замануха на грани:)
Неправильно предполагаете. У меня на си-компилятор есть в частности американский патент https://patents.justia.com/inventor/yuri-v-panchul
Я в этом посте показываю, что конвейер - это более общая концепция, чем конвейер инструкций в процессоре. Конвейер можно использовать для редактирования хедеров пакетов в роутерных чипах без участия процессора, изменения координат треугольников в GPU итд итп.
И одно дело - иметь научпопное представление о стадиях конвейера на словах, а другое дело - сделать минимальный пример конвейера на языке описания аппаратуры Verilog.
конвейер - это более общая концепция
Извините Юрий , но это очевидно любому программисту, да и не программисту тоже. И даже домохозяйке при готовке
Неправильно предполагаете.
Это не доказательство . У меня есть патент на использование псевдослучайных последовательностей в томографии https://patents.justia.com/inventor/dmitry-samsonov , но это не значит что я разбираюсь в чтении результатов томографии или в псевдо-случайных последовательностях
Господи боже мой, неужели мне предлагается померяться членами в Си и ассемблере? Ну ладно, уговорили:
Си: я автор трех компиляторов Си - двух на основе Portable C Compiler (еще в древнее время - для Электроники СС БИС и Орбиты 20-700) и одного транслятора из Си в Verilog, на который я получил инвестиции от венчурного отделения Интела и который продал Hitachi и Fujitsu - см. https://en.wikipedia.org/wiki/C_Level_Design Кроме этого я был членом индустриального комитета по стандартам Accellera по тематике использования Си для представления хардверных дизайнов в 2000-2001 годах.
Ассемблер: я с молоком матери, то бишь в 8-10 классах, выучил ассемблеры IBM/360, PDP-11, 8080 и Z80 на котором написал обработчики прерываний для многозадачности на MSX Yamaha в 1986 году, за что получил диплом первой степени на Всесоюзной Летней Школе Юных Программистов в Новосибирске.
Во взрослой жизни я работал в №1(в 1995 году) компании по симуляторам процессоров Microtec Reasearch, которая стала частью Mentor Graphics, которая стала Siemens EDA. В процессе работы над симуляторами мне пришлось использовать ассемблеры: Motorola 68K, Intel i960, AMD 29000, Hitachi SH (для которой я написал симулятор сам). x86 разумеется возникал в моей жизни неоднократно.
Затем я работал 10 лет в процессорной компании MIPS, в которой сначала занимался симулятором, потом верификацией и потом проектированием процессорного ядра как такового. Вы представляете как выглядят тесты на ассемблере внутри процессорной компании? Тесты не только на банальные случаи, а на форвардинг в конвейере, многопоточность, кэш-когерентность и т.д.?
Я кончил, теперь ваш черед.
Про z80 было смешно. Ну а я начал писать программы в 1979 в матклассе школы 57 при ВЦ академии наук на алголе-60 для БЭСМ -6 . Писал на все перечисленные Вами архитектуры.На 4 бита(sharp3511,3811) ,8(z80, 6502 ,....) 16, 32,64 итд. А также на селл, ларабее, GPU и прочую фигню для HPC( вот тут как раз и конвейеры) . И пишу до сих пор . У меня стаж программирования больше :) Первым использовал GP-GPU в промышленном коде(GE CT reconstruction 2005 ) вместе с появлением float32 в пиксельных шедерах у Nvidia. (120 fps on single node за $2000 вместо 40fps шкаф асиков за $200000 -GE показало на RNSA 2006). Кстати GPU на СТ реконструкции уделывают fpga как игрушечных.
И меня удивляет ваше заявление что программисты на си не могут ничего понимать в конвейерах и способах их организации на неоднородном или однородном железе.
Могут. Мне просто приходится в процессе своих образовательных проектов наблюдать муки, которые испытывают скажем программисты привыкшие к параллелизму в RTOS при решении простой задачки для верилога: написать блок с двумя valid/ready интерфейсами - один интерфейс принимает куски данных шириной N байт, а другой выдает куски данных шириной 2N байт. Так вот, так как люди интуитивно предполагают (из опыта программирования), что valid - это запрос, а ready - это ответ, то они ставят ready в ответ на valid, после чего блок не может принимать данные back-to-back (то есть трансфер в каждом цикле. И еще куча таких моментов.
module upsizing
#(
parameter W = 40
)
(
input aclk,
input aresetn,
input [W - 1:0] in_tdata,
input in_tvalid,
output in_tready,
output reg [W * 2 - 1:0] out_tdata,
output reg out_tvalid,
input out_tready
);Но все это еще куда ни шло, когда это естественные страдания у студента. Но вот тот же Роберт Дунни (ссылка выше) решил поучить молодежь, не дойдя до понимания сам. Все нетривиальные дизайны построены на конвейерах (CPU, GPU, сетевые чипы), поэтому курсы в которых он не вводится или вводится только с процессорами - это ущербные курсы с неправильным фокусом (совственно мой пост - это реакция на его случай).
В этом контексте Вы правы, но не обижайте программистов и хоббистов :)
output in_tready,
input out_tready
Это чтобы окончательно запутать врага ??? :)
Копипаст он такой копипаст... У любых программистов.
Это не копипаст. Здесь имеется в виду, что у блока есть два соседа - от одного соседа слева данные получаются, а другому соседу направо данные передаются. при этому блок должен сказать левому соседу что он готов данные принять (output in_tready), а правый сосед говорит блоку, что он готов данные получить (input out_tready).

Но вообще вы правы - и я поправлю эту задачку - для уменьшения confusion лучше использовать не префиксы in_/out_ , а upstream/downstream или up_ / down_, хотя это прийдется специально объяснять:
module upsizing
#(
parameter W = 40
)
(
input aclk,
input aresetn,
input [W - 1:0] up_tdata,
input up_tvalid,
output up_tready,
output reg [W * 2 - 1:0] down_tdata,
output reg down_tvalid,
input down_tready
);Правда тогда прийдется объяснять почему up находится слева, а down справа, но такое в микроархитектурных диаграммах сплошь и рядом (префиксы left/right не приняты)
Да, но здесь фактически два мастера - один блок слева (upstream) по отношению к блоку посередине, а второй блок посередине по отношению к блоку справа (downstream). И соотвественно два слейва - блок посередине по отношению к блоку слева и блок справа по отношению к блоку посередине. В качестве базы для протокола примера используется AXI Stream https://developer.arm.com/documentation/ihi0051/a/Interface-Signals/Signal-list?lang=en
неужели мне предлагается померяться членами в Си и ассемблере?
Вопрос независимым наблюдателям: кто в итоге победил?
Господа, прошу продолжать, я уже сбегал за попкорном.
Мой вариант ответов на вопрос #11: вариант c).
Поясняю. Комбинаторная имплементация выдаст решение в тот же такт в котором появлился сигнала run, но только после того, как устаканятся переходные процессы внутри всех вентилей схемы. Это самый медленый вариант с точки зрения пропускной спсобности (тактовой частоты), но самый быстрый с точки зрения момента - результат готов почти сразу. Секвенсерный вариант выдаст решение через шесть тактов: пять тактов вычисления и один загрузки/выдачи результата. Его макс частота будет зависить от того, как быстро распространится сигнал между умножителем, мультиплексором и регистром. С точки зрения частоты, это гораздо быстрее чем комбинаторная имплементация, но медленнее чем конвейрная. Конвейрная имплементация имеет пять ступеней, будет выдавать результаты непрерывно на каждый такт, но результат будет отставать от входного параметра на пять тактов. Частота тактирования конвейра определяется самой медленной ступенью, в данном случае это несколько одинаковых ступеней содержащих последовательно соединенные регистр и умножитель, что несколько короче чем "умножитель + мультиплексор + регистр" в секвенсерной имплементации. Жду предложений о работе из AMD. :)
PS: Программировать начал в 11 лет (в 1988), первый язык FORTRAN для ЕС ЭВМ. Далее ассемблеры всех мастей - 6502 (Atari), КР580ВМ80А, PDP-11 (БК/ДВК), x86, ARM. ПЛИСами занялся недавно, с января 2021, в следствии увлечения идеей RISC-V, появлении приличных HDL типа SpinalHDL и открытого тулчейна Yosys.
*** Комбинаторная имплементация выдаст решение в тот же такт в котором появлился сигнала run, но только после того, как устаканятся переходные процессы внутри всех вентилей схемы. ***
Тут недочет: комбинаторная иплементация вообще не использует сигнал run. Но все остальное правильно.
Насчет AMD: вопросы в этом посте для студентов, вопросы по мотивам интервью в AMD и другие конторы уровнем несколько выше, но они будут по плану в феврале, так что регистрируйтесь:
http://www.chipexpo.ru/shkola-sinteza-cifrovyh-shem-na-verilog
19 февраля 2022: 14. Имитиция собеседования на позицию проектировщика цифровых микросхем.
26 февраля 2022: 15. Разбор имитации интервью с вручением поощрительных призов.
Если хотите развлечься интервьюшными задачками прямо сейчас, вот три многократно заезженные в разных компаниях (два из них есть в сборнике таких задач на амазоне):
Напишите код, который генерирует сигнал с частотой в N раз меньше чем частота тактового сигнала, и при этом glitch-free (то бишь без импульсных помех) и с duty-cycle / скважность 50%. То есть при N=3 выходной сигнал должен состоять из полтора такта 1 и полтора такта 0.
Напишите код для очереди FIFO которая может каждый такт принимать либо один кусок данных, либо два, а также выдавать или один кусок данных или два за один такт. Как это обобщить для N?
Ниже код, который определяет с помощью конечного автомата, делится ли число из последовательности нуликов и единичек на 3. Каждая новая цифра последовательности возникает каждый такт и добавляется справа. Это старый интервьюшный вопрос, и его знает слишком много людей, поэтому поменяем условие: 1) напишите конечный автомат, который исходит из того, что цифры добавляются слева, а не справа и 2) напишите другой конечный автомат, который определяет остаток от деления на 7:
module fsm_3_bits_coming_from_right
(
input clk,
input rst,
input new_bit,
output reg [1:0] rem
);
reg [1:0] n_rem;
always @ (posedge clk)
if (rst)
rem <= 0;
else
rem <= n_rem;
always @*
case (rem)
2'd0: n_rem = new_bit ? 2'd1 : 2'd0;
2'd1: n_rem = new_bit ? 2'd0 : 2'd2;
2'd2: n_rem = new_bit ? 2'd2 : 2'd1;
default: n_rem = 2'bx;
endcase
endmoduleЮрий, про AMD это шутка юмора была. Старый я уже задницу отрывать от нагретого стула. :)
Про run в комбинаторной - протупил, в AMD не возьмут, однозначно!
Напишите код, который генерирует сигнал с частотой в N раз меньше чем частота тактового сигнала, и при этом glitch-free (то бишь без импульсных помех) и с duty-cycle / скважность 50%. То есть при N=3 выходной сигнал должен состоять из полтора такта 1 и полтора такта 0.
Неужели до сих пор такое спрашивают? И вообще, какой практический смысл в этом, особенно при наличии pll, где ещё и фазу можно задать?
Это вопрос с интервью в группу Apple которая проектирует и верифицирует SoC Apple Air лет 10 назад.
Практический смысл - напишите ответ, мы обсудим практический смысл.
Вы будете ставить тысячу блоков PLL в систему на кристалле чтобы генерить каждый левый сигнал?
Нет под рукой modelsim, но примерно так для нечетного N:
Два счётчика. Один по фронту, другой по спаду, два компоратора и rs триггер.
Но зачем в проекте делать тысячу левых сигналов?
rs-триггеры в коде для asic-в не используется (может их синтезирует quartus или vivado - не знаю). Идея в принципе правильная - использовать фронт и спад, хотя счетчик достаточно один, а спад использовать чтобы задержать сигнал регистрированный по фронту. Пример удобен для проверки базового владения верилогом (posedge / negedge, blocking / non-blocking, параметризация и generate для четных / нечетных).
Но вы правы что это элементарный пример. Хотите пример посложнее? Знаете схему контроля потока данных с помощью кредитных счетчиков?

А теперь внимание вопрос: как возвращать кредиты, если FIFO справа используется для clock domain crossing, то бишь если модуль на картинке и его downstream сосед справа работают на разных частотах асинхронных притом?
rs-триггеры в коде для asic-в не используется (может их синтезирует quartus или vivado - не знаю).
На d-триггере и логике можно любой построить. А для объяснения функционала удобно использовать более расширенную номенклатуру)
Хотите пример посложнее? Знаете схему контроля потока данных с помощью кредитных счетчиков?
Нет, не надо, я не на собеседовании) а бесплатно сложно работать.
Но стояла подобная задача лет 12...13 назад. Надо было гистограмму на лету считать.
А теперь вернёмся к вопросу практического применения "хитрых" делителей.
Я такого практически не применяю :-) только спрашиваю на интервью в начале отсева (потом перехожу к вопросам про AXI, FIFO и кредитные счетчики :-)
Напишите решение, если не облом, про делитель, сравним (там тонкий момент - избежать glitch-а)
А вот от меня задачка. Есть 8 отчётов по 8 бит. Функция fft. Напишите, пожалуйста, "шапку" модуля, как это будет выглядит у Вас?
module
(
input clk,
input....
output....
)
Вам нужно получать восемь 8-битных чисел за такт? Для передачи данных можно использовать двухмерный массив для порта, который разрешает SystemVerilog, то есть "input [n - 1:0][w - 1:0] data". Также можно использовать SystemVerilog interface. Для контроля flow я чаще всего использую не valid/ready, а credit-based интерфейс то бишь пару сигналов valid/credit_return (в некоторых компаниях пишут send/free). Если в одном такте посылается не ровно 8 чисел, а от 1 до 8, тогда можно использовать 8-битную маску указывающую какой из байтов valid. Для этого также нужно модифицировать credit_return чтобы можно было возвращать кредиты от 1 до 8. Если хочется экономить динамическое энергопотребление, можно на это навешать логику для инвертирования шины. Это то, что вы хотели услышать, или вы спрашиваете нечто другое?
Немного другое. Интересно, как Вы написали бы интерфейс. 8 отчётов на входе, 8 на выходе, тактирование и разрешение.
Да так же как выше, только два интерфейса - один на входе, другой на выходе. Данные и valid/credit на входе, данные и valid/credit на выходе. Поставил бы FIFO чтобы данные из конвейера внутри складировать и возвращать кредиты когда получатель берет из этого fifo. А вы как? (Я сейчас буду спать, то есть отвечу не сразу если вы чего-то напишете)
Вот как раз интересно как бы Вы описали входы и выходы. Входы я увидел, Выходы нет. Внутренняя часть стандартная, поэтому не интересно. Интересна только шапка модуля, именно интерфейс.
module fft
#(
parameter n = 8, w = 8
)
(
input clk,
input rst,
input [n - 1:0][w - 1:0] in_data,
input in_valid,
output in_credit_return,
output [n - 1:0][w - 1:0] out_data,
output out_valid,
input out_credit_return,
// Ну и тут можно для проверки статуса операции
// или если нужен интерфейс к внешней памяти
);Вы что-то такое хотите? Или какие-то специфически FFT штуки типа real, img ?
Давайте я попробую ответить, про сигнал в N раз медленнее.
Я бы сделал так: из опорного клока я бы сформировал импульсы отдельно по переднему и отдельно по заднему фронту (умножаем клок на его задержанную инверсию -получаем импульс. При этом задержка - не менее MPW для библиотеки), затем я бы эти импульсы сложил и получил частоту X2 (констрейнт - generated_clock -edges), затем поставил бы счетчик деления на N, а после него - делитель на 2 на одном флопе, чтобы выровнять скважность. Поскольку все работает от переднего и заднего фронта опорного клока, MPW не нарушается, и скважность 50% - задача выполнена, причем на стандартных селлах, синхронно и понятно тулу.
А кодом? Короче, вот моя версия распостраненного решения. Для n=3 оно есть в книжке Digital Logic RTL & Verilog Interview Questions by Trey Johnson (там правда собраны плоские вопросы, реальность тяжелее). Есть такой сигнал нужно использовать как clock, то его нужно пропустить через псевдомодуль global на альтере и BUFG в Xilinx):
module clock_divider
#
(
parameter [7:0] n = 3
)
(
input clk,
input rst,
output div_clk
);
reg [7:0] cnt;
always @ (posedge clk or posedge rst)
if (rst)
cnt <= 0;
else if (cnt == 0)
cnt <= n - 1;
else
cnt <= cnt - 1;
reg div_clk_unadjusted;
always @ (posedge clk or posedge rst)
if (rst)
div_clk_unadjusted <= 0;
else if (cnt == n - 1 || cnt == (n - 1) / 2)
div_clk_unadjusted <= ~ div_clk_unadjusted;
generate
if (n % 2 == 0)
begin
assign div_clk = div_clk_unadjusted;
end
else
begin
reg div_clk_negedge;
always @ (negedge clk or posedge rst)
if (rst)
div_clk_negedge <= 0;
else
div_clk_negedge <= div_clk_unadjusted;
assign div_clk = div_clk_unadjusted | div_clk_negedge;
end
endgenerate
endmoduleИнтересное решение, мне такое в голову не пришло. Но оно не корректно по одной простой причине - единственное известное решение по получению скважности 50% из "грязного" клока , это деление частоты в два раза на флопе с обратной связью. В вашем варианте выход комбинационный, наклоны сигнала зависят от летенси клока в двух параллельных путях, а такие пути никогда и ничем не выровнять даже в теории (из-за вариации параметров - процесса, среды и т.д.).
Итого, плясать надо от делителя на выходе. А поскольку коэфф. деления бывает дробный - надо поднимать частоту в два раза. Так получилось мое решение. Простите, много лет не писал на верилоге, вот так сходу не готов предложить код, только описание словами. Может быть позже опубликую - надо вспомнить синтаксис и где нибудь промоделировать. Или просто схему нарисую
*** наклоны сигнала зависят от летенси клока в двух параллельных путях ***
Не от latency (она меряется в тактах), а от propagation delay (он меряется в пикосенкундах).
Но вообще я согласен, что clock из этого будет грязноват. Но я же специально сформулировал не "сгенерить clock", а "сгенерить сигнал" :-)
*** Напишите код, который генерирует сигнал с частотой в N раз меньше чем частота тактового сигнала, и при этом glitch-free (то бишь без импульсных помех) и с duty-cycle / скважность 50%. То есть при N=3 выходной сигнал должен состоять из полтора такта 1 и полтора такта 0. ***
Не считайте придиркой, но latency - общий термин, измеряется в отсчетах времени (любых). К примеру, в STA это просто задержка сигнала insertion/propagation (etc.) delay - в пикосекундах, если угодно, а в логическом дизайне - в тактах если угодно. Ключевое слово - если угодно. Т.е. зависит от дисциплины и аудитории.
Объясните пожалуйста, что в первом задании имеется в виду под glitch-free
Что сигнал не будет дергаться вверх-вниз посередине такта
См. напр. https://www.eecs.umich.edu/courses/eecs270/270lab/270_docs/Glitches.pdf
Соединять можно разными способами. Либо все подряд - тогда можно сделать все за такт, но такт будет длинным (низкая частота). Либо разбить операцию на части и исполнять последовательно часть - поднять частоту, но делать все за много тактов, сначала с одном данным, потом с другим. Либо сделать так, что пока вычисляется вторая часть вычисления для первого по порядку данного, одновременно начать вычислять первую часть вычисления для второго по порядка данного, а промежуточные результаты хранить в регистрах (группах d-триггеров).
Полностью согласен. Программирование машины и процесс описания железа на HDL это два разных вида мышления. Последний кстати, чем-то пересекается с мышлением программиста на предикатных языках типа Prolog или Erlang - в них прцесс проистекает как бы параллельно по всем логическим веткам и это требует определенной гибкости мозга.
Радио-86РК не трожь!!
Конвеерные вычисления - частный случай параллельных, о которых не сказано ни слова. А между тем, параллельные вычисления - основа синхронной логики. И именно понимание параллельных вычислений проходит тяжелее всего, в т.ч. и в программировании.

Мне кажется, концепция становится понятнее, когда видно, что на каждой стадии конвейера оба множителя защелкиваются триггерами, что выравнивает задержку.
Конечно. Но до этого начинающему на верилоге нужно быть в курсе, что это существует. А я уже увидел несколько текстов, в том числе два свежих учебника по верилогу (одного этого Дунне, а другого - российского автора), в которых до конвейера не доходит дело. Все нетривиальные дизайны построены на конвейерах (GPU, сетевые чипы), поэтому курсы в которых он не вводится или вводится только с процессорами - это ущербные курсы с неправильным фокусом.
Статья огонь! Я сам наверное вообще посторонний человек - разве что в детстве видел схему Радио-86РК, Специалиста и прочего КР580ВМ80А и аналогах построенного, сам я больше по софту чем по железкам упарываюсь. Но мне понравились военкоматовские аналогии и ещё хорош концепт ментального рывка (вероятно в каждой профессии он свой, но везде есть - то, что отличает профи от любителя и где надо совершить это ментальное усилие)
Юрий, можете смело занести в черный список еще одну группу авторов: Noam Nisan and Shimon Schocken написали книгу по "железу" под названием "The Elements of Computing Systems: NAND2Tetris", в которой авторы пытаются обучить читателя проектировать простейшую ЭВМ на некоем своём придуманном языке HDL. Описанная в книге ЭВМ имеет 16-битную инструкцию в которой битами закодировано включение/отключение блоков. Машина одноступенчатая, без конвейера и без машины состояний. Слова: "pipeline", "state machine" и "FIFO" не упоминаются в книге вообще.
Да, я эту книгу хорошо знаю, но у меня к ней другая претензия. В принципе, если цель книги - научить не микроархитектуре / проектированию на уровне регистровых передач, а всему стеку - от физики до прикладных программ, то в ней использование однотактной машины допустимо. Но зачем автор изобрел свой HDL? Чем он лучше верилога?
Вот например HDL из книги NAND2Tetris:
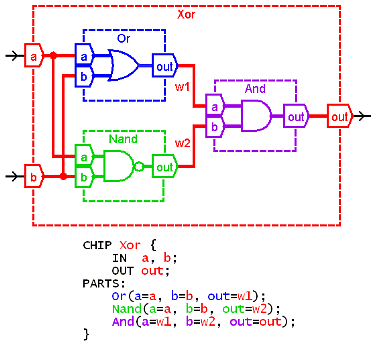
А вот то же, но на обычном верилоге, в трех вариантах реализации:
// Первый вариант реализации
module top1 (input a, b, output out);
assign out = (a | b) & (a ~& b);
endmodule
// Второй вариант реализации - с промежуточными соединениями
module top2 (input a, b, output out);
wire w1 = a | b;
wire w2 = a ~& b;
assign out = w1 & w2;
endmodule
// Третий вариант реализации - через подмодули примитивов
module top3 (input a, b, output out);
or or1 (w1, a, b);
nand nand1 (w2, a, b);
and and1 (out, w1, w2);
endmoduleНу и чем HDL из NAND2Tetris лучше, чем любой из этих вариантов? Бесплатностью тулов? Так для верилога есть бесплатный Icarus Verilog. Зачем переизобретать велосипед?
NAND2Testris напоминает игрушечные лопату и грабли из пластмассы для детей. Зачем они нужны? Как они помогают научить детей огородничеству? Детям можно давать настоящие лопаты и грабли из стали, просто меньшего размера, пусть копают настоящие грядки и высаживают на них рассаду помидоров, а не играются в огородничество.
Полностью согласен, тоже удивился когда начал читать. Они там еще свою Яву изобрели. :)
Юрий, посоветуй какую нибудь книгу в которой про внутренности микропроцессоров, в современном аспекте (суперскаляр, предсказатель, OoO, etc) напримере MIPS.
Вот хорошая книжка - Modern Processor Design: Fundamentals of Superscalar Processors by John Paul Shen, Mikko H. Lipasti
https://www.amazon.com/Modern-Processor-Design-Fundamentals-Superscalar/dp/1478607831
Если совсем с нуля, скоро выходит новое издание Харрис & Харрис на русском, там в главе 7.7 быстрое введение в вопрос на несколько страниц https://dmkpress.com/catalog/electronics/circuit_design/978-5-97060-961-3/
Насчет однотактных машин - чем машина из NAND2Tetris лучше чем schoolRISCV написанная на реальном верилоге и на подмножестве реальной архитектуры RISC-V? По уровню сложности они одинаково простые, но schoolRISCV привязана к реальному производству, а машина из NAND2Testris нет:
https://github.com/zhelnio/schoolRISCV

А зачем и кому вообще надо былр ставить такой вопрос? Кому и когда надо отличить любого профкссионала от лббого хиббитса?
Когда студенты спрашивают совета по литературе и нагугливают в интернете разные материалы (как от хоббистов, так и от профессионалов). От хоббистов бывают качественные, но ограниченные материалы (когда автор ни на что не претендует, помогать лампочками и подсоединить сенсор), но бывает, как с эти Дунне, которого я привел в качестве примера, когда автор не знает как это делается в индустрии, но пытается создать пример на основе интуиции из другой области, после чего решает что в индустрии иак якобы и делается.
Cпециалист по Windows GUI Петзольд в книге Code и специалист по ОС Minix Таненбаум в книге Компьютерная архитектура про микроархитектуру тоже пишут криво (напр. защелки вместо D-триггеров) и упускают ключевые детали (тайминг внутри такта) потому что их знание идет не от сохи, а он аналогии и эрудиции.
Также бывает совсем трэшак (я видел интернет статью с 30 тысячами просмотров, где автор пытался домыслить разницу между блокирующими и неблокирующими присваиваниями совсем невпопад, основываясь на наблюдении за временными диаграммами и вместо понимания очереди событий вводит ложную сущность "приоритет присваивания"), но это вообще суровые случаи, типа хоббист который ничего не читает, а просто играется и догадывается. Но про такие статьи тоже спрашивают - это хорошо изучать или нет.
Разрабатывть конвейеры на verilog это, конечно, хорошо. Но сегодня есть HLS. На c++ пишется алгоритм, на systemC интерфейс, задается количество ступеней, разрядность и т.п. и на выходе имеем готовый verilog с буфером. Это ведь удобней и быстрее. Особенно, если надо чуть изменить алгоритм, на verilog надо весь код перелопатить, а HLS это делает значительно быстрее.
Не спорю, основы надо знать, даже чтобы понять, что нагенерил HLS.
Вы надеюсь не считаете что процессор и GPU в каждом смартфоне задизайнен с помощью HLS? Или чипы в магистральных роутерах? В каком проекте вы встретили HLS? Или вы просто увидели маркетинговую презентацию говорящую что якобы вся индустрия выстроилась за HLS на SystemC? Дык такие презентации уже 30 лет ходят. Только в начале 1990-х это бы behavioral compiler без Си, в 1996 Synopsys стал говорить об этом клиентам, в 1998 выкатил SystemC, потом Cadence присоединился, Xilinx купил у стартапа такой тул для Vivado итд итп. Ну и что?
HLS используется во многих проектах. Перечислить где я участвовал не могу, nda не позволяет.
Друзья на катапульте делали цифровой многоканальный приемник (стандарт не назову, но обработка серьёзная).
Я делал на vivado HLS. Достаточно достойный продукт, учитывая, что начал работать с ним, как только он появился.
Сам к этому (HLS) скептически относился году, эдак 2006. Но сейчас проекты большие, модель устройства удобней и быстрее делать на c++, верифицировать также на этой же модели. Раньше приходилось с референсной модели делать verilog для тестов и верификации, что добавляло время и ошибки. А так есть модель, которая в Visual studio запускается, её можно протестировать. Потом делится на блоки (каждый класс - это модуль), добавляются интерфейсы на systemC, это отправляется в HLS, сгенерированный verilog через systemC подсоединяется к модели и верифицируется. Просто сказка)
Конечно, systemC это не панацея от всего. И этим инструментом надо правильно пользоваться. Здесь нет такого: тупо написал класс и это сразу будет работать. Надо понимать как работает железо (триггеры и комбинаторика), понимать что такое конвейер и правильно выбрать глубину, правильно задать параметры для компилятора. Но все равно это значительно облегчает работу и экономит время.
Я вам скажу такую вещь. Я лично работал с Расселом Клайном, менеджером в Ментор Графиксе в том числе проекта Catapult C. С ним я работал в 1996 году, а Catapult C он мне показывал в 2002 на Design Automation Conference.
Так вот между 1996 и 2002 годами я сделал стартап и написал ранний C -> Verilog тул который генерил FSM из Си-кода, а также позволял специфицировать конвейер специальным стилем под названием CycleC. https://en.wikipedia.org/wiki/C_Level_Design
У меня есть патент на это дело, который приобрел Synopsys - https://patents.justia.com/inventor/yuri-v-panchul
Про это даже писали обозреватели, что мой тул победил SystemC - см.
http://www.deepchip.com/items/dac01-08.html( DAC 01 Item 8 ) ---------------------------------------------- [ 7/31/01 ]
Subject: Forte/CynApps, C-Level, CoWare, SystemC, Frontier, Y Explorations
THE NEXT GENERATION: On two levels, Synopsys has been horribly embarrassed
in pioneering SystemC as the "wave of the future". The first embarrassment
came from the poltical fiasco around getting SystemC out as a supposedly
"independent" standard. Too many people kept walking out loudly saying
SystemC was a Synopsys scam. And this happened multiple times! Ouch. The
second embarrassment for Synopsys here is, after all this grief, C-Level's
"System Compiler" is beating the crap out of Synopsys's "SystemC Compiler"!!
Three months ago at SNUG'01, Dan Joyce of Compaq reported the first C-Level
tape-out. Below, I have 6 more designers reporting either that they're
using C-Level "System Compiler" for current designs or that they've already
taped out with C-Level. In contrast, there's only 1 guy around talking
about using Synopsys "SystemC Compiler" for a design plus a lot of other
user letters saying how they tried but couldn't get SystemC to work! Ouch!Forte/CynApps' special CynLibs flavor of C classes seems to be capitulating
to the massive marketing arm of Synopsys SystemC. They're talking about
'merging' their CynLibs with SystemC.Frontier, Y Explorations, and CoWare seem to be forgotten sideshows here.
Out of the 182 customer responses I got for this report, these 3 companies
were only mentioned once (each).
Так к чемпу это я говорю. Это все очень мило, и я понимаю, что прошло 25 лет, но до сих пор в CPU, GPU, роутерных чипах HLS используют очень мало, в периферийных местах и говорят "легче написать конвейер ручками, чем массажировать HLS прагмами". А для дизайнов типа конвейера CPU с форвардингом HLS вообще не вписывается. (вы можете нагулить в LinkedIn места моей работы)
Вообще насчет SystemC, вы не представляете ужас и отвращение инженеров, использующих долго верилог, когда они пытались еще 20 лет назад пользовать SystemC и получали какие-то ошибки на целый экран внутри templated классов (но это отдельная история, у меня есть про это пост в ЖЖ - https://panchul.livejournal.com/473865.html )
Про это даже писали обозреватели, что мой тул победил SystemC - см.
Причём здесь тул и systemC?
говорят "легче написать конвейер ручками, чем массажировать HLS прагмами".
Да, я писал выше, что если внести изменения в алгоритм, то "настоящим пацанам" проще ещё недельку-другую потратить на переписывание конвейера на verilog :)
А изначально настроить прагмы и добиться хорошего результата, а затем пользоваться и дополнять - нет, это не наш метод.
Вообще насчет SystemC, вы не представляете ужас и отвращение инженеров, использующих долго верилог, когда они пытались еще 20 лет назад пользовать SystemC и получали какие-то ошибки на целый экран внутри templated классов (но это отдельная история, у меня есть про это пост в ЖЖ - https://panchul.livejournal.com/473865.html )
Отвращения, если описывать элементарную логику, как в книжках. А если использовать по назначению - даже удобно.
Всё программы на начальной стадии (и не только) глючат и дают ошибки. Та же vivado HLS с классом cfft в начале без ошибок просто вылетала, потом просто учитывая нюансы работы с ней.
*** Причём здесь тул и systemC? ***
Я имею в виду SystemC Compiler, HLS тул, который Synopsys пытался продавать в 1998-2002 годах
Ничего на месте не стоит. Все развивается.
Оно просто еще не развилось и не разовьется в обозримом будущем до состояния, когда можно сказать "молодежь, забудьте про ручные стадии конвейера, ручной анализ пикосекунд из STA, skid-buffers, байпасы, расчет длины FIFO, которое стоит после конвейера для приема результатов и кредитные счетчики. Просто напишите высокоуровневое описание на Си, помассажируйте его прагмами и тул все расчитает и расставит по стадиями конвейера за вас. Даже количество банков у всех используемых памятей определит и сделать для них азделение между читателями и писателями".
Если бы он развился, это было уже было во всех компаниях, чего мы не наблюдаем.
А такого никто не обещает. Чтобы использовать HLS, нужно понимать как это работает. И пока человек не научится понимать поведенческие модели, HLS с прагмами будет как в басне "мартышка и очки".
Но изучать и пользоваться инструментами, которые облегчают работу более правильно.
Это как печатные платы разводить: можно вручную, а можно автоматом. В первом случае чтобы подвинуть bga, надо пол платы перелопатить. Во втором случае, надо потратить время, чтобы описать стратегию разводки, тогда двигать детали на много проще.
Как отличить начинающего профессионала от умудренного хоббиста в цифровой схемотехнике?