Very often we've heard that some frameworks fit together so good, that they are considered as "match made in heaven". In this article I would like to share our experience regarding integration of those frameworks.
Introduction
Recently we were investigating possibility to introduce some kind of business automation framework in our quarkus-based set of microservices. Quarkus has acquired rather big amount of libraries and is steeply evolving from the niche solution to the set of libraries, which can solve problems of different nature. For business automation quarkus framework suggests usage of kogito framework. This is a collection of well established frameworks like drools, jbpmn, optaplanner with ability to be executed as cloud-native services. Knime is well known data analytics platform and while analytics platform is available as open source solution, knime servers are available only by subscription. Therefore we've got an idea to create a prototype, where we have trained a model using knime data analytics platform and then embed it into kogito on quarkus, compile it in native mode using GraalVM and host on kubernetes platform.
Oversimplified use case
For our prototype we have taken following use case: based on location we would like to retrieve recommendations regarding outerwear.

Surely, this use case could be implemented in kogito using simple gateway, as shown on the picture, but our idea was to incorporate decision tree model resulting from Knime data mining into kogito model.
Technical implementation, 9000 feet view
Technical implementation of the prototype includes rest-based service, which accepts location as input parameter, then connects to openweather api to get current weather in the location provided and provides this information to the decision model. It uses embedded decision tree model, exported from knime, for making decisions. Result of decision (generally T-Shirt or Winter Jacket or Magenta T-Shirt or Magenta Winter Jacket for Bonn location) is returned to the service consumer.

Technical implementation, closer look
As it described in many quarkus kogito tutorials, creation of a project with dmn inside is a pretty simple task (see for example https://quarkus.io/guides/kogito). Generally we create the new quarkus project with enabled kogito extensions, then create model classes and then design dmn. In our case we were using openapi generator (api first approach) to automatically generate interface classes out of rest interfaces (for out prototype and for openweather service). Doing so we could skip writing them manully.
Auxiliary classes
To provide mapping between internal dmn classes and to create rest-client for consumption of openweather api, we have created additional classes.

with following content:
WeatherRestClient.java:
@Path("/weather") @RegisterRestClient(configKey="weather") public interface WeatherRestClient { @GET @Produces("application/json") Model200 get(@QueryParam("q") String location, @QueryParam("appId") String applicationId, @QueryParam("units") String units); }
ClothesResponse is just a simple dto for internal model represenation with fields:
private Main main; private Clothes clothes; private String location;
WeatherMapper is just a simple mapper from internal representation to external representation using mapstruct library:
@ApplicationScoped @Mapper(componentModel = "cdi") public interface WeatherMapper { default Clothes mapResponseToClothes(ClothesSelectorResponse response) { return response.getClothes(); } }
WeatherService contains some logic to invoke rest client and provide default answer:
@ApplicationScoped public class WeatherService { @Inject @RestClient WeatherRestClient weatherRestClient; @ConfigProperty(name="weather.appId") String applicationId; @Fallback(fallbackMethod = "defaultWeather") public Main get(String location) { Model200 weatherModel = weatherRestClient.get(location, applicationId,"metric"); return weatherModel.getMain(); } public Main defaultWeather(String location) { Main main = new Main(); main.setTemp(new BigDecimal(0.0)); return main; } }
Main.class for openweather structure is not an intention to introduce bad practices it is named so in original openweather api specification, so for prototyping purposes it is left as is.
BPMN and DMN
Having all the stuff prepared, it's time to create BPMN and DMN in it. We skip here detailed description, how to create such kind of model, just concentrate on some basic stuff.

The "Get weather by location" and "Map internal representation to external" custom tasks are just invocations of WeatherService.get and WeatherMapperImpl.mapResponseToClothes.
The "REST" rectangle is rather interesting here, namely this is an REST endpoint to invoke embedded DMN with following definition:
[ [ "name" : "Rest", "parameters" : [ "Url" : new StringDataType(), "ContentData" : new ObjectDataType(), "Method": new StringDataType, "Host" : new StringDataType(), "Port" : new IntegerDataType(), "Username" : new StringDataType(), "Password" : new StringDataType() ], "results" : [ "Result" : new ObjectDataType(), ], "displayName" : "REST", "icon" : "defaultservicenodeicon.png" ] ]
with following settings:
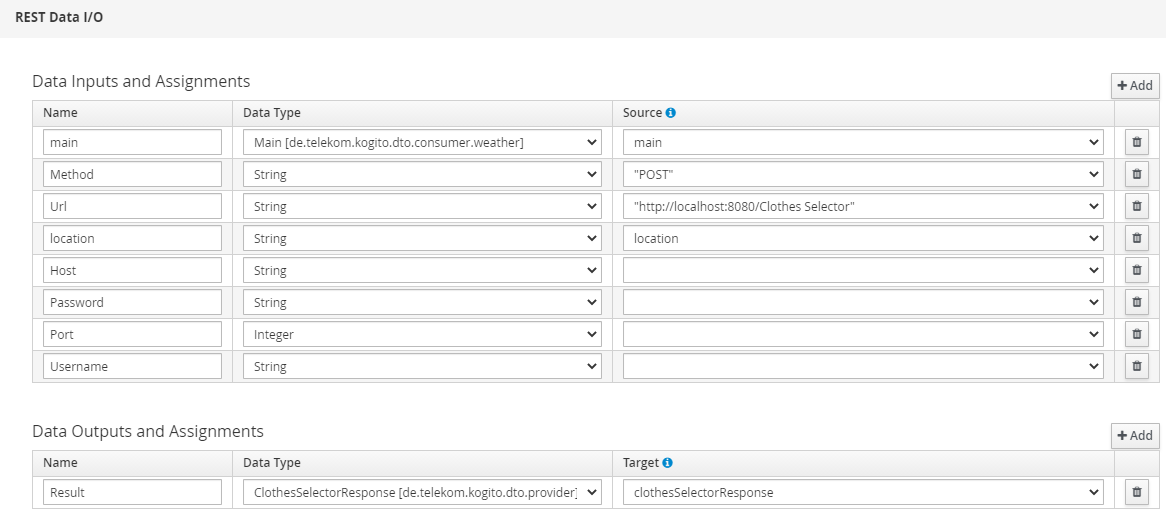
Clothes Selector is in this case the name of the embedded DMN.
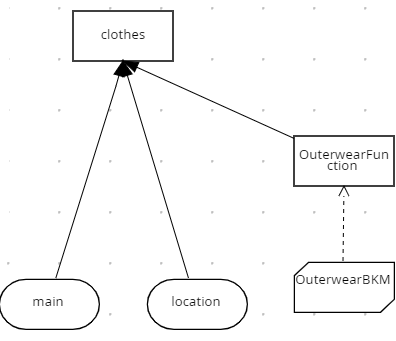
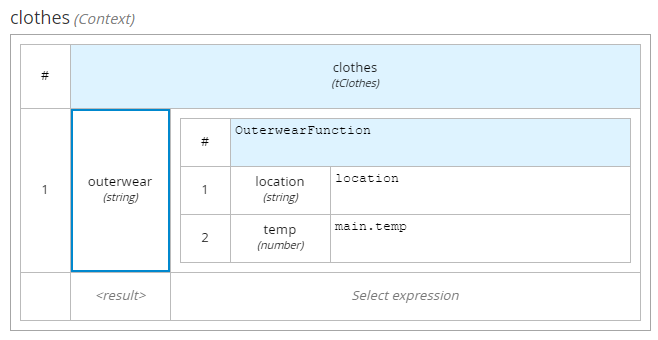
So, there are 2 input structures (main with weather information and location with location information). The stuff on the right hand side represents Function based on embedded pmml and it's invocation.
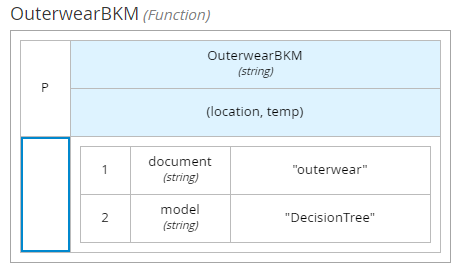
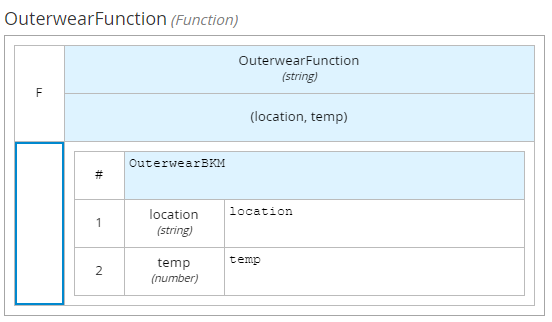
Finally in clothes decision DMN we use dmn context to put result of function invocation to the right field inside of tClothes structure.
PMML model
To get trained model for providing decisions, which outerwear to take based on location an temperature we will use Knime data analytics platform.
The input data are delivered as csv file with following information:

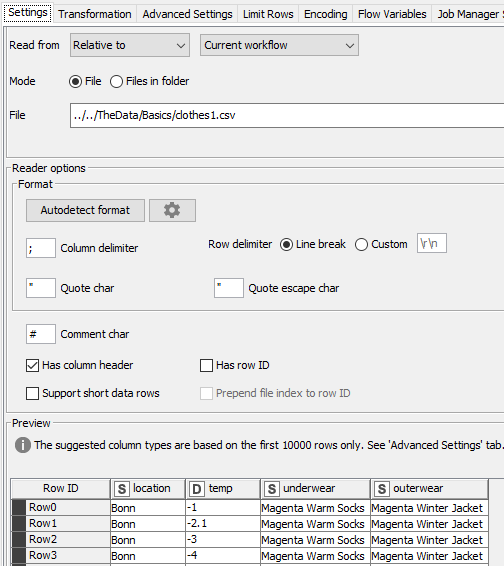
So we are building decision tree model using location and temp as input data and outerwear as decision data. Underwear column is skipped in framework of this prototype.

Input data are split into data, which are used for model training and data (80%), which are used for test execution (20%)
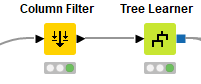
Result of Decision Tree Learner is saved as model in pmml format.

So, after successful learning of the model it is exported to the pmml file, which later on should be imported to the dmn model.

Putting all together
Having all preparations, described above, done, we can write unit tests (we do so by sending some requests to external rest interfaces of the application) and execute it in jvm development mode. There are some error messages in the logs, if the kogito data index url is missing (i.e. endpoint for kogito indexing), so for development profile you might suppress them using following settings:
%dev.kogito.data-index.url=http://localhost:8080
When you execute application in the development mode, you can easily access not only external interface of the application, but also internal model interfaces (also they are listed in swagger-ui).

The final step is to provide correct compilator configuration for successful native compilation. Generally you should list all the resources, which you need inside of application, mark all classes, where reflection is used and specify classes, which shouldn't be initialized in compile time. In our case all the models (dmn, bpmn, pmml) should be listed as resources for native compilation.
Over last 2 years GraalVM error messages have been significantly improved, so that they give you now rather clear instruction which exactly classes should be initialized in the runtime. In complicated cases you still have possibility to use tracing agent.
Running application in the native mode you have following benefits:
significantly less resource consumption
much shorter start times
smaller size of docker image
There are following drawbacks:
models are fixed during native compilation, so there is no chance to change them in runtime
correct configuration of compiler options might be tricky in cases when libraries of different nature are used inside of application
Conclusion
As the result of this prototyping activity we have created a way to create native quarkus rest-based services, which include as a decision tree any externally trained models. In our case most suitable mean to train such kind of models was Knime analytics platform.
In the follow-up article I want to describe more complicated scenario, when you need to embed more than one pmml model into dmn. Surprisingly, during configuration we have faced with some difficulties, so it might be interesting for the audience to have a look at our approach for solving them.
