Контекст
В настоящее время многие программные системы полагаются на обработку потока событий в реальном времени. При обработке потока событий согласование данных является важным этапом/процессом, который необходимо выполнить для обеспечения полноты и целостности данных.
Особенно в приложениях на основе SOX полнота и целостность данных играют ключевую роль в обеспечении соответствия программных систем SOX.
Постановка задачи
Большинству организаций требуется согласование данных в потоках событий (Fast Data — обработка больших объемов данных) в режиме реального времени. Выявление пропусков и согласование огромных объемов данных в ручном или пакетном режиме не отвечает требованиям и не является эффективным. Наряду с этим часто существуют специфические требования бизнеса/системы к выполнению произвольных действий, основанных на времени, прошедшем до успешного согласования. Такие действия, основанные на времени, могут длиться от нескольких секунд до нескольких часов.
Что такое согласование данных?
Согласование данных — это процесс сопоставления события с другим событием на основе некоторого ключа события. В контексте текущей проблемы:
Сообщение будет считаться успешно согласованным, если «механизм согласования» (Reconciliation Engine) получил сообщение для данного ключа из всех различных источников.
В случае, если сообщение для данного ключа не получено из одного или нескольких источников на основе заранее определенного бизнес-кейса (например, время, прошедшее с момента первого сообщения), такие сообщения должны быть помечены как несогласованные/непринятые сообщения.
На приведенной ниже схеме сообщение K1A1 представляет сообщение с ключом ( K1 ) и A1 в качестве соответствующей полезной нагрузки сообщения от источника Source_A. Чтобы это сообщение с ключом K1 было согласовано, все источники должны выдать сообщение с ключом K1 и их полезной нагрузкой, специфичной для источника.
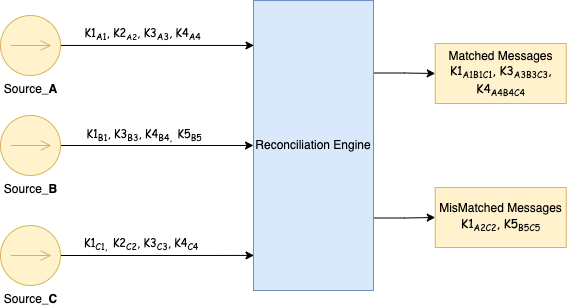
Возможные подходы к согласованию данных в режиме реального времени
Согласование данных Fast Data в режиме реального времени можно разделить на два основных этапа, как указано ниже:
1. Определение пропущенных сообщений на основе заданного ключа сообщения
2. Согласование данные с источником с использованием идентифицированного пропущенного ключа
В этой статье мы сосредоточимся на первом шаге выявления пропущенных сообщений в режиме реального времени. Возможные подходы для второго шага будут обсуждаться в моей следующей статье. Давайте проанализируем три шаблона, используемые для выявления пропущенных данных, а именно:
1. Идентификация на основе базы данных
2. Идентификация состояния в памяти — шаблон Event Sourcing
3. Идентификация состояния в памяти — шаблон Event Sourcing с использованием CQRS
1. Идентификация на основе базы данных
Это наиболее часто используемый подход, при котором база данных интенсивно используется для управления состоянием. Как показано на схеме ниже, сообщения из всех источников поступают в базу данных согласования, и база данных в основном используется для управления состоянием.
Как правило, в базу данных вставляется событие из первого источника. Впоследствии события из других источников с совпадающим ключом добавляются/вставляются (append/upsert) в существующее событие. Upsert включает в себя чтение, за которым следует операция обновления. Необходимо создать запланированный процесс, выполняемый через определенные промежутки времени, чтобы извлекать записи, которые имеют/не имеют всех необходимых источников, чтобы сделать сообщение полным, основываясь на доступности source_A, source_B и source_C.

Таблица согласования:
С точки зрения временной последовательности, приведенная ниже последовательность представляет базу данных с разными порядковыми номерами.

В приведенной выше таблице представлена последовательность, в которой события вставляются в базу данных. Как правило, вставляемые атрибуты данных включают в себя ключ сообщения о событии, состояние сообщения и флаг, показывающий, что данные были получены от конкретного источника.
Как показано выше, с каждым новым источником сложность времени и пространства будет экспоненциально возрастать для обновления последнего состояния, и в конечном итоге столбец состояния может стать очень большим. Временно-пространственная сложность будет увеличиваться, поскольку при каждой новой записи все данные о состоянии извлекаются, а затем перезаписываются после добавления входящего сообщения.
В приведенной ниже таблице описывается временная сложность выполнения вышеуказанных операций:
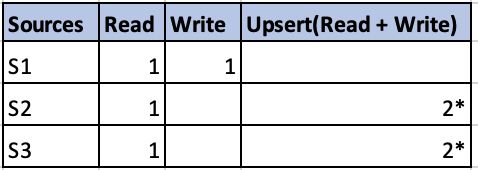
* Как правило, операция upsert в два раза дороже, чем простая запись. Кроме того, так как при этом считывается все объединенное состояние для данного ключа и записывается снова, это может быть неэффективно.
Наряду с вышеуказанной стоимостью частота запланированного процесса также повлечет за собой дополнительные затраты на операции БД, поэтому придется искать компромисс между гранулярностью интервала запланированного процесса и стоимостью операций БД. Более частые временные интервалы увеличат стоимость операций БД, а более длительные интервалы вызовут задержку в определении согласованных сообщений.
Плюсы этого решения:
Позволяет вам создавать приложения без сохранения состояния, при этом управление состоянием выполняется исключительно на уровне базы данных.
Легковесное на уровне кода приложения и тяжелое на уровне базы данных. Это упрощает обслуживание приложения.
Минусы этого решения:
Для создания легкого приложения большая часть сложности передается на уровень базы данных, что требует от нас выбора очень производительной и дорогостоящей БД.
В облачной модели БД понесенные затраты прямо пропорциональны количеству операций чтения и Upsert. При таком интенсивном подходе с большим количеством операций БД стоимость облака может быть выше.
Размеры индексов могут значительно вырасти, и их необходимо тщательно спланировать, чтобы обеспечить уменьшение задержки записи и ограничить стоимость БД.
Меньший интервал запланированного процесса повлечет за собой очень большие затраты на БД, а больший интервал запланированного процесса приведет к задержке в определении совпадающих/несовпадающих заказов. Поэтому может быть сложно найти правильный баланс между запланированным интервалом процесса и приемлемой задержкой в идентификации.
Поскольку каждая запись всякий раз добавляется к существующему состоянию в БД, результирующая запись может стать очень большой в зависимости от количества источников и размеров полезной нагрузки сообщения. Возможно, мы захотим использовать шаблон проверки требований, чтобы позаботиться об этом и гарантировать, что тобеспечить передачу только ключевой информации менеджеру состояний.
2. Идентификация состояния в памяти — шаблон Event Sourcing
В первом подходе мы видели, что для согласования было много активности БД. Мы можем уменьшить эту активность БД и избирательно выбирать, когда действительно нужно обращаться к БД с помощью нового подхода, как показано ниже. Мы можем сделать это, реализовав Event Sourcing, а также воспользовавшись преимуществом персистентности распределенного приложения, которая может поддерживать состояние ключа сообщения в памяти распределенного приложения. (Есть хорошие технические фреймворки, которые поддерживают ее «из коробки». Фреймворк Akka EventSourcing — один из них).

Согласно этому подходу, каждое сообщение будет сохраняться в базе данных как событие, а состояние в памяти будет обновляться в соответствии с текущим состоянием. Исходя из требований, состояние памяти для ключа события может сохраняться до тех пор, пока не будут выполнены критерии бизнес-кейса «совпадение/несовпадение сообщений». Как только ключ будет идентифицирован как совпадающий или несовпадающий, все необходимые события могут быть опубликованы на выходе, а состояние в памяти может быть отброшено. В случае какого-либо сбоя состояние в памяти может быть пересчитано из событий, уже хранящихся в базе данных записи с источниками событий. Состояние события также можно зафиксировать как моментальный снимок, если мы хотим сократить время восстановления.
С точки зрения временной сложности приведенные ниже операции будут выполняться всякий раз, когда сообщение с заданным ключом будет соответствовать данному шаблону.

Как мы видим, это решение значительно снижает временную сложность согласования и работает лучше, поскольку мы продолжаем добавлять больше источников для согласования. Однако это решение может работать лучше, если мы сосредоточимся только на совпадающих сообщениях. Выявление долгосрочных несоответствий может увеличить сложность решения.
Плюсы этого решения
Временная и пространственная сложность значительно снижается, так как выполняются только операции записи, а операция чтения не производятся, если только не выполняется аварийное восстановление. Кроме того, этот подход не выполняет каких-либо обновлений, которые обычно являются самой дорогостоящей операцией.
Поскольку этот подход является легким на уровне базы данных, стоимость облака значительно снижается по сравнению с первым подходом.
При таком подходе логика приложения может обеспечить огромную горизонтально масштабируемую базу данных, дающую большую гибкость, производительность и преимущество в стоимости БД.
Он обеспечивает более высокую производительность, поскольку операции выполняются в памяти, что позволяет избежать задержек в базе данных и сети.
Минусы этого решения
Создается приложение с сохранением состояния, поэтому при разработке решения обычно требуется больше времени на обдумывание.
Легковесное на уровне базы данных и тяжелый на уровне приложения, что увеличивает затраты на обслуживание.
Это решение может работать лучше, если количество совпадающих сообщений, как правило, намного больше, так как состояние в памяти будет продолжать освобождаться по мере согласования записей. Долгосрочные несоответствия могут значительно увеличить размер состояния в памяти, если только для его обработки не будет предпринято несколько других действий (третий подход, рассматриваемый ниже), чтобы справиться с этим.
3. Идентификация состояния в памяти — шаблон Event Sourcing с использованием CQRS
Как упоминалось выше, одним из недостатков во втором подходе было то, что иногда состояние в памяти могло стать большим. В таком случае мы можем расширить подход 2, включив в шаблон Event Sourcing с использованием принципа разделения ответственности за запросы и команды на обработку данных CQRS (Command and Query Responsibility Segregation ). Это поможет реализовать чистое моделирование предметной области, где можно разделить ответственность за команды и запросы, а модели запросов могут быть расширены для обработки нескольких сценариев использования в зависимости от системных требований. Обновленная диаграмма с этим подходом будет выглядеть следующим образом:

Как показано выше, при таком подходе нам не нужно считывать все объединенное состояние и обновлять его обратно. База данных запросов или состояние приложения могут использоваться выборочно (вот почему пунктирная линия из двух источников) для идентификации согласованных и несогласованных сообщений, чтобы обеспечить идентификацию в реальном времени и не беспокоиться о гранулярности интервала запланированного процесса. Это позволит изолировать логику команд и запросов, чтобы обеспечить разделение задач и независимое масштабирование.
Плюсы этого решения
Задачи команд и запросов разделены, при этом модель запросов не должна иметь дело с состоянием.
Возможность независимого масштабирования, а также гибкость в выборе различных типов БД в зависимости от сценария использования.
Чтение будет более производительным. Поскольку чтение выполняется чаще, чем запись, общая система будет наиболее оптимальной.
Минусы этого решения
Создаются 2 базы данных, которые могут потребовать дополнительного обслуживания.
Согласованность данных между чтением и записью, возможно, должна быть хорошо спроектирована, наряду с решением проблемы конечной согласованности.
Заключение
Все упомянутые выше подходы имеют свои преимущества и недостатки. В зависимости от требований:
Первый подход может быть лучше, если мы не имеем дело с огромным объемом данных и предпочитаем приложение без сохранения состояния. Однако, возможно, будет сложно масштабировать БД, учитывая задержки и стоимость для больших объемов данных.
Второй подход может быть лучше, если мы хотим обрабатывать огромные данные в быстром темпе с меньшими задержками и затратами на БД и ориентируемся в первую очередь на согласованные сообщения.
Третий подход также может подойти, если нам нужно обрабатывать большой объем данных в быстром темпе и необходимо обрабатывать динамические сценарии для обработки как совпадающих, так и несовпадающих сообщений. Однако он может потребовать больше усилий по обслуживанию.
Выше приведены некоторые из подходов, с которыми я экспериментировал при согласовании данных. Пожалуйста, оставляйте комментарии или пишите по электронной почте, чтобы поделиться любыми замечаниями/отзывами/предложениями по вышеупомянутым подходам. Буду рад получить дополнительную информацию.
