In this article, I would like to describe how we’ve tackled the document recognition issue mostly with the help of OCR, BERT and Yandex’s Natasha, with the end goal being extraction of entities for reconciliation followed by a payment. Abby FineReader is a well-known optical character recognition application developed by ABBYY. BERT is an open-source transformer-based ML framework used for a variety of NLP tasks pre-trained by Google on 3.3B words. Natasha is currently a set of open-source NLP tools for the Russian language that solves such tasks as tokenization, sentence segmentation, word embedding, morphology tagging, lemmatisation, phrase normalization, syntax parsing, NER tagging. The quality of every task is similar or better than current state-of-the-art for the Russian language on news articles.
Just imagine countless textual documents even a medium-sized organisation deals with on a daily basis, let alone huge corporations. Our company, for example, collaborates with hundreds of suppliers, contractors and other counterparties, which implies thousands of contracts. For instance, the estimated number of legal documents to be processed in 2022 has been over 70,000, each of them consisting of 30 pages on average. During the lifecycle of a contract, it is usually updated with 3 to 5 additional agreements. On top of this, a contract is accompanied by various source documents describing transactions. And in the PDF format, too.
Previously, the processing duty befell our service centre’s employees who checked whether payment details in a bill match those in the contract and then sent the document to the Accounting Department where an accountant double-checked everything. This is quite a long journey to a payment, right?
The human factor added to the problem: the task of entering information into an ERP system is not your dream job and is quite mundane, which significantly affects the quality of the resulting data, not to mention that the entire process is relatively slow: according to our calculations, it takes about 3.5 minutes for an employee to process one contract. In addition, employees extract entities from documents only partially, for specific purposes, while all entities contain valuable information that we could use for other projects.
Here comes our document recognition task.
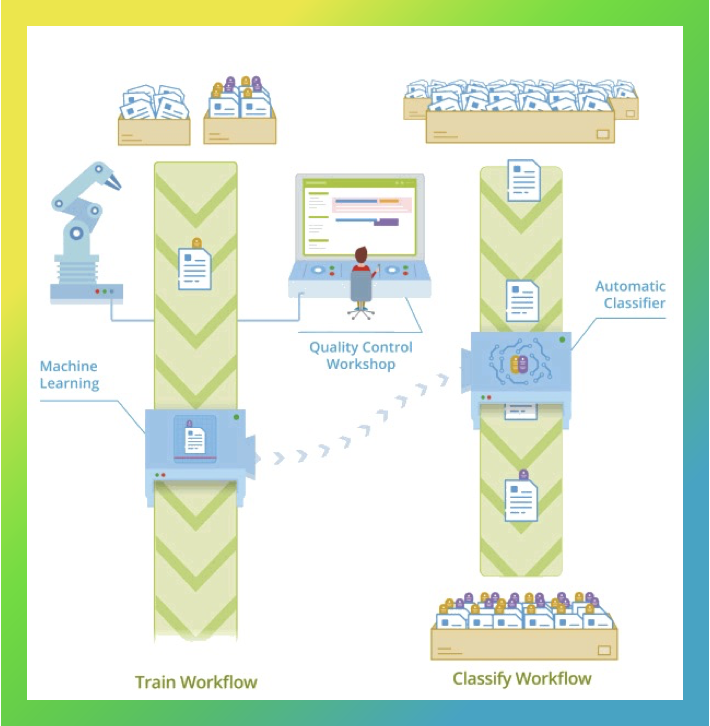
The contemporary tech space offers multiple intelligent document recognition solutions but none of them quite befitted our purposes (aside from, probably, ABBYY FineReader) because we needed a universal solution.
Typically, for optical character recognition (OCR) tasks, flexible templates put on top of the document structure are used. If the structure is the same, the information is retrieved with high quality. The same process is applicable to tables. It may seem like recognising tabular data is a simple problem because structure is virtually the definition of a table. But there are some buts here. For example, different types and formatting of the cells, or wrong association between a cell and the text it contains, in the OCR results.
With this problem in mind and having carefully considered all pros and cons of creating our own product, we’ve come up with a solution that works for all kinds of tables. And here is how: a flexible template first recognises the borders of the table, with three JSON files containing the border coordinates, a textual layer and metadata on the recognition results generated, and then recalculates them, eliminating inaccuracies in the coordinates. This way we can have the coordinates of all elements of the table, and it is quite easy to proceed from there with the usual NLP tasks. In some respects, this solution is unique and is the heart of our proprietary AI platform. We are currently in the process of migrating from ABBYY FR to a more sophisticated OCR solution developed on site.
As for the architecture specifics, the system includes the source and target systems, which is our ERP system, PDF documents to be processed, and the AI platform itself, with an integration layer between SAP and the platform. First, the system recognises the document structure, then classifies the documents and pastes together contracts with additional agreements, after which relevant entities are finally extracted.

One of the problems that we faced at the first step was some loss of information because some of our entities were handwritten and, besides, had stamps upon them, which was problematic for ABBYY FR to process. This situation, however, was not common as it occurred only in 3% of the cases. Another issue was data corruption due to low quality of scanned documents, some of which dated back to the 1980s.
Then comes the second stage where we recognise a document structure using fundamental models to segment the document into sections, classify the segments and pages, as well as to recognise individual clauses and subclauses in legal texts. All entity extraction models heavily depend on this step because they look up only certain sections of the contract to ensure better quality of entity extraction. The same goes for the model joining documents together because we need first to recognise the amendment type (these being removals, additions or replacements) and then to amend the contract accordingly.
Our next AI model classifies incoming documents into groups, such as contracts vs. additional agreements, and further, into more specific groups like signed vs. unsigned contracts, and so on. This step eliminates the need for manual selection of the document to be recognised and provides for downloading documents en masse.
The contract joining model is followed by the entity extraction models. Speaking of the types of entities, we saw that dates and numbers of contracts and signatures, as well as amounts showed good recognition quality of more than 80%. Addresses, names and positions, however, required further refinement. The most problematic ones, with the quality of less than 70%, were signing dates, contract start and end dates, and the subject of the agreement, and these are the top-priority entities for labelling.
In our workflow, the models extract up to 44 entities from every contract and additional agreement and up to 20 entities from source documents. All the entities from the updated contract are then reconciled with those from the relevant source documents. And if there is a match, an auto payment can be made.
Seeing as 100 people out of 149 employees of our service centre are engaged in reconciliation activities, the solution we have offered will greatly optimise the headcount in the centre as well as speed up the reconciliation process (1 minute vs. 3.5 minutes).
As for the quality of the document processing as measured with standard metrics such as precision, recall and F-measure, our models have shown the accuracy of 90% for the majority of the entities vs. expected 60%.
Another important implication of this project is that we have received valuable historical data that can be further used in other projects and for decision-making.
We have been continuously improving this project and trying to form a common understanding of the labelling, development and validation processes with the business customer. Seeing that the entity extraction quality is directly related to the labelling quantity/quality and that only the business members of the team can expertly assess what entities must be extracted, we have needed their help with additional labelling because some fundamental models (like section or page classification, or (sub)clause extraction models) require retraining with more data. The business customer’s engagement in the results validation and motivation of the team responsible for the related work on the ERP system and development of the integration layer are also important.
