В этом посте будет проанализировано, как каналы Unix реализуются в Linux. Для этого мы напишем и в несколько итераций оптимизируем тестовую программу, которая записывает и считывает данные через канал1.
Сноска 1
Стилистически эта работа будет напоминать исследование производительности на примере atan2f, которое я ранее уже публиковал у меня в блоге, хотя, та программа, которую мы рассмотрим, будет полезна только в качестве учебного материала. Более того, мы оптимизируем код на ином уровне. В то время как тонкая настройка atan2f заключалась в микро-оптимизациях на основе ассемблерного вывода, при настройке нашей программы с каналами нам придется уделить внимание событиям perf и сократить разнообразные издержки в ядре.
Начнем с простой программы, чья пропускная способность составляет около 3,5 гибибайт/с и двадцатикратно улучшим этот показатель. Информацию об этих улучшениях мы получим, пропрофилировав программу при помощи инструмента perf для Linux2. Весь код выложен на GitHub.
Сноска 2
Тесты проводились на процессоре Intel Skylake i7-8550U CPU под Linux 5.17.
У вас значение пробега обязательно будет варьироваться, поскольку внутренности Linux, обеспечивающие работу программ, описанных в этом посте,
постоянно менялись в течение пары последних лет и, вероятно, будут и далее
дорабатываться в последующих релизах. Читайте дальше, подробности воспоследуют!

Этот пост был написан под впечатлением от чтения сильно оптимизированной программы FizzBuzz, которая у меня на ноутбуке выдавала вывод в канал со скоростью ~35 гибибайт/с3. Наша первая цель – выйти примерно на такую скорость, объясняя все шаги, которые мы сделаем по пути. Добавим еще один показатель, позволяющий оценить улучшение производительности – в FizzBuzz он не требовался, поскольку там самое узкое место находилось именно в точке расчета вывода, а не в операциях ввода/вывода, как минимум, на моей машине.
Сноска 3
«FizzBuzz» - это пресловутый вопрос с программистских собеседований. В рамках этого поста детали его не важны. Лично мне этого вопроса никогда не задавали, но мне известно из достоверных источников, что он в самом деле довольно популярен.
Разделим работу на следующие этапы:
Первая медленная версия нашего тестового стенда для испытания каналов;
Как именно каналы реализованы на внутрисистемном уровне, и почему запись в них и считывание из них получаются такими медленными;
Как системные вызовы
vmspliceиspliceпозволяют частично (но не полностью) победить эту медлительность;Описание разбивки памяти на страницы в Linux; этот ход позволяет получить значительно ускоренную версию программы путем применения гигантских страниц;
Окончательный вариант оптимизации, на котором мы заменим опрос активным ожиданием в цикле;
Некоторые заключительные мысли.
В разделе 4 мы сильнее всего углубимся во внутреннее устройство ядра Linux, поэтому она может заинтересовать вас, даже если остальные темы, разобранные в этом посте, вам хорошо знакомы. Читателям, не знакомым с этими темами, для изучения поста понадобятся лишь элементарные знания C.
Начнем же!
Наша задача и ее первое решение - медленное
Первым делом давайте измерим производительность легендарной программы FizzBuzz, придерживаясь правил, изложенных в посте на StackOverflow:
% ./fizzbuzz | pv >/dev/null
422GiB 0:00:16 [36.2GiB/s]pv – это «просмотрщик каналов» (pipe viewer), удобная утилита для измерения пропускной способности канала, по которому текут данные. Итак, fizzbuzz дает вывод со скоростью 36 ГиБ/с.
fizzbuzz записывает вывод блоками, каждый из которых по размеру равен кэшу L2, чтобы хорошо сбалансировать дешевый доступ к памяти и издержки ввода/вывода, которые должны быть минимальными.
На моей машине размер кэша L2 равен 256 КиБ. На протяжении этой статьи мы также будем получать на выход блоки размером по 256 КиБ, ничего при этом не «вычисляя». В сущности, мы попытаемся измерить верхний предел производительности для программ, записывающих данные в канал при условии, что мы располагаем буфером достаточного размера4.
Сноска 4
Притом, что размер буфера мы фиксируем, цифры, на самом деле, не сильно изменятся, если мы станем использовать буферы другого размера – учитывая, что у нас проявятся и другие узкие места.
Притом, что fizzbuzz использует pv для измерения скорости, мы соорудим немного иную конфигурацию: мы реализуем программы по обе стороны канала. Сделаем так, чтобы полностью контролировать код, занятый как вводом данных в канал, так и за вывод данных из канала.
Этот код доступен в репозитории pipes-speed-test. Файл write.cpp реализует запись, а файл read.cpp - считывание. write многократно записывает одни и те же 256 КиБ, это продолжается вечно. read считывает из конца в конец 10 ГиБ данных и завершает работу, выводя в завершение пропускную способность, выраженную в ГиБ/с. Оба исполняемых файла принимают ряд опций командной строки, при помощи которых мы можем менять их поведение.
Первая попытка считывать из каналов и записывать в них будет сделана при помощи системных вызовов write и read, причем, размер буфера будет таким же, как у fizzbuzz. Вот как ситуация выглядит с записывающего конца:
int main() {
size_t buf_size = 1 << 18; // 256 КиБ
char* buf = (char*) malloc(buf_size);
memset((void*)buf, 'X', buf_size); // вывод
while (true) {
size_t remaining = buf_size;
while (remaining > 0) {
// Продолжаем вызывать `write` до тех пор, пока не запишем всю информацию,
// содержащуюся в буфере. Не забываем: операция записи возвращает, сколько
// она может записать по адресу назначения, в данном случае,
// в наш канал.
ssize_t written = write(
STDOUT_FILENO, buf + (buf_size - remaining), remaining
);
remaining -= written;
}
}
}
Для краткости в этом листинге и во всех последующих не проверяются ошибки5.
Сноска 5
Смело отправляйтесь в репозиторий, там вся мякотка. Точнее, я не буду воспроизводить здесь код дословно, поскольку детали несущественны. Вместо этого вставлю те фрагменты, которые хорошо иллюстрируют происходящие события.
Здесь memset гарантирует, что весь вывод можно будет отобразить на экране, а также играет и другую роль, о чем мы поговорим ниже.
Вся эта работа выполняется в вызове write, а остальной код нужен, чтобы гарантировать, что буфер заполняется целиком. На считывающем конце все очень похоже, но данные считываются в buf, и работа завершается, когда считан достаточный объем информации.
После сборки код из репозитория можно выполнить следующим образом:
% ./write | ./read
3.7GiB/s, 256KiB buffer, 40960 iterations (10GiB piped)Мы записываем тот же самый буфер в 256 КиБ, в который 40960 раз ставим 'X', а затем измеряем пропускную способность. В данном случае нас волнует, что наша программа в 10 раз медленнее fizzbuzz! А мы ведь не выполняем никакой работы, просто пишем байты в канал.
Оказывается, что мы и не сможем существенно ускориться, если попытаемся
обойтись write и read.
Беда с write
Чтобы выяснить, на что программа тратит время, можно воспользоваться perf 6, 7:
% perf record -g sh -c './write | ./read'
3.2GiB/s, 256KiB buffer, 40960 iterations (10GiB piped)
[ perf record: Woken up 6 times to write data ]
[ perf record: Captured and wrote 2.851 MB perf.data (21201 samples) ]Сноска 6
Обратите внимание: здесь мы профилируем вызов оболочки, в рамках этой работы выполняется как считывание канала, так и запись в канал — perf record по умолчанию прослеживает все дочерние процессы.
Сноска 7
При профилировании этой программы я заметил, что вывод perf загрязнен информацией, относящейся к инфраструктуре подсистемы Pressure Stall Information (PSI).
Следовательно, цифры взяты из работы с ядром, которое было скомпилировано при отключенной PSI. Этого можно добиться, поставив CONFIG_PSI=n в конфигурации сборки ядра. В NixOS:
boot.kernelPatches = [{
name = "disable-psi";
patch = null;
extraConfig = ''
PSI n
'';
}];Более того, в коде должны присутствовать символы отладки ядра, чтобы perf корректно показывала, на что и где тратится время при системных вызовах. Порядок установки символов варьируется от дистрибутива к дистрибутиву. В новейших версиях NixOS они устанавливаются по умолчанию.
Команда -g приказывает perf записывать графы вызовов: это позволит нам взглянуть сверху вниз на все процессы и лучше понять, на что тратится время.
Просмотреть такой хронометраж удобно при помощи perf report. Вот слегка отредактированная выдержка. В ней поставлен разрыв там, где write тратит свое время8:
% perf report -g --symbol-filter=write
- 48.05% 0.05% write libc-2.33.so [.] __GI___libc_write
- 48.04% __GI___libc_write
- 47.69% entry_SYSCALL_64_after_hwframe
- do_syscall_64
- 47.54% ksys_write
- 47.40% vfs_write
- 47.23% new_sync_write
- pipe_write
+ 24.08% copy_page_from_iter
+ 11.76% __alloc_pages
+ 4.32% schedule
+ 2.98% __wake_up_common_lock
0.95% _raw_spin_lock_irq
0.74% alloc_pages
0.66% prepare_to_wait_event
Сноска 8
Обратите внимание: здесь мы профилируем вызов оболочки, в рамках этой работы выполняется как считывание канала, так и запись в канал — perf record по умолчанию прослеживает все дочерние процессы.
47% времени тратится на pipe_write, именно в нее разрешается write, если мы пишем в канал. Это неудивительно: примерно половину времени мы тратим на запись, а еще половину времени – на считывание.
В пределах pipewrite 3/4 времени тратится на копирование или выделение страниц (copypagefromiter и __alloc_pages). Если мы уже представляем, как устроена коммуникация между ядром и пользовательским пространством, то это может показаться целесообразным. Как бы то ни было, чтобы полностью понять, что происходит, сначала нужно разобраться в том, как работают каналы.
Из чего состоят каналы?
Структура данных, содержится в include/linux/pipe_fs_i.h, а операции, производимые над ней – в fs/pipe.c.
Канал Linux – это кольцевой буфер, в котором содержатся ссылки на те страницы, куда записываются и откуда считываются данные.
На картинке выше в кольцевом буфере 8 ячеек, но их может быть как больше, так и меньше, а по умолчанию ставится 16. В архитектуре x86-64 размер каждой страницы составляет 4 КиБ, но на других архитектурах этот размер может отличаться. Всего в канале может содержаться не более 32 КиБ данных. Это ключевой момент: у каждого канала есть предел, связанный с общим объемом данных, который в канале может содержаться до заполнения.
В затененной части диаграммы представлены данные, находящиеся в канале в настоящий момент, а незатененная часть – это пустое пространство в канале.
Несколько парадоксально, что в head хранится записывающий конец канала. То есть, заноситься информация будет в тот буфер, на который указывает head, и, соответственно, head будет увеличиваться при необходимости перейти к следующему буферу. В буфере записи присутствует переменная len, в которой хранится, сколько данных мы в буфер записали.
Наоборот, в tail содержится считывающий конец канала; читатели начинают потреблять канал именно отсюда. В переменной offset указано смещение, с которого нужно начинать считывание.
Обратите внимание: tail может идти после head, как показано на картинке, что логично, ведь мы работаем с кольцевым буфером. Также учитывайте, что некоторые ячейки могут оставаться неиспользованными, если мы не заполнили канал целиком – это будут ячейки NULL в середине. Если канал полон (в нем нет ни NULL, ни свободного пространства на страницах), то write блокируется. Если канал пуст (в нем одни только NULL), то read блокируется.
Вот сокращенная версия структур данных C, содержащихся в pipe_fs_i.h:
struct pipe_inode_info {
unsigned int head;
unsigned int tail;
struct pipe_buffer *bufs;
};
struct pipe_buffer {
struct page *page;
unsigned int offset, len;
};Здесь мы пропускаем много полей и пока не объясняем, что содержится в struct page, но это – ключевая структура данных, необходимая для понимания того, как происходит считывание из канала и запись в канал.
Считывание из каналов
Теперь перейдем к определению pipe_write, чтобы попытаться осмыслить вывод perf, показанный выше.
Вот упрощенное объяснение, характеризующее работу pipe_write:
Если канал уже полон, то ждем, пока в нем освободится место и перезапускаемся;
Если есть место в том буфере, на который в данный момент указывает head, то первым делом заполняем это место;
Пока остаются свободные ячейки и еще остаются байты к записи, выделяем новые страницы и заполняем их, обновляя
head.

Вышеописанные операции защищены блокировкой, которую pipe_write приобретает и при необходимости высвобождает.
piperead – это зеркальное отражение pipewrite, с той оговоркой, что в данном случае мы потребляем страницы, высвобождаем их, как только они будут полностью прочитаны, и обновляем tail9.
Сноска 9
Всего одна «сэкономленная страница» под названием tmp_page на самом деле приберегается pipe_read и повторно используется pipe_write.
Но, так как это в любом случае всего одна страница, я не могу с ее помощью добиться более высокой производительности, учитывая, что повторное использование этой страницы все равно сопряжено с фиксированными издержками при вызове pipe_write и pipe_read.
Итак, перед нами развертывается весьма безрадостная картина происходящего:
Мы дважды копируем каждую страницу. Сначала из пользовательской памяти в ядро, а затем обратно, из ядра в пользовательскую память;
При работе копируется по одной странице в 4 Кибибайт за раз, и копирование перемежается с другими действиями, например, синхронизацией чтения и записи, выделением и высвобождением страниц;
Мы работаем с памятью, которая может быть несплошной, поскольку мы постоянно выделяем новые страницы;
Мы приобретаем и высвобождаем блокировку канала.
На данной машине такты последовательного считывания RAM отсчитываются с частотой около 16 ГиБ/с:
% sysbench memory --memory-block-size=1G --memory-oper=read --threads=1 run
...
102400.00 MiB transferred (15921.22 MiB/sec)Учитывая всю возню, описанную выше, четырехкратное замедление по сравнению с однопоточной последовательной обработкой RAM уже не столь удивителен.
Если откорректировать размер буфера или размер канала, чтобы сократить количество системных вызовов и общие издержки на синхронизацию, либо откорректировать другие параметры – на этом мы далеко не уедем. К счастью, есть способ вообще обойти проблемы, связанные с медлительностью write и read.
Нам поможет сплайсинг
Такой подход с копированием буферов из пользовательской памяти в ядро и обратно – та «палка», которая часто попадает в «колеса» разработчику, желающему реализовать быстрый ввод/вывод. Распространенное решение – просто вынести ядро за скобки и выполнять операции ввода/вывода напрямую. Например, можно было бы взаимодействовать непосредственно с сетевой картой и обходить ядро, добиваясь низких задержек при сетевой работе.
В принципе, когда мы пишем в сокет, или в файл, или в нашем случае – в канал, сначала информация заносится в буфер где-нибудь в ядре, а затем ядро делает свое дело. Что касается каналов, канал – это и есть серия буферов в ядре. Если для нас критична производительность, то все это копирование нежелательно.
К счастью, в состав Linux включены системные вызовы для ускорения операций, когда нам требуется перемещать данные в каналы из них, без копирования. А именно:
splice перемещает данные из канала в дескриптор файла и наоборот.
vmsplice перемещает данные из пользовательской памяти в канал10.
Сноска 10
Строго говоря, vmsplice также поддерживает и перенос данных в другом направлении, хотя, пользы от этого и немного. Как указано на странице man-справки:
vmsplice на самом деле поддерживает подлинный сплайсинг только в направлении из пользовательской памяти в канал. В противоположном направлении данные просто копируются в пользовательское пространство.
Принципиально важно, что при выполнении обеих операций ничего не копируется. Теперь, в целом разобравшись, как работают каналы, мы уже примерно представляем, как осуществляются две эти операции: они просто «подхватывают» имеющийся буфер откуда-нибудь и помещают его в кольцевой буфер канала или наоборот, а не выделяют новых страниц по мере необходимости.
Вскоре увидим, как именно это работает.
Сплайсинг на практике
Заменим write на vmsplice. Вот сигнатура vmsplice:
struct iovec {
void *iov_base; // Начальный адрес
size_t iov_len; // Количество байт
};
// Возвращает, сколько информации мы сплайснули в канал
ssize_t vmsplice(
int fd, const struct iovec *iov, size_t nr_segs, unsigned int flags
);fd – это целевой канал, struct iovec *iov – это массив буферов, которые мы будем продвигать к каналу. Обратите внимание, что vmsplice возвращает, сколько информации было «сплайснуто» в канал, и это может быть неполный объем информации – примерно так write возвращает, сколько было записано. Не забывайте: емкость каналов ограничена количеством ячеек в кольцевом буфере у каждого из них, и vmsplice подчиняется этому ограничению, как и прочие операции.
Мы также должны проявлять известную осторожность, работая с vmsplice. Поскольку память из пользовательского пространства перемещается в канал без копирования, мы должны гарантировать, что она будет потреблена на считывающем конце прежде, чем мы сможем переиспользовать сплайснутый буфер.
Именно поэтому fizzbuzz использует схему с двойной буферизацией, работающую следующим образом:
Разбить на две части буфер размером 256 КиБ;
Задать размер канала 128 КиБ, в результате размер кольцевого буфера канала получит размер 128 КиБ/4 КиБ = 32 ячеек;
Переключаться между двумя половинами: сначала записывать в первую половину буфера и при помощи vmsplice перемещать ее в канал, а затем делать то же самое со второй половиной.
Поскольку мы, во-первых, устанавливаем размер канала в 128 КиБ, а во-вторых, ожидаем, пока vmsplice полностью даст на вывод один буфер размером 128 КиБ, это гарантирует нам, что к моменту окончания одной итерации vmsplice мы будем знать, что предыдущий буфер полностью считан — в противном случае мы были бы не в состоянию полностью vmsplice новый буфер в 128 КиБ в канал размером 128 КиБ.
Теперь мы, в сущности, ничего не записываем в буферы, но схему с двойной
буферизацией мы сохраним, поскольку подобная схема в самом деле понадобится нам
для любой программы, фактически записывающей контент11.
Сноска 11
11. Тревис Даунз указывал, что эта схема все равно будет небезопасной, поскольку страницу можно будет сплайсить и далее, тем самым продлевая ее жизнь. Эта проблема представлена и в оригинальном посте, посвященном FizzBuzz.
На самом деле, мне не вполне ясно, является ли vmsplice без SPLICE_F_GIFT по-настоящему безопасной — на странице man-справки по vmsplice подразумевается, что, кажется, не должна. Тем не менее, не приходится сомневаться, что только при большом старании можно организовать работу с каналами без какого-либо копирования, при этом поддерживая должный уровень безопасности.
В тестовой программе на считывающем конце канал сплайсится в /dev/null, поэтому может быть так, что ядро само знает: страницы можно сплайсить без копирования. Но я не проверял, так ли это.
Теперь наш цикл записи выглядит примерно так:
int main() {
size_t buf_size = 1 << 18; // 256KiB
char* buf = malloc(buf_size);
memset((void*)buf, 'X', buf_size); // X на выход
char* bufs[2] = { buf, buf + buf_size/2 };
int buf_ix = 0;
// Переключаемся между двумя буферами, выполняя сплайсинг, пока все не будет готово.
while (true) {
struct iovec bufvec = {
.iov_base = bufs[buf_ix],
.iov_len = buf_size/2
};
buf_ix = (buf_ix + 1) % 2;
while (bufvec.iov_len > 0) {
ssize_t ret = vmsplice(STDOUT_FILENO, &bufvec, 1, 0);
bufvec.iov_base = (void*) (((char*) bufvec.iov_base) + ret);
bufvec.iov_len -= ret;
}
}
}Вот, что получится, если записывать при помощи vmsplice, а не write:
% ./write --write_with_vmsplice | ./read
12.7GiB/s, 256KiB buffer, 40960 iterations (10GiB piped)Так вполовину уменьшается объем копирования, который нам придется сделать. Пропускная способность уже улучшилась более чем в три — до 12,7 ГиБ/с. Если переориентировать на использование splice и считывающий конец, то копирование исключается полностью, а скорость увеличивается еще в 2,5 раза:
% ./write --write_with_vmsplice | ./read --read_with_splice
32.8GiB/s, 256KiB buffer, 40960 iterations (10GiB piped)Наудим страниц
Что дальше? Спросим perf :
% perf record -g sh -c './write --write_with_vmsplice | ./read --read_with_splice'
33.4GiB/s, 256KiB buffer, 40960 iterations (10GiB piped)
[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.305 MB perf.data (2413 samples) ]
% perf report --symbol-filter=vmsplice
- 49.59% 0.38% write libc-2.33.so [.] vmsplice
- 49.46% vmsplice
- 45.17% entry_SYSCALL_64_after_hwframe
- do_syscall_64
- 44.30% __do_sys_vmsplice
+ 17.88% iov_iter_get_pages
+ 16.57% __mutex_lock.constprop.0
3.89% add_to_pipe
1.17% iov_iter_advance
0.82% mutex_unlock
0.75% pipe_lock
2.01% __entry_text_start
1.45% syscall_return_via_sysret
Львиная доля времени тратится на блокировку канала, удерживаемую в течение записи (__mutex_lock.constprop.0) и на то, чтобы задвинуть страницы в канал (iov_iter_get_pages). На блокировку мы повлиять особенно не можем, зато можем улучшить производительность iov_iter_get_pages.
Как понятно из названия, ioviterget_pages превращает структуры struct iovec, которые мы скармливаем vmsplice, в struct pages, которые мы подаем в канал. Чтобы понять, что именно делает эта функция, и как ее ускорить, нам сначала потребуется сделать небольшое отступление и поговорить о том, как в CPU и Linux организована работа со страницами.
Страницы: экспресс-экскурсия
Вероятно, вам известно, что процессы не обращаются напрямую к конкретным местоположениям в RAM: вместо этого им присваиваются виртуальные адреса в памяти, которые разрешаются в физические адреса. Такая абстракция называется «виртуальная память», у нее целый ряд достоинств, в которые мы вдаваться не будем. Наиболее очевидное достоинство в том, что виртуальная память существенно упрощает одновременную эксплуатацию множества процессов, конкурирующих за одну и ту же физическую память.
Как бы то ни было, всякий раз, когда мы выполняем программу и загружаем
данные, сохраняем данные из памяти или в память, CPU требуется преобразовать наши виртуальные адреса в физический адрес.
Сохранять и отображать данные с любого виртуального адреса на соответствующий
ему физический адрес непрактично. Поэтому память разделяется на равновеликие
фрагменты, именуемые страницами, и виртуальные страницы отображаются на
физические страницы12:
Сноска 12
Здесь представлена упрощенная модель, где физическая память – это просто плоская линейная последовательность. В реальности все несколько сложнее, но в рамках этой статьи нам подойдет и простая модель.
Величина 4 КиБ в данном случае непринципиальна: в каждой архитектуре этот размер выбирается отдельно, исходя из различных компромиссов, и некоторые из них мы вскоре исследуем.
Для большей конкретики давайте здесь предположим, что нам нужно выделить
10000 байт при помощи malloc:
void* buf = malloc(10000);
printf("%p\N", buf); // 0x6f42430Во время использования наши 10k будут представлены в виртуальной памяти как один непрерывный участок, но отображаться они будут на 3 физические страницы, которые могут и не быть непрерывными13:
Сноска 13
Можно проверить физические адреса, присвоенные виртуальным страницам процесса, работающего в настоящий момент. Для этого прочитайте /proc/self/pagemap и умножьте номер страничного блока на размер страницы.
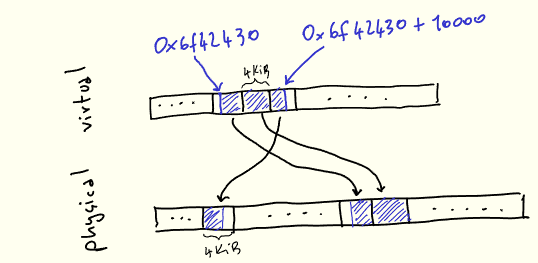
Одна из задач ядра – управлять этим отображением, которое воплощено в виде структуры данных, именуемой «таблица страничных блоков» (page table). Процессор указывает, как выглядит эта таблица (поскольку ему нужно ее понимать), и ядро управляет этой таблицей так, как нужно. В архитектуре x86-64 таблица страничных блоков – это четырехуровневое 512-ветвистое дерево, которое само находится в памяти14.
Сноска 14
В Intel таблица страничных блоков была расширена и, начиная с Ice Lake, состоит из 5 уровней. Таким образом, максимальная адресуемая область памяти увеличивается с 256 ТиБ до 128 ПиБ. Правда, эту возможность требуется явно активировать, поскольку работа некоторых программ зависит от того, чтобы верхние 16 бит в указателях оставались неиспользуемыми.
Каждый узел этого дерева (как вы уже догадались!) имеет 4 КиБ в ширину, причем, каждая запись внутри узла ведет на новый уровень с соответствующим участком в 8 байт (4КиБ/8байт = 512). Записи содержат адрес следующего узла, а также другие метаданные.
На каждый процесс у нас одна таблица страничных блоков – иными словами, за каждым процессом зарезервировано виртуальное адресное пространство. Когда ядро, переключая контекст, переходит к некоторому процессу, в качестве значения специального регистра CR3 задается физический адрес корня данного дерева15.
Сноска 15
Адреса в рамках таблицы страничных блоков должны быть физическими, иначе нам придется иметь дело с бесконечным циклом.
Всякий раз, когда виртуальный адрес требуется преобразовать в физический, процессор делит адреса на секции, а затем с их помощью обходит это дерево и вычисляет физический адрес.
Чтобы придать конкретики этим концепциям, покажу наглядно, как виртуальный адрес 0x0000f2705af953c0 может разрешаться в физический:
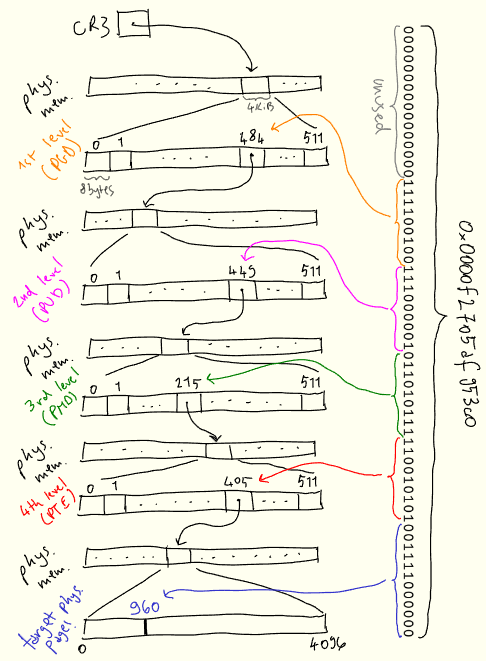
Поиск начинается с первого уровня, именуемого «глобальный каталог страниц»
(PGD), физическое местоположение которого хранится в CR3. Первые 16 бит адреса не используются16.
Сноска 16
Обратите внимание, что не используются 16 высших бит; это значит, что каждый процесс может адресовать не более 2^{48}-1248−1 байт или 256 ТиБ физической памяти.
Следующие 9 бит мы используем под запись PGD, после чего переходим на следующий уровень, «верхний каталог страниц» (PUD). Следующие 9 бит используются для выбора записи из PUD. Тот же процесс повторяется и для следующих двух уровней, PMD («средний каталог страниц») и PTE («таблица дескрипторов страницы»). PTE сообщает, где фактически находится искомая физическая страница, а затем, ориентируясь на последние 12 разрядов, находим нужное смещение на странице.
Разреженная структура страничной таблицы позволяет постепенно выстраивать такое отображение по мере того, как нам будут требоваться новые таблицы. Всякий раз, когда процессу требуется память, ядро обновляет страничную таблицу, добавляя в нее новую запись.
Роль struct page
Структура данных struct page – ключевой элемент описываемого механизма; именно эту структуру данных ядро использует для ссылки на конкретную физическую страницу, сохраняя ее физический адрес, а также всевозможные прочие метаданные о ней17.
Сноска 17
struct page также может ссылаться на физические страницы, которые еще предстоит выделить, страницы, у которых пока нет физических адресов, а также на другие абстракции, касающиеся работы со страницами. Считайте их совершенно абстрактными ссылками на физические страницы; но такая ссылка не обязательно указывает на уже выделенную физическую страницу.
Этот тонкий момент будет важен в одной из следующих сносок.
Например, можно получить struct page из информации, содержащейся в PTE (это последний из описанных выше уровней табличной страницы). В принципе, данная структура данных повсюду используется в коде, обрабатывающем проблемы, касающиеся страниц.
При работе с каналами именно struct page держит их данные в кольцевом буфере, это мы уже видели:
struct pipe_inode_info {
unsigned int head;
unsigned int tail;
struct pipe_buffer *bufs;
};
struct pipe_buffer {
struct page *page;
unsigned int offset, len;
};Однако, vmsplice принимает виртуальную память в качестве ввода, тогда как struct page ссылается непосредственно на физическую память.
Следовательно, нам требуется преобразовать произвольные фрагменты виртуальной памяти в совокупность struct pages. Именно это и делает iov_iter_get_pages, на это мы и тратим половину времени:
ssize_t iov_iter_get_pages(
struct iov_iter *i, // ввод: буфер заданного размера в виртуальной памяти
struct page **pages, // вывод: список страниц, составляющих буферы вывода size_t maxsize, // максимальное количество байт к получению
unsigned maxpages, // максимальное количество страниц к получению
size_t *start // смещение на первой странице, если входной буфер не выровнен по страницам
);struct iov_iter – это структура данных из ядра Linux, предоставляющая различные способы обхода сегментов памяти, в том числе, struct iovec. В нашем случае она будет указывать на буфер размером 128 КиБ. vmsplice использует iov_iter_get_pages для преобразования входного буфера struct page и придержания их. Итак, теперь, разобравшись с разбивкой на страницы, можно также представить, как работает iov_iter_get_pages, но мы подробно рассмотрим этот вопрос в следующем разделе.
Здесь мы стремительно разобрали множество новых концепций, так что просто в качестве напоминания:
Для работы с процессами в современных CPU используется виртуальная память;
Память разделена на страницы заранее предусмотренного размера;
CPU транслирует виртуальные адреса в физические на основе страничной таблицы, отображающей виртуальные страницы на физические;
Ядро по мере необходимости добавляет записи в таблицу страниц или удаляет их оттуда;
Каналы состоят из ссылок на физические страницы, поэтому vmsplice требуется преобразовывать диапазоны виртуальной памяти в физические страницы и придерживаться их.
Во что обойдется получение страниц
Время, затрачиваемое в рамках iov_iter_get_pages, на самом деле полностью тратится в другой функции, get_user_pages_fast:
% perf report -g --symbol-filter=iov_iter_get_pages
- 17.08% 0.17% write [kernel.kallsyms] [k] iov_iter_get_pages
- 16.91% iov_iter_get_pages
- 16.88% internal_get_user_pages_fast
11.22% try_grab_compound_head
get_user_pages_fast – это более минималистичная версия iov_iter_get_pages:
int get_user_pages_fast(
// виртуальный адрес, выровненный по границе страниц
unsigned long start,
// количество байт, которые нужно извлечь
int nr_pages,
// флаги, значения которых мы подробно разбирать не будем
unsigned int gup_flags,
// количество физических страниц в выводе
struct page **pages
)Здесь “user” (в отличие от “kernel”) означает, что мы превращаем виртуальные страницы в ссылки на физические страницы.
Чтобы получить наши struct page, getuserpagesfast делает именно то, что делал бы CPU, но на программном уровне: обходит таблицу страниц, чтобы собрать все физические страницы, сохраняя результаты этой работы в struct page.В нашем случае имеется буфер на 128 КиБ, а размер страницы составляет 4КиБ, так что у нас будет nrpages = 32 (сноска 18).
Сноска 18
На самом деле, оказывается, что код канала всегда вызывает get_user_pages_fast со значением nr_pages = 16, при необходимости перебирая страницы в цикле. Предположительно, так делается для того, чтобы можно было обойтись небольшим статическим буфером. Но это деталь реализации, и общее количество сплайснутых страниц все равно будет 32.
get_user_pages_fast придется обойти табличное дерево, собрав 32 листа и сохранив результат в 32 struct page.
get_user_pages_fast также должна убедиться, что физическая страница не будет переопределяться для другой цели до тех самых пор, пока она больше не будет нужна вызывающей стороне. Это достигается в ядре благодаря подсчету ссылок, сохраняемых в struct page, благодаря чему удается узнать, когда физическую страницу можно будет высвободить и в будущем использовать по-новому. В какой-то момент сторона, вызывающая get_user_pages_fast, должна вновь высвободить страницы при помощи put_page, и тогда значение подсчета ссылок будет уменьшено.
Наконец, getuserpagesfast работает по-разному в зависимости от того, есть ли уже
виртуальные адреса в таблице страниц. Именно здесь нам пригодится суффикс fast: ядро сначала попытается получить запись, уже имеющуюся в таблице страниц и соответствующую ей struct page, просто пройдя по таблице страниц (это относительно малозатратная операция), а если не получится – откатиться к порождению struct page другими, более ресурсоемкими средствами. Поскольку мы делаем memset памяти с самого начала, гарантирует, что мы никогда не вступим на «медленный» путь к getuserpages_fast, поскольку записи в таблице страниц будут создаваться по мере заполнения нашего буфера 'X'-ами19.
Сноска 19
18. В этой сноске излагаются тонкости, которые не являются необходимыми для понимания поста!
Если в таблице страниц не содержится та запись, которую мы ищем, get_user_pages_fast все равно требуется вернуть struct page. Наиболее очевидный способ этого добиться – создать в таблице запись под нужную страницу, а затем вернуть соответствующую struct page.
Однако, get_user_pages_fast сделает так лишь в том случае, если мы запросим у нее struct page для записи в эту структуру данных. В противном случае таблица страниц обновлена не будет, вместо этого будет возвращена struct page, дающая ссылку на такую физическую страницу, которую еще только предстоит выделить. Именно то же самое происходит в случае с vmsplice, поскольку нам всего лишь нужно сделать struct page для заполнения канала, а фактически записывать что-либо в память мы не собираемся.
Иными словами, выделение страницы откладывается до того момента, пока она в самом деле нам не понадобится. Это избавляет нас от выделения физической страницы, но может столкнуть нас на медленный путь get_user_pages_fast, так как эта функция будет вызываться раз за разом, если страница ни разу не откажет по какой-то другой причине.
Следовательно, если мы не делали memset ранее и, следовательно, не отбраковывали страницы в таблице «вручную», мы не только пойдем по медленному пути, стоит лишь нам вызвать get_user_pages_fast, но пойдем по нему и при следующих вызовах, что существенно замедлит работу (25 ГиБ/с против 30 ГиБ/с):
% ./write --write_with_vmsplice --dont_touch_pages | ./read --read_with_splice
25.0GiB/s, 256KiB buffer, 40960 iterations (10GiB piped)
Более того, такое не наблюдается при использовании гигантских страниц; в таком случае get_user_pages_fast станет штатно отбрасывать страницы, если тот диапазон виртуальной памяти, в который они передаются, будет занят гигантскими страницами.
Если вы от всего этого запутались – не волнуйтесь; представляется, что getuserpages очень заковыристый элемент ядра, даже для разработчиков ядра.
Обратите внимание, что семейство функций get_user_pages полезно не только при работе с каналами, но и играет центральную роль при использовании многих драйверов. Как правило, они используются при уже упомянутом обходе ядра (kernel bypass): драйвер сетевой карты может при помощи такого приема может превратить некоторую область пользовательской памяти в физическую страницу, затем сообщить сетевой карте, где находится эта физическая страница, после чего сетевая карта сможет взаимодействовать с этой областью памяти напрямую, совершенно не привлекая к работе ядро.
Гигантские страницы
До сих пор мы говорили о страницах как о сущностях, имеющих один и тот же размер — 4 КиБ в архитектуре x86-64. Но во многих архитектурах CPU, в том числе, и в x86-64, предусмотрены и страницы более крупного размера. В случае с x86-64 можно использовать не только страницы по 4 КиБ («стандартный» размер), но и по 2 МиБ, и даже по 1 ГиБ («гигантские» страницы). В оставшейся части страницы мы будем иметь дело только с огромными страницами размером по 2 МиБ, поскольку страницы по 1 ГиБ встречаются достаточно редко и при решении нашей задачи являются стрельбой из пушки по воробьям.
Архитектура | Самая маленькая страница | Более крупные страницы |
x86 | 4KiB | 2MiB, 4MiB |
x86-64 | 4KiB | 2MiB, 1GiB20 |
ARMv7 | 4KiB | 64KiB, 1MiB, 16MiB |
ARMv8 | 4KiB | 16KiB, 64KiB |
RISCV32 | 4KiB | 4MiB |
RISCV64 | 4KiB | 2MiB, 1GiB, 512GiB, 256 TiB |
Power ISA | 8KiB | 64 KiB, 16 MiB, 16 GiB |
Сноска 20
Только когда в процессоре CPU установлен флаг PDPE1GB
Основное достоинство гигантских страниц в том, что им проще вести учет, поскольку для покрытия эквивалентного объема памяти нужно меньше таких страниц. Более того, зачастую и операции над ними не столь затратны – такие операции, как разрешение виртуального адреса в физический. Дело в том, что участвующая в работе таблица страниц на уровень меньше. На странице приходится делать смещение не в 12 бит, а в 21 бит, так и экономится один уровень.
Так удается снизить нагрузку на те части процессора, которые обрабатывают
это преобразование; в результате во многих случаях удается улучшить производительность21.
Сноска 21
Например, CPU включает выделенное аппаратное обеспечение для кэширования частей таблицы страниц, «буфер ассоциативной трансляции» (TLB). Содержимое TLB сбрасывается при каждом переключении контекста (всякий раз, когда меняется содержимое CR3).
Гигантские страницы позволяют существенно снизить количество промахов в TLB,
поскольку каждая запись-страница размером 2 МиБ занимает в 512 раз больше памяти, чем страница в 4 КиБ.
Правда, в нашем случае давление оказывается не на аппаратную часть, отвечающую за обход таблицы страниц, а на сопутствующую программную часть, отвечающую за эксплуатацию ядра.
В Linux страницу размером 2 МиБ можно выделить разнообразными способами, например, выравнивая память фрагментами по 2 МиБ каждый, а затем при помощи madvise сообщать ядру, что в предоставленном буфере нужно использовать огромные страницы:
void* buf = aligned_alloc(1 << 21, size);
madvise(buf, size, MADV_HUGEPAGE)
Если в нашей программе переключиться на работу с огромными страницами, удается улучшить производительность еще примерно на 50%:
% ./write --write_with_vmsplice --huge_page | ./read --read_with_splice
51.0GiB/s, 256KiB buffer, 40960 iterations (10GiB piped)
Правда, причина таких улучшений не вполне очевидна. На первый взгляд могло бы показаться, что при использовании огромных страниц struct page просто ссылается на страницу размером 2 МиБ, а не 4 КиБ.
К сожалению, это не так: код ядра везде исходит из того, что struct page ссылается на страницу такого размера, который считается «стандартным» для данной архитектуры. Таким образом, при работе с огромными страницами (и в принципе с такими страницами, которые называются в Linux «составными страницами» предполагается, что «головная страница» struct page содержит информацию о конкретной физической странице, а последующие «хвостовые страницы» содержат всего лишь указатели на головную страницу.
Таким образом, чтобы представить огромную страницу размером 2 МиБ,
имеем 1 «головную» struct page и до 511 «хвостовых» struct page. Либо, в нашем случае, когда размер буфера составляет 128 КиБ, у нас 31 хвостовая struct page22
Сноска 22
Если вам кажется, что «это же ужасно!» - поверьте, не только вам.
Принимаются различные меры, чтобы упростить и/или оптимизировать эту ситуацию.
В новейших версиях ядра (от 5.17 и выше) включен новый тип, struct folio, явно идентифицирующий головные страницы. Таким образом, становится не столь важно проверять во время выполнения, является конкретная struct page головной или хвостовой, что позволяет улучшить производительность.
Другие разработки нацелены на то, чтобы вообще избавиться от лишних struct page, хотя, я не в курсе, как они идут.

Даже если нам понадобятся все эти struct page, генерирующий их код теперь оказывается существенно быстрее. Вместо того, чтобы многократно обходить страницу, действуем так: как только найдена первая запись, последующие страницы struct page могут генерироваться в рамках обычного цикла. Вот и улучшение производительности!
Активное ожидание
Уже почти все готово, обещаю! Давайте вновь рассмотрим вывод perf :
- 46.91% 0.38% write libc-2.33.so [.] vmsplice
- 46.84% vmsplice
- 43.15% entry_SYSCALL_64_after_hwframe
- do_syscall_64
- 41.80% __do_sys_vmsplice
+ 14.90% wait_for_space
+ 8.27% __wake_up_common_lock
4.40% add_to_pipe
+ 4.24% iov_iter_get_pages
+ 3.92% __mutex_lock.constprop.0
1.81% iov_iter_advance
+ 0.55% import_iovec
+ 0.76% syscall_exit_to_user_mode
1.54% syscall_return_via_sysret
1.49% __entry_text_startТеперь мы тратим существенное время, дожидаясь, пока канал будет готов принимать информацию на запись (wait_for_space) и будим считывателей, которые дожидались, пока в канале появится содержимое (__wake_up_common_lock).
Чтобы обойтись без этих издержек на синхронизацию, можем попросить vmsplice возвращать нам сообщение о том, что в канал невозможно записывать (если так), а затем активно ожидать, пока не представится возможность записи – и точно так же действовать при считывании при помощи splice:
...
// SPLICE_F_NONBLOCK заставит `vmsplice` немедленно вернуться,
// если сейчас запись в канал невозможна, при этом будет возвращено EAGAIN
ssize_t ret = vmsplice(STDOUT_FILENO, &bufvec, 1, SPLICE_F_NONBLOCK);
if (ret < 0 && errno == EAGAIN) {
continue; // активно ожидать, если мы пока не готовы записывать
}
...Благодаря активному ожиданию, получается улучшить производительность еще на 25%:
% ./write --write_with_vmsplice --huge_page --busy_loop | ./read --read_with_splice --busy_loop
62.5GiB/s, 256KiB buffer, 40960 iterations (10GiB piped)
Очевидно, активное ожидание имеет свою цену: приходится полностью отдавать под него ядро процессора, дожидаясь готовности vmsplice. Но часто такой компромисс оправдан и, на самом деле, это распространенный паттерн при работе с высокопроизводительными серверными приложениями: меняем время, в течение которого CPU, возможно, работал бы впустую, на уменьшение задержки и/или увеличение пропускной способности.
В данном случае здесь завершается наша оптимизационная экспедиция,
позволившая добиться существенного прогресса: увеличить производительность с 3,5
ГиБ/с до 65 ГиБ/с.
Заключительные мысли
Мы систематически улучшили производительность нашей программы, рассмотрев вывод perf и исходники and the Linux. Каналы и, в особенности, сплайсинг, не так активно обсуждаются в дискуссиях по высокопроизводительному программированию, но вот какой круг тем мы затронули: операции с нулевым копированием, кольцевые буферы, разбивка на страницы и виртуальная память, издержки на синхронизацию.
Есть некоторые детали и интересные темы, которых я не коснулся в этой статье, но только потому, что она стала неконтролируемо разрастаться и уже получилась длинноватой:
В реальном коде буферы выделяются по отдельности, чтобы снизить конкуренции за ячейки в таблице страниц, размещая страницы в ячейках, отдаленных друг от друга (нечто подобное делается и в программе FizzBuzz). Не забывайте, что, когда запись из таблицы страниц берется при помощи
get_user_pages, величина подсчета ссылок (refcount) в ней увеличивается, а приput_pageнаоборот, уменьшается. Если мы задействуем две табличные записи для двух буферов, а не одну табличную запись для обоих этих буферов, то у нас получится меньшая конкуренция при модификацииrefcount.Тесты прогоняются при помощи процессов
./writeи./readна двух ядрах, при помощиtaskset.Код, лежащий в репозитории, содержит и множество других вариантов, с которыми я поэкспериментировал, но результаты сюда не включал, поскольку они не относились к делу или получились недостаточно интересными.
В репозитории также содержится синтетический бенчмарк для
get_user_pages_fast, при помощи которого можно в точности измерить, насколько медленнее она работает с гигантскими страницами и без нихСплайсинг как таковой – это слегка сомнительная/опасная концепция, до сих пор раздражающая разработчиков ядра Linux
Благодарности
Большое спасибо Александру Скворцову, Максу Штаудту, Алексу Аппетит, Алексу Сойерсу, Стивену Лавеоллю, Питеру Коули и Никласу Хамбюхену за рецензирование черновиков этого поста. Макс Штаудт также помог мне разобраться в некоторых тонкостях get_user_pages.
