Comments 31
if (smart_check && test != 0) //Смущает то, что даже когда флаг отключен, все равно test вычисляется, т.е. по идее нужно сравнивать два решения - классическое, которое не выполняет хитрые манипуляции с битами, и Ваше. А у Вас получается, что классическое все равно прогоняет вычисления. И да, эти вычисления фактически скрывают в себе проверки, для которых потребовалось бы бегать циклом.
Кроме того, не забывайте, что задача о n-ферзях является NP-полной https://habr.com/ru/post/406423/ - т.е. по сути, как с битами не ухищряйся, кардинально снизить сложность так не получится (поскольку битовые манипуляции по сути заменяют обычный цикл, сделанный типа за одну инструкцию процессора).
Со smart_check так сделано по причине, чтобы не усугублять вложенность блоков (отступ) для демо-примера. По идее нужны две функции с "классикой" и моей оптимизацией. Учту при последующих продолжениях
BSR-инструкция - не заменяет обычный цикл! Я привел прототип на 64-битной арифметике. Примерно также, BSR-инструкция реализована на вентилях процессора (развернутый цикл из 6 операций)
Уже есть второй шаг. Надо аккуратно его прописать. Кол-во переборов и реверсов - снизилось ещё
solution_count = 92
solve_count = 592
reverse_count = 622
Надеюсь будет и 3-й шаг. Заключительный, так сказать
В современном .Net есть класс BitOperations, имеющий методы PopCount и LeadingZeroCount. Если процессор поддерживает инструкции popcnt и lzcnt/bsr соответственно, то эти методы работают как интринсики и JIT компилирует их напрямую в соответствующие инструкции процессора.
Также можно вызывать данные интринсики напрямую, но BitOperations обеспечивает fallback на оптимизированную программную реализацию, если процессор их не поддерживает.
Увы! Мне не удалось подключить BitOperations на момент написания прототипа. Итоговый вариант будет дополнительно сопровождаться исходником на MS C++. Я выбрал C# для быстрого прототипирования. На данный момент, код уже подвергся сильной модифакации, по сравнению с данным исходником.
Доска симметричная, так что можно искать только решения где в первом столбце ферзь стоит на клетках от a1 до a4, а дальше удвоить результат (отразив доску по вертикали мы получим столько же решений для ферзя от a5 до a8). Аналогично, можно потребовать чтобы после первых 4 столбцов в 1 строке оказался ферзь, а потом удвоить число решений отразив доску по горизонтали. а нет, не так всё просто. Ведь эти два критерия не независимы.
Я это знаю. И в первом наброске - это присутствовало (A1-A4). Я удалил этот код. Кол-во переборов по схеме A1-A4 равняется 592/2=296 по алгоритму 1а.
Я достиг своего начального предположения, что кол-во шагов перебора не будет превышать 300. Теперь надо постараться снизить и это количество

Код на медленном cPython: доска 8×8 за 0.000655с, доска 12×12 за 0.302с, доска 14×14 за 10 секунд на cPython и за 2 секунды на PyPy.
У вас есть возможность запустить ваш код на досках 12×12? Какое время работы?
from time import perf_counter
def queens(n, cur_column=None, all_positions=None, pos_in_prev_columns=None, used_rows=None, used_diags1=None, used_diags2=None):
# При стартовом вызове заполняем все необходимые массивы
if cur_column is None:
cur_column = 0
all_positions = [] # Список всех найденных позиций
pos_in_prev_columns = []
used_rows = [False] * n # Список ферзей в предыдущих столбцах (True=занято)
used_diags1 = [False] * (2 * n - 1) # Список занятых диагоналей первого типа
used_diags2 = [False] * (2 * n - 1) # Список занятых диагоналей второго типа
# В первом столбце перебираем только верхнюю половину доски, дальше по симметрии. Ускоряет в 2 раза
if cur_column == 0:
check_rows_in_this_column = (n + 1) // 2
else:
check_rows_in_this_column = n
for row_num in range(check_rows_in_this_column):
# Если горизонталь или диагональ заняты, идём дальше
if used_rows[row_num] or used_diags1[row_num + cur_column] or used_diags2[row_num - cur_column]:
continue
# Если дошли до конца, то это победа!
elif cur_column == n - 1:
all_positions.append(pos_in_prev_columns + [row_num])
# При необходимости добавляем симметричный вариант
if pos_in_prev_columns[0] < n // 2:
all_positions.append([n - 1 - x for x in all_positions[-1]])
else:
# Стандартный перебор с возвратом. Ставим нового ферзя, запускаем рекурсию, откатываемся
used_rows[row_num] = used_diags1[row_num + cur_column] = used_diags2[row_num - cur_column] = True
pos_in_prev_columns.append(row_num)
queens(n, cur_column + 1, all_positions, pos_in_prev_columns, used_rows, used_diags1, used_diags2)
pos_in_prev_columns.pop()
used_rows[row_num] = used_diags1[row_num + cur_column] = used_diags2[row_num - cur_column] = False
return all_positions
n = 8
st = perf_counter()
all_pos = queens(n)
en = perf_counter()
print(f'Всего {len(all_pos)} позиций для доски {n}×{n}')
print('time:', '{:.3}'.format(en - st))
for pos in sorted(all_pos):
print(', '.join('ABCDEFGHIJKLMNOP'[col_n] + str(row_n + 1) for col_n, row_n in enumerate(pos)))
Получилось у меня достаточно просто, для людей разбирающихся в целочисленной арифметике. Ведь я ввел в алгоритм первичный позиционный анализ.
Целью исследования является сокращения числа переборов, так называемая "оптимизация перебора". Также целью публикации является акцентировать внимание читателя на так называемой "битовой магии". Битовой магией владе/ли/ют достаточно известные личности - Брезенхем, Кармак, Абраш...
Я не закончил еще с оптимизацией 8×8. Я на данный вижу несколько новых возможностей для оптимизации перебора.
Как закончу исследования переключусь на доски других размерностей. Для этого просто потребуется кластеризация 64-битной арифметики на N-битную. Ожидается стократный выигрыш перед Pyton (как минимум), ведь все состоит из элементарных процессорных инструкций с минимумом обращений по памяти.
Просто битовая «магия» (когда она не нужна сама по себе) хорошо работает, когда чисел много и они не лезут в кеш процессора. Тогда битовые маски, сжатие и т.п. отлично работают. Здесь же хоть и перебор большой, но чисел и bool'ов в любой момент очень мало.
Я по своему огромному опыту знаю, что на C/C++ - всё будет очень угарно. А ведь задачу можно еще и распределить на множестве ядер/процессоров. Можно её и видюху сунуть и в FPGA. Так что вопрос замера скорости у меня пока не возникал.
Еще раз, - первоочередная цель - "оптимизация перебора". И демонстрация целочисленной арифметики, как средства наилучшей реализации по-скорости.
Запустил ваш код вот здесь, получается 30мс, что в 10 раз медленнее питона на том же onlinegdb.
Уж не знаю, что вы там оптимизировали, но получилось медленно.
Это потому-что, алгоритм нацелен на C/C++ с применением intrinsic и forceinline. Здесь в статье дан прототип на C#. В этом прототипе идут вызовы функций, которые выделены намеряно демонстративно! Для лучшего понимания читателем.
Каким образом буферизируется вывод на консоль C# и Python? А это время не зависящее от работы алгоритма. Для правильных замеров надо в тестах убирать вывод на консоль. Надо делать оптимизацию "A1-A4". Надо убирать лишние вызовы функций. Надо делать 1000-кратные вызовы алгоритма, и в моем случае не вызывать постоянно функцию init().
Когда я говорил про видюху и FPGA - то естественно подразумевались решения на доске типа 1000x1000 и более.
Не может язык с динамической типизацией (Python) работать быстрее, чем алгоритм, где каждая операция представляется соответствующей инструкцией процессора, да еще и однотактной или полутактной(U+V Pipes). Исходник на C++ будет по завершению статьи.
Более эффективный алгоритм на Python'е может быть в 100 раз быстрее неудачного алгоритма на C++ с intrinsic'ами и чем угодно.
ИМХО, ваша реализация неудачная, и даже версия на C++ не обгонит Python.
А на большие доски она вообще очень тяжело масштабируется. А pypy обсчитывает доску 14х14 за 2 секунды.
В чём эффективность Вашего алгоритма? В лобовом переборе? В маркировке атак, через массив? Я маркирую атаки в ЕДИНОМ 64-битном числе и не затрачиваюсь на циклы для установки/снятия атак во время выполнения алгоритма.
Дождитесь версии на C++ пожалуйста, прежде чем делать выводы. Я много раз повторил уже - это прототип для ознакомления с логикой. Я планировал 3 публикации сделать, на эту тему.

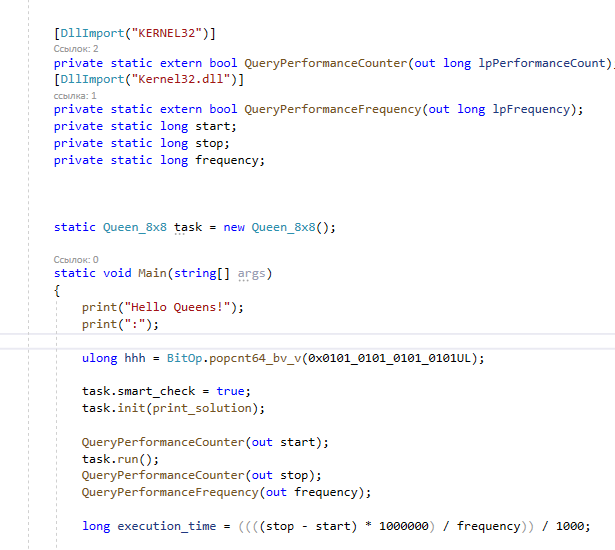
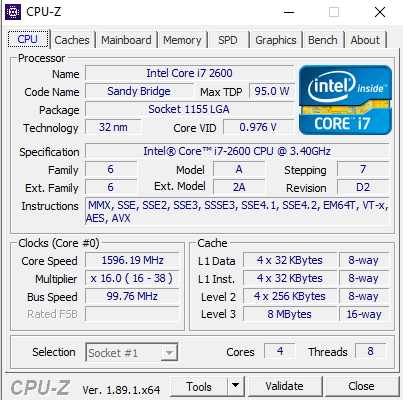
Вы меня порядком вымучили сегодня! 0-1мс у меня на процессоре от 2011 года. Вывод в консоль отключен. Перестаньте уже пожалуйста!
Я не знаю C#, чтобы не разбираться и оценить алгоритм, хорошо было бы понять хоть что-то про время. Я много раз встречал ситуацию, когда «умный велосипед» работает в 100 раз медленнее обычного.
Пришлось разобраться с запуском C#.
Сделал везде 100000 вызовов без вывода в консоль.
На одну итерацию у меня получается:
C# — 0.1013ms
cPython — 0.6469ms
PyPy — 0.1005ms
Rust — 0.0269ms (клон python-решения)
Вот теперь понятен масштаб и уже интересно, до чего можно оптимизировать.
Только вот лучше на доске 12×12 или 14×14. Иначе получается сравнение 0-1ms и 0-1ms.
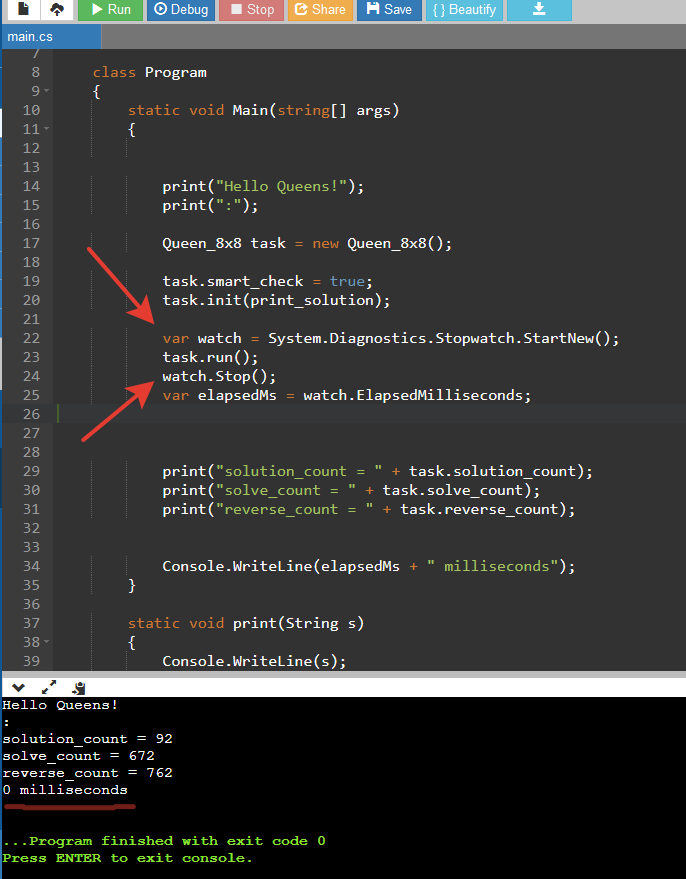
Замерять ввод вывод это конечно отлично для сравнения алгоритмов
Я ещё в конце 90х, на Паскале на I386SX, находил все комбинации за 12сек, против 4минут на вложенных циклах. Применялся 3D массив 8*8*8, при поиске не угрожающих комбинаций. Сейчас не помню, шагов перебора по моему было 284. Если расстановка предыдущих ферзей не создавала угроз, они копировались на слой выше. Если получалась угроза, опускалось на слой ниже и последний ферзь перемещался на следующую клетку. Конец поиска осуществлялся при достижении верхнего слоя без угроз . Потом найденные комбинации поворачивались на 90, 180 и 270 градусов.
Ну... трудно что-либо сказать, если Вы "по памяти" говорите. За основу и меня взята установка ферзей в не угрожающие позиции. Это 2056 вариантов перебора. Я добавил в алгоритм позиционный анализ, что сократило число шагов перебора до 592. Если первого ферзя двигать в пределах [A1-A4] - это 592 / 2 = 296. Все атаки фиксируются битами в 64-битном числе.
Тест выполнения дает 0мс на процессоре от 2011 года. Было бы интересно, если бы восстановили свой алгоритм.
Не мучайте автора, он оптимизирует алгоритм только для доски 8x8.
Он не собирается писать быстрый алгоритм для других размеров доски.
Там его оптимизации просто не будут работать.
На доске 8x8 я хотел изложить концепты. Оптимизации будут работать и на досках другой мерности. Но код будет достаточно огромный, чтобы его размещать в статье. Неужели - это непонятно? Я уже изъял из кода много вещей для статьи, чтобы не загромождать концепт и был подвержен различным замечаниям и полезным советам.
Для других мерностей потребуется кластеризация арифметики. Можно оптимизировать по быстродействию определенные из них. Но данная задача настолько синтетическая и не приносящая практической пользы, что непонятно зачем устраивать вообще весь этот трудоёмкий цирк.
Для супер-мерностей можно прибегнуть к распараллеливанию, шейдерам, FPGA. Только объясните, зачем весь этот балаган нужен?
Эффектов SIMD-байт-вектора хватит до мерности N=127. Для мерностей некратных 8-ми потребуется просто прибавить довесок к числу. Дальше идет переход на слова(2 байта).
Ваши оптимизации основаны на обработке всех клеток за одну операцию. При других размерах это работать не будет.
И самое главное, у вас полный перебор остался, а значит время поиска растет очень быстро.
Насчет супер-мерностей ничего не понял. Тут нет никаких супер-мерностей, доска всегда двумерна, меняется только ее размер.
Вы абсолютно невнимательно смотрели!
1. У меня не осталось полного перебора. Я ввел первичный позиционный анализ. И число переборов значительно сократилось. Я прерываю перебор и делаю реверс-шаги по доске. Реверс-шаг это установка ферзя в единственно возможную позицию на доске. И я обнаруживаю такие ситуации на столбцах и строках. и это собственно моё нововведение/ноухау. Я прерываю линейное прохождение и это отображается в переменной reverse_count. А при помощи 64-разрядной арифметики и SIMD-стиля я делаю это очень быстро. Реверс-ситуация уже может случиться после установки 3-го ферзя. Уже первых три ферзя своими атаками могут образовать строку или столбец, куда можно поставить только одного ферзя.
2. Мои переменные работают в SIMD-стиле. И довольно странно слышать утверждение о том, что они не будут работать на повышенной мерности. Это практически, аналогично как работают MMX/SSE. А они и создавались для обработки больших векторов
Супер-мерности - это доски с очень большим размером. Я только это и имел ввиду. Например 1000x1000
Доска с размером 27 - уже имеет 234,907,967,154,122,528 решений
Вроде и возраст у вас солидный, но каждое высказывание - АХИНЕЯ. Как будто вы сюда потроллить зашли. Абсолютно во всем царит упоротое непонимание. Вы не видите, что написано и сделано. Вы придумываете себе тезисы - и с ними и проводите спор. Ну а я то, тут причём спрашивается. Спорьте сам-с-собой в другом месте.
Переход на оскорбления и личности пока игнорирую.
Извиняюсь, что написал про полный перебор, конечно же у вас перебор с отсечениями. У вас сейчас отсечения только когда осталась одна клетка в стороке/столбце, возможно на больших досках будет работать хуже...
Искать строку/столбец с минимальным количеством свободных клеток думаю будет работать несколько лучше на больших досках. Возможно вам надо попробовать такую оптимизацию (ускоряет она алгоритм или замедляет для больших досок надо проверять). Думаю ускорит. Насколько она будет быстрее вашего отсечения тоже надо проверять на больших досках.
Может вам сразу писать алгоритм для досок любого размера? И использовать System.Runtime.Intrinsics для ускорения с помощью SIMD инструкций? Иначе я не верю, что ваш код будет полезен при переходе от частного случая.
Также для измерения производительности думаю будет полезно заменить вывод в консоль чем нибудь быстрым... Тогда будет легче сравнивать производительность разных хитростей.
В любом случае пока для решения этой задачи существуюь только алгоритмы переборов. Поэтому их сложность быстро растет даже с отсечениями.
Я пытался объяснить в комментариях под этой статьей, почему я выбрал C# и почему работаю на стандартной доске 8x8.
Если бы я начал делать, как говорите/предлагаете Вы, то сложность бы листинга многократно возросла, что привело бы читателя к "закипанию мозгов". И в таком формате "лишь только немногие" могут прочитать код. А дальше - будет ещё намного сложнее.
Я выбрал формат для наиболее популярного изложения замысла и реализации. Естественно в итоге я построю реализацию на C++ с интринсиками и в том числе для разноразмерных досок.
Из-за ограниченности процессорных инструкций приходится прибегать к различным ухищрениям и дополнением, которые даны в новом алгоритме.
Тут все предельно упростилось бы при помощи FPGA на простейшей и элементарной перекоммутации сигналов (Массово переставить биты в числах), но обычный читатель наверно этого бы не понял.
И дальше будут продолжения по теме "оптимизации перебора".
Так как акцент именно на оптимизации/отсечении!
https://habr.com/ru/post/679738/
Не вникнув в первую версию реализации, еще труднее вникнуть в версию 1a
Выбор языка для статьи определялся способностью программисткой аудитории читать код.
Мой листинг на C# спокойно будет читаться программистами: С#, С++, Java
С некоторым напрягом будет доступен программистам: JS, Typescript, AS3
А вот исходники на C++ читаются труднее и заранее отторгаются к прочтению широкой аудиторией.
Лично мне проще всё писать сразу на SystemC)))
Сразу удаляется куча заморочек и шаманские танцы с бубном
Задача о 8-ми ферзях. Свежий взгляд. Шаг первый. Сокращаем количество шагов перебора в три раза