Comments 36
Отличная статья, спасибо, сохранил в закладки)
Буду использовать как мануал ?
Спасибо за статью, очень интересно и структурировано!
За примеры - отдельное спасибо.
В закладки, спасибо
Спасибо за базу - в закладки
Не совсем понятно, а какой выигрыш у GraphQL в сравнении с каким-нибудь json-rpc-like протоколом. Указанные плюсы или совсем несущественные (уменьшение числа получаемых полей) или неверны (уменьшение зависимости от бэка). А вот проблемы - очень существенные, по сути делающими невозможным работу с сколь-нибудь существенной нагрузкой и объемом данных.
У GraphQL есть интересные сценарии использования - но совсем не такие, как указаны в статье.
Уж как пробивал у нас на проекте один товарищ GQL, уж как нахваливал его, любо-дорого было послушать. Как он осмеивал и оплёвывал простой REST. Дали ему добро, в результате, он просит запрашивать максимум по 15-25 сущностей и не чаще чем раз в 5 секунд, иначе сервис ложится... В общем, то ли приготовил он его хреново, то ли лыжи не едут...
Тоже встречал такую проблему, сложные запросы вешали сервер по нагрузке. Кучка маленьких рестов оказались много эффективнее.
Потому что в инете очень много реализаций с крайне неэффективными резолверами, например с запросами в цикле. Причем самое смешное, что это исправляется очень быстро.
Хотя даже 100 сущностей перебором в цикле не должны давать сколь нибудь существенной нагрузки.
Протокол на самом деле очень крутой и решает множество проблем. Где то тут была такая же статья яндекса по переходу. Проблема в том что нет исчерпывающей, доступной каждому информации с указением best practice. Например сколько я обсуждал "проблему n+1" людя делятся на тех кто мучается (и даже не в курсе что резолверы так работать не должны) и тех кто не понимает о чем речь (потому что by design)
GraphQL хорош для взаимодействия фронта с беком. Человеческого фронта. В связи с чем на странице необходимы данные из 15-25 сущностей? Есть ощущение, что это избыточно.
Исходя из моего опыта, в абсолютном большинстве случаев достаточно до 5-6 сущностей на запрос. И вполне может быть несколько gql-запросов, каждый поставляет данные по своему жизненному циклу. Скажем профиль пользователя с его расширенными свойствами, типа подразделение, роли, должности, подтягиваются одним запросом. Табличные данные с пажинацией, другим запросом. Нотификации - третьим.
А проблема N+1 - у нее два аспекта. 1) если источник данных один для двух сущностей, которые нужно склеивать, то это значит разработчики поленились реализовать правильные фетчеры. graphql не причем, это просто транспорт. 2) источники данных разные для двух сущностей, которые нужно склеить. это нетривиальный случай. причем нетривиальный хоть для graphql, хоть для любой другой технологии. dataloader'ы из graphql позволяют закрыть определенные аспекты, но важно понимать, что задача склеивания данных из двух разных источников в общем случае само по себе нетривиальная.
Вот с чем нужно быть осторожным в graphql, это с мутациями. Использовать их очень точечно, там где логика тривиальна. Можно конечно RPC пытаться натягивать на мутации, но это чревато. Для RPC лучше использовать REST.
Мне кажется, мутации это и есть RPC в чистом виде, какой он и должен быть — с методами, аргументами и типами, а не имитация через HTTP-протокол. Только разделения на пространства имен нету, приходится префиксами группировать.
Для RPC использовать REST категорически нельзя, так как это принципиально разные подходы к организации API. Для RPC нужно использовать json-over-http, но не REST
GraphQL по своей природе позволяет вытаскивать сложные графы взаимосвязанных объектов. Что порождает проблему N+1 при взаимодействии с реляционными базами данных.
Это не означает, что GraphQL "плохой". Это означает, что GraphQL'ем надо уметь пользоваться. Точно так же, как и например SQL'ем. Ведь запросто можно написать SQL запрос, который "положит" реляционную базу. Но из за этого же никто не отказывается от реляционных баз в пользу файлового хранилища.
Тут вообще хорошо прослеживается аналогия с реляционными СУБД. Неопытный "GraphQL разработчик" совершает те же ошибки, что и неопытный "SQL разработчик".
На первом месте стоит ошибка в проектировании GraphQL API. Неопытный "SQL разработчик" начитавшись умных книжек начинает проектировать схему базы данных чуть ли не в 5й нормальной форме. Неопытный "GraphQL разработчик" под впечатлением от возможностей синтаксиса GraphQL'я при проектировании API лепит связи там где нужно и там где не нужно. Лечится эта болезнь точно так же, как болезнь 5й нормальной формы - денормализацией. В случае реляционных СУБД проектируем схему в 3й нормальной форме, а потом, в узких местах "денормализуем" до 2й или даже 1й нормальной формы. В случае с GraphQL API закладываем в API все естественныен связи между нашими типами, а потом критически смотрим на получившуюся схему - и убираем все лишние связи и связи, которые потенциально могут породить сложные выборки.
Неопытный SQL разработчик выучив джойны начинает джойнить все что нужно и все что не нужно - потому что может. Точно так же, неопытный GraphQL разработчик начинает тащить сложные граф одним запросом, даже если для решения его прикладной задачи весь этот граф даром не нужен. Просто тащит, потому что может :)
В целом, при переходе на GraphQL нужно четко понимать, что это не серебряная пуля и не волшебная палочка Гарри Потера. Это очень мощный и серьезный инструмент. С помощью которого, при неумелом использовании, можно запросто отстрелить себе ноги. Но, если его хорошо освоить и грамотно использовать, то можно получить гигантские преимущества. На мой взгляд преимущества GraphQL перед REST API такие же, как преимущества реляционных СУБД перед помойкой из файликов.
А как выглядит описание моделей для мобильных клиентов? На каждый кастомный квери запрос пишется кастомная модель?
Да, клиент формирует запрос и должен знать структуру ответа. По сути это коллекция моделей с ассоциативной вложеностью.
Да, так и есть. Спасибо за ответ)
Может быть, будет полезно: в GraphQL запросах клиенты могут использовать Fragments для повторяющихся объектов с одним набором данных. Почитать можно здесь – https://graphql.org/learn/queries/#fragments
И все-таки, как вы решаете 1,2 и 4 "минусы"? Это, мне кажется, настолько большие проблемы, что без решения могут поставить крест на всей этой замечательной архитектуре.
С одной стороны, надо развивать культуру разработки в компании (как минимум бэкенд должен общаться с фронтом). У нас все разработчики клиентских приложений знают об этих уязвимостях GraphQL, так что мы стараемся все вместе продумывать, чтобы их запросы были адекватны по нагрузке для бэкенда. А с другой стороны, и в GraphQL есть механизмы защиты от таких запросов. Можно, например, использовать систему весов. Для этого на каждое поле в схеме навешивается определённый вес. Итоговый вес приходящего запроса превышает максимальный – такой запрос не обрабатывается.
Лично я считаю, что GraphQL правда не очень подходит для сильно конфиденциальной информации, для важных пользовательских данных (поэтому GraphQL не слишком широко используется банками и тд). Однако и на уровне GraphQL сервисов у нас есть проверка токенов пользователя, так что никому ничего лишнего мы не отдадим.
Я упомянул, что с GraphQL имеются проблемы именно с использованием стандартного HTTP кэширования. Если мы при этом хотим отдать что-то очень быстро, нам это не мешает использовать Redis, чтобы не идти за данными в БД, а быстро получить их из памяти.
Если вам надо разработать простой сервис с небольшим количеством страниц, объектов и их взаимосвязей, то GraphQL может быть излишне сложным и медленным. Но если именно сложность системы и связи между различными объектами в ней значительно замедляют вашу разработку. GraphQL – классный вариант решения этой проблемы)
Спасибо за вопрос)
Ну, доступ-то к GraphQL имеют не только "хорошие разработчики backed'а", но и "плохие хакеры". Можно ж тупо выкачать всю, пусть и публичную, базу. Веса спасут, если нагрузка спокойная и/или прогнозируемая. А если маркетинг что-то хорошее придумает, а у вас сервис будет отваливаться по "Too many requests", полетят щепки... Есть ли какой-нибудь fail2ban в GraphQL?
Токены "хорошие"? Со сроком действия и возможностью/необходимостью обновления, типа JWT? В современном мире даже e-mail уже становится "конфиденциальной информацией", а тут такой простор для "парсинга", даже параметры можно выбрать...
Можно спроектировать API так, чтобы даже у хакеров не было возможности получить чужие пользовательские данные (такие, как email). Если не украсть чужой пользовательский токен, никакие чужие данные даже хакер получить не сможет. Если уж хакер украл токен, то защититься в любом случае будет сложно, GraphQL тут не при чём.
Fail2ban, непрогнозируемая нагрузка и тд можно решать (и мы это делаем) на уровне nginx, который стоит перед нашим бэкендом. То есть GraphQL имеет непрямое отношение к этому. Все необходимые меры безопасности надо предпринимать не только на уровне кода, но и на уровне инфраструктуры (имею в виду nginx и тд)
*"хорошие разработчики frontend'а" конечно
При правильном подходе GraphQL API мало чем отличается от обычного REST/RPC API. Вы возвращаете сущность или DTO из контроллера, а GraphQL-слой выбирает из нее поля в соответствии с запросом и настройками маппинга. Не все библиотеки для GraphQL так делают, но это возможно.
О каких библиотеках речь? Клиентских? "Плохие люди" могут использовать "плохие библиотеки". Если я правильно понимаю, то GraphQL по сути как открытый MySQL - пиши свои запросы как хочешь и кто хочешь (понятно утрировано, но все же). Имхо, слой приложения хорош тем, что в нем относительно удобно можно (и нужно) ограничить доступ к данным.
Нет, для бэкенда Например для PHP есть библиотека GraphQLite. По личному впечатлению такой код проще писать и поддерживать, чем HTTP API с громоздкой документацией для Swagger.
Т.е. в данном случае GraphQL используется "тупо" как БД? Как мне кажется, идея была именно в том, чтобы отдать клиенту всю логику приложения и убрать слой php полностью.
Т.е. Javascript на клиенте делает запрос типа
curl 'https://zvuk.com/api/v1/graphql' --data-raw $'{"operationName":"getTracks","variables":{"withReleases":true,"withArtists":true,"ids":[124167105]}}"и получает JSON с данными напрямую (автор говорит через NGINX, но без PHP). Захотел, отсортировал как надо. Захотел, получил больше полей. Захотел, скачал всю базу ;)
Нет нет нет, GraphQL совсем не предполагает отказ от разработки бэкенда. Под GraphQL может вообще не быть базы данных. Слой PHP (или любого другого языка) не исчезает.
Какие-то поля могут подтягиваться из базы (это надо прописывать кодом), какие-то поля могут быть получены по API из других систем (это тожно надо прописывать кодом), а какие-то поля могут быть рассчитаны прям в коде (очевидно, тут тоже код)
То есть GraphQL – это такое же API, которое надо разрабатывать. И логику для каждого объекта/поля можно (и нужно) отдельно программировать
Как мне кажется, идея была именно в том, чтобы отдать клиенту всю логику приложения и убрать слой php полностью.
Нет, такой идеи, насколько я знаю, нигде никогда не было.
GraphQL можно рассматривать как развитие обычного HTTP API, с типами и возможностью указывать список нужных полей. Что там что там нужен бэкенд.
кеширование на стороне источника данных. там где канонически и должно быть. понятно, что у этого есть свои плюсы/минусы.
Выглядит на первый взгляд интересно, но немного удивляет описанная в статье архитектура. Неужели Apollo Federation действительно торчит голой ж в интернет доступна с клиентов напрямую?
Кажется же что тогда на неё ложиться ещё вагон всяких задач как раз в духе авторизации, прав доступа и тому подобного, или я ошибаюсь? И они, кажется, могут быть уникальны для каждого сетапа.
Но в роли того чтобы на беке собирать забросы по разным микросервисам - выглядит интересно.
На самом деле, это скорее концептуальная архитектура на диаграмме. Вы очень правильно заметили, что в таком случае на федерацию ложится слишком много работы, для которой она не приспособлена.
В частности, для авторизации запросов перед федерацией ещё стоит nginx, который и проверяет токены пользователей)
Спасибо за хороший вопрос))
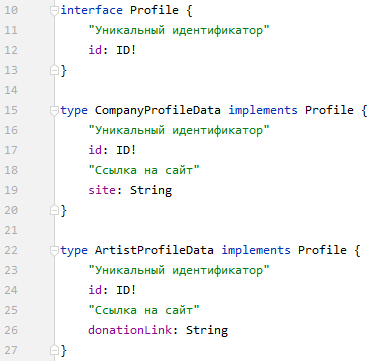
Чем обусловлено использование именно union, а не interface?
Профили содержат одинаковый набор данных, за исключением некоторых полей (сайт\ссылки для доната). Можно сделать общий Profileинтерфейс и определить в нем все общие поля для всех профилей, затем для каждого конкретного типа свои собственные специальные поля и получить доступ к этим конкретным полям с помощью фрагментов.
На мой взгляд union подходит, когда используются совершенно разные объекты. Например, при получении данных в каталоге по книгам, фильмам и еще чего-нибудь, но в случае с профилем это ведь не совсем так.
Например, у нас в Звуке есть несколько типов профилей – обычные пользователи, профили компаний и профили артистов. У профилей компаний есть сайт, которого нет у остальных типов. А у профилей артистов есть ссылка для донатов и связанный с профилем артист из сервиса информации о контенте. Для организации таких разных профилей используется UNION.
Ну тут основная проблема в том, что перед открытием профиля мы знаем только его ID, но ещё не знаем его тип. В зависимости от типа у него может быть разный набор полей. Таким образом, при помощи UNION мы в запросе можем указать нужные данные для каждого из типов в одном запросе. Нет необходимости сначала узнавать тип профиля, а потом понимать, какие дополнительные поля по нему надо дозапросить (хотя фрагменты и упростят этот процесс).
Вполне возможно, что я вообще не очень понял вашу идею. Если так, то буду рад более подробным объяснением того, как это может работать через интерфейсы и фрагменты.
И вообще, спасибо за хороший вопрос)
И union, и interface не требуют знаний типа профиля. Оба способа действуют по схеме "Один из..". Идея interface заключается в том, что структуру данных для профиля Компании и профиля Артиста можно задать в общем интерфейсе - профиле (или м.б. профиле Юзера). В концепции unoin это все разные не связанные объекты.
Как можно представить схему:
Как может выглядеть сам запрос:
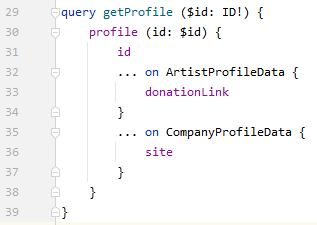
Пример без фрагментов, но думаю с ними все понятно: вместо donationLink/site добавить ссылки на фрагменты со специфичными данными для каждого профиля. Как видно, общие данные для каждого типа интерфейса определяются и запрашиваются не в типах. На выходе у конкретного профиля получим общие + специфичные данные.
В общем-то, мне было интересно, почему в вашем проекте используется именно Union :)
Не так давно моя команда тоже перешла на GQL, приходится все быстро изучать и придумывать, как это все документировать при подходе API\GQL-First. Спасибо за статью, почерпнула для себя интересные моменты.
Да, и вправду в случае с профилями можно было бы использовать интерфейсы. Насколько я понимаю, главное отличие от UNION здесь заключается в слове __typename, которого нет в случае интерфейсов. Конкретно в нашей системе от этого __typename довольно много зависит (логика отображения в приложении). Если бы надо было только отображать/не отображать какие-то поля или блоки на странице, то можно было бы обойтись интерфейсом, а нам надо иногда знать тип.
При этом я понимаю, что можно было бы просто использовать отдельное поле type, но в этом случае нет уже совсем никакого отличия между union и interface
Мне все еще кажется что graphql может быть идеальным инструментом когда он идет в одну таблицу/коллекцию где ВСЕ данные уже собраны. Т.е. read side от CQRS. Фронтендеры и клиенты получают унифицированный язык и это хороше.
А вот когда туда запихивают запросы к разным сущностям, базам, коллекциям, я даже не представляю как оно может нормально работать при нагрузке.
Еще никто меня не смог переубедить :/
Ну теперь понятно почему он такой тормознутый.
Мы считаем, что в Звуке достоинства GraphQL значительно перевешивают недостатки. Благодаря этой технологии мы значительно упрощаем разработку и снижаем время доставки новых фичей до пользователей нашего сервиса.
Повышая при этом время отклика и неадекватность поиска. Как так получается, что в приложении при поиске по точному названию группы в быстрых результатах он выдаёт одни подкасты? Мне кажется, что музыкальный сервис прежде всего должен быть про музыкантов и их музыку, а подкасты должны быть в наименьшем приоритете.
Как упростить жизнь за 312 коротких шагов: проектируем GraphQL API в микросервисной архитектуре